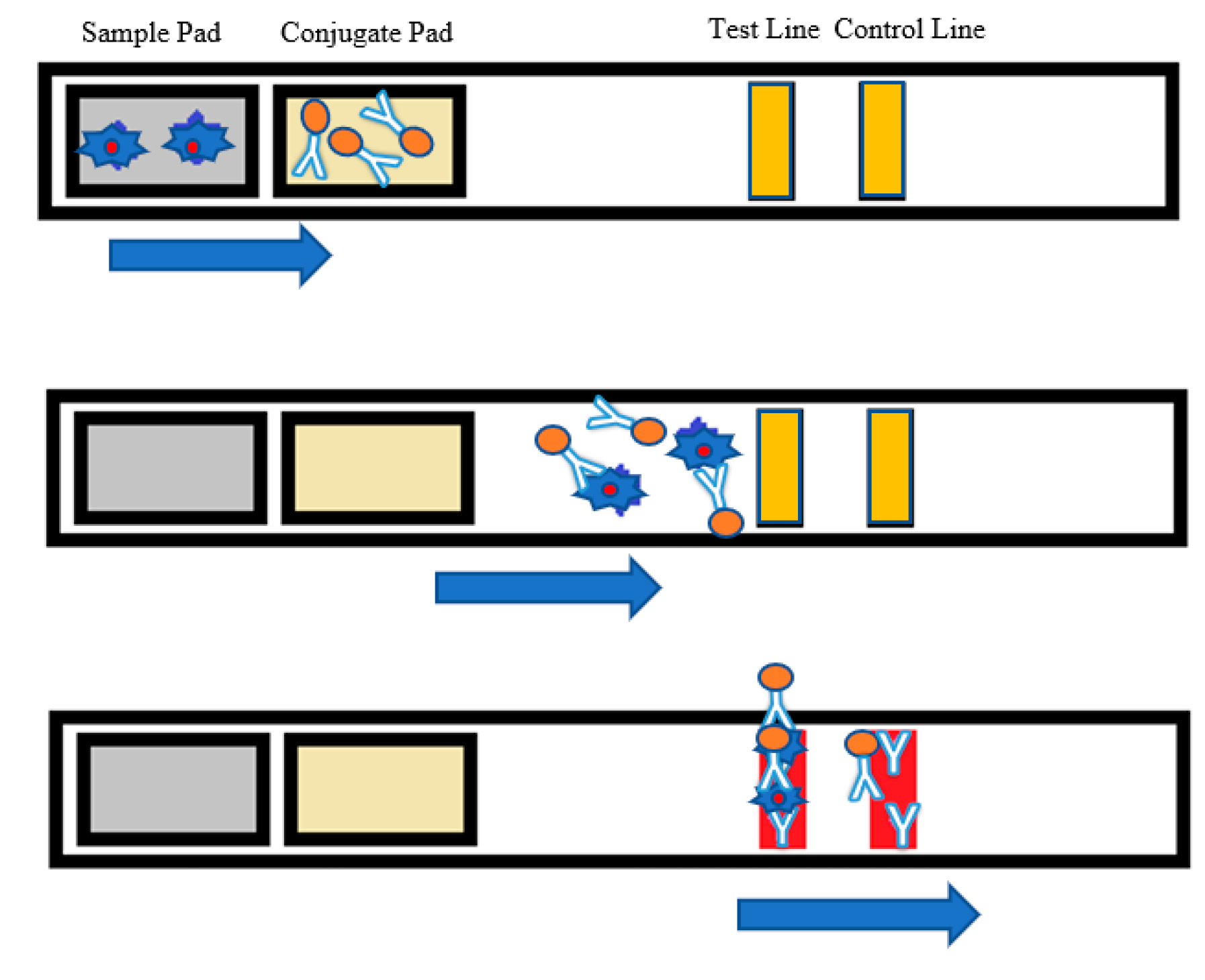
Figure 1.
Lateral flow assay (LFA) strip architecture where the analyte is detected in the test line, and the red control line indicates that the test was performed.
Figure 1.
Lateral flow assay (LFA) strip architecture where the analyte is detected in the test line, and the red control line indicates that the test was performed.
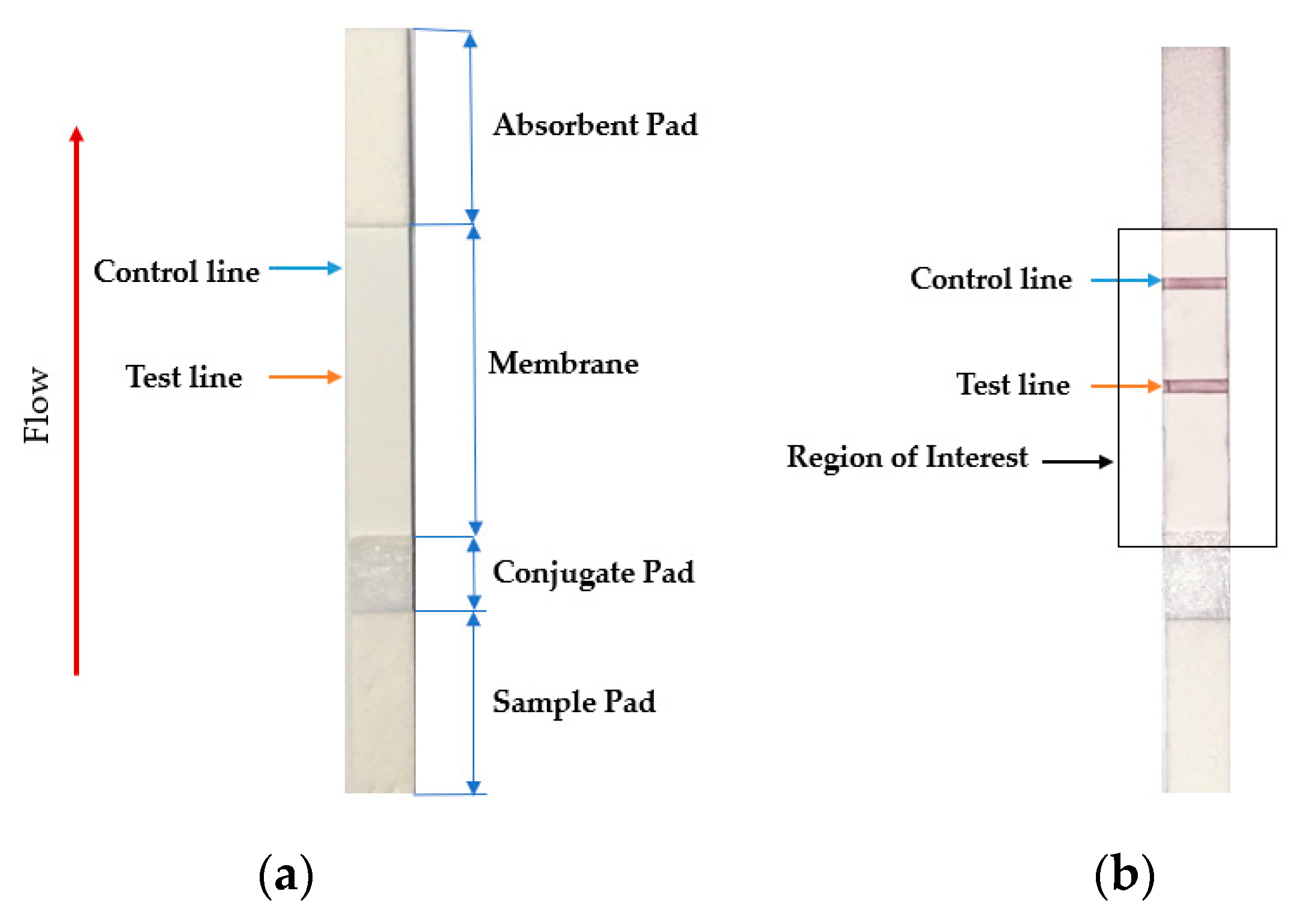
Figure 2.
