1. Introduction
Aircraft safety requires highly reliable navigation information. Traditionally, the inertial navigation system and global positioning system (INS/GPS) integrated navigation algorithm has been widely used [
1]. However, GPS cannot operate independently and is also vulnerable to jamming. To overcome such weakness, the terrain-aided navigation (TAN) techniques can be used. TAN is a navigation technology that estimates the aircraft’s precise position by comparing the altitude measured by an altimeter with the uploaded digital elevation data (DEM). To acquire precise position information using TAN, nonlinear estimation problems must be solved in real-time. The extended Kalman filter (EKF)-based TAN algorithms have solved these problems through regional linearization [
2]. However, because of the highly nonlinear characteristics of the terrain, the EKF-based TAN algorithm can diverge due to linearization. Recent studies have suggested that the TAN techniques that use the Bayesian estimate method, such as particle filter (PF) and point mass filter (PMF), can prevent the problem [
3,
4,
5,
6,
7]. The techniques can be directly applied to nonlinear problems without having to perform linearization, like EKF. When using the Bayesian approach, integration terms are included when the measurements are updated. It’s difficult to calculate the integration terms in real time. PF uses the Monte-Carlo sampling method instead of the integration terms required to normalize the posterior pdf via Bayes’ rule [
8]. Increasing the precision of PF requires many particles, and the computation load rapidly increases if the dimension of the state variables increases. As a means for more efficient calculations, there have been studies that applied the Rao-Blackwellization technique where state variables are divided into linear and nonlinear parts [
9,
10,
11]. In this study, the two-dimensional PF was composed of latitude and longitude errors. The altitude bias generates errors in the likelihood calculations of the PF. To compensate for this, a one-dimensional Kalman filter was added. If the three-dimensional PF was composed of latitude, longitude, and altitude errors, more particles are needed to ensure accuracy. This causes the computational complexity. To alleviate this problem, we used the Rao-Blackwellization technique that marginalize the states that vary close to linearly in the dynamics. One Kalman filter was assigned to each particle by marginalization.
TAN for aircraft, UAVs, and missiles is a well-established technique that has been studied for several decades. Recently, there have been active studies in the field of the autonomous underwater vehicles (AUVs) [
10,
12]. The main differences between TAN for AUVs and aerial vehicle systems are the vehicle dynamics and sensors used to measure the relative position from the vehicle to the terrain [
12]. In particular, the AUVs and UAVs systems require high reliability and have to guarantee a stable navigation performance in the GPS-less environment, but most studies about the TAN technique for AUVs and UAVs have focused on rough and unique terrains. Otherwise, there have been studies that represented the stable TAN performance to make a detour around the flat and repetitive terrains through path planning or simultaneous localization and mapping (SLAM) techniques [
12,
13], but as vehicles have been recently required to perform various missions, even in GPS-less environments, the path planning or SLAM techniques are limited in terms of survivability and reliability. Therefore, in this study, we suggest the robust TAN technique for reliable navigation performance, even in flat or repetitive terrains. In other words, we designed a TAN technique that can perform in flat or repetitive terrain, instead of avoiding these terrains and moving into rough or unique terrains by using the path planning and SLAM techniques.
