Abstract
Cathepsin L (CatL) is a critical protease involved in cleaving the spike protein of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), facilitating viral entry into host cells. Inhibition of CatL is essential for preventing SARS-CoV-2 cell entry, making it a potential therapeutic target for drug development. Six QSAR models were established to predict the inhibitory activity (expressed as IC50 values) of candidate compounds against CatL. These models were developed using statistical method heuristic methods (HMs), the evolutionary algorithm gene expression programming (GEP), and the ensemble method random forest (RF), along with the kernel-based machine learning algorithm support vector regression (SVR) configured with various kernels: radial basis function (RBF), linear-RBF hybrid (LMIX2-SVR), and linear-RBF-polynomial hybrid (LMIX3-SVR). The particle swarm optimization algorithm was applied to optimize multi-parameter SVM models, ensuring low complexity and fast convergence. The properties of novel CatL inhibitors were explored through molecular docking analysis. The LMIX3-SVR model exhibited the best performance, with an of 0.9676 and 0.9632 for the training set and test set and RMSE values of 0.0834 and 0.0322. Five-fold cross-validation = 0.9043 and leave-one-out cross-validation = 0.9525 demonstrated the strong prediction ability and robustness of the model, which fully proved the correctness of the five selected descriptors. Based on these results, the IC50 values of 578 newly designed compounds were predicted using the HM model, and the top five candidate compounds with the best physicochemical properties were further verified by Property Explorer Applet (PEA). The LMIX3-SVR model significantly advances QSAR modeling for drug discovery, providing a robust tool for designing and screening new drug molecules. This study contributes to the identification of novel CatL inhibitors, which aids in the development of effective therapeutics for SARS-CoV-2.
1. Introduction
The coronavirus illness of 2019 (COVID-19) was caused by the positive-sense, single RNA virus known as the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) [1], which first appeared in December 2019 and then spread throughout the world [2,3,4,5]. International public health infrastructure and economic productivity have been negatively impacted by the estimated 777 million verified COVID-19 illnesses and 7.07 million deaths worldwide as of early April 2024 [6,7,8,9,10]. Currently, the principal preventative strategy is still vaccination against inactivated viruses [11]. Nevertheless, this method can only stop infection; it cannot stop the virus from infecting people who are already infected. Additionally, some immunocompromised populations may be in danger from vaccinations [12].
Currently available treatments for SARS-CoV-2 include remdesivir [13] and molnupiravir [14], which target RNA-dependent RNA polymerases [13,14]. These medications do, however, have serious drawbacks, including lack of specificity and severe responses. The discovery of safe, oral bioavailable anti-SARS-CoV-2 medications is therefore desperately needed, especially those that can lessen the virus’s possible long-term effects.
In the latest research, an elevated level of circulating cathepsin L (CatL) is correlated [15] with COVID-19 disease progression and severity. Emerging evidence posits that the SARS-CoV-2 Omicron variant may exhibit a predilection for the CatL-mediated endosomal pathway for cellular entry [16,17]. Thus, CatL can be a potential target against SARS-CoV-2. A promising therapeutic approach for COVID-19 could involve the attenuation of CatL activity to obstruct the viral entry into host cells.
The literature [18] indicates that a new class of peptidomimetic analogues (PDAs) was recognized as an effective cathepsin L (CatL) inhibitor, and peptidomimetic aldehyde exhibited notable efficacy in suppressing CatL enzymatic function. To find compounds with improved therapeutic effectiveness and fewer adverse effects, more research should be performed on a number of PDAs that structurally resemble peptidomimetic aldehyde. The potency of inhibition toward CatL can be quantified using the IC50 metric, representing the inhibitor concentration required to decrease CatL activity by 50%. As such, determining IC50 values for various PDAs is pivotal in the process of identifying more effective and safer CatL-targeting drug candidates.
Due to the fact that the traditional IC50 measurement method consumes a lot of manpower and material resources, more efficient and economical methods are needed.
The quantitative structure–activity relationship (QSAR) [19,20] is a technique utilized to define the link between molecular structure and specific biological activities using mathematical modeling. The fundamental tenet of QSARs is that a compound’s physical characteristics and bioactivity are determined by its chemical structure [21]. The main goal is to develop a quantitative relationship model between a compound’s structural features and biological activity in order to forecast the biological activity or other pertinent qualities of novel compounds and to direct its synthesis and design. The physical and chemical characteristics of substances can be described by molecular descriptors in QSAR models [22,23]. Therefore, by employing mathematical techniques built from carefully selected chemical descriptors, a QSAR makes it possible to estimate biological activity in new substance [24,25].
QSAR models contribute to lowering research expenditures and enhancing productivity in drug development, thereby offering a reliable strategy for estimating the IC50 of CatL inhibitors and efficiently identifying promising candidate compounds.
Six models based on four modeling methodologies were created and compared in this study. These included the statistical method heuristic method (HM), the evolutionary algorithm gene expression programming (GEP), the ensemble learning method random forest (RF), and the kernel-based machine learning algorithm support vector regression (SVR). For SVR, three kernel structures were explored: a single kernel using the radial basis function (RBF), a dual kernel combining linear and radial basis functions (LMIX2-SVR), and a triple kernel integrating linear, radial basis, and polynomial functions (LMIX3-SVR). These models were constructed to predict the IC50 values of CatL inhibitors. In the SVR models, the single kernel employed the radial basis function, the double kernel combined the radial basis and polynomial functions linearly, while the triple kernel incorporated radial basis, polynomial, and linear functions through linear integration. LMIX3-SVR outperformed other SVR models in terms of performance and robustness, highlighting the usefulness of its integrated triple kernel design in assisting creative drug development initiatives. Furthermore, in order to facilitate the logical design and screening of new chemical entities, the created models were applied to docking experiments and molecular activity prediction. Five new CatL inhibitors stood out from 578 new designed CatL inhibitors. According to these experimental results, the developed compounds performed better, which supports the idea that they could be used as better choices in the context of target-specific inhibition. The study offers new compounds that target and inhibit CatL, providing important information for the creation of antiviral medications that combat SARS-CoV-2.
2. Results
2.1. HM
A total of 604 molecular descriptors were computed using the CODESSA 2.64 software (https://revvitysignals.com accessed on 10 January 2025). To identify molecular descriptors most associated with CatL inhibitory activity, a series of linear models were constructed using progressively more descriptors. Figure 1 depicts the impact of descriptor quantity on both and .

Figure 1.
Influences of the number of descriptors on , .
As shown in Figure 1, the and improve as the number of descriptors increases. However, when the number of descriptors reached five, increasing the number of descriptors did not significantly improve the and . Therefore, the five descriptors in the HM model can be regarded as the most critical ones. Table 1 lists the five selected molecular descriptors along with their physicochemical interpretations, while Table 2 presents their correlation coefficients.

Table 1.
The selected descriptors and their physical–chemical meanings and coefficient by HM.
Table 2.
Correlation coefficient of the five descriptors by HM.
In the HM model, the values for the training and test sets are 0.8000 and 0.8159, with corresponding values of 0.0658 and 0.0764. Moreover, the plot of measured and predicted lg (IC50) by the HM model with five descriptors is shown in Figure 2.
Figure 2.
Plot of measured and predicted lg (IC50) by HM model. The black line is the y = x line, and the red line is the regression line.
In summary, the HM model provides moderate prediction accuracy and good interpretability, but its linear nature limits its ability to capture complex nonlinear relationships.
Equation (1) is the HM model’s mathematical expression:
2.2. XGBoost
Using a nonlinear method to select descriptors can better capture nonlinear relationships between data [26]. Therefore, the correctness of descriptors selected by HM is verified by the nonlinear method XGBoost. All descriptors calculated from CODESSA were exported and preprocessed. The split gain for each descriptor was then calculated to determine the importance of the descriptor. Table 3 shows the physical–chemical meanings of the top ten descriptors selected by XGBoost. Figure 3 shows the ten descriptors with highest importance. Table 4 shows the correlation coefficients between the ten most important descriptors screened by XGBoost.
Table 3.
The selected descriptors and their physical-chemical meanings by XGBoost.
Figure 3.
Importance of ten descriptors selected by XGBoost.
Table 4.
Correlation coefficient of the ten descriptors by XGBoost.
However, the HM method selects descriptors by considering the correlation between them, while XGBoost only ranks descriptors based on the importance score calculated from the split gain method, completely ignoring the correlation between the descriptors. This leads to a key issue that a considerable proportion of correlation coefficients between the top ten descriptors selected by XGBoost exceed 0.6, as clearly demonstrated in Table 4. When these highly relevant descriptors are removed, the resulting subset is exactly consistent with the descriptors chosen by the HM method.
XGBoost selection results based on split gain importance strongly validate the rationality of the HM descriptor selection method. Thus, while XGBoost serves for initial importance evaluation, HM proves superior for obtaining nonredundant descriptor sets, justifying its use in this study.
