1. Introduction
Data fusion is the process of obtaining a more meaningful and precise estimate of a state by combining data from multiple sources. The architecture of multisensor data fusion can be broadly categorized into two, depending on the way raw data are processed: (1) Centralized fusion architecture [
1], where raw data from multiple sources are directly sent to and fused in the central node for state estimation and (2) Distributed fusion architecture [
1,
2], where data measured at multiple sources are processed independently at individual nodes to obtain local estimates before they are sent to the central node for fusion. In the centralized architecture, it is possible to apply data fusion methodology such as the Kalman filter [
3] to all raw data received to yield optimal estimates in the sense of minimum variance. However, the centralized architecture can be costly especially for a large system in terms of infrastructure and communication overheads at the central node, let alone the issues of reliability and scalability. On the other hand, the distributed architecture is advantageous in reliability and scalability, with lower infrastructure and communication costs. Although advantageous, the distributed architecture needs to address statistical dependency among the local state estimates received from multiple nodes for fusion. This is due to the fact that local state estimates at individual nodes can be subject to the same process noise [
4] and to double counting, i.e., sharing the same data sources among them [
5]. Ignoring such statistical dependency or cross-correlation among multiple nodes leads to inconsistent results, causing divergence in data fusion [
6]. In the case of known cross-correlation, the Bar-Shalom Campo (BC) formula [
7] provides a consistent fusion result for a pair of redundant data sources, where the fused estimate is based on maximum likelihood [
8]. A generalization to more than two data sources with known cross-correlations is given by weighted fusion algorithms of the generalized Millman’s formula (GMF) [
9] and weighted Kalman filter (WKF) [
10].
Sensors often provide spurious and inconsistent data due to unexpected situations such as short duration spike faults, sensor glitches, a permanent failure or slowly developing failure due to sensor elements [
5,
11]. Since these types of uncertainties are not attributable to the inherent noise, they are difficult to predict and model. The fusion of inconsistent sensor data with correct data can lead to severely inaccurate results [
12]. For example, when exposed to abnormalities and outliers, a Kalman filter would easily diverge [
13]. Hence, a data validation scheme is required to identify and eliminate the sensor faults/outliers/inconsistencies before fusion.
The detection of inconsistency needs either a priori information often in the form of specific failure model(s) or data redundancy [
5]. Model-based approaches use the generated residuals between the model outputs and actual measurements to detect and remove faults. For instance, in [
14], the Nadaraya–Watson estimator and a priori observations are used to validate sensor measurements. Similarly, a priori system model information as a reference is used to detect failures in filtered state estimates [
15,
16,
17]. However, requirement of the prior information restricts the usage of these methods in the general case where prior information is not available or unmodeled failure occurs. A method to detect spurious data based on the Bayesian framework is proposed in [
18,
19]. The method adds a term to the Bayesian formulation which has the effect of increasing the covariance of the fused probability distribution when measurement from one of the sensor is inconsistent with respect to the other. However, the method is based on heuristics and assumes independence of sensor estimates in its analysis. In [
20], the Covariance Union (CU) method is proposed where the fused covariance is enlarged to cover all local means and covariances in such a way that the fused estimate is consistent under spurious data. However, the method incurs high computational cost and results in an inappropriately large conservative fused result.
In some applications, the state variables observed in a multisensory system may be subject to additional constraints. These constraints can arise due to the basic laws of physics, kinematics or geometry consideration of a system or due to the mathematical relations to satisfy among states. For instance, the energy conservation laws in an undamped mechanical system; Kirchhoff’s laws in electric circuits; a road constraint in a vehicle-tracking scenario [
21]; an orthonormal constraint in quaternion-based estimation [
22] etc. These constraints if properly included can lead to improvement in state estimation and data fusion.
Various methods have been proposed to incorporate linear constraints among the state variables of dynamic systems [
23,
24,
25,
26,
27,
28]. For instance, the dimensionality reduction method converts a constrained estimation problem to an unconstrained one of lower dimension by eliminating some state variables using the constraints [
25]. However, the state variables in a reduced dimension model may become difficult to interpret and their physical meaning may be lost [
23]. The pseudo-measurement method satisfies the linear constraints among state variables by treating the state constraints as additional perfect/noise-free measurements [
26,
27,
28]. However, this method increases the computational complexity of state estimation due to an increase in the dimension of augmented measurement. Furthermore, due to the singularity of augmented measurement covariance, the method may cause numerical problems [
23,
29]. A popular approach, the estimate projection method, projects the unconstrained estimate obtained from conventional Kalman filtering onto the constraint subspace using classical optimization methods [
23,
24]. Unfortunately, the method may not lead to the true constraint optimum since the projection method merely gives the solution as a feasible point that is closest to the unconstrained minimum.
This paper presents a unified and general data fusion framework, referred to as the Covariance Projection (CP) method to fuse multiple data sources under arbitrary correlations and linear constraints as well as data inconsistency. The method projects the probability distribution of true states and measurements around the predicted states and actual measurements onto the constraint manifold representing the constraints to be satisfied among true states and measurements. The proposed method also provides a framework for identifying and removing outliers in a fusion architecture where only sensor estimates may be available at the fusion center. This paper is an extended and improved version of the conference paper [
30]. What was presented in [
30] is a preliminary new framework of data fusion that we proposed. On the other hand, what is presented here represents a much more detailed implementation and refinement of the concept proposed in the conference paper. Specifically, this paper includes the following additions: (1) a detailed analysis of the equivalence of the proposed method to conventional methods for fusing redundant data sources; (2) handling linear constraints simultaneously under the proposed data fusion framework; (3) refining the mathematical formula and technical descriptions associated with them; and (4) detailed analysis of the method with additional simulations that deal with state estimation and data fusion in the presence of correlations, outliers and constraints.
