1. Introduction
Quantitative structure–activity relationship (QSAR) modelling is based on the similarity principle that structurally similar compounds have similar physicochemical properties. Therefore, compounds with similar structures can be expected to have similar effects in biological systems. QSAR methods are important complements to in vitro and animal testing methods. In the drug development process, they may provide a quick and cost-effective assessment of the compound properties. Although the QSAR methods cannot completely replace all in vitro and animal testing methods, they present an important contribution to the reduction in animal tests. Therefore, QSAR methods have also been recognized as important for the risk assessment of chemicals. In addition to directly predicting the property of compounds using a QSAR model, the read-across method can be used to predict the same endpoint based on the known endpoint value of a structurally similar compound or group of similar compounds. Self-organizing maps (SOMs), also known as Kohonen neural networks, are known for their ability to group objects according to their similarity and can be used to project objects from multidimensional to two-dimensional space [
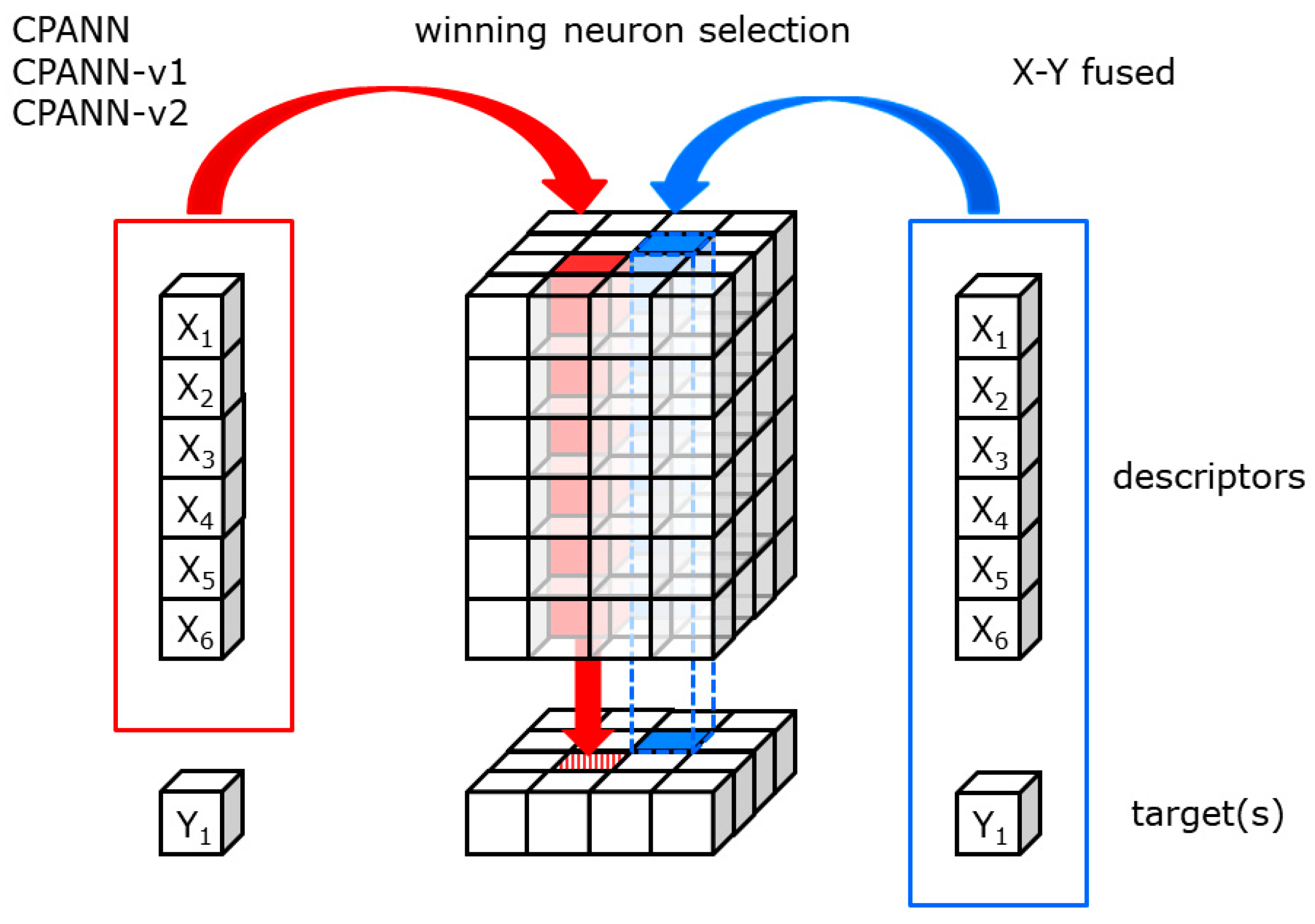
1]. Supervised Kohonen neural networks are an extension of SOMs that have an additional (output) layer of neurons that is trained to predict an endpoint. Probably the simplest extension of SOMs are counter-propagation neural networks (CPANNs), where the Kohonen layer of neurons is used to determine the position of the winning neuron, and the output layer is used to predict the endpoint. In CPANN, the endpoint is not used to determine the winning neuron or to correct the neuron weights in Kohonen layer, but only to correct the weights in the output layer. One can occasionally obtain models that are difficult to interpret because no relationship between the independent variables and the endpoint is apparent when comparing the model weights in the Kohonen and output layers, which is especially difficult when endpoint clusters in the output layer are not well formed. During the training process, SOMs can form clusters of objects that preserve topological relationships when projections of objects are made from multidimensional to lower dimensional space. The data can be grouped into the correct cluster, but clusters are often scattered on the map leading to overlapping clusters [
2]. Therefore, new learning algorithms have been developed to improve the predictive ability and interpretation of supervised SOM models.
The behavior of supervised Kohonen networks in overdetermined datasets was studied by Xiao et al. [
3]. Their observation confirmed the superior behavior of supervised SOM over supervised
k-means clustering, which are closely related. SOM is practically a
k-means clustering algorithm when the neighborhood function (kernel) of SOM becomes zero [
3,
4]. The better performance of SOM models over
