1. Introduction
Accurate localization in an unknown environment is essential for a robot to succeed in its missions. In many cases, existing external localization systems, such as motion capture systems, the global positioning system, or a pre-constructed map of the working area, are costly, insufficiently accurate, or unavailable. In this study, we focused on estimating a vehicle’s motion by fusing the measurements from a monocular camera and an inertial measurement unit (IMU). This task—the well-known monocular vision-aided inertial navigation system (VINS) problem—has drawn great interest in the robotic community (e.g., [
1,
2,
3,
4,
5,
6,
7]) for many reasons.
First, the monocular camera and the micro-electro-mechanical system IMU are both small and cheap and consume little power, and both are passive sensors, which means that they exert no influence on the external environment and do not interfere with each other like Lidars and RGB-D cameras. Second, the monocular camera cannot compute inter-frame motion alone, so some studies have assumed a constant-velocity model [
2,
3] between two frames. However, this assumption results in an inconsistent estimation. The micro-electro-mechanical system IMU usually works at a higher frequency than the monocular camera, so the IMU measurements can be integrated for accurate recovery of short-term inter-frame motion. However, the IMU measurements are corrupted by noise and slowly time-varying biases, which makes long-time integration unreliable [
4,
8], so visual information is required to aid the IMU in estimation of biases. Third, the monocular camera is a projective sensor that provides bearing information regarding visual features, so motion and structure can only be recovered up to an unknown scale [
1,
5]. In order to recover its metric scale by using IMU, a large enough acceleration and rotation rate are required along at least two axes of IMU [
9]. The direction of the gravity vector is also observable [
4,
8,
9], which means that the absolute roll and pitch of the VINS do not drift. Fourth, unlike some other sensors, such as wheel odometry and two-dimensional (2D) Lidar, IMUs and cameras both allow for three-dimensional (3D) motion and structure estimation. Hence, the system is versatile and applicable to various platforms, such as micro-aerial vehicles (MAVs), smart-phones, and humanoid robots.
The frameworks for information fusion of the VINS problem found in the literature fall into two categories: the loosely coupled framework [
1,
10,
11] and the tightly-coupled framework [
4,
8,
12,
13,
14,
15,
16]. The loosely coupled framework uses the results from a standalone visual system directly for fusion with the IMU measurements. For the monocular visual system, the visual scale is also included into the states of the filter. This kind of framework has some obvious drawbacks. First, there is a scale drift for monocular visual systems [
10,
17]; the most current estimation of the visual scale is used as the scale of the whole trajectory and structure, and the time-varying nature of the visual scale is not considered and cannot be modeled analytically [
10]. Second, the two systems operate independently, and the visual system is not assisted by the IMU measurements, so in this case, the fusion results are not optimal [
10,
11]. In contrast, the tightly-coupled framework integrates the visual and inertial measurements into one likelihood function, so the fusion is optimal. In this paper, we used the tightly-coupled framework.
The algorithms of information fusion of the VINS problem can also be grouped into two major categories: recursive Bayesian filters [
1,
9,
10,
11,
12,
15,
16] and bundle adjustment (BA)/graph-based optimization/smoothing methods [
4,
8,
18]. Bayesian filters are typically required to operate at the frame rate. For real-time performance, Bayesian filters marginalize out past poses and summarize the information gained over time with a joint probability distribution that serves as a prior. The computational cost of propagating joint distributions scales poorly with the dimension of the state vector. Hence, for the filters that model the 3D positions of map points in the map as the elements of the state vector, the number of map points in the map is severely limited, so the fusion precision is deduced, which is the main drawback of the filters [
19]. The multistate constraint Kalman filter (MSCKF) is a type of augmented extended Kalman filter [
12,
15,
16], its state vector keeps a sliding window of the past poses. The visual feature measurements are used to construct a probabilistic constraint between the poses. Its 3D positions are not modeled as the elements of the state vector. Hence, the computational complexity of MSCKF is linear with the number of features [
12,
15] and cubic with the length of the sliding window [
16]. For the MSCKF, the number of map points in the map is not limited, and it can achieve better performance when combined with delayed linearization. However, some information is lost if the tracking length of the visual feature is outside the range of the sliding window [
16]. The MSCKF and the extended Kalman filter are both susceptible to gradual accumulation of linearization errors. This problem becomes more serious if the number of long-term tracked visual features is small, such as during rapid rotation.
The graph-based optimization/BA methods possess many advantages, such as the iterative re-linearization that makes linearization errors negligible, the batch processing that makes the estimation results optimal and consistent, and the ability to add and remove measurements expediently. Compared with standard numerical optimization, the core features of the graph-based optimization methods take advantage of the sparsity of structure, including first- and second-order sparsity [
20,
21]. The sparsity makes the graph-based optimization methods particularly efficient. Nevertheless, as information accumulates, a full BA quickly becomes infeasible in computation for real-time or near real-time operation. To keep the computing time bounded, an alternative method is the local BA (LBA) that operates in the spirit of BA but maintains only some poses in the path (typically a sliding window of the most current poses; e.g., [
3,
4,
8,
18,
21]) and the observable map points. Obviously, direct removal of the edges related with the nodes outside the sliding window of the LBA is unwarranted. The literature includes two main types of methods to cope with those edges: the conditioning-based method [
3,
4] and the prior-based method [
8,
18]. For the conditioning-based method, the nodes outside the sliding window are directly fixed, and the related edges are used as usual. After the measurements of IMU are added, the first node (including the pose, velocity, and biases of IMU) of the sliding window must also be fixed to eliminate the ambiguity of motion [
4]. This kind of method is highly robust but is not optimal theoretically, because only a part of the graph is active while LBA is performed. For the prior-based method, a marginalization technique is performed on the edges related with the outside nodes to construct a prior distribution (typically, a Gaussian distribution) for the nodes in the sliding window. This kind of method is optimal theoretically but is also affected by linearization errors numerically and cannot cope properly with features whose tracking length lies outside the range of the sliding window.