2. Problem Statement
Consider a distributed sensor architecture [
1], where each sensor system is equipped with a tracking system to provide local estimates of some quantity of interest in the form of mean and covariance. Assume the following linear dynamic system model for each local sensor system,
where
is the discrete time,
is the system matrix,
is the input matrix,
is the input vector and
is the state vector. The system process is affected by zero mean Gaussian noise
with covariance matrix
. The sensor measurements are approximated as,
where
is the observation matrix and
represents the number of sensors.
is Gaussian noise with covariance matrices
. Each sensor systems employs a Kalman filter to provide local state mean estimate
and its covariance
[
31]. A prediction of the state estimate
and its estimation error covariance
can be computed based on process model (1),
The Kalman filter then provides the state estimate
and its covariance
as,
with the Kalman gain,
. The estimates provided by sensor systems are assumed to be correlated due to the common process noise or double counting, that is,
. To ensure optimality of the fused results, the cross-covariance
should be properly incorporated.
Due to the inherent nature of the sensor and environmental factors [
32], the sensor measurements can also be perturbed by unmodel random faults
,
Subsequently, the estimates computed by local sensor systems may be spurious and inconsistent. Therefore, validation of the sensor estimates is required to remove inconsistencies before the fusion process.
In addition, the states
of the sensor systems may subject to linear constraints due to the geometry of the system environment or the mathematical description of the system [
23], such that,
where
and
are both known.
is assumed to have a full row rank. The constraints provide deterministic information about the state variables and can be used to improve the fusion accuracy.
These issues of correlations, data inconsistency and state constraints motivate the development of the Covariance Projection method, which is described next.
3. Proposed Approach
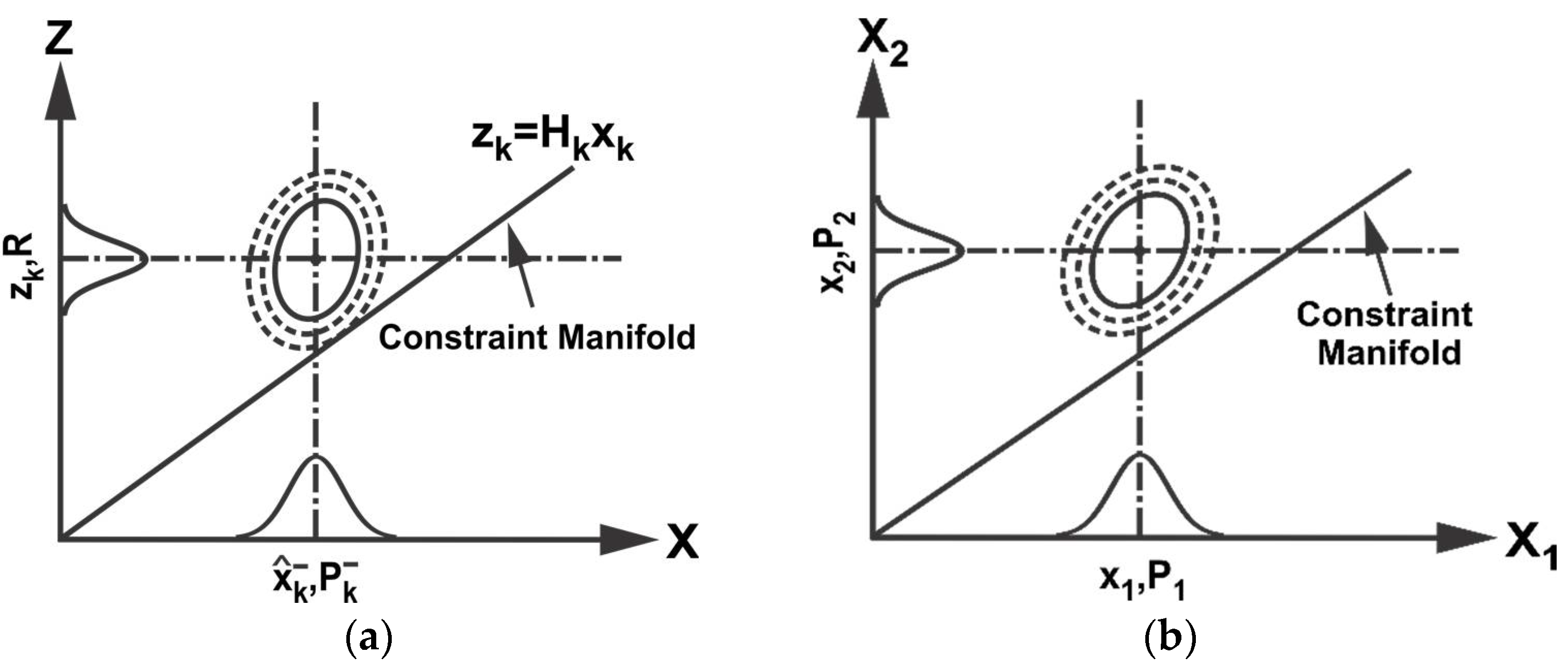
The proposed method first represents the probability of true states and measurements in the extended space around the data from state predictions and sensor measurements, where the extended space is formed by taking states and measurements as independent variables. Any constraints among true states and measurements that should be satisfied are then represented as a constraint manifold in the extended space. This is shown schematically in
Figure 1a for filtering as an example (refer to Equations (1)–(6)). Data fusion is accomplished by projecting the probability distribution of true states and measurements onto the constraint manifold.
More specifically, consider two mean estimates,
and
, of the state
, with their respective covariances as
,
. Furthermore, the estimates are assumed to be correlated with cross-covariance
. The mean estimates and their covariances together with their cross-covariance in
are then transformed to an extended space of
along with the linear constraint between the two estimates:
where
and
are constant matrices of compatible dimensions. In the case where
and
estimate the same entity,
and
become identity matrix
.
Figure 1b illustrates schematically the fusion of
and
in the extended space based on the proposed CP method. Fusion takes place by finding the point on the constraint manifold that represents the minimum weighted distance from
in
, where the weight is given by
. As seen later, the proposed CP method with the minimum weighted distance is shown to be equivalent to the minimum variance estimates but advantageous for dealing with additional constraints and data inconsistency.
