1. Introduction
The sharp increase in demand for global food raises the awareness of the public, especially agricultural scientists, to global food security. To meet the high demand for food in 2050, agriculture will need to produce almost 50 percent more food than was produced in 2012 [
1]. There are many ways to improve yields for canola and other crops. One of the solutions is to increase breeding efficiency. In the past decade, advances in genetic technologies, such as next generation DNA sequencing, have provided new methods to improve plant breeding techniques. However, the lack of knowledge of phenotyping capabilities limits the ability to analyze the genetics of quantitative traits related to plant growth, crop yield, and adaptation to stress [
2]. Phenotyping creates opportunities not only for functional research on genes, but also for the development of new crops with beneficial features. Image-based phenotyping methods are those integrated approaches that enable the potential to greatly enhance plant researchers’ ability to characterize many different traits of plants. Modern advanced imaging methods provide high-resolution images and enable the visualization of multi-dimensional data. The basics of image processing have been thoroughly studied and published. Readers can find useful information on image fusion in the textbooks by Starck or Florack [
3,
4]. These methods allow plant breeders and researchers to obtain exact data, speed up image analysis, bring high throughput and high dimensional phenotype data for modeling, and estimate plant growth and structural development during the plant life cycle. However, with low-cost and low-resolution sensors, phenotyping would meet some obstacles to solve low-resolution images. To cope with this issue, image fusion is a valuable choice.
Image fusion is a technique that combines many different images to generate a fused image with highly informative and reliable information. There are several image fusion types, such as multi-modal and multi-sensor image fusion. In multi-modal image fusion, two different kinds of images are fused, for example, combining a high-resolution image with a high-color image. In multi-sensor image fusion, images from different types of sensors are combined, for example, combining an image from a depth sensor with an image from a digital sensor. Image fusion methods can be divided into three levels depending on the processing: pixel level, feature level, and decision level [
5,
6]. Image fusion at the pixel level refers to an imaging process that occurs in the pixel-by-pixel manner in which each new pixel of the fused image obtains a new value. At a higher level than the pixel level, feature-level image fusion first extracts the relevant key features from each of the source images and then combines them for image-classification purposes such as edge detection. Decision-level image fusion (also named as interpretation-level or symbol-level image fusion) is the highest level of image fusion. Decision-level image fusion refers to a type of fusion in which the decision is made based on the information separately extracted from several image sources.
Over the last two decades, image fusion techniques have been widely applied in many areas: medicine, mathematics, physics, and engineering. In plant science, many image fusion techniques are being deployed to improve the classification accuracy for determining plant features, detecting plant diseases, and measuring crop diversification. Fan et al. [
7] well implemented a Kalman filtering fusion to improve the accuracy of the prediction on the citrus maturity. In a related work, a feature-level fusion technique [
8] was successfully developed to detect some types of leaf disease with excellent results. In other similar research, apple fruit diseases were detected by using feature-level fusion in which two or more color and feature textures were combined [
9]. Decision-level fusion techniques have been deployed to detect crop contamination and plague [
10]. Dimov et al. [
11] have also implemented the Ehler’s fusion algorithm (decision level) to measure the diversification of the three critical crop systems with the highest classification accuracy. These findings suggest that image-fusion techniques at many levels are broadly applied in the plant science sector because they offer the highest classification accuracy.
