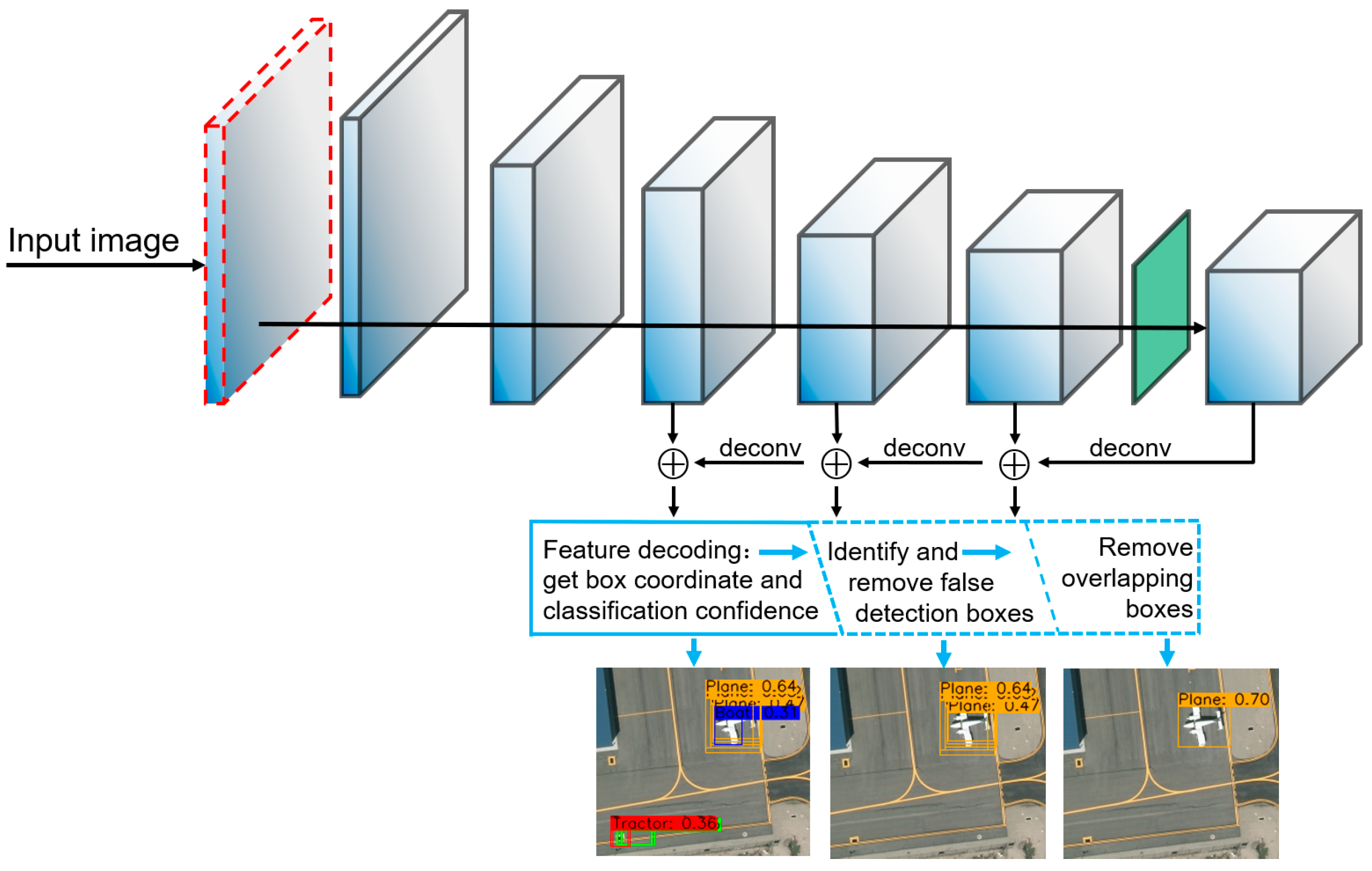
Dual-NMS: A Method for Autonomously Removing False Detection Boxes from Aerial Image Object Detection Results

 ,
,
Abstract
:1. Introduction
- 1)
- The dual-NMS is proposed. As an optimization algorithm for detection results, the precision of the object detection results is greatly improved under the premise of keeping the recall unchanged.
