Abstract
Clinical genomics sequencing is rapidly expanding the number of variants that need to be functionally elucidated. Interpreting genetic variants (i.e., mutations) usually begins by identifying how they affect protein-coding sequences. Still, the three-dimensional (3D) protein molecule is rarely considered for large-scale variant analysis, nor in analyses of how proteins interact with each other and their environment. We propose a standardized approach to scoring protein surface property changes as a new dimension for functionally and mechanistically interpreting genomic variants. Further, it directs hypothesis generation for functional genomics research to learn more about the encoded protein’s function. We developed a novel method leveraging 3D structures and time-dependent simulations to score and statistically evaluate protein surface property changes. We evaluated positive controls composed of eight thermophilic versus mesophilic orthologs and variants that experimentally change the protein’s solubility, which all showed large and statistically significant differences in charge distribution (p < 0.01). We scored static 3D structures and dynamic ensembles for 43 independent variants (23 pathogenic and 20 uninterpreted) across four proteins. Focusing on the potassium ion channel, KCNK9, the average local surface potential shifts were 0.41 kBT/ec with an average p-value of 1 × 10−2. In contrast, dynamic ensemble shifts averaged 1.15 kBT/ec with an average p-value of 1 × 10−5, enabling the identification of changes far from mutated sites. This study demonstrates that an objective assessment of how mutations affect electrostatic distributions of protein surfaces can aid in interpreting genomic variants discovered through clinical genomic sequencing.
1. Introduction
Clinical genomics data are increasingly gathered to diagnose diseases and identify potential treatment options. Thus, interpreting genomics data is critical for precision medicine [1,2,3]. Most genomic variants used in clinical decision-making alter the protein-coding sequence of genes, yet the properties of the 3D and time-dynamic molecule are rarely assessed [4]. Proteins interact with each other and bind to metabolites and drugs using specific surfaces. Enzymatic sites, for example, have precisely calibrated surfaces for their chemistry. Similarly, many interaction surfaces, such as those that form multiprotein complexes, have been tuned to accommodate folding, assembly, and functional motions. Protein surface properties are thus critical characteristics for their function.
Currently, interpreting genomic variants considers gene or protein sequence changes, with data such as prior observation of variants, protein domains, or amino acid conservation annotated to those sequences [5,6,7]. However, it frequently occurs that the polypeptide chain folds on itself, making a diverse array of loops, turns, twists, and bends, resulting in regions of protein surfaces that are non-linear in the protein sequence. Such characteristics, with unique charge patterns, hydrophobicity, and shape, become characteristic features of the protein that are indispensable for the protein’s function. These surfaces are distinctive, irregular, and based on their specific role, such as ligand binding, protein–protein interactions, protein–membrane interactions, etc. Therefore, a 3D approach is more appropriate for the evaluation of variants.
Surface properties are determined by the combined contributions of intrinsic and extrinsic factors, which influence each other in a dynamic interplay of entropic and enthalpic exchanges. In an absolute sense, Anfinsen’s dogma would reduce protein intrinsic factors to the amino acid sequence. Still, the sequence itself can be separated into components of backbone dihedral angles, sidechain chemistry, sidechain packing, folding kinetics, and more. Protein extrinsic factors include substrates, cofactors, ions, other proteins, lipids, carbohydrates, and molecules that make up the environment. Further, surfaces have different characteristics, including shape, flexibility, and how hydrophobic and electrostatic potentials are distributed across them. Because protein intrinsic and extrinsic factors constantly interact, mutations can tip the balance among their combinations, potentially altering or dysregulating their function. In general, any small perturbation in intrinsic or extrinsic factors leads to cooperative surface rearrangements [8], which could vary depending on the type and nature of the perturbation. While surface differences have been investigated for specific proteins and disease variants [9], there are no general and standardized approaches for statistically determining the significance of surface changes for genetic variants identified through high-throughput sequencing. Therefore, this study sought to determine the statistical performance of a strategy for scoring differences in protein surface electrostatic properties due to mutations.
We designed this study to begin with straightforward positive controls for global and local changes, then progress to mutations with known effects, followed by genomic variants currently uninterpreted in the same genes. The positive control variants a priori should have distinct changes, such as thermophilic and mesophilic orthologs, and experimentally determined mutations that increase protein solubility. Then, equipped with a reference for what functional surface changes can look like, we characterized a series of genomic variants identified using high-throughput sequencing of patients, undiagnosed at the time of sequencing, but through our collaborative functional genomic studies [10] found to likely having damaging variants causing rare genetic diseases, and pathogenic controls in the same proteins. We used computational mutagenesis for each variant and scored their corresponding changes to protein surfaces using static models of each protein. Finally, we used physics-based simulations to model the protein dynamic ensembles and compared the results using these two levels of detail of the protein surface. Our data demonstrate that greater sensitivity is gained by including protein dynamics. Thus, we conclude that it is possible to standardize a process for scoring genomic mutations using protein surface-based scores, adding a new dimension to the interpretation of human genetic variation.
2. Results
We applied our approach to scoring protein surface changes to a collection of genomic variants, selected to span positive examples with existing functional validation and disease association and those currently uninterpreted (Figure 1). Below, we summarize our findings from assessing 14 proteins. We demonstrate how global and local changes occur for eight proteins with different physiologic operating temperatures, four proteins with solubilizing mutations (Granzyme H and IGF1R), and four proteins harboring 43 genomic mutations. As our goal is to demonstrate the feasibility of standardizing a protein surface-based approach to scoring the effects of genomic mutations, we chose the four proteins to represent different functions: the complex adaptor protein, TBL1XR1; dimeric potassium ion channel, KCNK9; membrane-bound receptor, PIK3R1; and the soluble enzyme uroporphyrinogen decarboxylase, UROD.
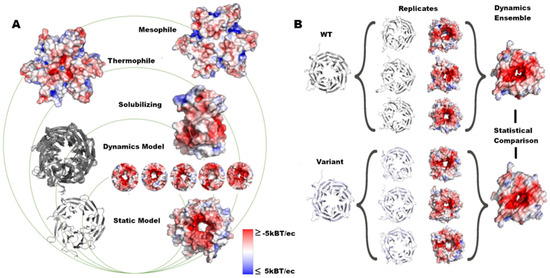
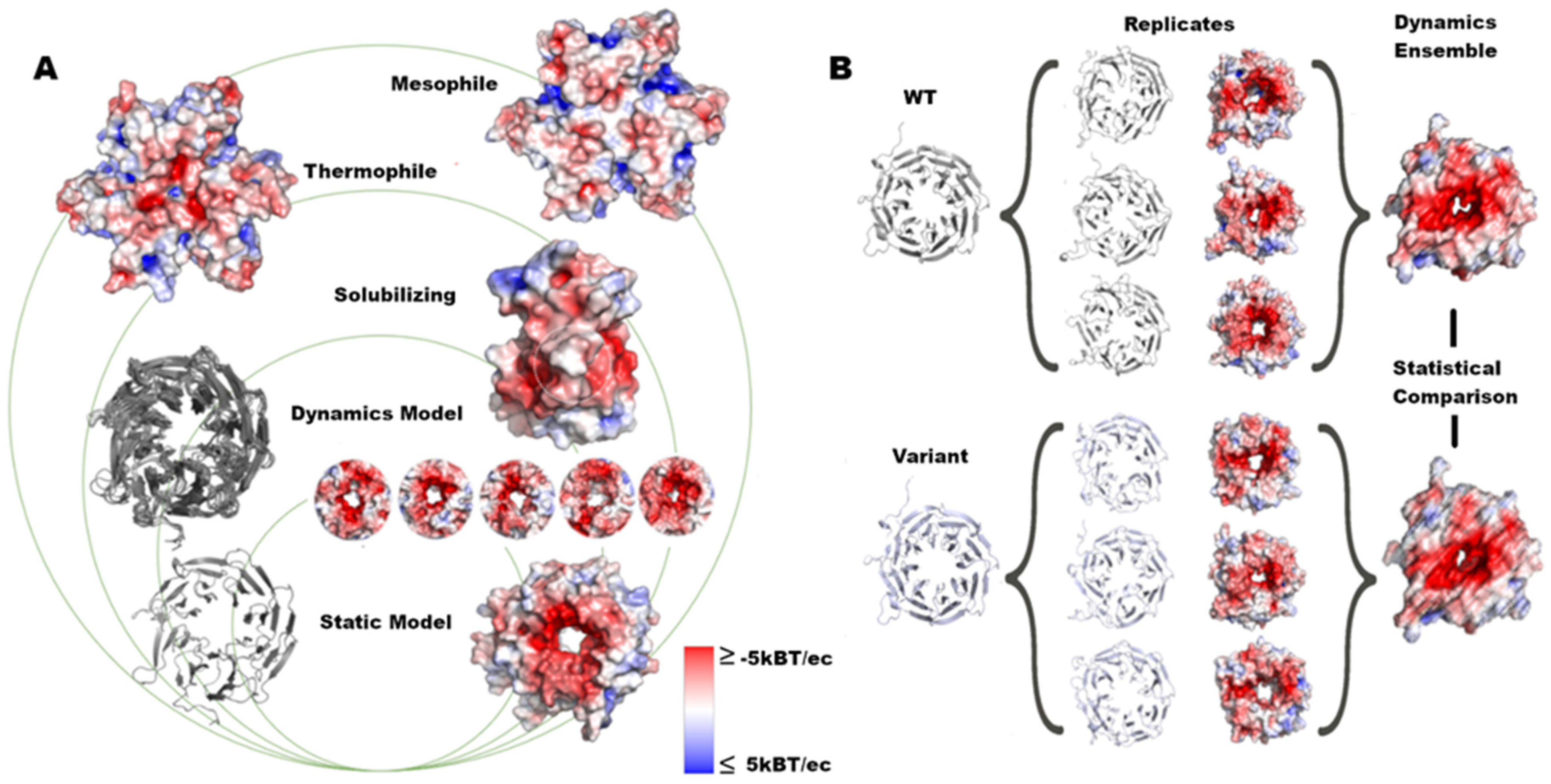
Figure 1.
