A Q-Learning-Based Delay-Aware Routing Algorithm to Extend the Lifetime of Underwater Sensor Networks



Abstract
:1. Introduction
2. Related Work
3. Q-learning Based Model
3.1. The Basic Q-Learning Technique
3.2. Q-Learning Based System Model
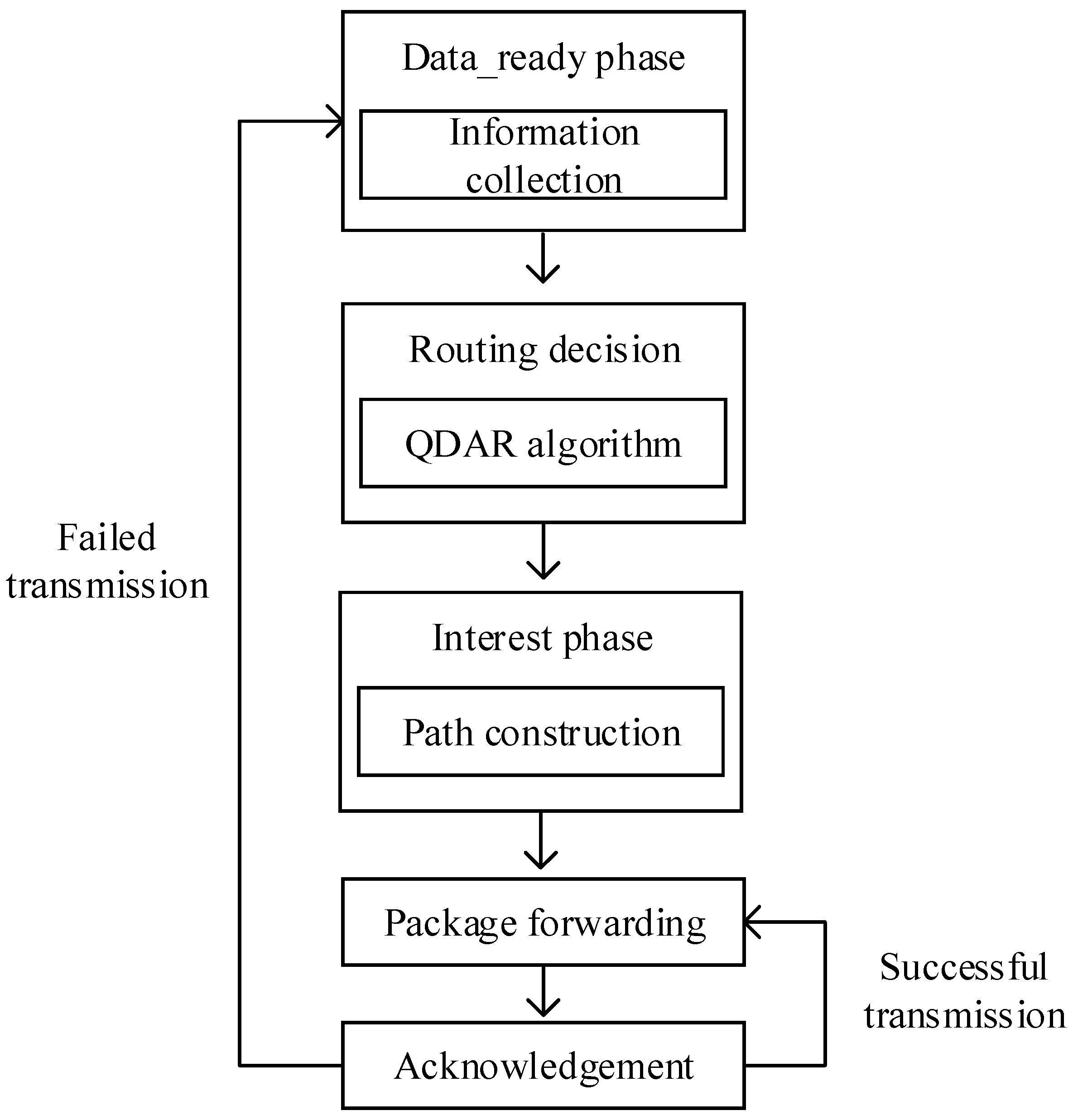
4. QDAR Mechanism Overview
4.1. The QDAR Mechanism
4.2. Assumptions
- Nodes hold their own depth information and can embed it in the packets;
- Nodes in UWSNs implement Source_initiated Query [23];
- The sink node keeps the successful and failed communication record of the nodes.
