
Systematical Screening of Intracellular Protein Targets of Polyphemusin-I Using Escherichia coli Proteome Microarrays


Abstract
:
1. Introduction
2. Results
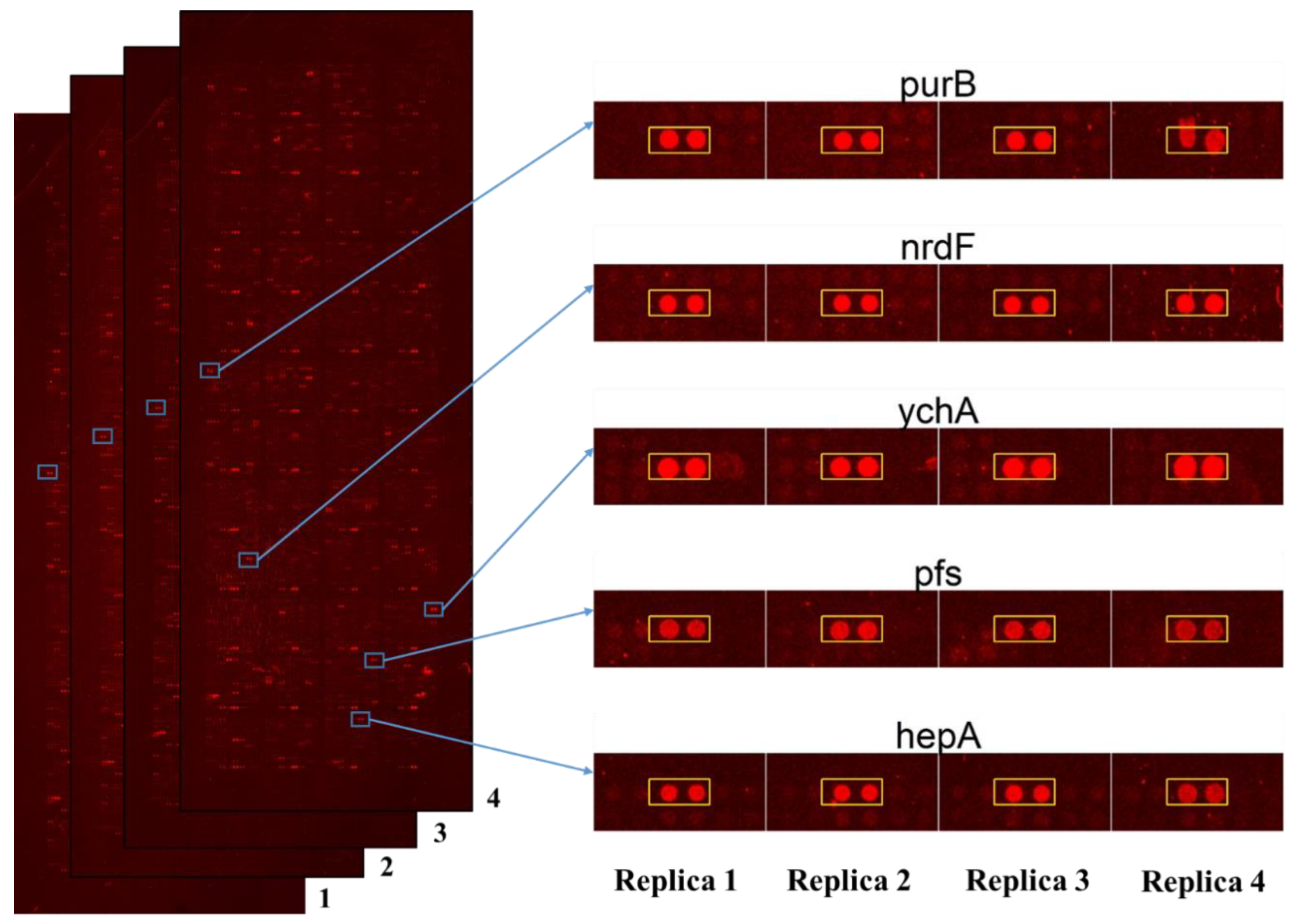
2.1. Escherichia coli Proteome Microarrays Assays of Polyphemusin-I
2.2. Statistical Analysis of Escherichia coli Proteome Microarrays Data for the Identification of Potential Protein Targets of Polyphemusin-I
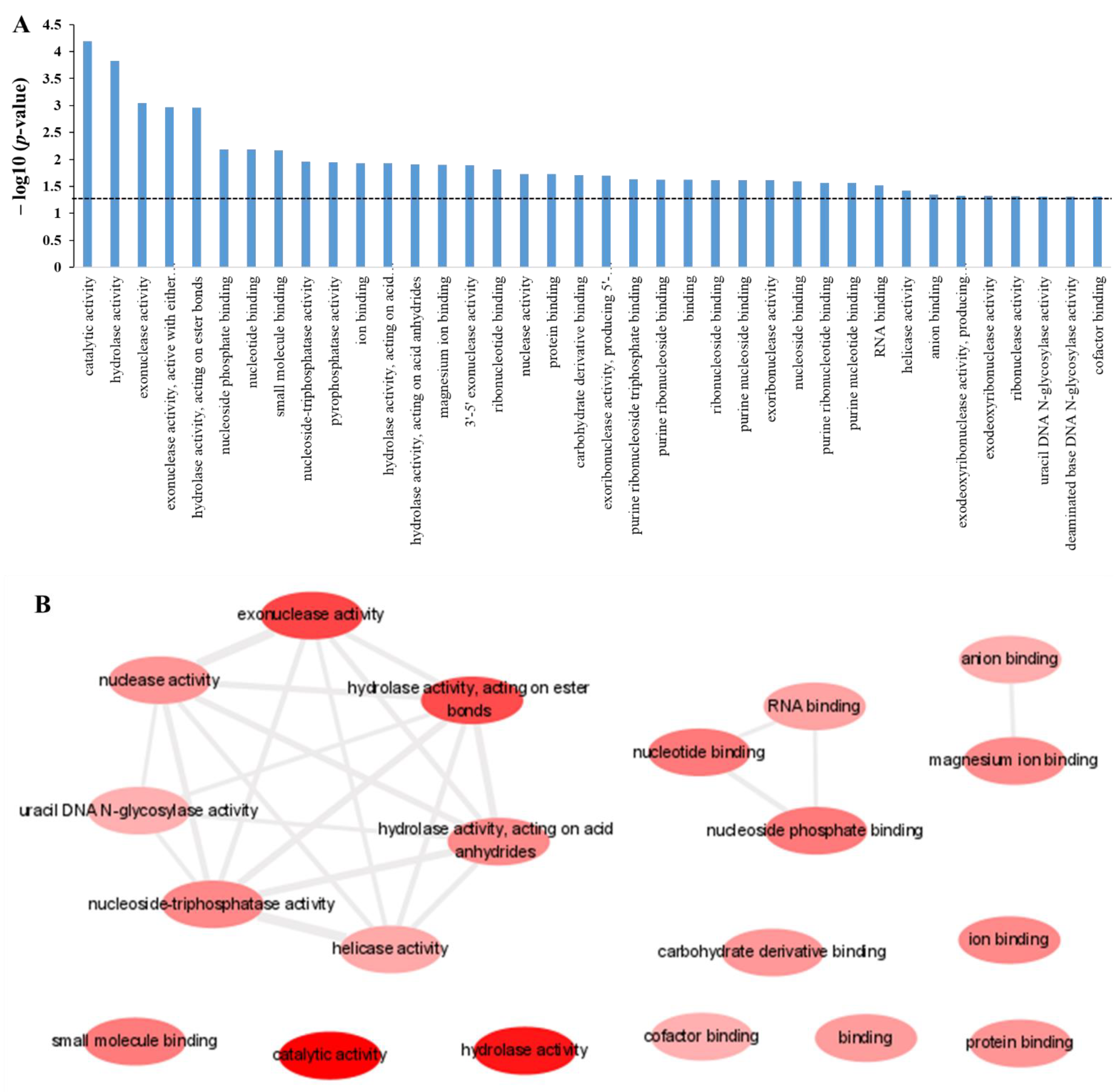
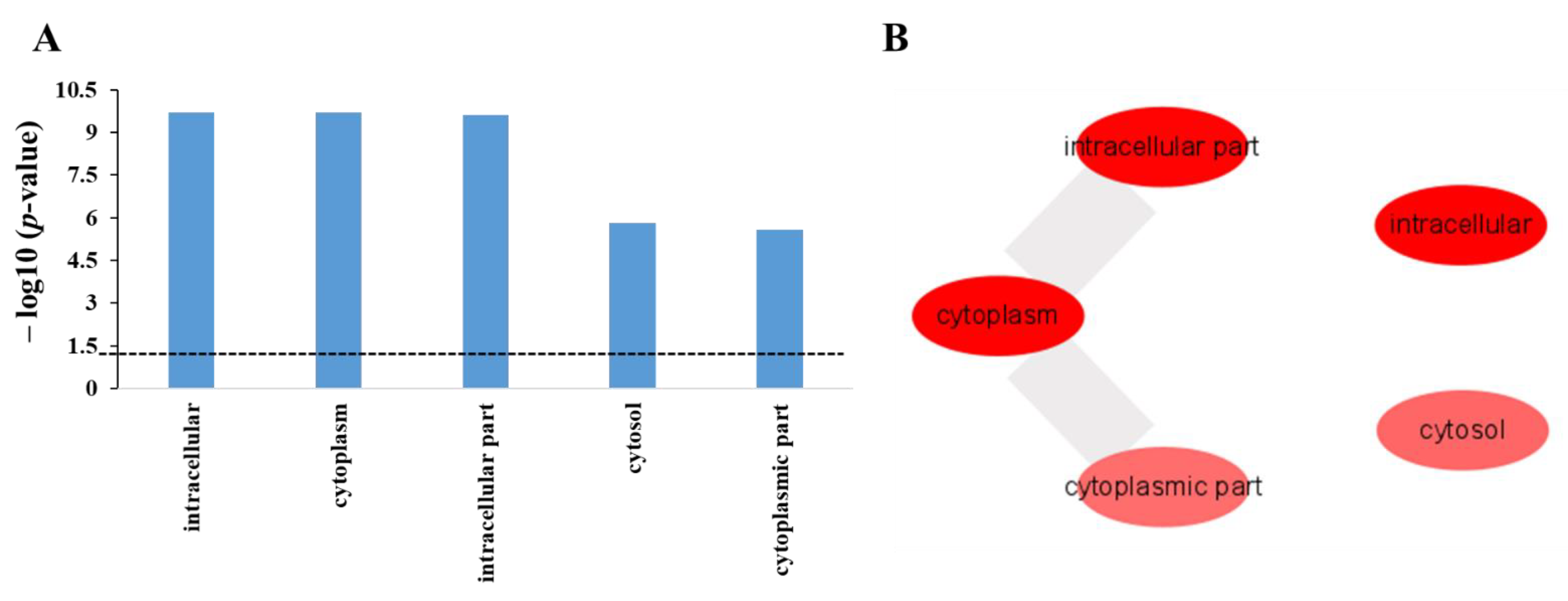
2.3. Enrichment Analysis in Gene Ontology of Protein Targets of Polyphemusin-I
2.4. Enrichment Analysis in Domain of the Protein Targets of Polyphemusin-I
2.5. Enrichment Analysis in Pathway of Protein Targets of Polyphemusin-I
3. Discussion
4. Materials and Methods
4.1. Expression and Purification of Entire Proteins of Escherichia coli K12 Strain
4.2. Fabrication of Escherichia coli Proteome Microarrays from the Individually Purified Entire Escherichia coli Proteome
4.3. Escherichia coli Proteome Microarrays Assay for Polyphemusin-I
4.4. Identification of Protein Targets of Polyphemusin-I from Escherichia coli Proteome Microarrays
4.5. Bioinformatics Analysis
4.5.1. Information on the Escherichia coli K12 Protein Targets of Polyphemusin-I
4.5.2. Enrichment Analysis of Protein Targets of Polyphemusin-I
4.5.3. Re-Enrichment Analysis for Non-Redundant GO Term from the GO Enrichment Analysis Results
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cudic, M.; Otvos, L., Jr. Intracellular targets of antibacterial peptides. Curr. Drug Targets 2002, 3, 101–106. [Google Scholar] [CrossRef]
- Bahar, A.A.; Ren, D. Antimicrobial peptides. Pharmaceuticals 2013, 6, 1543–1575. [Google Scholar] [CrossRef] [Green Version]
- Yeaman, M.R.; Yount, N.Y. Mechanisms of antimicrobial peptide action and resistance. Pharmacol. Rev. 2003, 55, 27–55. [Google Scholar] [CrossRef] [Green Version]
- Hancock, R.E.; Scott, M.G. The role of antimicrobial peptides in animal defenses. Proc. Natl. Acad. Sci. USA 2000, 97, 8856–8861. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, L.T.; Haney, E.F.; Vogel, H.J. The expanding scope of antimicrobial peptide structures and their modes of action. Trends Biotechnol. 2011, 29, 464–472. [Google Scholar] [CrossRef]
