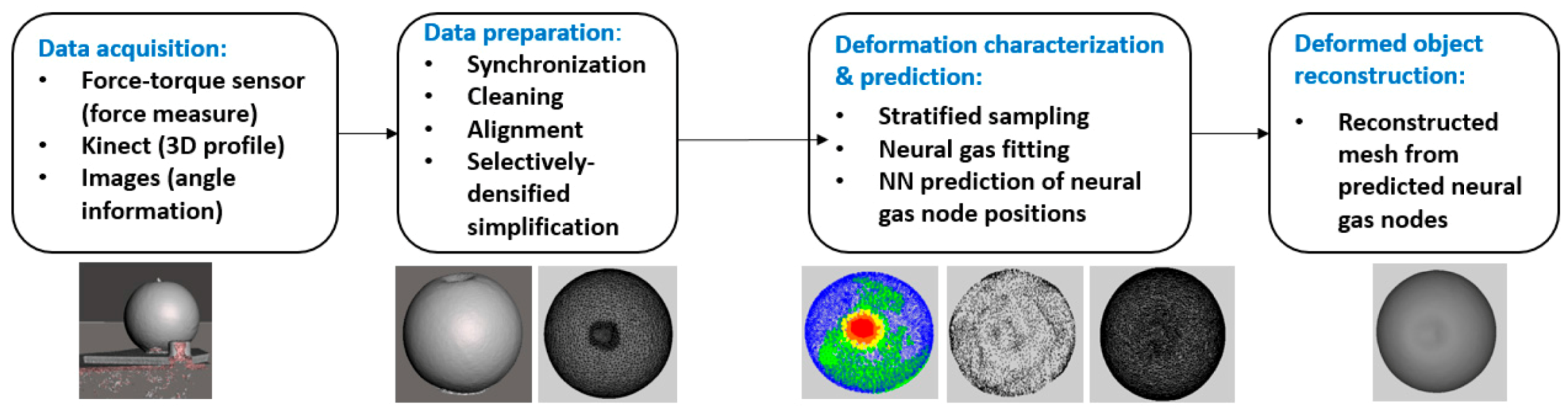
1. Introduction
The acquisition and realistic simulation of deformations, especially for soft objects whose behavior cannot be simply described in terms of elasticity parameters, is still an active area of research. Realistic and plausible deformable object models require experimental measurements acquired through physical interaction with the object in order to capture its complex behavior when subject to various forces. The measurement of the behavior of an object can be carried out based on the results of instrumented indentation tests. Such tests usually involve the monitoring of the evolution of the force (e.g., its magnitude, direction, and location) using a force-feedback sensor. The active indentation probing is usually accompanied by a visual capture of the deformed object to collect geometry data characterizing the local surface deformation.
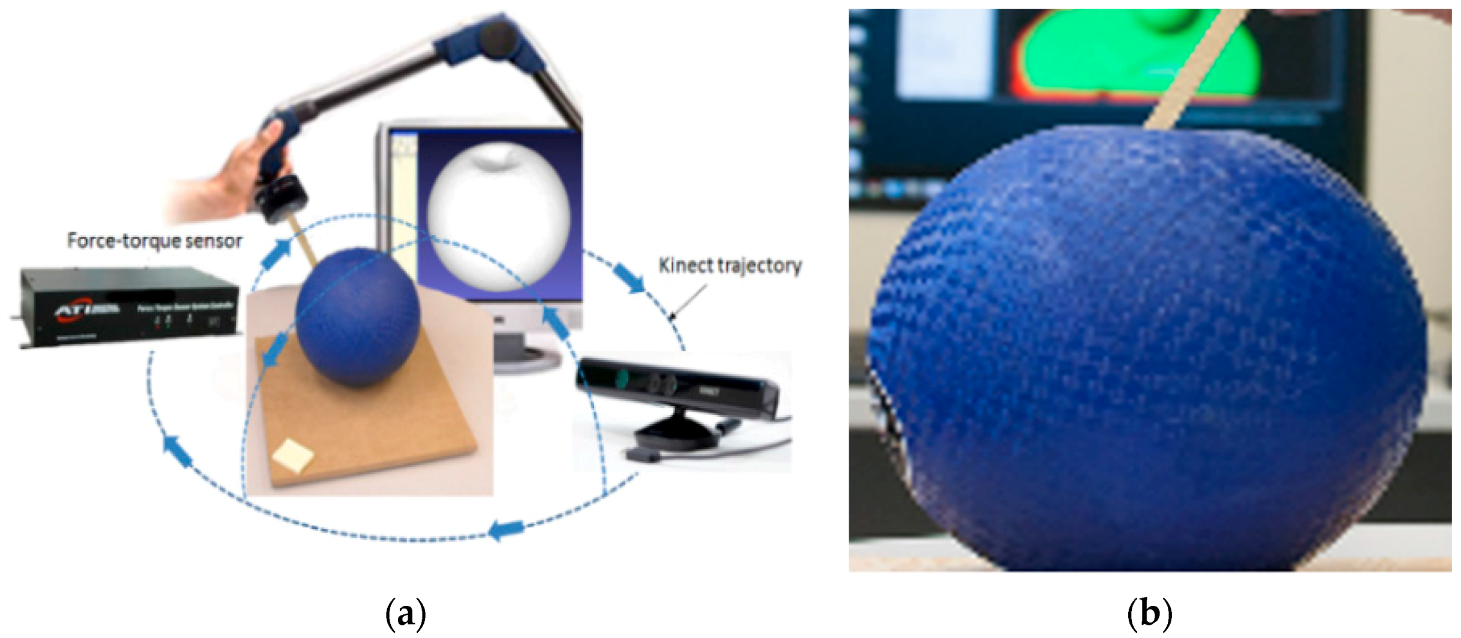
A classical high precision solution for collecting 3D geometry data are laser scanners. However, they are expensive and the acquisition process is often lengthy. The Kinect sensor proves to be a simple, fast, and cost-effective alternative. It is however known that, while small objects are difficult to capture with the sensor due to its relatively low resolution, it offers enough precision for measuring objects with a reasonable size, such as a ball or a sponge, as used in this work. RGB-D (red, green, blue and depth) data collected by this sensor has been successfully used for the reconstruction of complete 3D pointclouds of objects by merging data from multiple viewpoints, for both rigid [
1] and non-rigid objects [
2,
3]. A few open-source options to integrate and stitch multiview data, such as Kinect Fusion [
4], and commercial solutions, such as Skanect [
5], are also available.