k-means clustering apparently arises from the neighborhood information that is lost when the neighborhood becomes zero.
In the work of Melssen et al. [
5], examples of clustering results using different learning algorithms for SOM models are given. To obtain a desirable response surface of the model, they proposed an X-Y fused network and a bi-directional Kohonen neural network. Compared to the checkerboard response obtained for some of the examples shown in their paper with the counter-propagation and supervised Kohonen neural network, the proposed algorithms produced a response surface with well-formed class clusters. In the X-Y fused network, the endpoint property was used to determine the winning neuron and weight the learning rate based on the similarity of the object to the neuron in the Kohonen and output layers. In the bi-directional Kohonen neural network, the corrections of weights in both layers are not made all at once, as in X-Y fused networks, but sequentially, with two passes of objects through the network. In the first pass, the winning neuron is determined based on the similarity in the output layer and the weights in the Kohonen layer are updated using all the objects. This is followed by the second pass, where the winning neuron is determined based on the similarity in the Kohonen layer and then the weights in the output layer are corrected for all objects.
Recently, Torres-Alegre et al. [
6] proposed a concept of metaplasticity in SOMs (AMSOMs) for modification of the learning process using Gaussian function implementing the metaplasticity concept. Previously, they introduced the concept to improve the backpropagation algorithm [
7] in the training of multilayer perceptron artificial neural networks. The idea was to give higher relevance to infrequent patterns and reduce in cases of the frequent ones. Performance evaluation showed that the standard SOM method performed slightly better than AMSOM when using smaller networks, while AMSOM performance showed better results when using larger networks. The observed learning progress was slower in AMSOM, with larger variabilities observed during training, however better performances were obtained at larger network sizes.
The above-mentioned authors tried to improve learning strategies of SOM with different approaches. One of the important tasks in QSAR is finding appropriate chemical space representation. Approaches for utilizing information on infrequent patterns, for example, can boost the model, but without adequate chemical representation one may have difficulties building a good model due to so-called activity cliffs. The activity cliffs were generally defined as pairs of structurally similar active compounds with a large difference in potency [
8]. They represent steep changes in the structure−activity relationship (SAR), so they hinder QSAR modeling [
9], although on the other hand they can identify small chemical modifications that determine activity of compounds [
10] and are thus very important.