- 2)
- We proposed the CorrNet. The feature extraction capability of the convolutional network is enhanced by introducing the correlation calculation layer of the feature channel separation and the dilated convolution guidance structure. This enhancement makes the CorrNet more suitable for the detection of small objects in aerial images.
- 3)
- Experiments were carried out by using several aerial image object detection datasets to verify the effects of the dual-NMS and CorrNet, and the results were compared with those of YOLOv3. The experimental results show that the CorrNet has better detection effects for the small objects in aerial images.
2. Related Works
3. Our Methods
3.1. Dual-NMS
3.1.1. The False Detection Boxes
3.1.2. The Differences between True and False Detection Boxes
3.1.3. Removing the False Detection Boxes by Using the Dual-NMS
| Algorithm 1: Dual-NMS |
| Input: B = {b1, …, bN}, S = {s1, …, sN}, Nt1, Nt2, α, β, γ B is a set of predicted bounding boxes for class A S is a set of corresponding classification confidences Nt1 and Nt2 are the NMS thresholds α, β and γ are the parameters in function f that are used to suppress false predicted bounding boxes Output: D the final predicted bounding boxes 1: D = ∅ 2: while B ≠ ∅ do 3: bt ← the first element in B; T = ∅; Sp = ∅ 4: T ← T ∪ {bt} 5: Sp ← Sp ∪ {st} 6: B ← B \ {bt} 7: S ← S \ {st} 8: for bi ∈ B do 9: if IoU (bt, bi) ≥ Nt1 then 10: T ← T ∪ {bi} 11: Sp ← Sp ∪ {si} 12: B ← B \ {bi} 13: S ← S \ {si} 14: end if 15: end for 16: Ssum ← sum (Sp) 17: d ← len(T) 18: s_m ← argmax (Sp) 19: if Ssum > f (d, s_m, α, β, γ) then 20: while T ≠ ∅ do 21: sm ← argmax (Sp) 22: T ← T \ {tm} 23: Sp ← Sp \ {sm} 24: D ← D ∪ {tm} 25: for ti ∈ T do 26: if IoU (tm, ti) ≥ Nt2 then 27: T ← T \ {ti} 28: Sp ← Sp \ {Si} 29: end if 30: end for 31: end while 32: end if 33: end while 34: return D |
- 1)
- All the detection boxes are grouped according to the IoU between them (lines 3~15). The detection boxes with a certain degree of overlap are divided into a group.
- 2)
- The density of the detection boxes in each group is counted. The sum and the maximum of the classification confidences in each group of the detection boxes are calculated.
- 3)
- The dynamic threshold that is calculated by function and the above statistics are used to determine whether the detection boxes in this group are false or not. If they are false detection boxes, delete them.