Currently, many multi-focus image fusion techniques have been developed [
12,
13]. The techniques can be categorized into two classes: spatial domain methods and frequency domain methods. In the spatial domain methods, source images are directly fused, in which the information of image pixels are directly used without any pre-processing or post-processing. In the frequency domain methods, source images are transformed into frequency domain, and then combined. Therefore, frequency domain methods are more complicated and time-consuming than spatial domain methods. Many studies investigated multi-focus image fusion techniques in spatial and frequency domains to improve the outcomes. Wan et al. [
14] proposed a method based on the robust principal component analysis in the spatial domain. They developed this method to form a robust fusion technique to distinguish focused and defocused areas. The method outperforms wavelet-based fusion methods and provides better visual perception; however, it has a high computation cost. In the similar spatial domain, a multi-focus image fusion method based on region [
15] was developed, in which, their algorithm offers smaller distortion and a better reflection of the edge information and importance of the source image. Similarly, Liu et al. [
16] investigated a fusion technique based on dense scale invariant feature transform (SIFT) in the spatial domain. The method performs better than other techniques in terms of visual perception and performance evaluation, but it requires a high amount of memory. In the frequency domain, Phamila and Amutha [
17] conducted a method based on Discrete Cosine Transform. The process computes and obtains the highest variance of the 8 × 8 DCT coefficients to reconstruct the fused image. However, the method suffers from undesirable side effects such as blurring and artifact. In a recently published article, the authors reviewed the works using sparse representation (SR)-based methods on multi-sensor systems [
18]. Based on sparse representation, the same authors also developed the image fusing method for multi-focus and multi-modality images [
19]. This SR method learns an over-complete dictionary from a set of training images for image fusion, it may result in a huge increment of computational complexity.
To deal with these obstacles mentioned above, a new multi-focus image fusion based on the image quality assessment (IQA) metrics is proposed in this paper. The proposed fusion method is developed based on crucial IQA metrics and a gradient domain fast guided image filter (GDFGIF). This approach is motivated by the fact that visual saliency maps, including visual saliency, gradient similarity, and chrominance similarity maps, outperform most of the state-of-the-art IQA metrics in terms of the prediction accuracy [
20]. According to Reference [
20], visual saliency similarity, gradient similarity, and chrominance maps are vital metrics in accounting for the visual quality of image fusion techniques. In most cases, changes of visual saliency (VS) map can be a good indicator of distortion degrees and thus, VS map is used as a local weight map. However, VS map does not work well for the distortion type of contrast change. Fortunately, the image gradient can be used as an additional feature to compensate for the lack of contrast sensitivity of the VS map. In addition, VS map does not work well for the distortion type change of color saturation. This color distortion cannot be well represented by gradient either since usually the gradient is computed from the luminance channel of images. To deal with this color distortion, two chrominance channels are used as features to represent the quality degradation caused by color distortion. These IQA metrics have been proved to be stable and have the best performance [
20]. In addition, gradient domain guided filter (GDGIF) [
21] and fast guided filter (FGF) [
22] are adopted in this work as the combination of GDGIF and FGF and can offer fast and better fused results, especially near the edges, where halo artifacts appear in the original guided image filter. This study focuses on how to fuse multi-focus color images to enhance the resolution and quality of the fused image using a low-cost camera. The proposed image fusion method was developed and compared with other state-of-the-art image fusion methods. In the proposed multi-focus image fusion, two or more images captured by the same sensor from the same visual angle but with a different focus are combined to obtain a more informative image. For example, a fused image with clearer canola seedpods can be produced by fusing many different images of a canola plant acquired by the same Pi camera at the same angle with many different focus lengths.
3. Results and Discussion
3.1. Multi-Focus Image Fusion
This section describes the comprehensive experiments conducted to evaluate and verify the performance of the proposed approach. The proposed algorithm was developed to fit many types of multi-focus images that are captured by any digital camera or Pi camera. The proposed method was also compared with five multi-focus image fusion techniques: the multi-scale weighted gradient based method (MWGF) [
26], the DCT based Laplacian pyramid fusion technique (DCTLP) [
27], the image fusion with guided filtering (GFF) [
28], the gradient domain-based fusion combined with a pixel-based fusion (GDPB) [
29], and the image matting (IM)-based fusion algorithm [
30]. The codes of these methods were downloaded and run on the same computer to compare to the proposed method.
The MWGF method is based on the image structure saliency and two scales to solve the fusion problems raised by anisotropic blur and miss-registration. The image structure saliency is used because it reflects the saliency of local edge and corner structures. The large-scale measure is used to reduce the impacts of anisotropic blur and miss-registration on the focused region detection, while the small-scale measure is used to determine the boundaries of the focused regions. The DCTLP presents an image fusion method using Discrete Cosine Transform based Laplacian pyramid in the frequency domain. The higher level of pyramidal decomposition, the better quality of the fused image. The GFF method is based on fusing two-scale layers by using a guided filter-based weighted average method. This method measures pixel saliency and spatial consistency at two scales to construct weight maps for the fusion process. The GDPB method fuses luminance and chrominance channels separately. The luminance channel is fused by using a wavelet-based gradient integration algorithm coupled with a Poisson Solver at each resolution to attenuate the artifacts. The chrominance channels are fused based on a weighted sum of the chrominance channels of the input images. The image mating fusion (IM) method is based on three steps: obtaining the focus information of each source image by morphological filtering, applying an image matting technique to achieve accurate focused regions of each source image, and combining these fused regions to construct the fused image.