(a) Sample LFA strip and (b) region of interest of an LFA strip with an analyte. The intensity and density of red color in the test line region determine the amount of analyte in the sample.
Figure 2.
(a) Sample LFA strip and (b) region of interest of an LFA strip with an analyte. The intensity and density of red color in the test line region determine the amount of analyte in the sample.
Figure 3.
LFA strips for different quantities of analyte under laboratory ambient lighting condition.
Figure 3.
LFA strips for different quantities of analyte under laboratory ambient lighting condition.
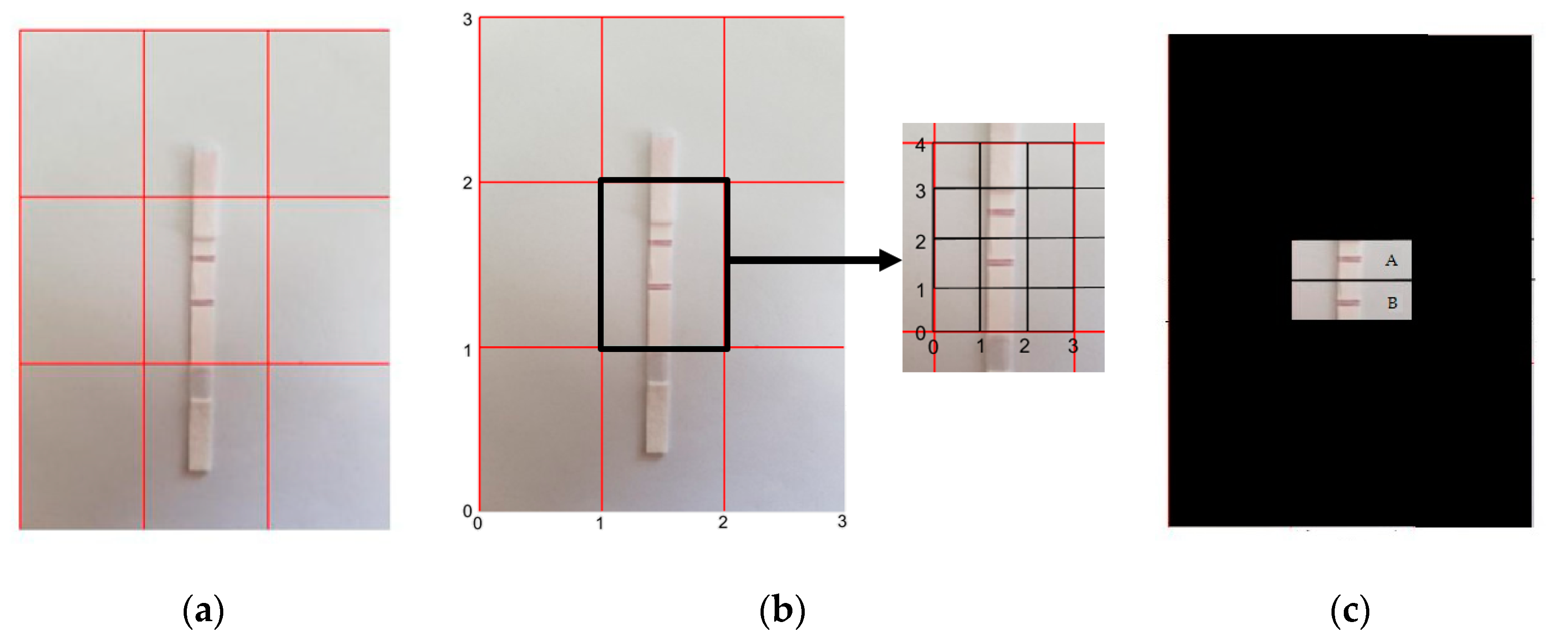
Figure 4.
(a) A 3 × 3 grid of the smartphone camera view with proper positioning of LFA, (b) dimension extraction of regions from the center box ((1, 1), (2, 1), (1, 2), (2, 2)), with the test line and the control line position indexes ((0, 1), (3, 1), (0, 2), (3, 2)) and ((0, 2), (3, 2), (0, 3), (3, 3)), respectively, and (c) the control line and the test line regions (marked as A and B, respectively).
Figure 4.
(a) A 3 × 3 grid of the smartphone camera view with proper positioning of LFA, (b) dimension extraction of regions from the center box ((1, 1), (2, 1), (1, 2), (2, 2)), with the test line and the control line position indexes ((0, 1), (3, 1), (0, 2), (3, 2)) and ((0, 2), (3, 2), (0, 3), (3, 3)), respectively, and (c) the control line and the test line regions (marked as A and B, respectively).
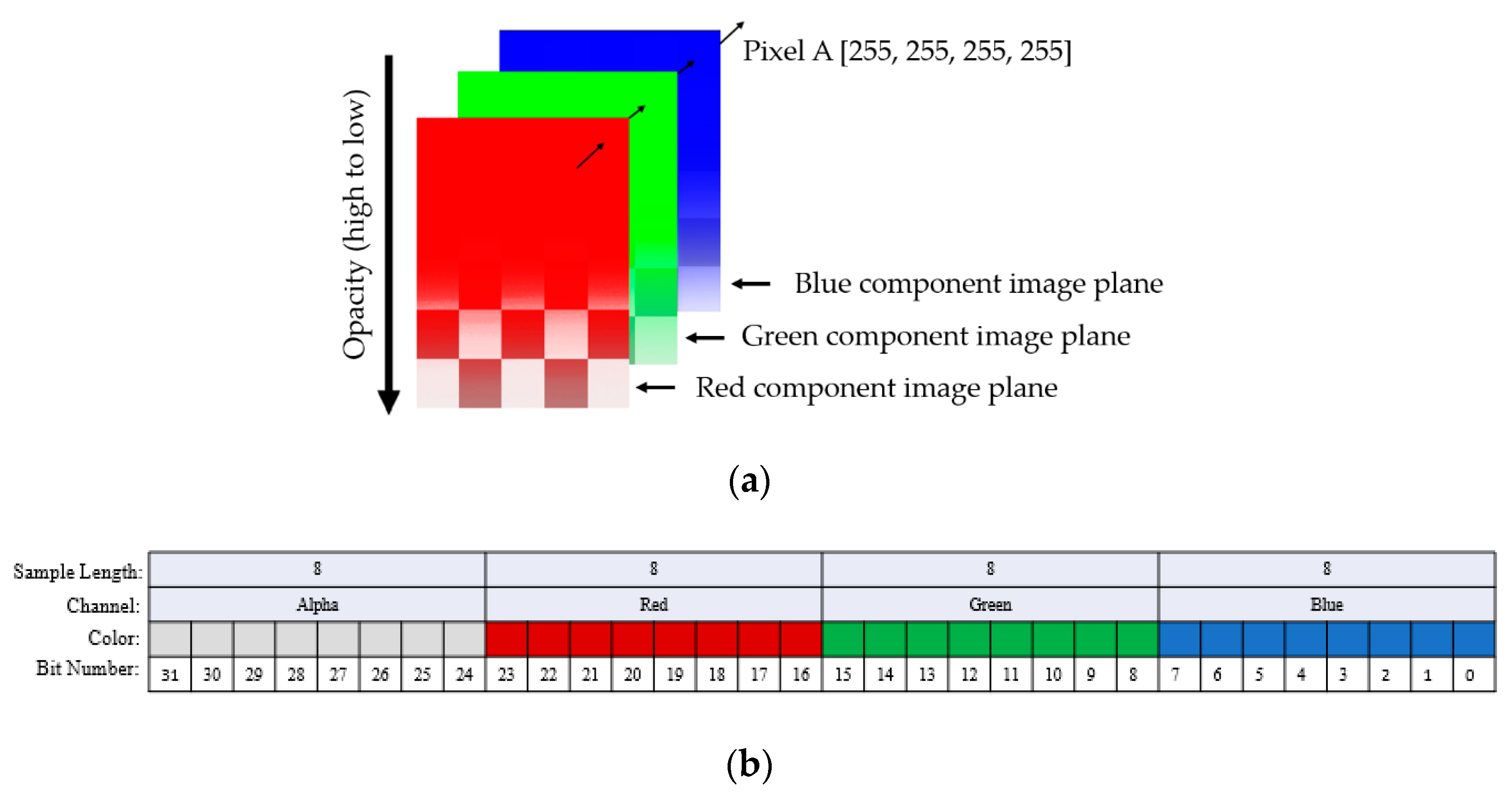
Figure 5.