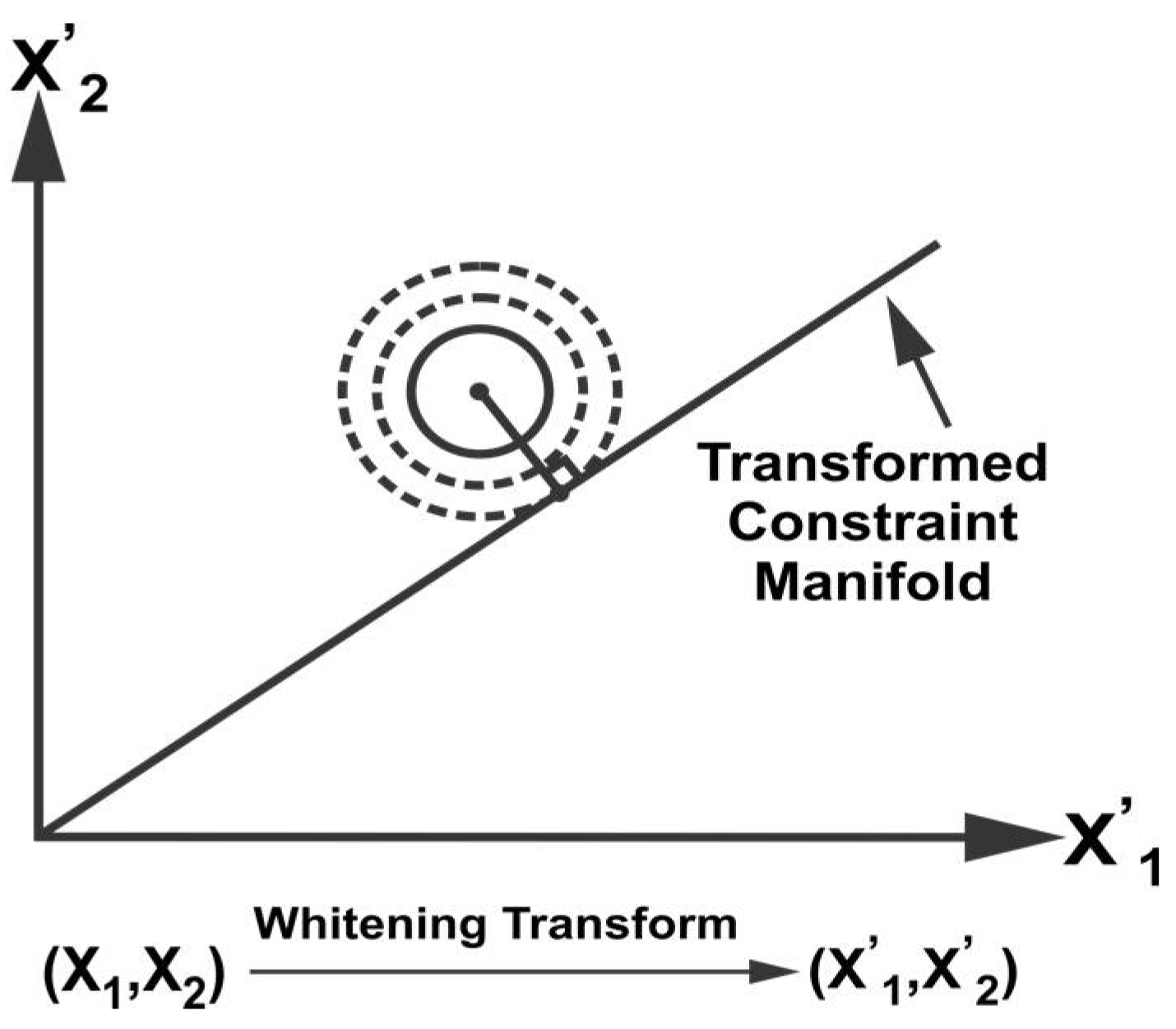
To find a point on the constraint manifold with minimum weighted distance, we apply the whitening transform (WT) defined as,
, where
D and
E are the eigenvalue and eigenvector matrices of
. Applying WT,
where the matrix
is the subspace of the constraint manifold.
Figure 2 illustrates the transformation of the probability distribution as an ellipsoid into a unit circle after WT. The probability distribution is then orthogonally projected on the transformed manifold
to satisfy the constraints between the data sources in the transformed space as illustrated in
Figure 2. Inverse WT is applied to obtain the fused mean estimate and covariance in the original space,
where
is the orthogonal projection matrix. Using the definition of various components in (10) and (11), a close form simplification can be obtained as,
The details of the simplification are provided in
Appendix A. Due to the projection in extended space of
, (12) and (13) provide a fused result with respect to each data source. In the case where
and
estimate the same entity, that is,
, the fused result will be same for the two data sources. As such, a close form equation for fusing redundant data sources in
can be obtained from (12) and (13) as,
Given mean estimates , , …, of a state with their respective covariances and known cross-covariances , (14) and (15) can be used to obtain the optimal fused mean estimate and covariance with .
For fusing correlated estimates from
redundant sources, the CP method is equivalent to the weighted fusion algorithms [
9,
10], which compute the fused mean estimate and covariance as a summation of weighted individual estimates as,
with
. Where the weights
are determined by solving some cost function of (16) and (17) such that,
. Equivalently, the CP fused mean and covariance can be written as,
where
and
. In the particular case of two data sources, the CP fused solution reduces to the well-known Bar-Shalom Campo formula [
7],
Although equivalent to the traditional approaches in fusing redundant data sources, the proposed method offers a generalized framework not only for fusing correlated data sources but also for handling linear constraints and data inconsistency simultaneously within the framework.
The proposed method provides an unbiased and optimal fused estimate in the sense of minimum mean square error (MMSE).
