
Dig-up Primers: A Pipeline for Identification of Polymorphic Microsatellites Loci within Assemblies of Related Species

 , , ,
, , ,  , , and
, , and 
Abstract
1. Introduction
2. Results
2.1. Joint SSR Marker Identification in Two Species
2.2. Joint SSR Marker Identification in Three Subspecies
3. Discussion
4. Materials and Methods
4.1. Data Accessibility
4.2. Pipeline Availability and Requirements
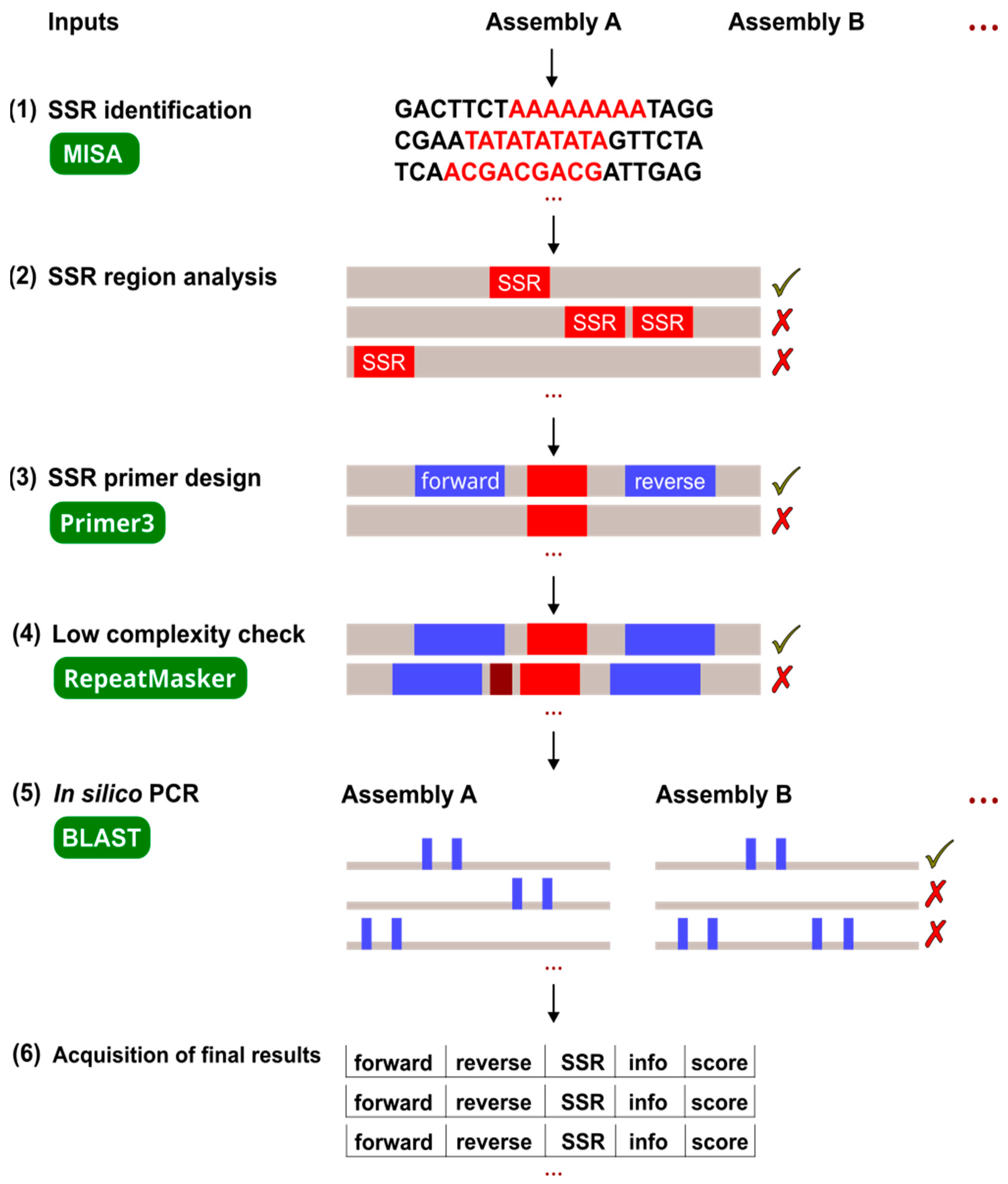
4.3. Pipeline Process
4.3.1. SSR Identification
4.3.2. SSR Region Analysis
4.3.3. SSR Primer Design
4.3.4. Low-Complexity Check
4.3.5. In Silico PCR
4.3.6. Final Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Moxon, E.R.; Wills, C. DNA Microsatellites: Agents of Evolution? Sci. Am. 1999, 280, 94–99. [Google Scholar] [CrossRef] [PubMed]
- Zane, L.; Bargelloni, L.; Patarnello, T. Strategies for Microsatellite Isolation: A Review. Mol. Ecol. 2002, 11, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, E.J.; Pádua, J.G.; Zucchi, M.I.; Vencovsky, R.; Vieira, M.L.C. Origin, Evolution and Genome Distribution of Microsatellites. Genet. Mol. Biol. 2006, 29, 294–307. [Google Scholar] [CrossRef]
- Sia, E.A.; Butler, C.A.; Dominska, M.; Greenwell, P.; Fox, T.D.; Petes, T.D. Analysis of Microsatellite Mutations in the Mitochondrial DNA of Saccharomyces Cerevisiae. Proc. Natl. Acad. Sci. USA 2000, 97, 250–255. [Google Scholar] [CrossRef] [PubMed]
- Tóth, G.; Gáspári, Z.; Jurka, J. Microsatellites in Different Eukaryotic Genomes: Surveys and Analysis. Genome Res. 2000, 10, 967–981. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.C.; Korol, A.B.; Fahima, T.; Nevo, E. Microsatellites within Genes: Structure, Function, and Evolution. Mol. Biol. Evol. 2004, 2, 991–1007. [Google Scholar] [CrossRef]
- Ellis, J.R.; Burke, J.M. EST-SSRs as a Resource for Population Genetic Analyses. Heredity 2007, 99, 125–132. [Google Scholar] [CrossRef]
- Selkoe, K.A.; Toonen, R.J. Microsatellites for Ecologists: A Practical Guide to Using and Evaluating Microsatellite Markers. Ecol. Lett. 2006, 9, 615–629. [Google Scholar] [CrossRef]
- Kalia, R.K.; Rai, M.K.; Kalia, S.; Singh, R.; Dhawan, A.K. Microsatellite Markers: An Overview of the Recent Progress in Plants. Euphytica 2011, 177, 309–334. [Google Scholar] [CrossRef]