Representation of an image obtained using a Samsung Galaxy S7 smartphone. (a) Alpha-Red-Green-Blue (ARGB) representation of an image. An ARGB image consists of four planes, which are the alpha, red, green, and blue channels. Each channel’s intensity value can vary from 0 to 255. A pixel in the original image shows the combination of the intensity values of the color channels, and (b) the 32-bit representation of a pixel of the image (a). In an ARGB image, each pixel corresponds to a specific 32-bit binary value, of which the lowest eight bits represent blue, the next 8 bits represent green, the next eight bits for red, and the highest eight bits represent the alpha channel intensity values. The pixel’s color is the combination of these color intensities.
Figure 5.
Representation of an image obtained using a Samsung Galaxy S7 smartphone. (a) Alpha-Red-Green-Blue (ARGB) representation of an image. An ARGB image consists of four planes, which are the alpha, red, green, and blue channels. Each channel’s intensity value can vary from 0 to 255. A pixel in the original image shows the combination of the intensity values of the color channels, and (b) the 32-bit representation of a pixel of the image (a). In an ARGB image, each pixel corresponds to a specific 32-bit binary value, of which the lowest eight bits represent blue, the next 8 bits represent green, the next eight bits for red, and the highest eight bits represent the alpha channel intensity values. The pixel’s color is the combination of these color intensities.
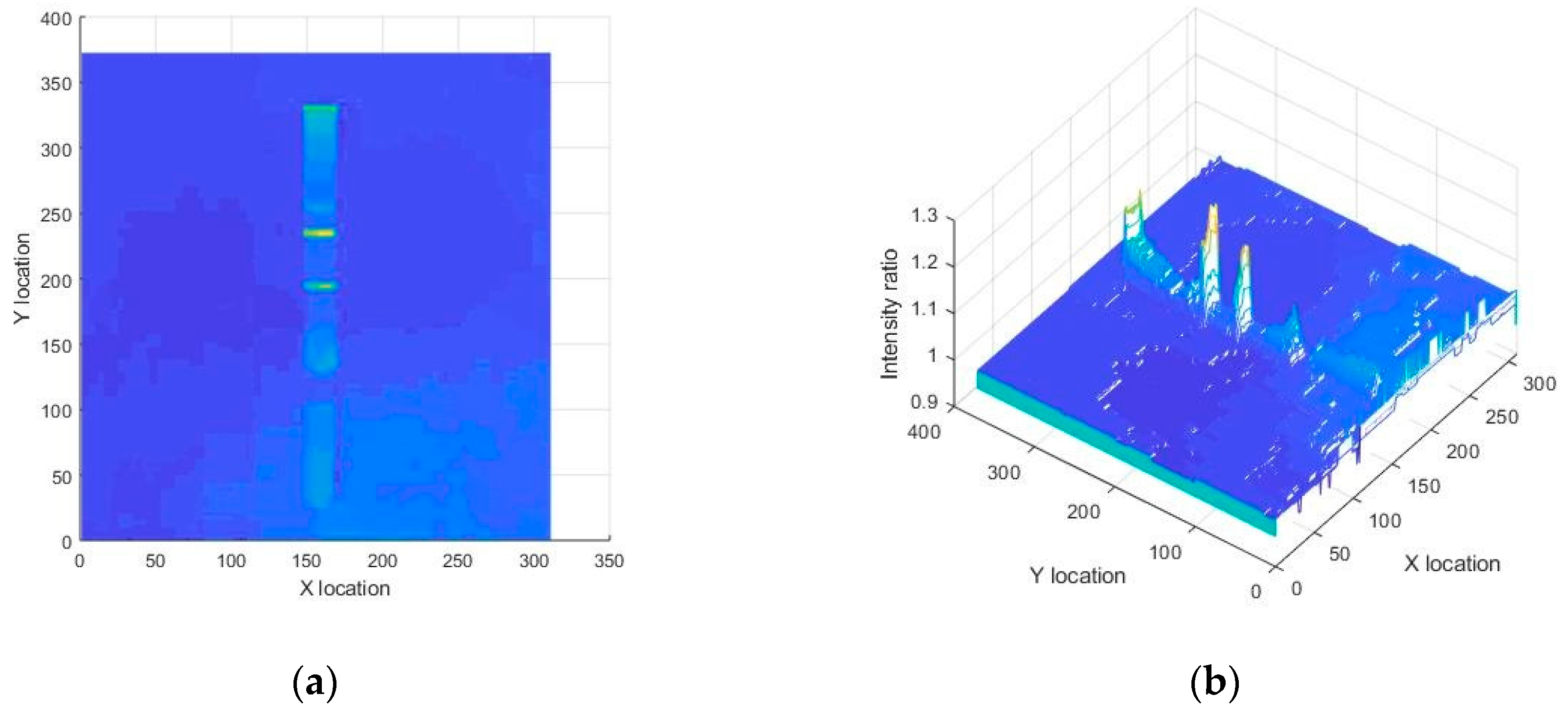
Figure 6.
Ratio of red channel to green channel of a sample LFA strip is visualized by (a) a 2D surface, and (b) a 3D surface. It is clear that the test and control lines had the maximum value that can be used to differentiate them from other regions.
Figure 6.
Ratio of red channel to green channel of a sample LFA strip is visualized by (a) a 2D surface, and (b) a 3D surface. It is clear that the test and control lines had the maximum value that can be used to differentiate them from other regions.
Figure 7.
(a) Visualization of two pixels in a sample LFA strip image with red, green, and blue channel intensity values. Pixel A is in the test line region and pixel B is in the non-ROI region, (b) the calculated mask where the red to green intensity ratio was greater than the threshold THmask, and (c) the extracted control line and test line regions are shown.
Figure 7.
(a) Visualization of two pixels in a sample LFA strip image with red, green, and blue channel intensity values. Pixel A is in the test line region and pixel B is in the non-ROI region, (b) the calculated mask where the red to green intensity ratio was greater than the threshold THmask, and (c) the extracted control line and test line regions are shown.