Theorem 1. Forunbiased mean estimates, the fused mean estimateprovided by the CP method is an unbiased estimator of, that is, .
Proof. Taking the expectation on both sides, we get,
Since the sensor estimates
are unbiased, we have
,
where
. This concludes that the fused state estimate
is an unbiased estimate of
. ☐
Theorem 2. The fused covarianceof the CP method is smaller than the individual covariances, that is,.
Proof. From equation (15), we can write,
By Schwartz matrix inequality, we have,
where
is the constraint between data sources and
is the constraint matrix for
. The equality holds for
that is,
when
.
It can be observed from (14) and (15) that computation of cross-covariance
is needed to compute the fused mean and covariance. Cross-covariance among the local estimates can be computed as [
9,
10,
33],
where
and
are the Kalman gain of source
and
respectively for
and
represent the cross covariance of the previous cycle between source
and
. ☐
4. Fusion in the Presence of Spurious Data
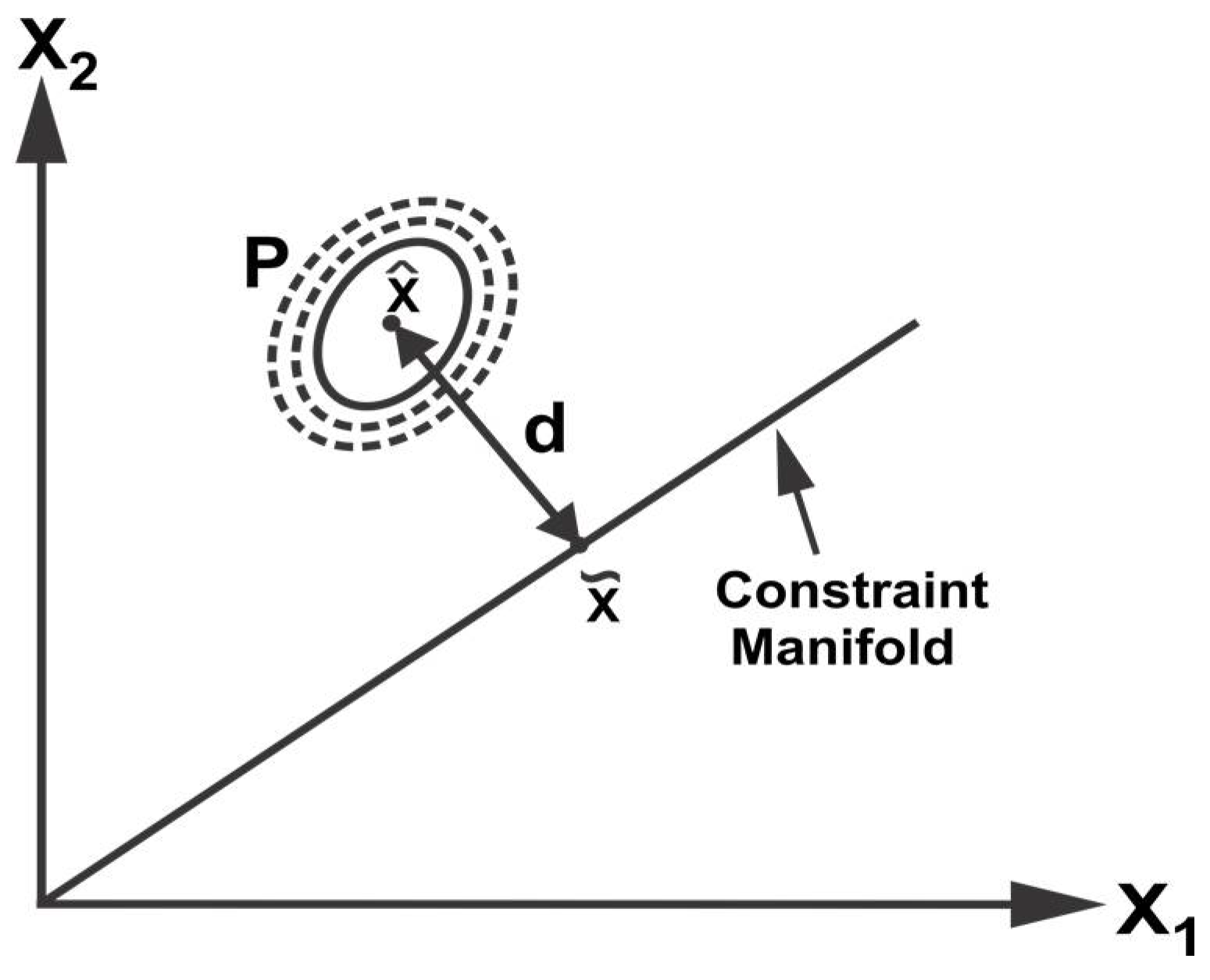
Due to the inherent nature of sensor devices and the real-world environment, the sensor observations may also be affected by random faults. Subsequently, the local estimates provided by sensor systems in a distributed architecture may be spurious and inconsistent. This may cause the fusion methodologies to fail since they are based on the assumption of consistent input sensor estimates. Therefore, a validation scheme is required to detect and remove the spurious estimates from the fusion pool. The proposed approach exploits the constraint manifold among sensor estimates to identify any data inconsistency. The identification of inconsistent data is based on the distance from the constraint manifold to the mean of redundant data sources in the extended space that provides a confidence measure with the relative disparity among data sources. Assuming a joint multivariate normal distribution for the data sources, the data confidence can be measured by computing the distance from the constraint manifold as illustrated in
Figure 3.
Consider the joint space representation of
sensor estimates
,
where
is the dimension of the state vector. The distance
from the constraint manifold can be calculated as,
where
is the point on the manifold and can be obtain by using (12). In the case of two data sources with mean
,
∈
and respective covariance matrices
and
∈
. The distance
can be obtained as,
The point on the manifold is given as,
The details of simplifications are provided in
Appendix B. From (24), it can be observed that distance
is a weighted distance between the two data sources and it can provide a measure of nearness or farness of the two data sources to each other. A large value of
implies a large separation while a small
signifies closeness of the data sources. In other words, the distance from the manifold provides an indication of the relative disparity among data sources.