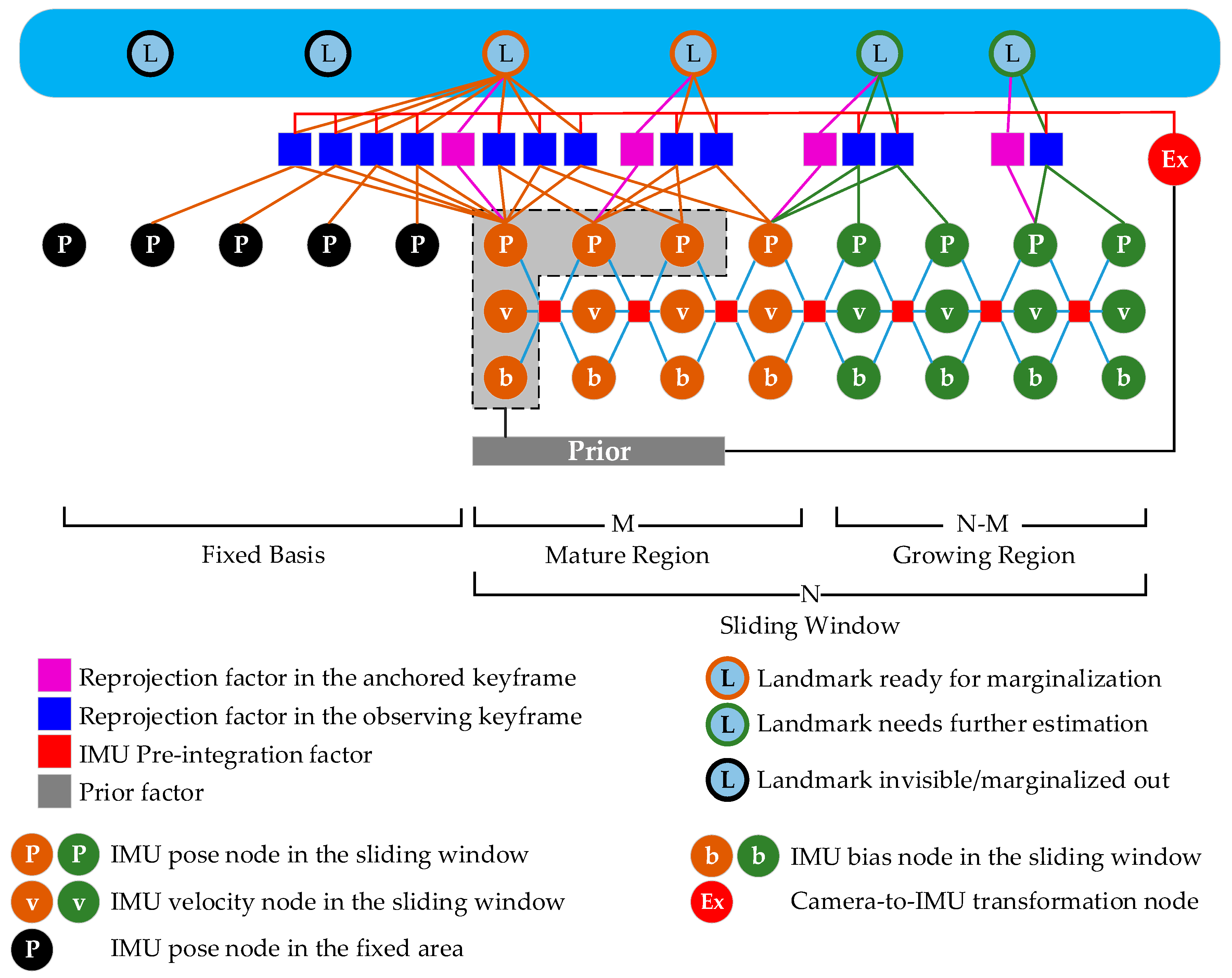
In this paper, we propose a novel hybrid sliding window optimizer (HSWO) that has the advantages of both the conditioning-based and prior-based methods. To make the linearization points of the prior distribution reliable, the sliding window in our method is divided into two parts. We call the front part the mature region and the back part the growing region. We marginalize a map point out only if its last measurement lies within the mature region. To cope with map points whose tracking length lies outside the range of the sliding window, we follow the conditioning-based method. The nodes outside the sliding window are fixed directly and are called the fixed basis. For balancing the linearization errors within the growing region and fixed basis, the size of the mature region should be selected carefully.
The two kinds of marginalization techniques—the Schur complement technology [
8,
18] and the null-space-based method [
12,
15,
16]—are equivalent mathematically [
22]. For the traditional method, all reprojection factors of marginalized map points are linearized at the current estimation, and a Hessian matrix is constructed by stacking linearized factors. Because there is a submatrix in the Hessian matrix that needs to be inversed, and the dimension of the submatrix depends on the number of marginalized map points (possibly more than hundreds). It is time-consuming and numerically unstable if we directly calculate the inverse matrix of the submatrix, as in [
8]. For our method, we first used the null-space-based method to calculate the multi-state constraints factors of the marginalized map points, i.e., the map point position parameters were marginalized first. Then, we stacked the multistate constraint factors to construct the Hessian matrix. In our method, the dimension of the submatrix that needs to be inversed is quite low.
To avoid the repeated integration of IMU measurements, the well-known IMU pre-integration technology has been widely adopted in graph-based optimization methods. This technique was first proposed by Lupton et al. [
23,
24] and further improved by [
8,
25,
26]. The integration is performed in the first body reference frame during a period, so no previous estimates or covariance are necessary except for the current estimates of the IMU biases.
It is well known that the uncertainty of low-parallax features is poorly approximated by Gaussian distribution in Euclidean (
XYZ) space, which makes
XYZ parameterization suitable only for relatively close features. An inverse depth parameterization technology was proposed by Civera et al. to handle this case [
5,
27]. However, the dimension of the inverse depth parameterization is six, which is twice the size of the
XYZ parameterization. For this reason, an anchored inverse depth parameterization was proposed by Pietzsch [
28]. In this study, we adopted the anchored inverse depth parameterization and selected the first keyframe in the sliding window as the anchored frame.