- Echt, C.S.; Saha, S.; Krutovsky, K.V.; Wimalanathan, K.; Erpelding, J.E.; Liang, C.; Nelson, C.D. An Annotated Genetic Map of Loblolly Pine Based on Microsatellite and CDNA Markers. BMC Genet. 2011, 12, 17. [Google Scholar] [CrossRef]
- Vieira, M.L.C.; Santini, L.; Diniz, A.L.; Munhoz, C.d.F. Microsatellite Markers: What They Mean and Why They Are so Useful. Genet. Mol. Biol. 2016, 39, 312–328. [Google Scholar] [CrossRef]
- Wenne, R. Microsatellites as Molecular Markers with Applications in Exploitation and Conservation of Aquatic Animal Populations. Genes 2023, 14, 808. [Google Scholar] [CrossRef] [PubMed]
- Jarne, P.; Lagoda, P.J.L. Microsatellites, from Molecules to Populations and Back. Trends Ecol. Evol. 1996, 11, 424–429. [Google Scholar] [CrossRef] [PubMed]
- Ellegren, H. Microsatellites: Simple Sequences with Complex Evolution. Nat. Rev. Genet. 2004, 5, 435–445. [Google Scholar] [CrossRef] [PubMed]
- Guichoux, E.; Lagache, L.; Wagner, S.; Chaumeil, P.; Léger, P.; Lepais, O.; Lepoittevin, C.; Malausa, T.; Revardel, E.; Salin, F.; et al. Current Trends in Microsatellite Genotyping. Mol. Ecol. Resour. 2011, 11, 591–611. [Google Scholar] [CrossRef]
- Wolff, R.K.; Plaetke, R.; Jeffreys, A.J.; White, R. Unequal Crossingover between Homologous Chromosomes Is Not the Major Mechanism Involved in the Generation of New Alleles at VNTR Loci. Genomics 1989, 5, 382–384. [Google Scholar] [CrossRef]
- Barbará, T.; Palma-Silva, C.; Paggi, G.M.; Bered, F.; Fay, M.F.; Lexer, C. Cross-Species Transfer of Nuclear Microsatellite Markers: Potential and Limitations. Mol. Ecol. 2007, 16, 3759–3767. [Google Scholar] [CrossRef]
- Hodel, R.G.J.; Segovia-Salcedo, M.C.; Landis, J.B.; Crowl, A.A.; Sun, M.; Liu, X.; Gitzendanner, M.A.; Douglas, N.A.; Germain-Aubrey, C.C.; Chen, S.; et al. The Report of My Death Was an Exaggeration: A Review for Researchers Using Microsatellites in the 21st Century. Appl. Plant Sci. 2016, 4, 1600025. [Google Scholar] [CrossRef]
- Lemopoulos, A.; Prokkola, J.M.; Uusi-Heikkilä, S.; Vasemägi, A.; Huusko, A.; Hyvärinen, P.; Koljonen, M.L.; Koskiniemi, J.; Vainikka, A. Comparing RADseq and Microsatellites for Estimating Genetic Diversity and Relatedness—Implications for Brown Trout Conservation. Ecol. Evol. 2019, 9, 2106–2120. [Google Scholar] [CrossRef]
- Sunde, J.; Yıldırım, Y.; Tibblin, P.; Forsman, A. Comparing the Performance of Microsatellites and RADseq in Population Genetic Studies: Analysis of Data for Pike (Esox lucius) and a Synthesis of Previous Studies. Front. Genet. 2020, 11, 218. [Google Scholar] [CrossRef]