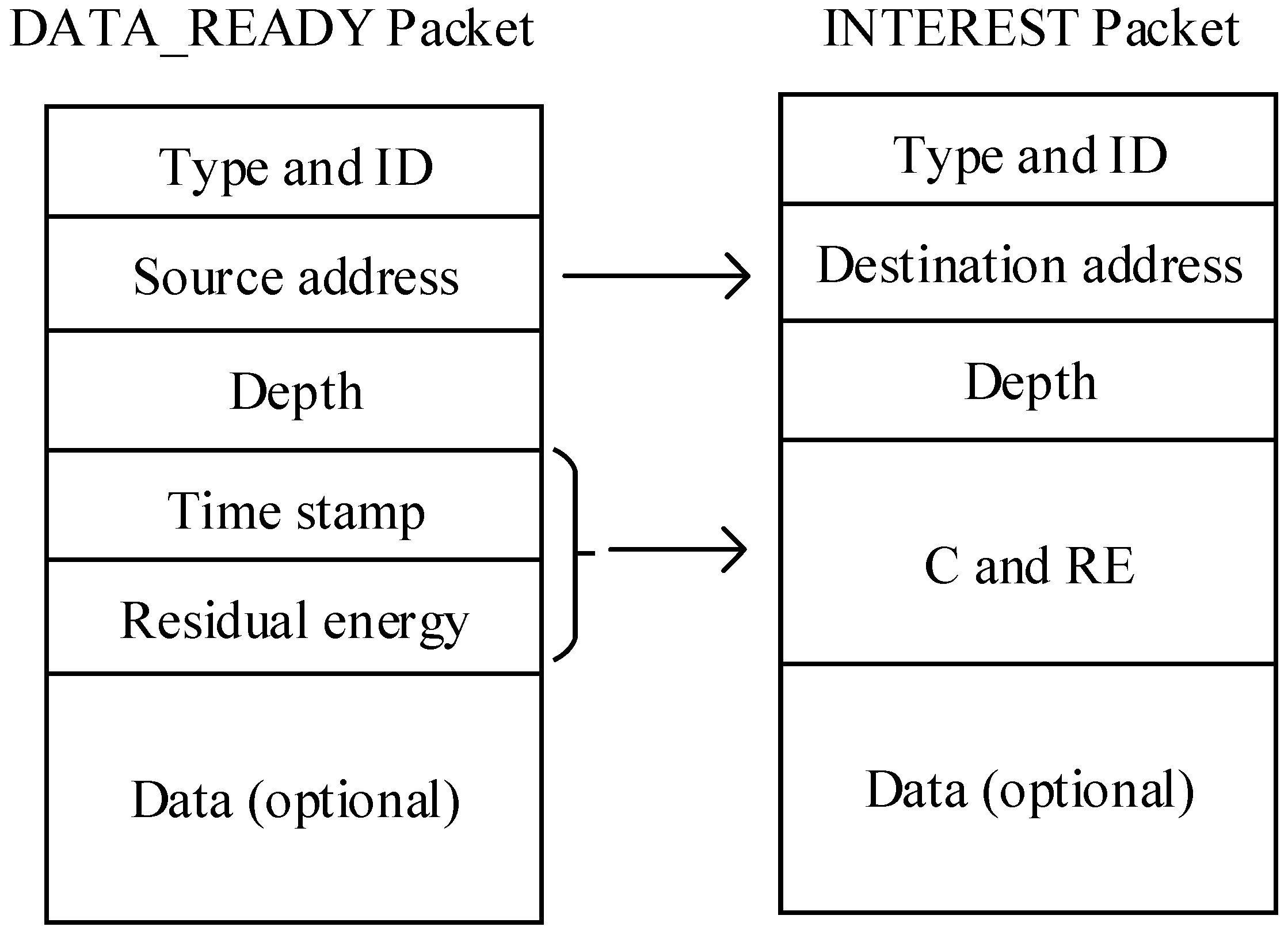
4.3. The Packet Structures
- Calculate. The nodes extract RE and TS. With these information, the nodes can compute their energy-related costs and delay-related costs depending on the delay and residual energy.
- Update and relay. The nodes update TS, C and RES packet fields with their own information or calculation results and relay the DATA_READY packet to neighbor nodes until the packet arrives at the sink node.