Some VINS solutions, such as VI-ORB-SLAM [
4], assume that the camera-to-IMU transformation is known. This requirement is not always met, such as with a new device. Although the camera-to-IMU transformation can be calibrated by offline methods [
29,
30], these methods are time-consuming and complex and require a professional user to carefully move the device in front of a stationary calibration target [
29,
30]. In this study, the camera-to-IMU transformation was estimated online.
Both the conditioning-based method and the prior-based method are susceptible to linearization error. Directly fixing the outside nodes makes the conditioning-based method more sensitive to linearization error, so a high-precision initialization method is essential for the VINS problem [
7]. Two types of online initialization methods are found in the literature: loosely-coupled methods [
31,
32,
33] and tightly-coupled methods [
34,
35]. As reported by Liu et al. [
32], the tightly-coupled methods that aim to recover all navigation quantities in one attempt perform poorly because they attempt to solve a large number of variables in a poorly conditioned system. In this study, we adopted the method proposed by Huang et al. [
31].
Our contributions are threefold:
We designed a novel hybrid sliding window optimizer that has the advantages of both the conditioning-based method and the prior-based method.
We designed a distributed marginalization technology based on multi-state constraint factors.
We estimated the camera-to-IMU transformation online.
The remainder of this paper is organized as follows.
Section 2 briefly introduces the anchored inverse depth parameterization and IMU pre-integration technology. In
Section 3, we demonstrate the framework of the hybrid sliding window optimizer in detail. In
Section 4, we demonstrate the distributed marginalization technology, and in
Section 5, we show our experimental results and some implementation details, and in
Section 6, we make our conclusions.
4. Distributed Marginalization
Marginalization technology is widely used in both Bayesian filters and graph-based optimization methods to make system scalable. For the traditional method (e.g., [
8,
18]), the last prior residual function, all reprojection residual functions of marginalized map points, and the first pre-integration residual function in the sliding window are directly linearized and normalized at current estimates. Then, all of those linearized and normalized residuals are stacked into one residual (we refer readers to the open-source code of [
8] for more details), as follows:
where
is the state variables related with the residuals used in the marginalization.
represents the current estimation of
. The notation
denotes the function value of
at current estimation
.
is the perturbation increments of
with respect to
, as follows:
where
is the size of the mature region.
is the number of marginalized map points.
denotes perturbation increments of the state variables that need to be marginalized.
corresponds to the state variables that remain.
is the full state variables of IMU as the above section. The perturbation increments of the elements of
are additive, e.g.,
, except for the unit quaternion
. The perturbation of unit quaternion is defined as follows:
where
is an angle-axis vector. So, the perturbation increments of
can be denoted as follows:
the perturbation increments of
are additive, i.e.,
.
For calculating the prior residual function for next optimization, the Shur complement technology was used on Equation (21) to marginalize the map points out, yields
the Equation (25) is only related with
, and serves as the prior residual function for next optimization after normalization. The map points that have be marginalized out will never be used again. According to Equation (21), it can be found that the dimension of the submatrix
is
, and mainly depends on the number of marginalized map points. However, in some cases, the
will be quite large, e.g., rich texture and fast rotation, which makes the matrix inversion
time-consuming and numerically unstable.
In this paper, we designed a distributed marginalization method to reduce the dimension of the submatrix
, in order to make the matrix inversion
efficient and stable. The core idea of our method is that we first calculate the MSC factors of the marginalized map points. The 3D inverse depth positions of the map points are marginalized out by using the null-space-based method [
12,
22]. Therefore, those MSC factors are only related with the poses of IMU within the mature region and the camera-to-IMU transformation.
We marginalized a map point out only if all its measurements (at least 3) lie outside the growing region and at least two measurements lie within the mature region. In mathematic terms, there are
,
, and
, where
denotes the number of elements of the set. For a marginalized map point, there are no visual measurements within the growing region. According to Equation (15), the cost function of the marginalized map point
is as follows:
where
is the reprojection residual function of the map point
.
is the state variables including the full state variables of IMU within the mature region and the camera-to-IMU transformation.
is a block-diagonal covariance matrix. The residual function of
can be linearized and normalized at the current estimation
and
, as follows:
where
signifies the function value of
at current estimation
and
.
We rewrite Equation (28) in a compact form, as follows:
the 3D inverse depth position deviation
can be marginalized out by using the left null space of the Jacobian matrix
. The left null space can be calculated by QR decomposition, and we denote it as
. Substituting
into the Equation (28), we have
where
,
, and
. Equation (29) is the well-known MSC factor [
12,
15]. It can be found that the Equation (29) is independent of the 3D inverse depth position
.
By combining the last prior residual function Equation (17), the linearized and normalized pre-integration residual function in Equation (14) of the first pre-integration in the sliding window, and all of the MSC factors, we can construct the equation Equation (21). Compared with the traditional method (e.g., [
8,
18]), the dimension of submatrix
of our method decreases to 6 + 3 + 6 (corresponding to the first IMU pose, velocity, and biases in our implementation). We can compute the inversed matrix of
in an effective and stable manner.
5. Results and Discussion
We evaluated the proposed hybrid sliding window optimizer on the publicly available EuRoC datasets using a commercial laptop computer (Lenovo ThinkPad T470p, Intel i7-7700HQ, 2.8GHz). The EuRoC visual-inertial datasets were collected onboard by an MAV flying in two Vicon covered rooms and a large industrial machine hall. The datasets contain synchronized stereo image sequences, IMU measurements, and accurate ground truth [
40]. All sequences were classified as easy, medium, and difficult levels according to texture, illumination, fast/slow motion, and motion blur [
40]. In our data processing, we used only the left image sequence (i.e., monocular). The original publicly available ORB-SLAM has three main threads: the tracking thread, the local mapping thread, and the loop closing thread. We implemented the HSWO based on the local mapping thread, and the loop closing thread was removed. The iterative linear solver of the nonlinear VINS problem requires a good initial value to achieve a rapid rate of convergence. Hence, a good initialization for the VINS problem is necessary. In this paper, we followed the method proposed by Huang et al. [
31]. A visual-inertial bundle adjustment is performed immediately after visual-inertial initialization.