Assessment of structure and dynamics of protein surfaces. (A) In this work, we analyzed the surface changes of proteins with groups ranging from global to local changes caused by variants. (B) We ran MD simulations in triplicate, calculated the electrostatic potential for each replicate, and measured the difference in the dynamic ensemble for each structure.
2.1. Thermophilic and Mesophilic Enzymes Demonstrate Clear Surface Differences
The evaluation of surface potential distributions showed that all thermophilic and mesophilic proteins differed significantly (pAD < 0.01) (Figure 2, Table 1), supporting the feasibility of our hypothesis that differences in protein surfaces can be evaluated in a standardized way. Compared to its mesophilic ortholog, acyl phosphatase demonstrated a shift toward electropositive (Figure 2A–C), a pAD of 1.06 × 10−7 (Table 1), while adenylate kinase showed a strong electronegative shift (Figure 2D–F), with a pAD of 1.80 × 10−51 (Table 1). Malate dehydrogenase has four published structures along the mesophilic to thermophilic adaptation spectrum. They show an electronegative peak congruent with the host organism’s temperature adaptation (Figure 2G–K). Thus, protein surface properties can be sensitive to temperature adaptation and support our central premise that they could be used to score genomic mutations.

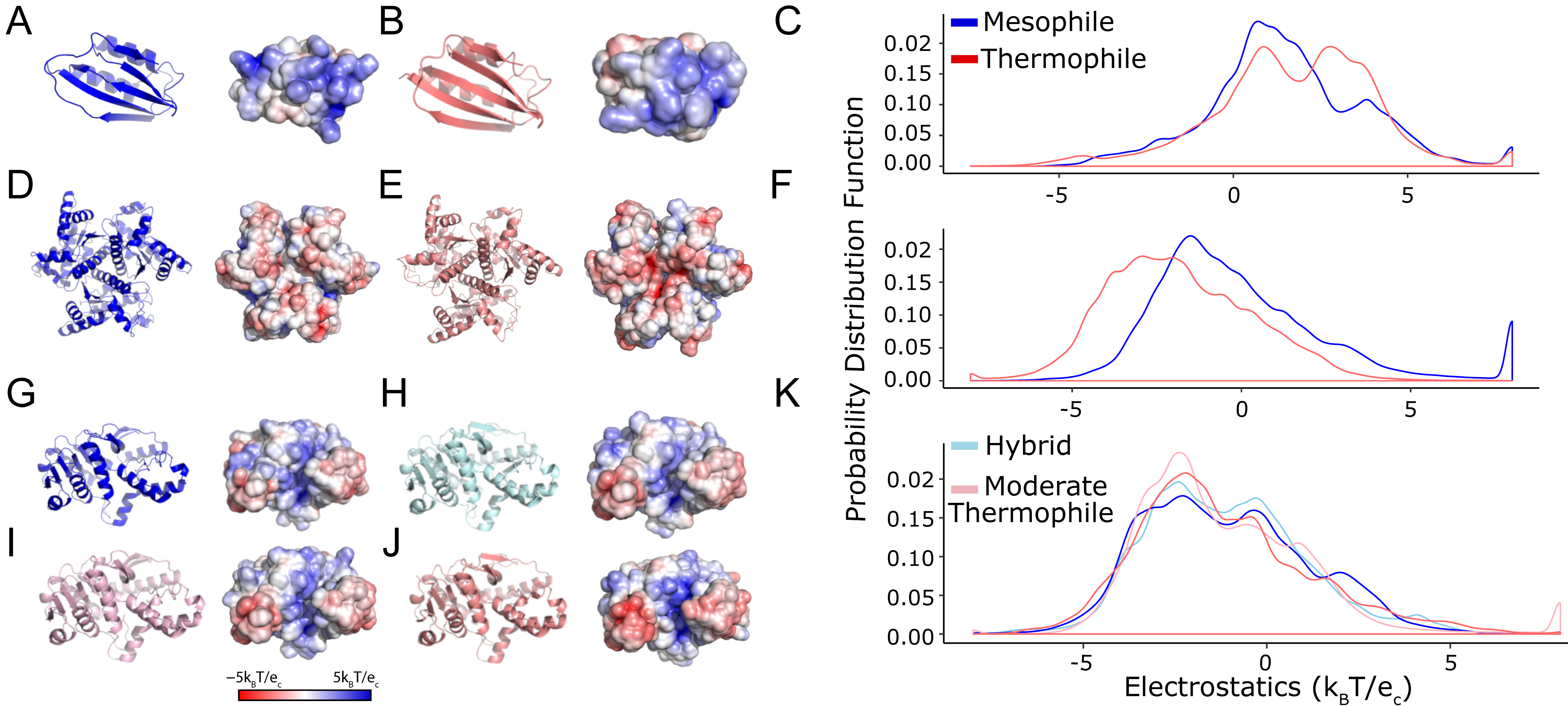
Figure 2.
Thermophilic and mesophilic enzymes demonstrate significant shifts in surface electrostatics. We consider these comparisons as a baseline for defining a considerable change in protein surface electrostatics. We compared 3D models and surface representations for three (A,D,G) mesophilic enzymes (blue), their (B,E,J) thermophilic orthologs (salmon), and their (C,F,K) electrostatic potential probability distributions. These three enzymes are (A–C), acyl phosphatase, (D–F) adenylate kinase, and (G–K) malate dehydrogenase. Malate dehydrogenase has hybrid and moderate thermophile structures that show small changes intermediate between the mesophile and thermophile. Protein cartoon surface representations are as in Figure 1.

Table 1.
Surface-based comparison of mesophilic and thermophilic enzymes.
We hypothesized that different statistical tests can be parameterized to reasonably assess the observed differences in protein surfaces. However, even for these positive-control cases, the conclusions depended on the type of statistical test used (Table 1). For example, t-tests could only distinguish between forms of adenylate kinase but not acyl phosphatase or malate dehydrogenase. The KS test could distinguish among acyl phosphatase forms but not for the other two proteins. Finally, the AD test distinguished among forms of all three proteins. Because the AD and KS tests consider differences in the shape of the surface potential distribution rather than mean differences, they are more able to identify the visually apparent patterns (Figure 2). The AD test leverages data from the tails of the empirical probability distribution of each dataset, which in this study is the distribution of electrostatic potential values at the molecular surface and is, therefore, a more robust test for quantifying the patterns that are visually apparent and described above. Thus, comparing mesophilic and thermophilic enzymes indicates that a resampling-based procedure using the AD test is the most promising for evaluating surface potential changes.
2.2. Solubilizing Protein Variants Have Significant Local Changes
We next assessed a group of positive control missense variants that have been experimentally characterized and increased protein solubility. They are thus the same type of change that we seek to score, genomic variants, but with a biochemically established effect.