- Ritschel, P.S.; Lins, T.C.D.L.; Tristan, R.L.; Buso, G.S.C.; Buso, J.A.; Ferreira, M.E. Development of Microsatellite Markers from an Enriched Genomic Library for Genetic Analysis of Melon (Cucumis melo L.). BMC Plant Biol. 2004, 4, 9. [Google Scholar] [CrossRef]
- Zalapa, J.E.; Cuevas, H.; Zhu, H.; Steffan, S.; Senalik, D.; Zeldin, E.; McCown, B.; Harbut, R.; Simon, P. Using Next-Generation Sequencing Approaches to Isolate Simple Sequence Repeat (SSR) Loci in the Plant Sciences. Am. J. Bot. 2012, 99, 193–208. [Google Scholar] [CrossRef]
- Merritt, B.J.; Culley, T.M.; Avanesyan, A.; Stokes, R.; Brzyski, J. An Empirical Review: Characteristics of Plant Microsatellite Markers That Confer Higher Levels of Genetic Variation. Appl. Plant Sci. 2015, 3, 1500025. [Google Scholar] [CrossRef]
- Peakall, R.; Gilmore, S.; Keys, W.; Morgante, M.; Rafalski, A. Cross-Species Amplification of Soybean (Glycine Max) Simple Sequence Repeats (SSRs) within the Genus and Other Legume Genera: Implications for the Transferability of SSRs in Plants. Mol. Biol. Evol. 1998, 15, 1275–1287. [Google Scholar] [CrossRef]
- Radosavljević, I.; Jakse, J.; Javornik, B.; Satovic, Z.; Liber, Z. New Microsatellite Markers for Salvia Officinalis (Lamiaceae) and Cross-Amplification in Closely Related Species. Am. J. Bot. 2011, 98, e316–e318. [Google Scholar] [CrossRef]
- Radosavljević, I.; Satovic, Z.; Jakse, J.; Javornik, B.; Greguraš, D.; Jug-Dujaković, M.; Liber, Z. Development of New Microsatellite Markers for Salvia Officinalis L. and Its Potential Use in Conservation-Genetic Studies of Narrow Endemic Salvia Brachyodon Vandas. Int. J. Mol. Sci. 2012, 9, 12082–12093. [Google Scholar] [CrossRef]
- Arnold, M.L. Natural Hybridization and Evolution; Oxford Series in Ecology and Evolution; Oxford University Press: New York, NY, USA, 1997. [Google Scholar]
- Rhymer, J.M.; Simberloff, D. Extinction by Hybridization and Introgression. Annu. Rev. Ecol. Syst. 1996, 27, 83–109. [Google Scholar] [CrossRef]
- Allendorf, F.W.; Leary, R.F.; Spruell, P.; Wenburg, J.K. The Problems with Hybrids: Setting Conservation Guidelines. Trends Ecol. Evol. 2001, 16, 613–622. [Google Scholar] [CrossRef]