For the robust TAN, the validity check technique of measurements by terrain roughness and uniqueness is an important technique that determines the navigation performance. The mean squared difference (MSD) and mean absolute difference (MAD) of the height deviation have been widely used for contour matching based TAN [
14,
15]. As for the bank of Kalman filter (BKF)-based TAN, the validity check technique that uses smoothed weighted residual squared (SWRS) is standard [
16]. However, for the TAN that uses Bayesian filters, like PF and PMF, there is no commonly used validity check technique. Therefore, at first, we considered the validity check technique by using mutual information (MI) and residual check logic, which can be applied to PF. In [
17], the validity check technique that uses MI was introduced. The MI about the joint probability function of the likelihood and prior probability distribution measures how much the likelihood reduces uncertainty about the prior distribution. Therefore, if the value of MI is positive, the likelihood from generating the measurement can be useful [
17]. However, although the measurement error is instantaneously large, using the measurement can be helpful to the PF in some cases. In other words, the current value of MI is not enough to provide robust solutions on certain flight trajectories. Also, the incorrect estimates of PF can cause the validity check logic by using residuals between the measurements and the estimates to malfunction. The validity check technique cannot thoroughly guarantee the reliability and robustness of the TAN.
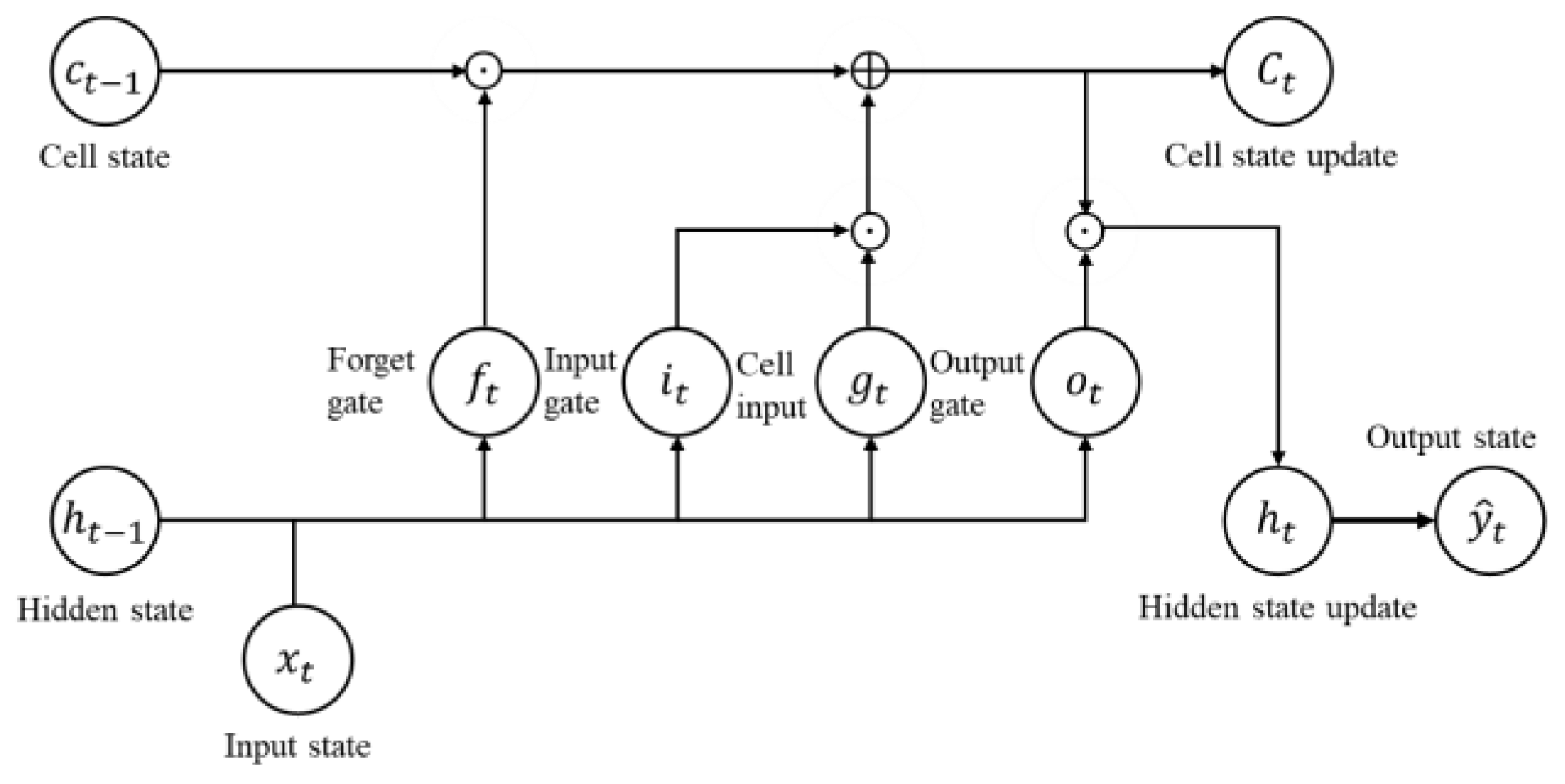
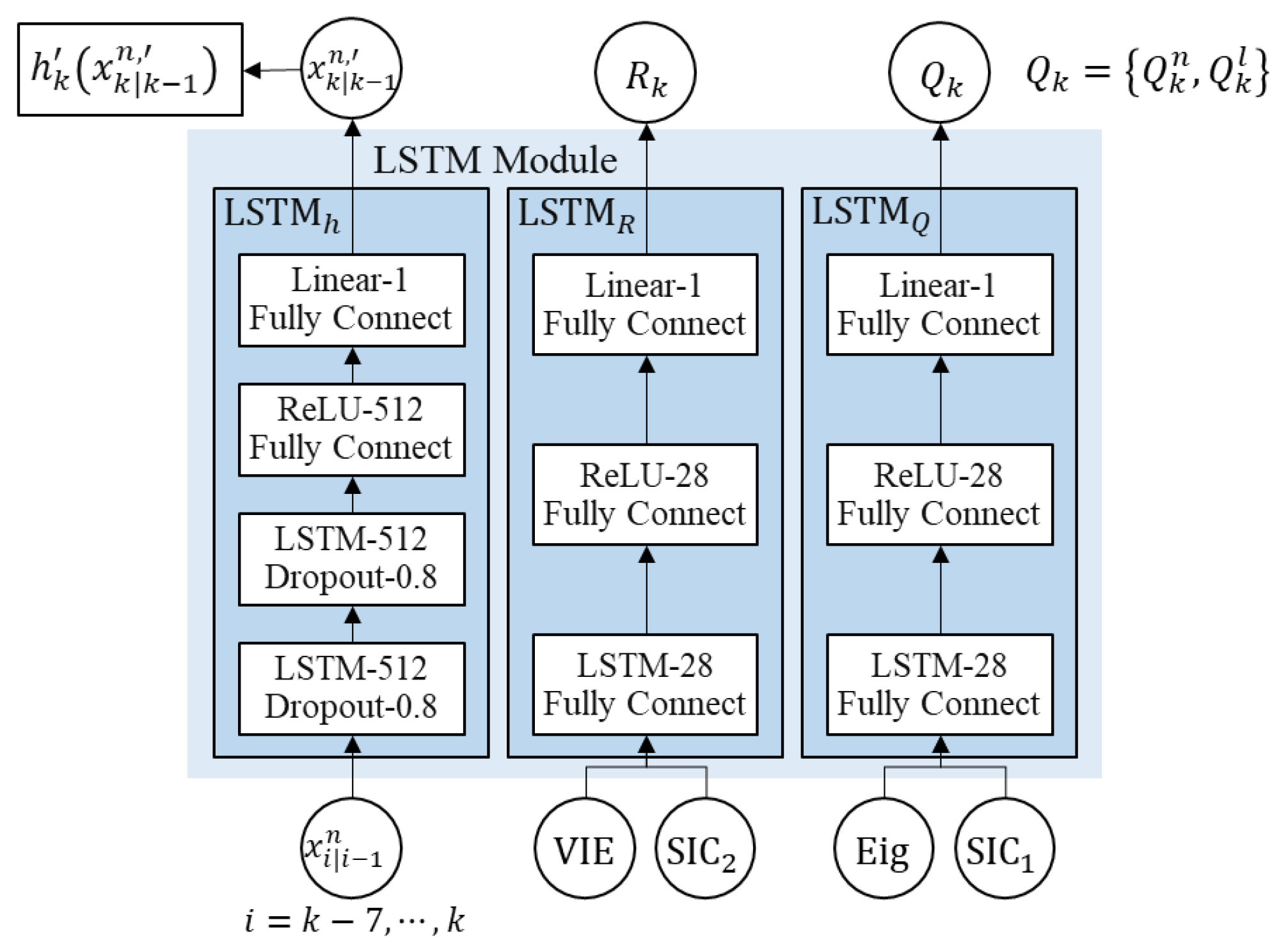
Next, we considered the method that can control the noise covariance and measurement model to reduce the navigation error. There have been studies that estimated the process noise by modelling the magnitude of the maximum uncertainties or the sufficient statistics of the process and measurement noise parameters [
18,
19]. However, this method models the magnitude of noise at the moment accurately instead of determining the optimal process and measurement noise for generating stable particles in flat and repetitive terrains. In other words, modeling close to the true magnitude of noise may, at times, degrade the filter performance in flat and repetitive terrains. To solve this problem, this study adopted an improved recurrent neural networks (RNN) method called long short-term memory (LSTM). RNN is an artificial neural network that recognizes patterns from the time series data, which is one of the deep learning techniques that considers current and past input data via inner memory [
20]. However, as for the RNN, its error gradient decreases along with back propagation when going back in time, so it is inappropriate to analyzing long time series data patterns. LSTM networks update intermediate memory cells with the sum of values that pass through the input and output gates, so they can deal with longer sequences than RNN, which is composed of only multiplication. Recently, there have been active studies that use the expectation-maximization (EM) algorithm or Bayes rules to efficiently conduct RNN or LSTM training or studies that use LSTM to improve the performance of KF or PF [
21,
22,
23,
24,
25,
26]. These studies are not suitable for providing real-time solutions or they are mostly limited to image recognition. This paper used LSTM networks to train noise covariances and measurement model of RBPF based TAN for improving the navigation performance in flat and repetitive terrains.
