
Antisense Peptide Technology for Diagnostic Tests and Bioengineering Research


Abstract
:1. Introduction
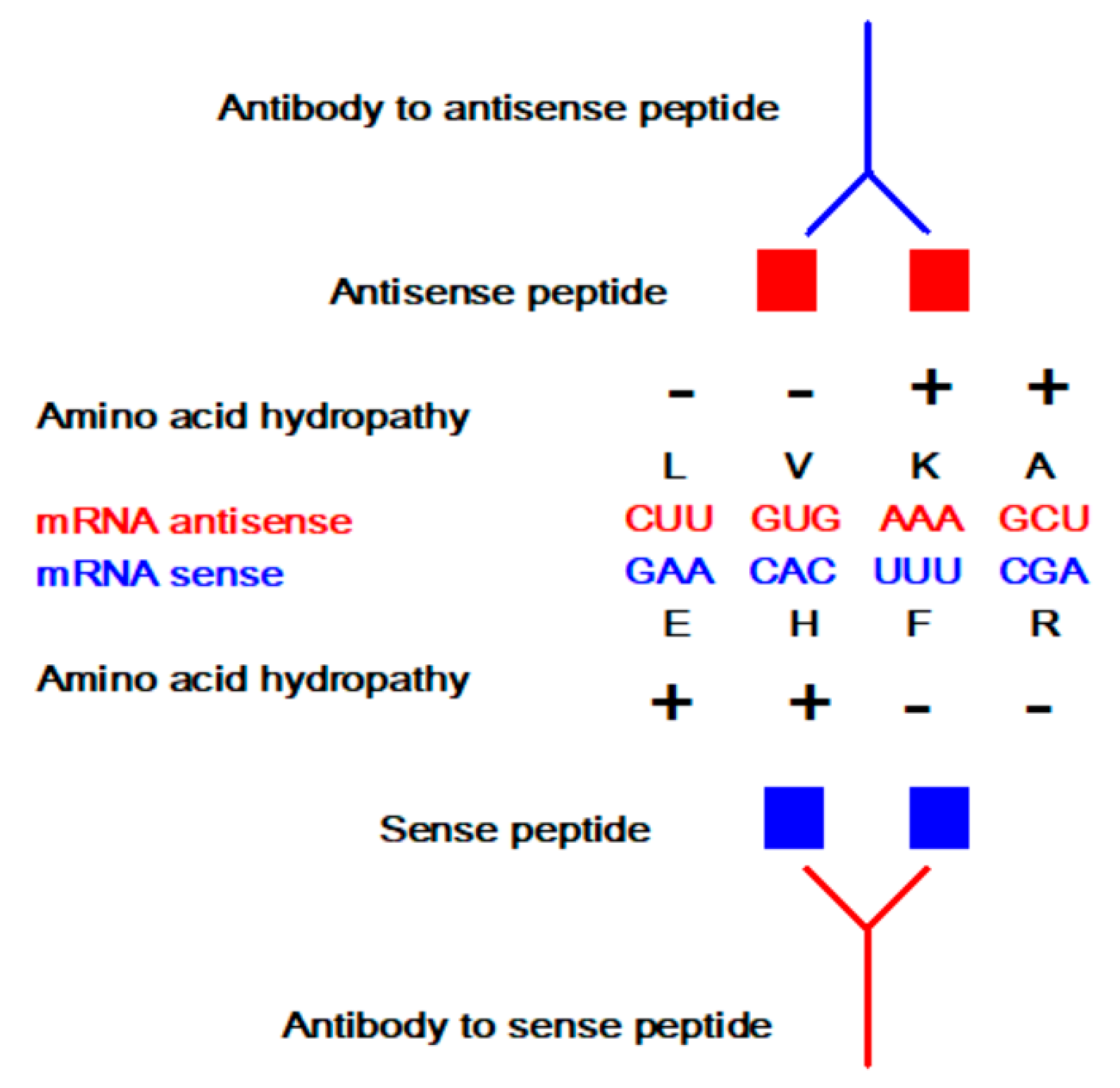
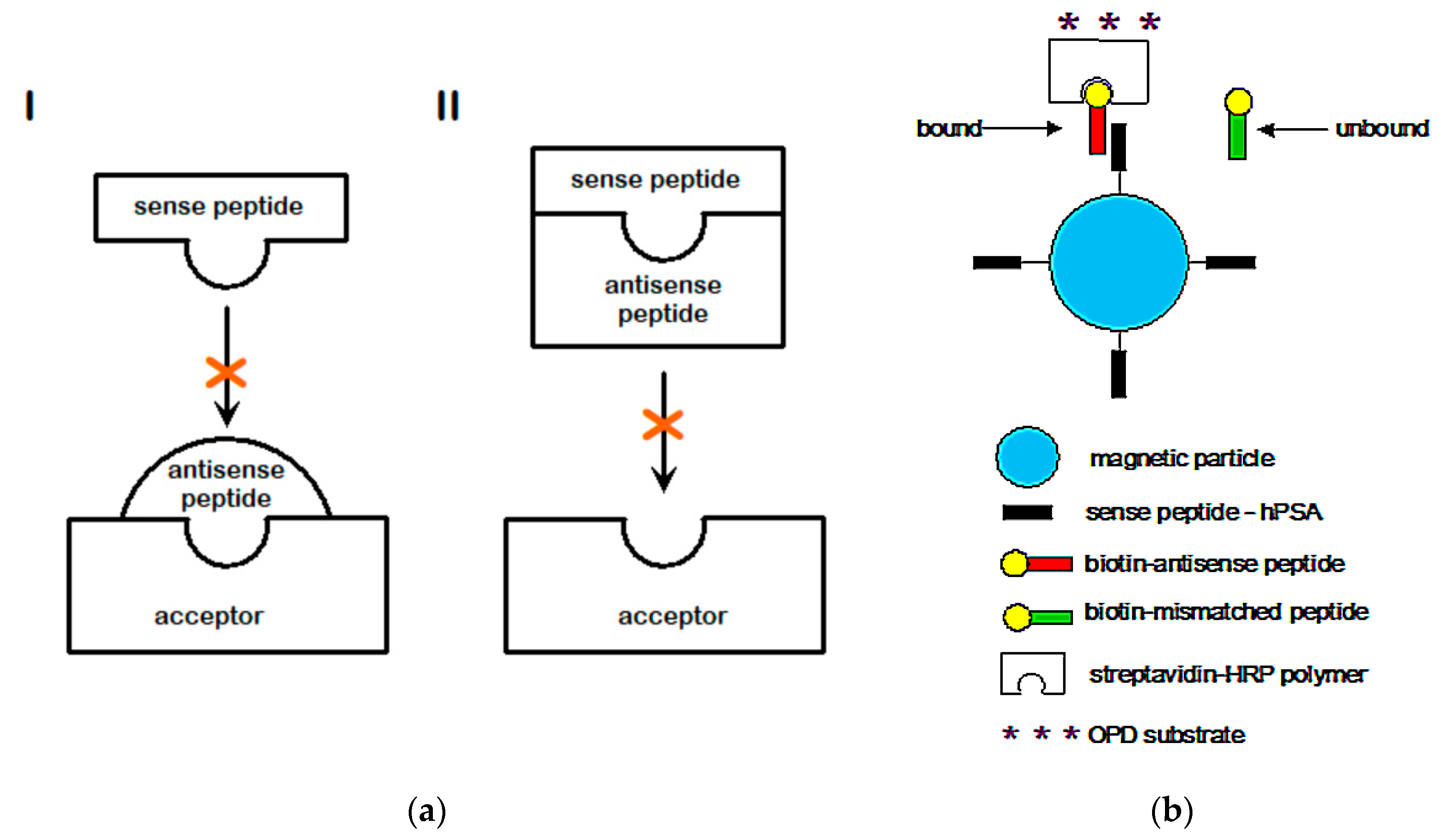
2. Antisense Peptide Technology (APT)
- reliance on continuous epitopes,
- overconfidence in ligand specificity,
- amino acid bias in characterizing ligand-acceptor (receptor) interactions,
- difficulties in the estimation of structure-function relationships between specific ligand–acceptor (receptor) pairs,
- amino acid coding, complementarity, and frameshifts.
2.1. Reliance on Continuous Epitopes
2.2. Overconfidence in the Ligand Specificity
2.3. Amino Acid Bias in Characterizing Ligand-Acceptor (Receptor) Interactions
2.4. Difficulties in the Estimation of Structure-Function Relationships between Specific Ligand-Acceptor (Receptor) Pairs
- peptides binding into molecular complexes (leaving none or low levels of sense peptide to elicit its own biological effects),
- total or partial antagonization of the sense peptide receptor by means of its complexation with an antisense ligand,
- combination of the first two factors,
- other biological or biochemical effects of an antisense peptide that cannot be explained by the involvement of a sense peptide and its receptors (e.g., generation of bioactive antibodies to peptides and/or their complexes, cellular receptor, and growth factor modulation).