- Arnold, M.L. Evolution through Genetic Exchange; Oxford University Press: New York, NY, USA, 2007. [Google Scholar]
- Kong, S.; Kubatko, L.S. Comparative Performance of Popular Methods for Hybrid Detection Using Genomic Data. Syst. Biol. 2021, 70, 891–907. [Google Scholar] [CrossRef] [PubMed]
- Wenger, A.M.; Peluso, P.; Rowell, W.J.; Chang, P.C.; Hall, R.J.; Concepcion, G.T.; Ebler, J.; Fungtammasan, A.; Kolesnikov, A.; Olson, N.D.; et al. Accurate Circular Consensus Long-Read Sequencing Improves Variant Detection and Assembly of a Human Genome. Nat. Biotechnol. 2019, 37, 891–907. [Google Scholar] [CrossRef] [PubMed]
- Pritchard, J.K.; Stephens, M.; Donnelly, P. Inference of Population Structure Using Multilocus Genotype Data. Genetics 2000, 155, 945–959. [Google Scholar] [CrossRef]
- Goulet, B.E.; Roda, F.; Hopkins, R. Hybridization in Plants: Old Ideas, New Techniques[OPEN]. Plant Physiol. 2017, 173, 65–78. [Google Scholar] [CrossRef] [PubMed]
- Vähä, J.P.; Primmer, C.R. Efficiency of Model-Based Bayesian Methods for Detecting Hybrid Individuals under Different Hybridization Scenarios and with Different Numbers of Loci. Mol. Ecol. 2006, 15, 63–72. [Google Scholar] [CrossRef] [PubMed]
- Corander, J.; Marttinen, P. Bayesian Identification of Admixture Events Using Multilocus Molecular Markers. Mol. Ecol. 2006, 15, 2833–2843. [Google Scholar] [CrossRef] [PubMed]
- Neophytou, C. Bayesian Clustering Analyses for Genetic Assignment and Study of Hybridization in Oaks: Effects of Asymmetric Phylogenies and Asymmetric Sampling Schemes. Tree Genet. Genomes 2014, 10, 273–285. [Google Scholar] [CrossRef]
- Huson, D.H.; Bryant, D. Application of Phylogenetic Networks in Evolutionary Studies. Mol. Biol. Evol. 2006, 23, 254–267. [Google Scholar] [CrossRef] [PubMed]
- Lawson, D.J.; van Dorp, L.; Falush, D. A Tutorial on How Not to Over-Interpret STRUCTURE and ADMIXTURE Bar Plots. Nat. Commun. 2018, 9, 3258. [Google Scholar] [CrossRef] [PubMed]
- Anderson, E.C.; Thompson, E.A. A Model-Based Method for Identifying Species Hybrids Using Multilocus Genetic Data. Genetics 2002, 160, 1217–1229. [Google Scholar] [CrossRef]
- Bohling, J.H.; Adams, J.R.; Waits, L.P. Evaluating the Ability of Bayesian Clustering Methods to Detect Hybridization and Introgression Using an Empirical Red Wolf Data Set. Mol. Ecol. 2013, 22, 74–86. [Google Scholar] [CrossRef]