- Mahlapuu, M.; Hakansson, J.; Ringstad, L.; Bjorn, C. Antimicrobial Peptides: An Emerging Category of Therapeutic Agents. Front. Cell. Infect. Microbiol. 2016, 6, 194. [Google Scholar] [CrossRef] [Green Version]
- Galdiero, S.; Falanga, A.; Berisio, R.; Grieco, P.; Morelli, G.; Galdiero, M. Antimicrobial peptides as an opportunity against bacterial diseases. Curr. Med. Chem. 2015, 22, 1665–1677. [Google Scholar] [CrossRef] [PubMed]
- Nicolas, P. Multifunctional host defense peptides: Intracellular-targeting antimicrobial peptides. FEBS J. 2009, 276, 6483–6496. [Google Scholar] [CrossRef]
- Lei, J.; Sun, L.; Huang, S.; Zhu, C.; Li, P.; He, J.; Mackey, V.; Coy, D.H.; He, Q. The antimicrobial peptides and their potential clinical applications. Am. J. Transl. Res. 2019, 11, 3919–3931. [Google Scholar] [PubMed]
- Le, C.F.; Fang, C.M.; Sekaran, S.D. Intracellular Targeting Mechanisms by Antimicrobial Peptides. Antimicrob. Agents Chemother. 2017, 61, e02340-16. [Google Scholar] [CrossRef] [Green Version]
- Jenssen, H.; Hamill, P.; Hancock, R.E. Peptide antimicrobial agents. Clin. Microbiol. Rev. 2006, 19, 491–511. [Google Scholar] [CrossRef] [Green Version]
- Brogden, K.A. Antimicrobial peptides: Pore formers or metabolic inhibitors in bacteria? Nat. Rev. Microbiol. 2005, 3, 238–250. [Google Scholar] [CrossRef]
- Shah, P.; Hsiao, F.S.; Ho, Y.H.; Chen, C.S. The proteome targets of intracellular targeting antimicrobial peptides. Proteomics 2016, 16, 1225–1237. [Google Scholar] [CrossRef]
- Miyata, T.; Tokunaga, F.; Yoneya, T.; Yoshikawa, K.; Iwanaga, S.; Niwa, M.; Takao, T.; Shimonishi, Y. Antimicrobial peptides, isolated from horseshoe crab hemocytes, tachyplesin II, and polyphemusins I and II: Chemical structures and biological activity. J. Biochem. 1989, 106, 663–668. [Google Scholar] [CrossRef]
- Powers, J.P.; Rozek, A.; Hancock, R.E. Structure-activity relationships for the beta-hairpin cationic antimicrobial peptide polyphemusin I. Biochim. Biophys. Acta 2004, 1698, 239–250. [Google Scholar] [CrossRef]
- Edwards, I.A.; Elliott, A.G.; Kavanagh, A.M.; Zuegg, J.; Blaskovich, M.A.; Cooper, M.A. Contribution of Amphipathicity and Hydrophobicity to the Antimicrobial Activity and Cytotoxicity of beta-Hairpin Peptides. ACS Infect. Dis. 2016, 2, 442–450. [Google Scholar] [CrossRef]