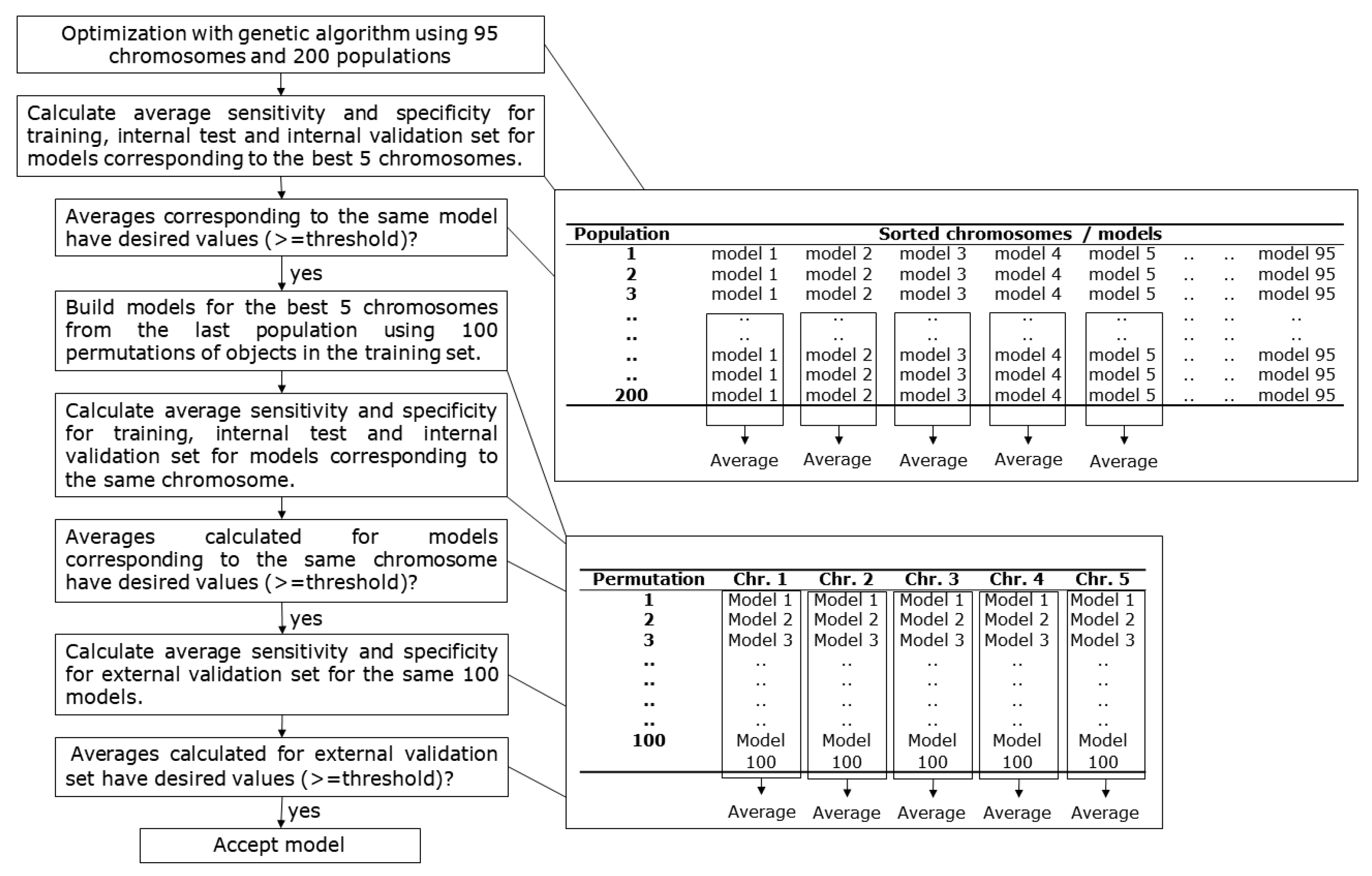
The aim of this work was to develop a learning strategy for counter-propagation artificial neural networks that improves the training capabilities of the network and leads to the good formation of clusters on the SOM top-map. In the training and testing phase, the determination of the winning neuron is performed in the same way as in the standard CPANN model, independently of the endpoint. Different learning strategies were used and genetic algorithm optimization of CPANNs was performed to evaluate the relative learning strengths of the algorithms. Weight correction algorithms of the standard CPANN are proposed, where the difference between scaled object variable and the corresponding scaled model weight is used to adjust the amount of weight correction. Initially, the weight corrections resemble classical CPANN algorithm, and the scaling gradually gains importance in weight correction during the training process. The proposed algorithms may reduce the effect of structural outliers on the training. They were used for the classification of drugs from LiverTox database and showed improved clustering abilities compared to standard CPANN.