5. QDAR Algorithm
| Algorithm 1: The routing mechanism. |
| Initialize (); |
| While xi. next_hop ! = source node |
| for xj in Ni do |
| calculate ce, ct, P; |
| nodes satisfy are saved in set ; |
| end for |
| if then |
| set to , ; |
| calculate the direct reward r; |
| select the node xj with maximum value in set Ni; |
| calculate (xi, ah),; |
| aj = argmax((xi, ah)); |
| else aj = argmax((xi, ah)) |
| end if |
| xi = xj |
6. Performance Evaluation
6.1. Experimental Framework
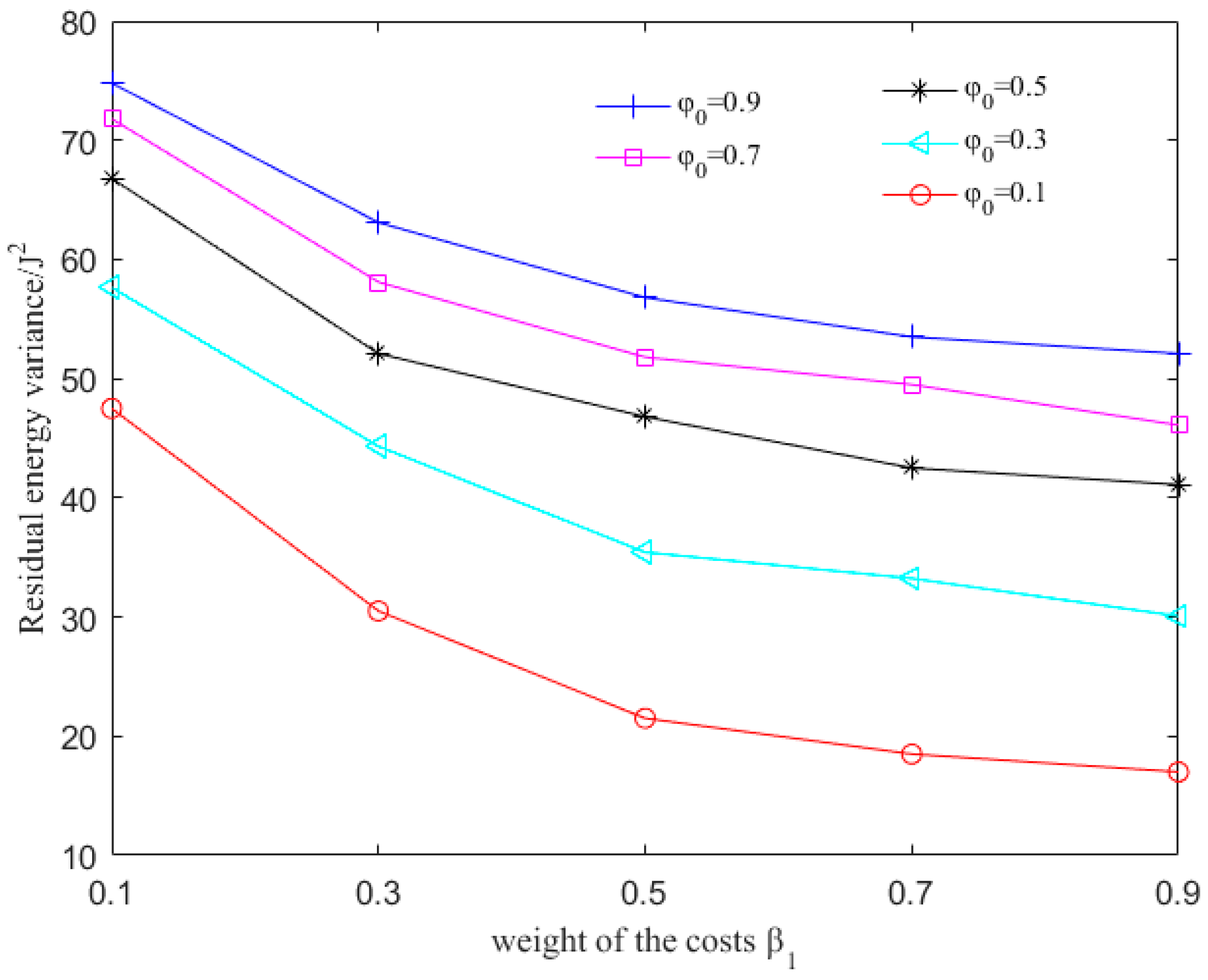
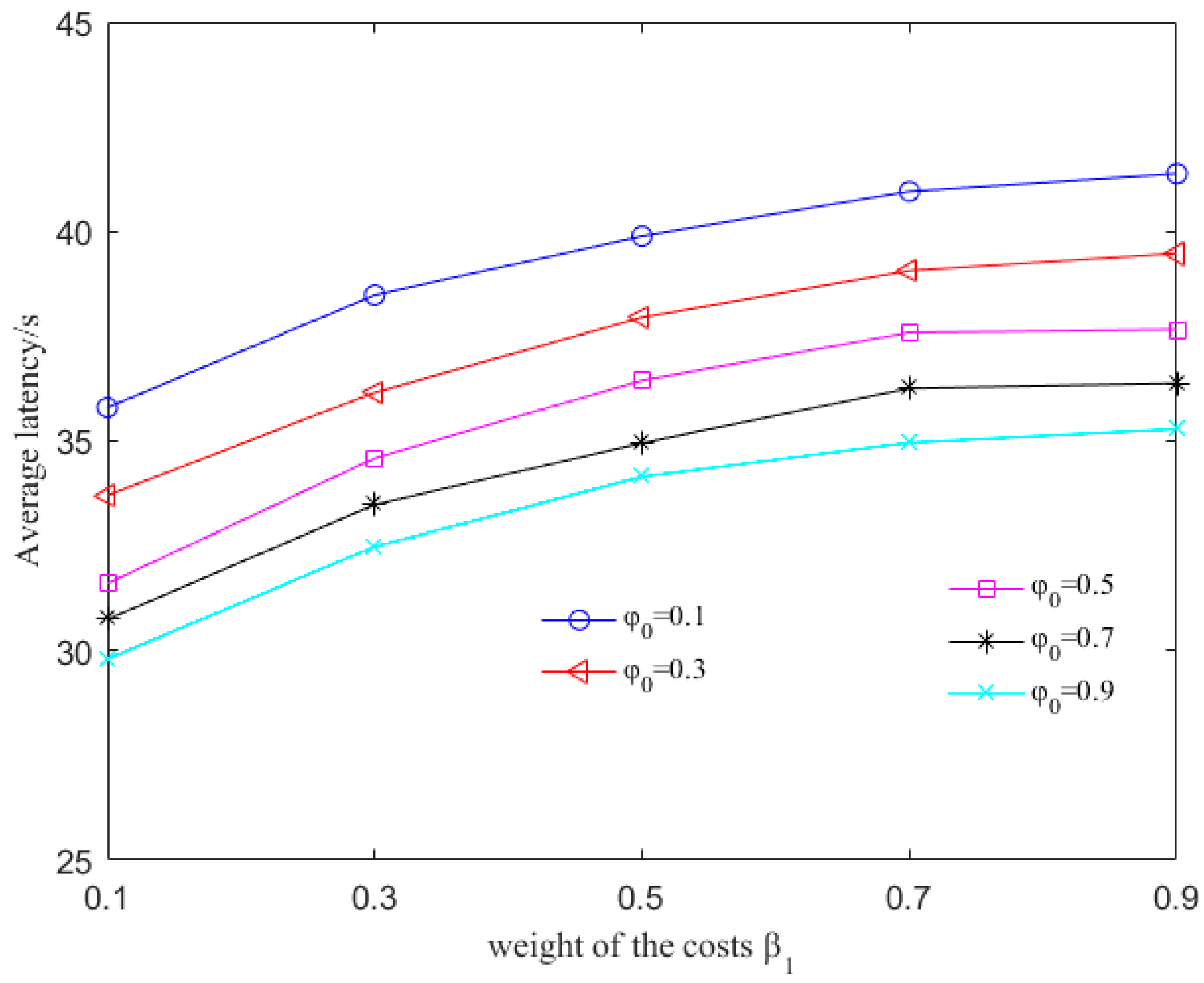
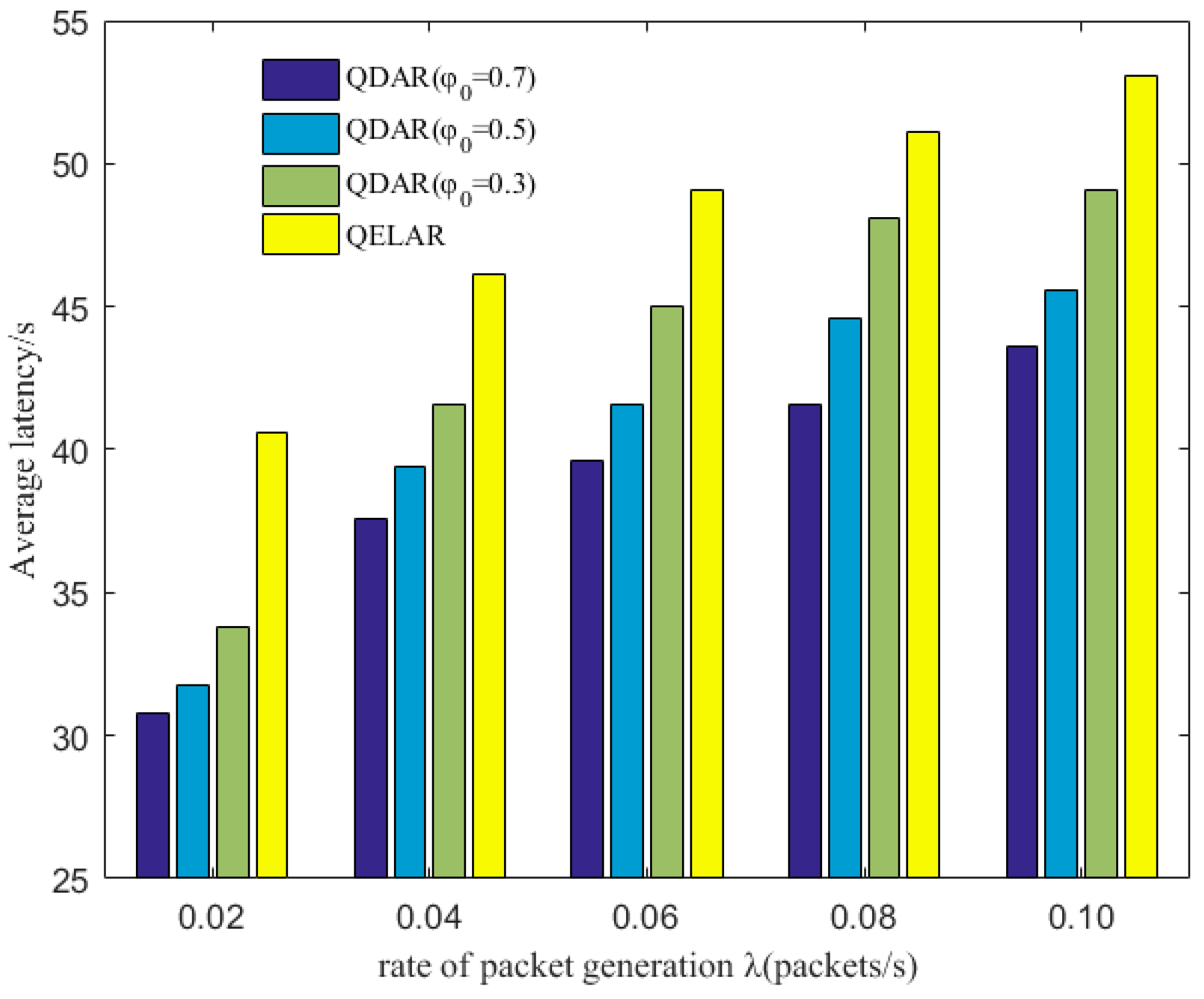
6.2. Evaluation with Different Parameters
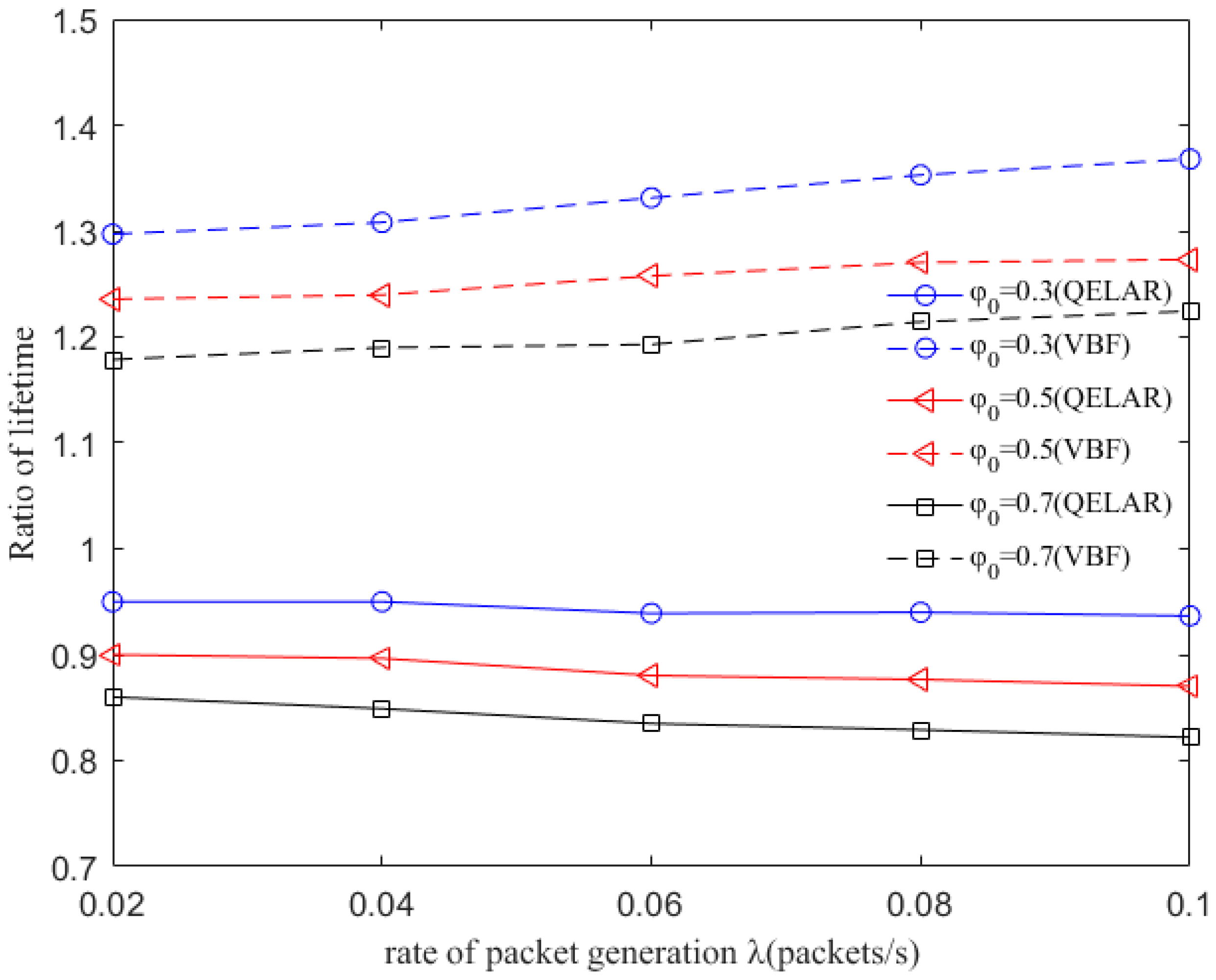
6.3. Comparison with QELAR and VBF
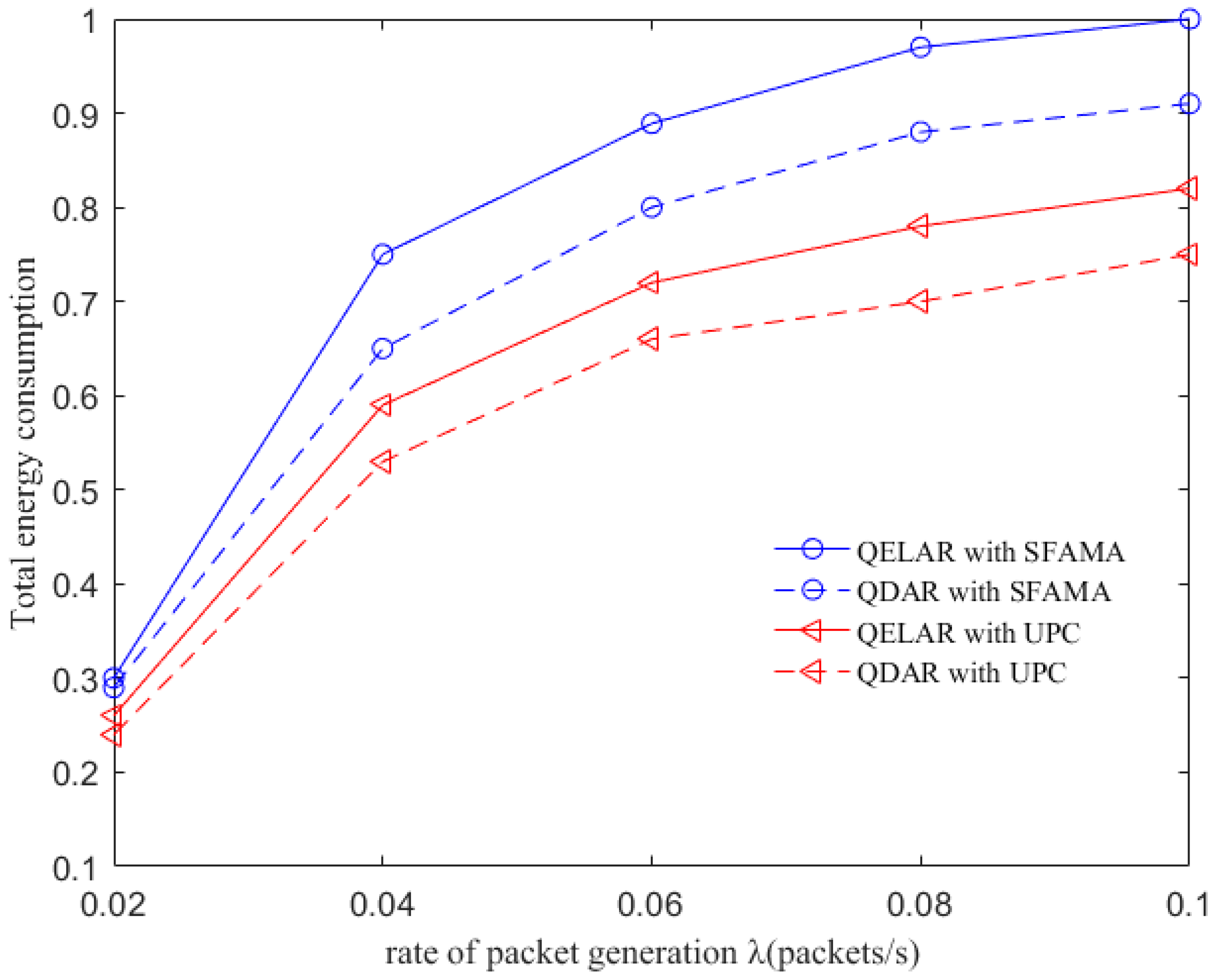
6.4. Evaluation with Different MAC Protocols
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Felemban, E.; Shaikh, F.K.; Qureshi, U.M.; Sheikh, A.A.; Qaisar, S.B. Underwater sensor network applications: A comprehensive survey. Int. J. Distrib. Sens. Netw. 2015, 11, 1–14. [Google Scholar] [CrossRef]
- Sheikh, A.A.; Felemban, E.; Felemban, M.; Qaisar, S.B. Challenges and opportunities for underwater sensor networks. In Proceedings of the 12th IEEE International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 28–30 November 2016; pp. 1–6. [Google Scholar]