Once the 3D data is acquired, various approaches can be used for modeling a deformable object such as: mass-spring models, the finite element method, viscoelastic tensor-mass models, Green functions [
6], NURBS (Non-uniform rational basis splines), or surfels [
1]. Most of these techniques assume that the parameters describing the object behavior (e.g., elasticity parameters) are known a priori or values for these parameters are chosen by manually tuning them until the results seem plausible. This is a subjective process and while it can be used for certain types of applications, it cannot be employed where a certain level of accuracy is expected, as an improper choice of parameters can lead to undesired behavior.
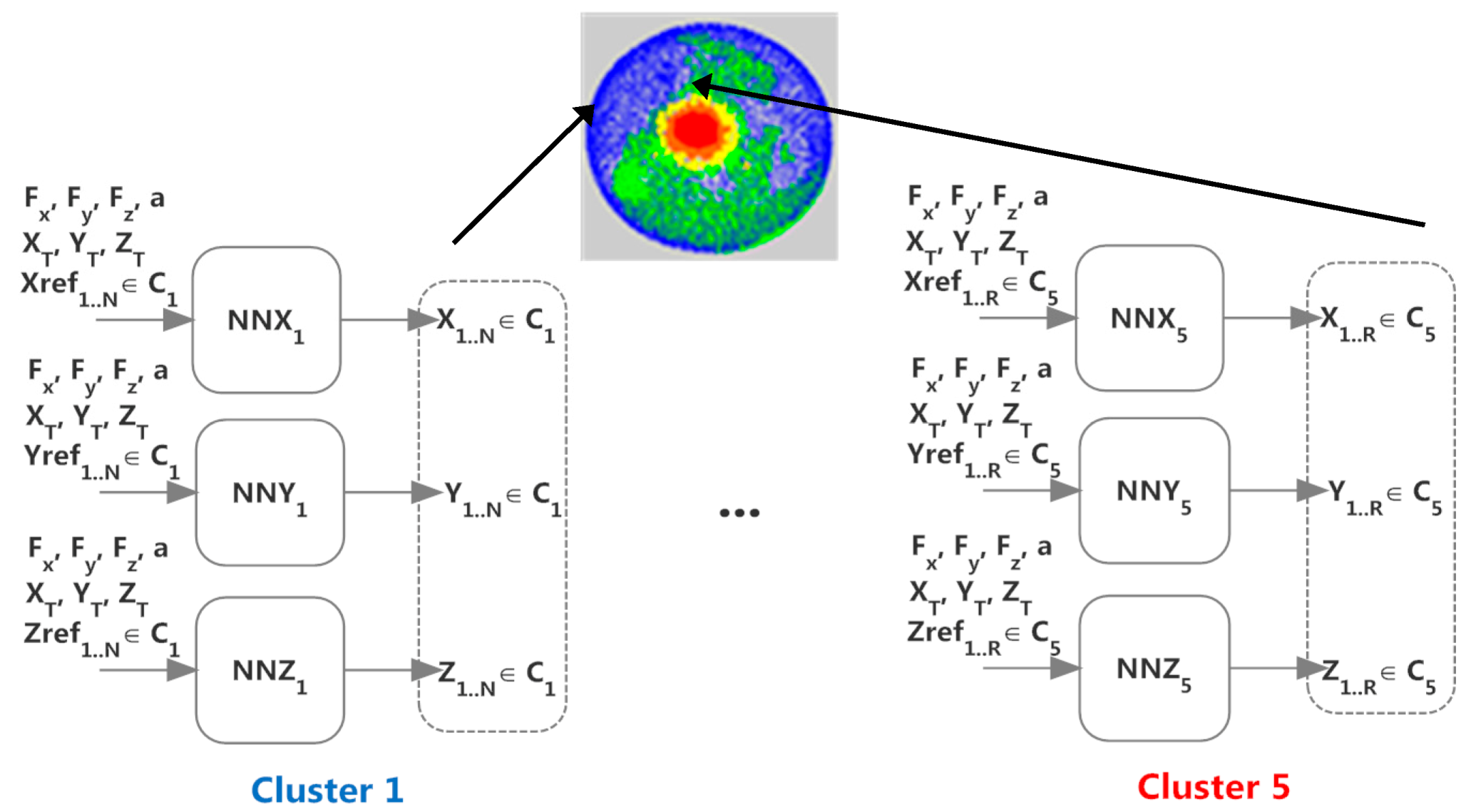
The objective of this work is therefore to propose an original solution to the modeling and prediction of the deformation of soft objects that does not make assumptions about the material of the object and that capitalizes on computational intelligence solutions, namely on combining neural gas fitting with feedforward neural network prediction. It builds on a previously proposed solution [
7] for capturing the deformed object shape using neural gas fitting. However, the modeling process is improved in this work by an alignment procedure that ensures a simpler interpretation of the deformation (e.g., simpler comparison for various angles and forces) and a similar treatment of the deformation over the surface of an object. In addition, an in-depth analysis conducted on the parameters leads to a more appropriate choice of parameters, that results in a better performance for object representation. Finally, a novel solution is proposed based on a neural network architecture to predict the deformed shape of an object when subjected to an unknown interaction.