2.3. GEP
Five selected descriptors were input into APS 2.9 software (http://www.gepsoft.com accessed on 2 April 2025) to construct the GEP model.
In the GEP model, the values for the training and test sets are 0.7637 and 0.7798, with corresponding values of 0.3394 and 0.2400. The plot of measured and predicted lg (IC50) by the GEP model with five descriptors is shown in Figure 4. The nonlinear model established by GEP is expressed as Equation (2).
Figure 4.
Plot of measured and predicted lg (IC50) by GEP model. The black line is the y = x line, and the red line is the regression line.
While GEP is capable of modeling nonlinear patterns and yields interpretable equations, its prediction accuracy was relatively low, suggesting limited generalization capacity.
2.4. RF
When using RF regression, the following four important parameters were determined [27].
- The number of decision trees in the forest (): This number is positively correlated with model performance and computational complexity.
- The minimum number of samples required for node splitting (): It serves to constrain the minimum size of leaf nodes, avoiding mitigating overfitting.
- The maximum depth of a single tree (): This parameter limits the complexity of the tree and prevents overfitting.
- The minimum number of samples required for a leaf node (): This parameter will prevent the appearance of leaves with a very small number of samples, improving the generalization ability of the model.
The optimal parameters for the RF model are shown below. In the RF model, the values for the training and test sets are 0.9617 and 0.7781, with corresponding values of 0.1321 and 0.3089. The plot of measured and predicted lg (IC50) by the RF model with five descriptors is shown in Figure 5.
Figure 5.
Plot of measured and predicted lg (IC50) by RF model. The black line is the y = x line, and the red line is the regression line.
The RF model demonstrated high training accuracy but showed signs of overfitting with lower test set performance, indicating weaker robustness.
2.5. RBF-SVR
RBF is universal, flexible, and efficient and is often used as a kernel function. And the effect of RBF mainly depends on the penalty factor and scale factor . controls the amount of regularization applied to the data. Higher values of lead to better fit on the training data, while simultaneously raising the likelihood of overfitting [28]. controls the width of the RBF nucleus. A larger γ value makes the kernel function more sensitive to distance, and a smaller value makes the kernel less sensitive to distance. In addition, the effectiveness of the SVR is also affected by . The parameter determines how sensitive the model is to input noise. The PSO algorithm is used in the process of parameter optimization to accelerate the convergence speed. The best-performing RBF parameter combination obtained via PSO is listed below.
The plot of measured and predicted lg (IC50) by the RBF-SVR model with five descriptors is shown in Figure 6. The of the training set and the test set in the model are 0.9431 and 0.8971, and the are 0.0063 and 0.0614.
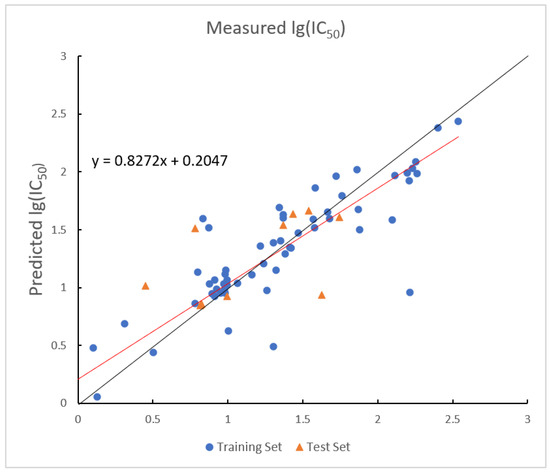
Figure 6.
Plot of measured and predicted lg (IC50) by RBF-SVR model. The black line is the y = x line, and the red line is the regression line.
The RBF-SVR demonstrates universal approximation capability, enabling effective modeling of complex nonlinear relationships between molecular descriptors and bioactivity without requiring prior knowledge of data structure. This property receives empirical validation through the model’s training performance metrics, specifically achieving a coefficient of determination value of 0.9431 and maintaining an of 0.0063. The kernel exhibits high learning efficiency by successfully capturing intricate patterns using only five descriptors while preserving computational feasibility.
The RBF-SVR demonstrates weaker generalization capability, as evidenced by a significant performance gap between training and test sets. While the model achieves strong predictive accuracy on the training data, with an of 0.9431, its performance declines to an of 0.8971 on the test set. This 4.9% reduction in explanatory power indicates overfitting to training-specific patterns. This divergence implies excessive fitting to training-specific noise patterns, attributable to kernel sensitivity to bandwidth parameter .
2.6. LMIX2-SVR
However, a 0.046 higher value of the training set than that of test set indicates overfitting of the RBF-SVR model, and a balance between the model’s learning capacity and generalization ability needs to be maintained. Therefore, the combination of RBF kernel function with linear kernel function is intended to balance the model’s learning ability against its generalization capacity. According to Equation (9), a new parameter is added to indicate the proportion of the RBF kernel of the double-kernel function. The optimal parameter set for the dual-kernel function, obtained via PSO, is presented below.
The optimal prediction results of the model established by the LMIX2-SVR are shown in Figure 7. The values of the training set and the test set in the model are 0.9671 and 0.9410, and the values are 0.0045 and 0.1199.
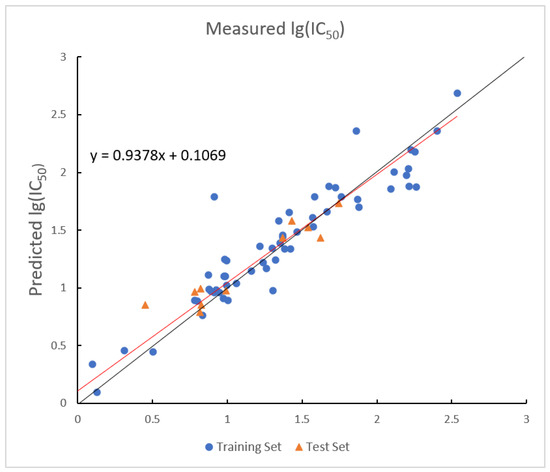
Figure 7.
Plot of measured and predicted lg (IC50) by LMIX2-SVR model. The black line is the y = x line, and the red line is the regression line.
The LMIX2-SVR model demonstrates robust predictive performance, achieving a training set value of 0.9671 and maintaining a test set value of 0.9410. These results indicate superior generalization capability when applied to out-of-sample data. The dual-kernel architecture effectively combines the linear kernel stability in handling low-dimensional linear relationships with the RBF kernel strength in modeling high-dimensional nonlinear patterns. Notably, while the linear kernel ensures out-of-sample robustness, the RBF kernel successfully captures complex feature interactions. This combination enables the model to maintain balanced adaptability across heterogeneous data structures, as demonstrated by a test value of 0.1199 despite its high training accuracy.
The double-kernel architecture in this model requires simultaneous optimization of multiple hyperparameters, which significantly increases computational overhead. This complexity raises overfitting risks, as shown by the 0.0261 generalization gap between the training set value of 0.9671 and test set value of 0.9410. Parameter selection sensitivity in the RBF kernel may worsen performance instability in noisy or high-dimensional domains, where improper calibration could disproportionately amplify prediction errors. Additionally, the linear–RBF combination needs careful weighting to prevent either kernel from dominating. If the kernel contributions are not properly balanced, model performance may degrade when handling datasets that have sharp transitions between linear and nonlinear patterns.
2.7. LMIX3-SVR
The results demonstrate that, in the LMIX2-SVR model, the value for the training set remains more than 0.026 higher than that of the test set, suggesting insufficient generalization performance. To address this limitation, the polynomial kernel function was incorporated into the mixed kernel configuration of LMIX3-SVR in order to enhance the model’s generalization ability. Compared to LMIX2-SVR, parameters and are additional, which represent the proportion of polynomial kernel function of triple kernel function and the order of the polynomial. The optimal LMIX3-SVR parameter set obtained through PSO is listed below.
In the optimized triple-kernel SVR model, the assigned weights for the RBF, polynomial, and linear components were 0.324:0.515:0.161, which indicates that the polynomial kernel function plays an important role in implementing the inner product operation of the kernel function. Figure 8 shows the optimal prediction result of the LMIX3-SVR model. The values of the training set and the test set in the model are 0.9676 and 0.9632, and the values are 0.0834 and 0.0322. Although the fitting curve appears tight, the minimal difference between training and test values, together with cross-validation and external validation results, indicates that the model achieves high accuracy without overfitting.
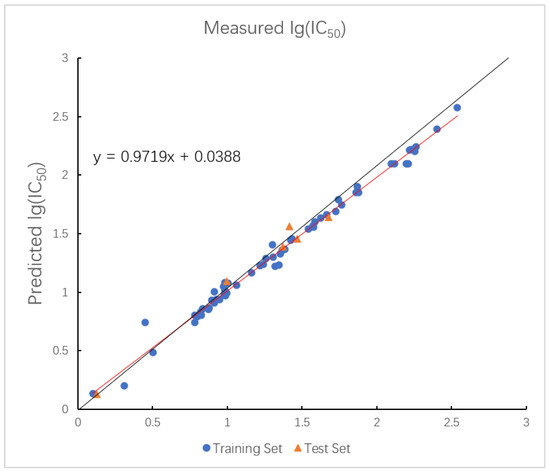
Figure 8.