- Powers, J.P.; Martin, M.M.; Goosney, D.L.; Hancock, R.E. The antimicrobial peptide polyphemusin localizes to the cytoplasm of Escherichia coli following treatment. Antimicrob. Agents Chemother. 2006, 50, 1522–1524. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.S.; Zhu, H. Protein microarrays. Biotechniques 2006, 40, 423–429. [Google Scholar] [CrossRef] [Green Version]
- Sutandy, F.X.; Qian, J.; Chen, C.S.; Zhu, H. Overview of protein microarrays. Curr. Protoc. Protein Sci. 2013, 27, 27.1.1–27.1.16. [Google Scholar] [CrossRef]
- Ho, Y.H.; Shah, P.; Chen, Y.W.; Chen, C.S. Systematic Analysis of Intracellular-targeting Antimicrobial Peptides, Bactenecin 7, Hybrid of Pleurocidin and Dermaseptin, Proline-Arginine-rich Peptide, and Lactoferricin B, by Using Escherichia coli Proteome Microarrays. Mol. Cell. Proteom. 2016, 15, 1837–1847. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tu, Y.H.; Ho, Y.H.; Chuang, Y.C.; Chen, P.C.; Chen, C.S. Identification of lactoferricin B intracellular targets using an Escherichia coli proteome chip. PLoS ONE 2011, 6, e28197. [Google Scholar] [CrossRef] [Green Version]
- Ho, Y.H.; Sung, T.C.; Chen, C.S. Lactoferricin B inhibits the phosphorylation of the two-component system response regulators BasR and CreB. Mol. Cell. Proteom. 2012, 11, M111.014720. [Google Scholar] [CrossRef] [Green Version]
- UniProt, C. UniProt: A worldwide hub of protein knowledge. Nucleic Acids Res. 2019, 47, D506–D515. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.W.; Sherman, B.T.; Lempicki, R.A. Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nat. Protoc. 2009, 4, 44–57. [Google Scholar] [CrossRef]
- Supek, F.; Bosnjak, M.; Skunca, N.; Smuc, T. REVIGO summarizes and visualizes long lists of gene ontology terms. PLoS ONE 2011, 6, e21800. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kitagawa, M.; Ara, T.; Arifuzzaman, M.; Ioka-Nakamichi, T.; Inamoto, E.; Toyonaga, H.; Mori, H. Complete set of ORF clones of Escherichia coli ASKA library (a complete set of E. coli K-12 ORF archive): Unique resources for biological research. DNA Res. 2005, 12, 291–299. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.S.; Korobkova, E.; Chen, H.; Zhu, J.; Jian, X.; Tao, S.C.; He, C.; Zhu, H. A proteome chip approach reveals new DNA damage recognition activities in Escherichia coli. Nat. Methods 2008, 5, 69–74. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term_ID | Enrichment in GO Molecular Function | p-Value | Hit in This Category | Total Gene in This Category | Redundancy |
|---|---|---|---|---|---|
| GO:0000287 | Magnesium ion binding | 0.012486 | 11 | 178 | Non-redundant |
| GO:0003824 | Catalytic activity | 0.0000646 | 68 | 2036 | Non-redundant |
| GO:0004527 | Exonuclease activity | 0.000896 | 6 | 31 | Non-redundant |
| GO:0016796 | Exonuclease activity, active with either ribo- or deoxyribonucleic acids and producing 5′-phosphomonoesters | 0.001072 | 5 | 19 | Redundant |
| GO:0004540 | Ribonuclease activity | 0.048466 | 4 | 33 | Redundant |
| GO:0004532 | Exoribonuclease activity | 0.024589 | 3 | 10 | Redundant |
| GO:0004529 | Exodeoxyribonuclease activity | 0.04661 | 3 | 14 | Redundant |
| GO:0016895 | Exodeoxyribonuclease activity, producing 5′-phosphomonoesters | 0.04661 | 3 | 14 | Redundant |
| GO:0016896 | Exoribonuclease activity, producing 5′-phosphomonoesters | 0.019993 | 3 | 9 | Redundant |
| GO:0008408 | 3′-5′ exonuclease activity | 0.012774 | 4 | 20 | Redundant |
| GO:0005488 | Binding | 0.023957 | 66 | 2262 | Non-redundant |
| GO:0000166 | Nucleotide binding | 0.006481 | 28 | 681 | Non-redundant |
| GO:0017076 | Purine nucleotide binding | 0.02744 | 20 | 484 | Redundant |
| GO:0035639 | Purine ribonucleoside triphosphate binding | 0.023405 | 20 | 476 | Redundant |
| GO:0001883 | Purine nucleoside binding | 0.024367 | 20 | 478 | Redundant |
| GO:0001882 | Nucleoside binding | 0.025361 | 20 | 480 | Redundant |
| GO:0032550 | Purine ribonucleoside binding | 0.023882 | 20 | 477 | Redundant |
| GO:0032549 | Ribonucleoside binding | 0.024367 | 20 | 478 | Redundant |
| GO:0032555 | Purine ribonucleotide binding | 0.026909 | 20 | 483 | Redundant |
| GO:0032553 | Ribonucleotide binding | 0.015182 | 22 | 521 | Redundant |
| GO:0048037 | Cofactor binding | 0.049752 | 13 | 285 | Non-redundant |