The organization of the paper is as follows: After a general introduction on deformable object acquisition and modeling and the associated challenges in
Section 2, the proposed framework for 3D deformable object modeling and prediction using a Kinect and a force-torque sensor is presented in
Section 3. The obtained experimental results are presented and discussed in
Section 4. The paper is concluded in
Section 5.
2. Related Work
Several solutions have been proposed in the literature for modeling deformable objects, including: mass-spring model [
8,
9], finite-element (FEM) representation [
10,
11,
12], Green functions [
6], NURBS [
13], and surfels [
1], just to mention a few. Most of these techniques assume that the parameters describing the object behavior (e.g., elasticity parameters) are known a priori or that values for these parameters are chosen by manually tuning them until the results seem plausible. This is a subjective process and while it can be used for certain types of applications, it cannot be employed where accuracy is expected, as an improper choice of parameters can lead to undesired behavior. To overcome this problem, several researchers propose recuperating the parameters based on a comparison between the real and simulated object subject to interactions. Zaidi et al. [
8] modeled an object in an interaction with a robot hand as a non-linear isotropic mass-spring system, but do not capture visual data to build the model. Object deformations are computed based on tracking the node positions and solving the dynamic equations of Newton’s second law. Elbrechter et al. [
9] modeled a piece of paper in an interaction with a robot hand as a 2D grid of nodes connected by links that specify the bending constraints and a stiffness coefficient. The parameters of the model are tuned manually. The authors of [
11] tracked deformable objects from a sequence of point clouds by identifying the correspondence between the points in the cloud and a model of the object composed of a collection of linked rigid particles, governed by dynamical equations. An expectation-minimization algorithm found the most probable node positions for the model given the measurements. Experimentation is performed in a controlled environment, against a green background, which limits its applicability to real conditions. Choi et al. [
14] tracked the global position of moving deformable balls, painted in red against a blue background, in a video stream and adjusted the elasticity parameters of a mass-spring model of the ball by optimizing the differences with the real object. Petit et al. [
12] tracked 3D elastic objects in RGB-D data. A rigid transformation from the point cloud to a linear tetrahedral FEM model representing the object was estimated based on the iterative closest point (ICP) algorithm. Linear elastic forces exerted on vertices are computed from the point cloud to the mesh based on closest point correspondence and the mechanical equations are solved numerically to simulate the deformed mesh. Their work focuses solely on elastic objects. In [
15], the stiffness properties of mass-spring models were estimated by applying force constraints at different locations on the object, recording the resulting displacements and comparing them between the reference and the estimated model using particle filters. In a similar way, the authors of [
16] presented a genetic-based solution to identify stiffness properties of mass-spring-systems by using a linear FEM model as a reference. While the method seems to support isotropic and anisotropic reference models, only simulated results are presented. In order to compute the elasticity parameters, Frank et al. [
10] minimized the difference between the real object in interaction with a force-torque sensor and captured it visually as a pointcloud and the simulated object in the form of a linear FEM model. However, their method only works on homogeneous and isotropic materials. These methods justify the interest in the development of new methods that do not make assumptions on the material of the object, such as the one proposed in this paper.
