
A Deep Learning-Based Quantitative Structure–Activity Relationship System Construct Prediction Model of Agonist and Antagonist with High Performance



Abstract
:1. Introduction
2. Results and Discussion
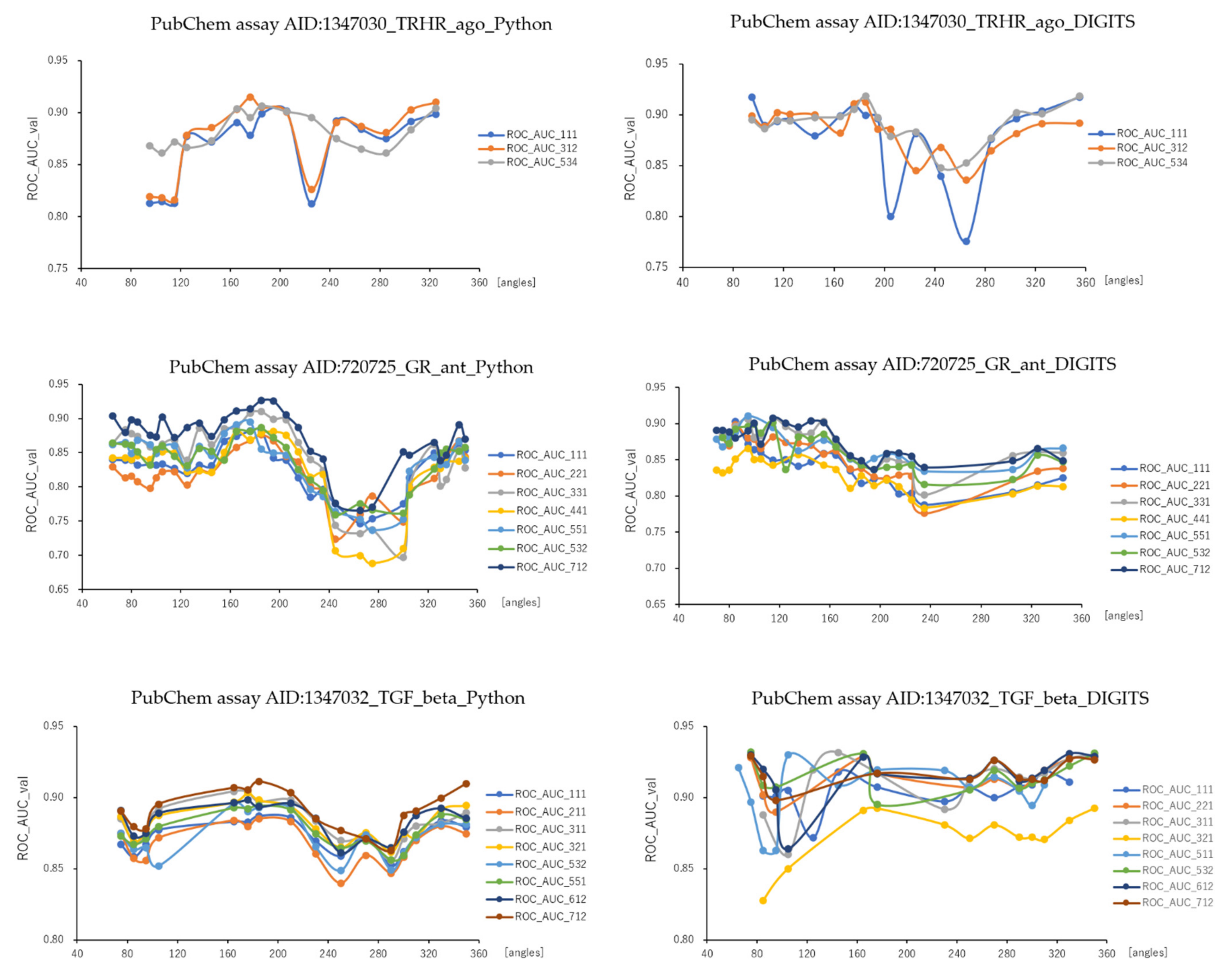
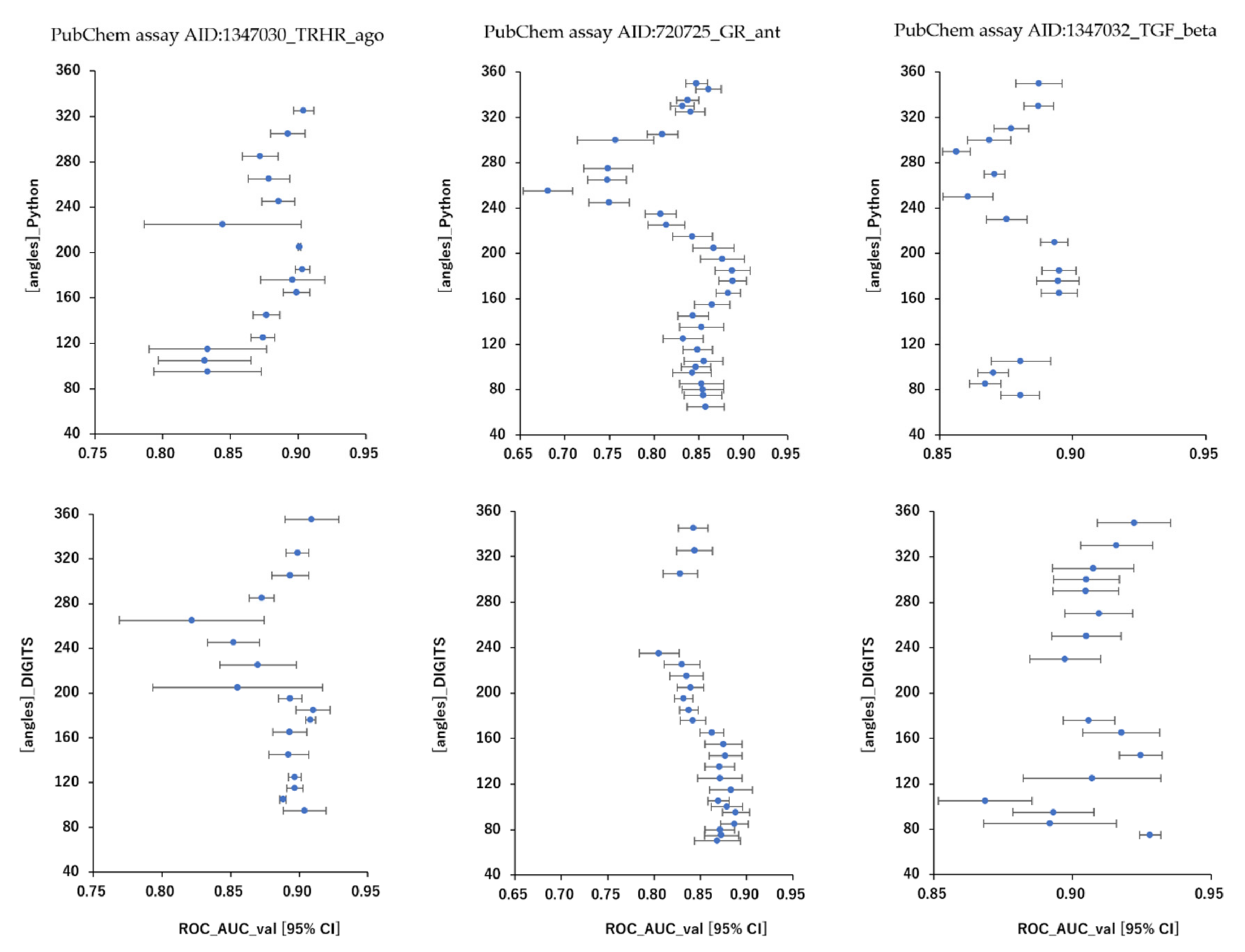
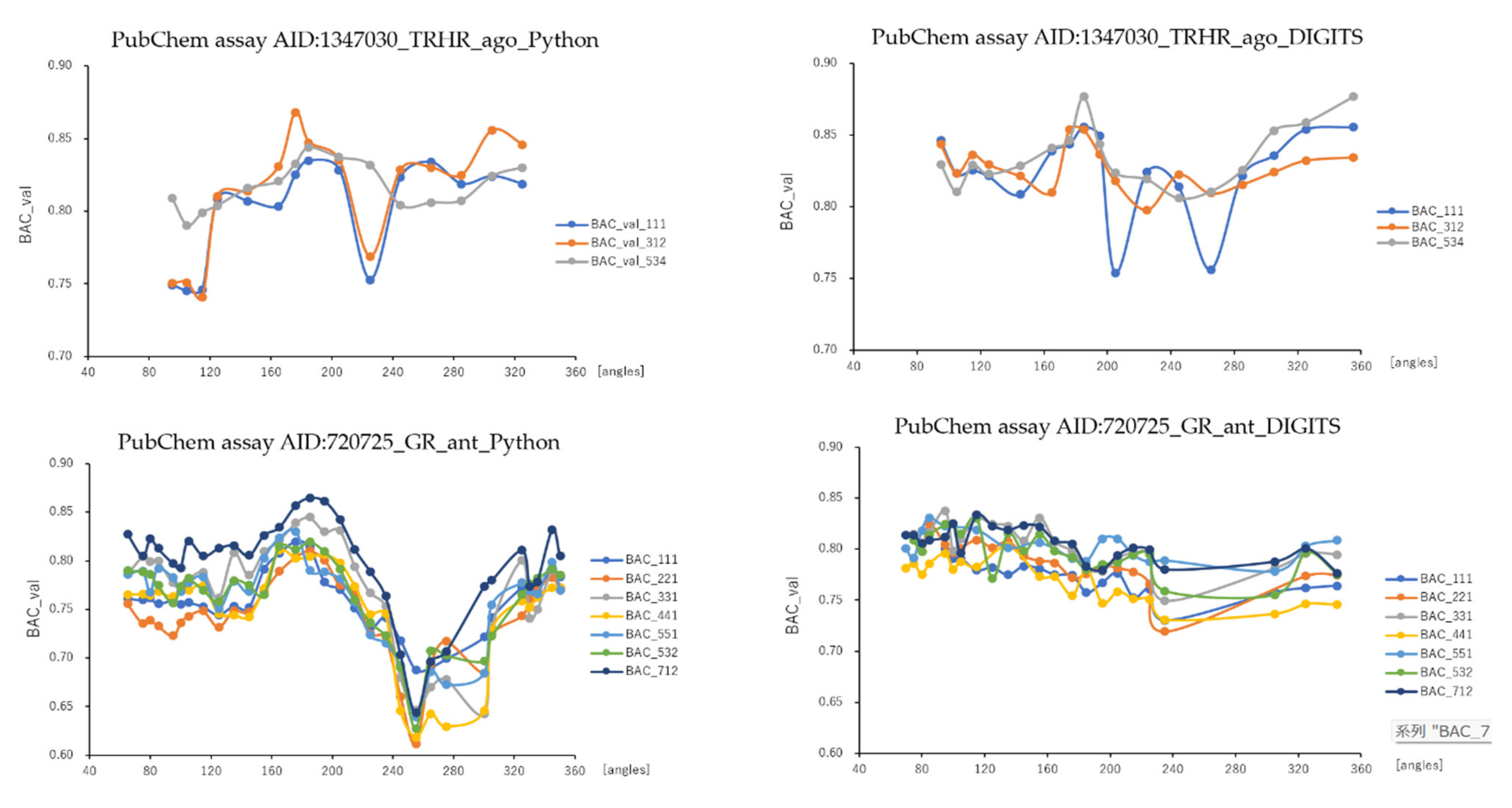
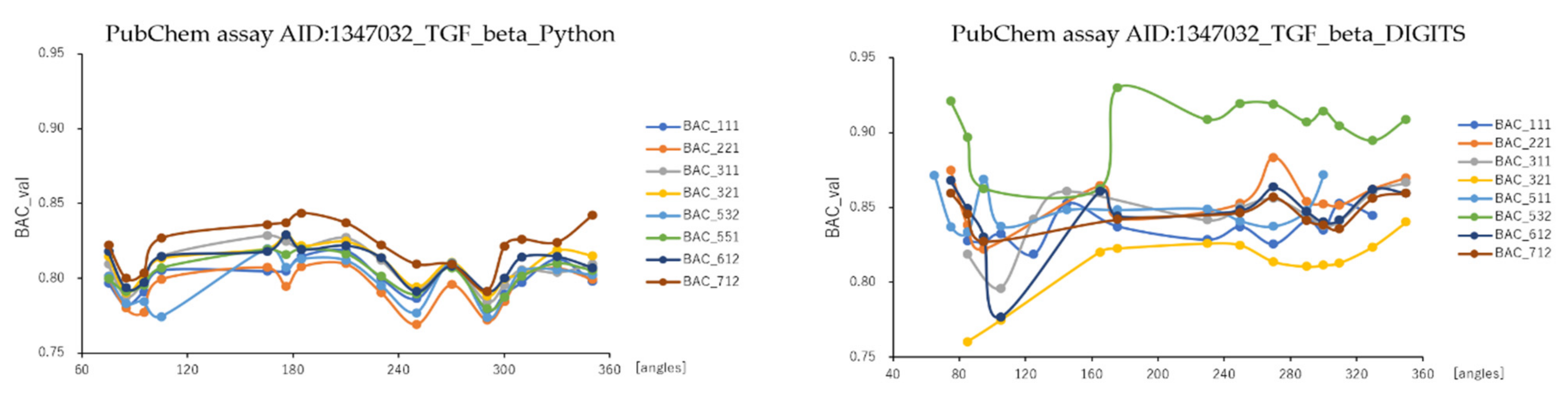
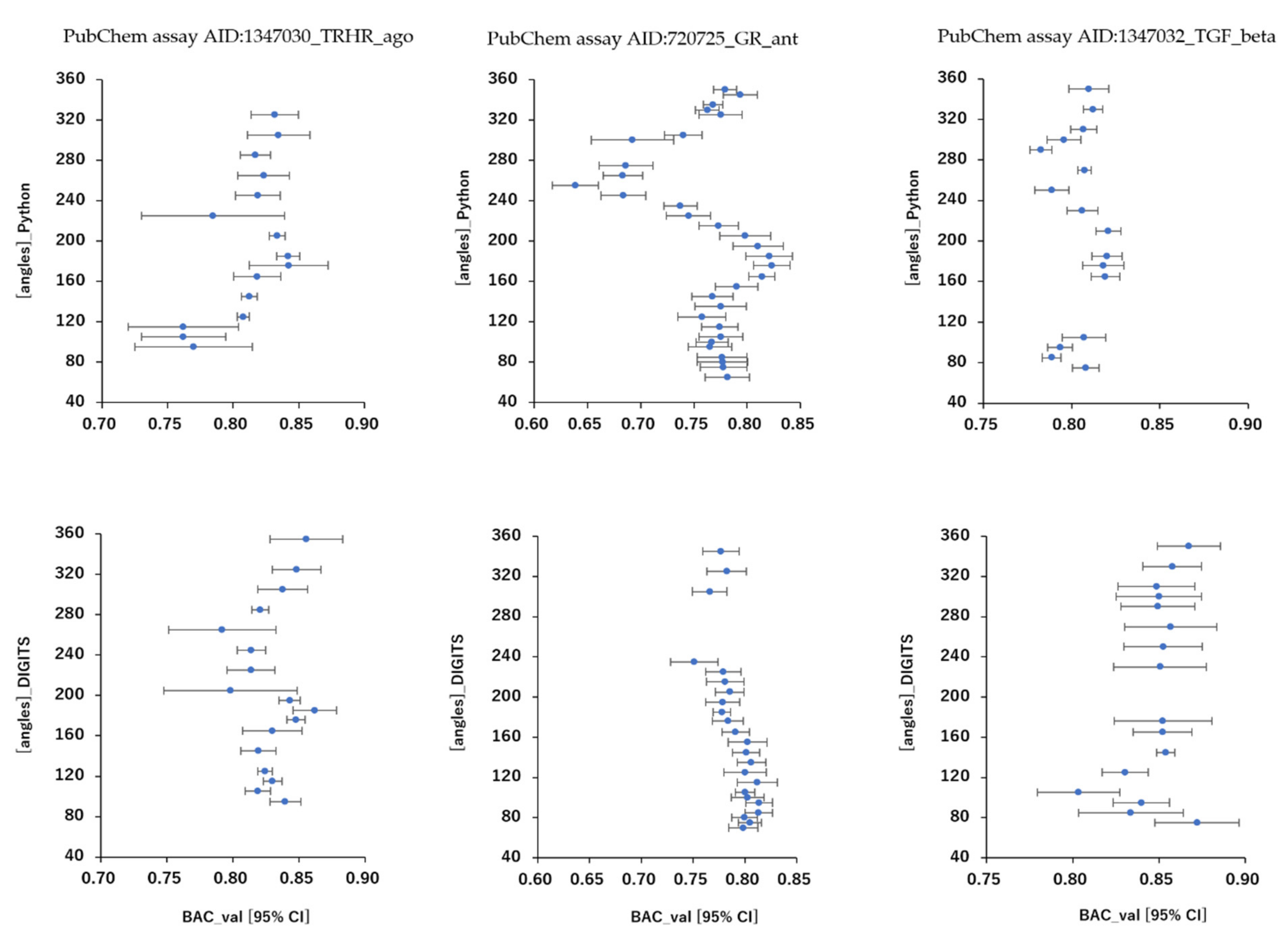
2.1. Angles and Data Split in DeepSnap-DL with DIGITS and Python Systems
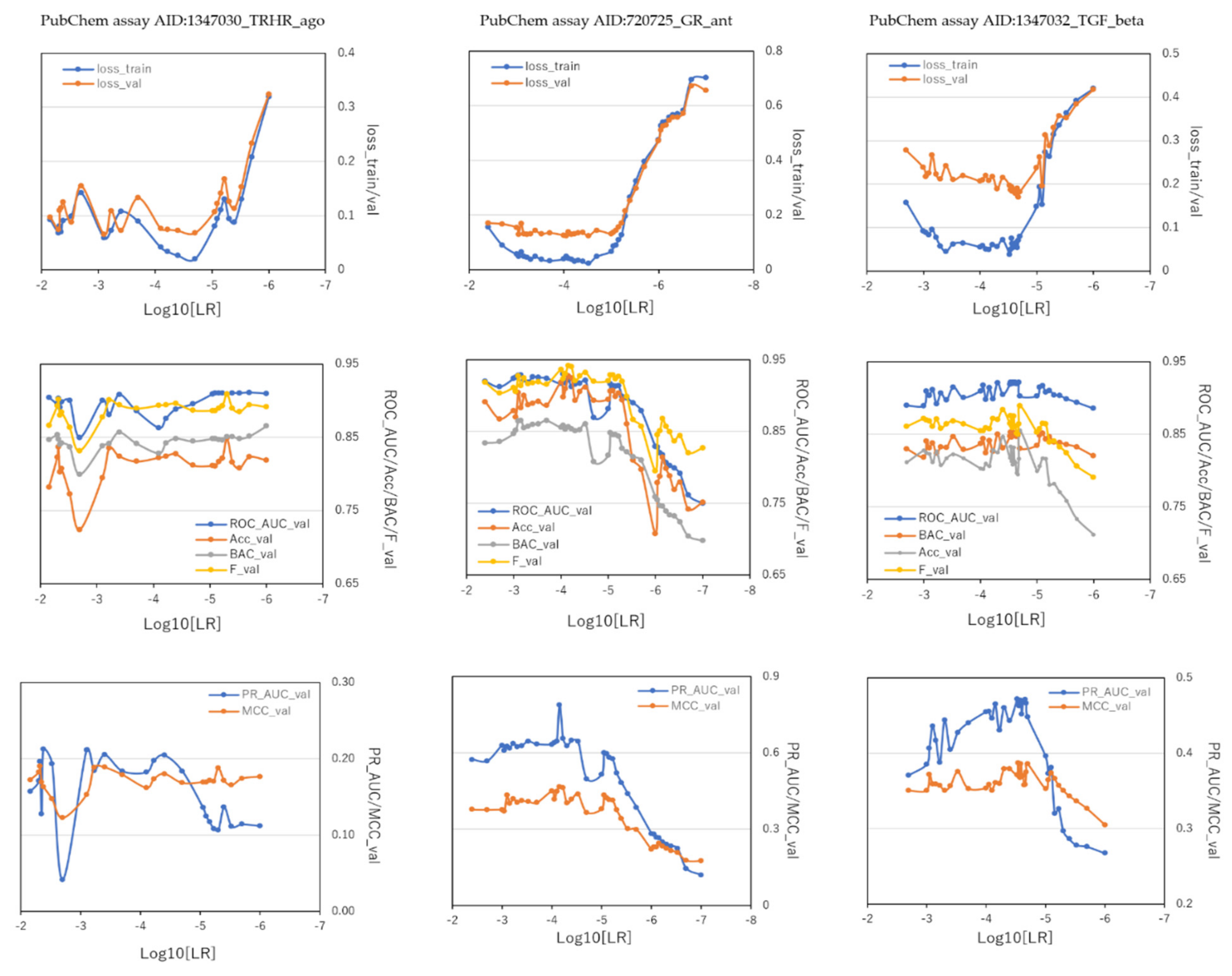
2.2. LR and BS in DeepSnap-DL
3. Materials and Methods
3.1. Data
3.2. DeepSnap
3.3. Evaluation of Prediction Models
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mao, J.; Akhtar, J.; Zhang, X.; Sun, L.; Guan, S.; Li, X.; Chen, G.; Liu, J.; Jeon, H.N.; Kim, M.S.; et al. Comprehensive strategies of machine-learning-based quantitative structure-activity relationship models. iScience 2021, 24, 103052. [Google Scholar] [CrossRef]
- Ahmadi, S.; Moradi, Z.; Kumar, A.; Almasirad, A. SMILES-based QSAR and molecular docking study of xanthone derivatives as alpha-glucosidase inhibitors. J. Recept. Signal. Transduct. Res. 2021, 12, 1–12. [Google Scholar] [CrossRef]
- Amin, S.A.; Ghosh, K.; Gayen, S.; Jha, T. Chemical-informatics approach to COVID-19 drug discovery: Monte Carlo based QSAR, virtual screening and molecular docking study of some in-house molecules as papain-like protease (PLpro) inhibitors. J. Biomol. Struct. Dyn. 2021, 39, 4764–4773. [Google Scholar] [CrossRef] [PubMed]
- Ashraf, S.; Ranaghan, K.E.; Woods, C.J.; Mulholland, A.J.; Ul-Haq, Z. Exploration of the structural requirements of Aurora Kinase B inhibitors by a combined QSAR, modelling and molecular simulation approach. Sci. Rep. 2021, 11, 18707. [Google Scholar] [CrossRef]
- Aziz, M.A.; Shehab, W.S.; Al-Karmalawy, A.A.; El-Farargy, A.F.; Abdellattif, M.H. Design, Synthesis, Biological Evaluation, 2D-QSAR Modeling, and Molecular Docking Studies of Novel 1H-3-Indolyl Derivatives as Significant Antioxidants. Int. J. Mol. Sci. 2021, 22, 10396. [Google Scholar] [CrossRef]
- de Souza, A.S.; de Souza, R.F.; Guzzo, C.R. Quantitative structure-activity relationships, molecular docking and molecular dynamics simulations reveal drug repurposing candidates as potent SARS-CoV-2 main protease inhibitors. J. Biomol. Struct. Dyn. 2021, 9, 1–18. [Google Scholar] [CrossRef]
- Bahmani, A.; Tanzadehpanah, H.; Hosseinpour Moghadam, N.; Saidijam, M. Introducing a pyrazolopyrimidine as a multi-tyrosine kinase inhibitor, using multi-QSAR and docking methods. Mol. Divers. 2021, 25, 949–965. [Google Scholar] [CrossRef]
- Elekofehinti, O.O.; Iwaloye, O.; Molehin, O.R.; Famusiwa, C.D. Identification of lead compounds from large natural product library targeting 3C-like protease of SARS-CoV-2 using E-pharmacophore modelling, QSAR and molecular dynamics simulation. Silico Pharmacol. 2021, 9, 49. [Google Scholar] [CrossRef] [PubMed]
- Gentile, D.; Floresta, G.; Patamia, V.; Chiaramonte, R.; Mauro, G.L.; Rescifina, A.; Vecchio, M. An Integrated Pharmacophore/Docking/3D-QSAR Approach to Screening a Large Library of Products in Search of Future Botulinum Neurotoxin A Inhibitors. Int. J. Mol. Sci. 2020, 21, 9470. [Google Scholar] [CrossRef]