Section 2 summarizes the design of the conventional RBPF based TAN.
Section 3 introduces the terrain and measurement validity check logic and its application to the designed RBPF-based TAN. Next, the LSTM modules are designed, and an LSTM-RBPF-based TAN is proposed, of which the noise covariances and measurement model are trained by the LSTM modules. Finally, this study determines the model parameters for the proposed LSTM modules using training data and performs Monte Carlo simulations that use evaluation data to verify the proposed design.
2. Conventional RBPF Based TAN
As for the EKF-based TAN, there is a high probability of divergence if the nonlinearity of the system or measurement model is too great. Therefore, this study considered PF-based TAN. PF is one of the general Bayesian filters that use global approximation instead of regional linearization [
3,
8,
27]. In this study, the two-dimension PF was composed of latitude and longitude errors. The Bayesian filter was applied to the following TAN system and measurement model:
is a two-dimensional state vector composed of latitude and longitude errors at the
-th time.
and
denote the velocity vector composed of velocities in a northward and eastward direction and terrain elevation from the DEM evaluated at the position,
.
is the terrain height calculated by the measurements of the IRA and barometer. In the system above,
is the system white noise that meets
and
. Here,
is the system process noise covariance, and
is the sampling time. In the measurement above,
is the white measurement noise that meets
and
. Here,
is the measurement noise covariance. The prior pdf is as follows. The prediction step uses the TAN system model (1) to obtain the prior pdf of the state at time step
via the Chapman-Kolmogorov Equation (6):
By using the same process above from Equation (2), the likelihood is as follows:
At time step
, measurement
becomes available, and this may be used to update the prior pdf via Bayes’ rule [
28]. The posterior pdf that uses this is as follows:
Here,
and
.
is the parameter that normalizes the posterior pdf. The state variable estimate and covariance that minimize the mean square error are as follows:
The computational load due to the integral calculation included in the above conditional pdf is large. To alleviate the computational load, the sequential importance sampling-PF (SIS-PF) is generally used. SIS-PF is a technique that implements a sequential Bayesian filter using Monte Carlo sampling. If
is the
-th weighted particle with the
-th weight,
, the time propagation equation of the PF is as follows:
is the number of the sampled particles and . If , is a sample generated from the target probability density, , the above weight is as follows by the importance sampling principle:
The process of PF can be expressed as follows by separating the time propagation equation and the measurement update equation:
In this study, the current value of the state vector is determined by the one previous value that uses a Markov process, and the Gaussian distribution is used as the target distribution,
. By using the Dirac delta function, the posterior pdf,
at the
step can be approximated as (12):
Here,
denotes the Dirac delta function. The state variable estimate and covariance that minimize the mean square error are as follows [
8]:
The SIS-PF updates the weights and particles when the measurements are put sequentially. When the method runs several steps, a degeneracy problem occurs in which the weights of all particles are too small, except for a few particles. To solve this problem, the number of valid samples,
, should be maintained [
28].
is determined by the user and is set to
in this study:
Here,
. It is hard to calculate the target weight,
, as the target distribution is unknown exactly. So, the estimate is used as shown in the above equation. That is, to maximize
, important sampling is performed so that
becomes the minimum. The simplest way to implement this is to perform resampling, and this PF is called sequential importance resampling-PF (SIR-PF). Among various resampling methods, this study employed the stratified sampling method with simulation. This method is as follows [
28]:
When the number of particles after resampling is
, the weights are recalculated as follows:
Resampling can resolve the degeneracy problem, but since the particles with large weights are replicated when the filter is updated, a sampling impoverishment problem occurs where the diversity disappears over time. To alleviate this problem, the Markov Chain Monte Carlo (MCMC)-step was added to PF by replacing only particles that satisfy the diversity judgement condition through Metropolis-Hasting sampling [
27]:
Here,
and
are determined by considering the move step size to a new set of particles that use the following random walk model where it was set to
and
, respectively, in this study. This MCMC-step is performed after the resampling step. The corresponding acceptance probability is expressed as:
To increase the accuracy of the posterior pdf estimate, the number of particles must increase. As the dimension of the state variable increases, the amount of computation increases rapidly [
28]. To solve this problem, there have been studies that used the marginalization method for efficient computation in the positioning, navigation, and tracking problems [
10,
11,
29]. This is a method that separates the state variables into linear and nonlinear parts. It also applies nonlinear parts to PF and linear parts to construct one KF for each particle. The most general model about RBPF is as follows [
9]:
Here,
,
and
. The following includes a general formula that consists of the linear state variables of RBPF,
and nonlinear state variables,
[
9,
10].
is the dynamic function of the nonlinear state variables and is equal to
in Equation (1).
is the dynamic function of the nonlinear state variables and determined by the linear state variable in one previous time. It was set to zero matrix in this study. This means that the prediction of the nonlinear state variables is not affected by the linear state variable [
9].
is the dynamic model of the linear state variable determined by the nonlinear state variables.
is the dynamic function of the nonlinear state variable by the linear state variables in one previous time.
is the measurement model determined by the linear state variable. Assume that
follows the normal distribution in the condition given
in the above model, the model can be expressed as:
That is, (24) and (26) are the measurement models and (25) is the system model from the viewpoint of
. In Equation (24),
is equal to
in Equation (1). Therefore, it is possible to interpret
as a measurement and
as the corresponding measurement noise from the viewpoint of
. From the viewpoint of
,
of (25) and
of (26) are regarded as additional process and measurement noise, respectively. First,
is calculated through (9) and (10) for
. By Bayes’ rule, the joint pdf
and
in the condition of given
is as follows [
9]:
Here,
is analytically tractable and given by the optimal KF.
can be estimated by PF.