Theorem 3. Fordata sources ofdimension, thedistance (23) follow a chi-squared distribution withdegrees of freedom (DOF), that is,.
Proof. Under the whitening transformation,
,
and
. Thus, we can write,
where for normal distribution
,
is an independent standard normal distribution
. For
N dimensions of the state vector, the right-hand side of (26) is
, thus distance d follows a chi-square distribution with
DOF, that is,
. For
data sources with
states,
Since
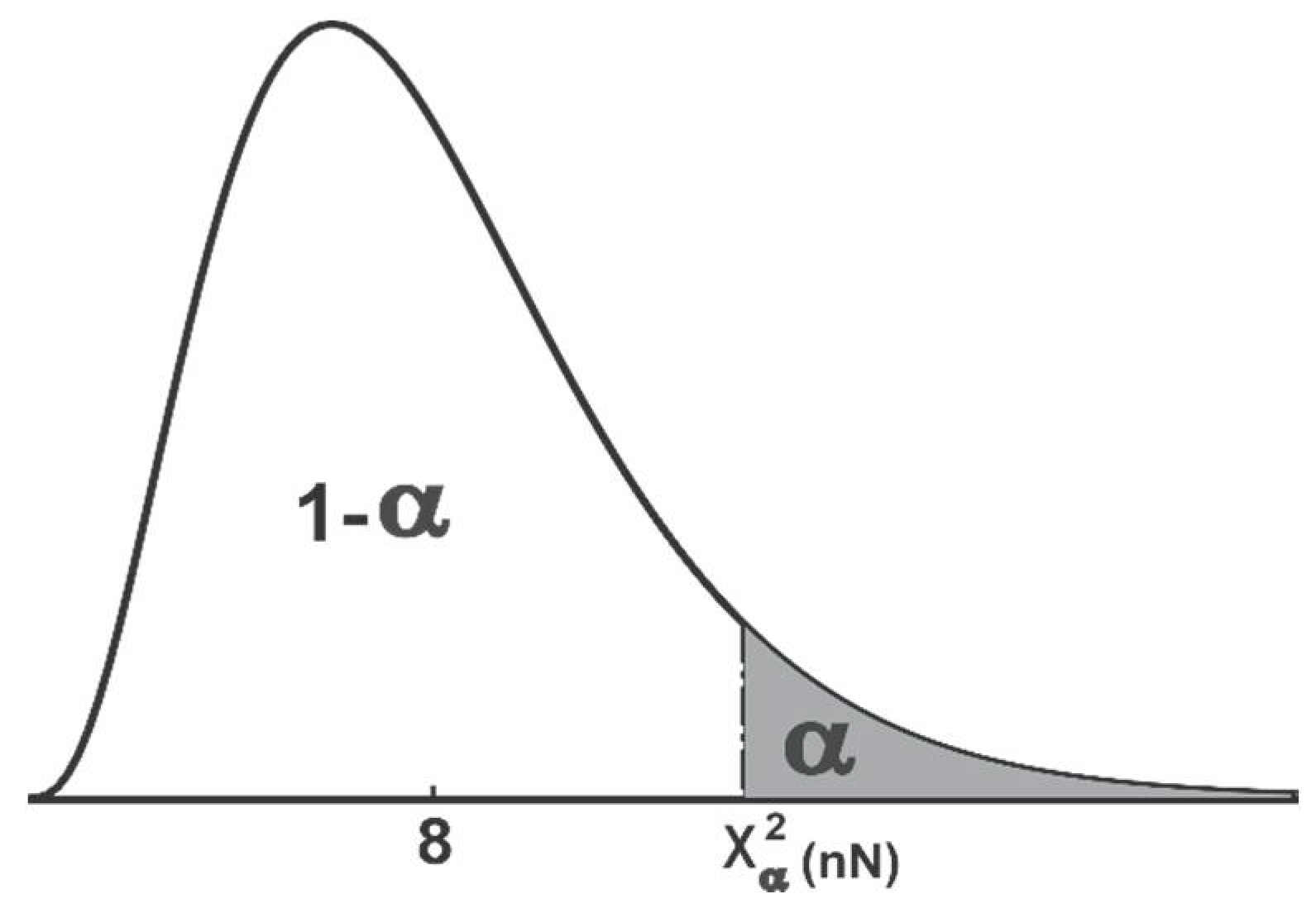
is a chi-square distribution with
DOF, then for any significance level
,
is defined such that the probability,
This is depicted in
Figure 4. Hence, to have a confidence of 100 × (1 −
) percent,
should be less than respective critical value as illustrated in
Figure 4. A chi-square table [
34] can be used to obtain the critical value for the confidence distance with a particular significance level and DOF. A value of
= 0.05 is assumed in this paper unless specified. ☐
4.1. Inconsistency Detection and Exclusion
To obtain reliable and consistent fusion results, it is important that the inconsistent estimates be identified and excluded before fusion. For this reason, at each time step when the fusion center receives computed estimates from sensor nodes, distance is calculated. A chi-square table is then used to obtain the critical value for a particular significance level and DOF. A computed distance less than the critical value mean that we are confident about the closeness of sensor estimates and that they can be fused together to provide a better estimate of the underlying states. On the other hand, a distance greater than or equal to the critical value indicate spuriousness of the sensor estimates. At least one of the sensor estimate is significantly different than the other sensor estimates. To exclude the outliers, a distance from the manifold is computed for every estimate and compared with the respective critical values. For mean estimates with respective covariances and cross-covariances , the hypothesis and decision rule are summarized as follows,
Compute: Decision Rule: Accept if
Reject if
If the hypothesis
is accepted, then the estimates are optimally fused using (14) and (15). On the other hand, rejection of null hypothesis means that at least one of the sensor estimates is significantly different than the other estimates. Then, a distance from the manifold is computed for each of the estimates as,
with
computed using (14). The outliers are identified and eliminated based on the respective critical value, that is, if
, they are rejected, where
is the dimension of an individual data source.