We used EVO [
41], a third-party evaluation software, to analyze the trajectory calculated by the HSWO. EVO aligned the trajectory with the ground truth via Umeyama’s method and then provided the RMSE of the absolute metric position deviation. Because the threads of ORB-SLAM run in parallel with other tasks of the operating system, some randomness will be introduced into the results [
3]. Our implementation also inherited this property; therefore, we provide the median value of the RMSEs of five runs just as reference [
3] did.
There are different choices for the size of the sliding window N and the size of the mature area M, which affects the results significantly. In this paper, we evaluated and optimize the performance of the HSWO by changing the size of N and M. In addition, the “MapPointFusion()” function in the ORB-SLAM is in charge of fusing the same map point (if available) in the scene, which may introduce some local loop closures and large loop closures. Those potential loop closures may interfere with the evaluation results and cause unfair comparison. Therefore, we adopt three methods to remove them: (a) Do not fuse the two map points if the map point with large ID has been marginalized; (b) Allow a map point to add new observation only if the new observation is within the growing region; (c) Limit the size of the Fixed basis F.
In the EuRoC datasets, the dataset labeled with
MH_03
_medium is the longest and contains fast motion that motivates the IMU. So, we analyzed the influence of changing
N,
M, and
F in the HSWO by using this representative dataset. The parameter tuning results are listed in
Table 1.
The accuracy of the system will be improved if increase N, which is because more information is contained;
By comparing N15-M10-F15 with N15-M10-F00, we can find that the accuracy will degrade dramatically if the fixed basis is removed, which is because the information in the fixed basis is omitted;
By comparing N15-M10-F15 with N15-M05-F15, or N20-M10-F20 with N20-M05-F20, we can find that the accuracy will degrade if the value of M is too small, in which case the fixed basis has more weight than the prior factor, and directly fixing the pose of the keyframe in the fixed basis makes it more sensitive to the linearization error;
By comparing N20-M10-F20 and N20-M15-F20, we can find that the accuracy of the system will also degrade if the value of M is too large.
Theoretically, the prior factor has one-order accuracy, the keyframe nodes related with the prior factor still have the chance to be updated. However, the linearization error of the prior factor will increase if M is too large, because the keyframe nodes with larger ID are estimated less times than the ones with smaller ID. For making the linearization error less and giving the keyframe nodes with large ID more freedom (i.e., making the keyframe nodes with large ID not related with the prior factor), we set N = 20, M = 10 in the following data processing.
An array of publicly available VINS pipelines (MSCKF, OKVIS, ROVIO, VINS-Mono, etc.) have been evaluated on various hardware configurations [
42]. They performed sim3 trajectory alignment to the ground truth and computed the root-mean-square error (RMSE) of the absolute position over the aligned trajectory. All results are listed as a table, and we used the results evaluated on a common mobile workstation (Lenovo ThinkPad W540) for comparison. The accuracy of VI-ORB-SLAM proposed in [
4] was also evaluated with the EuRoC dataset, and all metric position RMSEs are shown in the same table. Because our implementation includes no full visual-inertial bundle adjustment, we selected the results labeled as “NO full BA” for comparison. We also directly used the results reported for the VI-DSO proposed by Von Stumberg [
43]. All of the results are listed in
Table 2, “HSWO (Limited)” means that we removed potential local loop closures by using the three methods mentioned above, and the maximum of the size of the fixed basis
F is set as 20. “HSWO” means that we keep the original “MapPointFusion()”, the map point will be treated as a new map point after fusion with other map point, which will cause reuse of visual measurements. Note that many details of these VINS pipelines, e.g., the data association of the front end, setting of optimizers, and trajectory saved, are different. For those reasons, the purpose of the comparison is not to show which VINS pipeline is better, but to demonstrate that our implementation can also achieve high-accuracy results by using the results provided by others VINS pipelines as a third-party reference standard.
The full trajectory contains the poses of every frame, not only the keyframe. The original ORB-SLAM recovered this trajectory from the relative pose and the reference keyframe of every frame, and we follow the same method in this paper. In most cases, the accuracy of the full trajectory may be lower than the one of the keyframe trajectory. But, in some cases, the accuracy of full trajectory may be better, and there are two reasons for this: (a) the full trajectory is recovered from the keyframe trajectory, therefore the accuracy of two trajectory should be comparable; (b) the number of pose in the full trajectory is much larger than the one in the keyframe trajectory. So, the weight of every pose deviation will be decreased during calculating the RMSE of trajectory. Then, the weight of some big deviation will also be decreased. In this case, the RMSE of the full trajectory will be less than the RMSE of the keyframe trajectory.
VI-ORB-SLAM used a conditioning-based method for fusing the visual and inertial measurements, and the first IMU pose, velocity, and biases node are also directly fixed. Theoretically, this method is more sensitive to linearization error. However, the accuracy of the keyframe trajectory produced by VI-ORB-SLAM is quite high. The reason might be: The EuRoC datasets contain many local and large loops, the “MapPointFusion ()” function in the local mapping thread may implicitly close many local loops and some large loops, which phenomenon is also found by [
44]. In VINS-mono, visual features are tracked by the KLT sparse optical flow algorithm. Both VI-DSO and ROVIO use direct method for data association. Also, they cannot achieve map point fusion like ORB-SLAM. Therefore, it cannot be proven that the conditioning-based method is sufficient for VINS problem, even if the accuracy of VI-ORB-SLAM is higher than some other VINS pipelines. In order to eliminate the influence of map point fusion, the results of the HSWO in which map point fusion has been limited are also listed in
Table 2. It can be found that its accuracy slightly degrades compared with the HSWO with map point fusion. Also, compared with other VINS pipelines with no map point fusion, our implementation still achieves better performance on more than half of the EuRoC datasets. Note that the VI-ORB-SLAM cannot process the
V1_03_ difficult dataset because the movement has exceeded the limit for the monocular system [
4]. In our implementation, IMU measurements are used to reckon the frame pose during tracking lost epoch, and a reprojection method is then used to perform feature matching, which makes it possible to process the
V1_03_ difficult dataset. However, our implementation cannot process the
V2_03_ difficult dataset if the map point fusion function is limited using the methods mentioned above, even if an approximate frame pose has been provided by integrating the IMU measurements, our implementation still cannot find suitable map points for matching.