- Zhang, S.; Wang, Z.; Liu, M.; Qiu, M. Energy-aware routing for delay-sensitive underwater wireless sensor networks. Sci. China Inf. Sci. 2014, 57, 1–14. [Google Scholar] [CrossRef]
- Li, N.; Martínez, J.F.; Meneses Chaus, J.M.; Eckert, M. A survey on underwater acoustic sensor network routing protocols. Sensors 2016, 16, 414. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qian, L.; Zhang, S.; Liu, M.; Zhang, Q. A MACA-Based Power Control MAC Protocol for Underwater Wireless Sensor Networks. In Proceedings of the IEEE/OES Ocean Acoustics (COA), Harbin, China, 9–11 January 2016; pp. 1–8. [Google Scholar]
- Kacimi, R.; Dhaou, R.; Beylot, A.L. Load balancing techniques for lifetime maximizing in wireless sensor networks. Ad Hoc Netw. 2013, 11, 2172–2186. [Google Scholar] [CrossRef] [Green Version]
- Darehshoorzadeh, A.; Boukerche, A. Underwater sensor networks: A new challenge for opportunistic routing protocols. IEEE Commun. Mag. 2015, 53, 98–107. [Google Scholar] [CrossRef]
- Han, G.; Jiang, J.; Bao, N.; Wan, L.; Guizani, M. Routing protocols for underwater wireless sensor networks. IEEE Commun. Mag. 2015, 53, 72–78. [Google Scholar] [CrossRef]
- Ahmadi, A.; Shojafar, M.; Hajeforosh, S.F.; Dehghan, M.; Singhal, M. An efficient routing algorithm to preserve k-coverage in wireless sensor networks. J. Supercomput. 2014, 68, 599–623. [Google Scholar] [CrossRef]