- Meglécz, E.; Pech, N.; Gilles, A.; Dubut, V.; Hingamp, P.; Trilles, A.; Grenier, R.; Martin, J.F. QDD Version 3.1: A User-Friendly Computer Program for Microsatellite Selection and Primer Design Revisited: Experimental Validation of Variables Determining Genotyping Success Rate. Mol. Ecol. Resour. 2014, 14, 1302–1313. [Google Scholar] [CrossRef]
- Xia, E.H.; Yao, Q.Y.; Zhang, H.B.; Jiang, J.J.; Zhang, L.P.; Gao, L.Z. CandiSSR: An Efficient Pipeline Used for Identifying Candidate Polymorphic SSRs Based on Multiple Assembled Sequences. Front. Plant Sci. 2016, 6, 1171. [Google Scholar] [CrossRef] [PubMed]
- Fox, G.; Preziosi, R.F.; Antwis, R.E.; Benavides-Serrato, M.; Combe, F.J.; Harris, W.E.; Hartley, I.R.; Kitchener, A.C.; de Kort, S.R.; Nekaris, A.I.; et al. Multi-Individual Microsatellite Identification: A Multiple Genome Approach to Microsatellite Design (MiMi). Mol. Ecol. Resour. 2019, 19, 1672–1680. [Google Scholar] [CrossRef] [PubMed]
- Guang, X.M.; Xia, J.Q.; Lin, J.Q.; Yu, J.; Wan, Q.H.; Fang, S.G. IDSSR: An Efficient Pipeline for Identifying Polymorphic Microsatellites from a Single Genome Sequence. Int. J. Mol. Sci. 2019, 20, 3497. [Google Scholar] [CrossRef]
- Biswas, M.K.; Biswas, D.; Sheng, O.; Yi, G.; Deng, G. MMdb: Genomic Resource for the Improvement of the Family Musaceae. 2023; Preprints. [Google Scholar] [CrossRef]
- Yue, J.; Liu, Y. SSR2Marker: An Integrated Pipeline for Identification of SSR Markers within Any Two given Genome-Scale Sequences. Mol. Hortic. 2022, 2, 11. [Google Scholar] [CrossRef]
- Duhan, N.; Meshram, M.; Loaiza, C.D.; Kaundal, R. CitSATdb: Genome-Wide Simple Sequence Repeat (SSR) Marker Database of Citrus Species for Germplasm Characterization and Crop Improvement. Genes 2020, 11, 1486. [Google Scholar] [CrossRef] [PubMed]
- Duhan, N.; Kaundal, R. LegumeSSRdb: A Comprehensive Microsatellite Marker Database of Legumes for Germplasm Characterization and Crop Improvement. Int. J. Mol. Sci. 2021, 22, 11350. [Google Scholar] [CrossRef]
- Biswas, M.K.; Biswas, D.; Bagchi, M.; Yi, G.; Deng, G. A Comprehensive Plant Microrna Simple Sequence Repeat Marker Database to Accelerate Genetic Improvements in Crops. Agronomy 2021, 11, 2298. [Google Scholar] [CrossRef]
- Fernandez-Manjarres, J.F.; Gerard, P.R.; Dufour, J.; Raquin, C.; Frascaria-Lacoste, N. Differential Patterns of Morphological and Molecular Hybridization between Fraxinus excelsior L. and Fraxinus Angustifolia Vahl (Oleaceae) in Eastern and Western France. Mol. Ecol. 2006, 15, 3245–3257. [Google Scholar] [CrossRef]