- He, Q.; Han, C.; Li, G.; Guo, H.; Wang, Y.; Hu, Y.; Lin, Z.; Wang, Y. In silico design novel (5-imidazol-2-yl-4-phenylpyrimidin-2-yl)[2-(2-pyridylamino)ethyl]amine derivatives as inhibitors for glycogen synthase kinase 3 based on 3D-QSAR, molecular docking and molecular dynamics simulation. Comput. Biol. Chem. 2020, 88, 107328. [Google Scholar] [CrossRef]
- Huang, M.; Duan, W.G.; Lin, G.S.; Li, B.Y. Synthesis, Antifungal Activity, 3D-QSAR, and Molecular Docking Study of Novel Menthol-Derived 1,2,4-Triazole-thioether Compounds. Molecules 2021, 26, 6948. [Google Scholar] [CrossRef] [PubMed]
- Izadpanah, E.; Riahi, S.; Abbasi-Radmoghaddam, Z.; Gharaghani, S.; Mohammadi-Khanaposhtanai, M. A simple and robust model to predict the inhibitory activity of alpha-glucosidase inhibitors through combined QSAR modeling and molecular docking techniques. Mol. Divers. 2021, 25, 1811–1825. [Google Scholar] [CrossRef]
- Kasmi, R.; Hadaji, E.; Chedadi, O.; El Aissouq, A.; Bouachrine, M.; Ouammou, A. 2D-QSAR and docking study of a series of coumarin derivatives as inhibitors of CDK (anticancer activity) with an application of the molecular docking method. Heliyon 2020, 6, e04514. [Google Scholar] [CrossRef]
- Mellado, M.; González, C.; Mella, J.; Aguilar, L.F.; Viña, D.; Uriarte, E.; Cuellar, M.; Matos, M.J. Combined 3D-QSAR and docking analysis for the design and synthesis of chalcones as potent and selective monoamine oxidase B inhibitors. Bioorganic Chem. 2021, 108, 104689. [Google Scholar] [CrossRef]
- Menke, J.; Maskri, S.; Koch, O. Computational Ion Channel Research: From the Application of Artificial Intelligence to Molecular Dynamics Simulations. Cell Physiol. Biochem. 2021, 55, 14–45. [Google Scholar] [CrossRef]
- Metelytsia, L.O.; Trush, M.M.; Kovalishyn, V.V.; Hodyna, D.M.; Kachaeva, M.V.; Brovarets, V.S.; Pilyo, S.G.; Sukhoveev, V.V.; Tsyhankov, S.A.; Blagodatnyi, V.M.; et al. 1,3-Oxazole derivatives of cytisine as potential inhibitors of glutathione reductase of Candida spp.: QSAR modeling, docking analysis and experimental study of new anti-Candida agents. Comput. Biol. Chem. 2021, 90, 107407. [Google Scholar] [CrossRef] [PubMed]
- Oyewole, R.O.; Oyebamiji, A.K.; Semire, B. Theoretical calculations of molecular descriptors for anticancer activities of 1,2,3-triazole-pyrimidine derivatives against gastric cancer cell line (MGC-803): DFT, QSAR and docking approaches. Heliyon 2020, 6, e03926. [Google Scholar] [CrossRef] [PubMed]
- Poustforoosh, A.; Faramarz, S.; Nematollahi, M.H.; Hashemipour, H.; Tüzün, B.; Pardakhty, A.; Mehrabani, M. 3D-QSAR, molecular docking, molecular dynamics, and ADME/T analysis of marketed and newly designed flavonoids as inhibitors of Bcl-2 family proteins for targeting U-87 glioblastoma. J. Cell Biochem. 2021, in press. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.M.; Saha, T.; Islam, K.J.; Suman, R.H.; Biswas, S.; Rahat, E.U.; Hossen, M.R.; Islam, R.; Hossain, M.N.; Mamun, A.A.; et al. Virtual screening, molecular dynamics and structure-activity relationship studies to identify potent approved drugs for Covid-19 treatment. J. Biomol. Struct. Dyn. 2021, 39, 6231–6241. [Google Scholar] [CrossRef]