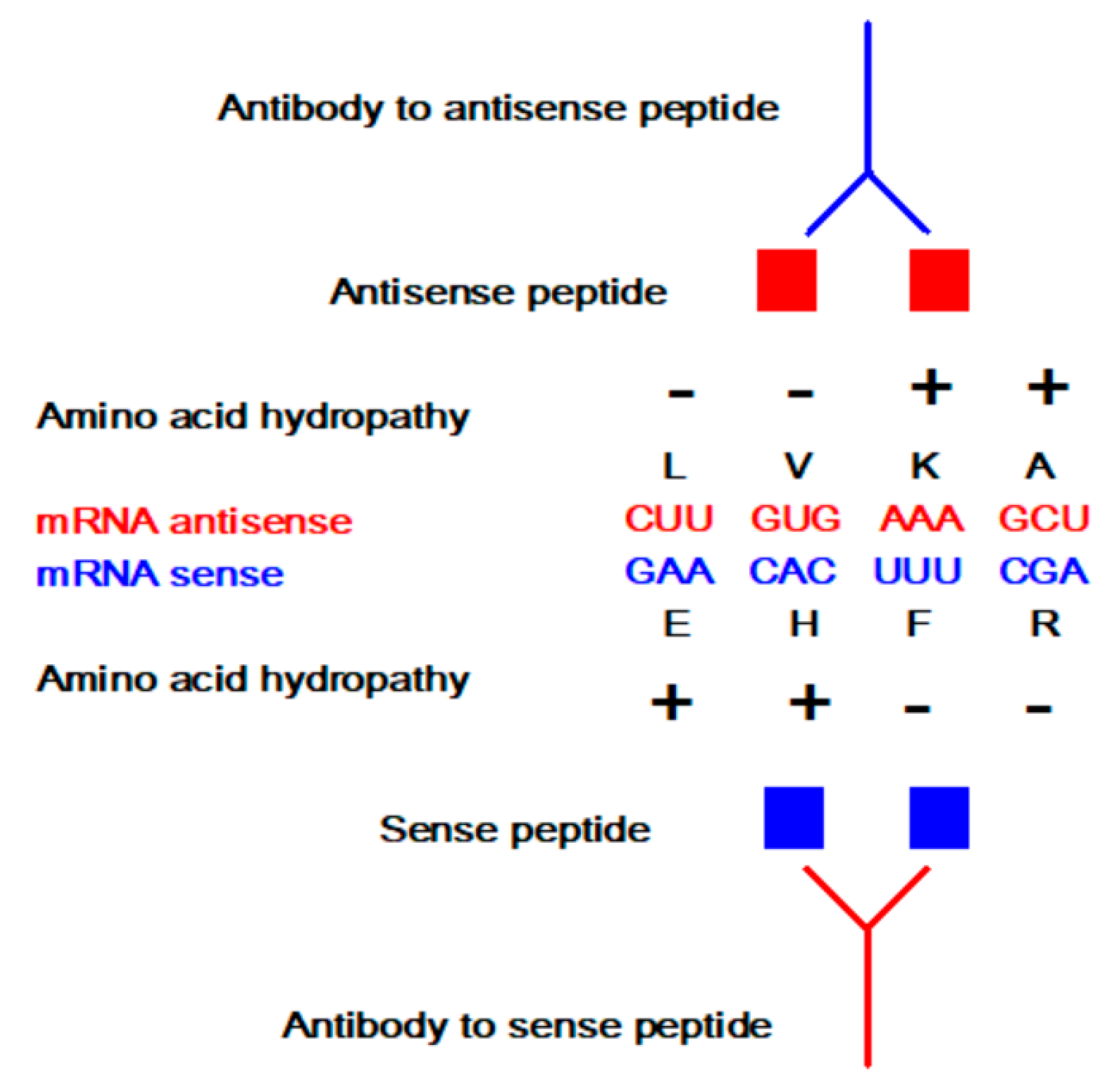
2.5. Amino Acid Coding, Complementarity, and Frameshifts
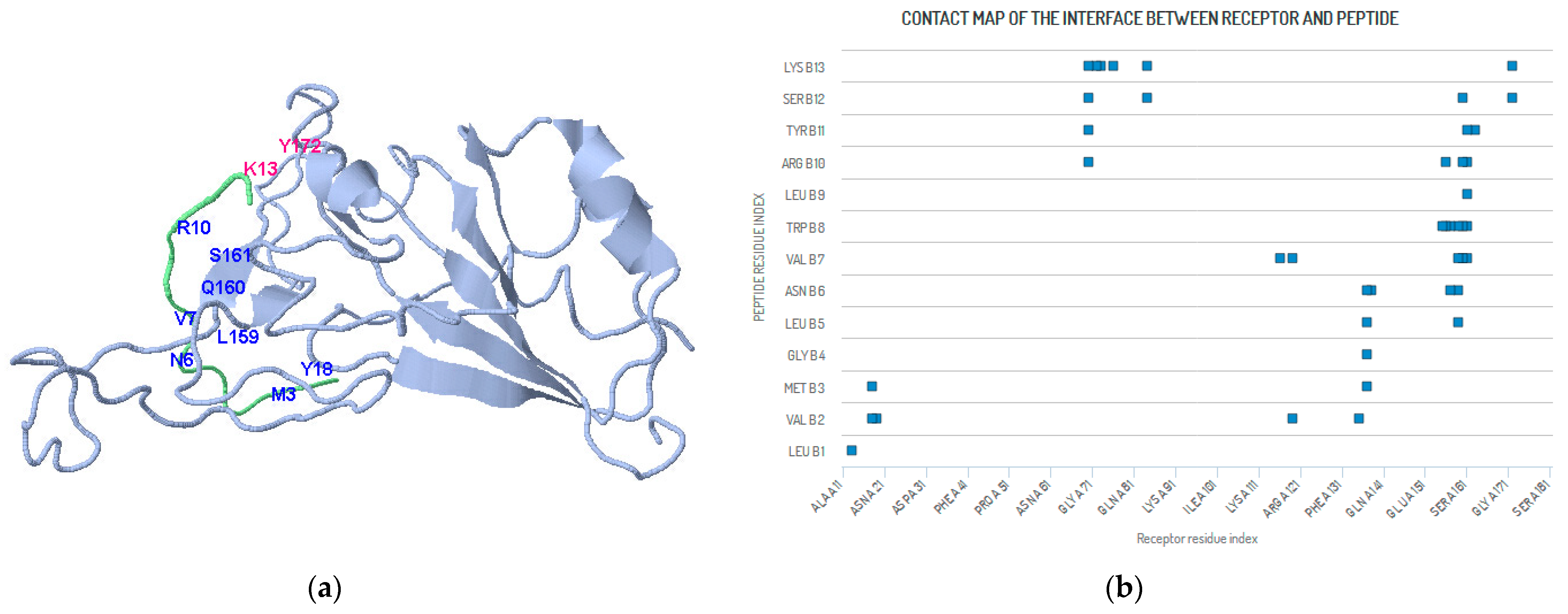
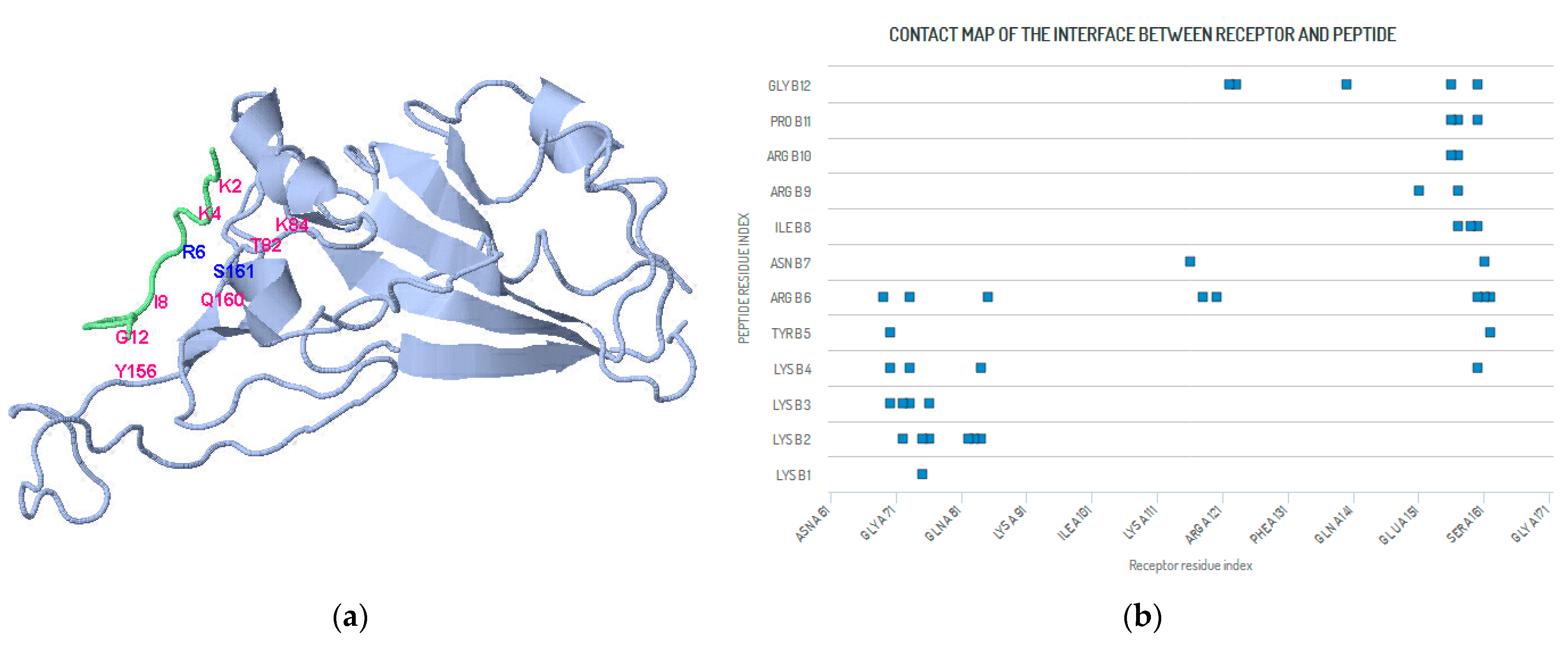
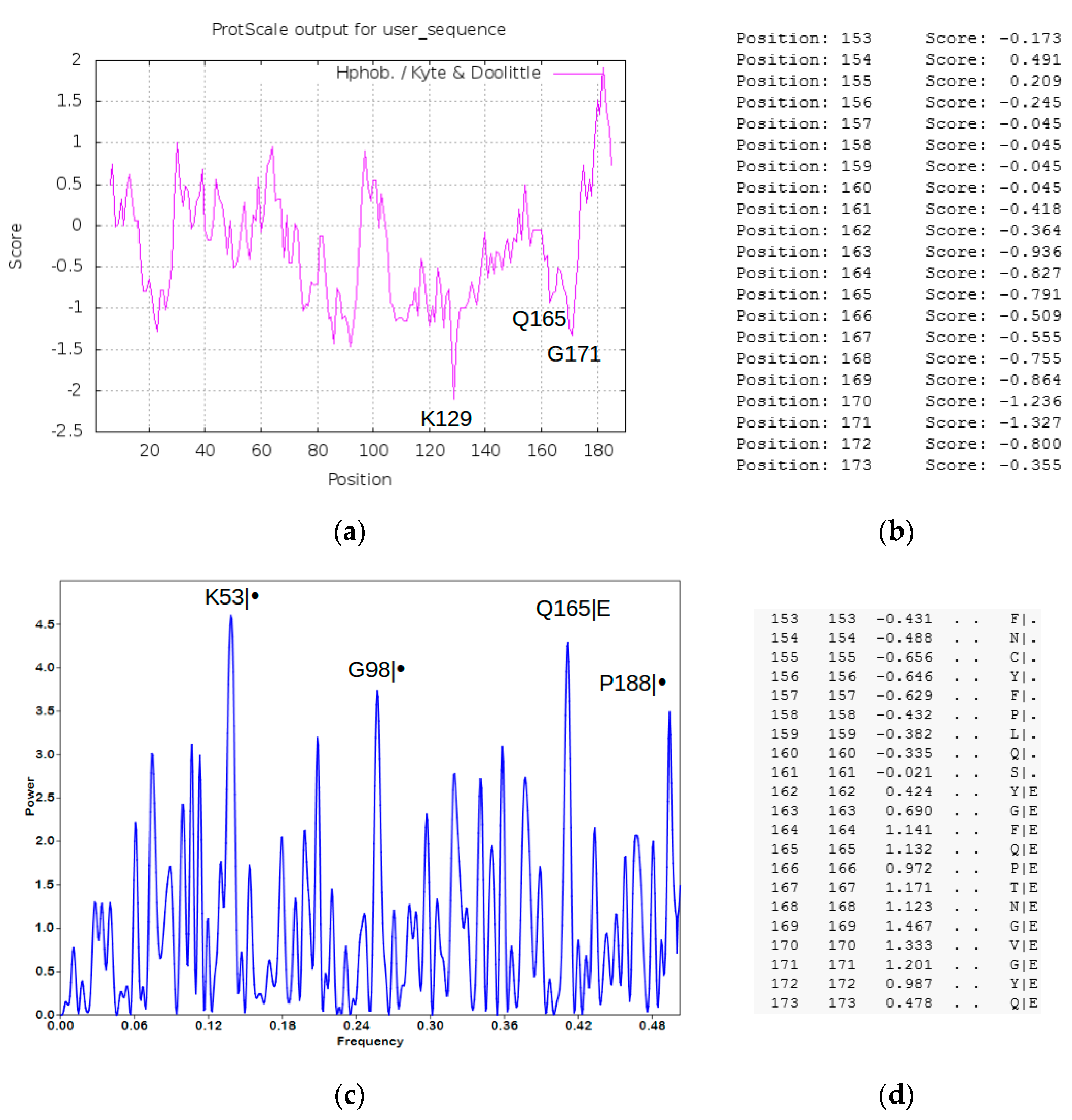
3. An Example of SARS-CoV-2