3.2. CorrNet
3.2.1. The Characteristics of Aerial Images
3.2.2. The Optimization Methods
4. Experiments and Results
4.1. The Metrics that Were Used in the Experiments
4.2. The Effectiveness of the Dual-NMS
4.3. Ablation Experiment
4.4. Analysis of the Effectiveness of the Network Optimization Methods
4.5. Comparison of the Detection Results
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OA, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Gordon, A.; Li, H.; Jonschkowski, R.; Angelova, A. Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras. arXiv 2019, arXiv:1904.04998. [Google Scholar]
- Li, Y.; Wang, H.; Zhang, Y.; Lu, H. Monocular image depth estimation based on structured depth learning. Robot 2017, 6, 812–819. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. CornerNet-Lite: Efficient Keypoint Based Object Detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Object Detection with Keypoint Triplets. arXiv 2019, arXiv:1904.08189. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. arXiv 2019, arXiv:1904.11490. [Google Scholar] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, Hawaii, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle Detection in Aerial Images Based on Region Convolutional Neural Networks and Hard Negative Example Mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Ke, Y.; Zhang, Z.; Wang, M.; Li, P.; Zhang, S. Urban Land Use and Land Cover Classification Using Novel Deep Learning Models Based on High Spatial Resolution Satellite Imagery. Sensors 2018, 18, 3717. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; pp. 816–832. [Google Scholar] [Green Version]
- He, Y.; Zhu, C.; Wang, J.; Savvides, M.; Zhang, X. Bounding box regression with uncertainty for accurate object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 2888–2897. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 658–666. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS — Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- He, Y.; Zhang, X.; Savvides, M.; Kitani, K. Softer-NMS: Rethinking Bounding Box Regression for Accurate Object Detection. arXiv 2018, arXiv:1809.08545. [Google Scholar]
- Hosang, J.; Benenson, R.; Schiele, B. A convnet for non-maximum suppression. In Proceedings of the German Conference on Pattern Recognition, Hannover, Germany, 12–15 September 2016; pp. 192–204. [Google Scholar]
- Hosang, J.; Benenson, R.; Schiele, B. Learning non-maximum suppression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, 21–26 July 2017; pp. 4507–4515. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 3146–3154. [Google Scholar]
- Mou, L.; Hua, Y.; Zhu, X.X. A Relation-Augmented Fully Convolutional Network for Semantic Segmentation in Aerial Scenes. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019; pp. 12416–12425. [Google Scholar]
- Napoletano, P.; Piccoli, F.; Schettini, R. Anomaly Detection in Nanofibrous Materials by CNN-Based Self-Similarity. Sensors 2018, 18, 209. [Google Scholar] [CrossRef] [PubMed]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote. Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, AL, USA, 18–22 June 2018; pp. 3974–3983. [Google Scholar]
- Yuliang, L.; Lianwen, J.; Shuaitao, Z.; Sheng, Z. Detecting Curve Text in the Wild: New Dataset and New Solution. arXiv 2017, arXiv:1712.02170. [Google Scholar]
- Dai, Y.; Huang, Z.; Gao, Y.; Xu, Y.; Chen, K.; Guo, J.; Qiu, W. Fused text segmentation networks for multi-oriented scene text detection. In Proceedings of the 2018 24th International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 3604–3609. [Google Scholar]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the 2018 IEEE winter conference on applications of computer vision (WACV), Lake Tahoe, NV/CA, USA, 12–15 Mrach 2018; pp. 1451–1460. [Google Scholar]