Only minor differences at the mutation site were observed when we assessed the entire protein surface. Therefore, we assessed if the variation was significant at the local electrostatic potential changes caused by the variant. The global surface potential distribution (Figure 3) for Granzyme H and IGF1R are statistically significant with pAD of 6.22 × 10−10 and 8.16 × 10−10, respectively (Table 2). The local surface potential shows the solubilizing variants alter surface properties, in some instances shifting toward a hydrophilic surface in Granzyme H (Figure 3A,B) or neutral in IGF1R (Figure 3D–F), both of which have an extremely small pAD (Table 2), demonstrating the statistical significance of the protein’s surface charge distribution changes upon mutation. The change in surface potential could explain the improved resolution of crystal structure for Granzyme H from 3.0 Å [11] to 2.2 Å [12] and IGF1R from 2.7 Å [13] to 1.5 Å [14]. All three statistical tests give a significant p-value for local changes caused by the genetically engineered solubilizing mutations. We investigated an additional mutation in UROD, D306Y, which has been reported to affect its solubility [15]. The local electrostatic difference in the static WT and D306Y is distinguishable (pAD = 6.28 × 10−19; Table 2) and can help us possibly predict the reason for the variant to be insoluble. Therefore, the permutation-based AD test is also sensitive enough to identify the positive control mutations (Granzyme H and IGF1R) as significant alterations to protein surface properties and helped us evaluate the insoluble genetic mutation in UROD.

Figure 3.
Mutations that increase protein solubility induce significant local changes in electrostatic potential. (A,D) Wild-type crystal structure with the electrostatic surface shown and zoomed to show the local distribution of charges. (B,E) 3D structure with the variant shown as sticks in orange followed by the surface showing the change in the local surface compared to the WT. (C,F) The electrostatic potential distribution shows a significant change between the WT and structure with the variant. Colors are as in Figure 2.
Table 2.
Surface-based comparison of solubilizing variants.
2.3. Dynamic Ensembles Provide More Explicit Mechanistic Interpretation than Static Structures
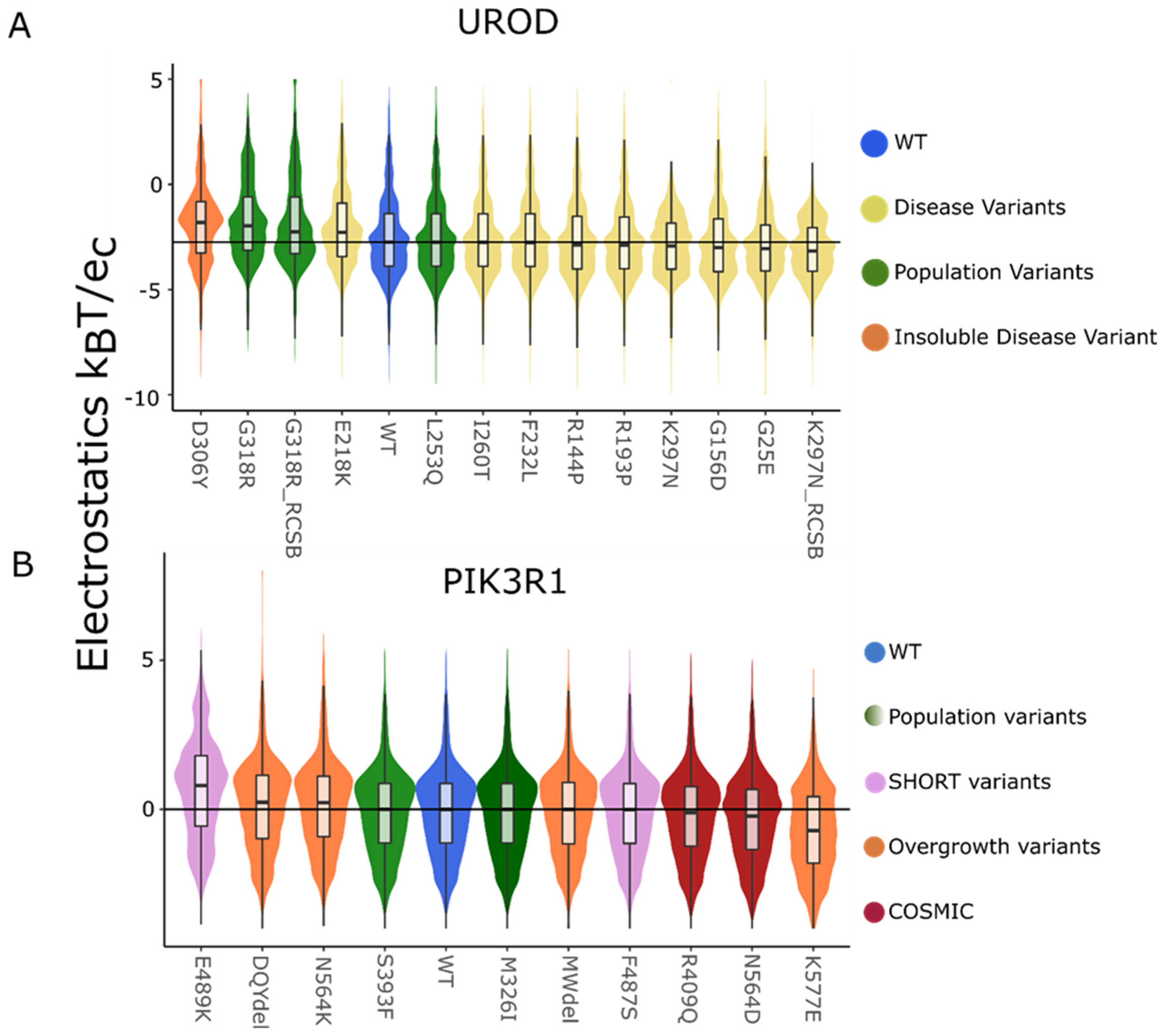
Equipped with the benchmarks above for positive controls, we now assessed the static structure and their corresponding dynamic ensembles (Figure 1) for interpreting the effects of missense genetic variation. When assessed globally, static structures show a very small to no difference in the local electrostatic distribution between WT and variants. Of variants, 53% have statistically significant surface charge distribution changes under the AD test for the static structures. UROD (Figure 4A) and PIK3R1 (Figure 4B) local surface changes showed that when the variant was a charged amino acid or changed from a charged to a neutral amino acid, the potential changes are significant (pAD < 0.01, with a single exception) compared to the WT (Table 3).

Figure 4.
Static local surface potential shows a nuanced change in the variants when compared to the WT. The local surface potential displayed as a violin plot for the static structures of (A) UROD and (B) PIK3R1 show small to no difference in the distribution and median with the exception of charged variants.
Table 3.
Local surface-based comparison of missense genetic variants using static structures.
Static structures capture the nuanced changes observed in the local surface potential. The TBL1XR1 and KCNK9 static median potential change from the median WT were compared to the dynamic median potential change from the median WT (Figure 5 and Figure 6). The pAD was again consistently discriminating significant changes, and to a much greater effect when a dynamics ensemble was used (Table 4). In the case of KCNK9, the average local surface potential shifts for static structures were 0.41 kBT/ec with an average pAD of 1 × 10−2, and the average local surface potential shifts for static structures of TBL1XR1 were 0.43 kBT/ec with an average pAD 1 × 10−4. Thus, modeling protein flexibility and the mutation-specific conformational adjustments improved the ability to determine differences statistically.