Based on all of the above analysis, we claim that:
- (a)
The accuracy of the proposed HSWO will degrade if the size of mature region M is too small, in which case, the performance of HSWO tends to the conditioning-based method.
- (b)
The accuracy of HSWO will degrade if the fixed basis is removed, in this case, the HSWO degenerates into the prior-based method, and the map point whose tracking length is larger than the sliding window cannot be used effectively.
- (c)
We need to select a suitable value for M to balance the linearization error within the fixed basis and the prior factor. For our implementation, we set N = 20, and M = 10.
- (d)
Compared with the results provided by other VINS pipelines, the accuracy of our results is competitive.
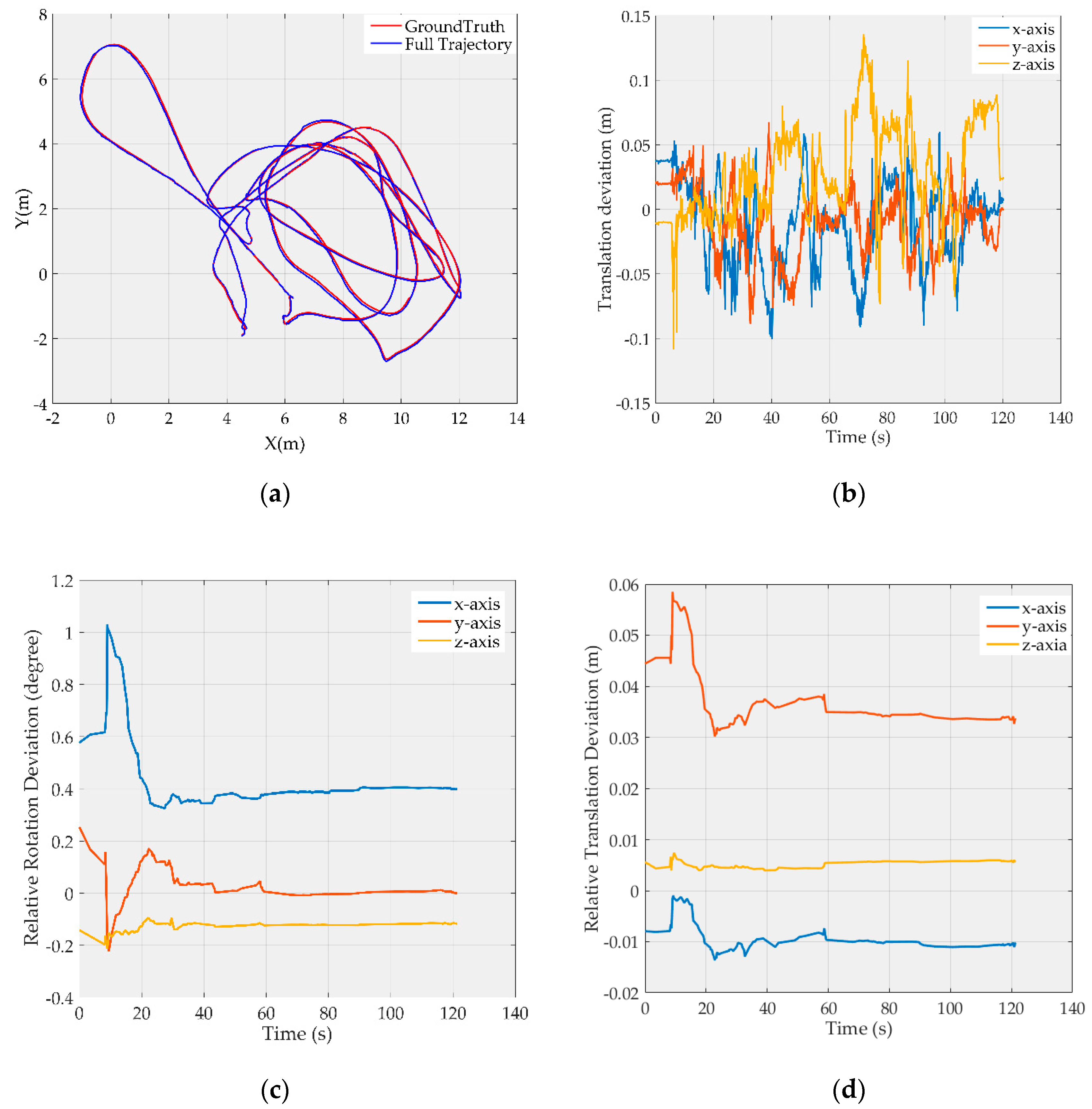
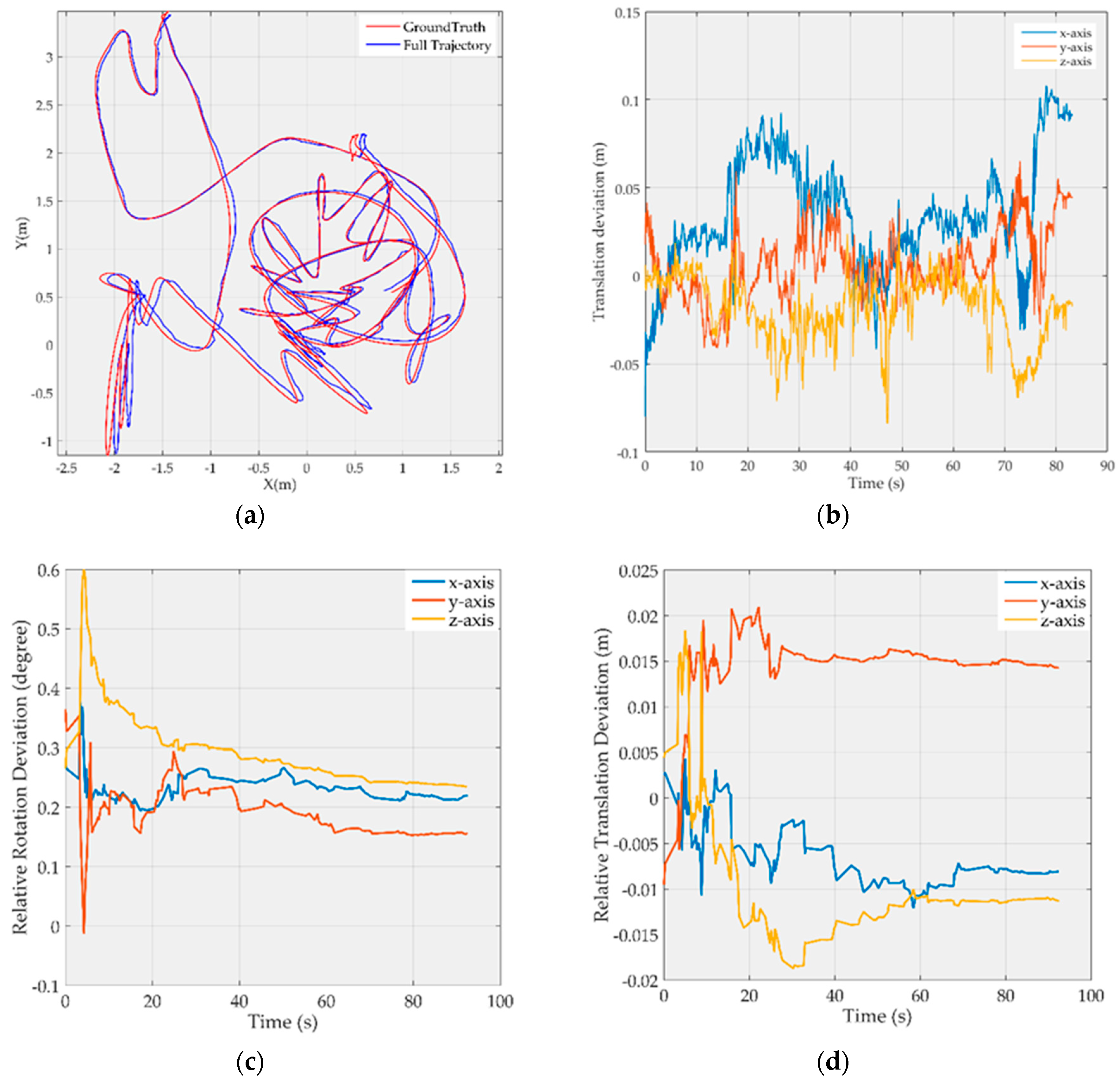
Due to limited space,
Figure 2 and
Figure 3 show only the results on
MH_03_medium and