is calculated by the time propagation of
. Then the conditional pdf for
is given by applying two-step measurement updates using
, where
is the value in the time propagation step of PF in the condition of given
and
, where
is the value in the measurement update step of PF in the condition of given
:
is calculated by performing a measurement update through (12) for
. When
is smaller than the threshold value, resampling is performed. Afterwards, Equation (28) is calculated by the measurement update for
. Finally, the posterior pdf is obtained as follows:
is a one-dimensional state vector that is given in terms of altitude error. The time propagation of the linear component of the states and covariance is as follows:
The likelihood of the nonlinear part of RBPF is compensated by this estimated altitude error state and covariance:
Kalman gain is updated as follows:
If the measurement is available, the update state and covariance are performed as follows:
3. Validity Check Logic of Terrain for RBPF Based TAN
In TAN, the validity check technique of measurements by terrain roughness and uniqueness is an important technique that determines the navigation performance. In this study, the interferometric radar altimeter (IRA) is used to measure the angle of the direction of flight, the angle perpendicular to the direction of flight, and the range from the aircraft to the nearest terrain point. It then converts these measurements to a three-dimensional position information on an earth-centered earth-fixed (ECEF) coordinate system [
30,
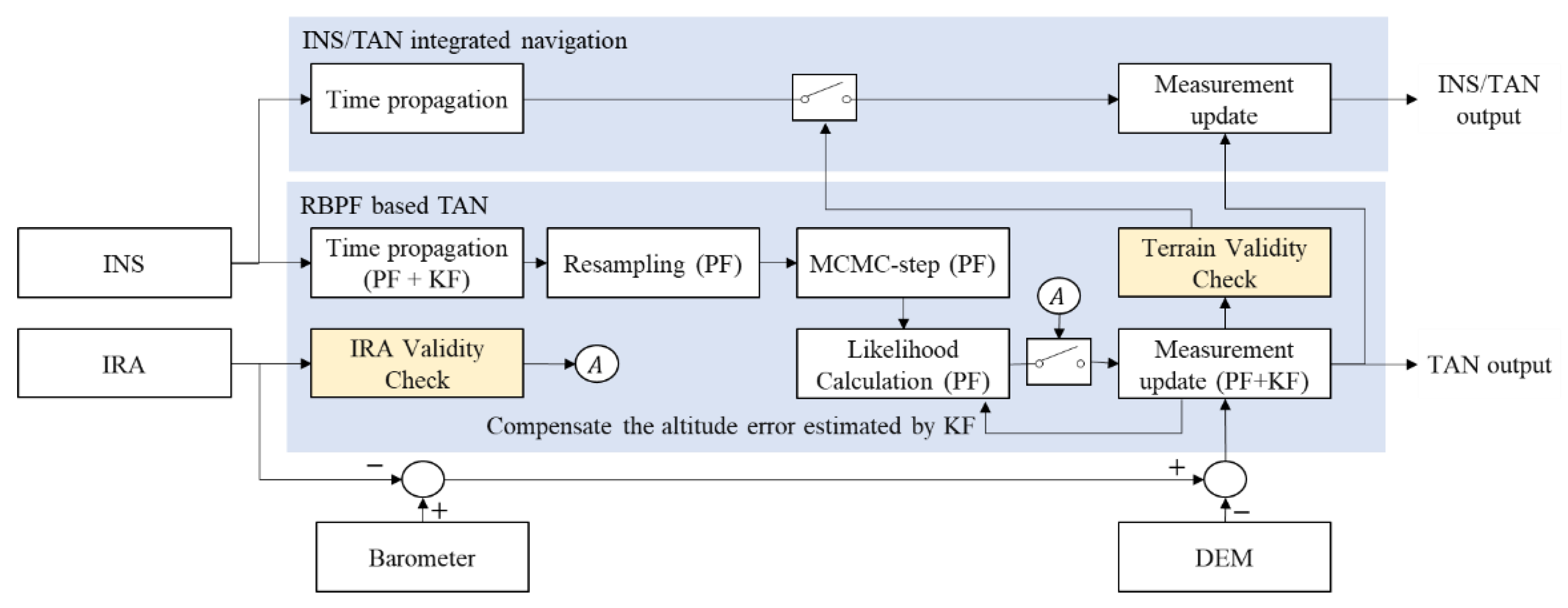
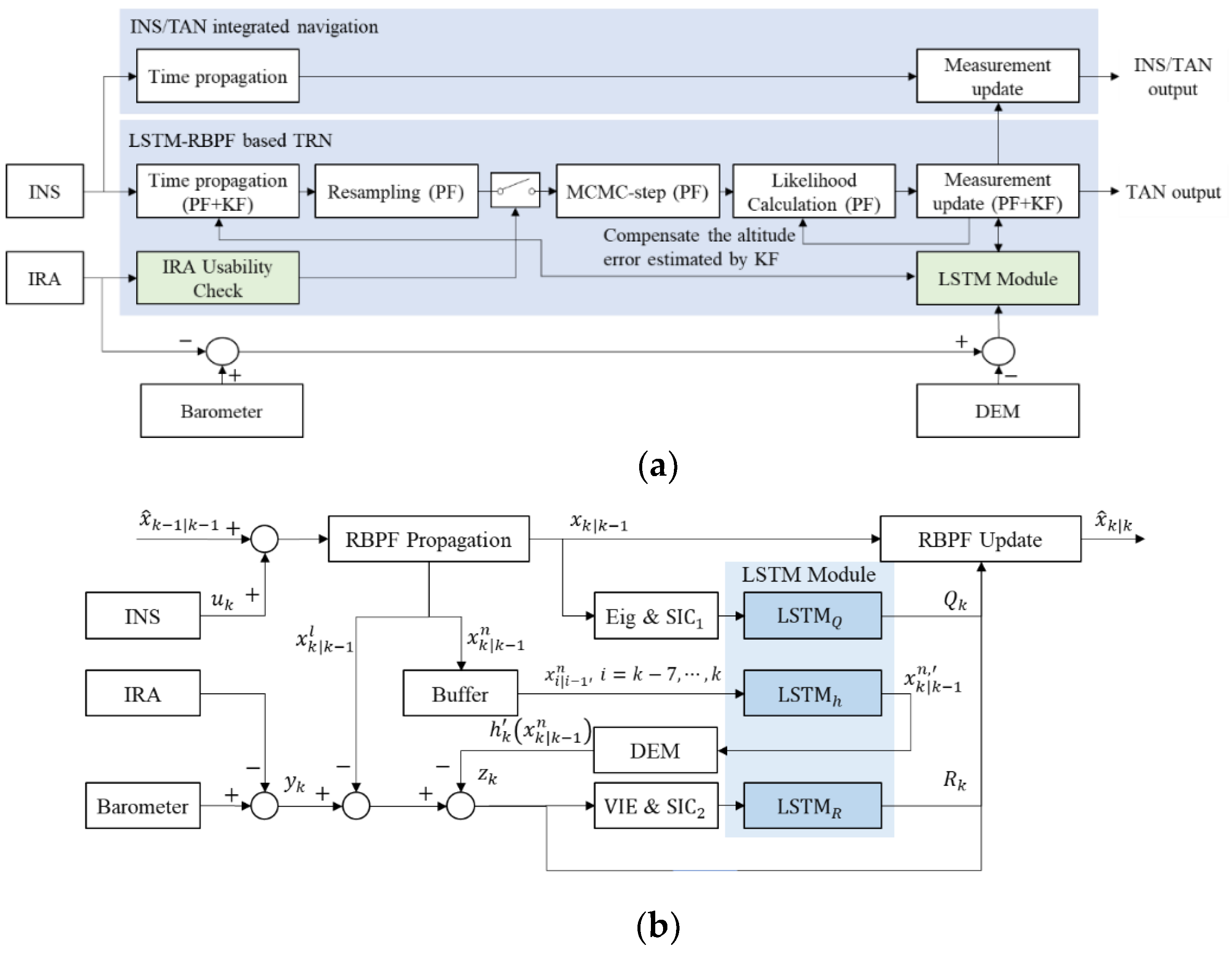
31]. Moreover, it can acquire precise position estimates and maintains a very small margin of error, even at high altitudes. Despite these advantages, IRA has many uncertainties, including environmental factors and IRA inherent measurement errors. Generally, the uncertainties are large in flat and repetitive terrains. In particular, it is difficult to estimate the ambiguity errors generated through the signal processing and the glint errors caused by the target fluctuation or clutter, making it challenging to find appropriate compensation techniques. Accordingly, as the TAN that uses the raw data of IRA is likely to be diverted due to uncertain measurements, only the measurements that are useful for TAN should be used selectively. This study describes the RBPF-based TAN, including the validity check logic of the terrain and IRA measurements, as shown in
Figure 1. The difference between altitude from the aircraft to the mean sea level (MSL) measured by the barometer and distance from the aircraft to the nearest terrain point measured by IRA was matched with the terrain height on DEM. If the IRA measurement errors are large, PF may not converge. Therefore, this study designed a system that only updates RBPF when it decides the measurement is valid, and if not, the system only conducts time propagation. The INS/TAN integrated navigation uses the estimated position by RBPF-based TAN as measurement and only updates in terrains that seem to be rough and unique through a terrain validity check, as in