2. Results and Discussion
Genetic optimizations of neural network models were performed using hepatotoxicity datasets with 268 and 49 initial descriptors in the training set and four neural network training algorithms described in
Section 3.2.
Theoretical Background. The neural networks used were the standard counter-propagation neural network (CPANN), the X-Y fused neural network, and two proposed learning algorithms called CPANN-v1 and CPANN-v2. The same initial conditions and the same model selection criteria were used for all optimizations with the same initial number of descriptors. The same number of optimizations were performed using all four learning algorithms. Results obtained for individual optimizations are available in the file the “
optimization_results.zip”. Sensitivity, specificity, and clustering formation score (CFS) values are given in
supplementary file separately for each of the training algorithms used. The following tables,
Table 1 and
Table 2, show the number of selected models that were obtained when different training algorithms and optimization criteria were used in the optimization process.
From
Table 1, it can be seen that with the proposed CPANN-v2 algorithm, the largest number of selected models was found overall. The number is slightly larger than the number of selected models found with the X-Y fused neural network. With the standard CPANN model, the smallest number of the model was found, and the CPANN-v1 algorithm resulted somewhere in the middle between the largest and lowest numbers of the selected models found. Significantly lower numbers are observed in
Table 2 than in
Table 1, which was to be expected because the large reduction in the number of initial descriptors in the training set reduced the amount of valuable information available to build a model. In this case, using the CPANN-v1 algorithm resulted in the largest number of selected models found. Again, the use of the standard CPANN algorithm resulted in the smallest number of models found, while the use of the X-Y fused network and CPANN-v2 algorithm resulted in approximately the same number of models found. The only difference between the CPANN-v1 and CPANN-v2 algorithm is larger emphasis of the endpoint on the weight correction in the CPANN-v2 algorithm given by a factor and considering differences between the scaled object endpoint variable and corresponding scaled response weight in the weight correction equation.
The comparison of the number of selected models in
Table 1 and
Table 2 shows that the largest number of selected models was found using the optimization criterion OC2. The same number of selected models was found using optimization criteria OC1 and OC2 when using 49 descriptors, as shown in
Table 2. The optimization criterion OC2 was also the most complex optimization criterion used. Nevertheless, optimization criterion OC4 resulted in the lowest number of selected models, indicating that trying to minimize the differences between minimal and maximal sensitivity and/or specificity may not result in better models. The optimization criterion OC4 was derived from a simpler optimization criterion OC3, but fewer models were found by OC4 than by OC3.
The modifications to the standard weight correction equations were made in the CPANN-v1 and CPANN-v2 training algorithms to develop models with better cluster formations than when the standard CPANN algorithm was used. With the better formation of clusters, the interpretation of the models may be simpler. X-Y fused neural networks are known to generate such models. However, during training, the endpoint variables (targets) are used along with independent variables (descriptors) to select the winning neuron. The activation of a neuron during training depends significantly on the endpoint variable, which is removed when predictions are made with an existing model. In the proposed CPANN-v1 and CPANN-v2 algorithms, the winning neurons are selected independently of the endpoint variables during training and when making predictions, in the same way as when using standard CPANNs. The models developed using standard CPANN, X-Y fused neural network, CPANN-v1 and CPANN-v2 were evaluated using the clustering formation score (CFS) described in
Section 3.4.