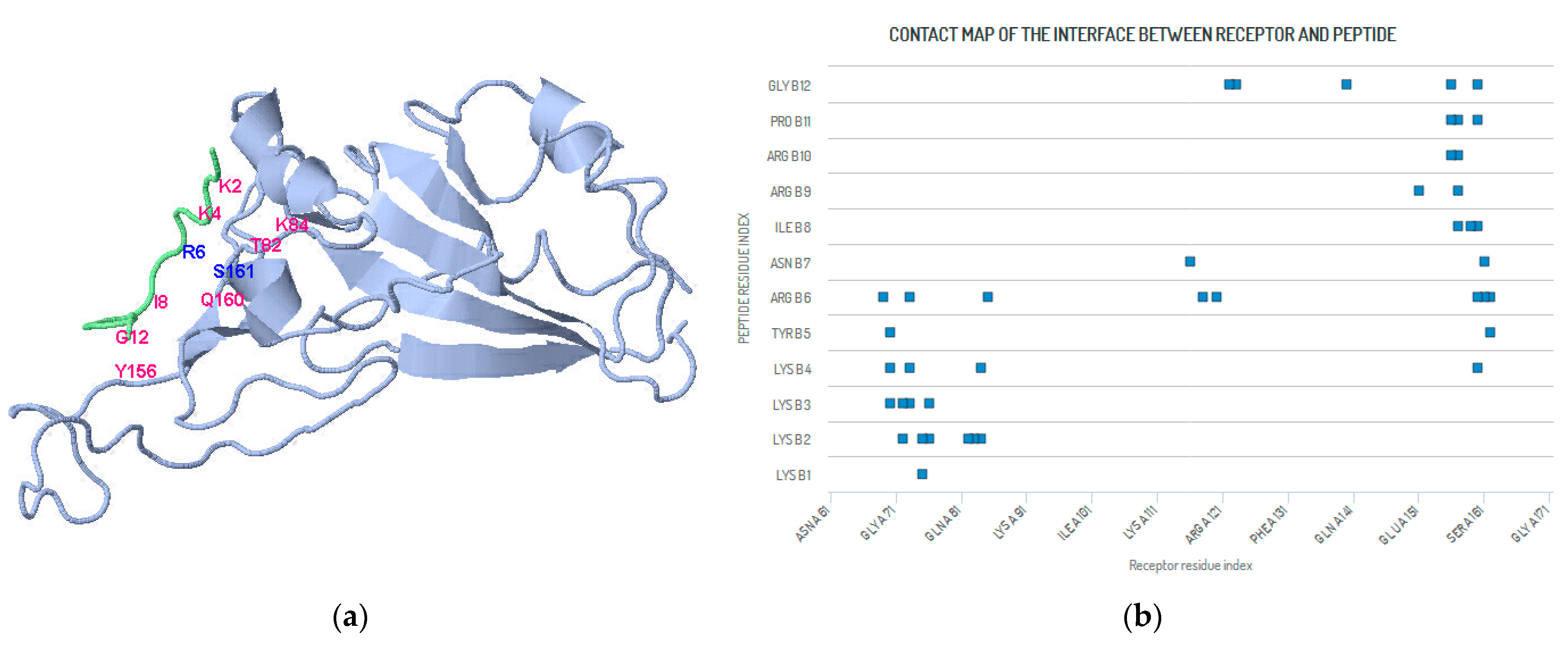
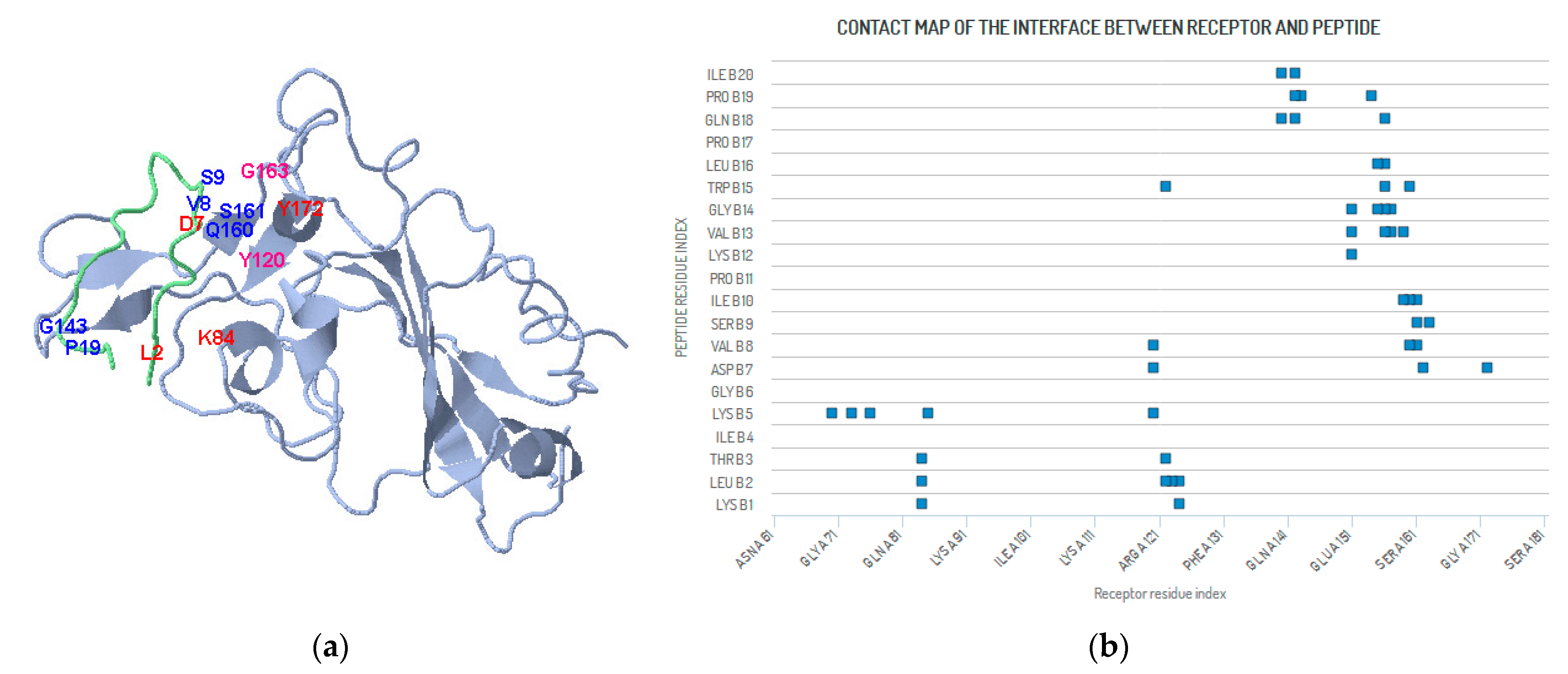
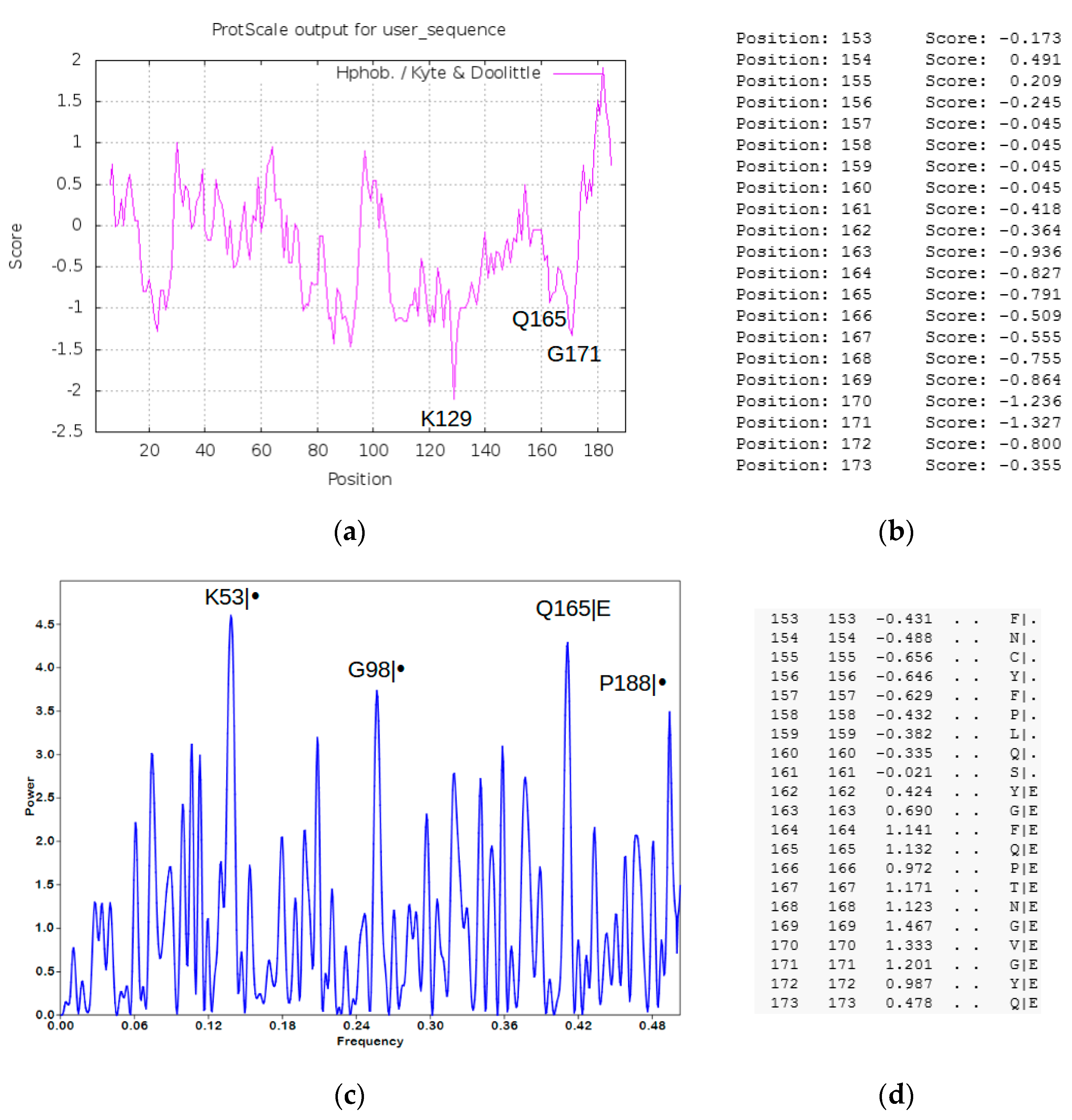
4. Methods and Results (SARS-CoV-2 Peptide Modeling)
4.1. Peptide Modeling and Peptide–Protein Docking
4.2. Heuristic Antinsense Peptide Design (HAPD)
5. Conclusions
- selection of different targets and evaluation of complementary (sense–antisense) peptide binding;
- quantification of specific antibodies, peptides, and proteins;
- design of MPEIAs and Multiplex ELISAs tailored for a specific purpose.
