1. Introduction
Human sensations during interaction with the physical world through tools or the skin are rich and varied. A person feels physical properties, such as strength, force, texture, and temperature, when holding objects in their hand or pressing them. This information is used when a person handles, grasps, and picks up various types of objects. For example, when picking up a variety of rigid objects, such as paper cups or glass cups, a person recognizes the physical properties of the object and handles the object according to that information. Another example is that surgeons feel the interaction force when they palpate organs during medical examinations, and pull thread using forceps during endoscopic surgery.
Recently, with the development of the robot industry, it has become important to use this information to help robots interact with the physical environment by sensing the properties of objects during their interaction. Service robots located in a human environment should be able to perform dexterous manipulation tasks in various conditions. Several studies have shown the interaction between a robot and its physical environment by sensing the physical properties, such as force [
1,
2,
3], texture [
4,
5,
6], and object shape [
7], using various sensors. In particular, the main physical property that a robot grasping and interacting with objects needs to sense is the interaction force. For measuring this interaction force during the robot’s interaction with the environment, a tactile sensor [
8,
9] is used to sense a small force, such as a human skin sensation, and a force/torque sensor [
10,
11] to sense a larger force, such as a human kinesthetic force. Operations involving picking up an object by hand require a richer tactile and kinesthetic sense than that which the current systems provide in order to achieve human-level performance [
12]. Furthermore, the physical sensors developed thus far have limitations in terms of their implementation, such as high cost or difficulty in attaching them to a real physical robot and other systems. In the case of a surgical robot, to measure the interaction force of forceps, various types of sensor, such as capacitive [
13], piezoresistive [
14], optoelectric [
15,
16], and strain gauge sensors [
17], are used. However, a commercially available surgical robot is controlled remotely without haptic feedback, because it is difficult to attach a force measurement sensor to the forceps due to limited space, safe packaging, warm gas sterilization, and error-inducing EMI from electrocautery. Therefore, surgeons estimate the interaction force through a monitor when using this type of robot.
To reduce these constraints, many studies have been conducted on sensing interaction force without using a force/torque or tactile sensor. Geravand et al. [
18] proposed a signal-based approach to whole body collision detection, robot reaction, and human-robot collaboration that is applied in the case of industrial manipulators with a closed control architecture by using the motor position, velocity, and motor currents, and without the use of additional sensors. Mattioli and Vendittelli [
19] suggested a method for reconstructing interaction forces and localizing the contact point for humanoids under a static hypothesis based on the joint torque. Li and Hannaford [
20] suggested a method for sensorless gripping force estimation of forceps with an encoder and joint torque sensing, based on the characteristics of elongated cable-driven surgical instruments.
Recently, an interaction force estimation technique without a force sensor was developed based on a depth camera or a camera and joint torque. Margrini et al. [
21] developed a comprehensive approach using an RGB-D camera and joint torque for detecting, estimating, and handling dynamic force interactions that may occur at any point along the robot structure, to achieve an effective physical human-robot collaboration. As the use of deep learning technology is widespread in various research domains, it has been used to study the recognition of physical properties when a robot interacts with a physical object. Aviles et al. [
22,
23] showed a method of applied force estimation that uses a stereo camera in a surgical robotic system. A three-dimensional (3D) artificial heart surface is reconstructed from the projections of homologue points on the left and right lattices defined for each stereo-pair image, and supervised learning is applied to estimate the applied force and provide the surgeon with a suitable representation of it. In addition to robotics research, image-related research studies have also been conducted to predict interaction force through visual information. Zhu et al. [
24] suggested a method of inferring interaction forces between a human body and a real-world object from video clips; however, they took into account physical quantities generated from 3D modeling. Pham et al. [
25] showed a method for estimating contact forces during hand-object interactions that relies solely on visual input provided by images captured by a single RGB-D camera of a manipulated object with known geometrical and physical properties. Fermuller et al. [
26] predicted actions in dexterous hand motions by using deep learning methods. Their method predicts different manipulation actions on the same object, such as “squeezing”, “flipping”, etc., by analyzing images. They also predicted the forces on the finger tips using the network. They predicted the force variations, but the absolute value of the force was not successfully estimated.