Figure 1. In this study, we designed an RBPF composed of two-dimensional PF and one-dimensional KF. Two-dimensional PF estimates the latitude and longitude errors. One-dimensional KF estimates the altitude error and compensates the errors in the likelihood step, as shown in
Figure 1. If the posterior pdf of the RBPF satisfies the IRA validity check conditions, the IRA measurements are updated. Also, if the posterior pdf is more informative than the prior pdf, the TAN output is judged as satisfying the TAN validity check condition and can be used as the measurements of the INS/TAN integrated navigation.
We need navigation information, including the position, velocity, and attitude. To acquire all the information, increasing the dimensions of RBPF causes computation complexity. There have been studies about the INS/TAN integrated navigation algorithms [
32]. In this study, the loosely-coupled INS/TAN integrated navigation was designed to reduce the computing load. The INS/TAN integrated navigation is designed with the EKF and uses the 13th state variables composed with the error of latitude,
, longitude,
, velocity,
, attitude,
, accelerometer bias,
, and gyro bias,
. Since the TAN filter can be unstable in flat and repetitive terrains, in this study, a feedforward structure was designed to prevent this problem. The state variables can be expressed as:
The system and measurement matrix of the discretized state equation are as follows. The system matrix is derived as an error model of INS, and the measurements are acquired from the estimates of the latitude and longitude of the RBPF-based TAN:
Here, , , and .
3.1. Measurement Validity Check Logic
As previously stated, the IRA measurements can be converted into three-dimensional position information. As shown in
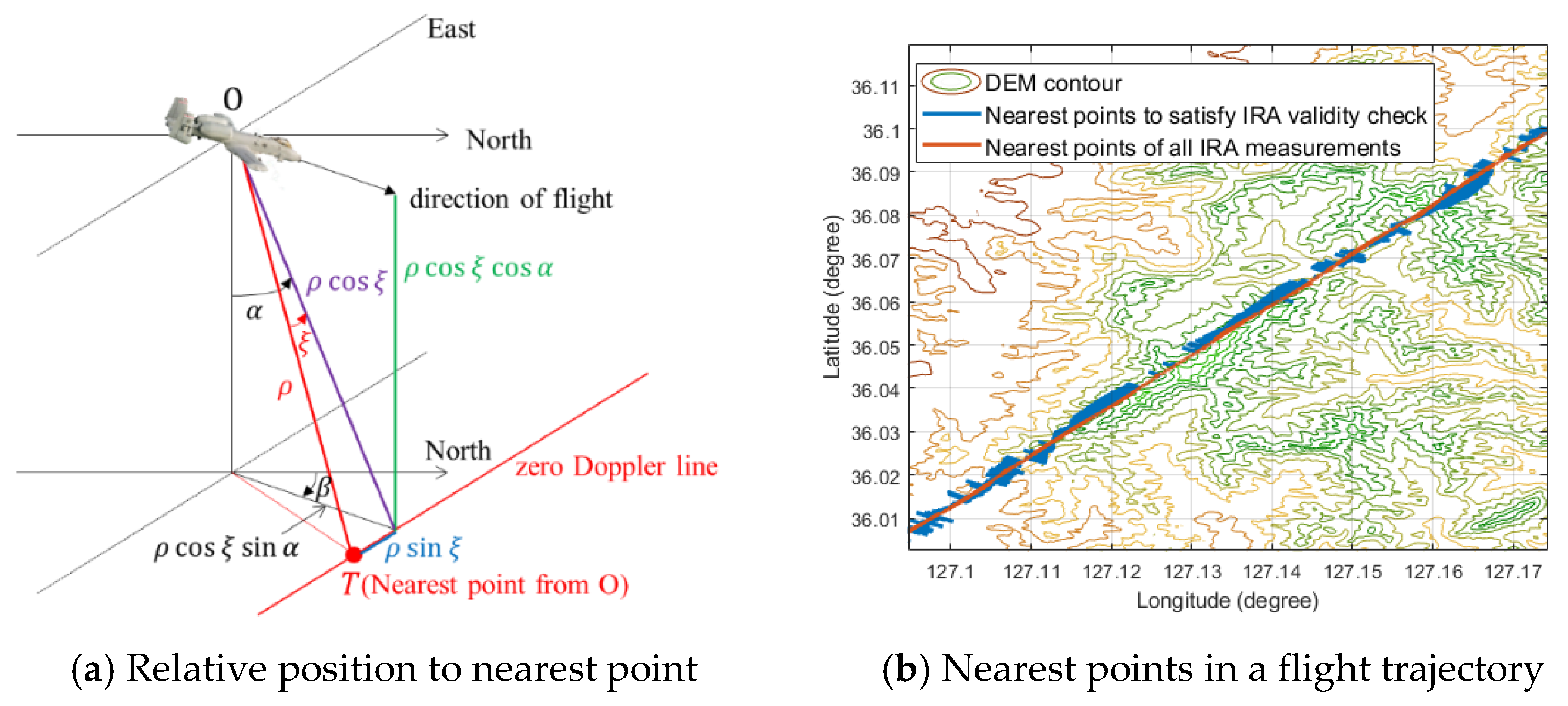
Figure 2., the relative position vector,
, of the nearest point from the aircraft is given in Equation (42):
Here,
and
are the range and look angle output of IRA, respectively. The virtual pitch angle,
, and azimuth angle,
, of the zero Doppler line are determined by the velocity of the aircraft as follows [
30]:
Here,
is the velocity of the aircraft in the navigation frame. So, the nearest point,
, is determined by the summation of the estimated aircraft position calculated by Equation (13) and the relative position,
. As shown in
Figure 2b, the nearest points acquired by the raw data of IRA measurements without an IRA validity check is very unstable. Therefore, to implement the robust TAN, we must use the beneficial measurements selectively. We could not find the references about the IRA validity check logic for the Bayesian filters. So, we developed a validity check logic through the simulations and captive flight tests.