4. Experimental Results
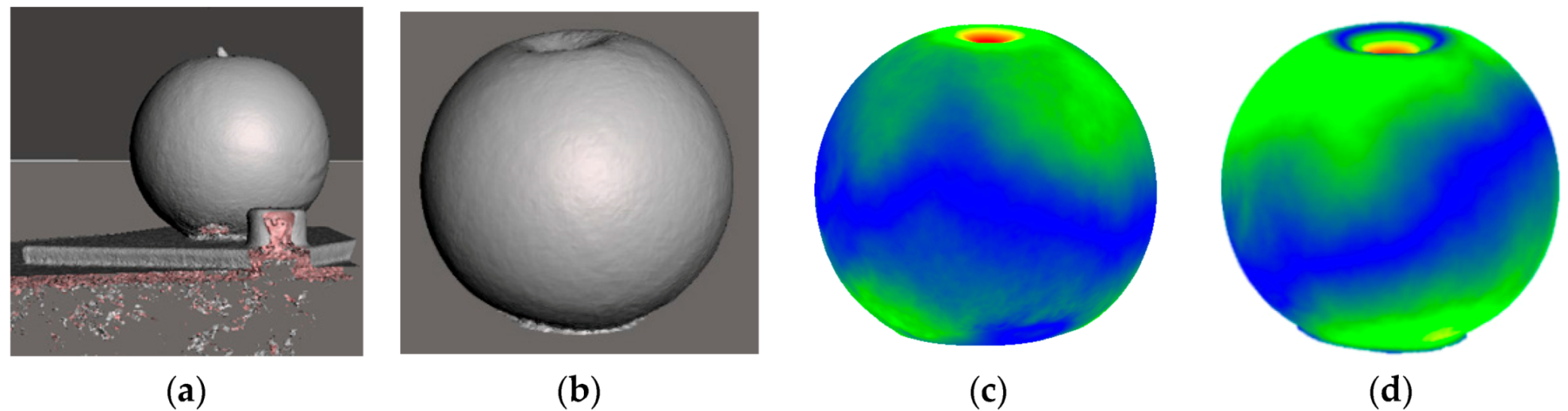
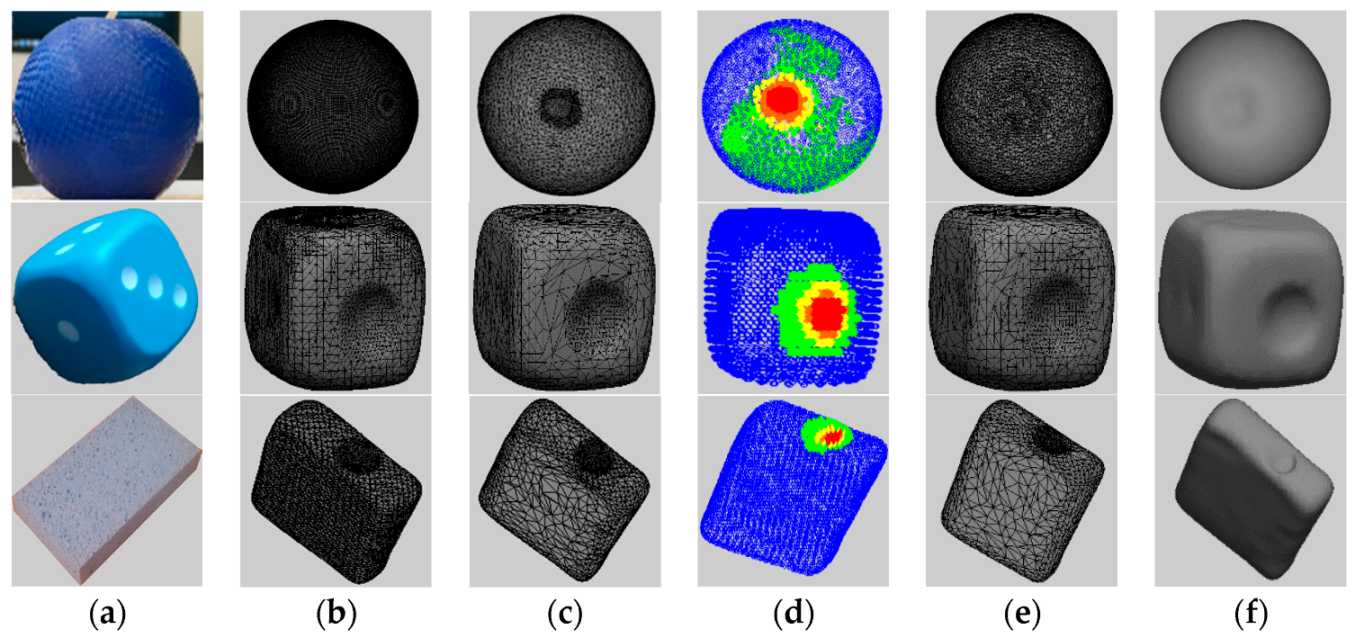
The proposed solution for modeling and predicting deformable object shapes is validated in this paper by using a soft rubber ball, a rubber-coated foam cube, and a foam sponge (
Figure 6a). Starting from the cleaned mesh, instead of using the entire collected pointcloud (
Figure 6b), a selectively-densified mesh (
Figure 6c) is first constructed, in which the area around the point of interaction between the probing tip and the object surface is preserved at higher resolution, while the other areas are simplified. This is achieved by adapting the QSlim [
22] algorithm to only simplify points that are not the interaction point with the probing tip and its immediate neighbors.
This simplification process ensures a uniform representation of the object by defining an equal number of faces, representing 40% of the faces in the initial model for all the instances of a deformed object. This 40% is chosen by monitoring the evolution of the errors and of the computation time for an increasing percentage (from 10% to 100%) and finding the best compromise between the two.