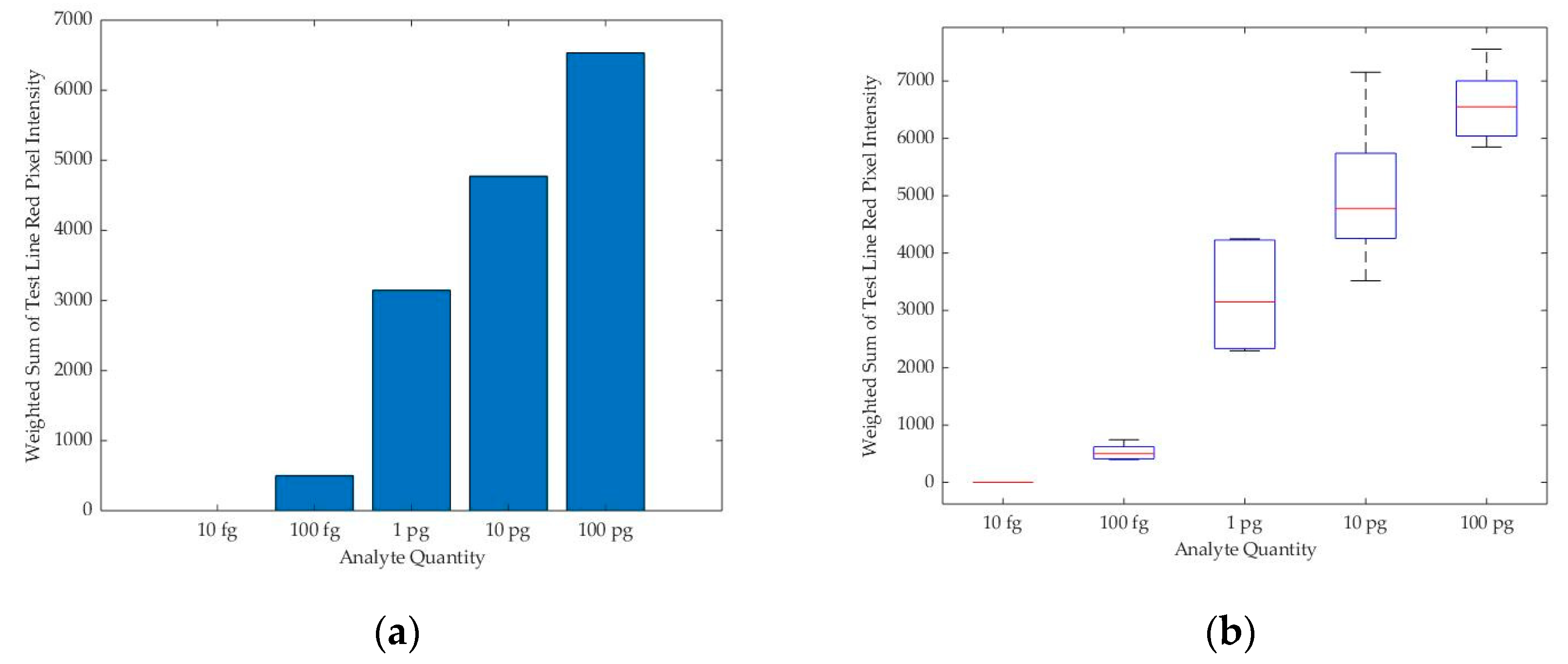
Figure 8.
(a) Bar chart for the median of the readings for the weighted sum of the test line red pixels’ intensity values against the quantity of analyte present in the sample in a specific lighting condition; (b) the boxplot for multiple readings for each analyte quantity.
Figure 8.
(a) Bar chart for the median of the readings for the weighted sum of the test line red pixels’ intensity values against the quantity of analyte present in the sample in a specific lighting condition; (b) the boxplot for multiple readings for each analyte quantity.
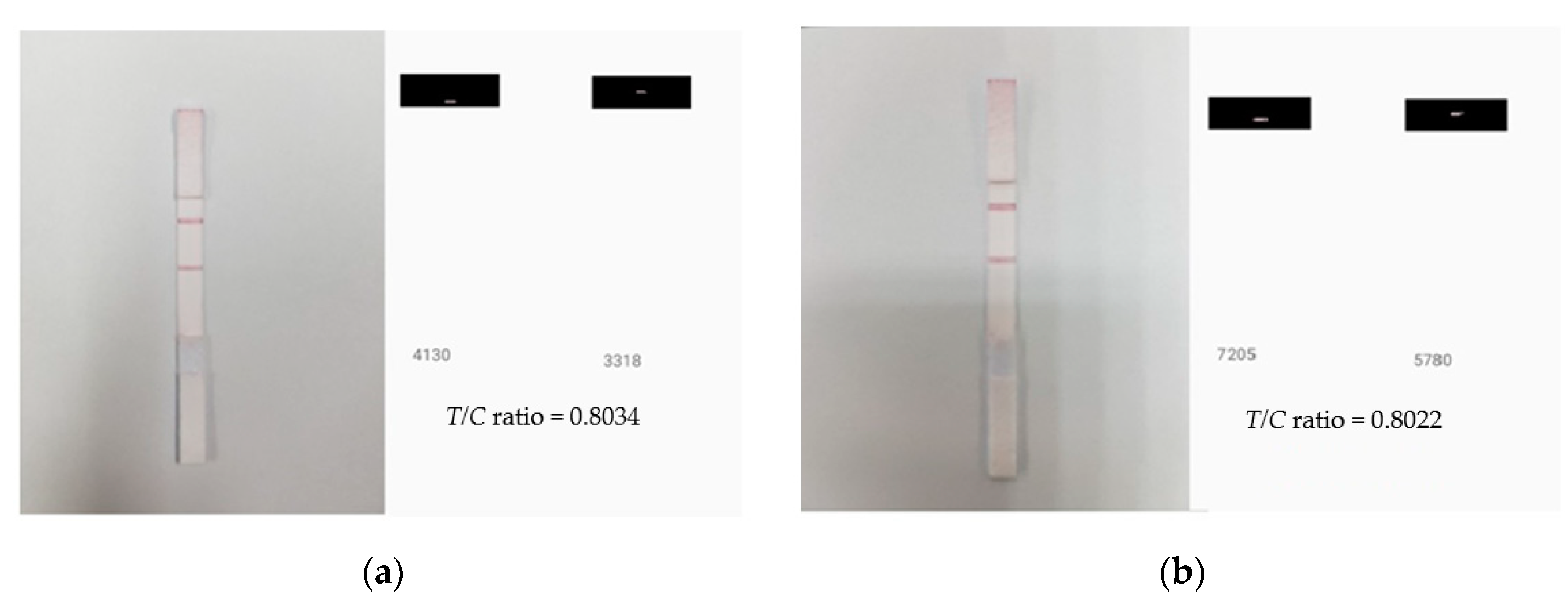
Figure 9.
LFA strip and calculated T/C ratio for two different lighting conditions: (a) 36-Watt LED ceiling lamp and (b) 27-Watt LED table lamp illuminated environments, showing a similar T/C ratio.
Figure 9.
LFA strip and calculated T/C ratio for two different lighting conditions: (a) 36-Watt LED ceiling lamp and (b) 27-Watt LED table lamp illuminated environments, showing a similar T/C ratio.