4.2. Effect of Correlation on d Distance
Since the estimates provided by multiple data sources are correlated, it is important to consider the effect of cross-correlation in the calculation of confidence distance. Consider two sensor estimates
and
with respective variances
and
and cross-covariance
, where
is the correlation coefficient. The
distance for the pair of multivariate Gaussian estimates
and
, with cross-covariance
can be written as,
It is apparent that the distance between the mean values is affected by the correlation between the data sources.
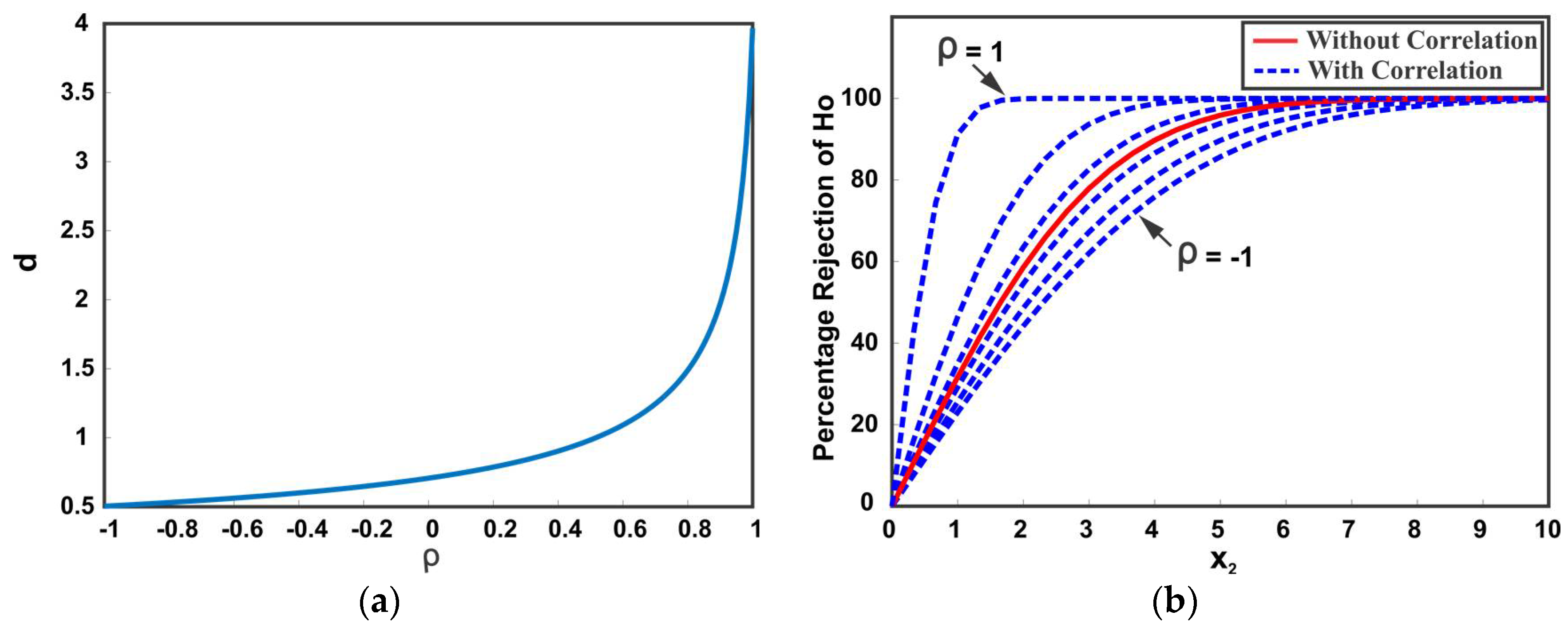
Figure 5 illustrates the dependency of confidence distance
on the correlation coefficient.
Figure 5a shows the distance
with changing correlation coefficient from −1 to 1. It can be observed that a positive correlation between the data sources results in a large
distance. This means that a slight separation between the positively correlated data sources indicates spuriousness with high significance as compared to negatively correlated and uncorrelated data sources.
Figure 5b shows the scenario in which a data source (with changing mean and constant variance) is moving away from another data source (with constant mean and constant variance). The distance
is plotted for various values of correlation coefficients. The y-axis shows the percentage of rejection of the null hypothesis
. It can be noted that ignoring the cross-correlation in distance
results in underestimated or overestimated confidence and may lead to an incorrect rejection of the true null hypothesis (Type I error) or incorrect retaining of false null hypothesis (Type II error). The proposed framework inherently takes care of any cross-correlation among multiple data sources in the computation of distance
.
Example: Consider a numerical simulation with the constant state, Three sensors are used to estimate the state
, where the measurements of the sensors are affected with respective variances of
. The values for the parameters assumed in the simulation are,
The sensor measurements are assumed to be cross-correlated. It is also assumed that the sensor 1, sensor 2 and sensor 3 measurements are independently corrupted by unmodeled noise and produce inconsistent data for 33%, 33% and 34% of the time respectively. The sensors compute local estimates of the state and send it to the fusion center. Three strategies for combining the local sensor estimates are compared: (1) CP, which fuses the three sensor estimates using (14) and (15) without removing outliers; (2) CP WO-d means the outliers were identified and rejected before fusion based on (27) with
, that is, correlation in computation of
is ignored and; (3) CP WO-dC, reject the outliers based on (27) with taking into account the cross-correlation.