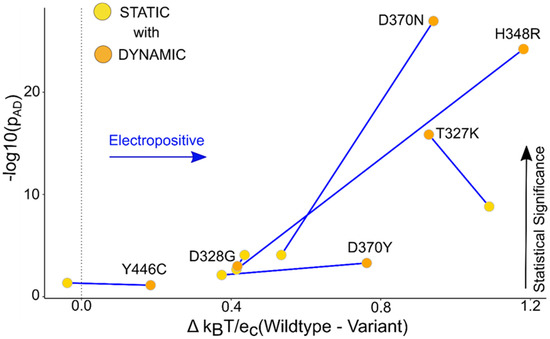
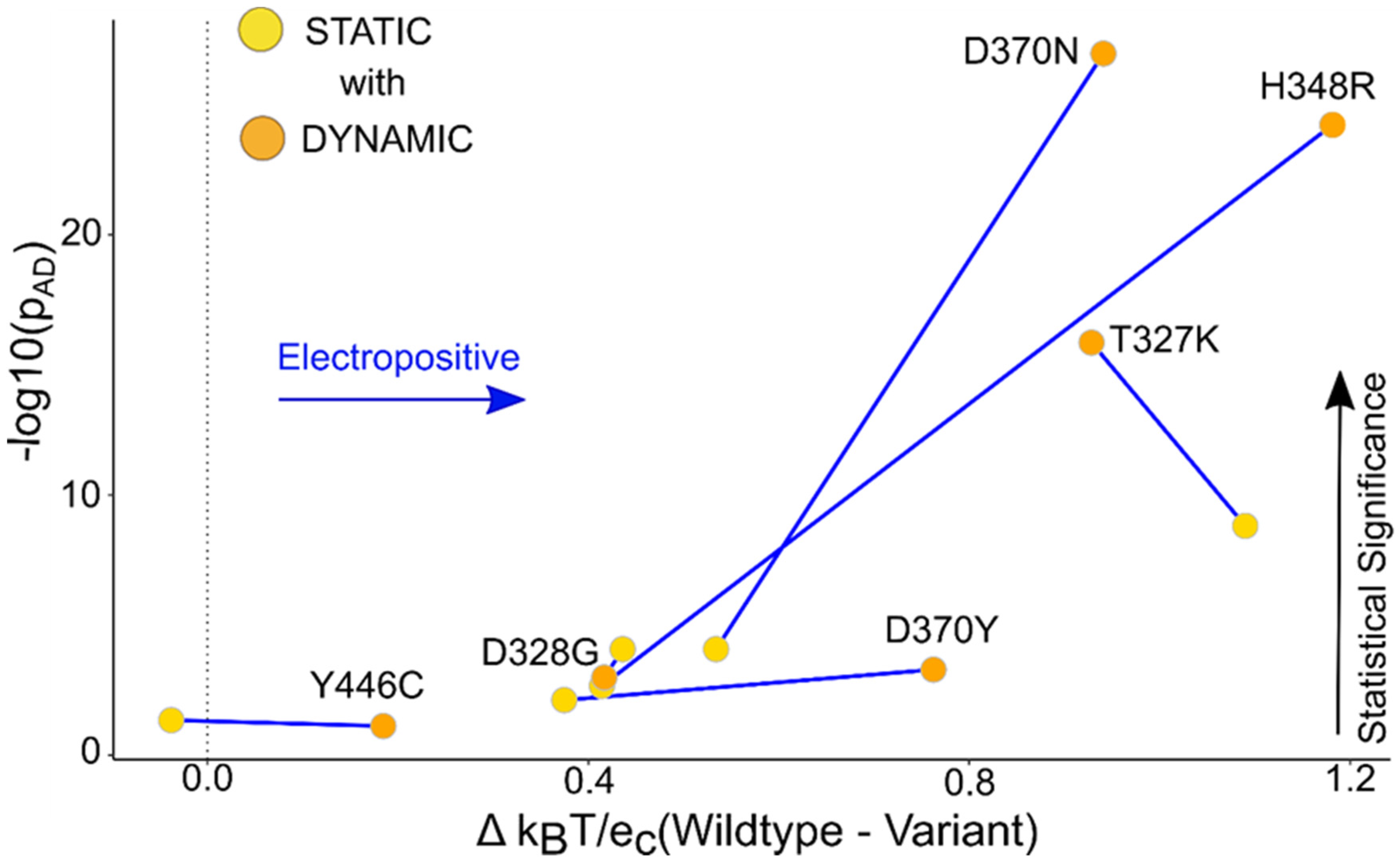
Figure 5.
TBL1XR1 dynamic ensemble helps show a distinguishable change in the surface potential compared to the static data. The graph of the median potential difference between the WT and the variant versus the p-value obtained from the AD test for the static and dynamic ensemble shows that the local surface potential for the ensemble was statistically more significant compared to the static structures. The labels in the graph are assigned to the dynamic points, and the connecting lines show the change in the p-value of static versus dynamic.

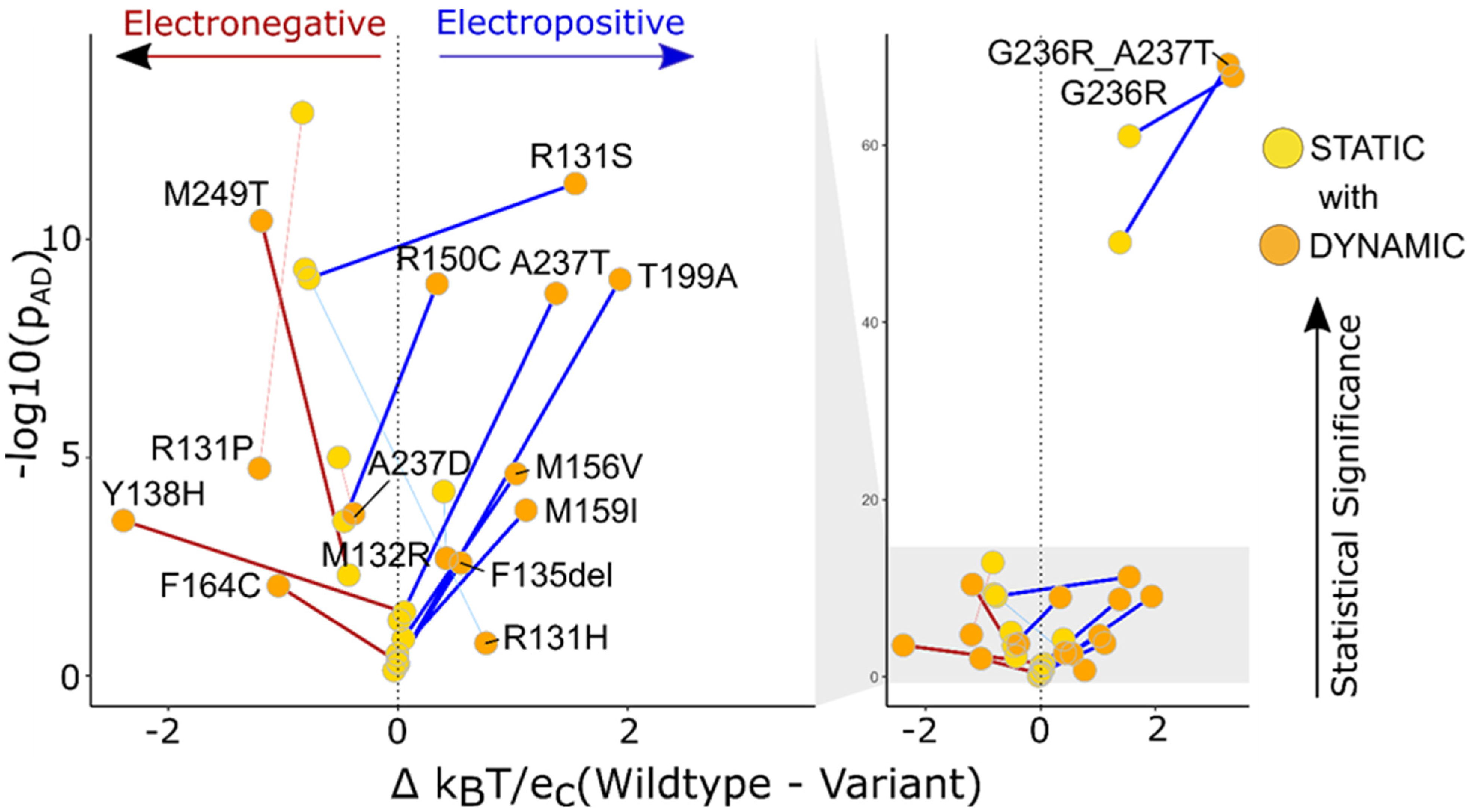
Figure 6.
We evaluated 12 KCNK9 variants using static structures and dynamic ensembles and demonstrate that the latter show more significant changes to local surface potentials. The graph represents the distinguishable change in the p-value from low to high (static to dynamic) for 12 variants and 4 variants change from a high p-value to low. The thicker lines connecting the static and dynamic variants show the p-value is more significant for the dynamic ensembles. The thinner lines are the 4 variants that had greater statistical significance in static structures than dynamic ensembles. Gray shading links the abscissa to zoom in on the region encompassing most of the genetic variants.
Table 4.
Local surface-based comparison of missense genetic variants using static structures and dynamic ensembles.