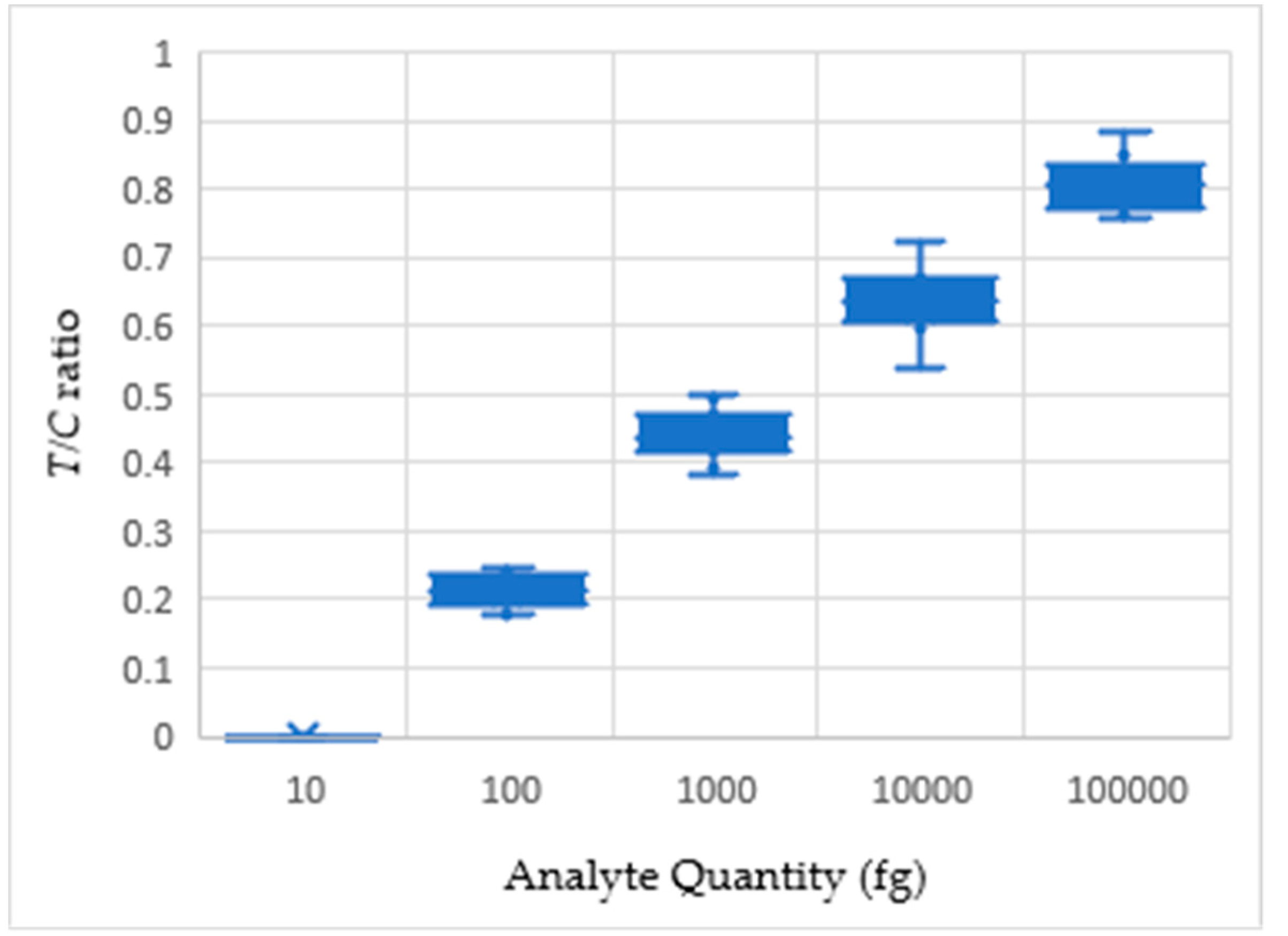
Figure 10.
Analyte quantity against T/C ratio plot for three different LFA sets.
Figure 10.
Analyte quantity against T/C ratio plot for three different LFA sets.
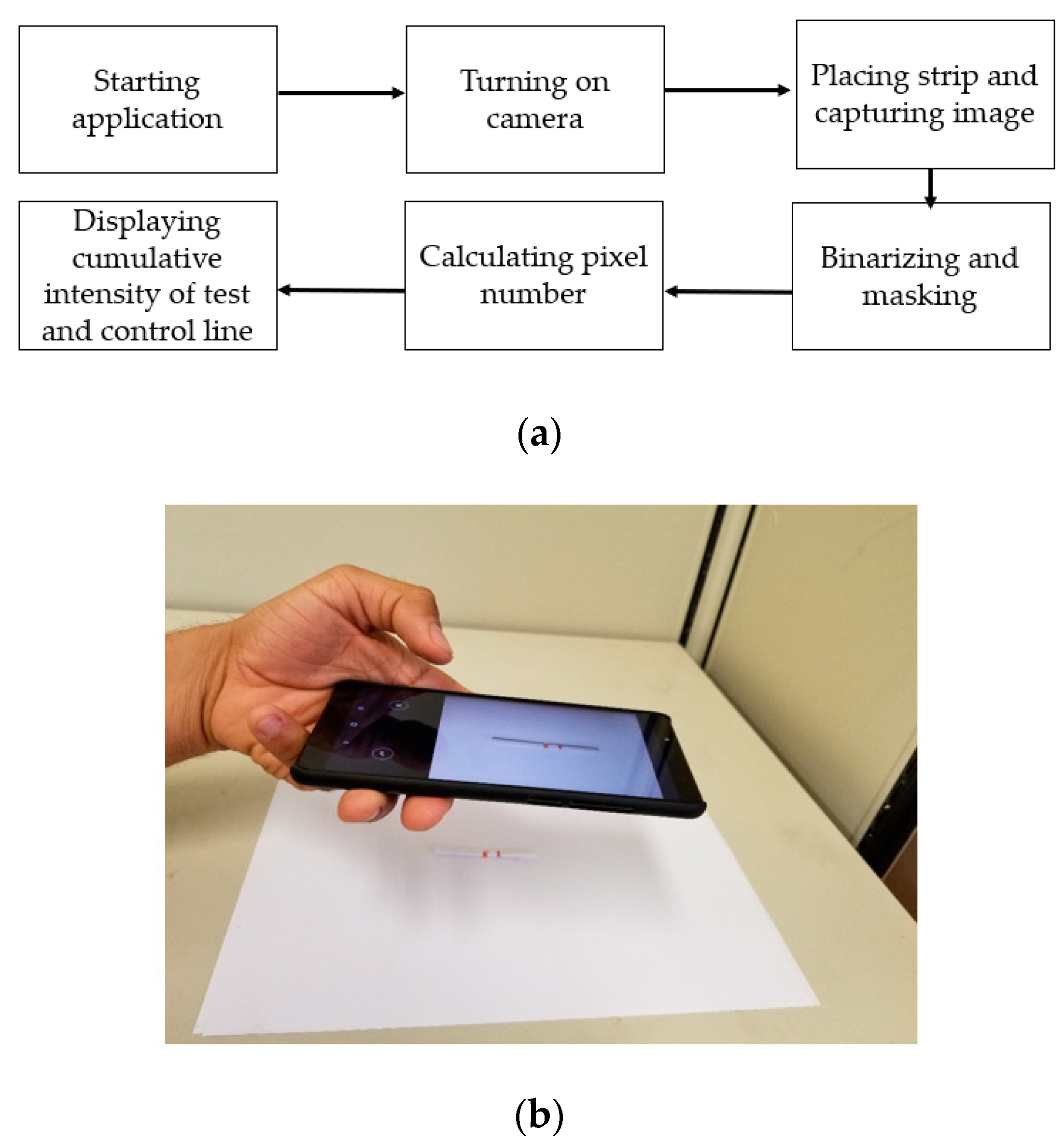
Figure 11.
(a) The flowchart describing the subsequent operations of our developed application; (b) the data acquisition procedure with accurate placement using our developed application.