Evaluation of Cluster Formation of Models to compare their relative ability to form clusters. The results of the evaluation are shown in
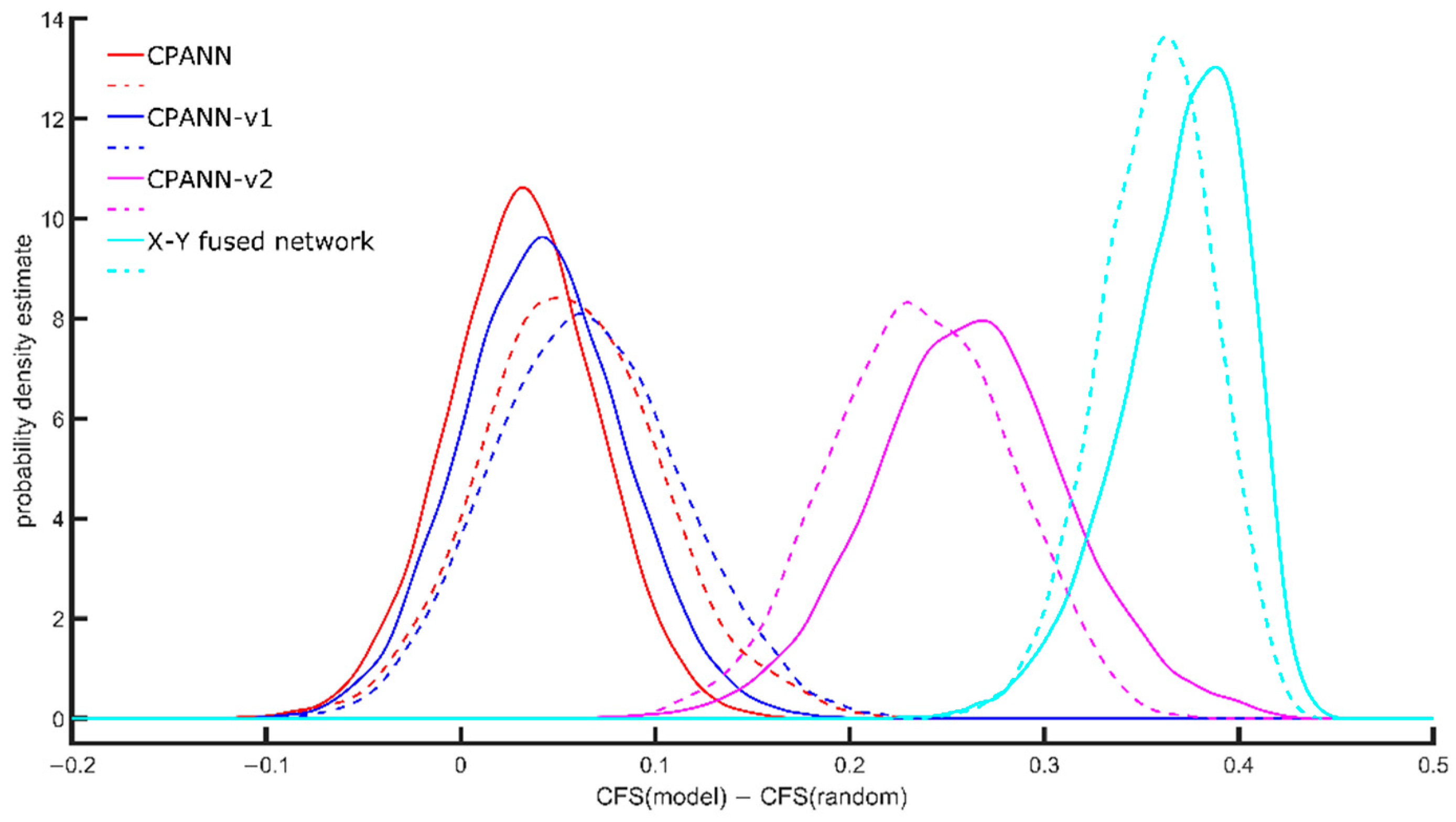
Figure 1. The CFS depends on the size of the network and the number of neurons giving response to a specific class; therefore, the CFS of a model (CFS(model)) was compared with the average CFS(random) that was calculated for random distribution of the same responses on the network with the same size. The calculation of the average CFS(random) was performed using 100 random distributions of the response values.
Figure 1 shows the probability density estimate obtained for the differences between CFS(model) and CFS(random). The solid lines indicate the distributions obtained using selected models developed during the optimizations with a set of 268 descriptors, and the dashed lines indicate the distributions obtained using the selected models developed during the optimizations with a set of 49 descriptors.