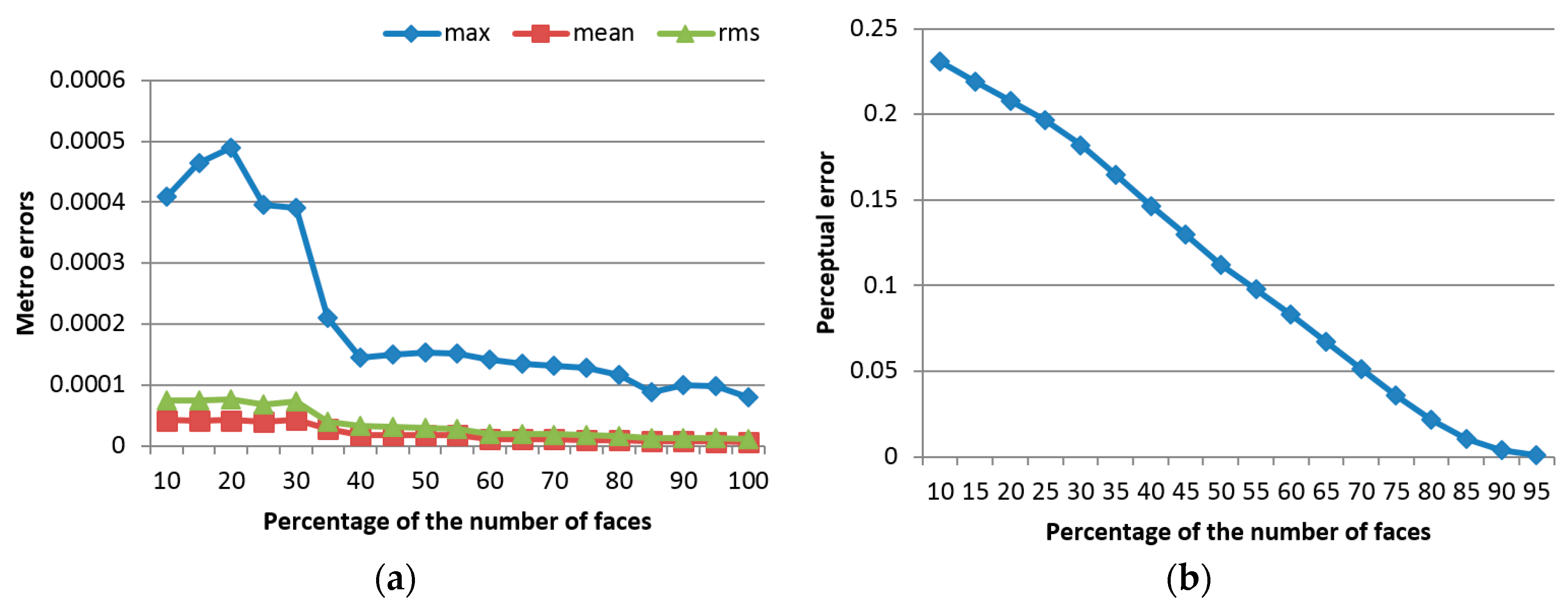
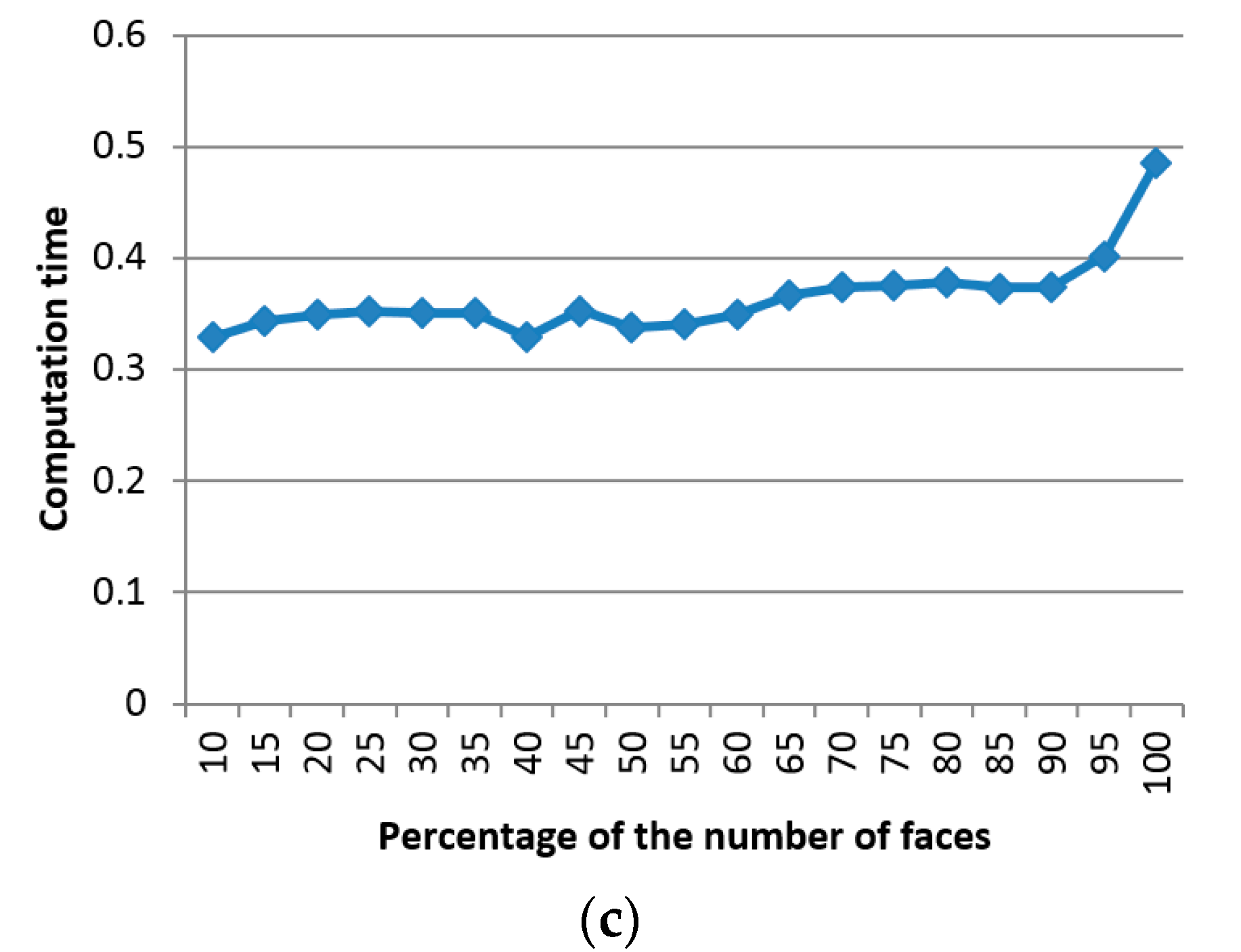
Figure 7 shows the evolution of the error measures detailed in
Section 3.4, namely of the Metro errors (
Figure 7a), the perceptual error (
Figure 7b), and of the computation time (
Figure 7c), calculated as an average over the entire surface of the three objects under study, with the percentage of faces used for simplification. One can notice that, as expected, the error decreases with an increase in the number of faces. At the same time, the computation time increases slightly with a larger number of faces, and therefore the best compromise is found between these two opposing criteria. The abrupt descent in Metro error and the relatively low computation time around 40% of the number of faces guided our choice for the selection of this parameter.
A second parameter that affects the simplification algorithm is the number of immediate neighbors that are preserved around the probing tip. In [
7], we have used 12 immediate neighbors for all the objects. In the current work, the 12-degree immediate neighbors are preserved for the rubber ball and 8-degree immediate neighbors for the foam sponge and the cube. Only values within this range (8 to 12) are tested, because they allow us to correctly capture the entire deformed area over the 3D point clouds collected. Within this range, the number of neighbors is chosen by selecting the model that results in the lowest perceptual error (or the highest perceptual similarity) with respect to the original, non-simplified mesh.