- Quick design and validation of the complementary ligands and acceptors;
- Computational validation and virtual screening of different protein and peptide structures;
- Rationalization of peptide library screening;
- The tests can be produced in a short period of time;
- The tests will be made composite (according to the LEGO principle) and will consist of less expensive and commercially available components;
- The time required to obtain results is shorter (since no antibody production is needed);
- The test enables large quantity sample testing using standard laboratory equipment (since it does not require special reagents or complicated sampling processing);
- The tests are likely to prove important for the investigation of the immune response, disease pathogenesis, and clinical outcome of different infections;
- Designed antisense peptides (and anti-antisenses [21]) may also provide a basis for further development of vaccines and lead compounds for different diseases;
- Detection of mutant strains is quicker since new antisense peptide motifs could be synthesized, evaluated for binding, and easily linked to magnetic particles in a short period of time, which avoids the antibody production process;
- A green chemistry approach significantly reduces or avoids the loss of animal life.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
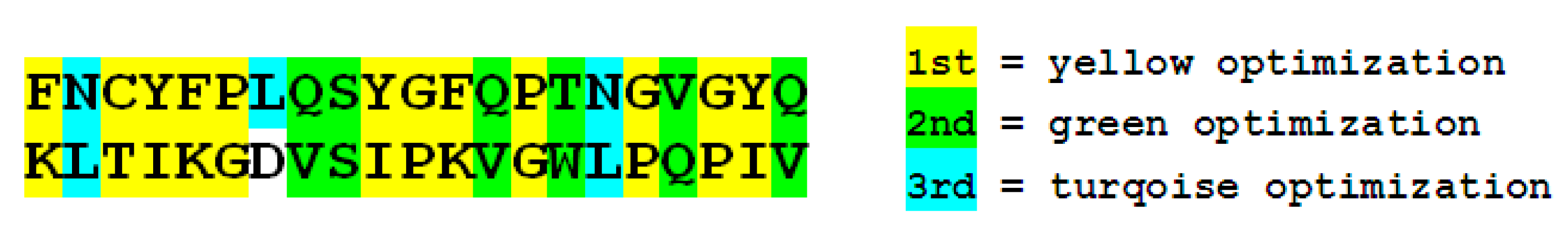{kind=link}
{kind=link}
| NLCPFGEVFNATRFASVYAWNRKRISNCVADYSVLYNSASFSTFKCYGVSPTKLNDLCFTNVYADSFVIRGDEVRQIAPGQTGKIADYNYKLPDDFTGCVIAWNSNNLDSKVGGNYNYLYRLFRKSNLKPFERDISTEIYQAGSTPCNGVEGFNCYFPLQSYGFQPTNGVGYQPYRVVVLSFELLHAPAT |
| Receptor Residue | Peptide Residue | Receptor Residue | Peptide Residue | Receptor Residue | Peptide Residue |
|---|---|---|---|---|---|
| SER A 161 | ASN B 7 | TYR A 162 | TYR B 5 | TYR A 162 | ARG B 6 |
| GLN A 160 | PRO B 11 | GLN A160 | GLY B 12 | SER A 161 | ARG B 6 |
| GLN A 160 | LYS B 4 | GLN A 160 | ARG B 6 | GLN A 160 | ILE B 8 |
| PHE A 157 | ARG B 10 | PHE A 157 | PRO B 11 | LEU A 159 | ILE B 8 |
| TYR A 156 | GLY B 12 | PHE A 157 | ILE B 8 | PHE A 157 | ARG B 9 |
| GLU A 151 | ARG B 9 | TYR A156 | ARG B 10 | TYR A156 | PRO B 11 |
| LEU A 122 | GLY B 12 | PHE A 123 | GLY B 12 | TYR A 140 | GLY B 12 |
| TYR A 116 | ASN B 7 | TYR A 118 | ARG B 6 | TYR A 120 | ARG B 6 |
| LYS A 84 | LYS B 2 | LYS A 84 | LYS B 4 | ILE A 85 | ARG B 6 |
| GLN A 76 | LYS B 3 | THR A 82 | LYS B 2 | GLY A 83 | LYS B 2 |
| ARG A 75 | LYS B 1 | ARG A 75 | LYS B 2 | GLN A 76 | LYS B 2 |
| GLU A 73 | LYS B 3 | GLU A 73 | LYS B 4 | GLU A 73 | ARG B 6 |
| ARG A 70 | TYR B 5 | ASP A 72 | LYS B 2 | ASP A 72 | LYS B 3 |
| ILE A 69 | ARG B 6 | ARG A 70 | LYS B 3 | ARG A 70 | LYS B 4 |
| Receptor Residue | Peptide Residue | Receptor Residue | Peptide Residue | Receptor Residue | Peptide Residue |
|---|---|---|---|---|---|
| TYR A 172 | ASP B 7 | TYR A 162 | ASP B 7 | GLY A 163 | SER B 9 |
| SER A 161 | ILE B 10 | SER A 161 | VAL B 8 | SER A 161 | SER B 9 |
| GLN A 160 | TRP B 15 | GLN A 160 | VAL B 8 | GLN A 160 | ILE B 10 |
| LEU A 159 | VAL B 13 | PHE A 157 | GLY B 14 | LEU A 159 | ILE B 10 |
| PHE A 157 | VAL B 13 | TYR A 156 | LEU B 16 | TYR A 156 | GLN B 18 |
| TYR A 156 | TRP B 15 | TYR A 156 | VAL B 13 | TYR A 156 | GLY B 14 |
| CYS A 155 | LEU B 16 | ASN A154 | PRO B 19 | CYS A 155 | GLY B 14 |
| GLU A 151 | GLY B 14 | GLU A 151 | LYS B 12 | GLU A 151 | VAL B 13 |
| GLYA 143 | PRO B 19 | ALA A 142 | PRO B 19 | ALA A 142 | ILE B 20 |
| ALA A 142 | GLN B 18 | TYR A 140 | GLN B 18 | TYR A 140 | ILE B 20 |
| ARG A 124 | LEU B 2 | PHE A 123 | LEU B 2 | ARG A 124 | LYS B 1 |
| LEU A 122 | TRP B 15 | LEU A 122 | LEU B 2 | LEU A 122 | THR B 3 |
| TYR A 120 | VAL B 8 | TYR A 120 | LYS B 5 | TYR A 120 | ASP B 7 |
| ILE A 85 | LYS B 5 | LYS A 84 | LEU B 2 | LYS A 84 | THR B 3 |
| LYS A 84 | LYS B 1 | GLU A 73 | LYS B 5 | GLN A 76 | LYS B 5 |
| ARG A 70 | LYS B 5 |
| Receptor Residue | Peptide Residue | Receptor Residue | Peptide Residue | Receptor Residue | Peptide Residue |
|---|---|---|---|---|---|
| TYR A 172 | LYS B 13 | GLY A 163 | TYR B 11 | TYR A 172 | SER B 12 |
| SER A 161 | TYR B 11 | SER A 161 | LEU B 9 | SER A 161 | ARG B 10 |
| SER A 161 | TRP B 8 | GLN A 160 | SER B 12 | SER A 161 | VAL B 7 |
| GLN A 160 | ARG B 10 | GLN A 160 | VAL B 7 | GLN A160 | TRP B 8 |
| LEU A 159 | TRP B 8 | LEU A 159 | ASN B 6 | LEU A 159 | VAL B 7 |
| LEU A 159 | LEU B 5 | PHE A 157 | ASN B 6 | PHE A 157 | TRP B 8 |
| TYR A 156 | ARG B 10 | CYS A 155 | TRP B 8 | TYR A 156 | TRP B 8 |
| GLU A 138 | ASN B 6 | THR A 137 | LEU B 5 | THR A 137 | ASN B 6 |
| THR A 137 | GLY B 4 | ILE A 135 | VAL B 2 | THR A 137 | MET B 3 |
| LEU A 119 | VAL B 7 | TYR A 116 | VAL B 7 | LEU A 119 | VAL B 2 |
| LYS A 84 | LYS B 13 | GLN A 76 | LYS B 13 | LYS A 84 | SER B 12 |
| GLU A 73 | LYS B 13 | ARG A 70 | LYS B 13 | ASP A 72 | LYS B 13 |
| ARG A 70 | SER B 12 | ARG A 70 | ARG B 10 | ARG A 70 | TYR B 11 |
| ALA A 19 | VAL B 2 | TYR A 18 | VAL B 2 | TYR A 18 | MET B 3 |
| ARG A 13 | LEU B 1 |

References
- Root-Bernstein, R.S. Amino acid pairing. J. Theor. Biol. 1982, 94, 885–894. [Google Scholar] [CrossRef]
- Loo, J.A.; Holsworth, D.D.; Root-Bernstein, R.S. Use of electrospray ionization mass spectrometry to probe antisense peptide interactions. Biol. Mass Spectrom. 1994, 23, 6–12. [Google Scholar] [CrossRef]
- Holsworth, D.D.; Kiely, J.S.; Root-Bernstein, R.S.; Overhiser, R.W. Antisense-designed peptides: A comparative study focusing on possible complements to angiotensin II. Pept. Res. 1994, 7, 185–193. [Google Scholar]
- Root-Bernstein, R.S.; Holsworth, D.D. Antisense peptides: A critical mini-review. J. Theor. Biol. 1998, 21, 107–119. [Google Scholar] [CrossRef]
- Root-Bernstein, R.S. Peptide self-aggregation and peptide complementarity as bases for the evolution of peptide receptors: A review. J. Mol. Recognit. 2005, 18, 40–49. [Google Scholar] [CrossRef]
- Root-Bernstein, R. How to make a non-antigenic protein (auto) antigenic: Molecular complementarity alters antigen processing and activates adaptive-innate immunity synergy. Anticancer Agents Med. Chem. 2015, 15, 1242–1259. [Google Scholar] [CrossRef]
- Blalock, J.E. Complementarity of peptides specified by ‘sense’ and ‘antisense’ strands of DNA. Trends. Biotechnol. 1990, 8, 140–144. [Google Scholar] [CrossRef]
- Blalock, J.E. Genetic origin of protein shape and interaction rules. Nat. Med. 1995, 1, 876–878. [Google Scholar] [CrossRef] [PubMed]
- Biro, J.C. The proteomic code: A molecular recognition code for proteins. Theor. Biol. Med. Model. 2007, 4, 1–45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mekler, L.B. Specific selective interaction between amino acid residues of the polypeptide chains. Biophys. USSR 1970, 14, 613–617. [Google Scholar]
- Mekler, L.B.; Idlis, R.G. Construction of models of three-dimensional biological polypeptide and nucleoprotein molecules in agreement with a general code which determines specific linear recognition and binding of amino acid residues of polypeptides to each other and to the trinucleotides of polynucleotides. Depos. Doc. VINITI 1981, 1476–1481. (In Russian) [Google Scholar]
- Tropsha, A.; Kizert, J.S.; Chaiken, I.M. Making sense from antisense: A review of experimental data and developing ideas on sense-antisense peptide recognition. J. Mol. Recognit. 1992, 5, 43–54. [Google Scholar] [CrossRef]