Plot of measured and predicted lg (IC50) by LMIX3-SVR model. The black line is the y = x line, and the red line is the regression line.
The triple-kernel architecture achieves exceptional generalization performance, demonstrated by a test of 0.9632 and test of 0.0322. The synergistic integration of kernels enhances adaptability to diverse data characteristics: the linear kernel stabilizes low-dimensional projections, the RBF kernel captures complex nonlinear patterns, and the polynomial kernel enables high-dimensional feature representation. The minimal training–test gap of 0.0044 confirms balanced learning capacity and robustness across heterogeneous datasets.
Computational complexity escalates significantly due to concurrent optimization of six interdependent hyperparameters, with high-dimensional polynomial operations substantially increasing training time and resource demands.
2.8. Design of New CatL Inhibitors
The factors affecting the IC50 of the CatL inhibitor were obtained by analyzing the molecular descriptors of the HM model. The nonnormalized coefficients in Table 1 reflect the slope of the regression equation for each independent variable, indicating how much the dependent variable IC50 changes in response to variations in each predictor. The five descriptors were ordered according to their importance: RNR > HDH2(QCP) > YS/YR > MPPBO > MEERCOB.
- “RNR” refers to the relative number of cyclic structures in a compound. Decreasing this value significantly reduces the IC50 value [29].
- “HDH2(QCP)” describes the hydrogen donor charged solvent-accessible surface area. Increasing this value slightly increases the IC50 value [30].
- “YS/YR” is the areas of the shadows S2 of the molecule as projected on the YZ plane. Increasing this value slightly lowers the IC50 value [31].
- “MPPBO” relates to the strength of intramolecular bonding interactions and characterizes the stability of the molecules. A positive coefficient indicates that increasing the value raises the IC50 value [32].
- “MEERCOB” refers to the maximum electron–electron repulsion force of a carbon–oxygen bond. The coefficient of “MEERCOB” indicates that increasing its value slightly increases the IC50 value [30].
In summary, the linear model and interpretation of molecular descriptors have revealed several critical factors influencing the compound activity. In order to design new and ideal CatL inhibitors, the rational approaches include reducing the number of cyclic structures in the compounds and improving intermolecular stability. Therefore, increasing the number of hydrogen bonds may favor the enhancement of the effect. Compound 71 is the most potent compound in the literature because it has the lowest IC50 value [33], and its structural composition can be modified based on these factors. The main adjustment positions of the molecular structure are shown in Figure 9.
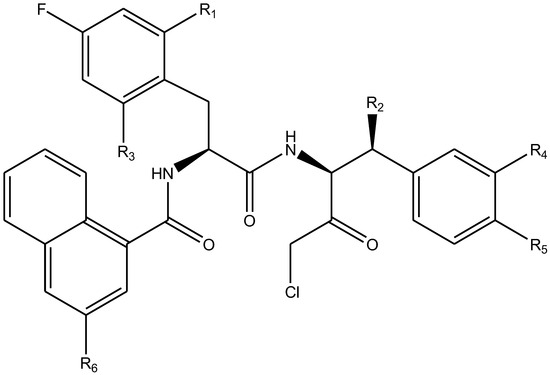
Figure 9.
The design strategy mainly focused on the R region of compound 71.
To attenuate the polar interactions between atoms and improve the distribution of various charges, functional groups such as halogens, carboxyls, hydroxyls, hydrocarboxyls, aldehydes, and amino groups were added and randomly combined at the R1 to R6 positions. Based on the descriptor analysis in the HM model, a group of 578 molecules was designed.
Descriptors of the newly designed molecules were computed using CODESSA, and their IC50 values were subsequently predicted using the HM model. When the predicted IC50 of a compound was below that of compound 71, it was retained for further evaluation and docking via the Property Explorer Applet (PEA). In the end, five compounds had lower IC50 values than compound 71, and Table 5 shows the predicted IC50 values and docking total scores of the newly designed CatL inhibitors.
Table 5.
Predicted IC50 by HM and Docking total score of new CatL inhibitors.
2.9. Property Prediction of New CatL Inhibitors
Property Explorer Applet (PEA) (https://www.organic-chemistry.org accessed on 16 April 2025) was applied to analyze the properties of new compounds. The applet offers real-time prediction of physicochemical properties and assesses potential toxicity risks for user-defined chemical structures. The tool evaluates multiple compound properties, such as partition coefficient, water solubility, topological polar surface area (TPSA), drug likeness, and more.
The partition factor P is described as a particular proportion of solute concentrations between two solvents, and LogP is the logarithm of this ratio. LogP denotes the log-transformed ratio of a compound’s solubility in n-octanol versus water and serves as a standard indicator of hydrophilicity. Compounds with LogP values ≤ 5.0 are more likely to possess good absorption characteristics [34].
Water solubility plays a crucial role in determining the intestinal uptake and cellular distribution of compounds. Enhanced solubility in aqueous environments generally leads to improved absorption of the designed molecules.
TPSA is the total surface area of polar molecules within a compound. The main contribution of TPSA is that it greatly reduces the likelihood of molecules crossing the membrane [35].
Drug likeness is used to evaluate the comparison of objects in terms of bioavailability [36]. Drug score combines the above characteristics into an overall score and is an important criterion for evaluating a compound’s overall potential to become a drug candidate. Table 6 shows the calculated properties of the newly designed compounds by PEA and corresponding predicted IC50 by the HM model.
Table 6.
Predicted IC50 by HM and properties by PEA of newly designed compounds.
2.10. Applicability Domain Analysis
The reliability of predictions was assessed using the applicability domain (AD), defined herein via the leverage method. Predictions for compounds residing within the AD represent interpolations and are thus reliable. In contrast, predictions for compounds located outside the AD constitute extrapolations, entailing higher uncertainty and consequently reduced reliability. Figure 10 demonstrates that all five newly designed compounds and the entire test set exhibited leverage values under the warning threshold ( = 0.25), thereby validating the reliability of their predictions. Nevertheless, the current AD scope is constrained by dataset size—a characteristic limitation of supervised machine learning frequently leading to a narrow AD [37]. The future development of novel anti-SARS-CoV-2 agents holds promise for broadening the model’s chemical space coverage, which will expand its applicability domain and ultimately enhance prediction reliability for emerging viral variants.
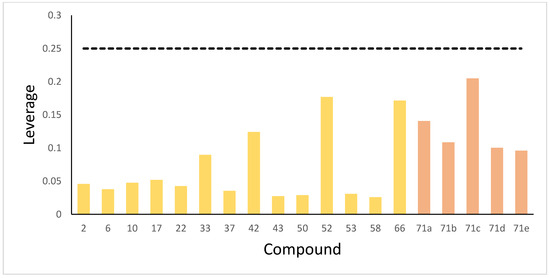
Figure 10.
The leverage of test set compounds and newly designed compounds. The dotted line is the warning threshold.
2.11. Molecular Docking of New CatL Inhibitors
To explore the binding affinities of the newly designed CatL inhibitors, molecular docking studies were carried out using Sybyl-X2.1. The receptor, cathepsin L (PDB ID: 7W33), was prepared by removing all water molecules and heteroatoms. The structure was optimized by adding missing hydrogen atoms and assigning Gasteiger charges to ensure a stable conformation suitable for docking. The protein was energy-minimized using the Tripos force field, a method that ensures proper alignment for molecular docking.
For the ligands (inhibitors), 3D structures were constructed, and charges were assigned using the Gasteiger method. The molecules were minimized using the MMFF94 force field to ensure the stability of their conformations.
Docking was performed using the FlexX docking algorithm within Sybyl-X2.1, which is based on a flexible docking approach. This algorithm first aligns the ligand to the receptor’s active site and then allows the ligand to adjust its conformation to fit the binding pocket of the receptor. The algorithm scores the generated docking poses by calculating their interaction energies, considering factors such as hydrogen bonding, hydrophobic interactions, and electrostatic forces between the ligand and the receptor.
The docking score, reflecting the binding affinity of the ligand to the target protein, was calculated for each compound. The lower the energy score, the more stable the ligand–receptor interaction. The best docking pose was chosen based on the lowest docking energy, suggesting the most stable binding conformation. The binding conformation of compound 71d is shown in Figure 11, where the hydrogen bond interactions are visualized with key residues. Figure 12 shows the 2D molecular docking conformation and binding energy.

Figure 11.
Docking analysis of compound 71d with PDA-related target (PDB ID:7w33).