| GO:0016787 | Hydrolase activity | 0.000148 | 33 | 694 | Non-redundant |
| GO:0097367 | Carbohydrate derivative binding | 0.019759 | 22 | 534 | Non-redundant |
| GO:0036094 | Small molecule binding | 0.006868 | 29 | 718 | Non-redundant |
| GO:0043167 | Ion binding | 0.011802 | 32 | 852 | Non-redundant |
| GO:0005515 | Protein binding | 0.018817 | 33 | 916 | Non-redundant |
| GO:0004844 | Uracil DNA N-glycosylase activity | 0.049597 | 2 | 2 | Non-redundant |
| GO:0097506 | Deaminated base DNA N-glycosylase activity | 0.049597 | 2 | 2 | Redundant |
| GO:0003723 | RNA binding | 0.03047 | 10 | 176 | Non-redundant |
| GO:0043168 | Anion binding | 0.044748 | 7 | 104 | Non-redundant |
| GO:0004386 | Helicase activity | 0.038039 | 4 | 30 | Non-redundant |
| GO:1901265 | Nucleoside phosphate binding | 0.006481 | 28 | 681 | Non-redundant |
| GO:0016788 | Hydrolase activity, acting on ester bonds | 0.001108 | 15 | 224 | Non-redundant |
| GO:0016817 | Hydrolase activity, acting on acid anhydrides | 0.012267 | 14 | 262 | Non-redundant |
| GO:0004518 | Nuclease activity | 0.01875 | 7 | 85 | Non-redundant |
| GO:0017111 | Nucleoside-triphosphatase activity | 0.011068 | 13 | 230 | Non-redundant |
| GO:0016462 | Pyrophosphatase activity | 0.011191 | 14 | 259 | Redundant |
| GO:0016818 | Hydrolase activity, acting on acid anhydrides, in phosphorus-containing anhydrides | 0.0119 | 14 | 261 | Redundant |
| Term_ID | Enrichment in GO Biological Process | p-Value | Hit in This Category | Total Gene in This Category | Redundancy |
|---|---|---|---|---|---|
| GO:0008152 | metabolic process | 0.000502 | 65 | 2321 | Non-redundant |
| GO:0065009 | regulation of molecular function | 0.043287 | 5 | 60 | Non-redundant |
| GO:0090305 | nucleic acid phosphodiester bond hydrolysis | 0.00065 | 7 | 49 | Non-redundant |
| GO:0006974 | cellular response to DNA damage stimulus | 0.009881 | 13 | 256 | Non-redundant |
| GO:0033554 | cellular response to stress | 0.029973 | 14 | 333 | Redundant |
| GO:0006284 | base-excision repair | 0.03258 | 3 | 13 | Redundant |
| GO:0044237 | cellular metabolic process | 0.019431 | 57 | 2126 | Non-redundant |
| GO:0006807 | nitrogen compound metabolic process | 0.034615 | 43 | 1519 | Non-redundant |