All methods used the same input images as the ones applied in the proposed technique. Ten multi-focused image sequences were used in the experiments. Four of them were canola images captured by setting well-focused and manual changing focal length of the Pi camera; the others were selected from the general public datasets used for many image fusion techniques. These general datasets are available in Reference [
31,
32]. In the first four canola database sets, three of them were artificial multi-focus images obtained by using LunaPic tool [
33], one of them was a multi-focus image acquired directly from the Pi camera after cropping the region of interest as described in
Section 2.1.
The empirical parameters of the gradient domain fast guided filter and VS metrics were adjusted to obtain the best outputs. The parameters of the gradient domain fast guided filter (see Equation (22)) consisted of a window size filter (), a small positive constant (, subsampling of the fast-guided filter (s), and a dynamic range of input images (L). The parameters of VS maps (Equation (16)), including α, β, and γ, were used to control visual saliency, gradient similarity, and color distortion measures, respectively. These empirical parameters of the gradient domain fast guided filters were experimentally set as s = 4, L = 9, and two pairs of , and , for optimizing base and detail weight maps. Other empirical parameters of VS maps were set as α = 1, β = 0.89, and γ = 0.31.
Surprisingly, when changing these parameters of the VS maps, such as,
α = 0.31,
β = 1, and
γ = 0.31, the fused results had a similar quality to the first parameter settings. It can be thus concluded that to obtain focused regions, both visual saliency and gradient magnitude similarity can be used as the main saliencies. In addition, the chrominance colors (
M and
N) also contributed to the quality of the fused results. For example, when increasing the parameters of
M and
N, the blurred regions appeared in the fused results.
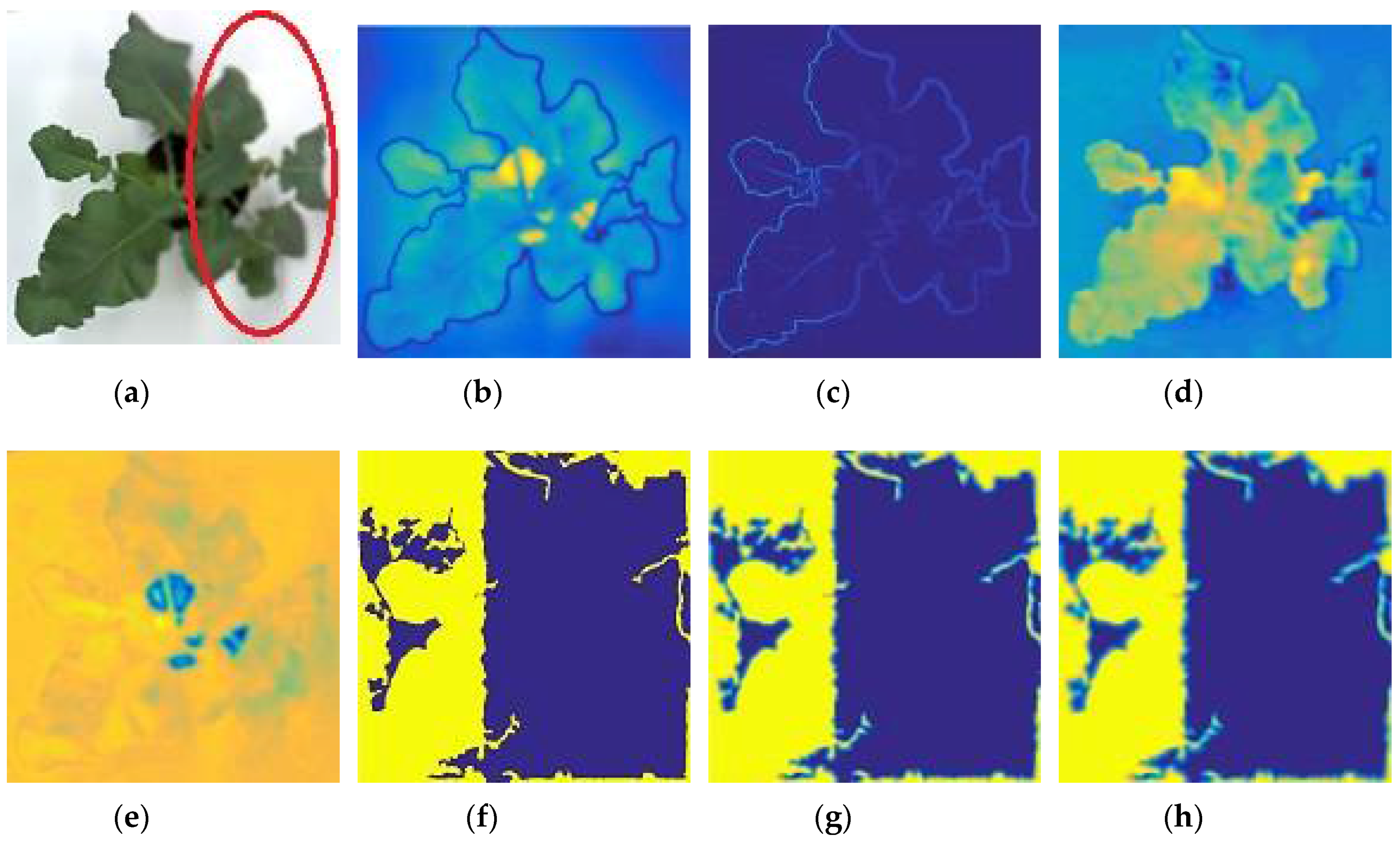
Figure 3 shows the outputs of the proposed algorithm, including visual saliency, gradient magnitude similarity, and chrominance colors. The red oval denotes the defocused region of the input image (
Figure 3a).
3.2. Comparison with Other Multi-Fusion Methods