Table 1 shows the evolution of the perceptual errors with the size of the neighborhood (
n) around the probing tip and justifies the choice of the neighborhood size based on the highest similarity.
The results for the selective simplification around the probing tip with the above detected values for the parameters are shown for the three test objects in
Figure 6c. After having obtained the selectively-densified mesh, a stratified sampling technique, as detailed in
Section 3.3.1, is employed to only retain a subset of data for neural-gas tuning. In particular, the mesh is initially clustered according to the distance with respect to the initial non-deformed mesh. It is desired that the highest possible number of points from the deformed zone is situated in the farthest cluster. In our previous work [
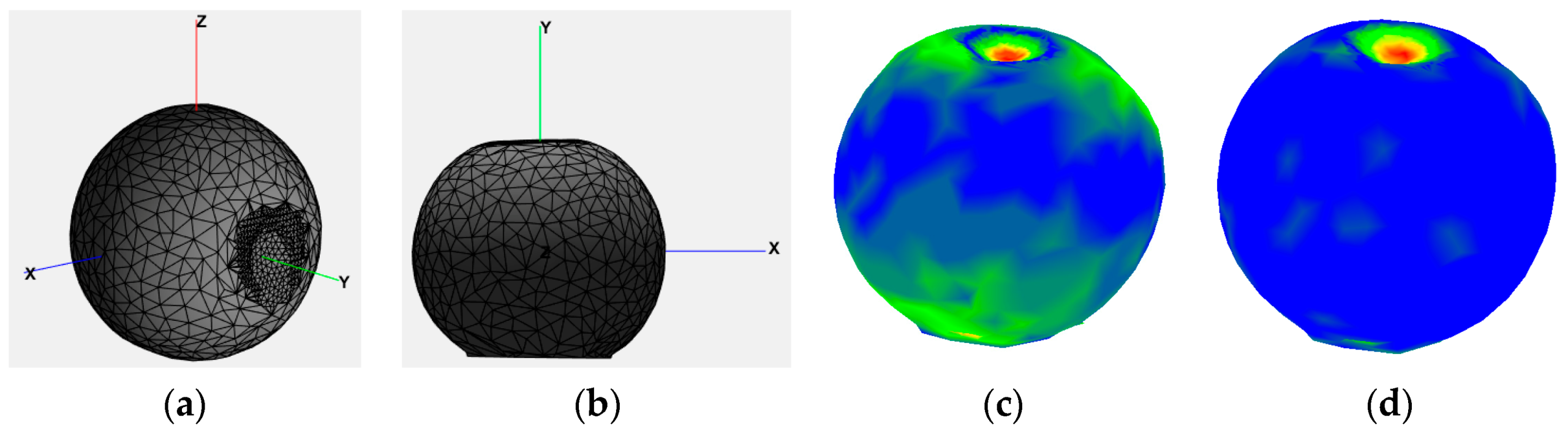
7], during testing, the number of points of the deformed zone in this cluster was monitored, and the process was stopped once the largest number of points in the deformed zone was found in this cluster. A number of five clusters was identified to ensure the best results. In this work, a more thorough analysis led to a better definition of the area around the deformation zone by increasing the number of clusters and regrouping the ones at the largest distance to cover the entire deformation area. In this case, an equal number of five clusters were used, but by identifying seven clusters and regrouping the three farthest together.