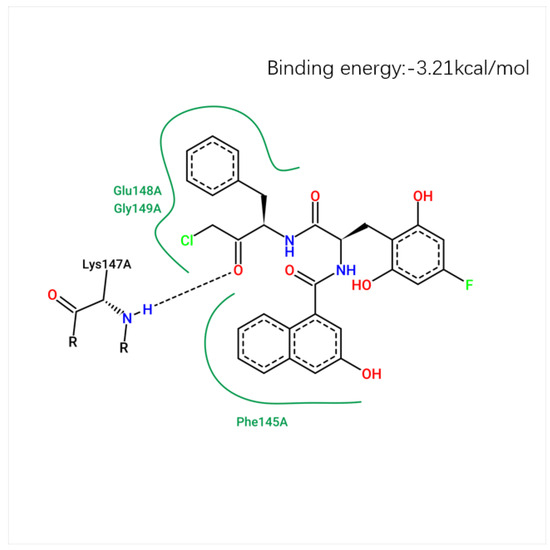
Figure 12.
The 2D molecular docking conformation and binding energy.
Among the newly designed compounds, compound 71d exhibited the most favorable binding affinity, as reflected by a docking score of 5.7972, which was markedly higher than that of compound 71. According to the predicted docking conformation of compound 71d, several key hydrogen bonding interactions are established between the ligand and the active site residues of the target protein. Specifically, oxygen atoms within the core structure of 71d form hydrogen bonds with GLU-148 and LYS-147. The binding site of compound 71d is located in the active site, specifically in the catalytic region of the protein. The hydrogen bond between compound 71d and GLU-148 has a bond length of 2.5 Å, with a bond angle of approximately 151.1°. The hydrogen bond with LYS-147 measures 2.7 Å, with a bond angle of about 173.0°. These interactions are crucial for the stability and inhibitory potential of compound 71d. These interactions are consistent with the binding pattern previously observed in compound 71, suggesting that compound 71d retains essential interaction features of its predecessor. In addition, the oxygen atoms introduced through the newly incorporated structural fragment engage in further hydrogen bonding with GLU-148, thereby enhancing the overall interaction strength. The presence of both conserved and newly formed hydrogen bonds contributes to a more stable and favorable binding conformation. This strong molecular recognition between compound 71d and PDAs supports its potential as a promising lead inhibitor for this protease [27].
3. Discussion
As shown in Table 7, the averages of and for all models are much smaller than 0.2 [38], indicating that there are no chance correlations in the models. All optimal predicted results of models based on HM, GEP, RF, RBF-SVR, LMIX2-SVR, and LMIX3-SVR and their are given in Table 8.
Table 7.
y-Randomization results of different models.
Table 8.
Comparison of prediction and cross-validation results of different methods.
As demonstrated in Table 8, nonlinear models are more adaptable than linear HM models for describing intricate data patterns, but this increased adaptability inevitably makes them more prone to overfitting. As evidenced by the tendency of models such as RF to overfit training data when improperly regularized, this problem can seriously impair generalization performance. Compared to GEP which is often susceptible to converging to a local optimum, SVR offers a distinct advantage for its convex quadratic-based optimization, ensuring that the local optimal solution coincides with the global optimum. In addition, SVR, as opposed to RF, enables the selection and adjustment of kernel functions to better suit the properties of the data and adjust to different distribution patterns. In contrast to RBF-SVR, the difference in between the training set and test set for the LMIX2-SVR model decreases significantly, from 0.04600 to 0.00221. This substantial reduction highlights the critical role of the linear kernel function in improving the generalization ability of the LMIX2-SVR model. Compared to LMIX2-SVR, the values for both the training set and test set in the LMIX3-SVR model show a modest increase of 0.0005 and 0.00222, respectively. Especially, the gap between the training set and test set of the LMIX3-SVR model is reduced to a mere 0.0044, the smallest difference observed between the training set and test set in all models tested, thereby demonstrating that the incorporation of a polynomial kernel function significantly elevates generalization performance of the LMIX3-SVR model.
Because of the synergy between its kernels, LMIX3-SVR outperformed the other two SVR models using distinct kernel functions in both learning and generalization. Furthermore, the cross-validation results also show that the values predicted by the LMIX3-SVR model are the most suitable for the actual data. As shown in Table 9, the LMIX3-SVR model demonstrates excellent generalization ability, as evidenced by the externally validated parameters and , with values of 0.9839, 0.9651, 0.9793, and 0.9632, respectively. These results indicate that the model maintains consistent accuracy across different datasets.
Table 9.
Comparison of statistical parameters of different methods.
The remarkable performance of the models suggests the descriptors selected by HM are indeed the most relevant and effective in capturing the underlying patterns in the data, further confirming the validity of the HM descriptor selection process.
Additionally, the docking results provide further validation for the compounds identified by the regression models. The top compounds, which showed the best predicted IC50 values from the regression models, demonstrated favorable binding affinities in the molecular docking simulations. These compounds not only showed strong interactions with the target protein but also exhibited consistent docking scores with their predicted biological activity. Moreover, the pharmacokinetic properties and toxicity predictions, such as LogP, solubility, and drug likeness, were aligned with the docking results, indicating that these compounds have promising drug-like characteristics. The integration of the regression model, docking analysis, and property predictions presents a comprehensive approach for identifying effective CatL inhibitors, supporting the potential for these compounds to move forward in drug development.
4. Materials and Methods
4.1. Dataset
The dataset of 74 CatL inhibitors was collected from the literature [18] between 2005 and 2023 and they are listed in Table 10, Table 11, Table 12 and Table 13. Information on the chemical structures and IC50 values of the 74 CatL inhibitors is summarized in the tables, with measurements obtained through consistent methodologies and uniform laboratory settings. The dataset was partitioned into training and testing subsets at a 4:1 ratio using a uniform random sampling technique. The internal training set consisted of 60 compounds, which were used for model training and internal cross-validation. The external test set included 14 compounds, which were used to evaluate the model’s prediction accuracy during external validation. In order to test the robustness of the model, 5-fold cross-validation (5-fold) [39] and leave-one-out cross-validation (LOO) were used.
Table 10.
Measured and predicted lg (IC50) of CatL inhibitors 1–42. * The compounds of the test set.
Table 11.
Measured and predicted lg (IC50) of CatL inhibitors 43–55. * The compounds of the test set.
Table 12.
Measured and predicted lg (IC50) of CatL inhibitors 56–67. * The compounds of the test set.
Table 13.
Measured and predicted lg (IC50) of CatL inhibitors 68–74.
To characterize the dataset’s activity profile, the distribution of measured lg (IC50) values was analyzed and visualized (Figure 13). A logarithmic transformation of IC50 values was applied for normalization. The histogram shows lg (IC50) values range from approximately −0.5 (leftmost bin) to 2.5 (rightmost bin), spanning about three orders of magnitude. This broad range reflects diverse inhibitory potency, critical for QSAR modeling as it enables capturing structure–activity relationships across varying strengths. Values are spread across bins without excessive clustering, confirming sufficient activity diversity. The training set (60 compounds) and test set (14 compounds) exhibit overlapping distributions, ensuring test set representativeness for reliable validation.
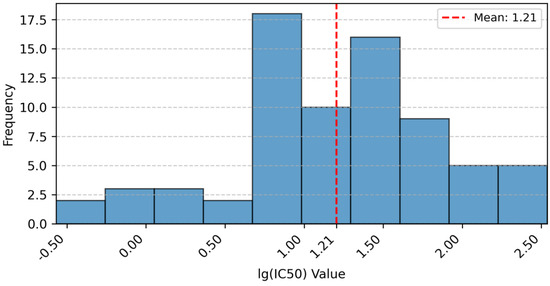
Figure 13.
Distribution of lg (IC50) Values.
4.2. Computation of Molecular Descriptors
Molecular descriptors are calculated using CODESSA2.64 (https://revvitysignals.com accessed on 10 January 2025), which provides a wide range of 2D and 3D descriptors. The descriptors used in this study are 2D descriptors and include topology, composition, and electrostatic properties. These descriptors are used to develop QSAR models to predict IC50 values of CatL inhibitors.
The steps to calculate the molecular descriptors of a compound are shown below.
The molecular structures of all compounds were first plotted in ChemDraw 8.0 software (https://revvitysignals.com accessed on 1 May 2025) and subsequently aromatized where applicable. Subsequently, the structure of the compound was initially optimized by the MM+ molecular mechanical force field in HyperChem 4.0 software (http://hypercubeusa.com accessed on 17 May 2025) and more accurately by semi-empirical PM3 or AM1 methods [40]. The three-step procedure yielded the conformation with the lowest potential energy and optimal structural stability, thereby contributing to more accurate molecular descriptor calculations. Finally, the files obtained from HyperChem were put into the MOPAC 6.9 [41] software (Stewart Computational Chemistry MOPAC Home Page accessed on 11 May 2025) to produce MNO files, and then the MNO files were utilized as input to the CODESSA 2.64 software to compute five classes of molecular descriptors: constitutional, topological, geometrical, electrostatic, quantum chemical from 604 descriptors [42].