| GO:1901605 | alpha-amino acid metabolic process | 0.035589 | 9 | 172 | Non-redundant |
| GO:0034655 | nucleobase-containing compound catabolic process | 0.030997 | 5 | 54 | Non-redundant |
| GO:0034641 | cellular nitrogen compound metabolic process | 0.020584 | 38 | 1258 | Non-redundant |
| GO:0090501 | RNA phosphodiester bond hydrolysis | 0.030508 | 4 | 31 | Non-redundant |
| GO:0009262 | deoxyribonucleotide metabolic process | 0.042623 | 3 | 15 | Non-redundant |
| GO:0006950 | response to stress | 0.025047 | 19 | 505 | Non-redundant |
| Term_ID | Enrichment in GO Cellular Component | p-Value | Hit in This Category | Total Gene in This Category | Redundancy |
|---|---|---|---|---|---|
| GO:0005622 | Intracellular | 1.94 × 10−10 | 54 | 1613 | Non-redundant |
| GO:0005737 | Cytoplasm | 2.04 × 10−10 | 52 | 1471 | Non-redundant |
| GO:0044424 | Intracellular part | 2.41 × 10−10 | 53 | 1546 | Non-redundant |
| GO:0005829 | Cytosol | 1.52 × 10−6 | 39 | 1049 | Non-redundant |
| GO:0044444 | Cytoplasmic part | 2.61 × 10−6 | 39 | 1069 | Non-redundant |
| ID | Enrichment in PFAM | p-Value | Hit in This Category | Total Gene in This Category | Protein Targets in This Category |
|---|---|---|---|---|---|
| PF00575 | S1 RNA binding domain | 0.00058 | 4 | 8 | NUSA, RNR, RPSA, RNG |
| PF00155 | Aminotransferase class I and II | 0.033687 | 3 | 13 | MALY, KBL, ALAA |
| PF00268 | Ribonucleotide reductase, small chain | 0.044827 | 2 | 2 | NRDF, NRDB |
| PF03695 | Uncharacterized protein family (UPF0149) | 0.044827 | 2 | 2 | YGFB, YECA |
| PF01612 | 3′-5′ exonuclease | 0.044827 | 2 | 2 | POLA, RND |
| PF03167 | Uracil DNA glycosylase superfamily | 0.044827 | 2 | 2 | MUG, UNG |
| ID | Enrichment in KEGG Pathway | p-Value | Hit in This Category | Total Gene in This Category | Protein Targets in This Category |
|---|---|---|---|---|---|
| eco03410 | Base excision repair | 0.037412 | 3 | 14 | POLA, MUG, UNG |
| eco00230 | Purine metabolism | 0.04109 | 6 | 87 | PURB, ADD, POLA, NRDF, MAZG, NRDB |
| eco00240 | Pyrimidine metabolism | 0.046694 | 5 | 62 | POLA, NRDF, MAZG, NRDB, PSUK |
| Term_ID | Enrichment in Biological Process | p-Value | Hit in This Category | Total Gene in This Category |
|---|---|---|---|---|