In this study, the IRA validity check technology was applied using residual check logic in the following equations:
Here, is the MSL altitude measured by the barometer. is the relative height calculated by the IRA. is the height error estimated by the KF part of RBPF and is equal to the calculated in Equation (37). is equal to in Equation (37) and means the estimate of the height error state assigned to the -th particle. is the estimate of the latitude and longitude of the -th particle. is the mean of the terrain DEM data of the particles and is the mean of the terrain DEM data squares of the particles. is the variance of the measurement noise, and is the covariance of the height error state estimated by the KF. means the terrain height by the measurements, and means the estimate of the terrain height by RBPF. So, the difference between both terms is the residual. is the acceptable range of the height error square that considers the measurement noise and height error state covariance. is the additional range of the height error square that considers the terrain roughness and uniqueness in the distributed area of particles, so the IRA measurements are valid, but only if the residual is more than one sigma of the acceptable error range, and the minimum residual among the residuals of all the particles is more than 0.1 sigma of the estimated error range by RBPF. These logics were designed through simulations and verified by the captive flight tests.
3.2. Terrain Validity Check
As mentioned above, unlike contour matching or BKF based TAN, we could not find a well-established terrain validity check logic in PF based TAN. In this study, a technique was performed that uses mutual information, which is a measure of the mutual dependence between the entropy of a prior distribution and a posterior distribution [
33]. Entropy is an index that displays the uncertainties of random variables. If the random variables are in a uniform distribution, the value of entropy is at its maximum. The entropy of the prior pdf,
is expressed in terms of the probability
in Equation (8) so that:
The entropy of the posterior pdf,
, is defined as follows [
33]:
Mutual information indicates the amount of entropy of
reduced by measuring