- Righetti, G.; Casale, M.; Liessi, N.; Tasso, B.; Salis, A.; Tonelli, M.; Millo, E.; Pedemonte, N.; Fossa, P.; Cichero, E. Molecular Docking and QSAR Studies as Computational Tools Exploring the Rescue Ability of F508del CFTR Correctors. Int. J. Mol. Sci. 2020, 21, 8084. [Google Scholar] [CrossRef]
- Rosa, G.P.; Palmeira, A.; Resende, D.I.S.P.; Almeida, I.F.; Kane-Pagès, A.; Barreto, M.C.; Sousa, E.; Pinto, M.M.M. Xanthones for melanogenesis inhibition: Molecular docking and QSAR studies to understand their anti-tyrosinase activity. Bioorganic Med. Chem. 2021, 29, 115873. [Google Scholar] [CrossRef] [PubMed]
- Rosell-Hidalgo, A.; Young, L.; Moore, A.L.; Ghafourian, T. QSAR and molecular docking for the search of AOX inhibitors: A rational drug discovery approach. J. Comput. Aided Mol. Des. 2021, 35, 245–260. [Google Scholar] [CrossRef]
- Shah, B.M.; Modi, P.; Trivedi, P. Pharmacophore-based virtual screening, 3D-QSAR, molecular docking approach for identification of potential dipeptidyl peptidase IV inhibitors. J. Biomol. Struct. Dyn. 2021, 39, 2021–2043. [Google Scholar] [CrossRef] [PubMed]
- Shamsi, E.; Rahati, A.; Dehghanian, E. A modified binary particle swarm optimization with a machine learning algorithm and molecular docking for QSAR modelling of cholinesterase inhibitors. SAR QSAR Environ. Res. 2021, 32, 745–767. [Google Scholar] [CrossRef] [PubMed]
- Shulga, D.A.; Kudryavtsev, K.V. Selection of Promising Novel Fragment Sized S. aureus SrtA Noncovalent Inhibitors Based on QSAR and Docking Modeling Studies. Molecules 2021, 26, 7677. [Google Scholar] [CrossRef]
- Taha, I.; Keshk, E.M.; Khalil, A.M.; Fekri, A. Synthesis, characterization, antibacterial evaluation, 2D-QSAR modeling and molecular docking studies for benzocaine derivatives. Mol. Divers. 2021, 25, 435–459. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Feng, L.; Sun, X.; Yu, R.; Kang, C. Design and screening of FAK, CDK 4/6 dual inhibitors by pharmacophore model, molecular docking, and molecular dynamics simulation. J. Biomol. Struct. Dyn. 2021, 39, 5358–5367. [Google Scholar] [CrossRef] [PubMed]
- Tong, J.B.; Luo, D.; Feng, Y.; Bian, S.; Zhang, X.; Wang, T.H. Structural modification of 4, 5-dihydro-[1, 2, 4] triazolo [4, 3-f] pteridine derivatives as BRD4 inhibitors using 2D/3D-QSAR and molecular docking analysis. Mol. Divers. 2021, 25, 1855–1872. [Google Scholar] [CrossRef]
- Veligeti, R.; Madhu, R.B.; Anireddy, J.; Pasupuleti, V.R.; Avula, V.K.R.; Ethiraj, K.S.; Uppalanchi, S.; Kasturi, S.; Perumal, Y.; Anantaraju, H.S.; et al. Synthesis of novel cytotoxic tetracyclic acridone derivatives and study of their molecular docking, ADMET, QSAR, bioactivity and protein binding properties. Sci. Rep. 2020, 10, 20720. [Google Scholar] [CrossRef]
- Wang, F.; Qiu, Y.; Zhou, B. In silico exploration of hydroxylated polychlorinated biphenyls as estrogen receptor beta ligands by 3D-QSAR, molecular docking and molecular dynamics simulations. J. Biomol. Struct. Dyn. 2021, 1, 1–12. [Google Scholar] [CrossRef]