4.3. Statistical Parameters
The coefficient of determination, represented by , was utilized as a measurement of the model’s goodness-of-fit [43]. And the root mean square error () was adopted to measure the forecasting accuracy of different models for a particular dataset.
Validating the QSAR model is essential to guarantee its reliability in predicting the biological activity of unknown samples. Model validation includes internal validation, which tests the reproducibility of the model, and external validation, which evaluates the model’s ability to generalize to an independent dataset and its potential for application to novel or external conditions. The internal prediction ability of the model was verified by 5-fold and LOO cross-validation. In addition, four external validation parameters, concordance correlation coefficient (), , , and , were also adopted. Specifically, the concordance correlation coefficient () assesses reproducibility, a fundamental principle that supports the integrity of the scientific method [44]. The , , and assess the external prediction performance of the models [44,45,46,47]. Higher values of these metrics indicate better external prediction capability of the model.
y-Randomization was used to test for chance correlations in the process of constructing models. To ensure the randomness of the models, y-randomization was performed for 100 rounds. and of each round were recorded to calculate the averages. These two parameters were used to indicate whether there were any chance correlations in the models.
4.4. Linear Model by HM
HM, which has no dataset size limitation, is an effective method for descriptor selection and linear model construction [48]. After obtaining descriptors from CODESSA, preselection is performed to exclude nonuniversal descriptors, constants, highly correlated ones (correlation > 0.8), and those with low F-test or t-values [27,47]. The remaining descriptors are used to build HM linear regression models. The performance of these models depends on the number of selected descriptors, with the optimal number determined by the point at which adding more descriptors does not significantly improve model accuracy. The selected descriptors are then used in subsequent nonlinear models for further analysis.
4.5. Calculate Feature Importance by XGBoost
An efficient method is required to optimize nonlinear models and reveal nonlinear interactions among descriptors in complicated datasets. XGBoost is useful for evaluating feature importance by assessing the contribution of each descriptor to model performance.
The coverage method and the split gain method are the two approaches commonly employed in XGBoost to determine feature importance. The split gain approach calculates the increase in prediction accuracy that occurs when decision tree nodes are split using a feature. Higher split gain features are thought to be more significant because they capture more nuanced, nonlinear relationships between descriptors.
The split gain method was applied in this study due to its suitability for uncovering complex relationships within the data. In XGBoost, the importance of molecular descriptors is assessed based on their split gain during the construction of decision trees. Descriptors with higher split gain values, such as hydrophobicity and hydrogen bond counts, show strong associations with inhibitory activity and contribute significantly to predictive performance. The algorithm automatically identifies these key features, while regularization parameters such as lambda and gamma help control model complexity and reduce the risk of overfitting. This approach enhances predictive accuracy and offers valuable insights into the structure–activity relationships of CatL inhibitors.
4.6. Nonlinear Model by GEP
Given the inherent complexity and nonlinearity of factors influencing the inhibitory effects of CatL targeting compounds, gene expression programming (GEP) was employed to construct a nonlinear model for predicting their IC50 values.
GEP is a new type of adaptive evolution algorithm based on the invention of biological gene structure and function. GEP was developed from genetic algorithms (GAs) and genetic programming (GP) [49,50,51,52], which absorbs the advantages of both but overcomes the shortcomings of both, and its distinctive feature is that it can solve complex problems with simple coding.
GEP uses a unique chromosome-based encoding method that optimizes both the model structure and its parameters simultaneously. This characteristic enables GEP to effectively capture nonlinear relationships between molecular descriptors and biological activity while maintaining strong predictive performance. As a result, GEP is particularly suitable for modeling the complex relationships observed in the CatL inhibitor dataset.
4.7. Nonlinear Model by RF
Random forest (RF) regression is an ensemble learning algorithm that constructs multiple decision trees and averages their predictions to perform regression tasks [53]. Each tree is trained on a random subset of samples, which helps reduce overfitting. The final prediction is obtained by averaging the results from all decision trees. RF regression is particularly effective for handling high-dimensional data, missing values, and diverse data distributions. It also provides assessable feature importance and reliable predictions with uncertainty estimation [54]. These advantages make RF regression useful for predicting the IC50 value of CatL inhibitors.
The standardized descriptor set was employed to train an optimized RF model, configured with an ensemble of decision trees and constrained leaf node sizes to maintain an optimal balance between predictive accuracy and computational efficiency. Through the training process, the model quantitatively assessed descriptor contributions while capturing complex nonlinear relationships between molecular features and inhibitory potency. Rigorous five-fold cross-validation confirmed model reliability. This dual function model enables accurate IC50 prediction for novel CatL inhibitors.
4.8. Nonlinear Models by SVR
Support vector regression (SVR), an extension of support vector machine (SVM), seeks a hyperplane that optimally fits continuous data points [55]. SVM maps data to a high-dimensional space to find the best separating hyperplane for classification or regression [56]. Maximizing the margin between samples and the hyperplane enhances prediction accuracy.
SVR differs from SVM in that it focuses on minimizing the overall deviation of all data points from the regression hyperplane, rather than maximizing the margin between the hyperplane and the nearest data points. SVR imported the -insensitive loss function to penalize errors beyond a specified threshold , which improves robustness and generalization ability of the model. In addition, penalization parameter serves as a regularization term that regulates the penalty applied to classification errors and slack variables and which are introduced as tolerance allowing some samples at the boundary of classification errors or intervals. The final optimization problem is as follows in Equation (3).
To simplify the solution for SVR, Lagrange multipliers are introduced. If the Karush–Kuhn–Tucker conditions are satisfied, the dual problem can be solved by quadrature phase procedures [56]. The final solution is as in Equation (4).
The is the kernel function to be introduced in the next section.
4.8.1. SVR Kernel Function
Standard SVR struggles with nonlinear data due to the reliance on linear decision boundaries. To address this, complex data are mapped to a higher-dimensional space at the cost of increasing complexity and overfitting risk. Kernel functions solve this by efficiently computing inner products in the transformed space, avoiding explicit high-dimensional mappings and simplifying the handling of complex data. Basic kernel functions include the radial basis function (RBF) [57], the linear kernel function, the polynomial kernel function, and the sigmoid kernel function. The initial three kernel functions have been extensively used when establishing models by SVR [58].
However, considering the disadvantages of single kernel functions and the complementarity between popular kernel functions in handling complex datasets, it is necessary and reasonable to construct mixed kernel functions to meet the requirements. In fact, any function kernel that satisfies the theorem of Mercer can be used as a kernel function, which provides many ways to construct new kernel functions. If are kernel functions, then:
- 1
- is a kernel function.
- 2
- is a kernel function.
More importantly, integrating several basic kernel functions into mixed kernel functions means they are able to complement each other, thus overcoming their respective shortcomings.
The theorem of Mercer is defined as such that if satisfies Mercer’s premise shown in Equation (5) which means that is a semidefinite function [59].
Then it can be expressed in the form of a series expansion of the above-mentioned eigenvalues and eigenfunctions. This implies that can be represented as an inner product in some high-dimensional feature space.
4.8.2. Nonlinear Model
RBF is a universal kernel function that can be employed without prior knowledge of the data [60,61,62,63]. RBF stands out for its good learning ability and efficiency among all basic kernel functions [64]. However, the model exhibits limited generalization performance. The RBF kernel can be expressed as Equation (6).
SVR that adopted as its kernel function is called RBF-SVR.
The linear kernel is the most basic among all kernel functions, as it simply calculates the inner product between two feature vectors. Moreover, the linear kernel function has the advantages of strong learning ability which is restricted to linear relationships and effectively improves the generalization ability when the dataset is linearly separable and low-dimensional. However, since the linear kernel is limited to computing a simple inner product between feature vectors, its modeling capacity is inherently constrained. Consequently, the linear kernel typically achieves lower accuracy compared to more flexible kernel functions when handling nonlinear problems [65], but it efficiently identifies key feature vectors with minimal computational cost. The linear kernel is defined in Equation (7).
The polynomial kernel function is one of the most widely used nonlinear kernel functions, as it extends the linear kernel by introducing polynomial combinations of feature interactions. Unlike the linear kernel, which only computes a simple dot product, the polynomial kernel maps data into a higher-dimensional space, enabling the learning of complex nonlinear relationships. Moreover, the polynomial kernel function possesses the advantage of adjustable flexibility, governed by its degree parameter, which enables it to model a broad spectrum of decision boundaries spanning approximately linear to highly curved surfaces. This makes it particularly effective when data exhibits polynomial patterns or multiplicative feature dependencies. The polynomial kernel function demonstrates strong generalization performance due to its global approximation properties. However, this comes at the expense of weaker local learning capabilities, as the polynomial kernel tends to smooth over fine-grained variations in the feature space. The polynomial kernel can be expressed as Equation (8).