- Naranjo, P.G.V.; Shojafar, M.; Mostafaei, H.; Pooranian, Z.; Baccarelli, E. P-SEP: A prolong stable election routing algorithm for energy-limited heterogeneous fog-supported wireless sensor networks. J. Supercomput. 2016, 73, 1–23. [Google Scholar] [CrossRef]
- Shojafar, M.; Pooranian, Z.; Naranjo, P.G.V.; Baccarelli, E. FLAPS: Bandwidth and Delay-Efficient Distributed Data Searching in Fog-Supported P2P Content Delivery Networks. J. Supercomput. 2017, 1–22. [Google Scholar] [CrossRef]
- Bai, W.; Wang, H.; Shen, X.; Zhao, R.; Zhang, Y. Minimum delay multipath routing based on TDMA for underwater acoustic sensor network. Int. J. Distrib. Sens. Netw. 2016, 2016. [Google Scholar] [CrossRef]
- Al Salti, F.; Alzeidi, N.; Arafeh, B.R. EMGGR: An energy-efficient multipath grid-based geographic routing protocol for underwater wireless sensor networks. Wirel. Netw. 2016, 23, 1301–1314. [Google Scholar] [CrossRef]
- Ali, T.; Jung, L.T.; Faye, I. End-to-end delay and energy efficient routing protocol for underwater wireless sensor networks. Wirel. Pers. Commun. 2014, 79, 339–361. [Google Scholar] [CrossRef]
- Pooranian, Z.; Barati, A.; Movaghar, A. Queen-bee algorithm for energy efficient clusters in wireless sensor networks. World Acad. Sci. Eng. Technol. 2011, 73, 1080–1083. [Google Scholar]