. The validity check index,
, which uses the mutual information of the estimate, can be determined using Equations (8) and (12):
is the amount of reduced uncertainty after the measurement update. In other words, if
is positive, the position information estimated by TAN is valid and used as the measurement of the INS/TAN integrated navigation. To verify the method, this study conducted Monte Carlo simulation 100 times based on the simulation condition and RBPF design parameter indicated in
Table 1 and
Figure 3, respectively.
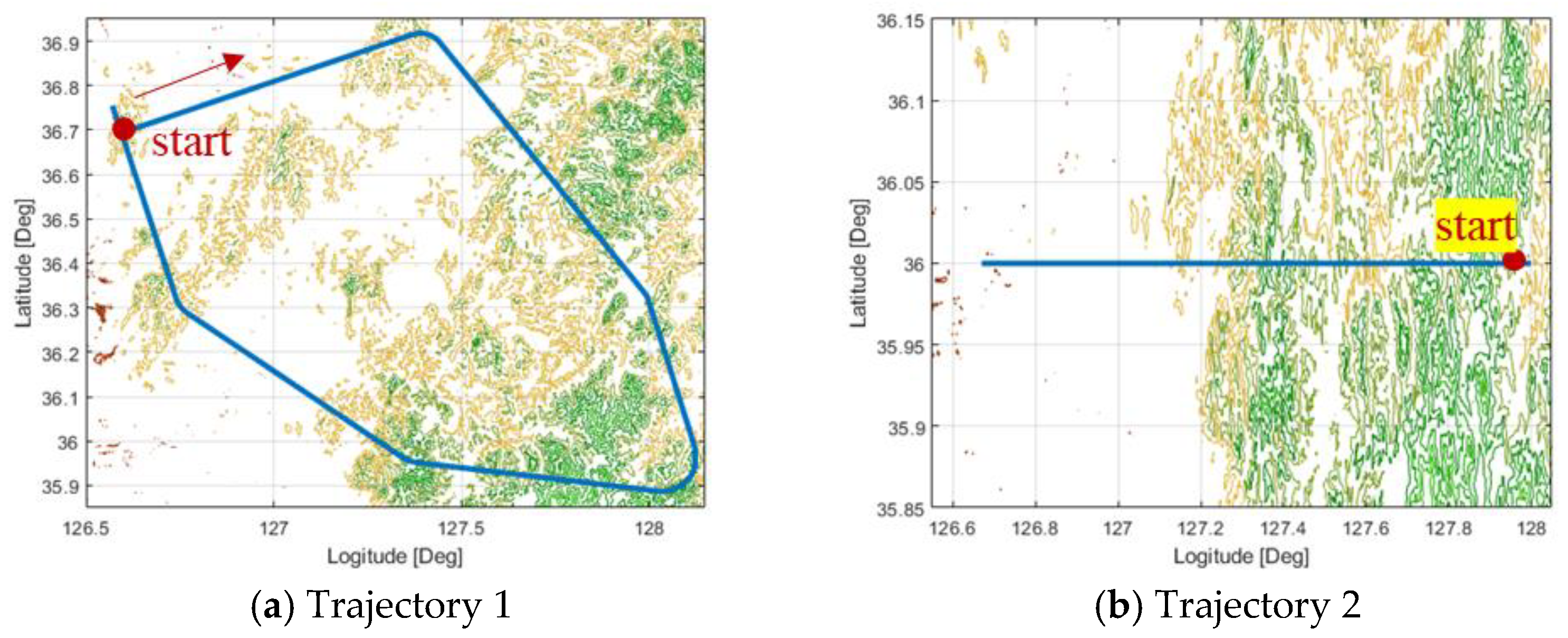
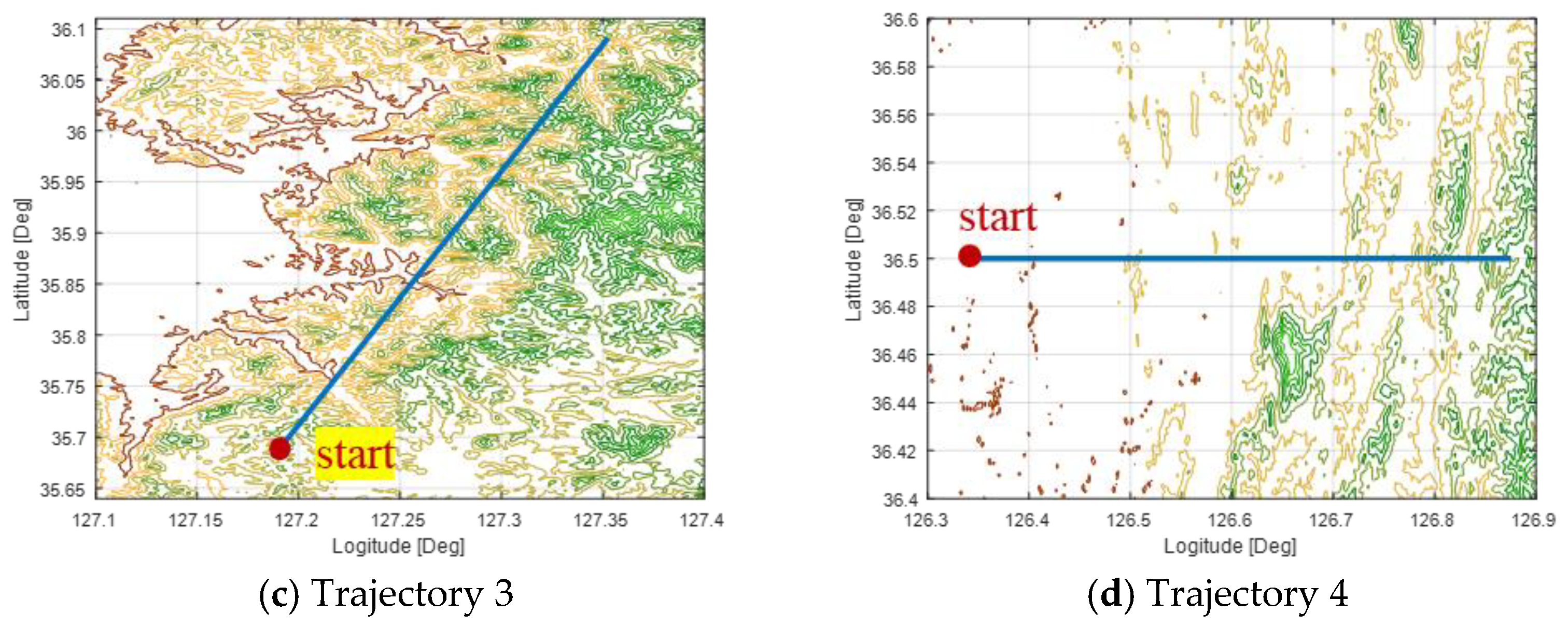
Figure 3 shows the simulation trajectories used to observe the performance in various terrain conditions.
Figure 3b shows a trajectory that starts from the rough terrain to sea, with
Figure 3c showing a trajectory that includes only rough terrains,
Figure 3d showing a trajectory that starts from flat land to rough terrain, and
Figure 3a showing a trajectory that includes all rough and flat terrains. Through these simulations in various terrains, we want to draw the most optimal design of the validity check logic. This study conducted simulations in various trajectories with
and without
, and the results are as shown in
Table 2. Also, this study compared the navigation error between cases that are decided by
in the current point of view and cases that are decided by
accumulated from previous times.
The cases in
Table 2 are defined as follows:
Case 1. RBPF based TAN without IRA and terrain validity check
Case 2. RBPF based TAN only with IRA validity check
Case 3. RBPF based TAN with IRA and terrain validity check using
Case 4. RBPF based TAN with IRA and terrain validity check using
and
Case 5. RBPF based TAN with IRA and terrain validity check using , , and
As
Table 2 indicates, all trajectories had a smaller position error with the IRA and terrain validity check logics than without the check logics. Even if the validity check logic was used, its performance was better on average when the measurement update was conducted with either one of the positive current or one-step previous
than if the current
was positive, or if either one among the current
and the previous two-step
were positive.