The X-Y fused network shows the best ability to form clusters. The proposed CPANN-v2 algorithm is the next one with good ability for the formation of clusters. CPANN-v1 algorithm shows slightly better ability than the standard CPANN algorithm. When using 49 descriptors during the optimizations, the formation of clusters improved with standard CPANN and CPANN-v1 algorithm compared to results obtained when 268 descriptors were used during optimizations. A small decrease in the formation of clusters was observed for the CPANN-v2 algorithm and X-Y fused network models.
The selected models differed in the size of the network and in the descriptors that were present in each of the models. Among these models, the most frequently selected descriptors in optimizations were identified. For optimizations performed with different training algorithms, the 10 most frequently selected descriptors were identified separately. Then, four lists of the most frequent descriptors were compared, and some common descriptors were identified. This was conducted separately for optimizations performed with 268 and 49 descriptors. The common descriptors that were found are listed in
Table 3. These descriptors can be considered as the most important descriptors for predicting hepatotoxic potential of drugs.
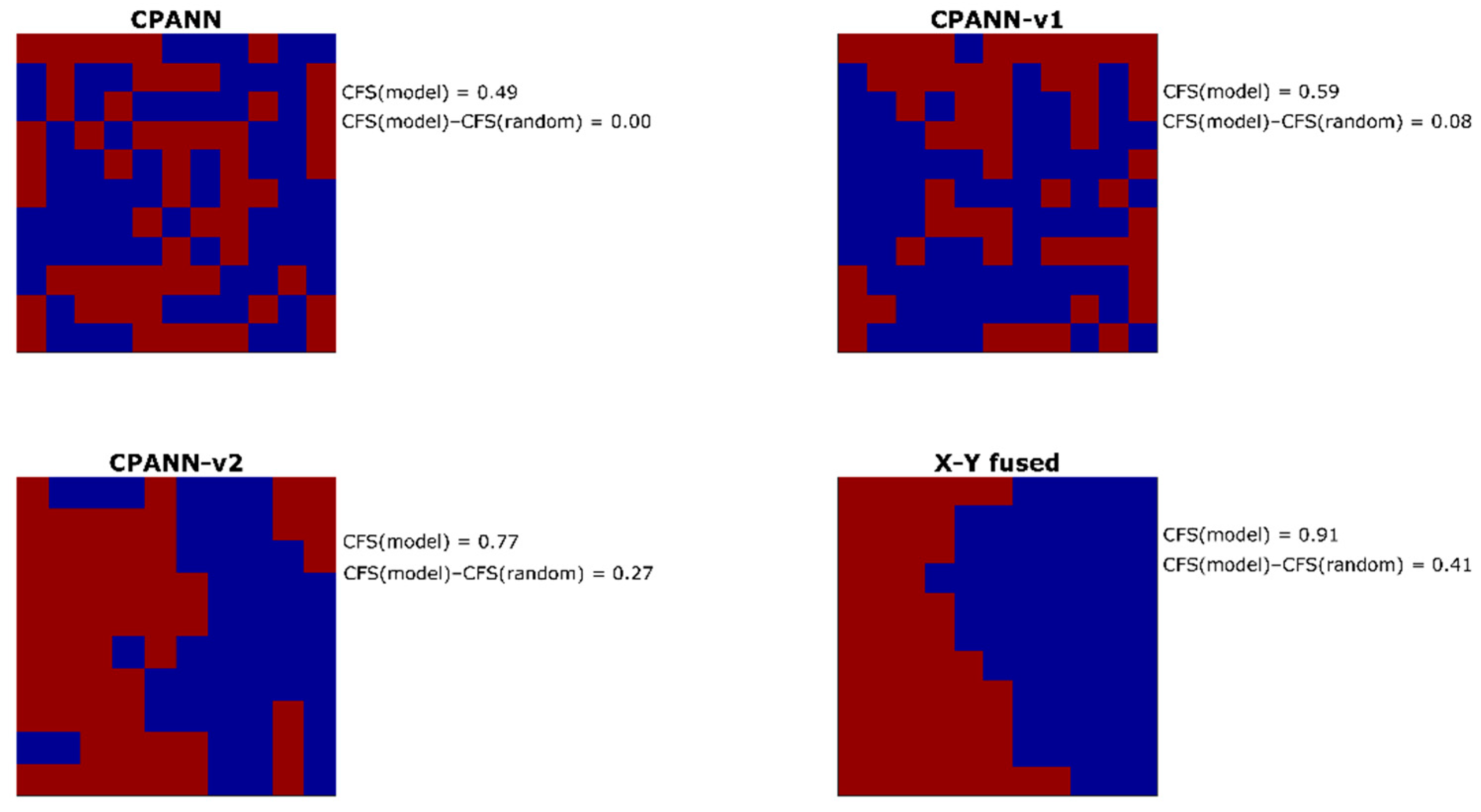
From the entire pool of the selected models, one model was selected for each of the algorithms. The models with high and comparable prediction performances were selected among the models obtained from optimizations with 268 initial descriptors in the sets. For the selection, average sensitivity and specificity values were considered that were calculated from 100 models built neural network training parameters and different permutations of objects in the training set. The average sensitivity values for the external validation set were 0.80 for CPANN model, 0.89 for CPANN-v1 model, 0.89 for CPANN-v2 model, and 0.81 for the X-Y fused model. Average specificity values for the external validation set were 0.82 for CPANN model, 0.84 for CPANN-v1 model, 0.85 for CPANN-v2 model, and 0.87 for the X-Y fused model. The response surfaces (predicted classes for each neuron) of these models are shown in
Figure 2. Level plots for the models are available in the
supplementary file “level_plots.zip” and the top-mapsthe in the
supplementary file “top-maps.zip”. Model weights and predictions of the models are available in the