- Gérard, P.R.; Temunović, M.; Sannier, J.; Bertolino, P.; Dufour, J.; Frascaria-Lacoste, N.; Fernández-Manjarrés, J.F. Chilled but Not Frosty: Understanding the Role of Climate in the Hybridization between the Mediterranean Fraxinus Angustifolia Vahl and the Temperate Fraxinus excelsior L. (Oleaceae) Ash Trees. J. Biogeogr. 2013, 40, 835–846. [Google Scholar] [CrossRef]
- Wallander, E. Systematics of Fraxinus (Oleaceae) and Evolution of Dioecy. Plant Syst. Evol. 2008, 273, 25–49. [Google Scholar] [CrossRef]
- Idžojtić, M.; Poljak, I. Morphological and Biological Characteristics and Natural Distribution of Narrow-Leaves Ash (Fraxinus angustifolia Vahl, Oleaceae). In Narrow-Leaved Ash in Croatia (Fraxinus angustifolia Vahl); Anić, I., Ed.; Academy of Forestry Sciences: Zagreb, Croatia, 2022; pp. 33–48. [Google Scholar]
- Franjić, J.; Temunović, M. Taxonomic Status of Narrow-Leaved Ash (Fraxinus angustifolia Vahl, Oleaceae). In Narrow-Leaved Ash in Croatia (Fraxinus angustifolia Vahl); Anić, I., Ed.; Academy of Forestry Sciences: Zagreb, Croatia, 2022; pp. 49–66. [Google Scholar]
- Gerard, P.R.; Fernandez-Manjarres, J.F.; Frascaria-Lacoste, N. Temporal Cline in a Hybrid Zone Population between Fraxinus excelsior L. and Fraxinus Angustifolia Vahl. Mol. Ecol. 2006, 15, 3655–3667. [Google Scholar] [CrossRef]
- Fraxigen. Ash Species in Europe: Biological Characteristics and Practical Guidelines for Sustainable Use; Oxford Forestry Institute, University of Oxford: Oxford, UK, 2005. [Google Scholar]
- Cock, P.J.A.; Antao, T.; Chang, J.T.; Chapman, B.A.; Cox, C.J.; Dalke, A.; Friedberg, I.; Hamelryck, T.; Kauff, F.; Wilczynski, B.; et al. Biopython: Freely Available Python Tools for Computational Molecular Biology and Bioinformatics. Bioinformatics 2009, 25, 1422–1423. [Google Scholar] [CrossRef]
- Thiel, T.; Michalek, W.; Varshney, R.K.; Graner, A. Exploiting EST Databases for the Development and Characterization of Gene-Derived SSR-Markers in Barley (Hordeum vulgare L.). Theor. Appl. Genet. 2003, 106, 411–422. [Google Scholar] [CrossRef]
- Smit, A.; Hubley, R.; Green, P. RepeatMasker Open-4.0.6 2013–2015. 2018. Available online: http://www.repeatmasker.org (accessed on 25 June 2023).