V1_03_difficult, respectively, where the map point fusion function has been limited. The full trajectories are aligned with the ground truth and shown in
Figure 2a and
Figure 3a, respectively; the translation deviations with respect to the ground truth are shown in
Figure 2b and
Figure 3b, respectively, and most of the deviations are less than 10 cm; the rotation deviations of camera-to-IMU transformation are shown in the
Figure 2c and
Figure 3c, respectively, and the translation deviations of camera-to-IMU transformation are shown in the
Figure 2d and
Figure 3d, respectively. It can be found that the estimation of camera-to-IMU transformation fluctuates at the start period, and then tends to be stable as time goes on. But there are still some constant biases in the estimation. This is because the resolution of the digital camera is limited, and most map points are far from the camera, in which case, small rotation biases and small translation biases in the camera-to-IMU transformation estimation will not cause sufficient parallax, and therefore cannot be observed effectively by the optimizer.
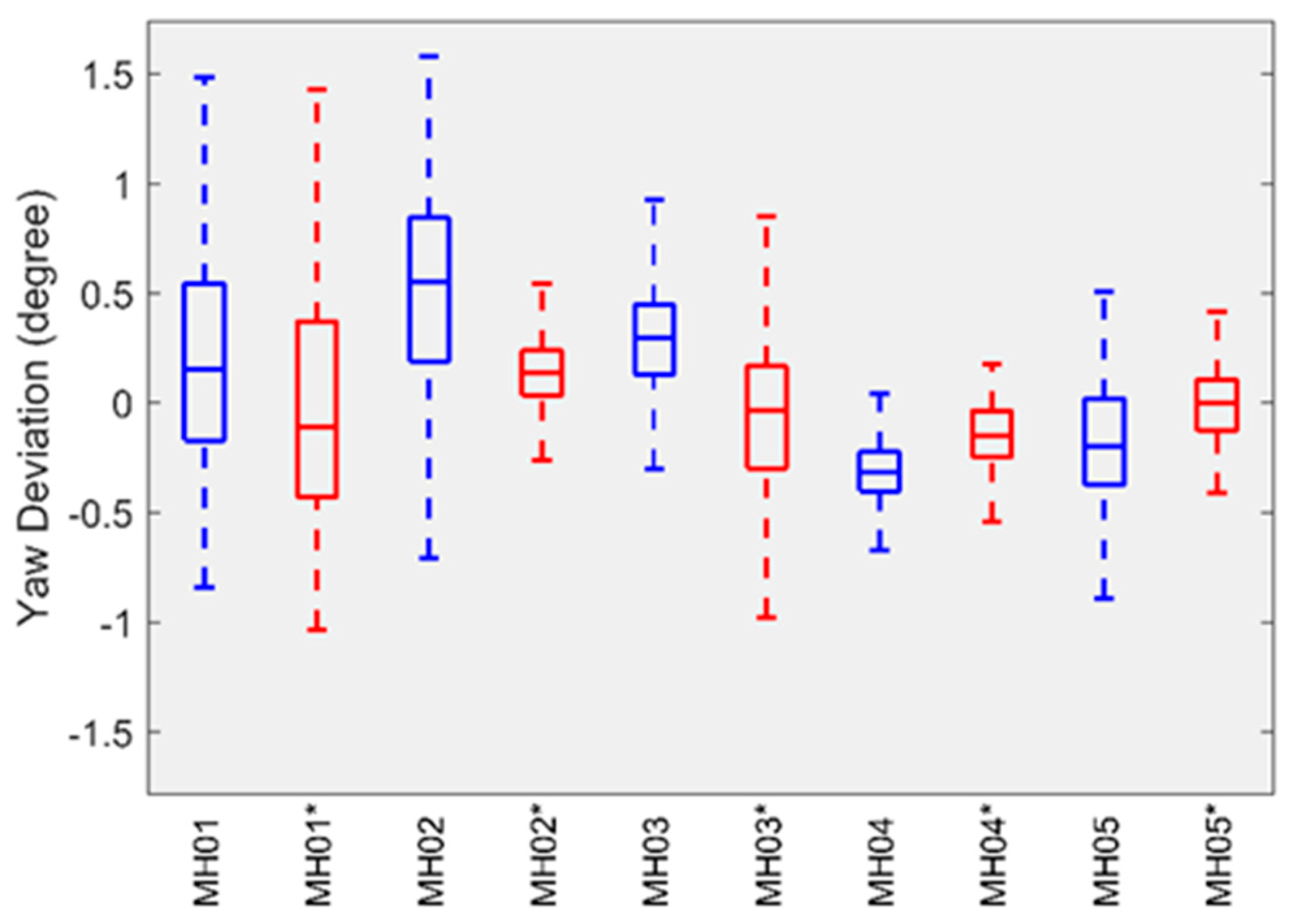
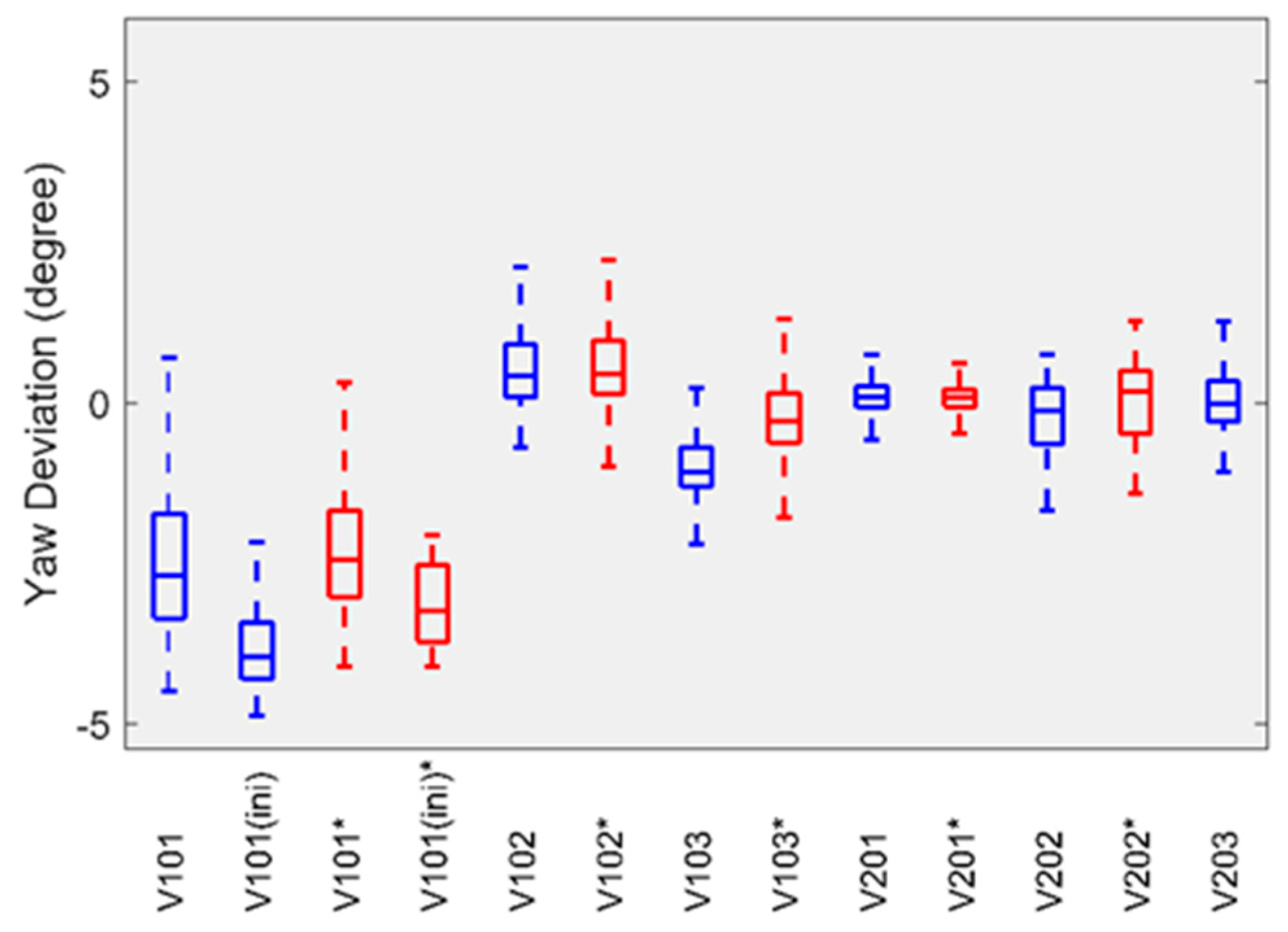
For attitude error, we followed the evaluation method proposed by Delmerico et al. [
42] and used the transformation matrix calculated by EVO to align the estimated attitude with its ground truth, and then computed the yaw error. The boxplots in
Figure 4 and
Figure 5 summarize the statistics of the yaw error on each sequence of the EuRoC datasets. The results provided by the HSWO (limited) are labeled with (*). The yaw error on
V1_01
_easy dataset is significantly larger than on the other datasets. Here we noticed that the motion on
V1_01_easy dataset is weak during initialization, which means our implementation cannot be well initialized, even if a visual-inertial bundle adjustment is performed right after the initialization.