To overcome the limitations of individual kernel functions while preserving their respective advantages, some kinds of mixed kernel functions incorporating different numbers of individual kernel functions were proposed.
The linear kernel function demonstrates strong learning capability and excellent generalization performance for linearly separable and low-dimensional datasets. However, its effectiveness is fundamentally limited to linear relationships. In comparison, the RBF kernel function shows superior learning ability in handling nonlinear and high-dimensional datasets, with relatively weaker generalization performance. To leverage their complementary strengths, a mixed kernel function combining both the RBF and linear kernels was proposed. The mixed kernel function that linearly combines the RBF kernel function and linear kernel function allows the linear kernel to enhance the overall generalization ability while the RBF kernel improves the learning capability for complex patterns, thereby achieving balanced performance across different data characteristics. The form of this new double-kernel function can be expressed as Equation (9).
SVR that adopted as its kernel function is called LMIX2-SVR.
The variable α takes values within the interval [0, 1].
To overcome the limitations of the linear kernel function, which exhibits strong generalization performance only for low-dimensional and linearly separable datasets but struggles with high-dimensional and nonlinear datasets, a mixed kernel function is constructed by incorporating the RBF kernel function, linear kernel function, and polynomial kernel function.
The polynomial kernel further enhances nonlinear modeling by incorporating feature interactions through its adjustable degree parameter. Importantly, the polynomial kernel improves generalization in high-dimensional and nonlinear datasets, effectively compensating for the deficiency of the linear kernel in these scenarios.
The proposed mixed kernel function combines three complementary kernel functions including the linear kernel for low-dimensional linear separability, the RBF kernel for nonlinear pattern recognition, and the polynomial kernel for high-dimensional feature representation. This comprehensive integration achieves optimal balance between learning capacity and generalization ability across diverse data characteristics.
The form of the new triple-kernel function can be expressed as Equation (10).
SVR that adopted as its kernel function is called LMIX3-SVR.
The coefficients α and β are positive and satisfy the constraint α + β ≤ 1.
4.8.3. SVR Model Optimized by Particle Swarm Optimization (PSO)
The performance and generalization capacity of SVR models are highly sensitive to parameter settings. When constructing a model using a triple kernel SVR, six parameters require optimization: the penalty factor , the insensitive parameter , the kernel radius of RBF kernel function , the order of polynomial kernel function , the coefficient of RBF kernel function , and the coefficient of polynomial kernel function . Their search scope is as follows. , , , , , .
The optimization process becomes more difficult as the number of parameters of SVR increases. To address the limitations of conventional parameter tuning techniques such as grid and random search, particle swarm optimization (PSO) was employed to optimize model parameters during the construction of the three SVR-based models.
Particle swarm optimization (PSO), introduced in 1995, draws inspiration from the social behavior of bird flocks searching for optimal routes through shared information. The algorithm initializes particle positions and velocities using random values in a high-dimensional space and iteratively refines them through both individual learning and collective swarm interactions. In PSO algorithms, particles only pass optimal information during iterations. Therefore, PSO has the advantages of fast convergence speed, few parameters, and simple and easy implementation of algorithms.
PSO uses a velocity–position model, where the position and velocity of particles in D-dimensional solution space can be expressed as Equations (11) and (12).
The optimal position of particle is denoted as , the global best position is denoted as . In each iteration, particles track the , , and their previous states to adjust the position and velocity at the current moment. The iterative Equations (13) and (14) are as follows.
, , , are the velocity and position of the particle at the current time and the next time. is a random number in range . and are learning factors which are usually set to 2. is a weight factor, and its value automatically decreases with the iteration of the algorithm to speed up the convergence speed [66]. It is described as Equation (15).
represents the current iteration count, denotes the predefined upper limit. The parameters , correspond to the upper and lower bounds of the inertia weight, respectively [67].
4.9. Applicability Domain
The applicability domain (AD) is a vital mechanism for guaranteeing the reliability of predictive models. In this research, the AD served to quantify the uncertainty in predicting the activity of a specific compound. This assessment was accomplished by determining the compound’s structural similarity to those comprising the training set [68]. Specifically, the leverage method defined in Equation (16) was applied.
In this context, and denote the descriptor matrix for the test compound and the training set compounds, respectively, with the superscript indicating the matrix transpose. The warning threshold is established as , where signifies the number of model descriptors and corresponds to the number of training compounds. Compounds exhibiting a leverage value exceeding this threshold are deemed to lie beyond the AD [69].
4.10. Property Prediction and Molecular Docking
Based on a number of carefully chosen molecular descriptors that correspond to the activity of a compound and the ensuing data analysis, the QSAR model is crucial to the creation of new pharmaceuticals. In drug discovery, achieving potent binding affinity to the target is critical for identifying viable drug candidates. Furthermore, key drug-like properties, such as pharmacokinetics and toxicity profiles, are vital factors in determining whether a compound progresses to clinical development [70].
Molecular docking is a key tool in structural molecular biology and computer-aided drug design [71]. The objective of ligand–protein docking is to predict the primary binding mode between a ligand and a known three-dimensional protein. In this study, Sybyl-X 2.1 software was used to explore the potential interactions between the newly designed CatL inhibitors and the target protein at the binding site. The target protein, cathepsin L (PDB code: 7w33), was retrieved from the Protein Data Bank. The binding site was identified based on the known binding position of the ligand. The GRID for docking was marked according to the ligand’s original binding site, using standard parameters in Sybyl-X. The receptor was kept rigid during docking, while the ligand was allowed to flex within the binding site. To validate the docking protocol, redocking was performed to ensure the ligand could dock successfully to its original position in the target’s binding site. The docked conformations were then evaluated based on their binding affinities and interactions with key amino acid residues.
The docking procedure involved several steps: first, the input chemical structure was optimized using Sybyl-X. The Tripos force field was then applied to minimize the molecules and assign Gasteiger–Hückel charges until convergence was reached (0.05 kcal/mol/Å). Next, the protein structure was processed in Sybyl-X by removing irrelevant ligands and solvent molecules, ensuring proper alignment for docking. Finally, PyMol software (http://www.pymol.org/pymol accessed on 15 June 2025) was used to visualize the docking results.
5. Conclusions
This study demonstrates the strong predictive performance and robustness of the LMIX3-SVR model, which integrates linear, polynomial, and RBF kernels for effective QSAR analysis of CatL inhibitors. The PSO algorithm optimized the model parameters, enabling rapid convergence and reducing computational time. Five new CatL inhibitors were designed based on key descriptors from the HM model, with compound 71d showing the most potent activity and the highest docking score (5.7972).
The designed inhibitors exhibited favorable binding affinities, particularly compound 71d, which suggests it as a promising high-affinity ligand for CatL. Toxicity predictions indicated medium risk. The compounds were also chosen for their synthetic feasibility, with predicted pharmacokinetic properties such as LogP, solubility, and drug likeness, suggesting good bioavailability and body distribution.
In conclusion, the LMIX3-SVR model proved effective in designing CatL inhibitors with promising pharmacological profiles, providing a strong foundation for further experimental validation and drug development to accelerate the discovery of safer, more effective anti-SARS-CoV-2 therapeutics.
Author Contributions
S.L.: writing—original draft, conceptualization, formal analysis, investigation. Z.L.: writing—original draft, data curation, visualization. P.Z.: methodology. A.Q.: software, supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries may be addressed to the corresponding author.