Figure 11.
(a) The flowchart describing the subsequent operations of our developed application; (b) the data acquisition procedure with accurate placement using our developed application.
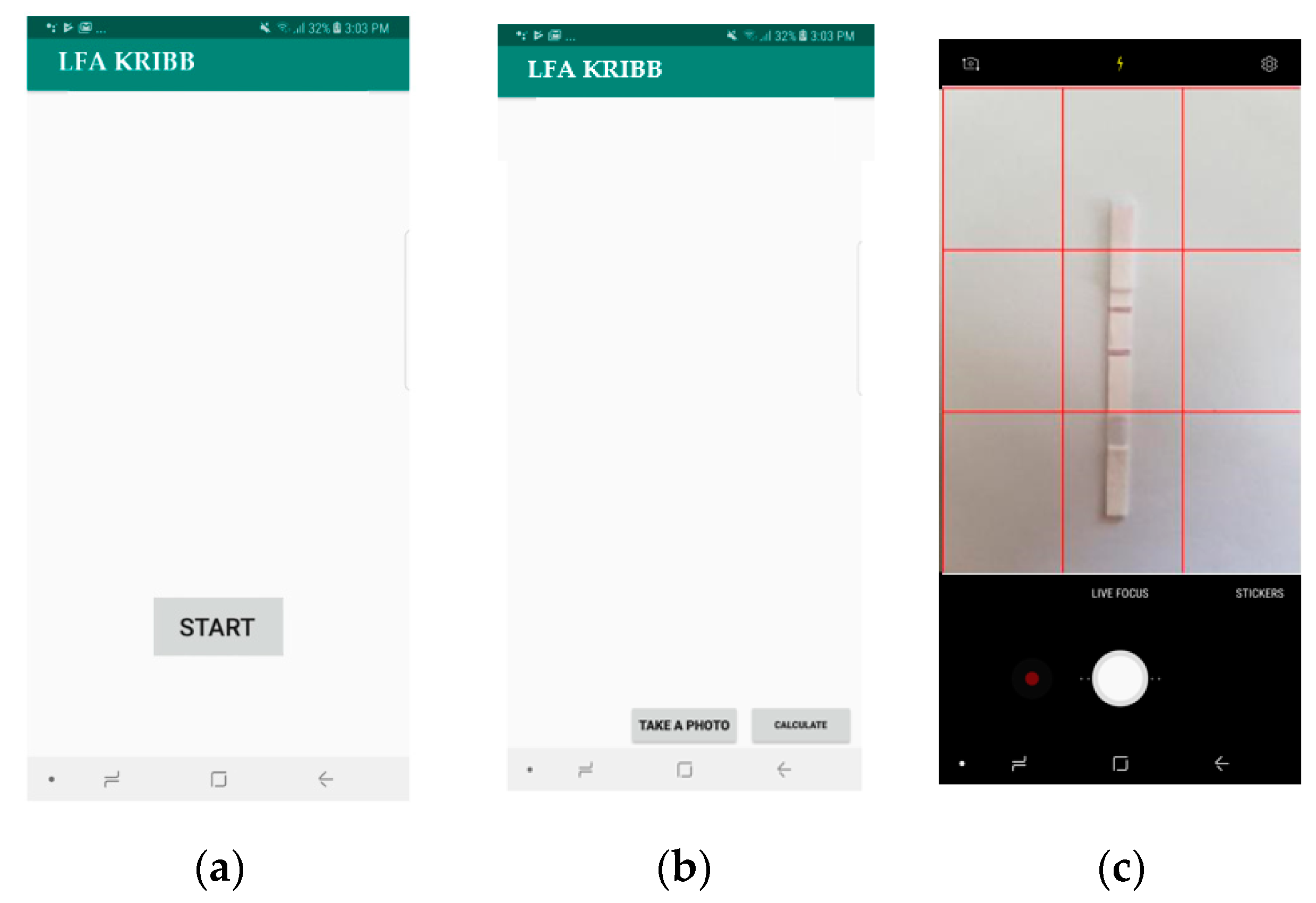
Figure 12.
Proposed application for the detection of an analyte in an LFA strip: (a) home screen, (b) second screen with an image capture option, (c) camera view with a 3 × 3 grid spacing, (d) captured raw image, (e) processed image using the created mask (total pixel number shown at the bottom of the image), and (f) calculated control (left) and test (right) line weighted sum of pixels’ intensity values.
Figure 12.
Proposed application for the detection of an analyte in an LFA strip: (a) home screen, (b) second screen with an image capture option, (c) camera view with a 3 × 3 grid spacing, (d) captured raw image, (e) processed image using the created mask (total pixel number shown at the bottom of the image), and (f) calculated control (left) and test (right) line weighted sum of pixels’ intensity values.
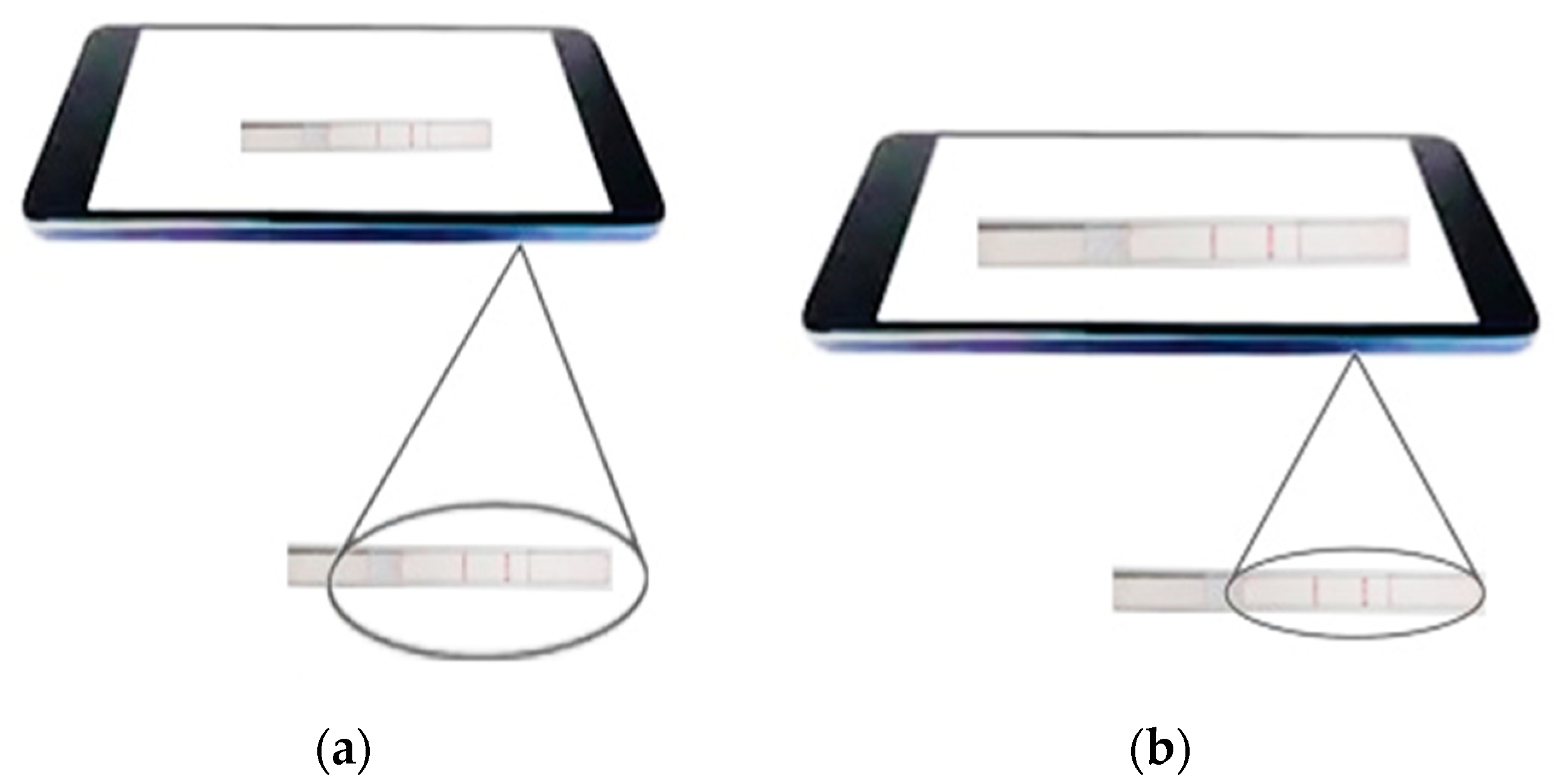
Figure 13.