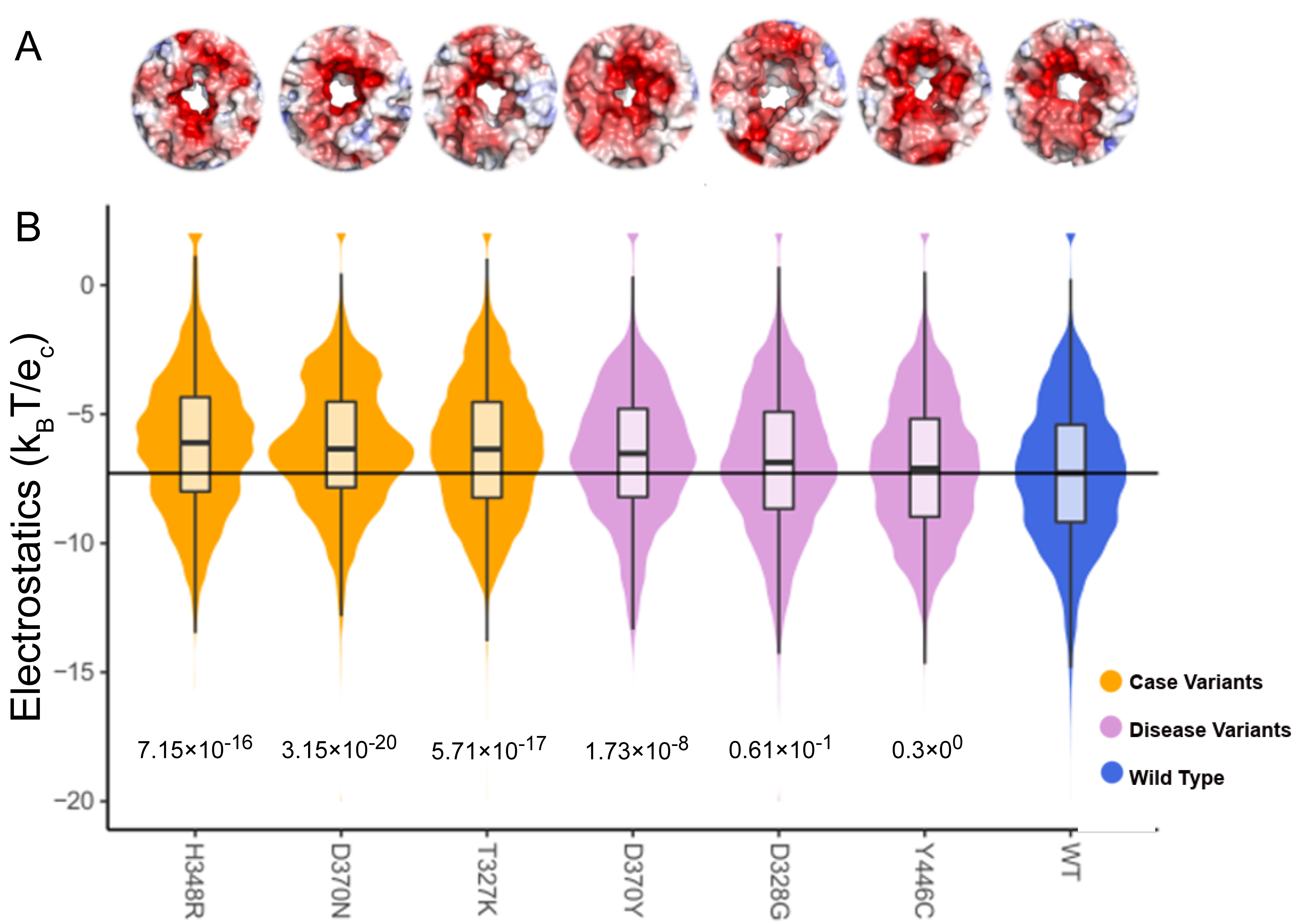
Dynamic ensembles help us have a better interpretation of the surface potential data. The local electrostatic potential of the structures obtained from the simulations shows the change compared to the WT in either a positive or negative direction. For TBL1XR1 (Figure 7B), we see that four out of six variants are more electropositive with a pAD < 0.01, thus possibly causing downstream binding effects for the variants [16]. We also see the difference in surface potential compared to the WT (Figure 7A).

Figure 7.
Electrostatic potential for each TBL1XR1 variant dynamic ensemble shows the change in the distribution and median when compared to the WT ensemble. (A) We show the electrostatic representation of the binding interface of TBL1XR1 with surface color representing electrostatic potential as in previous figures. (B) We observe the distribution and median of the local surface potential distribution shifts significantly for all three case variants and one additional disease variant (D370Y) as compared to the WT. The variants shift the potential toward the positive direction.
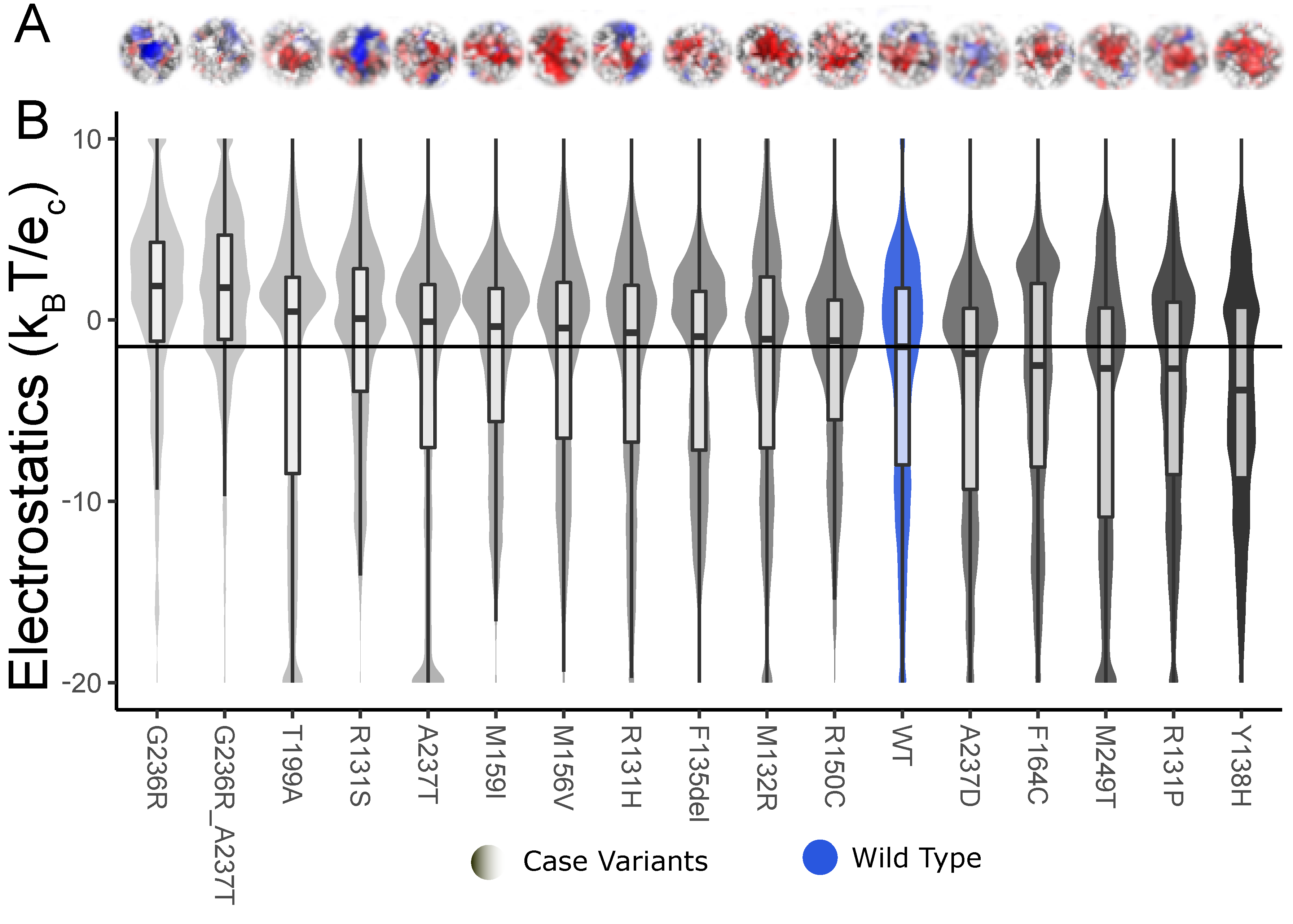
KCNK9 is a membrane-bound protein channel with a more electronegative surface (WT) for the ions to pass. We see the variants change the surface to either more electronegative or more electropositive (Figure 8). The electrostatic surface representation in Figure 7 and Figure 8 can also be used to compare the differences between the variant and the WT. The representation shows if the surface has moved. In this study, we have only looked at the electrostatic potential; we believe that the protein’s shape also plays a role, especially in protein channels like KCNK9.

Figure 8.
Shift in median surface potential for KCNK9 in both the electropositive and electronegative direction as compared to the WT. (A) We show the electrostatic potential distribution of the pore of the KCNK9 membrane protein with surface color representing electrostatic potential as in previous figures. (B) The variants move the potential in both directions compared to the WT. The shape fill color is based on the median values ranging from light gray for more electropositive to dark gray for more electronegative, and boxplots overlaid.
Scoring dynamic ensembles yielded more information with an average potential shift of 1.15 kBT/ec and an average pAD of 1 × 10−5; as for the TBL1XR1 dynamics ensemble, the average local surface potential shift was 0.85 kBT/ec with an average pAD of 1 × 10−10. Also, when we look at the statistical significance for TBL1XR1 and KCNK9, we see that 50% of the variants show significant p-values as a static structure. Still, we get about 86% of variants showing significant p-values using dynamics. This shows the dynamic ensemble data helps give a better idea about the local surface potential changes in cases where the static structures show a nuanced change.