- Wang, X.; Duan, W.; Lin, G.; Li, B.; Chen, M.; Lei, F. Synthesis, 3D-QSAR and Molecular Docking Study of Nopol-Based 1,2,4-Triazole-Thioether Compounds as Potential Antifungal Agents. Front. Chem. 2021, 9, 757584. [Google Scholar] [CrossRef] [PubMed]
- Yalcin-Ozkat, G. Molecular Modeling Strategies of Cancer Multidrug Resistance. Drug Resist. Updat. 2021, 24, 100789. [Google Scholar] [CrossRef] [PubMed]
- Zięba, A.; Laitinen, T.; Patel, J.Z.; Poso, A.; Kaczor, A.A. Docking-Based 3D-QSAR Studies for 1,3,4-oxadiazol-2-one Derivatives as FAAH Inhibitors. Int. J. Mol. Sci. 2021, 22, 6108. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Q.; Ren, Y.; Liu, F. Molecular modeling studies of benzothiophene-containing derivatives as promising selective estrogen receptor downregulators: A combination of 3D-QSAR, molecular docking and molecular dynamics simulations. J. Biomol. Struct. Dyn. 2021, 39, 2702–2723. [Google Scholar] [CrossRef] [PubMed]
- Fang, C.; Xiao, Z. Receptor-based 3D-QSAR in Drug Design: Methods and Applications in Kinase Studies. Curr. Top. Med. Chem. 2016, 16, 1463–1477. [Google Scholar] [CrossRef]
- Deb, P.K.; Chandrasekaran, B.; Mailavaram, R.; Tekade, R.K.; Jaber, A.M.Y. Molecular modeling approaches for the discovery of adenosine A(2B) receptor antagonists: Current status and future perspectives. Drug Discov. Today 2019, 24, 1854–1864. [Google Scholar] [CrossRef] [PubMed]
- Valizade Hasanloei, M.A.; Sheikhpour, R.; Sarram, M.A.; Sheikhpour, E.; Sharifi, H. A combined Fisher and Laplacian score for feature selection in QSAR based drug design using compounds with known and unknown activities. J. Comput. Aided Mol. Des. 2018, 32, 375–384. [Google Scholar] [CrossRef] [PubMed]
- Antelo-Collado, A.; Carrasco-Velar, R.; García-Pedrajas, N.; Cerruela-García, G. Effective Feature Selection Method for Class-Imbalance Datasets Applied to Chemical Toxicity Prediction. J. Chem. Inf. Model. 2021, 61, 76–94. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.K. Topological Distance-Based Electron Interaction Tensor to Apply a Convolutional Neural Network on Drug-like Compounds. ACS Omega 2021, 6, 35757–35768. [Google Scholar] [CrossRef] [PubMed]
- Bak, A. Two Decades of 4D-QSAR: A Dying Art or Staging a Comeback? Int. J. Mol. Sci. 2021, 22, 5212. [Google Scholar] [CrossRef]
- Damale, M.G.; Harke, S.N.; Kalam Khan, F.A.; Shinde, D.B.; Sangshetti, J.N. Recent advances in multidimensional QSAR (4D–6D): A critical review. Mini Rev. Med. Chem. 2014, 14, 35–55. [Google Scholar] [CrossRef] [PubMed]
- Fourches, D.; Ash, J. 4D-quantitative structure-activity relationship modeling: Making a comeback. Expert Opin. Drug Discov. 2019, 14, 1227–1235. [Google Scholar] [CrossRef] [PubMed]
- Vedani, A.; Dobler, M. 5D-QSAR: The key for simulating induced fit? J. Med. Chem. 2002, 45, 2139–2149. [Google Scholar] [CrossRef] [PubMed]
- Ducki, S.; Mackenzie, G.; Lawrence, N.J.; Snyder, J.P. Quantitative structure-activity relationship (5D-QSAR) study of combretastatin-like analogues as inhibitors of tubulin assembly. J. Med. Chem. 2005, 48, 457–465. [Google Scholar] [CrossRef] [PubMed]