supplementary file “model_weights_and_predictions.xlsx”. Each square on the response surface corresponds to response of one neuron. Red color indicates the neurons where the model predicts hepatotoxic class, and the blue color indicates non-hepatotoxic prediction. On the right side of each response surface, calculated clustering formation score values of the models (CFS(model)) and the differences CFS(model)–CFS(random) are given. Higher values of the differences CFS(model)–CFS(random) are expected for the models, resulting in better separation of classes. According to the values of the differences CFS(model)–CFS(random), the selected models can be sorted in the following order (from the highest to the lowest value): X-Y fused, CPANN-v2, CPANN-v1 and CPANN. It is visible from
Figure 2 that a better separation of hepatotoxic and non-hepatotoxic classes is obtained with the X-Y fused and CPANN-v2 networks than with CPANN or CPANN-v1 networks.
Misclassified external set compounds from each of the four models were inspected. The results are shown in
Table 4. Half of the misclassified cases were misclassified once. In
Table 4, the second column shows identification numbers of compounds from the training that excited the same neuron as the misclassified external set compound. There are nine cases where at least two compounds from the training set excited the same neuron as the external set compounds and have different hepatotoxic activity. Two such cases are found in predictions for the model built using the CPANN-v2 algorithm, one case in the model built with the X-Y fused network algorithm, and the remaining six cases are attributed to the other two algorithms.
Additional sets were used to further evaluate the results obtained by different training algorithms. A number of models were built using different sets for classification of compounds into a class with high or low affinity to the target proteins. The models were built for angiotensin-converting enzyme (ACE), acetylcholinesterase (ACHE), benzodiazepine receptor (BZR), cyclooxygenase-2 (COX2), dihydrofolate reductase (DHFR), glycogen phosphorylase b (GPB), thermolysin (THER), and thrombin (THR).
Table 5 shows the number of selected models obtained for the additional sets that were selected when using three different performance thresholds (0.70, 0.75 and 0.80). In
Table 5, the numbers in bold indicate the largest number of selected models for a protein target at a selected threshold value. From
Table 5, it can be seen that X-Y fused and CPANN-v2 network models most frequently achieved the largest number of selected models.