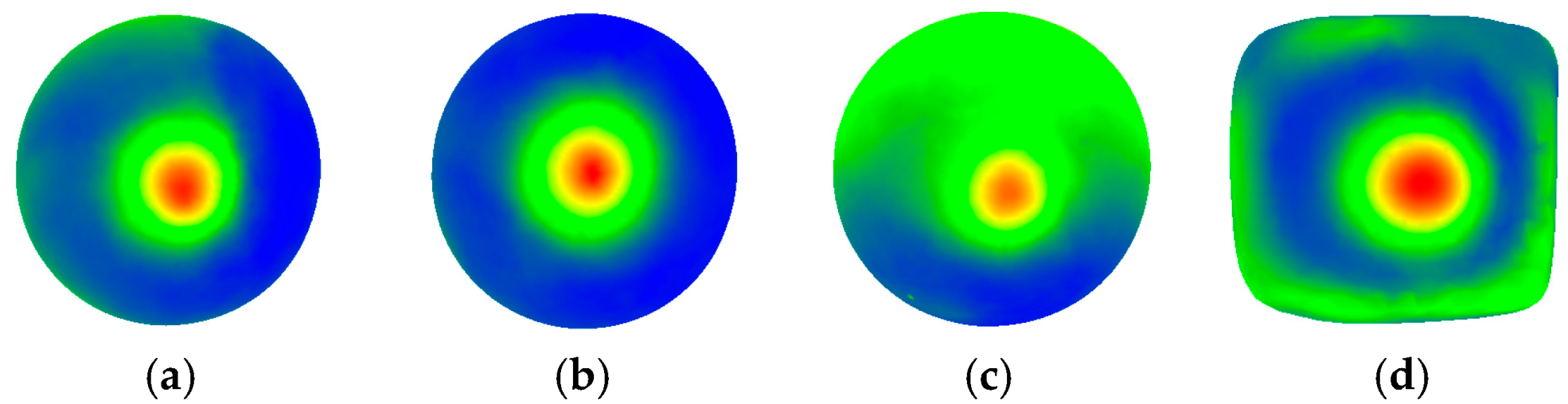
Figure 8 shows the difference, for each of the test objects, between the use of five and seven clusters. One can notice that in all three cases, the use of seven clusters and the combination of clusters at the farthest distance more accurately represents the deformation area. For example, for the case of the ball, the combination of the red, fuschia, and orange clusters in
Figure 8b results in a more accurate representation of the deformation area than the black cluster in
Figure 8a. The same conclusion can be reached by comparing
Figure 8c,d and
Figure 8e,f, respectively.
Figure 6d shows the clusters, with red points belonging to the farthest cluster from the initial object (deformed zone) and with orange, yellow, green, and blue points being increasingly closer with respect to the initial mesh (blue = perfect match), for the combination of 90% from the farthest (red) cluster, 80%, 70%, and 60%, respectively, from the 2nd, 3rd, and 4th cluster, and 50% from the closest distanced cluster points (blue). While a higher percentage might achieve better results, it will also result in a higher computation time.
The stratified sampling is not sufficient, as the fine differences around the deformed zone and over the object surface (
Figure 3c,d) might not be appropriately represented, which is the reason why a tuning of the selectively densified mesh is also executed using a neural gas network. A neural gas network is adapted, as explained in
Section 3.3.2, for 20 iterations. It uses a number of neurons in the map equal to the number of points sampled from the different clusters and a number of faces equal to the average of the number of faces over the selectively densified meshes. The object model is then constructed using the solution proposed in
Section 3.3.4.
Figure 9 presents the color-coded comparison with the initial full resolution object obtained using CloudCompare for each of the three objects after the construction of the selectively-densified mesh and after the neural gas tuning. One can notice that a very good match is associated in both cases with the deformed area (shown in blue), but that the errors are lower in each case after neural gas tuning due to a better distribution of faces over the surface of the object.