- Oberdorf, C.; Schmidt, T.J.; Wünsch, B. 5D-QSAR for spirocyclic sigma1 receptor ligands by Quasar receptor surface modeling. Eur. J. Med. Chem. 2010, 45, 3116–3124. [Google Scholar] [CrossRef] [PubMed]
- Vedani, A.; Dobler, M.; Lill, M.A. Combining protein modeling and 6D-QSAR. Simulating the binding of structurally diverse ligands to the estrogen receptor. J. Med. Chem. 2005, 48, 3700–3703. [Google Scholar] [CrossRef]
- Uesawa, Y. Quantitative structure-activity relationship analysis using deep learning based on a novel molecular image input technique. Bioor. Med. Chem. Lett. 2018, 28, 3400–3403. [Google Scholar] [CrossRef] [PubMed]
- Attene-Ramos, M.S.; Miller, N.; Huang, R.; Michael, S.; Itkin, M.; Kavlock, R.J.; Austin, C.P.; Shinn, P.; Simeonov, A.; Tice, R.R.; et al. The Tox21 robotic platform for the assessment of environmental chemicals--from vision to reality. Drug Discov. Today 2013, 18, 716–723. [Google Scholar] [CrossRef] [Green Version]
- Menegola, E.; Veltman, C.H.J.; Battistoni, M.; Di Renzo, F.; Moretto, A.; Metruccio, F.; Beronius, A.; Zilliacus, J.; Kyriakopoulou, K.; Spyropoulou, A.; et al. An adverse outcome pathway on the disruption of retinoic acid metabolism leading to developmental craniofacial defects. Toxicology 2021, 458, 152843. [Google Scholar] [CrossRef]
- Matsuzaka, Y.; Uesawa, Y. Optimization of a Deep-Learning Method Based on the Classification of Images Generated by Parameterized Deep Snap a Novel Molecular-Image-Input Technique for Quantitative Structure-Activity Relationship (QSAR) Analysis. Front. Bioeng. Biotechnol. 2019, 7, 65. [Google Scholar] [CrossRef] [Green Version]
- Matsuzaka, Y.; Uesawa, Y. Prediction model with high-performance constitutive androstane receptor (car) using deepsnap-deep learning approach from the Tox21 10K compound library. Int. J. Mol. Sci. 2019, 20, 4855. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Matsuzaka, Y.; Uesawa, Y. DeepSnap-deep learning approach predicts progesterone receptor antagonist activity with high performance. Front. Bioeng. Biotechnol. 2020, 7, 485. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Matsuzaka, Y.; Uesawa, Y. molecular image-based prediction models of nuclear receptor agonists and antagonists using the deepsnap-deep learning approach with the Tox21 10K library. Molecules 2020, 25, 2764. [Google Scholar] [CrossRef]
- Matsuzaka, Y.; Totoki, S.; Handa, K.; Shiota, T.; Kurosaki, K.; Uesawa, Y. Prediction Models for Agonists and Antagonists of Molecular Initiation Events for Toxicity Pathways Using an Improved Deep-Learning-Based Quantitative Structure-Activity Relationship System. Int. J. Mol. Sci. 2021, 22, 10821. [Google Scholar] [CrossRef]
- Heo, T.Y.; Kim, K.M.; Min, H.K.; Gu, S.M.; Kim, J.H.; Yun, J.; Min, J.K. Development of a Deep-Learning-Based Artificial Intelligence Tool for Differential Diagnosis between Dry and Neovascular Age-Related Macular Degeneration. Diagnostics 2020, 10, 261. [Google Scholar] [CrossRef] [PubMed]