- Wei, B.; Luo, Y.M.; Jin, Z.; Wei, J.; Su, Y. ES-VBF: An energy saving routing protocol. In Proceedings of the 2012 International Conference on Information Technology and Software Engineering, Beijing, China, 8−10 December 2012; pp. 87–97. [Google Scholar]
- Al-Bzoor, M.; Zhu, Y.; Liu, J.; Reda, A.; Cui, J.H.; Rajasekaran, S. Adaptive power controlled routing for underwater sensor networks. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Huangshan, China, 8–10 August 2012; pp. 549–560. [Google Scholar]
- Hu, T.; Fei, Y. QELAR: A machine-learning-based adaptive routing protocol for energy-efficient and lifetime-extended underwater sensor networks. IEEE Trans. Mob. Comput. 2010, 9, 796–809. [Google Scholar]
- Pompili, D.; Melodia, T.; Akyildiz, I.F. Distributed routing algorithms for underwater acoustic sensor networks. IEEE Trans. Wirel. Commun. 2010, 9, 2934–2944. [Google Scholar] [CrossRef]
- Hsu, C.C.; Liu, H.H.; Gómez, J.L.G.; Chou, C.F. Delay-sensitive opportunistic routing for underwater sensor networks. IEEE Sens. J. 2015, 15, 6584–6591. [Google Scholar] [CrossRef]
- Nowé, A.; Brys, T. A Gentle Introduction to Reinforcement Learning. Scalable Uncertainty Management; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Zhang, Y.; Chen, Y.; Zhou, S.; Xu, X.; Shen, X.; Wang, H. Dynamic node cooperation in an underwater data collection network. IEEE Sens. J. 2016, 16, 4127–4136. [Google Scholar] [CrossRef]