The objective of this study was to investigate the possibility of sensing the interaction force using a single camera, without using a physical tactile or force/torque sensor. A camera is a type of touchless sensor. Thus, no abrasion issues caused by long-term usage are involved, as compared to touchable sensors, e.g., tactile sensors. For this purpose, we propose that recurrent neural networks (RNNs) with fully-connected (FC) units are applicable to visual time-series modeling for force estimation and that learned temporal models can provide accurate force estimation by using sequential images, without requiring the use of physical force sensors. Specifically, the proposed end-to-end deep learning method allows the mapping of models from image pixels to an interaction force to be learned using long short-term memory (LSTM) [
27]. The main contribution of this paper is that it presents the first investigation of the possibility that long-range learning deep models can infer interaction forces from the data of a vision sensor without requiring the use of physical force sensors. Unlike previous studies [
21,
22,
23,
24,
25], in our study we used only 2D sequential images, not 3D models, for calculating the graphical models in order to measure the physical interactions between the objects. However, the proposed method involves deeper neural networks for learning straightforwardly the interaction forces between objects from 2D images. We performed comprehensive evaluations on three different materials (a sponge, PET bottle, and a living organism, an arm) and, in addition, we experimented with various condition changes of light and poses using a tube object, to demonstrate that the proposed method is capable of estimating the precise interaction force from the visual information.
This rest of this paper is organized as follows: In
Section 2, we describe the RNNs on which the force estimation method is based. In
Section 3, we describe the basic configuration of the proposed model architecture. In
Section 4, we describe the database collection method and the experimental results, and present the discussion. We finally draw our conclusion and note the scope of further study in
Section 5.
2. Recurrent Neural Network: Long Short-Term Memory
The RNN was basically designed to process time-series data [
28,
29,
30] in applications such as speech and text recognition. For this purpose, it uses the internal memory to process arbitrary sequences. The convolutional neural network (CNN) [
31], however, has been studied for processing fixed-size images and is a type of feed-forward neural network. Recently, the RNN has achieved good performance in various sequential data-based applications, but the problem of the vanishing and exploding gradient remains unresolved [
32], which makes learning long-term dynamics difficult. To overcome this problem, LSTM [
27] was proposed, which incorporates memory units and gate functions: a forget gate
to control how much information from the past hidden state
is preserved, an input gate
to control how much the current input
updates the memory cell
, an output gate
to control how much information of the memory is fed to the output, and an input modulation gate
to modulate the current input and the past hidden state before updating the memory cell. The memory cell
preserves the state captured by the load cell of a sequence and updates the current hidden state unit with the output gate. The LSTM updates for the time step
given inputs, such as
,
, and
. The corresponding equations are:
where
is the sigmoid activation,
, and
denotes element-wise multiplication. All the weights,
, and biases,
, of the network are learnt jointly on training data. In this study, we aimed to investigate the possibility of predicting the interaction force using only sequential images. We propose an LSTM-based deep learning architecture for this challenge.
3. Proposed Deep Learning Model Architecture
In this section, we propose a novel deep learning framework for estimating the interaction forces using only sequential images. It should be noted that we do not use a physical force sensor and additional depth sensors to collect additional measurements. The main learning task is the prediction of a single static value, the interaction force, at a specific moment, from the sequential visual inputs. The motivation to develop the proposed method is as follows. Humans, when in contact with an object, can infer how the forces applied to it interact with each other by observing the change in the shape of the object. This is largely because they have already gained sufficient experience of interaction forces during their life. From this viewpoint, we propose a vision-based interaction force estimator that uses the deep learning method. The overall view of the proposed LSTM-based framework is shown in
Figure 1. It contains two parts: the LSTM part models the relationship between the image and the interaction force using the total
sequential images and the FC layer part learns the processing model from the LSTM output to obtain an accurate estimation of the interaction force in a straightforward manner. The temporal aspect of the proposed method is important. In general, the situation of loading and unloading have an effect on the relationship between contact forces and indentation. This hysteresis damping generates different contact forces at the same deformation [
33]. Due to the hysteresis, the force is measured differently at the same deformation according to the loading and unloading conditions.