- Umer, M.; Ashraf, I.; Ullah, S.; Mehmood, A.; Choi, G.S. COVINet: A convolutional neural network approach for predicting COVID-19 from chest X-ray images. J. Ambient. Intell. Humaniz. Comput. 2021, 28, 535–547. [Google Scholar] [CrossRef] [PubMed]
- He, C.; Liu, J.; Zhu, Y.; Du, W. Data Augmentation for Deep Neural Networks Model in EEG Classification Task: A Review. Front. Hum. Neurosci. 2021, 15, 765525. [Google Scholar] [CrossRef]
- Nanni, L.; Paci, M.; Brahnam, S.; Lumini, A. Comparison of Different Image Data Augmentation Approaches. J. Imaging 2021, 7, 254. [Google Scholar] [CrossRef]
- Tsai, K.J.; Chang, C.C.; Lo, L.C.; Chiang, J.Y.; Chang, C.S.; Huang, Y.J. Automatic segmentation of paravertebral muscles in abdominal CT scan by U-Net: The application of data augmentation technique to increase the Jaccard ratio of deep learning. Medicine 2021, 100, e27649. [Google Scholar] [CrossRef]
- Chun, J.; Park, J.C.; Olberg, S.; Zhang, Y.; Nguyen, D.; Wang, J.; Kim, J.S.; Jiang, S. Intentional deep overfit learning (IDOL): A novel deep learning strategy for adaptive radiation therapy. Med. Phys. 2021, in press. [Google Scholar] [CrossRef]
- Lin, B.; Cheng, M.; Wang, S.; Li, F.; Zhou, Q. Automatic detection of anteriorly displaced temporomandibular joint discs on magnetic resonance images using a deep learning algorithm. Dentomaxillofac. Radiol. 2021, 29, 20210341. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.H.; Zhu, Z.; Zhang, Y.D. PSCNN: PatchShuffle Convolutional Neural Network for COVID-19 Explainable Diagnosis. Front. Public Health 2021, 9, 768278. [Google Scholar] [CrossRef] [PubMed]
- Tsai, J.Y.; Hung, I.Y.; Guo, Y.L.; Jan, Y.K.; Lin, C.Y.; Shih, T.T.; Chen, B.B.; Lung, C.W. Lumbar Disc Herniation Automatic Detection in Magnetic Resonance Imaging Based on Deep Learning. Front. Bioeng. Biotechnol. 2021, 9, 708137. [Google Scholar] [CrossRef]
- Hidayatullah, P.; Wang, X.; Yamasaki, T.; Mengko, T.L.E.R.; Munir, R.; Barlian, A.; Sukmawati, E.; Supraptono, S. DeepSperm: A robust and real-time bull sperm-cell detection in densely populated semen videos. Comput. Methods Programs Biomed. 2021, 209, 106302. [Google Scholar] [CrossRef]
- Whang, A.J.; Chen, Y.Y.; Tseng, W.C.; Tsai, C.H.; Chao, Y.P.; Yen, C.H.; Liu, C.H.; Zhang, X. Pupil Size Prediction Techniques Based on Convolution Neural Network. Sensors 2021, 21, 4965. [Google Scholar] [CrossRef] [PubMed]
- Cui, J.; Zhang, X.; Xiong, F.; Chen, C.L. Pathological Myopia Image Recognition Strategy Based on Data Augmentation and Model Fusion. J. Healthc. Eng. 2021, 2021, 5549779. [Google Scholar] [CrossRef]
- Mai, Z.; Hu, G.; Chen, D.; Shen, F.; Shen, H.T. MetaMixUp: Learning Adaptive Interpolation Policy of MixUp With Metalearning. IEEE Trans. Neural. Netw. Learn. Syst. 2021, in press. [Google Scholar] [CrossRef]
- Yi, L.; Mak, M.W. Improving Speech Emotion Recognition With Adversarial Data Augmentation Network. IEEE Trans. Neural. Netw. Learn Syst. 2022, 33, 172–184. [Google Scholar] [CrossRef]
- Tang, Z.; Gao, Y.; Karlinsky, L.; Sattigeri, P.; Feris, R.; Metaxas, D. OnlineAugment: Online Data Augmentation with Less Domain Knowledge. arXiv 2020, arXiv:2007.09271. Available online: https://arxiv.org/abs/2007.09271 (accessed on 17 July 2020).