In this section, a comprehensive assessment, including both subjective and objective assessment, is used to evaluate the quality of fused images obtained from the proposed and other methods. Subjective assessments are the methods used to evaluate the quality of an image through many factors, including viewing distance, display device, lighting condition, vision ability, etc. However, subjective assessments are expensive and time consuming. Therefore, objective assessments—mathematical models—are designed to predict the quality of an image accurately and automatically.
For subjective or perceptual assessment, the comparisons of these fused images are shown from
Figure 4,
Figure 5,
Figure 6 and
Figure 7. The figures show the fused results of the “Canola 1”, “Canola 2”, “Canola 4” and “Rose flower” image sets. In these examples, (a) and (b) are two source multi-focus images, and (c), (d), (e), (f), (g), and (h) are the fused images obtained with the MWGF, DCTLP, GFF, GDPB, IM, and the proposed methods, respectively. In almost all the cases, the MWGF method offers quite good fused images; however, sometimes it fails to deal with the focused regions. For example, the blurred regions remain in the fused image as marked by the red circle in
Figure 4c. The DCTLP method offers fused images as good as the MWGF but causes blurring of the fused images in all examples. The IM method also provides quite good results; however, ghost artifacts remain in the fused images, as shown in
Figure 4g,
Figure 6g, and
Figure 7g. Although the fused results of the GFF method reveal good visual effects at first glance, small blurred regions are still remained at the edge regions (the boundary between focused and defocused regions) of the fused results. This blurring of edge regions can be seen in the “Rose flower” fused images in
Figure 7e. The fused images of the GDPB method have unnatural colors and too much brightness. The fused results of the GDPB are also suffered from the ghost artifacts on the edge regions and on the boundary between the focused and defocused regions. It can be clearly seen that the proposed algorithm can obtain clearer fused images and better visual quality and contrast than other algorithms due to its combination of the gradient domain fast-guided filter and VS maps. The proposed algorithm offers fused images with fewer block artifacts and blurred edges.