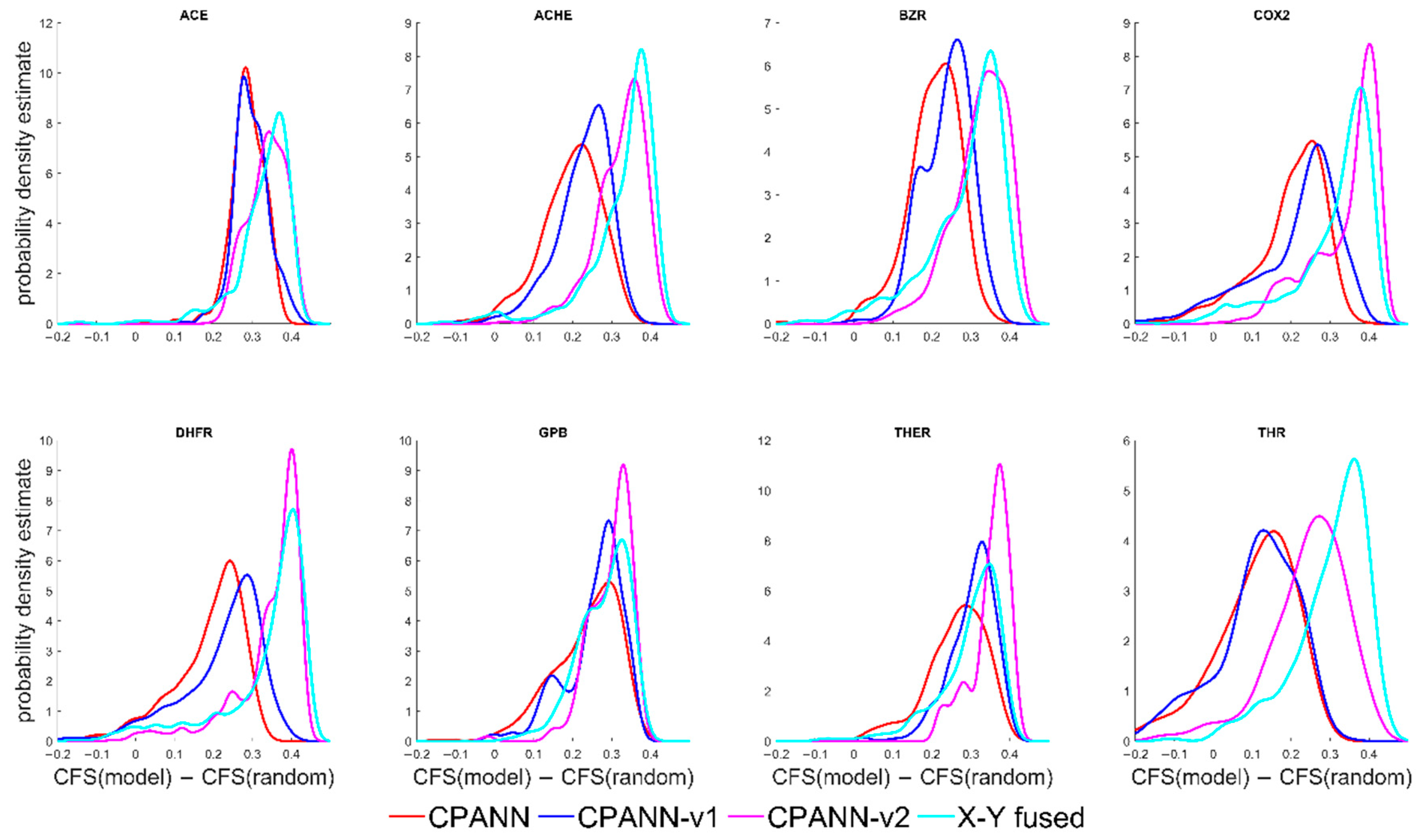
Clustering formation scores and the differences CFS(model)−CFS(random) were calculated for the models. The probability density estimates of the differences CFS(model)−CFS(random) are shown in
Figure 3. In the
Supplementary Material, supplementary file “results_for_additional_sets.zip” contains files with information about the performances and CFS values for the models that were built for the additional sets. In
Figure 3, the position of peaks in the distributions of CFS(model)−CFS(random) for the CPANN-v2 and X-Y fused networks are shifted to higher values than for CPANN and CPANN-v1, which is similar to the results shown in
Figure 1. However, there are smaller differences in the distributions and larger overlaps of the peaks are obtained for these models.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}