3. Discussion
In this study, we appropriately selected proteins and human genetic variants to test a method for grouping genomic variants based on their electrostatic potential distributions. We started with establishing differences of electrostatic distribution among thermophilic and mesophilic orthologs and solubilizing mutations. Finally, we showed clear differences between WT and pathogenic variants in our cohort, using genes that encode proteins with established protein complexation or substrate interaction surfaces. By proper selection of positive controls and the development of a resampling-based statistical approach, we have demonstrated that an objective and standardizable algorithm for assessing meaningful changes in protein electrostatic surface properties can be made. We successfully applied the method to classify variants based on how their mutations alter protein surface potentials. We present our approach, which defines a region of interest—either specific to the mutated site or a particular active site—and monitors how that region of interest is altered directly by the mutation or, with the introduction of dynamic simulation data, indirectly through repacking of the protein fold or allosteric transmission from the mutated site. We found that the dynamics approach enabled a more straightforward conclusion than the static structure alone. Changes to the protein surface properties were typically stronger and more statistically significant after accounting for protein dynamics. This type of mechanistic data is not currently predictable from genomic or protein sequences, and we believe it represents a new type of data that can be brought forth for informing the field of genomic data interpretation.
Because protein surfaces are dynamic and influenced by intrinsic and extrinsic factors, it is essential to point out that our goal is to interpret the mechanistic effect of a missense variant, not to identify the quantitative biophysical differences the variant will have in any particular physiologic setting. The latter would require accounting for many extrinsic factors, while we aim for the former, requiring primarily intrinsic factors informed by experimental data. We believe that the process we describe herein can be generalized to the assessment of many types of proteins. We assessed soluble and membrane-bound proteins, characterizing either the effect at the mutated, enzymatic, or functional sites, demonstrating the generalizability of such an approach. Further, surface-based scores can be tailored to account for extrinsic factors that could modulate the effect of a mutated protein in different environments or under other physiologic conditions. Surface-based scores can likely identify significant changes to interfaces and binding sites, without explicitly identifying the molecule(s) that bind. This is an enabling approach for protein science to improve genomic data interpretation.
Given the method’s generalizability, it can likely be applied to enzymes, receptors, ion channels, and structural proteins. Our examples span soluble and membrane-bound proteins, suggesting the model could work across diverse protein types. This generalization can further extend to proteins involved in drug binding, cell signaling, or structural integrity, among others.
Such a method has the potential to be incorporated into pipelines for interpreting VUS in research or clinical genomics and significantly enhance variant classification. Recent advancements in AI-based tools, such as AlphaFold [17] for structure prediction and generative AI [18] for protein dynamics, can be harnessed to automate steps of the process for any protein variant. By integrating these AI tools, we can predict conformational changes and surface electrostatic shifts across a broader range of proteins, allowing for high-throughput and precise analysis of VUS. This would streamline the assessment of potential pathogenicity, offering researchers and clinicians valuable insights into the functional impact of VUS without requiring experimental structures for each target. Such an approach could be integrated into existing clinical pipelines, providing an efficient, scalable solution for VUS interpretation, enabling faster decision-making, and improving personalized medicine strategies. However, not all regions of all proteins are modellable using current AI-based tools. Additionally, the location of a change is typically more important for interpreting its mechanistic effect than any numeric score’s value. For instance, if an experimental structure was solved for a monomer, but the mutation has an effect on a heterodimer, it will be more challenging to interpret the numeric scores. Interestingly, a surface-based score may still show a change to a distinctive surface property, even for a monomer. Finally, setting up and interpreting MD simulations remains a relatively specialized skill. Therefore, the appropriate expertise to evaluate three-dimensional protein models with an understanding of protein structure–function relationships, is necessary and highly recommended to optimally apply structural bioinformatics to human genomics.
The data presented in this study indicates an objective assessment of the significance of protein surface changes can be made. Determining an appropriate statistic is important for the new approach. We have shown that standard statistical tests have markedly different performances on protein surface electrostatic potential data. We observed that the change in the peak of the electrostatic potential distribution significantly changes the area under the distribution tails, making the Anderson–Darling test a better indicator of the distribution change compared to the other two statistical tests that we considered. We believe that combining permutation-based resampling and the Anderson–Darling test balances sensitivity and false discovery. Further, we believe that changes to protein surface properties could reach standardization, befitting use as supportive criteria in the guidelines for interpreting genomic variations. Further, while assessing the surface potential, we found that statistical tests were more sensitive when applied to regions of the protein centered on the altered site rather than when evaluating the entire protein surface. Our future work on protein surface scoring will consider shape-based metrics as well as benchmarking against standardized datasets for protein interactions and broader sets of human disease variation, including from cancer.
4. Materials and Methods
4.1. Aggregating Genomic Variants
We initiated the current study through collaborative work in rare and undiagnosed diseases, where patient cohorts were accrued based on common phenotypes and variants of uncertain significance (VUS) within genes plausible for causing the phenotype. The cohort studied are TBL1XR1 [19], KCNK9 [20], and PIK3R1 [21]. To gather additional genomic variants in the same genes, we used BioR [22] and custom scripts to map them onto 3D protein structures. Variants were obtained from GnomAD [10], HGMD [23], ClinVar [24], and COSMIC [25].
The cohort under study is clinically significant and their proper functioning is crucial for the normal function of human cells. Our case examples include (a) TBL1XR1 (Transducin Beta-Like 1X-Related Protein 1) is part of the nuclear receptor corepressor (NCoR) complex and plays a role in transcriptional regulation, particularly in gene silencing. Mutations in TBL1XR1 are associated with cancer, including lymphomas and other malignancies, by disrupting pathways involved in cell growth and differentiation [19,26], (b) KCNK9 (Potassium Channel Subfamily K Member 9) is a potassium ion channel that regulates membrane potential and neuronal excitability. Mutations in KCNK9 are linked to imprinting syndrome and neurological disorders, including mental retardation, hypotonia, and motor impairments [20], and (c) PIK3R1 (Phosphoinositide 3-Kinase Regulatory Subunit 1) is part of the PI3K signaling pathway, which is involved in cell growth, proliferation, and survival. Mutations in PIK3R1 are associated with overgrowth syndromes, vascular malformations, and various cancers [21]. This study focused on surface potential shifts in TBL1XR1, KCNK9, and PIK3R1 variants for substantiating a novel metric for differentiation among WT and pathogenic variants and further utilizing these metrics for reclassifying VUS in these proteins.
4.2. Experimental Structures of Wild-Type and Genomic Mutations
We selected four groups for comparison (Figure 1). First, thermophilic and mesophilic pairs and solubilizing mutations were used as two types of positive controls to parametrize the statistical tests described below. Then, we selected 3D static structures of disease-associated genomic variants as a third group. Our fourth group consisted of the same set of mutations but with the additional data of protein dynamic ensemble.
When extant, we used experimental structures for each protein obtained from the Protein Data Bank (PDB) [27]. Table 1 contains the PDB IDs of the thermophiles and mesophiles used for this study. Table 2 provides PDB IDs for proteins and genetically engineered point mutations that showed a substantial change in solubility, likely caused by changing surface properties. Table 3 and Table 4 have the PDB IDs for the WT structures of the proteins and two genetically engineered mutations, G318R and K297N [15], in UROD (3gvq). Experimentally solved structures existed for Wild Type (WT) TBL1XR1 (4lg9) [28] and IGF1R (1m7n [13]), so we used homology-based methods to fill in the loops that were not resolved [29,30]. We used I-Tasser [31] to generate the model for KCNK9 from human KCNK1 (3ukm [32]) and KCNK4 (3um7 [33]), as experimental structures did not exist. PIK3R1 was modeled using PIK3CD (5itd [34]). In silico mutagenesis was performed using FoldX version 4.0 [35] to generate initial 3D models of genomic variants.
When experimental structures for point mutations existed, we compared them to investigate the use of homology-based methods for interpreting the effect of the same genomic variants.
4.3. Molecular Dynamics Simulation Used to Generate Protein Structure Ensembles
Generalized Born implicit solvent molecular dynamics (MD) simulations were carried out for soluble proteins using NAMD [36] and the CHARMM36 [37] force field, following a similar procedure as previously described [38,39]. Models for TBL1XR1 and KCNK9, WT, and each genomic variant were used as input to MD simulations. Each model was used to generate three replicates, and each replicate was independently energy minimized for 10,000 steps and heated to 300K over 300 ps using a Langevin thermostat. A further 10 ns of simulation trajectory was generated, and all trajectories were first aligned to the initial WT conformation using Cα atoms. Frames were extracted from the final ¼th of each simulation as representatives of the dynamic ensemble and used in further analysis.