- Lam, T.K.; Ohta, M.; Schamoni, S.; Riezler, S. On-the-Fly Aligned Data Augmentation for Sequence-to-Sequence ASR. arXiv Preprint 2021, arXiv:2104.01393. Available online: https://arxiv.org/abs/2104.01393 (accessed on 3 April 2021).
- Vasudevan, S. Mutual Information Based Learning Rate Decay for Stochastic Gradient Descent Training of Deep Neural Networks. Entropy 2020, 22, 560. [Google Scholar] [CrossRef] [PubMed]
- Smith, S.L.; Kindermans, P.-J.; Ying, C.; Le, Q.L. Don’t Decay the Learning Rate, Increase the Batch Size. arXiv Prepr. 2018, arXiv:1711.00489. Available online: https://arxiv.org/abs/1711.00489 (accessed on 1 November 2017).
- Hanson, R.M. Jmol SMILES and Jmol SMARTS: Specifications and applications. J. Cheminform. 2016, 8, 50. [Google Scholar] [CrossRef] [Green Version]
- Scalfani, V.F.; Williams, A.J.; Tkachenko, V.; Karapetyan, K.; Pshenichnov, A.; Hanson, R.M.; Liddie, J.M.; Bara, J.E. Programmatic conversion of crystal structures into 3D printable files using Jmol. J. Cheminform. 2016, 8, 66. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hanson, R.M.; Lu, X.J. DSSR-enhanced visualization of nucleic acid structures in Jmol. Nucleic Acids Res. 2017, 45, W528–W533. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- PyMOLWiki. Available online: https://pymolwiki.org/index.php/Color_Values (accessed on 22 January 2011).
- Xu, T.; Wang, J.; Fang, Y. A model-free estimation for the covariate-adjusted Youden index and its associated cut-point. arXiv Prepr. 2014, arXiv:1402.1835v1. Available online: https://arxiv.org/abs/1402.1835 (accessed on 8 February 2014). [CrossRef] [PubMed] [Green Version]
- Yuan, M.; Li, P.; Wu, C. Semiparametric Inference of the Youden Index and the Optimal Cutoff Point under Density Ratio Models. arXiv Prepr. 2020, arXiv:2005.04362. Available online: https://arxiv.org/abs/2005.04362 (accessed on 9 May 2020).
- Syring, N. Robust posterior inference for Youden’s index cutoff. arXiv Prepr. 2021, arXiv:2108.04898v1. Available online: https://arxiv.org/abs/2108.04898 (accessed on 10 August 2021). [CrossRef]
- Artificial Intelligence Research. Computing Deviation of Area under the Precision-Recall CURVE (washington.edu). Available online: http://aiweb.cs.washington.edu/ai/mln/auc.html (accessed on 10 August 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Angles in DeepSnap_Python | Angles in DeepSnap_DIGITS | |||||
|---|---|---|---|---|---|---|
| PubChem Assay AID | No. | Minimum (°) | Maximum (°) | No. | Minimum (°) | Maximum (°) |
| 720725_GR_ant | 31 | 65 | 350 | 23 | 70 | 345 |
| 1347030_TRHR_ago | 15 | 95 | 325 | 17 | 95 | 355 |
| 1347032_TGF_beta | 16 | 75 | 350 | 16 | 75 | 350 |
| Data Splits in DeepSnap_Python | Data Splits in DeepSnap_DIGITS | |||
|---|---|---|---|---|
| PubChem Assay AID | No. | Type | No. | Type |
| 720725_GR_ant | 7 | 1:1:1, 2:2:1, 3:3:1, 4:4:1, 5:5:1, 5:3:2, 7:1:2 | 7 | 1:1:1, 2:2:1, 3:3:1, 4:4:1, 5:5:1, 5:3:2, 7:1:2 |
| 1347030_TRHR_ago | 3 | 1:1:1, 3:1:2, 5:3:4 | 3 | 1:1:1, 3:1:2, 5:3:4 |
| 1347032_TGF_beta | 8 | 1:1:1, 2:2:1, 3:1:1, 3:2:1, 5:3:2, 5:5:1, 6:1:2, 7:1:2 | 8 | 1:1:1, 2:2:1, 3:1:1, 3:2:1, 5:1:1, 5:3:2, 6:1:2, 7:1:2 |
| PubChem | 720725_GR_Ant | 1347030_TRHR_Ago | 1347032_TGF_Beta_Python | ||||
|---|---|---|---|---|---|---|---|
| Assay AID | Python | DIGITS | Python | DIGITS | Python | DIGITS | |
| ROC_AUC | average | 0.832 ± 0.048 | 0.856 ± 0.029 | 0.875 ± 0.031 | 0.886 ± 0.028 | 0.879 ± 0.015 | 0.907 ± 0.020 |
| max_ROC_AUC | 0.926 | 0.910 | 0.915 | 0.918 | 0.911 | 0.932 | |
| max_angle | 185 | 95 | 176 | 185 | 185 | 75 | |
| max_split | 7:1:2 | 5:5:1 | 3:1:2 | 5:3:4 | 7:1:2 | 5:3:2 | |
| BAC | average | 0.762 ± 0.044 | 0.791 ± 0.023 | 0.811 ± 0.032 | 0.829 ± 0.023 | 0.805 ± 0.015 | 0.849 ± 0.030 |
| max_BAC | 0.864 | 0.837 | 0.868 | 0.876 | 0.844 | 0.930 | |
| max_angle | 185 | 95 | 176 | 355 | 185 | 176 | |
| max_split | 7:1:2 | 3:3:1 | 3:1:2 | 5:3:4 | 7:1:2 | 5:3:2 | |
| MCC | average | 0.248 ± 0.065 | 0.282 ± 0.030 | 0.141 ± 0.017 | 0.155 ± 0.022 | 0.309 ± 0.025 | 0.384 ± 0.044 |
| max_MCC | 0.451 | 0.354 | 0.194 | 0.208 | 0.373 | 0.478 | |
| max_angle | 176 | 75 | 176 | 355 | 176 | 165 | |
| max_split | 7:1:2 | 4:4:1 | 3:1:2 | 1:1:1 | 7:1:2 | 2:2:1 | |
| Acc | average | 0.790 ± 0.058 | 0.812 ± 0.044 | 0.781 ± 0.030 | 0.769 ± 0.060 | 0.770 ± 0.029 | 0.833 ± 0.033 |
| max_Acc | 0.917 | 0.939 | 0.856 | 0.902 | 0.834 | 0.896 | |
| max_angle | 176 | 155 | 176 | 125 | 176 | 165 | |
| max_split | 7:1:2 | 4:4:1 | 3:1:2 | 1:1:1 | 7:1:2 | 2:2:1 | |
| loss_val | average | 0.383 ± 0.115 | 0.108 ± 0.014 | 0.189 ± 0.070 | 0.032 ± 0.007 | 0.316 ± 0.061 | 0.113 ± 0.011 |
| min_loss_train | 0.110 | 0.065 | 0.194 | 0.024 | 0.197 | 0.087 | |
| min_angle | 185 | 195 | 176 | 325 | 350 | 230 | |