In the multithread framework, the optimizer has no need to operate at the frame rate.
Table 3 lists the statistical results for the time consumption of the HSWO used in our implementation and the LBA (vision-only, a conditioning-based method) used in the mono ORB-SLAM [
3].
The standard deviation of the time consumed by the HSWO is less than that for the LBA, which means that the HSWO’s time consumption is more stable. This better stability is a result of the fixed size of the HSWO’s sliding window, whereas the number of the keyframes used in the LBA varies according to the co-visibility between keyframes, which makes the time consumed by the LBA fluctuate. If a large number of keyframes are used in the LBA and a map point is visible in all keyframes, the second-order sparsity will disappear. In this case, the computation complexity of the LBA is cubic with the number of keyframes. Therefore, the LBA’s maximum time consumption is much larger than that of the HSWO. The mean time consumption is approximately equivalent for both methods. During the initial period, the number of keyframes is small and the co-visibility is sparse, so the LBA is much more efficient. As the map grows and the co-visibility gradually becomes denser, the time consumed by LBA will increase. Therefore, the median time consumption of the HSWO is slightly greater than that of the LBA. Based on these statistical results, we claim that the HSWO shows comparable efficiency as the LBA.
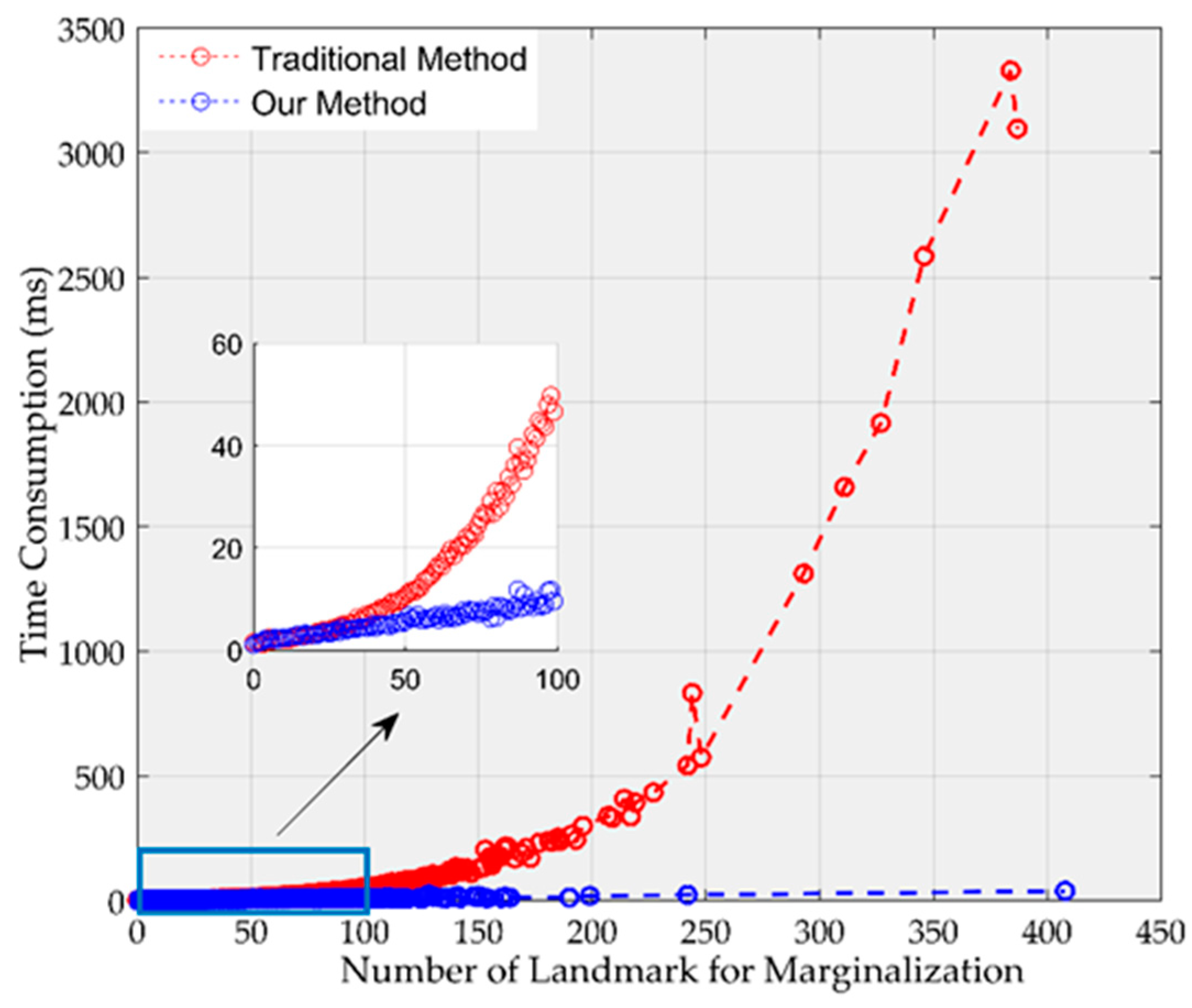
Generally, there are 30–80 map points to be marginalized at every step. But in some cases, such map points increase to more than a hundred. In order to evaluate our marginalization method, we increased the size of mature region for making more map points marginalized. Additionally, we performed marginalization in one thread to remove randomness.
Figure 6 plots the time consumed by the traditional method (e.g., [
8,
18]) and by our method. The time consumed by the traditional method is cubic with the number of map points used in marginalization, but the time consumed by our method is linear with the number of map points used in marginalization. Therefore, our method is much more efficient than the traditional method, especially with a large number of map points.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}