- Siemion, I.Z.; Cebrat, M.; Kluczyk, A. The problem of amino acid complementarity and antisense peptides. Curr. Protein Pept. Sci. 2004, 5, 507–527. [Google Scholar] [CrossRef] [PubMed]
- Heal, J.R.; Roberts, G.W.; Raynes, J.G.; Bhakoo, A.; Miller, A.D. Specific interactions between sense and complementary peptides: The basis for the proteomic code. ChemBioChem 2002, 3, 136–151. [Google Scholar] [CrossRef]
- Miller, A.D. Sense-antisense (complementary) peptide interactions and the proteomic code; potential opportunities in biology and pharmaceutical science. Expert. Opin. Biol. Ther. 2015, 15, 245–267. [Google Scholar] [CrossRef]
- Štambuk, N. On the genetic origin of complementary protein coding. Croat. Chem. Acta 1998, 71, 573–589. [Google Scholar]
- Štambuk, N.; Konjevoda, P.; Boban-Blagaić, A.; Pokrić, B. Molecular recognition theory of the complementary (antisense) peptide interactions. Theory Biosci. 2005, 123, 265–275. [Google Scholar] [CrossRef]
- Štambuk, N.; Manojlović, Z.; Turčić, P.; Martinić, R.; Konjevoda, P.; Weitner, T.; Wardega, P.; Gabričević, M. A simple three-step method for design and affinity testing of new antisense peptides: An Example of Erythropoietin. Int. J. Mol. Sci. 2014, 15, 9209–9223. [Google Scholar] [CrossRef]
- Štambuk, N.; Konjevoda, P.; Turčić, P.; Kövér, K.; Novak Kujundžić, R.; Manojlović, Z.; Gabričević, M. Genetic coding algorithm for sense and antisense peptide interactions. Biosystems 2018, 164, 199–216. [Google Scholar] [CrossRef]
- Štambuk, N.; Konjevoda, P.; Turčić, P.; Šošić, H.; Aralica, G.; Babić, D.; Seiwerth, S.; Kaštelan, Ž.; Kujundžić, R.N.; Wardega, P.; et al. Targeting Tumor Markers with Antisense Peptides: An Example of Human Prostate Specific Antigen. Int. J. Mol. Sci. 2019, 20, 2090. [Google Scholar] [CrossRef] [Green Version]
- McGuire, K.L.; Holmes, D.S. Role of complementary proteins in autoimmunity: An old idea re-emerges with new twists. Trends Immunol. 2005, 26, 367–372. [Google Scholar] [CrossRef]
- Dayhoff, G.W.; van Regenmortel, M.H.V.; Uversky, V.N. Intrinsic disorder in protein sense-antisense recognition. J. Mol. Recognit. 2020, 33, e2868. [Google Scholar] [CrossRef] [PubMed]
- Štambuk, N.; Kopjar, N.; Šentija, K.; Garaj-Vrhovac, V.; Vikić-Topić, D.; Marušić-Della Marina, B.; Brinar, V.; Trbojević-Čepe, M.; Žarković, N.; Ćurković, B.; et al. Cytogenetic effects of met-enkephalin (peptid-M) on human lymphocytes. Croat. Chem. Acta 1998, 71, 591–605. [Google Scholar]
- Štambuk, N.; Konjevoda, P. Determining amino acid scores of the genetic code table: Complementarity, structure, function and evolution. Biosystems 2020, 187, 104026. [Google Scholar] [CrossRef] [PubMed]
- Van Regenmortel, M.H.V. Synthetic peptide vaccines and the search for neutralization B cell epitopes. Open Vaccine J. 2009, 2, 33–44. [Google Scholar] [CrossRef]
- Uversky, V.N.; van Regenmortel, M.H.V. Mobility and disorder in antibody and antigen binding sites do not prevent immunochemical recognition. Crit. Rev. Biochem. Mol. Biol. 2021, 56, 149–156. [Google Scholar] [CrossRef] [PubMed]
- Edmundson, A.B.; Ely, K.R.; Herron, J.N.; Cheson, B.D. The binding of opioid peptides to the Mcg light chain dimer: Flexible keys and adjustable locks. Mol. Immunol. 1987, 24, 915–935. [Google Scholar] [CrossRef]
- Ciemny, M.; Kurcinski, M.; Kamel, K.; Kolinski, A.; Alam, N.; Schueler-Furman, O.; Kmiecik, S. Protein-peptide docking: Opportunities and challenges. Drug Discov. Today 2018, 23, 1530–1537. [Google Scholar] [CrossRef]
- Pomplun, S.; Jbara, M.; Quartararo, A.J.; Zhang, G.; Brown, J.S.; Lee, Y.C.; Ye, X.; Hanna, S.; Pentelute, B.L. De novo discovery of high-affinity peptide binders for the SARS-CoV-2 spike protein. ACS Cent. Sci. 2021, 7, 156–163. [Google Scholar] [CrossRef]
- Pomplun, S. Targeting the SARS-CoV-2-spike protein: From antibodies to miniproteins and peptides. RSC Med. Chem. 2021, 12, 197–202. [Google Scholar] [CrossRef]
- Bowen, J.; Schneible, J.; Bacon, K.; Labar, C.; Menegatti, S.; Rao, B.M. Screening of yeast display libraries of enzymatically treated peptides to discover macrocyclic peptide ligands. Int. J. Mol. Sci. 2021, 22, 1634. [Google Scholar] [CrossRef] [PubMed]
- Turčić, P.; Štambuk, N.; Konjevoda, P.; Kelava, T.; Gabričević, M.; Stojković, R.; Aralica, G. Modulation of γ2-MSH hepatoprotection by antisense peptides and melanocortin subtype 3 and 4 receptor antagonists. Med. Chem. 2015, 11, 286–925. [Google Scholar] [CrossRef]
- Graham, P. Instant Notes in Medicinal Chemistry, 1st ed.; Taylor & Francis: London, UK, 2001; pp. 62–69. [Google Scholar]
- Woese, C.R.; Dugre, D.H.; Saxinger, W.C.; Dugre, S.A. The molecular basis for the genetic code. Proc. Natl. Acad. Sci. USA 1966, 55, 966–974. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Houra, K.; Turčić, P.; Gabričević, M.; Weitner, T.; Konjevoda, P.; Štambuk, N. Interaction of α-Melanocortin and Its Pentapeptide Antisense LVKAT: Effects on Hepatoprotection in Male CBA Mice. Molecules 2011, 16, 7331–7343. [Google Scholar] [CrossRef]
- Mohri, M.; Rezapoor, H. Effects of heparin, citrate, and EDTA on plasma biochemistry of sheep: Comparison with serum. Res. Vet. Sci. 2009, 86, 111–114. [Google Scholar] [CrossRef] [PubMed]
- Minarova, H.; Palikova, M.; Mares, J.; Syrova, E.; Blahova, J.; Faldyna, M.; Ondrackova, P. Optimisation of the lymphocyte proliferation assay in rainbow trout (Oncorhynchus mykiss). Vet. Med. 2019, 64, 547–557. [Google Scholar] [CrossRef] [Green Version]
- Root-Bernstein, R. Simultaneous origin of homochirality, the genetic code and its directionality. Bioessays 2007, 29, 689–698. [Google Scholar] [CrossRef]
- Root-Bernstein, R. Experimental test of L- and D-amino acid binding to L- and D-codons suggests that homochirality and codon directionality emerged with the genetic code. Symmetry 2010, 2, 1180–1200. [Google Scholar] [CrossRef]
- Turčić, P.; Bradamante, M.; Houra, K.; Štambuk, N.; Kelava, T.; Konjevoda, P.; Kazazić, S.; Vikić-Topić, D.; Pokrić, B. Effects of α-Melanocortin Enantiomers on Acetaminophen-Induced Hepatotoxicity in CBA Mice. Molecules 2009, 14, 5017–5026. [Google Scholar] [CrossRef]
- Arquès, D.G.; Michel, C.J. A complementary circular code in the protein coding genes. J. Theor. Biol. 1996, 182, 45–58. [Google Scholar] [CrossRef] [Green Version]
- Michel, C.J. The maximal C3 self-complementary trinucleotide circular code X in genes of bacteria, eukaryotes, plasmids and viruses. J. Theor. Biol. 2015, 380, 156–177. [Google Scholar] [CrossRef] [PubMed]
- Bartonek, L.; Braun, D.; Zagrovic, B. Frameshifting preserves key physicochemical properties of proteins. Proc. Natl. Acad. Sci. USA 2020, 117, 5907–5912. [Google Scholar] [CrossRef] [Green Version]
- Štambuk, N. On circular coding properties of gene and protein sequences. Croat. Chem. Acta 1999, 72, 999–1008. [Google Scholar]
- Štambuk, N. Universal metric properties of the genetic code. Croat. Chem. Acta 2000, 73, 1123–1139. [Google Scholar]
- Wichmann, S.; Ardern, Z. Optimality in the standard genetic code is robust with respect to comparison code sets. Biosystems 2019, 185, 104023. [Google Scholar] [CrossRef] [PubMed]
- Wichmann, S.; Scherer, S.; Ardern, Z. Computational design of genes encoding completely overlapping protein domains: Influence of genetic code and taxonomic rank. bioRxiv 2020. [Google Scholar] [CrossRef]
- Youvan, D.C. Mathematics of the Genetic Code. Available online: https://www.youvan.com/Mathematics of the Genetic Code-submit 2-redacted.pdf (accessed on 23 March 2021).