In addition to subjective assessments, an objective assessment without the reference image was also conducted. Three objective metrics, including mutual information (MI) [
34], structural similarity (QY) [
35], and the edge information-based metric Q(AB/F) [
36] were used to evaluate the fusion performance of different multi-focus fusion methods.
The mutual information (MI) measures the amount of information transferred from both source images into the resulting fused image. It is calculated by
where
is the mutual information of the input image
X and fused image
F. is the mutual information of the input image
Y and fused image
F.
,
, and
denotes the entropies of the input image
X, Y, and used image
F, respectively.
The structural similarity (QY) measures the corresponding regions in the reference original image
x and the test image
y. It is defined as
where
is the local weight, and
and
are the variances of
and
, respectively.
The edge information-based metric
measures the amount of edge information that is transferred from input images to the fused image. For the fusion of source images A and B resulting in a fused image F, gradient strength
and orientation
are extracted at each pixel (
n,
m) from an input image, as given by
where
and
are the output of the horizontal and vertical Sobel templates centered on pixel
and convolved with the corresponding pixels of input image
A. The relative strength and orientation values of
and
of the input image
A with respect to the fused image
F are calculated by
From these values, the edge strength and orientation values are derived, as given by
and
model information loss between the input image
A and the fused image
F. The constants
,
,
and
,
determine the exact shape of the sigmoid functions used to form the edge strength and orientation preservation values (Equation 40 and Equation 41). Edge information preservation values are formed by
with
. The higher value of
, the less loss of information of the fused image.
The fusion performance
is evaluated as a sum of local information preservation estimates between each of the input images and fused image, it is defined as
where
and
are edge information preservation values, weighted by
and
, respectively.
Table 1 illustrates the quantitative assessment values of five different multi-focus fusion methods and the proposed method. The larger the value of these metrics, the better image quality is. The values shown in bold represent the highest performance. From
Table 1, it can be seen that the proposed method produces the highest quality scores for all three objectives metrics except for QY with “Canola 2” datasets and QAB/F with “Book” (extra images were also run to test the performance). These largest quality scores imply that the proposed method performed well, stably, and reliably. Overall, it can be concluded that the proposed method reveals the competitive performance when compared with previous multi-focus fusion methods both in visual perception and objective metrics.
Table 2 describes the ranking of the proposed method with others based on the quality of fused images. The performance (including quality of the images and the processing time) is scaled from 1 to 6. The results show the outperformance of the proposed technique with other techniques previously published.
4. Summary and Conclusions
To improve the description and quality images, especially images acquired from the digital camera or the Pi camera for canola phenotyping, an image fusion method is necessary. A new multi-focus image fusion method was proposed with the combination of the VS maps and gradient domain fast guided filters. In the proposed algorithm, the VS maps were first deployed to obtain visual saliency, gradient magnitude similarity saliency, and chrominance saliency (or color distortions), then the initial weight map was constructed with a mix of three metrics. Next, the final decision weight maps were obtained by optimizing the initial weight map with a gradient domain fast guided filter at two components. Finally, the fused results were retrieved by the combination of two-component weight maps and two-component source images that present large-scale and small-scale variations in intensity. The proposed method was compared with five proper representative fusion methods both in subjective and objective evaluations. Based on the experiment’s results, the proposed fusion method presents a competitive performance with or outperforms some state-of-the-art methods based on the VS maps measure and gradient domain fast guided filter. The proposed method can use digital images which are captured by either a high-end or low-end camera, especially the low-cost Pi camera. This fusion method can be used to improve the images for trait identification in phenotyping of canola or other species.
On the other hand, some limitations of the proposed multi-focus image fusion, such as small-blurred regions in the boundaries between the focused and defocused regions and computational cost, are worthwhile to investigate. Morphological techniques and optimizing the multi-focus fusion algorithm are also recommended for further study.
Furthermore, 3D modeling from enhancing depth images and image fusion techniques should be investigated. The proposed fusion technique can be implemented in the phenotyping system which has multiple sensors, such as thermal, LiDAR, or high-resolution sensors to acquire multi-dimensional images to improve the quality or resolution of the 2D and 3D images. The proposed system and fusion techniques can be applied in plant phenotyping, remote sensing, robotics, surveillance, and medical applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}