For the membrane-embedded protein KCNK9, we modeled the explicit environment using the Membrane builder in charmm-gui [40] and ran explicit solvent MD simulations in NAMD [36] and CHARMM27 forcefield [41]. We followed a similar procedure while maintaining a constant total membrane area and system density by equilibrating in NPT before production simulations in NVT.
4.4. Generating Protein Surface and Local Electrostatic Scores
We used EDTsurf [42] to generate protein molecular surfaces using the Vertex-Connected Marching Cubes (VCMC) algorithm and the Molecular Surface (MS) parameter. We calculated the electrostatic potential for the structures using APBS [43] and PDB2PQR [44,45]. The electrostatic distribution data were mapped to the molecular surface from EDTSurf to obtain the surface potential values. These values were used to compute and visualize the differences between the variants and the WT. We used the whole protein surface to compare thermophilic and mesophilic proteins. Structures with variants had their surface character focused on a region surrounding the variant of interest. The local surface selection was used to obtain the tessellations from EDTsurf using any amino acids within a minimum pairwise distance of 4 Å (Figure S1). We then calculated the electrostatic potential values at this subset of surface points. To assess protein dynamic ensembles, the same procedure was followed for each representative frame (also referred to as a conformer), with pairwise interactions calculated for each representative and the combined values from across time used to compare the WT to mutations.
4.5. Statistical Assessment of Altered Surface Potentials
We assessed changes in the electrostatic distribution using a resampling-based approach wherein we randomly selected 100 data points from each dataset, compared them using one of three statistical tests, and performed 1000 resampling iterations. A resampling approach is necessary for a robust approach because otherwise any surface change could be made to appear more significant by increasing the number of points used to measure the surface electrostatic potential, or the time density from dynamics. We used three tests—the t-test, Kolmogorov–Smirnov (KS), and Anderson–Darling (AD)—chosen because their statistics are based on the differences of means, maximum difference in empirical cumulative distribution, and differences among the tails of the empirical cumulative distribution, respectively. The p-values for the t-test, KS, and AD tests are abbreviated as pT, pKS, and pAD, respectively. The p-values obtained from these tests were compared to determine if a small change in distributions, such as for genomic mutations, would be considered significant. We used p < 0.01 as a threshold to evaluate our data. An analogous process was used for comparing dynamic ensemble representations of the protein surface, wherein resampling was performed across data from all conformers.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/ijms252212018/s1.
Author Contributions
Conceptualization, M.T.Z.; methodology, N.R.D. and M.T.Z.; formal analysis, N.R.D., N.H. and S.T.; resources, M.T.Z.; data curation, all authors; writing—original draft preparation, N.R.D. and M.T.Z.; writing—review and editing, all authors; visualization, N.R.D. and S.T.; supervision, M.T.Z.; project administration, M.T.Z.; funding acquisition, M.T.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was completed in part with computational resources and technical support provided by the Research Computing Center at the Medical College of Wisconsin. This publication was supported in part by The Linda T. and John A. Mellowes Endowed Innovation and Discovery Fund and the Genomic Sciences and Precision Medicine Center of the Medical College of Wisconsin.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are primarily made available through this publication and our cited previous works describing the clinical cohorts for novel genetic variants evaluated herein.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Norgeot, B.; Glicksberg, B.S.; Butte, A.J. A call for deep-learning healthcare. Nat. Med. 2019, 25, 14–15. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Rivera-Munoz, E.A.; Milko, L.V.; Harrison, S.M.; Azzariti, D.R.; Kurtz, C.L.; Lee, K.; Mester, J.L.; Weaver, M.A.; Currey, E.; Craigen, W.; et al. ClinGen Variant Curation Expert Panel experiences and standardized processes for disease and gene-level specification of the ACMG/AMP guidelines for sequence variant interpretation. Hum. Mutat. 2018, 39, 1614–1622. [Google Scholar] [CrossRef]
- Hu, Z.; Yu, C.; Furutsuki, M.; Andreoletti, G.; Ly, M.; Hoskins, R.; Adhikari, A.N.; Brenner, S.E. VIPdb, a genetic Variant Impact Predictor Database. Hum. Mutat. 2019, 40, 1202–1214. [Google Scholar] [CrossRef]
- Bean, L.J.H.; Hegde, M.R. Clinical implications and considerations for evaluation of in silico algorithms for use with ACMG/AMP clinical variant interpretation guidelines. Genome Med. 2017, 9, 111. [Google Scholar] [CrossRef]
- Richards, S.; Aziz, N.; Bale, S.; Bick, D.; Das, S.; Gastier-Foster, J.; Grody, W.W.; Hegde, M.; Lyon, E.; Spector, E.; et al. Standards and guidelines for the interpretation of sequence variants: A joint consensus recommendation of the American College of Medical Genetics and Genomics and the Association for Molecular Pathology. Genet. Med. 2015, 17, 405–424. [Google Scholar] [CrossRef] [PubMed]
- Madhavan, S.; Ritter, D.; Micheel, C.; Rao, S.; Roy, A.; Sonkin, D.; McCoy, M.; Griffith, M.; Griffith, O.L.; McGarvey, P.; et al. ClinGen Cancer Somatic Working Group—Standardizing and democratizing access to cancer molecular diagnostic data to drive translational research. Pac. Symp. Biocomput. 2018, 23, 247–258. [Google Scholar]
- Careri, G. Cooperative charge fluctuations by migrating protons in globular proteins. Prog. Biophys. Mol. Biol. 1998, 70, 223–249. [Google Scholar] [CrossRef]
- Martin, A.; Sieber, V.; Schmid, F.X. In-vitro selection of highly stabilized protein variants with optimized surface. J. Mol. Biol. 2001, 309, 717–726. [Google Scholar] [CrossRef]
- Karczewski, K.J.; Francioli, L.C.; Tiao, G.; Cummings, B.B.; Alfoldi, J.; Wang, Q.; Collins, R.L.; Laricchia, K.M.; Ganna, A.; Birnbaum, D.P.; et al. The mutational constraint spectrum quantified from variation in 141,456 humans. Nature 2020, 581, 434–443. [Google Scholar] [CrossRef]
- Wang, L.; Li, Q.; Wu, L.; Liu, S.; Zhang, Y.; Yang, X.; Zhu, P.; Zhang, H.; Zhang, K.; Lou, J.; et al. Identification of SERPINB1 as a physiological inhibitor of human granzyme H. J. Immunol. 2013, 190, 1319–1330. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Zhang, K.; Wu, L.; Liu, S.; Zhang, H.; Zhou, Q.; Tong, L.; Sun, F.; Fan, Z. Structural insights into the substrate specificity of human granzyme H: The functional roles of a novel RKR motif. J. Immunol. 2012, 188, 765–773. [Google Scholar] [CrossRef] [PubMed]
- Munshi, S.; Kornienko, M.; Hall, D.L.; Reid, J.C.; Waxman, L.; Stirdivant, S.M.; Darke, P.L.; Kuo, L.C. Crystal structure of the Apo, unactivated insulin-like growth factor-1 receptor kinase. Implication for inhibitor specificity. J. Biol. Chem. 2002, 277, 38797–38802. [Google Scholar] [CrossRef] [PubMed]
- Munshi, S.; Hall, D.L.; Kornienko, M.; Darke, P.L.; Kuo, L.C. Structure of apo, unactivated insulin-like growth factor-1 receptor kinase at 1.5 A resolution. Acta Crystallogr. D Biol. Crystallogr. 2003, 59 Pt 10, 1725–1730. [Google Scholar] [CrossRef] [PubMed]
