Biologically Inspired Hierarchical Contour Detection with Surround Modulation and Neural Connection

Abstract
:1. Introduction
2. Related Works
2.1. Contour Detection
2.2. Biologically-Inspired Methods
3. The BIHCD Model
3.1. Classical Receptive Field Models for Hierarchical Contour Detection
3.1.1. LGN
3.1.2. V1
3.1.3. V2
3.2. Surround Modulation Method of the NCRF
3.3. Multi-Scale Guided Contour Extraction
4. Experiments and Results
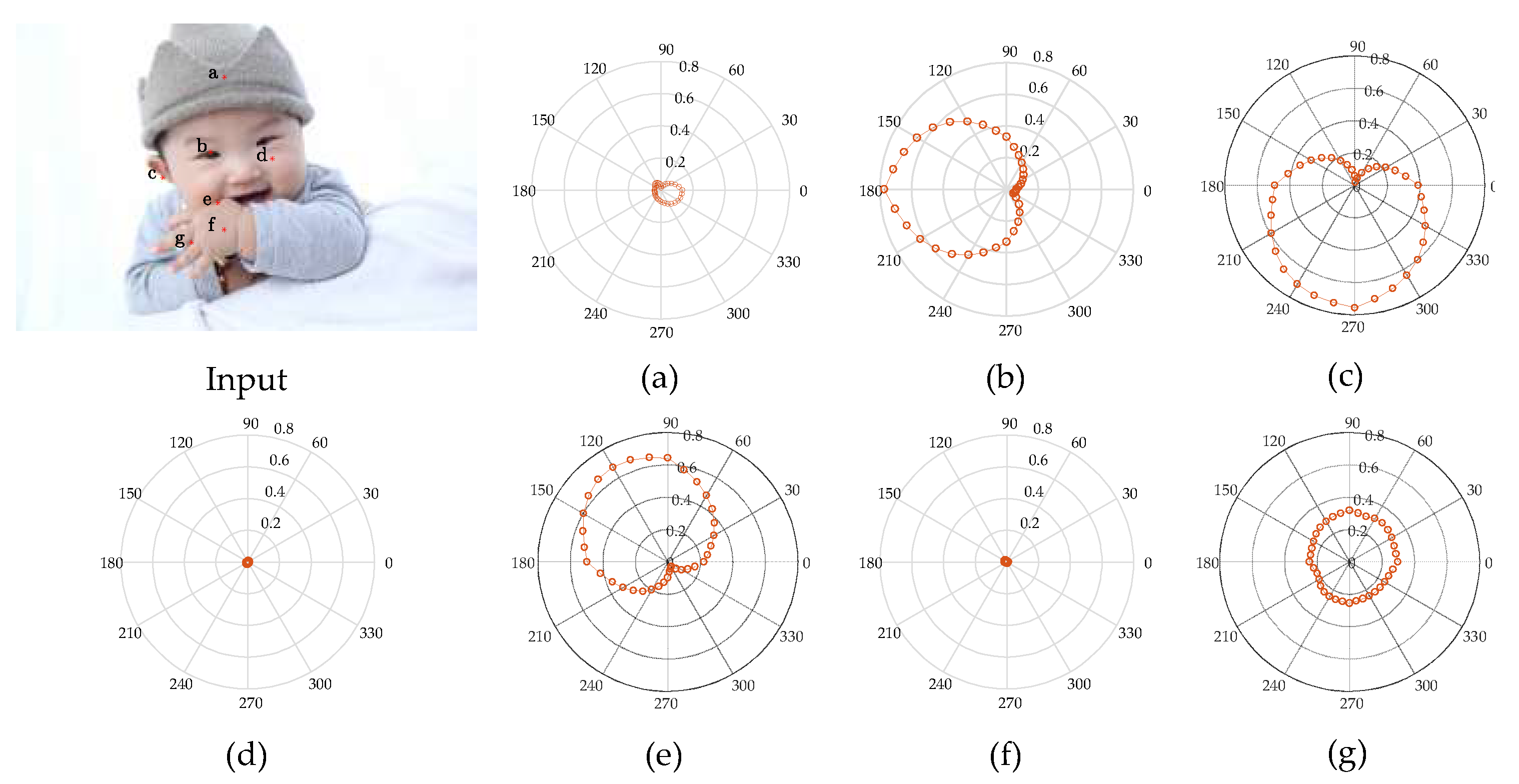
4.1. Analysis of V1 CRF Characteristics
4.2. Experiments on BSDS300/500 Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Arbelaez, P.; Maire, M.; Fowlkes, C.C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dicarlo, J.J.; Zoccolan, D.; Rust, N.C. How Does the Brain Solve Visual Object Recognition? Neuron 2012, 73, 415–434. [Google Scholar] [CrossRef] [PubMed]
- Wilder, J.; Feldman, J.; Singh, M. Contour complexity and contour detection. J. Vis. 2015, 15, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Canny, J.F. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Cour, T.; Florence, B.; Shi, J. Spectral segmentation with multiscale graph decomposition. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 1124–1131. [Google Scholar]
- Martin, D.R.; Fowlkes, C.C.; Malik, J. Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 530–549. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dollar, P.; Tu, Z.; Belongie, S.J. Supervised Learning of Edges and Object Boundaries. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 1964–1971. [Google Scholar]
- Bertasius, G.; Shi, J.; Torresani, L. DeepEdge: A multi-scale bifurcated deep network for top-down contour detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4380–4389. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Yang, K.; Li, C.; Li, Y. Multifeature-based surround inhibition improves contour detection in natural images. IEEE Trans. Image Process. 2014, 23, 5020–5032. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Shang, K.; Ming, D.; Tian, J.; Ma, J. A Biologically-Inspired Framework for Contour Detection Using Superpixel-Based Candidates and Hierarchical Visual Cues. Sensors 2015, 15, 26654–26674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.H.; Park, B.Y.; Akram, F.; Hong, B.W.; Choi, K.N. Multipass active contours for an adaptive contour map. Sensors 2013, 13, 3724–3738. [Google Scholar] [CrossRef] [PubMed]
- Maffei, L.; Fiorentini, A. The visual cortex as a spatial frequency analyser. Vis. Res. 1973, 13, 1255–1267. [Google Scholar] [CrossRef]
- Shapley, R.; Hawken, M.J. Color in the cortex—Single-and double-opponent cells. Vis. Res. 2011, 51, 701–717. [Google Scholar] [CrossRef] [PubMed]
- Johnson, E.N.; Hawken, M.J.; Shapley, R. The orientation selectivity of color-responsive neurons in macaque V1. J. Neurosci. 2008, 28, 8096–8106. [Google Scholar] [CrossRef] [PubMed]
- Loffler, G. Perception of contours and shapes: Low and intermediate stage mechanisms. Vis. Res. 2008, 48, 2106–2127. [Google Scholar] [CrossRef] [PubMed]
- Rodieck, R.W. Quantitative analysis of cat retinal ganglion cell response to visual stimuli. Vis. Res. 1965, 5, 583–601. [Google Scholar] [CrossRef]
- Daugman, J. Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters. J. Opt. Soc. Am. A 1985, 2, 1160–1169. [Google Scholar] [CrossRef] [PubMed]