| GO:0009262 | Deoxyribonucleotide metabolic process | 0.0064 | 3 | 15 |
| GO:0006595 | Polyamine metabolic process | 0.0092 | 3 | 18 |
| GO:0009186 | Deoxyribonucleoside diphosphate metabolic process | 0.0245 | 2 | 3 |
| GO:0044711 | Single-organism biosynthetic process | 0.0384 | 10 | 584 |
| GO:0043433 | Negative regulation of sequence-specific DNA binding transcription factor activity | 0.0485 | 2 | 6 |
| GO:0008295 | Spermidine biosynthetic process | 0.0485 | 2 | 6 |
| GO:0006596 | Polyamine biosynthetic process | 0.0485 | 2 | 6 |
| Enrichment in biological process | ||||
| GO:0016788 | Hydrolase activity, acting on ester bonds | 0.0032 | 8 | 224 |
| GO:0003824 | Catalytic activity | 0.0226 | 25 | 2036 |
| GO:0016787 | Hydrolase activity | 0.0349 | 12 | 694 |
| Enrichment in pathway | ||||
| eco01100 | Metabolic pathways | 0.0160 | 11 | 685 |
| eco00330 | Arginine and proline metabolism | 0.0172 | 3 | 25 |
| eco00270 | Cysteine and methionine metabolism | 0.0228 | 3 | 29 |
| Enrichment in PFAM | ||||
| PF00268 | Ribonucleotide reductase, small chain | 0.0168 | 2 | 2 |
| PF02613 | Nitrate reductase delta subunit | 0.0415 | 2 | 5 |
| PF00258 | Flavodoxin | 0.0496 | 2 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah, P.; Chen, C.-S. Systematical Screening of Intracellular Protein Targets of Polyphemusin-I Using Escherichia coli Proteome Microarrays. Int. J. Mol. Sci. 2021, 22, 9158. https://doi.org/10.3390/ijms22179158
Shah P, Chen C-S. Systematical Screening of Intracellular Protein Targets of Polyphemusin-I Using Escherichia coli Proteome Microarrays. International Journal of Molecular Sciences. 2021; 22(17):9158. https://doi.org/10.3390/ijms22179158
Chicago/Turabian StyleShah, Pramod, and Chien-Sheng Chen. 2021. "Systematical Screening of Intracellular Protein Targets of Polyphemusin-I Using Escherichia coli Proteome Microarrays" International Journal of Molecular Sciences 22, no. 17: 9158. https://doi.org/10.3390/ijms22179158
APA StyleShah, P., & Chen, C.-S. (2021). Systematical Screening of Intracellular Protein Targets of Polyphemusin-I Using Escherichia coli Proteome Microarrays. International Journal of Molecular Sciences, 22(17), 9158. https://doi.org/10.3390/ijms22179158