- Füllen, G.; Youvan, D.C. Genetic algorithms and recursive ensemble mutagenesis in protein engineering. Complex Int. 1994, 1. Available online: http://www.complexity.org.au/ci/vol01/fullen01/html/ (accessed on 23 March 2021).
- Arkin, A.P.; Youvan, D.C. An algorithm for protein engineering: Simulations of recursive ensemble mutagenesis. Proc. Natl. Acad. Sci. USA 1992, 89, 7811–7815. [Google Scholar] [CrossRef] [Green Version]
- Dila, G.; Michel, C.J.; Thompson, J.D. Optimality of circular codes versus the genetic code after frameshift errors. Bio. Syst. 2020, 195, 104134. [Google Scholar] [CrossRef]
- May, E.; Vouk, M.; Rosnick, D. An error-correcting code framework for genetic sequence analysis. J. Frankl. Inst. 2004, 341, 89–109. [Google Scholar] [CrossRef]
- Thompson, J.D.; Ripp, R.; Mayer, C.; Poch, O.; Michel, C.J. Potential role of the X circular code in the regulation of gene expression. Biosystems 2021, 203, 104368. [Google Scholar] [CrossRef]
- Seligmann, H.; Pollock, D.D. The ambush hypothesis: Hidden stop codons prevent off-frame gene reading. DNA Cell Biol. 2004, 10, 701–705. [Google Scholar] [CrossRef]
- Blanchet, S.; Cornu, D.; Hatin, I.; Grosjean, H.; Bertin, P.; Namy, O. Deciphering the reading of the genetic code by near-cognate tRNA. Proc. Natl. Acad. Sci. USA 2018, 115, 3018–3023. [Google Scholar] [CrossRef] [Green Version]
- Blanchet, S.; Cornu, D.; Argentini, M.; Namy, O. New insights into the incorporation of natural suppressor tRNAs at stop codons in Saccharomyces cerevisiae. Nucleic Acids Res. 2014, 15, 10061–10072. [Google Scholar] [CrossRef] [Green Version]
- Solis, A.D. Amino acid alphabet reduction preserves fold information contained in contact interactions in proteins. Proteins 2015, 83, 2198–2216. [Google Scholar] [CrossRef] [PubMed]
- Atchley, W.R.; Zhao, J.; Fernandes, A.D.; Drüke, T. Solving the protein sequence metric problem. Proc. Natl. Acad. Sci. USA 2005, 102, 6395–6400. [Google Scholar] [CrossRef] [Green Version]
- Polyansky, A.A.; Zagrovic, B. Evidence of direct complementary interactions between messenger RNAs and their cognate proteins. Nucleic Acids Res. 2013, 41, 8434–8443. [Google Scholar] [CrossRef] [PubMed]
- Koonin, E.V.; Novozhilov, A.S. Origin and evolution of the universal genetic code. Annu. Rev. Genet. 2017, 51, 45–62. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.; O’Loughlin, S.; Atkins, J.F.; Puglisi1, J.D. The energy landscape of −1 ribosomal frameshifting. Sci. Adv. 2020, 6, eaax6969. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rozov, A.; Westhof, E.; Yusupov, M.; Yusupova, G. The ribosome prohibits the G U wobble geometry at the first position of the codon–anticodon helix. Nucleic Acids Res. 2016, 44, 6434–6441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fang, Y.; Treffers, E.E.; Li, Y.; Tas, A.; Sun, Z.; van der Meer, Y.; de Ru, A.H.; van Veelen, P.A.; Atkins, J.F.; Snijder, E.J.; et al. Efficient −2 frameshifting by mammalian ribosomes to synthesize an additional arterivirus protein. Proc. Natl. Acad. Sci. USA 2012, 109, E2920–E2928. [Google Scholar] [CrossRef] [Green Version]
- Van Regenmortel, M.H.V. Structure-based reverse vaccinology failed in the case of HIV because it disregarded accepted immunological theory. Int. J. Mol. Sci. 2016, 17, 1591. [Google Scholar] [CrossRef] [Green Version]
- Moxon, R.; Reche, P.A.; Rappuoli, R. Editorial: Reverse Vaccinology. Front. Immunol. 2019, 10, 2776. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lan, J.; Ge, J.; Yu, J.; Shan, S.; Zhou, H.; Fan, S.; Zhang, Q.; Shi, X.; Wang, Q.; Zhang, L.; et al. Structure of the SARS-CoV-2 spike receptor-binding domain bound to the ACE2 receptor. Nature 2020, 581, 215–220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ni, W.; Yang, X.; Yang, D.; Bao, J.; Li, R.; Xiao, Y.; Hou, C.; Wang, H.; Liu, J.; Yang, D.; et al. Role of angiotensin-converting enzyme 2 (ACE2) in COVID-19. Crit. Care 2020, 24, 422. [Google Scholar] [CrossRef] [PubMed]
- Walls, A.C.; Park, Y.-J.; Tortorici, M.A.; Wall, A.; McGuire, A.T.; Veesler, D. Structure, function, and antigenicity of the SARS-CoV-2 spike glycoprotein. Cell 2020, 181, 281–292.e6. [Google Scholar] [CrossRef]
- Tai, W.; He, L.; Zhang, X.; Pu, J.; Voronin, D.; Jiang, S.; Zhou, Y.; Du, L. Characterization of the receptor-binding domain (RBD) of 2019 novel coronavirus: Implication for development of RBD protein as a viral attachment inhibitor and vaccine. Cell. Mol. Immunol. 2020, 6, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Whisenant, J.; Burgess, K. Blocking Coronavirus 19 Infection via the SARS-CoV-2 spike protein: Initial steps. ACS Med. Chem. Lett. 2020, 11, 1076–1078. [Google Scholar] [CrossRef]
- Zhang, G.; Pomplun, S.; Loftis, A.R.; Loas, A.; Pentelute, B.L. The first-in-class peptide binder to the SARS-CoV-2 spike protein. bioRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Pomplun, S.; Loftis, A.R.; Tan, X.; Loas, A.; Pentelute, B.L. Investigation of ACE2 N-terminal fragments binding to SARS-CoV-2 Spike RBD. bioRxiv 2020. [Google Scholar] [CrossRef] [Green Version]
- Glasgow, A.; Glasgow, J.; Limonta, D.; Solomon, P.; Lui, I.; Zhang, Y.; Nix, M.A.; Rettko, N.J.; Lim, S.A.; Zha, S.; et al. Engineered ACE2 receptor traps potently neutralize SARS-CoV-2. Proc. Natl. Acad. Sci. USA 2020, 117, 28046–28055. [Google Scholar] [CrossRef] [PubMed]
- Elton, T.S.; Dion, L.D.; Bost, K.L.; Oparil, S.; Blalock, J.E. Purification of an angiotensin II binding protein by using antibodies to a peptide encoded by angiotensin II complementary RNA. Proc. Natl. Acad. Sci. USA 1988, 85, 2518–2522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, Y.; Zhao, R.; Luo, J.; Xiong, S.; Shangguan, D.; Zhang, H.; Liu, G.; Chen, Y. Design, synthesis and screening of antisense peptide based combinatorial peptide libraries towards an aromatic region of SARS-CoV. J. Mol. Recognit. 2008, 21, 122–131. [Google Scholar] [CrossRef]
- Myers, D.G. Social Psychology, 10th ed.; McGraw-Hill: New York, NY, USA, 2010; p. 94. [Google Scholar]
- Michalewicz, Z.; David, B.; Fogel, D.B. How to Solve It: Modern Heuristics, 2nd ed.; Springer: Berlin, Germany, 2004; pp. 87–109. [Google Scholar]
- Heuristic Algorithms. Available online: https://optimization.mccormick.northwestern.edu/index.php/Heuristic_algorithms (accessed on 12 July 2021).