- Jones, H.E.; Grieve, K.L.; Wang, W.; Sillito, A.M. Surround Suppression in Primate V1. J. Neurophysiol. 2001, 86, 2011–2028. [Google Scholar] [CrossRef] [PubMed]
- Grigorescu, C.; Petkov, N.; Westenberg, M.A. Contour detection based on nonclassical receptive field inhibition. IEEE Trans. Image Process. 2003, 12, 729–739. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papari, G.; Petkov, N. Review article: Edge and line oriented contour detection: State of the art. Image Vis. Comput. 2011, 29, 79–103. [Google Scholar] [CrossRef]
- Freeman, J.; Ziemba, C.M.; Heeger, D.J.; Simoncelli, E.P.; Movshon, J.A. A functional and perceptual signature of the second visual area in primates. Nat. Neurosci. 2013, 16, 974–981. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akbarinia, A.; Parraga, C.A. Biologically plausible boundary detection. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016; pp. 5.1–5.13. [Google Scholar]
- Hansen, T.; Neumann, H. A recurrent model of contour integration in primary visual cortex. J. Vis. 2008, 8, 8. [Google Scholar] [CrossRef] [PubMed]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- Prewitt, J.M. Object enhancement and extraction. Pict. Process. Psychopictorics 1970, 10, 15–19. [Google Scholar]
- Isola, P.; Zoran, D.; Krishnan, D.; Adelson, E.H. Crisp Boundary Detection Using Pointwise Mutual Information. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 799–814. [Google Scholar]
- Zeng, C.; Li, Y.J.; Yang, K.F.; Li, C. Contour detection based on a non-classical receptive field model with butterfly-shaped inhibition subregions. Neurocomputing 2011, 74, 1527–1534. [Google Scholar] [CrossRef]
- Zeng, C.; Li, Y.J.; Li, C.Y. Center-surround interaction with adaptive inhibition: A computational model for contour detection. Neuro Image 2011, 55, 49–66. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Gao, S.; Li, C.; Li, Y. Efficient Color Boundary Detection with Color-Opponent Mechanisms. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2013; pp. 2810–2817. [Google Scholar]
- Yang, K.; Gao, S.; Guo, C.; Li, C.; Li, Y. Boundary detection using double-opponency and spatial sparseness constraint. IEEE Trans. Image Process. 2015, 24, 2565–2578. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Li, C.; Li, Y. Potential roles of the interaction between model V1 neurons with orientation-selective and non-selective surround inhibition in contour detection. Front. Neural Circuits 2015, 9, 30. [Google Scholar] [CrossRef] [PubMed]
- Spratling, M.W. Image Segmentation Using a Sparse Coding Model of Cortical Area V1. IEEE Trans. Image Process. 2013, 22, 1631–1643. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, H.; Lang, B.; Zuo, Q. Contour detection model with multi-scale integration based on non-classical receptive field. Neurocomputing 2013, 103, 247–262. [Google Scholar] [CrossRef]
- Diazpernas, F.J.; Martinezzarzuela, M.; Antonrodriguez, M.; Gonzalezortega, D. Double recurrent interaction v1-v2-v4 based neural architecture for color natural scene boundary detection and surface perception. Appl. Soft Comput. 2014, 21, 250–264. [Google Scholar] [CrossRef]