- Xie, P.; Cui, J.H.; Lao, L. VBF: Vector-Based Forwarding Protocol for Underwater Sensor Networks. In Proceedings of the International Conference on Research in Networking, Coimbra, Portugal, 15–19 May 2006; pp. 1216–1221. [Google Scholar]
- Su, Y.; Zhu, Y.; Mo, H.; Cui, J.H.; Jin, Z. UPC-MAC: A Power Control MAC Protocol for Underwater Sensor Networks. In Proceedings of the International Conference on Wireless Algorithms, Systems, and Applications, Zhangjiajie, China, 7–10 August 2013; pp. 377–390. [Google Scholar]
- Yan, H.; Zhou, S.; Shi, Z.J.; Li, B. A DSP implementation of OFDM acoustic modem. In Proceedings of the Second Workshop on Underwater Networks, Montreal, QC, Canada, 14 September 2007; pp. 89–92. [Google Scholar]
- Molins, M.; Stojanovic, M. Slotted FAMA: A MAC protocol for underwater acoustic networks. In Proceedings of the IEEE Oceans, Singapore, 16–19 May 2007; pp. 1–7. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description |
|---|---|
| Packet forwarding from node i to node j | |
| Constant cost | |
| , | Weight of two costs |
| The neighbor node set of i | |
| Delay sensitivity of communication between node i and j | |
| The modified | |
| Delay of communication between node i and j | |