- Zhang, X.; Wang, T.; Qi, J.; Lu, H.; Wang, G. Progressive Attention Guided Recurrent Network for Salient Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, AL, USA, 18–22 June 2018; pp. 714–722. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, AL, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Genmany, 10–13 September 2018; pp. 3–19. [Google Scholar]
- Shao, J.; Qu, C.; Li, J.; Peng, S. A Lightweight Convolutional Neural Network Based on Visual Attention for SAR Image Target Classification. Sensors 2018, 18, 3039. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Density (True Detection Boxes) | Density (False Detection Boxes) |
|---|---|---|
| VEDAI | 13.43 | 5.58 |
| UCAS-AOD | 20.08 | 6.29 |
| RSOD | 21.61 | 7.86 |
| DOTA | 12.18 | 3.85 |
| Dataset | S1 | S2 | S3 | S4 |
|---|---|---|---|---|
| VEDAI | 67.85% | 97.56% | 99.76% | 99.97% |
| UCAS-AOD | 15.78% | 54.67% | 90.87% | 96.60% |
| RSOD | 16.01% | 77.73% | 99.32% | 100.00% |
| DOTA | 14.31% | 70.07% | 100.00% | 100.00% |
| Model | VEDAI | UCAS-AOD | RSOD | DOTA |
|---|---|---|---|---|
| NMS | 0.5392 | 0.9200 | 0.7861 | 0.3356 |
| Dual-NMS | 0.5842 | 0.9495 | 0.7966 | 0.3842 |
| Model | Rr | VEDAI | UCAS-AOD | RSOD | DOTA |
|---|---|---|---|---|---|
| YOLOv3 | RrT | 11.54%/1.81% | 2.88%/0.86% | 2.81%/0.18% | 25.53%/8.50% |
| RrF | 56.92%/15.42% | 57.94%/30.05% | 51.02%/8.89% | 52.89%/32.19% | |
| CorrNet | RrT | 6.42%/2.09% | 1.01%/0.15% | 0.79%/0.08% | 11.06%/2.66% |
| RrF | 52.22%/16.22% | 40.44%/28.05% | 23.47%/14.37% | 61.56%/22.10% |
| Model | Reduced Downsampling Rates | Dilated Convolution Guidance Layer | Correlation Calculation Layer | mAP (%) | |||
|---|---|---|---|---|---|---|---|
| VEDAI | UCAS-AOD | RSOD | DOTA | ||||
| YOLOv3 | 62.86 | 95.99 | 83.23 | 38.91 | |||
| CorrNet | √ | 65.57 | 96.47 | 85.86 | 46.31 | ||
| √ | √ | 66.95 | 97.14 | 86.21 | 47.71 | ||
| √ | √ | √ | 68.05 | 96.82 | 88.02 | 48.69 | |
| Model | mAP (%) | |||
|---|---|---|---|---|
| VEDAI | UCAS-AOD | RSOD | DOTA | |
| Faster-RCNN | 64.70 | 89.00 | 84.47 | 60.46 |
| R-FCN | 61.80 | 93.50 | 84.07 | 52.58 |
| SSD | 46.10 | 78.88 | 87.85 | 29.86 |
| YOLOv2 | 50.30 | 89.41 | 87.35 | 39.20 |
| YOLOv3 | 62.86 | 95.99 | 83.23 | 38.91 |
| CorrNet | 68.05 | 96.82 | 88.02 | 48.69 |
| Model | NMS | Dual-NMS | mAP (%) | FPS | |||
|---|---|---|---|---|---|---|---|
| VEDAI | UCAS-AOD | RSOD | DOTA | ||||
| YOLOv3 | √ | 62.86 | 95.99 | 83.23 | 38.91 | 11.25 | |
| √ | 62.19 | 95.32 | 82.80 | 37.54 | 11.04 | ||
| CorrNet | √ | 68.05 | 96.82 | 88.02 | 48.69 | 9.99 | |
| √ | 67.70 | 96.71 | 88.00 | 48.14 | 9.81 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Z.; Wu, Q.; Fu, S.; Wang, S.; Zhang, Z.; Kong, Y. Dual-NMS: A Method for Autonomously Removing False Detection Boxes from Aerial Image Object Detection Results. Sensors 2019, 19, 4691. https://doi.org/10.3390/s19214691
Lin Z, Wu Q, Fu S, Wang S, Zhang Z, Kong Y. Dual-NMS: A Method for Autonomously Removing False Detection Boxes from Aerial Image Object Detection Results. Sensors. 2019; 19(21):4691. https://doi.org/10.3390/s19214691
Chicago/Turabian StyleLin, Zhiyuan, Qingxiao Wu, Shuangfei Fu, Sikui Wang, Zhongyu Zhang, and Yanzi Kong. 2019. "Dual-NMS: A Method for Autonomously Removing False Detection Boxes from Aerial Image Object Detection Results" Sensors 19, no. 21: 4691. https://doi.org/10.3390/s19214691
APA StyleLin, Z., Wu, Q., Fu, S., Wang, S., Zhang, Z., & Kong, Y. (2019). Dual-NMS: A Method for Autonomously Removing False Detection Boxes from Aerial Image Object Detection Results. Sensors, 19(21), 4691. https://doi.org/10.3390/s19214691