To avoid the obstacles of background clutter simply, we crop only the center region from an input image and normalize it to a fixed resolution image
, where
is the width and
is the height, with a single gray channel. We directly convert the gray image into a visual input vector
and the total
sequential normalized images are passed into an LSTM sequence learning module. The proposed model stacks one more LSTM on another to gain more accurate results, because the recent deep model for object recognition [
34] suggests that deeper layers usually lead to more accurate classification results. We apply a late-fusion method to merge the
step LSTM output for generating the input of the FC layers. It should be noted that the proposed method predicts the final static output, e.g., the interaction force value, with the sequential inputs. In this respect, to achieve better results, we add up two FC layers with
LSTM outputs. The basic assumption of the proposed method is that, if sufficient preceding input data exists, the most accurate result can be predicted using FC layers in the final time step. In RNNs, arbitrary input and output sizes are commonly handled, but, in this method, we take a fixed-size input for predicting the interaction force at the end of the network operation. Our main task is not to process arbitrary sizes of inputs and outputs, but to predict a single value using the sequential inputs. In this case, we can easily train the network with fixed-size inputs, because we can remove the uncertainty regarding the sizes of inputs and outputs in the training stage. We handle the sequential inputs with LSTM modules. For the first
time steps, the LSTM processes the total
inputs. Since FC layers need fixed-length input from LSTMs, until
time steps are executed, there are no prediction results.