| The time of failed communication between node i and j | |
| The energy-related cost of node i | |
| The delay-related cost of node i | |
| The discount factor of future reward |
| Name | Values |
|---|---|
| Transmission power | 10 W |
| Receiving power | 3 W |
| Idle power | 30 mW |
| Data packet size | 300 B |
| Transmission rate | 3 kbps |
| Transmission range | 500 m |
| Preamble signal length | 0.49 s |
| Simulation time | 104 s |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, Z.; Ma, Y.; Su, Y.; Li, S.; Fu, X. A Q-Learning-Based Delay-Aware Routing Algorithm to Extend the Lifetime of Underwater Sensor Networks. Sensors 2017, 17, 1660. https://doi.org/10.3390/s17071660
Jin Z, Ma Y, Su Y, Li S, Fu X. A Q-Learning-Based Delay-Aware Routing Algorithm to Extend the Lifetime of Underwater Sensor Networks. Sensors. 2017; 17(7):1660. https://doi.org/10.3390/s17071660
Chicago/Turabian StyleJin, Zhigang, Yingying Ma, Yishan Su, Shuo Li, and Xiaomei Fu. 2017. "A Q-Learning-Based Delay-Aware Routing Algorithm to Extend the Lifetime of Underwater Sensor Networks" Sensors 17, no. 7: 1660. https://doi.org/10.3390/s17071660
APA StyleJin, Z., Ma, Y., Su, Y., Li, S., & Fu, X. (2017). A Q-Learning-Based Delay-Aware Routing Algorithm to Extend the Lifetime of Underwater Sensor Networks. Sensors, 17(7), 1660. https://doi.org/10.3390/s17071660