(a) Exact placement of the LFA strip under a smartphone camera and (b) an improper placement of the LFA strip—a larger field of view due to the proximity of the camera to the LFA strip.
Figure 13.
(a) Exact placement of the LFA strip under a smartphone camera and (b) an improper placement of the LFA strip—a larger field of view due to the proximity of the camera to the LFA strip.
Figure 14.
(a) Android smartphone (Samsung Galaxy) camera view with a 3 × 3 grid positioning and (b) LFA strip ROI positioned in the center box.
Figure 14.
(a) Android smartphone (Samsung Galaxy) camera view with a 3 × 3 grid positioning and (b) LFA strip ROI positioned in the center box.
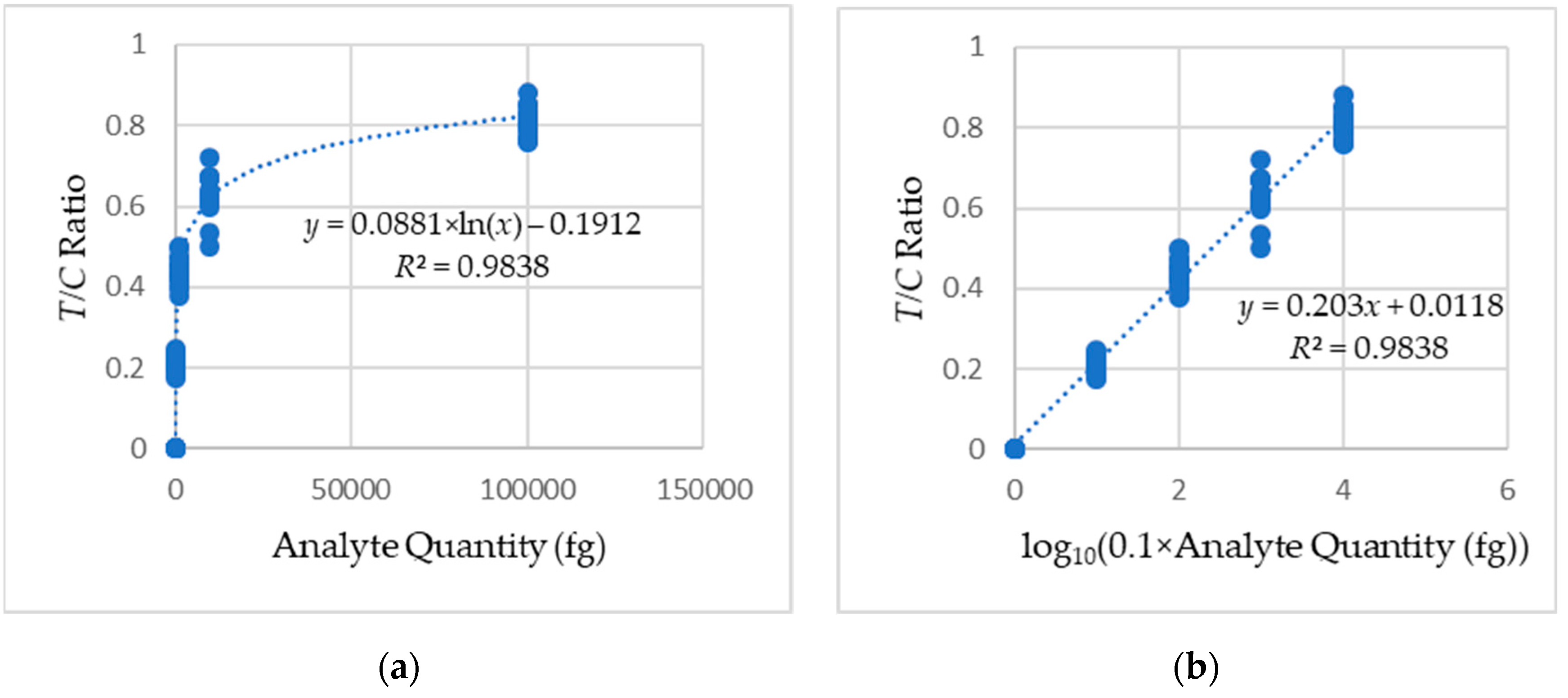
Figure 15.
Calibration curves obtained from the regression analysis of the LFA sets: (a) logarithmic and (b) linear.
Figure 15.
Calibration curves obtained from the regression analysis of the LFA sets: (a) logarithmic and (b) linear.