The predicted interaction force,
,
, is computed by taking the mean square error (MSE). The difference between the target and the estimated value is minimized based on MSE criteria. It is represented as:
where
and
are the predicted interaction force and the ground-truth, respectively.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
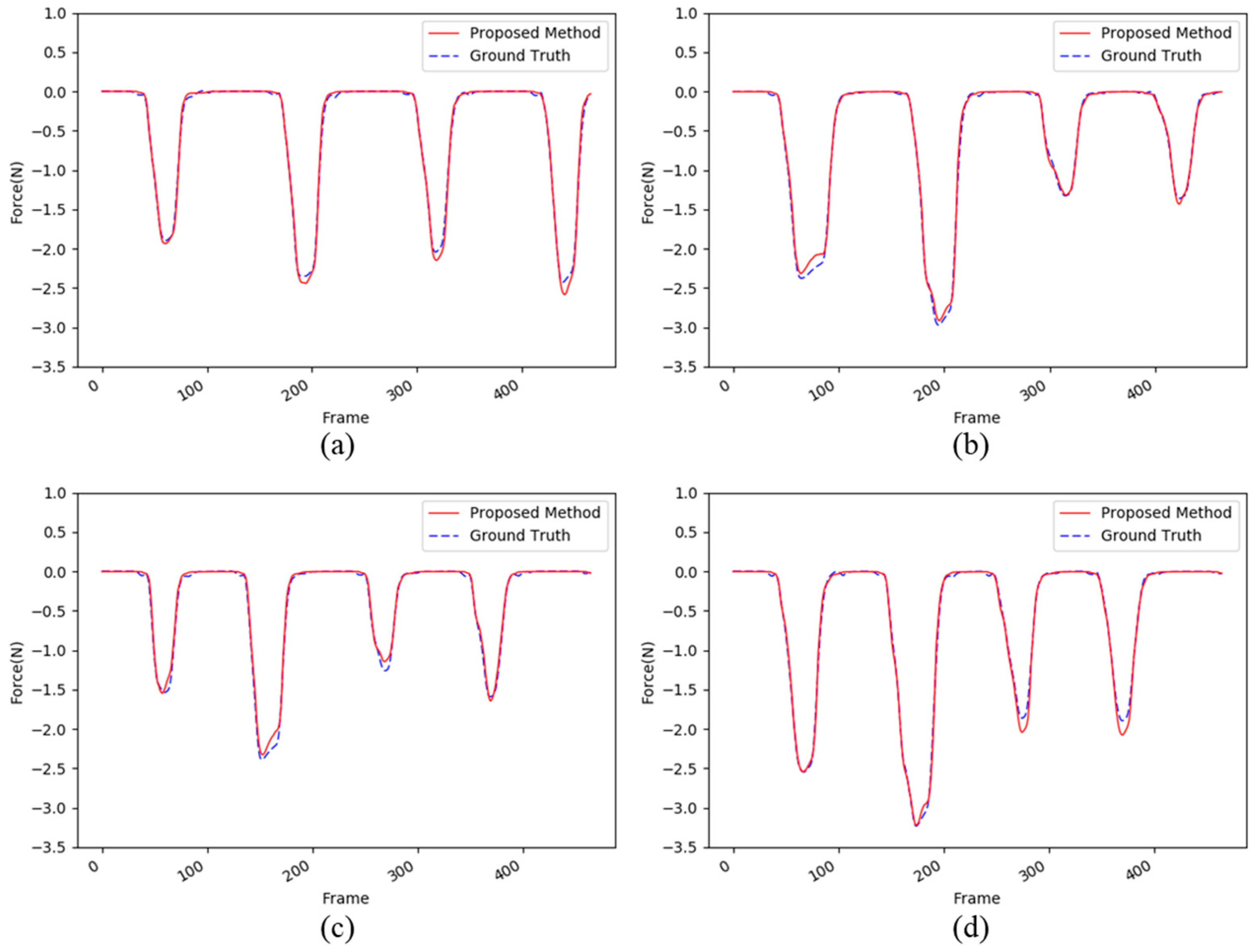{kind=link}
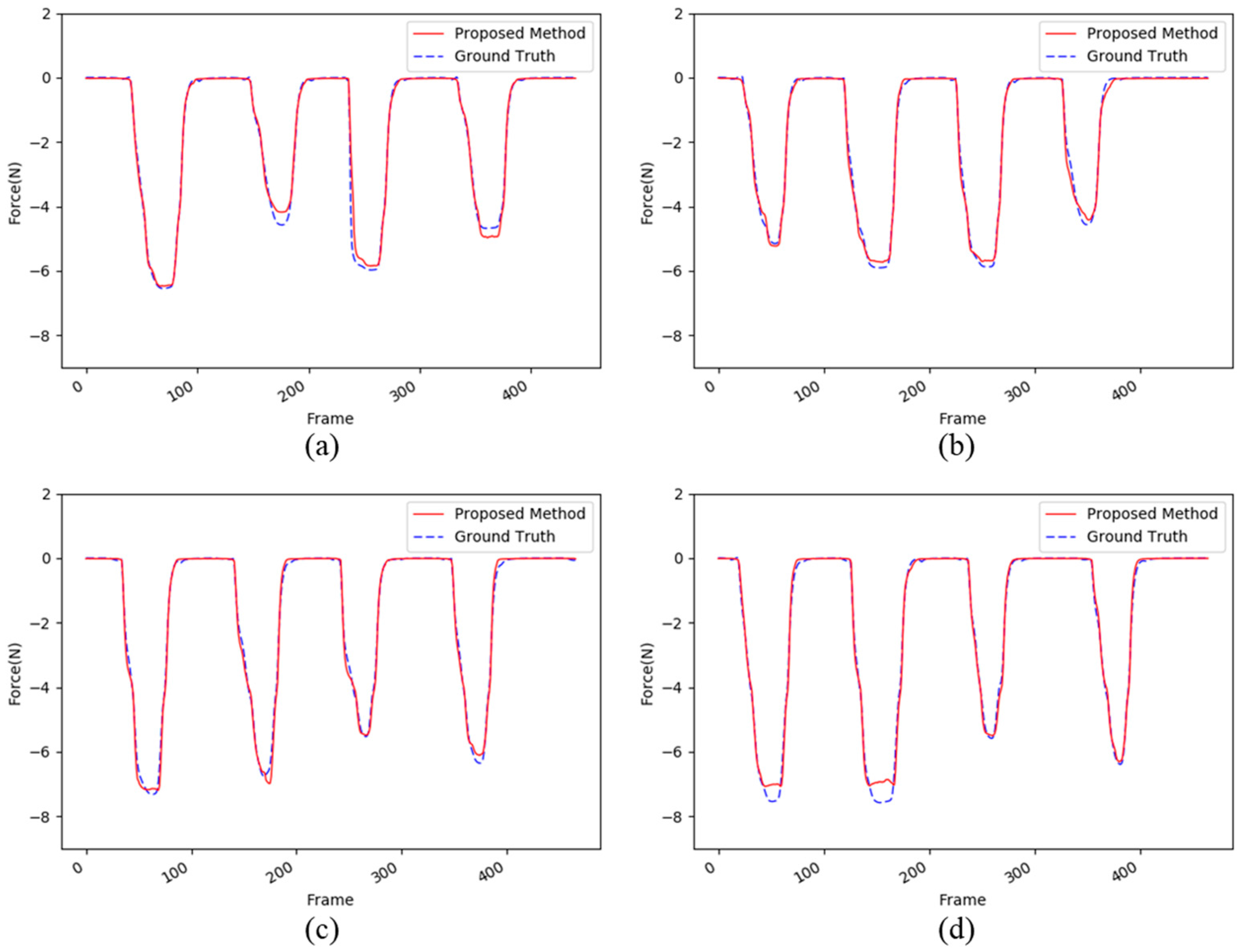{kind=link}
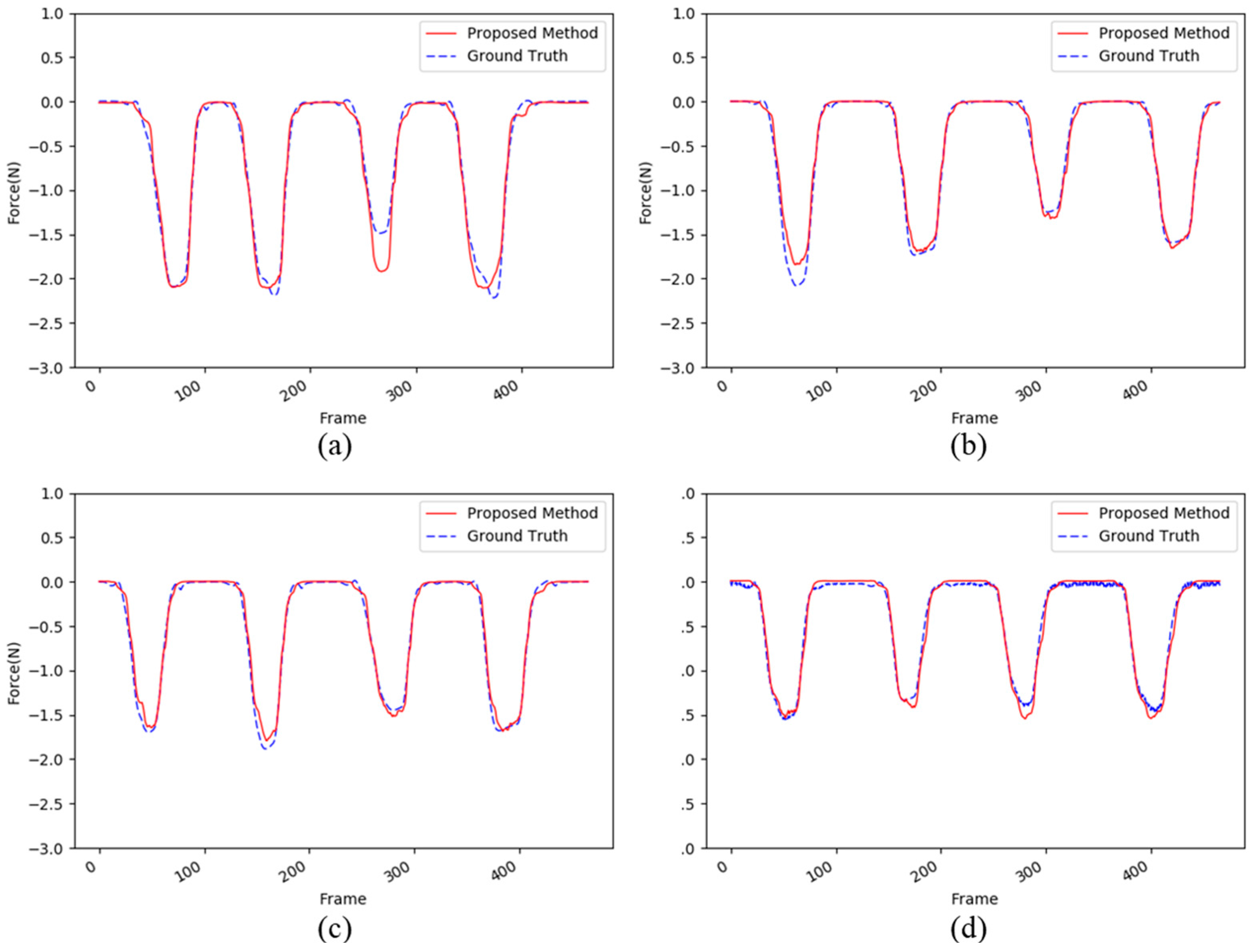{kind=link}
{kind=link}
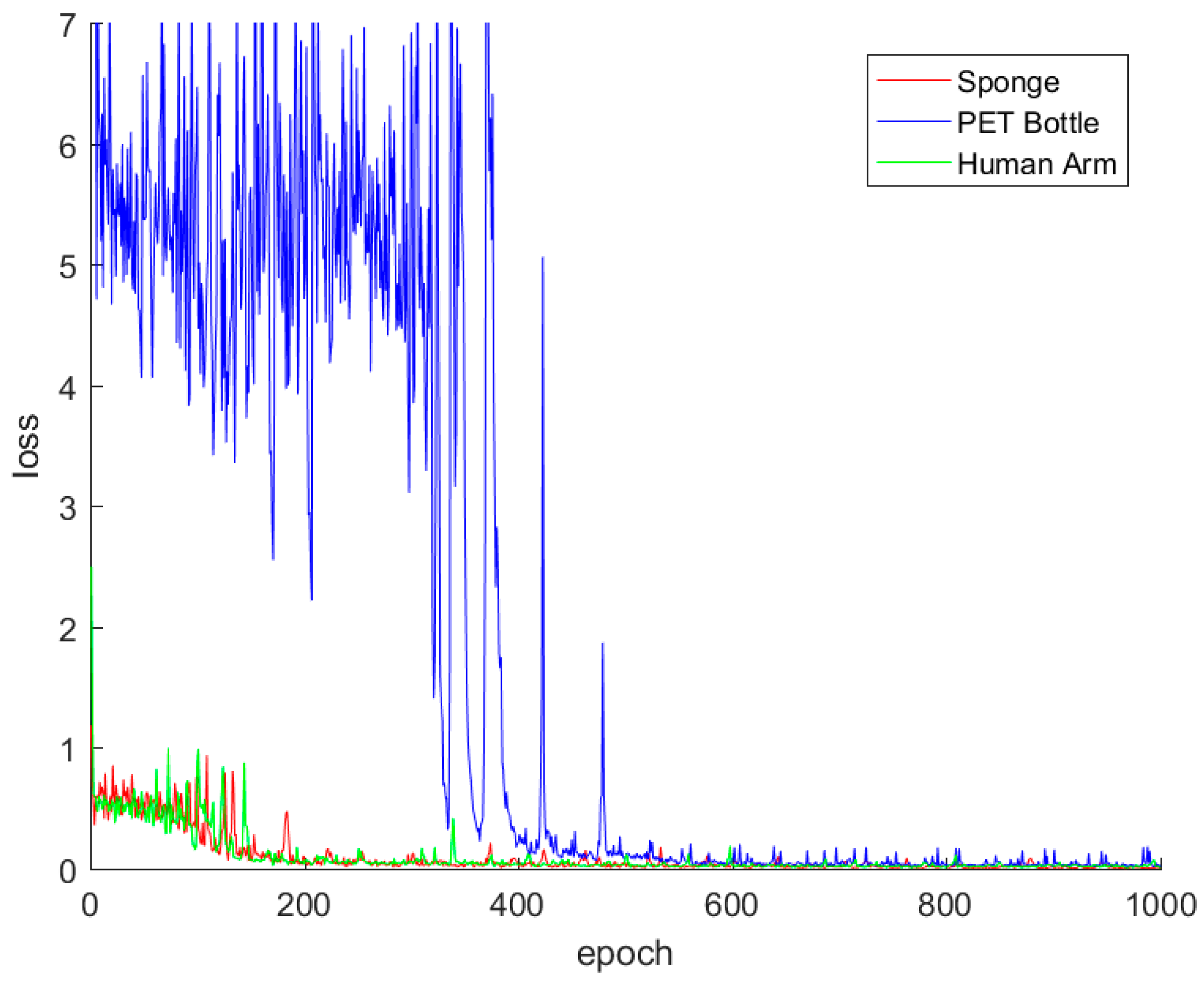{kind=link}
{kind=link}
{kind=link}