Acknowledgments
The authors sincerely acknowledge Weilong Deng, Xiao Hu, and their colleagues at Nankai University for generously providing the experimental data used in this study. The authors would like to thank Qingdao University for supporting the undergraduate innovation and entrepreneurship training program of Qingdao University. We would like to express our deepest gratitude to our mentor Aili Qu, who is the corresponding author of this article. Her deep expertise has helped shape our research questions and approaches.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Lamers, M.M.; Haagmans, B.L. SARS-CoV-2 pathogenesis. Nat. Rev. Microbiol. 2022, 20, 270–284. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. World Health Organization Director-General’s Opening Remarks at the Media Briefing on COVID-19; WHO: Geneva, Switzerland, 2020. [Google Scholar]
- Zhou, P.; Yang, X.L.; Wang, X.G.; Hu, B.; Zhang, L.; Zhang, W.; Si, H.R.; Zhu, Y.; Li, B.; Huang, C.L.; et al. A pneumonia outbreak associated with a new coronavirus of probable bat origin. Nature 2020, 579, 270–273. [Google Scholar] [CrossRef]
- Holmes, E.C.; Goldstein, S.A.; Rasmussen, A.L.; Robertson, D.L.; Crits-Christoph, A.; Wertheim, J.O.; Anthony, S.J.; Barclay, W.S.; Boni, F.M.; Donhert, P.C.; et al. The origins of SARS-CoV-2: A critical review. Cell 2021, 184, 4848–4856. [Google Scholar] [CrossRef] [PubMed]
- Hu, B.; Guo, H.; Zhou, P.; Shi, Z.L. Characteristics of SARS-CoV-2 and COVID-19. Nat. Rev. Microbiol. 2021, 19, 141–154. [Google Scholar] [CrossRef]
- Cao, Y.; Wang, J.; Jian, F.; Xiao, T.; Song, W.; Yisimayi, A.; Huang, W.; Li, Q.; Wang, P.; An, R.; et al. Omicron escapes the majority of existing SARS-CoV-2 neutralizing antibodies. Nature 2022, 602, 657–663. [Google Scholar] [CrossRef]
- Uraki, R.; Halfmann, P.J.; Iida, S.; Yamayoshi, S.; Furusawa, Y.; Kiso, M.; Ito, M.; Iwatsuki-Horimoto, K.; Mine, S.; Kuroda, M.; et al. Characterization of SARS-CoV-2 Omicron BA. 4 and BA. 5 isolates in rodents. Nature 2022, 612, 540–545. [Google Scholar] [CrossRef]
- Tamura, T.; Irie, T.; Deguchi, S.; Yajima, H.; Tsuda, M.; Nasser, H.; Mizuma, K.; Planchaisuk, A.; Suzuki, S.; Uriu, K.; et al. Virological characteristics of the SARS-CoV-2 Omicron XBB. 1.5 variant. Nat. Commun. 2024, 15, 1176. [Google Scholar] [CrossRef]
- Qu, P.; Faraone, J.N.; Evans, J.P.; Zheng, Y.M.; Carlin, C.; Anghelina, M.; Stevens, P.; Fernandez, S.; Jones, D.; Panchal, A.R.; et al. Enhanced evasion of neutralizing antibody response by Omicron XBB.1.5, CH.1.1, and CA.3.1 variants. Cell Rep. 2023, 42, 112443. [Google Scholar] [CrossRef]
- Zhao, X.J.; Li, X.L.; Zhang, S.; Chen, J.J.; Zhao, W.C.; Wu, N.N.; Wang, R.J.; Xu, Q.; Lv, C.L.; Jiang, B.G.; et al. Dynamic changes of neutralizing antibody and memory T cell responses six months post Omicron XBB reinfection. Front. Immunol. 2024, 15, 1477721. [Google Scholar] [CrossRef]
- Le, T.T.; Andreadakis, Z.; Kumar, A.; Román, R.G.; Tollefsen, S.; Saville, M.; Mayhew, S. The COVID-19 vaccine development landscape. Nat. Rev. Drug Discov. 2020, 19, 305–306. [Google Scholar] [CrossRef] [PubMed]
- DeRoo, S.S.; Pudalov, N.J.; Fu, L.Y. Planning for a COVID-19 vaccination program. JAMA 2020, 323, 2458–2459. [Google Scholar] [CrossRef] [PubMed]
- Ansems, K.; Grundeis, F.; Dahms, K.; Mikolajewska, A.; Thieme, V.; Piechotta, V.; Metzendorf, M.-I.; Stegemann, M.; Benstoem, C.; Fichtner, F. Remdesivir for the treatment of COVID-19. Cochrane Database Syst. Rev. 2021. [Google Scholar] [CrossRef]
- Jayk Bernal, A.; Gomes da Silva, M.M.; Musungaie, D.B.; Kovalchuk, E.; Gonzalez, A.; Delos Reyes, V.; Martín-Quirós, A.; Caraco, Y.; Williams-Diaz, A.; Brown, M.L.; et al. Molnupiravir for oral treatment of Covid-19 in nonhospitalized patients. N. Engl. J. Med. 2022, 386, 509–520. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, C.; Li, D.; He, J.; Liu, S.; Deng, H.; Cheng, J.; Du, J.; Liu, X.; Chen, H.; et al. COVID-19 receptor and malignant cancers: Association of CTSL expression with susceptibility to SARS-CoV-2. Int. J. Biol. Sci. 2022, 18, 2362. [Google Scholar] [CrossRef]
- Willett, B.J.; Grove, J.; MacLean, O.A.; Wilkie, C.; De Lorenzo, G.; Furnon, W.; Cantoni, D.; Scott, C.; Logan, N.; Ashraf, S.; et al. SARS-CoV-2 Omicron is an immune escape variant with an altered cell entry pathway. Nat. Microbiol. 2022, 7, 1161–1179. [Google Scholar] [CrossRef]
- Zhao, M.M.; Yang, W.L.; Yang, F.Y.; Zhang, L.; Huang, W.J.; Hou, W.; Fan, C.-F.; Jing, R.-H.; Feng, Y.-M.; Wang, T.-C.; et al. Cathepsin L plays a key role in SARS-CoV-2 infection in humans and humanized mice and is a promising target for new drug development. Signal Transduct. Target. Ther. 2021, 6, 134. [Google Scholar] [CrossRef]
- Deng, W.; Hu, X.; Tian, X.; Zhang, Y.; Shang, W.; Zhang, L.; Shang, L. Peptidomimetic Analogues Act as effective inhibitors against SARS-CoV-2 by blocking the function of Cathepsin L. J. Med. Chem. 2024, 67, 17124–17143. [Google Scholar] [CrossRef]
- An, L.Y.; Xiang, Y.H.; Zhang, Z.Y.; Hu, W.X. The new advance and applications of quantitative structure-activity relationship. J. Cap. Normal Univ. 2006, 27, 52–57. [Google Scholar]
- Chen, C.; Si, H. QSAR models of Celecoxib analogues and derivatives as COX-2 inhibitor to predict their anti-inflammatory effect. Cancer Cell 2021, 33, 827–835. [Google Scholar]
- Roy, K.; Narayan Das, R. A review on principles, theory and practices of 2D-QSAR. Curr. Drug Metab. 2014, 15, 346–379. [Google Scholar] [CrossRef] [PubMed]
- Varmuza, K.; Dehmer, M.; Bonchev, D. Statistical Modelling of Molecular Descriptors in QSAR/QSPR; Wiley Online Library: Hoboken, NJ, USA, 2012. [Google Scholar] [CrossRef]
- Consonni, V.; Todeschini, R. Molecular descriptors. In Recent Advances in QSAR Studies: Methods and Applications; Springer: Berlin/Heidelberg, Germany, 2010; pp. 29–102. [Google Scholar] [CrossRef]
- Vilar, S.; Cozza, G.; Moro, S. Medicinal chemistry and the molecular operating environment (MOE): Application of QSAR and molecular docking to drug discovery. Curr. Top. Med. Chem. 2008, 8, 1555–1572. [Google Scholar] [CrossRef]
- Si, Y.; Ma, K.; Hu, Y.; Si, H.; Zhai, H. QSAR model study of 2, 3, 4, 5-tetrahydro-1H-pyrido [4, 3-b] indole of cystic-brosis-transmembrane conductance-regulator gene potentiators. Lett. Drug Des. Discov. 2022, 19, 269–278. [Google Scholar] [CrossRef]
- Yamada, M.; Tang, J.; Lugo-Martinez, J.; Hodzic, E.; Shrestha, R.; Saha, A.; Ouyang, H.; Yin, D.; Mamistuka, H.; Sahinalp, C.; et al. Ultra high-dimensional nonlinear feature selection for big biological data. IEEE Trans. Knowl. Data Eng. 2018, 30, 1352–1365. [Google Scholar] [CrossRef]
- Gao, Z.; Xia, R.; Zhang, P. Prediction of anti-proliferation effect of [1, 2, 3] Triazolo [4, 5-d] pyrimidine derivatives by random forest and mix-kernel function SVM with PSO. Chem. Pharm. Bull. 2022, 70, 684–693. [Google Scholar] [CrossRef]
- Liu, X.; Chen, X.; Li, J.; Zhou, X.; Chen, Y. Facies identification based on multikernel relevance vector machine. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7269–7282. [Google Scholar] [CrossRef]
- Xu, H.; Wang, J.; Sun, H.; Lv, M.; Tian, X.; Yao, X.; Zhang, X. Semisynthesis and quantitative structure− activity relationship (QSAR) study of novel aromatic esters of 4′-demethyl-4-deoxypodophyllotoxin as insecticidal agents. J. Agric. Food Chem. 2009, 57, 7919–7923. [Google Scholar] [CrossRef]
- Clementi, E.; Clementi, E. Complexity Because of the Number of Components in the Chemical System. In Computational Aspects for Large Chemical Systems; Springer: Berlin/Heidelberg, Germany, 1980; pp. 86–177. [Google Scholar] [CrossRef]
- Ni, Z.; Lin, X. Insight into substituent effects in Cal-B catalyzed transesterification by combining experimental and theoretical approaches. J. Mol. Model. 2013, 19, 349–358. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Luan, F.; Si, H.; Hu, Z.; Liu, M. Prediction of retention times for a large set of pesticides or toxicants based on support vector machine and the heuristic method. Toxicol. Lett. 2007, 175, 136–144. [Google Scholar] [CrossRef] [PubMed]