| max_split | 7:1:2 | 7:1:2 | 3:1:2 | 3:1:2 | 3:2:1 | 7:1:2 | |
| loss_train | average | 0.413 ± 0.153 | 0.247 ± 0.088 | 0.280 ± 0.120 | |||
| min_loss_train | 0.038 | 0.047 | 0.044 | ||||
| min_angle | 176 | 176 | 176 | ||||
| max_split | 2:2:1 | 1:1:1 | 1:1:1 | ||||
| PR_AUC | average | 0.335 ± 0.117 | 0.103 ± 0.041 | 0.315 ± 0.056 | |||
| max_PR_AUC | 0.660 | 0.194 | 0.453 | ||||
| max_angle | 176 | 176 | 176 | ||||
| max_split | 7:1:2 | 3:1:2 | 3:1:1 | ||||
| F | average | 0.853 ± 0.039 | 0.868 ± 0.020 | 0.833 ± 0.020 | |||
| max_F | 0.935 | 0.914 | 0.876 | ||||
| max_angle | 176 | 176 | 176 | ||||
| max_split | 7:1:2 | 3:1:2 | 7:1:2 | ||||
| PubChem | 720725_GR_Ant | 1347030_TRHR | 1347032_TGF_Beta | |
|---|---|---|---|---|
| Assay AID | Train:Valid:Test = 7:1:2 | Train:Valid:Test = 3:1:2 | Train:Valid:Test = 7:1:2 | |
| ROC_AUC | average | 0.884 ± 0.053 | 0.897 ± 0.016 | 0.909 ± 0.011 |
| max_ROC_AUC | 0.930 | 0.911 | 0.922 | |
| max_LR | 0.00009 | 0.000002 | 0.000021 | |
| BAC | average | 0.817 ± 0.053 | 0.844 ± 0.012 | 0.839 ± 0.010 |
| max_BAC | 0.865 | 0.865 | 0.853 | |
| max_LR | 0.0007 | 0.000001 | 0.000029 | |
| MCC | average | 0.354 ± 0.090 | 0.171 ± 0.015 | 0.361 ± 0.016 |
| max_MCC | 0.466 | 0.191 | 0.387 | |
| max_LR | 0.00007 | 0.0048 | 0.000029 | |
| Acc | average | 0.859 ± 0.060 | 0.811 ± 0.025 | 0.807 ± 0.028 |
| max_Acc | 0.928 | 0.848 | 0.855 | |
| max_LR | 0.00007 | 0.000005 | 0.00002 | |
| loss_train | average | 0.215 ± 0.231 | 0.098 ± 0.062 | 0.125 ± 0.110 |
| min_loss | 0.022 | 0.020 | 0.038 | |
| min_LR | 0.00003 | 0.00002 | 0.00003 | |
| loss_val | average | 0.263 ± 0.186 | 0.122 ± 0.058 | 0.236 ± 0.062 |
| min_loss | 0.124 | 0.066 | 0.170 | |
| min_LR | 0.00003 | 0.0008 | 0.000021 | |
| PR_AUC | average | 0.502 ± 0.177 | 0.155 ± 0.045 | 0.410 ± 0.064 |
| max_PR_AUC | 0.789 | 0.213 | 0.472 | |
| max_LR | 0.00007 | 0.0042 | 0.00003 | |
| F | average | 0.898 ± 0.039 | 0.886 ± 0.015 | 0.858 ± 0.019 |
| max_F | 0.942 | 0.909 | 0.890 | |
| max_LR | 0.00007 | 0.000005 | 0.00002 |
| PubChem | 720725_GR_Ant | 1347030_TRHR | 1347032_TGF_Beta | |
|---|---|---|---|---|
| Assay AID | Train:Valid:Test = 7:1:2 | Train:Valid:Test = 3:1:2 | Train:Valid:Test = 7:1:2 | |
| ROC_AUC | average | 0.983 ± 0.032 | 0.929 ± 0.003 | 0.918 ± 0.005 |
| max_ROC_AUC | 0.983 | 0.934 | 0.925 | |
| max_BS | 125 | 14 | 28 | |
| BAC | average | 0.866 ± 0.033 | 0.877 ± 0.004 | 0.848 ± 0.007 |
| max_BAC | 0.930 | 0.881 | 0.862 | |
| max_BS | 125 | 22 | 44 | |
| MCC | average | 0.444 ± 0.056 | 0.194 ± 0.004 | 0.368 ± 0.011 |
| max_MCC | 0.604 | 0.200 | 0.390 | |
| max_BS | 200 | 14 | 28 | |
| Acc | average | 0.908 ± 0.021 | 0.855 ± 0.005 | 0.810 ± 0.011 |
| max_Acc | 0.954 | 0.863 | 0.835 | |
| max_BS | 200 | 14 | 20 | |
| loss_train | average | 0.045 ± 0.033 | 0.322 ± 0.013 | 0.097 ± 0.047 |
| min_loss | 0.019 | 0.301 | 0.037 | |
| min_BS | 48 | 14 | 20 | |
| loss_test | average | 0.119 ± 0.025 | 0.314 ± 0.022 | 0.203 ± 0.023 |
| min_loss | 0.073 | 0.255 | 0.172 | |
| min_BS | 120 | 2 | 34 | |
| PR_AUC | average | 0.654 ± 0.087 | 0.136 ± 0.011 | 0.431 ± 0.032 |
| max_PR_AUC | 0.800 | 0.154 | 0.476 | |
| max_BS | 290 | 14 | 28 | |
| F | average | 0.930 ± 0.014 | 0.914 ± 0.003 | 0.860 ± 0.008 |
| max_F | 0.961 | 0.919 | 0.877 | |
| max_BS | 200 | 14 | 20 |
| All | Active Compound | Inactive Compound | |||
|---|---|---|---|---|---|
| PubChem Assay AID | No. | No. | % | No. | % |
| 720725_GR_ant | 7537 | 283 | 3.75 | 7254 | 96.25 |
| 1347030_TRHR_ago | 7662 | 67 | 0.87 | 7595 | 99.13 |
| 1347032_TGF_beta | 7604 | 395 | 5.19 | 7209 | 94.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matsuzaka, Y.; Uesawa, Y. A Deep Learning-Based Quantitative Structure–Activity Relationship System Construct Prediction Model of Agonist and Antagonist with High Performance. Int. J. Mol. Sci. 2022, 23, 2141. https://doi.org/10.3390/ijms23042141
Matsuzaka Y, Uesawa Y. A Deep Learning-Based Quantitative Structure–Activity Relationship System Construct Prediction Model of Agonist and Antagonist with High Performance. International Journal of Molecular Sciences. 2022; 23(4):2141. https://doi.org/10.3390/ijms23042141
Chicago/Turabian StyleMatsuzaka, Yasunari, and Yoshihiro Uesawa. 2022. "A Deep Learning-Based Quantitative Structure–Activity Relationship System Construct Prediction Model of Agonist and Antagonist with High Performance" International Journal of Molecular Sciences 23, no. 4: 2141. https://doi.org/10.3390/ijms23042141
APA StyleMatsuzaka, Y., & Uesawa, Y. (2022). A Deep Learning-Based Quantitative Structure–Activity Relationship System Construct Prediction Model of Agonist and Antagonist with High Performance. International Journal of Molecular Sciences, 23(4), 2141. https://doi.org/10.3390/ijms23042141