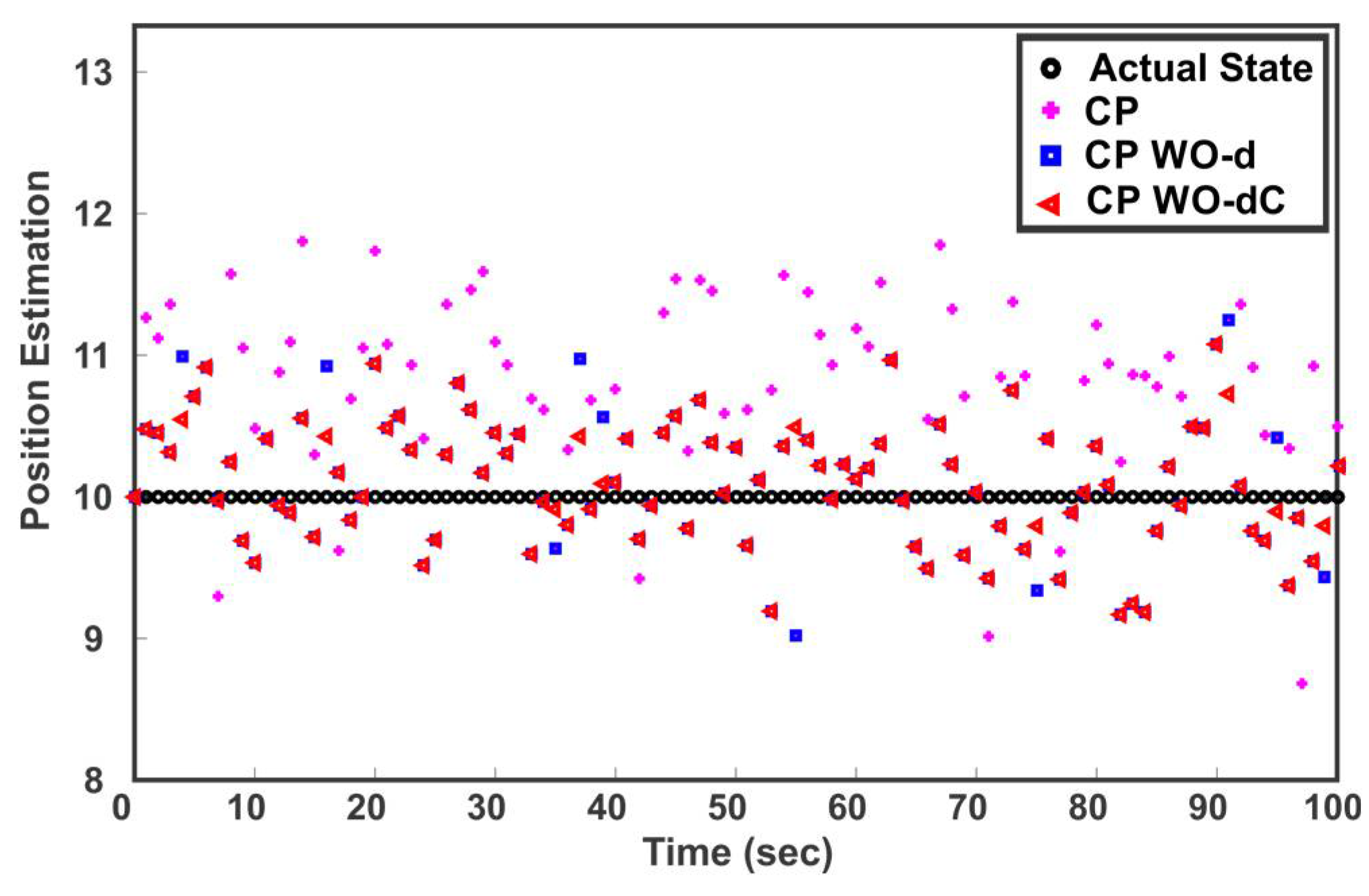
Figure 6 shows the fused solution of three sensors when the estimate provided by sensor 2 is in disagreement with sensor 1 and 3. It can be observed from
Figure 6 that neglecting the cross-correlation in CP WO-d results in Type II error, that is, all the three estimates are fused despite the fact that estimate 2 is inconsistent. CP WO-dC correctly identifies and eliminates the spurious estimate before the fusion process.
Figure 7 shows the estimated position after the fusion of the three sensors’ estimates for 100 samples. It can be seen that the presence of outliers greatly affects the outcome of multisensor data fusion. As depicted in
Figure 7, eliminating outliers before fusion improves the estimation performance. The fused samples of CP WO-d and CP WO-dC on average lies closer to the actual state.
Figure 7 also shows the difference in fusion performance when outliers are identified with and without considering cross-correlation. It can be noted that neglecting the correlation affects the estimation quality because of Type I and Type II errors.
5. Fusion under Linear Constraints
The system model of a linear dynamic system takes into account the relation and dependencies among components of the state vector. In some applications, however, the state variables may be subject to additional constraints due to the basic laws of physics, geometry of the system environment or due to the mathematical description of the state vector. Imposing such certain information in an otherwise probabilistic setting should yield a more accurate estimate that is guaranteed to be feasible.
Consider a linear dynamic system model,
where
represents the discrete-time index,
is the system matrix,
is the input matrix,
is the input vector and
is the state vector. The system process noise
with covariance matrix
and measurement noise
with covariance
are assumed to be correlated, that is,
The state
is known to be constrained as,
For , the state space can be translated by a factor such that . After constrained state estimation, the state space can be translated back by the factor c to satisfy . Hence, without loss of generality, the case is considered for analysis here. The matrix is assumed to have a full row rank. A row deficient matrix signifies the presence of redundant constraints. In such a case, we can simply remove the linearly dependent rows from . In the following, the estimate projection (EP) method is briefly reviewed which is followed by the Covariance Projection (CP) method for linear constraints among state variables.