Table 2 indicates that the IRA validity check logic provide great improvement. Although the terrain validity check logic is not perfect, it is helpful to improve the performance in some ways. As the IRA validity check logic is a technique to filter out the uncertain IRA measurements caused by the flat and repetitive terrains, a wide sense of the terrain validity check logic is a must for RBPF based TAN. Also,
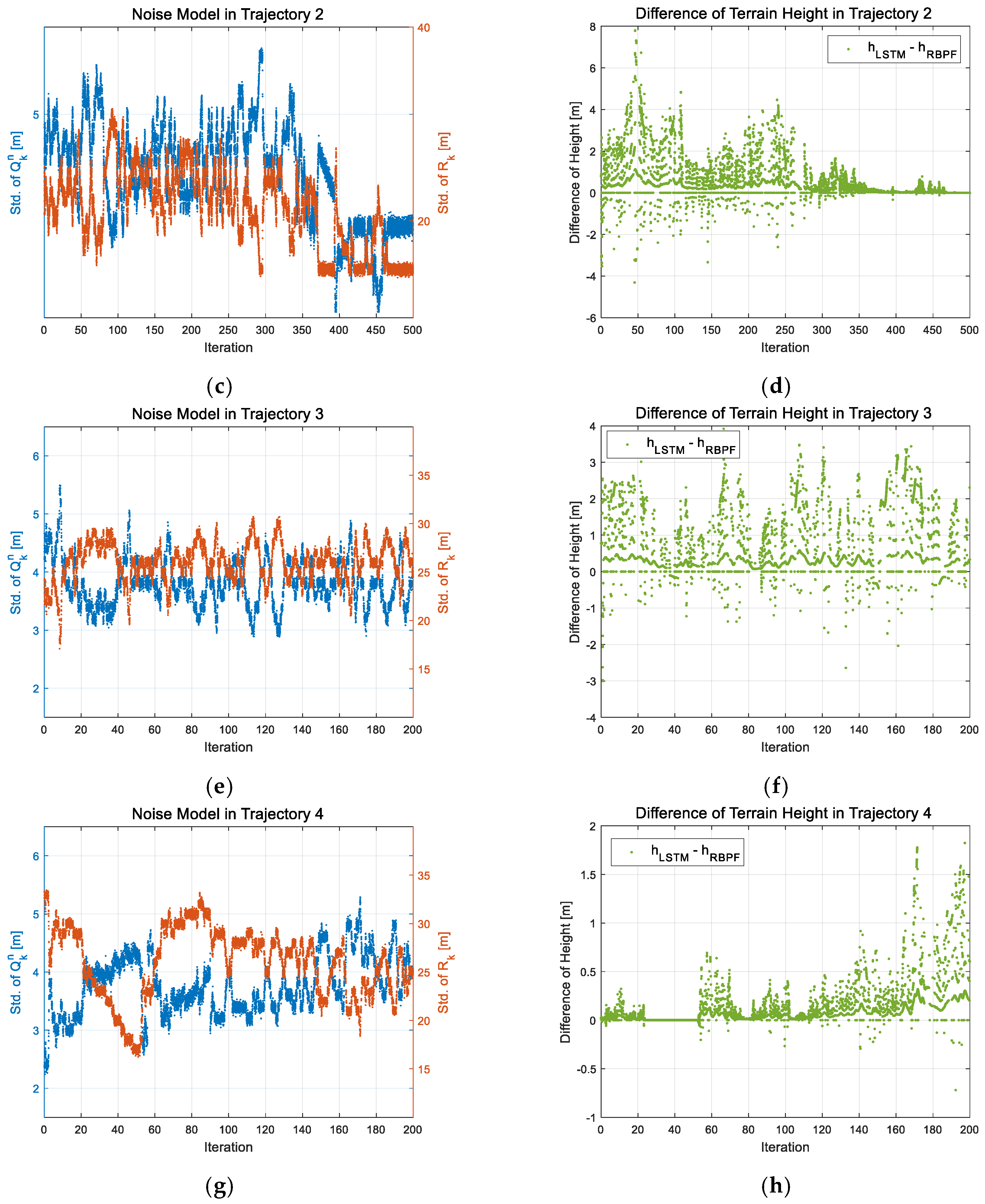
Table 2 shows that the previous data pattern rather than the current data must be considered. Also, these simulation results represent that it is difficult to numerically model the logic helpful to all the common trajectories. So, this study aimed to suggest a design with more improved performance than the conventional RBPF based TAN in various terrains by utilizing deep learning techniques that use time series data, which are called LSTM networks.










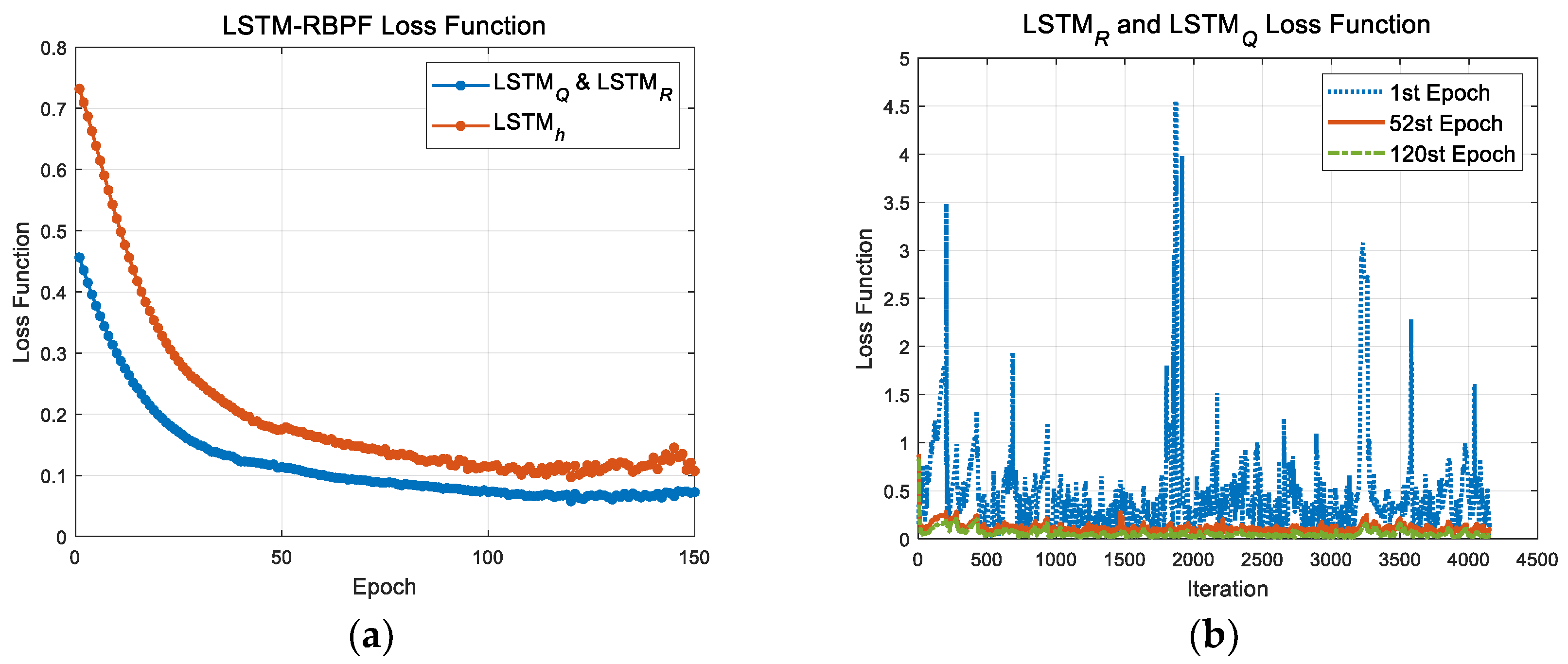






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}