- Warby, C.A.; Phillips, J.D.; Bergonia, H.A.; Whitby, F.G.; Hill, C.P.; Kushner, J.P. Structural and kinetic characterization of mutant human uroporphyrinogen decarboxylases. Cell. Mol. Biol. 2009, 55, 40–45. [Google Scholar]
- Venturutti, L.; Teater, M.; Zhai, A.; Chadburn, A.; Babiker, L.; Kim, D.; Béguelin, W.; Lee, T.C.; Kim, Y.; Chin, C.R.; et al. TBL1XR1 Mutations Drive Extranodal Lymphoma by Inducing a Pro-tumorigenic Memory Fate. Cell 2020, 182, 297–316.e27. [Google Scholar] [CrossRef]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A. Highly accurate protein structure prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Liao, W.; Lu, X.; Fei, Y.; Gu, Y.; Huang, Y. Generative AI design for building structures. Autom. Constr. 2024, 157, 105187. [Google Scholar] [CrossRef]
- McCarrier JAH, D.C.; Kappes, U.; Basel, D.B.; Dsouza, N.R.; Zimmermann, M.T.; Hagelstrom, R.T. Expanding the Phenotypic Spectrum of Pierpont Syndrome—Four Patients from One Institution. In Proceedings of the ACMG Meeting 2018, Charlotte, NC, USA, 10–14 April 2018. [Google Scholar]
- Cousin, M.A.; Veale, E.L.; Dsouza, N.R.; Tripathi, S.; Holden, R.G.; Arelin, M.; Beek, G.; Bekheirnia, M.R.; Beygo, J.; Bhambhani, V.; et al. Gain and loss of TASK3 channel function and its regulation by novel variation cause KCNK9 imprinting syndrome. Genome Med. 2022, 14, 62. [Google Scholar] [CrossRef]
- Cottrell, C.E.; Bender, N.R.; Zimmermann, M.T.; Heusel, J.W.; Corliss, M.; Evenson, M.J.; Magrini, V.; Corsmeier, D.J.; Avenarius, M.; Dudley, J.N.; et al. Somatic PIK3R1 variation as a cause of vascular malformations and overgrowth. Genet. Med. 2021, 23, 1882–1888. [Google Scholar] [CrossRef]
- Kocher, J.P.; Quest, D.J.; Duffy, P.; Meiners, M.A.; Moore, R.M.; Rider, D.; Hossain, A.; Hart, S.N.; Dinu, V. The Biological Reference Repository (BioR): A rapid and flexible system for genomics annotation. Bioinformatics 2014, 30, 1920–1922. [Google Scholar] [CrossRef] [PubMed]
- Stenson, P.D.; Mort, M.; Ball, E.V.; Howells, K.; Phillips, A.D.; Thomas, N.S.; Cooper, D.N. The Human Gene Mutation Database: 2008 update. Genome Med. 2009, 1, 13. [Google Scholar] [CrossRef] [PubMed]
- Landrum, M.J.; Lee, J.M.; Riley, G.R.; Jang, W.; Rubinstein, W.S.; Church, D.M.; Maglott, D.R. ClinVar: Public archive of relationships among sequence variation and human phenotype. Nucleic Acids Res. 2014, 42, D980–D985. [Google Scholar] [CrossRef] [PubMed]
- Forbes, S.A.; Bhamra, G.; Bamford, S.; Dawson, E.; Kok, C.; Clements, J.; Menzies, A.; Teague, J.W.; Futreal, P.A.; Stratton, M.R. The Catalogue of Somatic Mutations in Cancer (COSMIC). Curr. Protoc. Hum. Genet. 2008, 57, 10.11.1–10.11.26. [Google Scholar] [CrossRef]
- Shen, Y.; Yuan, M.; Luo, H.; Yang, Z.; Liang, M.; Gan, J. Rare variant of TBL1XR1 in West syndrome: A case report. Mol. Genet. Genom. Med. 2022, 10, e1991. [Google Scholar] [CrossRef] [PubMed]
- Berman, H.M.; Westbrook, J.; Feng, Z.; Gilliland, G.; Bhat, T.N.; Weissig, H.; Shindyalov, I.N.; Bourne, P.E. The Protein Data Bank. Nucleic Acids Res. 2000, 28, 235–242. [Google Scholar] [CrossRef]
- Xu, C.; Tempel, W.; He, H.; Wu, X.; Bountra, C.; Arrowsmith, C.H.; Edwards, A.M.; Min, J. Crystal structure of TBL1XR1 WD40 repeats. 2014; to be published. [Google Scholar] [CrossRef]
- Kallberg, M.; Margaryan, G.; Wang, S.; Ma, J.; Xu, J. RaptorX server: A resource for template-based protein structure modeling. Methods Mol. Biol. 2014, 1137, 17–27. [Google Scholar] [CrossRef]
- Biasini, M.; Bienert, S.; Waterhouse, A.; Arnold, K.; Studer, G.; Schmidt, T.; Kiefer, F.; Cassarino, T.G.; Bertoni, M.; Bordoli, L.; et al. SWISS-MODEL: Modelling protein tertiary and quaternary structure using evolutionary information. Nucleic Acids Res. 2014, 42, W252–W258. [Google Scholar] [CrossRef]
- Zhang, Y. I-TASSER server for protein 3D structure prediction. BMC Bioinform. 2008, 9, 40. [Google Scholar] [CrossRef]
- Miller, A.N.; Long, S.B. Crystal structure of the human two-pore domain potassium channel K2P1. Science 2012, 335, 432–436. [Google Scholar] [CrossRef]
- Brohawn, S.G.; del Marmol, J.; MacKinnon, R. Crystal structure of the human K2P TRAAK, a lipid- and mechano-sensitive K+ ion channel. Science 2012, 335, 436–441. [Google Scholar] [CrossRef] [PubMed]
- Hoegenauer, K.; Soldermann, N.; Stauffer, F.; Furet, P.; Graveleau, N.; Smith, A.B.; Hebach, C.; Hollingworth, G.J.; Lewis, I.; Gutmann, S.; et al. Discovery and Pharmacological Characterization of Novel Quinazoline-Based PI3K Delta-Selective Inhibitors. ACS Med. Chem. Lett. 2016, 7, 762–767. [Google Scholar] [CrossRef] [PubMed]
- Schymkowitz, J.; Borg, J.; Stricher, F.; Nys, R.; Rousseau, F.; Serrano, L. The FoldX web server: An online force field. Nucleic Acids Res. 2005, 33, W382–W388. [Google Scholar] [CrossRef] [PubMed]
- Phillips, J.C.; Braun, R.; Wang, W.; Gumbart, J.; Tajkhorshid, E.; Villa, E.; Chipot, C.; Skeel, R.D.; Kale, L.; Schulten, K. Scalable molecular dynamics with NAMD. J. Comput. Chem. 2005, 26, 1781–1802. [Google Scholar] [CrossRef]
- Huang, J.; MacKerell, A.D., Jr. CHARMM36 all-atom additive protein force field: Validation based on comparison to NMR data. J. Comput. Chem. 2013, 34, 2135–2145. [Google Scholar] [CrossRef]
- Zimmermann, M.T.; Urrutia, R.; Oliver, G.R.; Blackburn, P.R.; Cousin, M.A.; Bozeck, N.J.; Klee, E.W. Molecular modeling and molecular dynamic simulation of the effects of variants in the TGFBR2 kinase domain as a paradigm for interpretation of variants obtained by next generation sequencing. PLoS ONE 2017, 12, e0170822. [Google Scholar] [CrossRef]
- Zimmermann, M.T.; Urrutia, R.; Cousin, M.A.; Oliver, G.R.; Klee, E.W. Assessing Human Genetic Variations in Glucose Transporter SLC2A10 and Their Role in Altering Structural and Functional Properties. Front. Genet. 2018, 9. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Cheng, X.; Swails, J.M.; Yeom, M.S.; Eastman, P.K.; Lemkul, J.A.; Wei, S.; Buckner, J.; Jeong, J.C.; Qi, Y.; et al. CHARMM-GUI Input Generator for NAMD, GROMACS, AMBER, OpenMM, and CHARMM/OpenMM Simulations Using the CHARMM36 Additive Force Field. J. Chem. Theory Comput. 2016, 12, 405–413. [Google Scholar] [CrossRef]
- Brooks, B.R.; Brooks, C.L., III; Mackerell, A.D., Jr.; Nilsson, L.; Petrella, R.J.; Roux, B.; Won, Y.; Archontis, G.; Bartels, C.; Boresch, S. CHARMM: The biomolecular simulation program. J. Comput. Chem. 2009, 30, 1545–1614. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, Y. Generating triangulated macromolecular surfaces by Euclidean Distance Transform. PLoS ONE 2009, 4, e8140. [Google Scholar] [CrossRef]
- Jurrus, E.; Engel, D.; Star, K.; Monson, K.; Brandi, J.; Felberg, L.E.; Brookes, D.H.; Wilson, L.; Chen, J.; Liles, K.; et al. Improvements to the APBS biomolecular solvation software suite. Protein Sci. 2018, 27, 112–128. [Google Scholar] [CrossRef] [PubMed]
- Dolinsky, T.J.; Czodrowski, P.; Li, H.; Nielsen, J.E.; Jensen, J.H.; Klebe, G.; Baker, N.A. PDB2PQR: Expanding and upgrading automated preparation of biomolecular structures for molecular simulations. Nucleic Acids Res. 2007, 35, W522–W525. [Google Scholar] [CrossRef] [PubMed]
- Dolinsky, T.J.; Nielsen, J.E.; McCammon, J.A.; Baker, N.A. PDB2PQR: An automated pipeline for the setup of Poisson-Boltzmann electrostatics calculations. Nucleic Acids Res. 2004, 32, W665–W667. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).