5.1. Estimate Projection Method
The estimate projection (EP) method [
23,
24] projects the unconstrained estimate obtained from Kalman filtering onto the constraint subspace to satisfy the linear constraints among state variables. Let us denote the unconstrained filtered estimate and constrained estimate as
and
, respectively. Then the following optimization problem is solved to obtain the constrained estimate,
where
is any symmetric positive definite weighting matrix. Solving (31) using Lagrange multipliers results in a constrained mean and covariance,
where
is the projector on the null space of constrained matrix
, defined as,
Any symmetrical positive definite matrix can be used as a weighting matrix to obtain the constrained estimate but the two most common choices are identity matrix and inverse of unconstrained covariance .
5.2. Covariance Projection Method for Linear Constraints
The CP framework incorporates any linear constraints among states without any additional processing. Let us denote the constrained filtered estimate of the CP method as
. The extended space representation of the state predictions and measurements of multiple sensors can be written as,
Then the CP estimate in the presence of linear constraints among states can be obtained using (12) and (13) as,
where the
matrix is the subspace of the constraint among the state prediction
and sensor measurements
as well as linear constraints
among state variables. The subspace of the linear constraint among state prediction and sensor measurements can be written as,
Then,
is a combination of
and
, that is,
The projection of the probability distribution of true states and measurements around the predicted states and actual measurements onto the constraint manifold in the extended space provide the filtered or fused estimate of state prediction and sensor measurements as well as completely satisfying the linear constraints among the states directly in one step.
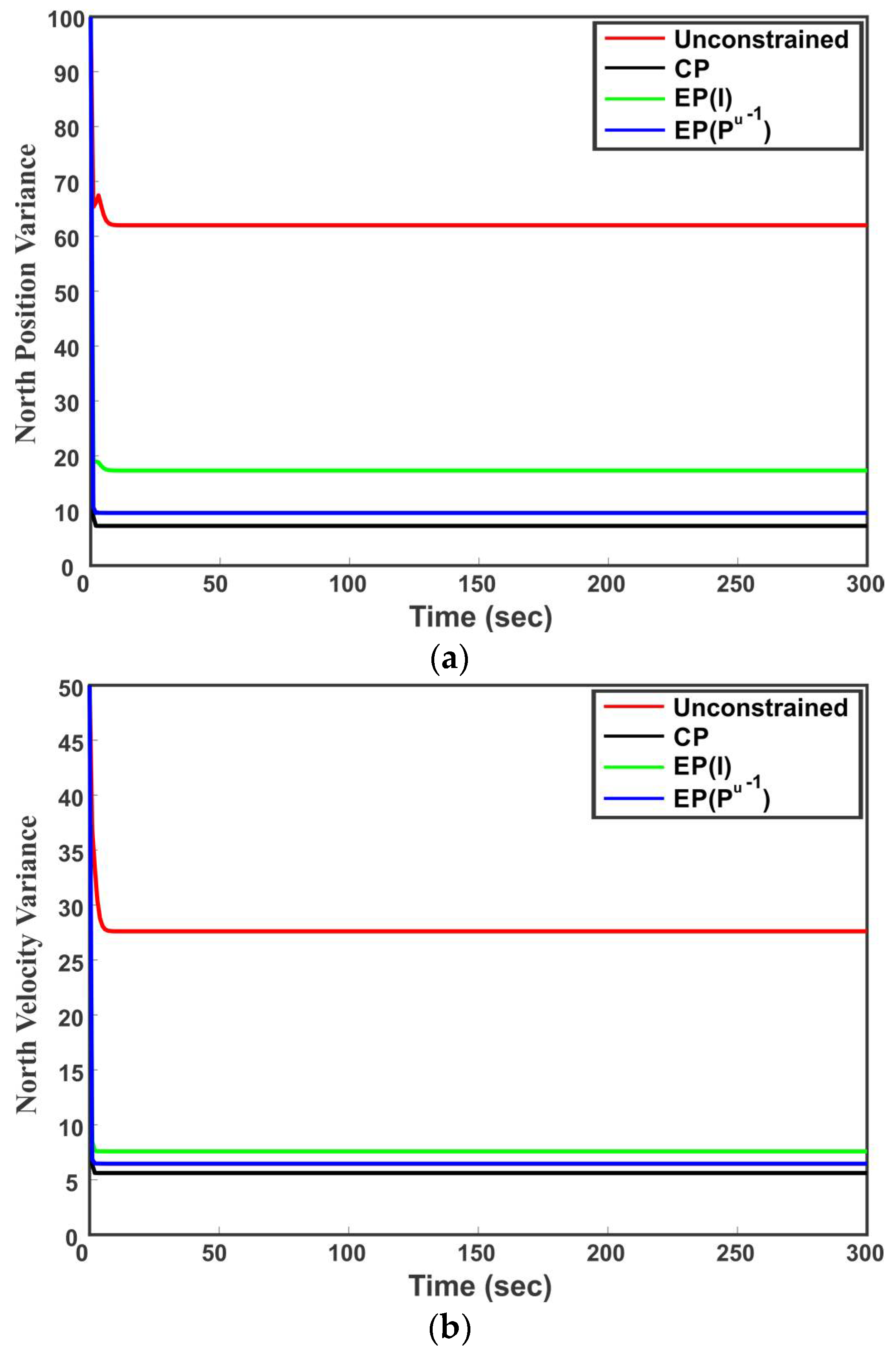
It can be observed from (31) that the EP method forces the unconstrained estimate on the linear constraint under some norm to satisfy the linear constraints among state variables. Consequently, the true optimality cannot be guaranteed due to the fact that the projected point close to the unconstrained estimate does not imply that it is close to the true constrained state [
29]. On the other hand, the unified constraint matrix
of the CP method ensures that the linear constraints among state variables are exactly satisfied. Furthermore, as compared to the EP method that needs the online projection steps (32) and (33) after filtering, the
matrix for the CP method can be computed offline. This means that the EP method is computationally less efficient. Additionally, the proposed CP method is inherently suitable for taking care of any cross-correlation in the constrained estimation process.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}