- Young, D.C. Computational Drug Design: A Guide for Computational and Medicinal Chemists; Wiley: Hoboken, NJ, USA, 2009; pp. 1–5. [Google Scholar]
- Yang, J.; Yan, R.; Roy, A.; Xu, D.; Poisson, J.; Zhang, Y. The I-TASSER Suite: Protein structure and function prediction. Nat. Methods 2015, 12, 7–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gasteiger, E.; Hoogland, C.; Gattiker, A.; Duvaud, S.; Wilkins, M.R.; Appel, R.D.; Bairoch, A. Protein Identification and Analysis Tools on the ExPASy Server. In The Proteomics Protocols Handbook; Walker, J.M., Ed.; Humana Press: Totowa, NJ, USA, 2005; pp. 571–607. [Google Scholar]
- Kyte, J.; Doolittle, R.F. A simple method for displaying the hydropathic character of a protein. J. Mol. Biol. 1982, 157, 105–132. [Google Scholar] [CrossRef] [Green Version]
- Veljkovic, V.; Veljkovic, N.; Esté, J.A.; Hüther, A.; Dietrich, U. Application of the EIIP/ISM bioinformatics concept in development of new drugs. Curr. Med. Chem. 2007, 14, 441–453. [Google Scholar] [CrossRef]
- Veljkovic, V.; Perovic, V.; Paessler, S. Prediction of the effectiveness of COVID-19 vaccine candidates. F1000Research 2020, 9, 1–9. [Google Scholar] [CrossRef]
- Larsen, J.E.; Lund, O.; Nielsen, M. Improved method for predicting linear B-cell epitopes. Immunome Res. 2006, 2, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kurcinski, M.; Badaczewska-Dawid, A.; Kolinski, M.; Kolinski, A.; Kmiecik, S. Flexible docking of peptides to proteins using CABS-dock. Protein Sci. 2020, 29, 211–222. [Google Scholar] [CrossRef] [Green Version]
- Kurcinski, M.; Ciemny, M.P.; Oleniecki, T.; Kuriata, A.; Badaczewska-Dawid, A.E.; Kolinski, A.; Kmiecik, S. CABS-dock standalone: A toolbox for flexible protein-peptide docking. Bioinformatics 2019, 35, 4170–4172. [Google Scholar] [CrossRef]
- Štambuk, N.; Konjevoda, P. The temperature dependence of amino acid hydrophobicity data is related to the genetic coding algorithm for complementary (sense and antisense) peptide interactions. Data Brief. 2020, 30, 105392. [Google Scholar] [CrossRef] [PubMed]
- Kelley, L.A.; Mezulis, S.; Yates, C.M.; Wass, M.N.; Sternberg, M.J. The Phyre2 web portal for protein modeling, prediction and analysis. Nat. Protoc. 2015, 10, 845–858. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Derreumaux, P.; Tufféry, P. PEP-FOLD: An updated de novo structure prediction server for both linear and disulfide bonded cyclic peptides. Nucleic Acids Res. 2012, 40, W288–W293. [Google Scholar] [CrossRef] [Green Version]
- Štambuk, N.; Konjevoda, P. Structural and functional modeling of artificial bioactive proteins. Information 2017, 8, 29. [Google Scholar] [CrossRef] [Green Version]
- Štambuk, N.; Konjevoda, P. The hydrophobic moment: An early bioinformatics method and de novo protein design. Science 2017. Available online: https://science.sciencemag.org/content/355/6321/201/tab-e-letters (accessed on 16 July 2021).
- Liu, R.; Liu, J.; Xie, L.; Wang, M.; Luo, J.; Cai, X. A fast and sensitive enzyme immunoassay for brain natriuretic peptide based on micro-magnetic probes strategy. Talanta 2010, 81, 1016–1021. [Google Scholar] [CrossRef] [PubMed]
- Pickering, J.W.; Hoopes, J.D.; Groll, M.C.; Romero, H.K.; Wall, D.; Sant, H.; Astill, M.E.; Hill, H.R. A 22-plex chemiluminescent microarray for pneumococcal antibodies. Am. J. Clin. Pathol. 2007, 128, 23–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]



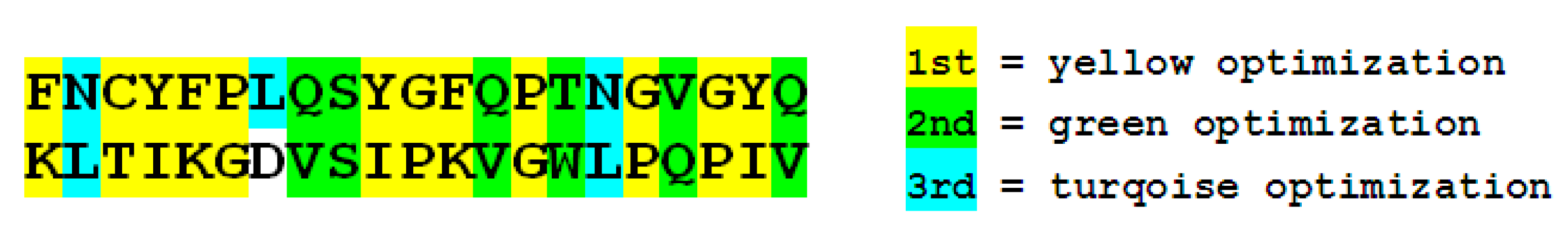
| First Letter (5′) | Second Letter | Third Letter (3′) | |||
|---|---|---|---|---|---|
| U | C | A | G | ||
| U | F | S | Y | C | U |
| F | S | Y | C | C | |
| L | S | stop | stop | A | |
| L | S | stop | W | G | |
| C | L | P | H | R | U |
| L | P | H | R | C | |
| L | P | Q | R | A | |
| L | P | Q | R | G | |
| A | I | T | N | S | U |
| I | T | N | S | C | |
| I | T | K | R | A | |
| M | T | K | R | G | |
| G | V | A | D | G | U |
| V | A | D | G | C | |
| V | A | E | G | A | |
| V | A | E | G | G | |
| Amino Acid | Antisense 3′ → 5′ | Antisense 5′ → 3′ | Consensus |
|---|---|---|---|
| F | K | K, E | K |
| L | D, E, N | E, Q, K | E |
| I | Y | N, D, Y | Y |
| M | Y | H | |
| V | H, Q | H, D, N, Y | H |
| S | S, R | G, R, T, A | R |
| P | G | G, W, R | G |
| T | W, C | G, S, C, R | C |
| A | R | R, G, S, C | R |
| Y | M, I | I, V | I |
| H | V | V, M | V |
| Q | V | L | |
| N | L | I, V | |
| K | F | F, L | F |
| D | L | I, V | L |
| E | L | L, F | L |
| C | T | T, A | T |
| W | T | P | |
| R | A, S | A, S, P, T | A, S |
| G | P | P, S, T, A | P |
| Parameter | Polarity (20 aa) | Polarity (X0, 12 aa) | Diversity (X1, 11 aa) |
|---|---|---|---|
| GUA—nucleobase preference | −0.54 * | −0.63 * | 0.71 * |
| PUR—nucleobase preference | −0.07 | −0.49 * | 0.82 * |
| PYR—nucleobase preference | 0.06 | 0.49 * | –0.85 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Štambuk, N.; Konjevoda, P.; Pavan, J. Antisense Peptide Technology for Diagnostic Tests and Bioengineering Research. Int. J. Mol. Sci. 2021, 22, 9106. https://doi.org/10.3390/ijms22179106
Štambuk N, Konjevoda P, Pavan J. Antisense Peptide Technology for Diagnostic Tests and Bioengineering Research. International Journal of Molecular Sciences. 2021; 22(17):9106. https://doi.org/10.3390/ijms22179106
Chicago/Turabian StyleŠtambuk, Nikola, Paško Konjevoda, and Josip Pavan. 2021. "Antisense Peptide Technology for Diagnostic Tests and Bioengineering Research" International Journal of Molecular Sciences 22, no. 17: 9106. https://doi.org/10.3390/ijms22179106
APA StyleŠtambuk, N., Konjevoda, P., & Pavan, J. (2021). Antisense Peptide Technology for Diagnostic Tests and Bioengineering Research. International Journal of Molecular Sciences, 22(17), 9106. https://doi.org/10.3390/ijms22179106