To quantify these results, we have also computed the Metro and perceptual errors for both the solutions proposed in [
7] and the one proposed in this paper, as shown in
Table 2 and
Table 3, respectively. For the solution in our previous work, the overall perceptual similarity achieved is on average 74% over the entire surface of the object and roughly 91% over the deformed area, with an average computing time per object of 0.43 s on a Pentium III, 2 Ghz CPU, 64 bit operating system, 4 Ghz memory machine.
The improvements in the current work, including the object alignment and a better selection of parameters, lead to an increase in performance, as can be noticed in
Table 3. The overall perceptual similarity obtained is on average 86% (i.e., an improvement of 11.7% with respect to [
7]) and 96.6% (i.e., an improvement of 5.9%) over the deformed area. The improved performance comes, however, at a higher average computation time per object, at an average of 0.70 s (roughly 39% higher with respect to the one reported in [
7]). This change in computation time is mainly due to the alignment and realignment procedure and to the higher percentage of points chosen for the selectively-densified mesh construction.
Another series of tests is aimed at evaluating the performance of the solution for the prediction of the shape of an object using the series of feedforward neural networks, as described in
Section 3.3.3. Networks are trained for 1000–2000 iterations, with an average training time of 15 s. The training error is of the order of e
−4. Once trained, they can provide (in real-time) estimates for the position of the neural gas nodes. The mesh is reconstructed by the redistribution of faces using the Qslim algorithm, as detailed in
Section 3.3.4.
Figure 10 shows a few examples of predicted deformed instances of objects obtained with the proposed solution, for the three objects under study. It is important to mention that we use here raw force data (i.e.,
,
, and
components) as returned by the force-torque sensor, instead of the force magnitude computed in Equation (1), in order to enable the interpretation of the results. The objects are shown such that the deformation is situated along the
y axis, and the
x axis points towards the left side of the ball, while the
z axis points towards the top of the image (as in
Figure 4a). Studying
Figure 10a that shows, for example, the difference between the ball model for
Fx = 3,
Fy = 17, and
Fz = −226 and the predicted ball model for
Fx = 2,
Fy = 14, and
Fz = −226, one can notice that there is a difference of force of 1 N along the
x axis. Again, CloudCompare is used to encode in color the differences—blue representing a perfect match and the error increases from green, to yellow, orange, and red. The difference along the
x axis is visible in the figure, in green, on the right side of the model. As one expects, the network was able to predict this movement of the object’s surface along the
x axis.
Additionally, there is a difference between the forces applied on the
y axis that is larger than the one over the
x axis (i.e., 3 N). This difference is visible in green, red, and yellow around the deformation zone, as expected. For the case in
Figure 10b, the force difference is mainly along the
y axis and is reflected by differences in the deformation zone, as one might expect. A certain error appears around the sides of the object, as reflected by the green-bluish patches. The last example for the ball is for a force that affects the
z and
y directions and it is again correctly predicted. Finally, an example is shown for the estimation of the cube for a force varying with 4 N the along
y axis. The difference shown in red, yellow, and green is mainly concentrated around this axis as well.
To quantify the errors obtained for neural network training and prediction, we compute the Metro errors and the perceptual errors over the object surface and in the deformed area. The results for the training are shown in
Table 4 and demonstrate that the network is able to capture quite accurately the neural gas nodes. One can notice that overall the errors for the ball are higher. This is mainly due to the fact that the ball that was used for experimentation is bigger in size than the cube and the sponge. Keeping the Kinect at roughly the same distance with respect to the probed object, the pointcloud collected for the ball contains more points than the cube and the sponge. For comparison, the number of points for the ball is 14,000, while for the cube and sponge it is 4680 and 5800, respectively.
Table 5 quantifies the prediction errors when the networks are tested over previously unseen data, for 10 test cases, including those illustrated in
Figure 10. It is important to notice that the differences in the force magnitude are not significant in the test scenarios with respect to the real measurements. The networks are only able to accurately predict within a limited region around the measured areas and for forces that do not differ significantly in magnitude and angle (i.e., about 4–5 N in force magnitude and 2–3° in angle). This is an important aspect that needs to be taken into consideration when designing solutions based on the training of neural networks for predicting deformable object behavior, and any data-driven solution in general. A large number of real data measurements are required to ensure a more accurate prediction. As expected, the errors are higher than those obtained for training, but still a good average similarity of 87.43% is preserved over the entire surface of an object and of roughly 96.6% in the deformed zone.
It is important to state as well that the complexity of the object’s geometry can also have an impact on the performance of the proposed framework. More complex shapes require more measurements than simpler objects in order to ensure a relatively accurate representation of the object’s behavior. This is due to the fact that when the force is applied to an arbitrary location, local deformation data might not be relevant for other regions where the geometric structure of the object (i.e., edges and corners) is different. One possible solution to this issue is to identify, based on visual information, the areas where the probing will take place such that the probing process is guided towards only relevant areas where changes in local geometry occur. While this topic is beyond the scope of this paper, a solution such as [
24] could be used for this purpose.
While a more complex geometry does not require any adjustment of the proposed framework, it would lead to an increase in the training time for the series of neural networks that map the interaction parameters with the local deformation, because of a larger volume of data to be processed. Due to the use of the neural gas and its ability to capture fine details in spite of a more complex shape, no additional challenges are expected at the level of simplification algorithm.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}