- Xue, H.; Zhang, R.; Yan, X.; Wang, R.; Zhang, P. Study of PARP inhibitors for breast cancer based on enhanced multiple kernel function SVR with PSO. Front. Pharmacol. 2024, 15, 1257253. [Google Scholar] [CrossRef]
- Kwon, Y. Handbook of Essential Pharmacokinetics, Pharmacodynamics and Drug Metabolism for Industrial Scientists; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Ertl, P.; Rohde, B.; Selzer, P. Fast calculation of molecular polar surface area as a sum of fragment-based contributions and its application to the prediction of drug transport properties. J. Med. Chem. 2000, 43, 3714–3717. [Google Scholar] [CrossRef]
- Smith, G.F. Designing drugs to avoid toxicity. In Progress in Medicinal Chemistry; Elsevier: Amsterdam, The Netherlands, 2011; Volume 50, pp. 1–47. [Google Scholar] [CrossRef]
- Boonpalit, K.; Kinchagawat, J.; Namuangruk, S. Expanding the applicability domain of machine learning model for advancements in electrochemical material discovery. ChemElectroChem 2024, 11, e202300681. [Google Scholar] [CrossRef]
- Kiralj, R.; Ferreira, M. Basic validation procedures for regression models in QSAR and QSPR studies: Theory and application. J. Braz. Chem. Soc. 2009, 20, 770–787. [Google Scholar] [CrossRef]
- Wong, T.T.; Yeh, P.Y. Reliable accuracy estimates from k-fold cross validation. IEEE Trans. Knowl. Data Eng. 2019, 32, 1586–1594. [Google Scholar] [CrossRef]
- Klein, E.; Matis, M.; Lukeš, V.; Cibulková, Z. The applicability of AM1 and PM3 semi-empirical methods for the study of N–H bond dissociation enthalpies and ionisation potentials of amine type antioxidants. Polym. Degrad. Stab. 2006, 91, 262–270. [Google Scholar] [CrossRef]
- Stewart, J.J. MOPAC: A semiempirical molecular orbital program. J. Comput.-Aided Mol. Des. 1990, 4, 1–103. [Google Scholar] [CrossRef]
- Wright, J.S.; Carpenter, D.J.; McKay, D.J.; Ingold, K.U. Theoretical calculation of substituent effects on the O− H bond strength of phenolic antioxidants related to vitamin E. J. Am. Chem. Soc. 1997, 119, 4245–4252. [Google Scholar] [CrossRef]
- Dangeti, P. Statistics for Machine Learning; Packt Publishing Ltd.: Mumbai, India, 2017. [Google Scholar]
- Glantz, S.A.; Slinker, B.K.; Neilands, T.B. Primer of Applied Regression & Analysis of Variance; McGraw-Hill Education: New York, NY, USA, 1990; Available online: https://cir.nii.ac.jp/crid/1970867909850138513 (accessed on 1 January 2025).
- Lawrence, I.; Lin, K. A concordance correlation coefficient to evaluate reproducibility. Biometrics 1989, 255–268. [Google Scholar] [CrossRef]
- Consonni, V.; Ballabio, D.; Todeschini, R. Comments on the definition of the Q 2 parameter for QSAR validation. J. Chem. Inf. Model. 2009, 49, 1669–1678. [Google Scholar] [CrossRef]
- Tropsha, A.; Gramatica, P.; Gombar, V.K. The importance of being earnest: Validation is the absolute essential for successful application and interpretation of QSPR models. QSAR Comb. Sci. 2003, 22, 69–77. [Google Scholar] [CrossRef]
- Schuurmann, G.; Ebert, R.U.; Chen, J.; Wang, B.; Kuhne, R. External validation and prediction employing the predictive squared correlation coefficient Test set activity mean vs training set activity mean. J. Chem. Inf. Model. 2008, 48, 2140–2145. [Google Scholar] [CrossRef]
- Ferreira, C. Gene expression programming: A new adaptive algorithm for solving problems. arXiv 2001. [Google Scholar] [CrossRef]
- Haupt, R.L.; Haupt, S.E. Practical Genetic Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Mirjalili, S.; Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 43–55. [Google Scholar] [CrossRef]
- Ferreira, C. Gene Expression Programming: Mathematical Modeling by An Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2006; Volume 21. [Google Scholar]
- Rigatti, S.J. Random forest. J. Insur. Med. 2017, 47, 31–39. [Google Scholar] [CrossRef]
- Lewis, R.J. An introduction to classification and regression tree (CART) analysis. In Annual Meeting of the Society for Academic Emergency Medicine in San Francisco, California; Department of Emergency Medicine Harbor-UCLA Medical Center Torrance: San Francisco, CA, USA, 2000; Volume 14. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Rojo-Álvarez, J.L.; Martínez-Ramón, M.; Camps-Valls, G. Support vector machines in engineering: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2014, 4, 234–267. [Google Scholar] [CrossRef]
- Hussain, M.; Wajid, S.K.; Elzaart, A.; Berbar, M. A comparison of SVM kernel functions for breast cancer detection. In Proceedings of the 2011 eighth international conference computer graphics, imaging and visualization, Singapore, 17–19 August 2011; IEEE: New York, NY, USA; pp. 145–150. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B.S. Support vector machine in machine condition monitoring and fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 2560–2574. [Google Scholar] [CrossRef]
- Chen, D.G.; Wang, H.Y.; Tsang, E.C. Generalized Mercer theorem and its application to feature space related to indefinite kernels. In Proceedings of the 2008 International Conference on Machine Learning and Cybernetics, Kunming, China, 12–15 July 2008; IEEE: New York, NY, USA; Volume 2, pp. 774–777. [Google Scholar] [CrossRef]
- Yang, X.; Qiu, H.; Zhang, Y.; Zhang, P. Quantitative structure–activity relationship study of amide derivatives as xanthine oxidase inhibitors using machine learning. Front. Pharmacol. 2023, 14, 1227536. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, P. Prediction of histone deacetylase inhibition by triazole compounds based on artificial intelligence. Front. Pharmacol. 2023, 14, 1260349. [Google Scholar] [CrossRef]
- Dong, W.; Zhang, P. Predicting anti-trypanosome effect of carbazole-derived compounds by powerful SVM with novel kernel function and comprehensive learning PSO. Antimicrob. Agents Chemother. 2024, 68, e00265-24. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Z.; Qu, A.; Zhang, P.; Si, H.; Zhai, H. Study of tacrine derivatives for acetylcholinesterase inhibitors based on artificial intelligence. Lat. Am. J. Pharm. 2020, 39, 1159–1170. [Google Scholar]
- An-na, W.; Yue, Z.; Yun-tao, H.; Yun-lu, L.I. A novel construction of SVM compound kernel function. In Proceedings of the 2010 International Conference on Logistics Systems and Intelligent Management (ICLSIM), Harbin, China, 9–10 January 2010; IEEE: New York, NY, USA; Volume 3, pp. 1462–1465. [Google Scholar] [CrossRef]
- Zhang, R. Research on student-centered financial aid to college students with financial difficulties. In 2020 International Conference on Management, Economy and Law (ICMEL 2020); Atlantis Press: Paris, France, 2020; pp. 349–352. [Google Scholar] [CrossRef]
- Mesquita, R.J.M. A Novel Path Planning Optimization Algorithm for Semi-Autonomous UAV in Bird Repellent Systems Based in Particle Swarm Optimization. Master’s Thesis, Universidade da Beira Interior (Portugal), Covilhã, Portugal, 2021. [Google Scholar]
- Xiong, W.L.; Xu, B.G. Study on optimization of SVR parameters selection based on PSO. J. Syst. Simul. 2006, 18, 2442–2445. [Google Scholar]
- Roy, K.; Kar, S.; Ambure, P. On a simple approach for determining applicability domain of QSAR models. Chemom. Intell. Lab. Syst. 2015, 145, 22–29. [Google Scholar] [CrossRef]
- Sahigara, F.; Mansouri, K.; Ballabio, D.; Mauri, A.; Consonni, V.; Todeschini, R. Comparison of different approaches to define the applicability domain of QSAR models. Molecules 2012, 17, 4791–4810. [Google Scholar] [CrossRef]
- Di, L.; Kerns, E.H.; Carter, G.T. Drug-like property concepts in pharmaceutical design. Curr. Pharm. Des. 2009, 15, 2184–2194. [Google Scholar] [CrossRef]
- Morris, G.M.; Lim-Wilby, M. Molecular docking. In Molecular Modeling of Proteins; Springer: Berlin/Heidelberg, Germany, 2008; pp. 365–382. [Google Scholar] [CrossRef]














































































































Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).