- Untergasser, A.; Cutcutache, I.; Koressaar, T.; Ye, J.; Faircloth, B.C.; Remm, M.; Rozen, S.G. Primer3-New Capabilities and Interfaces. Nucleic Acids Res. 2012, 40, e115. [Google Scholar] [CrossRef] [PubMed]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic Local Alignment Search Tool. J. Mol. Biol. 1990, 215, 403–410. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
| Steps | Description | Included | Excluded |
|---|---|---|---|
| (1) SSR identification | Total no. of SSRs found | 28,403 | |
| (2) SSR region analysis | No. of composite SSRs | 1137 | |
| No. of long SSRs | 162 | ||
| No. of SSRs close to another SSR | 1584 | ||
| No. of SSRs close to the contig end | 6 | ||
| No. of promising SSR regions | 25,514 | ||
| (3) SSR primer design | No. of SSR regions without suitable primers | 11,710 | |
| No. of SSR regions with suitable primers | 13,804 | ||
| (4) Low complexity check | No. of regions with low complexity | 5902 | |
| No. of regions close to a coding region | 78 | ||
| No. of promising SSR markers | 7824 | ||
| (5) In silico PCR | No. of markers amplified once in Assembly A | 6777 | |
| No. of markers amplified once in Assembly B | 1180 | ||
| (6) Acquisition of final results | Final no. of SSR markers | 910 |
| Steps | Description | Included | Excluded |
|---|---|---|---|
| (1) SSR identification | Total no. of SSRs found | 18,793 | |
| (2) SSR region analysis | No. of composite SSRs | 397 | |
| No. of long SSRs | 4 | ||
| No. of SSRs close to another SSR | 645 | ||
| No. of SSRs close to the contig end | 5129 | ||
| No. of promising SSR regions | 12,618 | ||
| (3) SSR primer design | No. of SSR regions without suitable primers | 4975 | |
| No. of SSR regions with suitable primers | 7643 | ||
| (4) Low complexity check | No. of regions with low complexity | 3021 | |
| No. of regions close to a coding region | 48 | ||
| No. of promising SSR markers | 4574 | ||
| (5) In silico PCR | No. of markers amplified once in Assembly A | 4403 | |
| No. of markers amplified once in Assembly B | 477 | ||
| No. of markers amplified once in Assembly C | 771 | ||
| (6) Acquisition of final results | Final no. of SSR markers | 154 |
| Species/Subspecies | Accession Number | Assembly Level | Assembly Size (Mb) | Number of Contigs |
|---|---|---|---|---|
| Fraxinus excelsior | GCA_019097785 | Chromosome | 806.5 | 421 |
| F. angustifolia subsp. angustifolia | GCA_902829175 | Contig | 692.6 | 489,825 |
| F. angustifolia subsp. oxycarpa | GCA_903798265 | Scaffold | 714.3 | 413,147 |
| F. angustifolia subsp. syriaca | GCA_903798275 | Scaffold | 586.0 | 323,049 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Turudić, A.; Liber, Z.; Grdiša, M.; Jakše, J.; Varga, F.; Poljak, I.; Šatović, Z. Dig-up Primers: A Pipeline for Identification of Polymorphic Microsatellites Loci within Assemblies of Related Species. Int. J. Mol. Sci. 2024, 25, 3169. https://doi.org/10.3390/ijms25063169
Turudić A, Liber Z, Grdiša M, Jakše J, Varga F, Poljak I, Šatović Z. Dig-up Primers: A Pipeline for Identification of Polymorphic Microsatellites Loci within Assemblies of Related Species. International Journal of Molecular Sciences. 2024; 25(6):3169. https://doi.org/10.3390/ijms25063169
Chicago/Turabian StyleTurudić, Ante, Zlatko Liber, Martina Grdiša, Jernej Jakše, Filip Varga, Igor Poljak, and Zlatko Šatović. 2024. "Dig-up Primers: A Pipeline for Identification of Polymorphic Microsatellites Loci within Assemblies of Related Species" International Journal of Molecular Sciences 25, no. 6: 3169. https://doi.org/10.3390/ijms25063169
APA StyleTurudić, A., Liber, Z., Grdiša, M., Jakše, J., Varga, F., Poljak, I., & Šatović, Z. (2024). Dig-up Primers: A Pipeline for Identification of Polymorphic Microsatellites Loci within Assemblies of Related Species. International Journal of Molecular Sciences, 25(6), 3169. https://doi.org/10.3390/ijms25063169