- Neumann, H.; Sepp, W. Recurrent V1–V2 interaction in early visual boundary processing. Biol. Cybern. 1999, 91, 425–444. [Google Scholar] [CrossRef] [PubMed]
- Raudies, F.; Mingolla, E.; Neumann, H. A model of motion transparency processing with local center-surround interactions and feedback. Neural Comput. 2011, 23, 2868–2914. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.-L.; Lv, C.; Ma, S.; Li, S. Motion feature extraction of Random-dot video sequences with the visual cortex mechanism. J. Univ. Electron. Sci. Technol. China 2017, 46, 630–635. [Google Scholar]
- Li, S.; Xu, Y.; Ma, S.; Ni, J.; Shi, H. New method for SAR occluded targets recognition using DNN. J. Xidian Univ. (Natl. Sci.) 2015, 3, 154–160. [Google Scholar]
- Simoncelli, E.P.; Heeger, D.J. A model of neuronal responses in visual area MT. Vis. Res. 1998, 38, 743–761. [Google Scholar] [CrossRef]
- Rust, N.C.; Mante, V.; Simoncelli, E.P.; Movshon, J.A. How MT cells analyze the motion of visual patterns. Nat. Neurosci. 2006, 9, 1421–1431. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; She, L.; Chen, M.; Liu, T.; Lu, H.D.; Dan, Y.; Poo, M. Spatial structure of neuronal receptive field in awake monkey secondary visual cortex (V2). Proc. Natl. Acad. Sci. USA 2016, 113, 1913–1918. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akbarinia, A.; Parraga, C.A. Feedback and Surround Modulated Boundary Detection. Int. J. Comput. Vis. 2017, 1–14. [Google Scholar] [CrossRef]
- Chaoyi, L.; Wu, L. Extensive integration field beyond the classical receptive field of cat’s striate cortical neurons-Classification and tuning properties. Vis. Res. 1994, 34, 2337–2355. [Google Scholar] [CrossRef]
- Martin, D.R.; Fowlkes, C.C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | F(BSDS300) | AP(BSDS300) | F(BSDS500) | AP(BSDS300) | ||
|---|---|---|---|---|---|---|
| Human | 0.79 | - | 0.80 | - | ||
| Machine learning | Shallow | Pb | 0.63 | - | 0.67 | - |
| BEL | 0.65 | - | 0.61 | - | ||
| Deep | gPb | 0.70 | 0.66 | 0.71 | 0.65 | |
| Deep Edge | - | - | 0.75 | 0.80 | ||
| HED | - | - | 0.78 | 0.83 | ||
| Low-level features | Classical edge detection | Canny | 0.58 | 0.58 | 0.61 | 0.58 |
| Normalised Cuts | 0.62 | 0.42 | 0.63 | 0.45 | ||
| Biological | SCO | 0.66 | 0.70 | 0.67 | 0.71 | |
| MCI | 0.62 | - | 0.64 | - | ||
| Ours | 0.68 | 0.70 | 0.70 | 0.74 | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Xu, Y.; Cong, W.; Ma, S.; Zhu, M.; Qi, M. Biologically Inspired Hierarchical Contour Detection with Surround Modulation and Neural Connection. Sensors 2018, 18, 2559. https://doi.org/10.3390/s18082559
Li S, Xu Y, Cong W, Ma S, Zhu M, Qi M. Biologically Inspired Hierarchical Contour Detection with Surround Modulation and Neural Connection. Sensors. 2018; 18(8):2559. https://doi.org/10.3390/s18082559
Chicago/Turabian StyleLi, Shuai, Yuelei Xu, Wei Cong, Shiping Ma, Mingming Zhu, and Min Qi. 2018. "Biologically Inspired Hierarchical Contour Detection with Surround Modulation and Neural Connection" Sensors 18, no. 8: 2559. https://doi.org/10.3390/s18082559
APA StyleLi, S., Xu, Y., Cong, W., Ma, S., Zhu, M., & Qi, M. (2018). Biologically Inspired Hierarchical Contour Detection with Surround Modulation and Neural Connection. Sensors, 18(8), 2559. https://doi.org/10.3390/s18082559