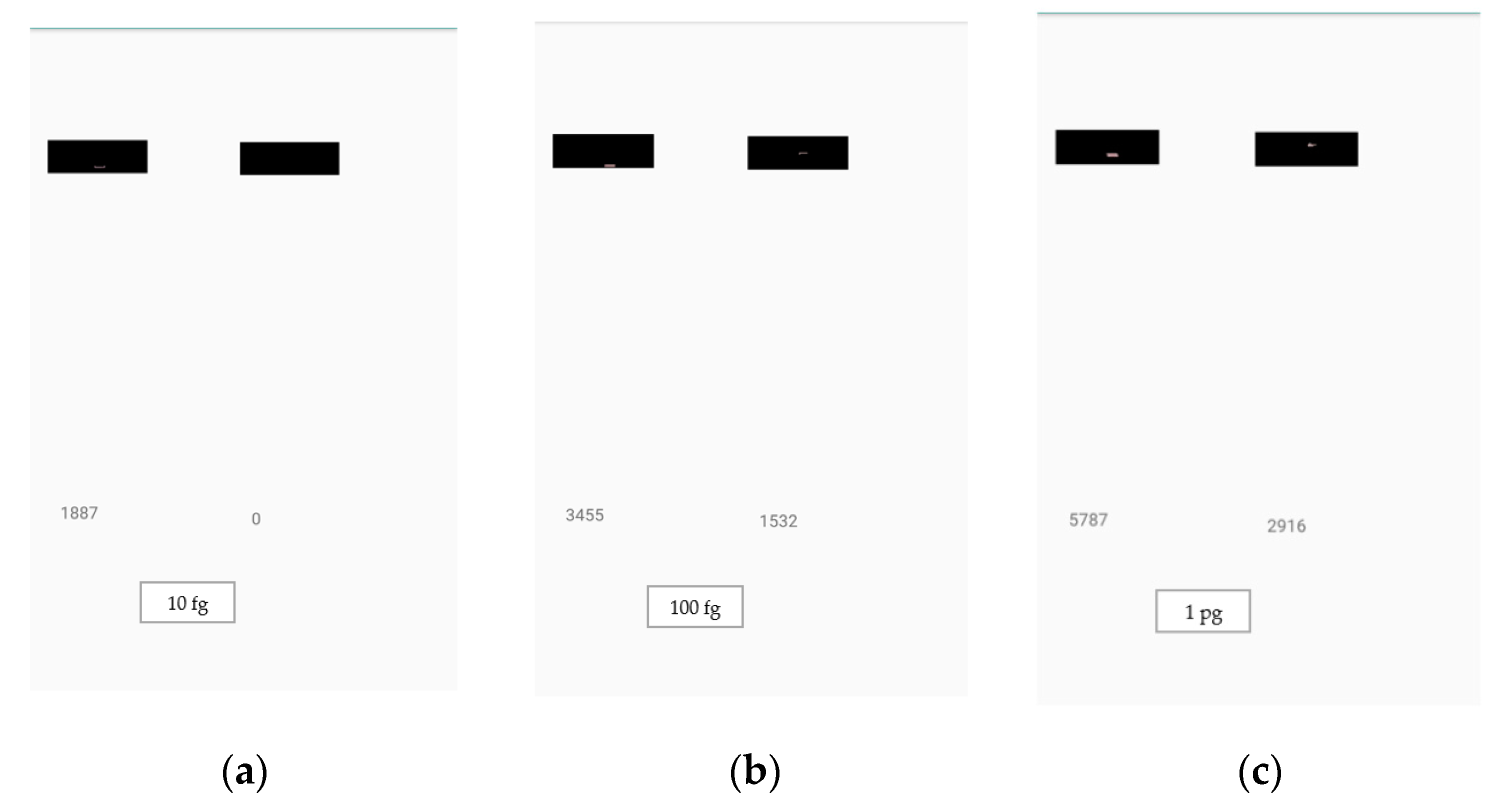
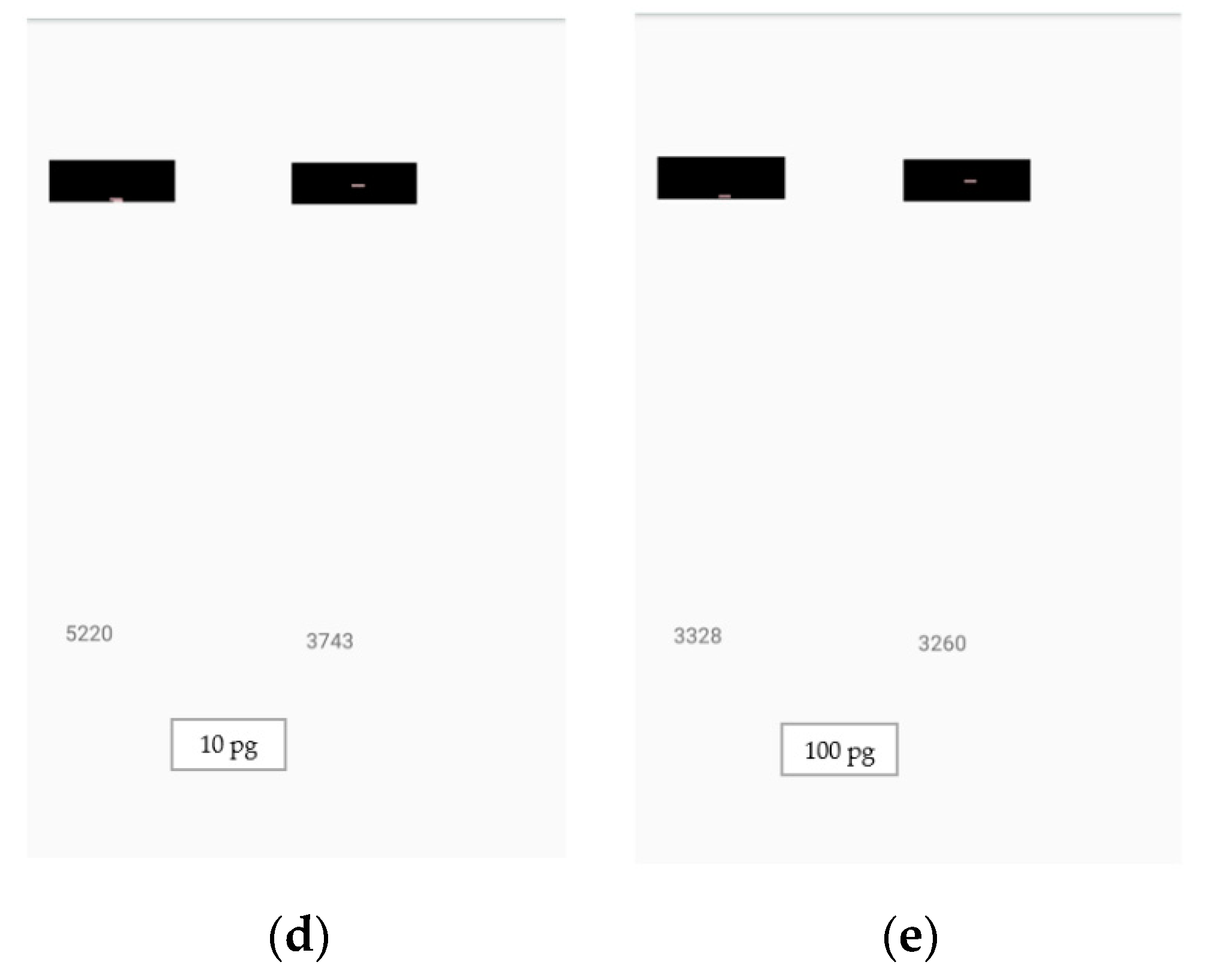
Figure 16.
Estimation of analyte quantity: (a) 10 fg, (b) 100 fg, (c) 1 pg, (d) 10 pg, and (e) 100 pg, using the developed application. The smartphone application was used for the detection of analyte quantities under various lighting conditions. The number on the left is the control line weighted sum of red pixels’ intensities, the number on the right is the test line weighted sum of red pixels’ intensities, and the analyte quantity is displayed at the bottom of the screen.
Figure 16.
Estimation of analyte quantity: (a) 10 fg, (b) 100 fg, (c) 1 pg, (d) 10 pg, and (e) 100 pg, using the developed application. The smartphone application was used for the detection of analyte quantities under various lighting conditions. The number on the left is the control line weighted sum of red pixels’ intensities, the number on the right is the test line weighted sum of red pixels’ intensities, and the analyte quantity is displayed at the bottom of the screen.
Table 1.
Calculated T/C ratio for LFA set #1.
Table 1.
Calculated T/C ratio for LFA set #1.
| Test Class | Reading 1 | Reading 2 | Reading 3 | Reading 4 | Reading 5 |
|---|
| 100 pg | 0.764 | 0.782 | 0.772 | 0.758 | 0.762 |
| 10 pg | 0.672 | 0.618 | 0.502 | 0.536 | 0.596 |
| 1 pg | 0.434 | 0.404 | 0.394 | 0.452 | 0.380 |
| 100 fg | 0.21 | 0.234 | 0.20 | 0.18 | 0.194 |
| 10 fg | 0 | 0 | 0 | 0 | 0 |
Table 2.
Calculated T/C ratio for LFA set #2.
Table 2.
Calculated T/C ratio for LFA set #2.
| Test Class | Reading 1 | Reading 2 | Reading 3 | Reading 4 | Reading 5 |
|---|
| 100 pg | 0.806 | 0.807 | 0.82 | 0.85 | 0.836 |
| 10 pg | 0.634 | 0.622 | 0.674 | 0.67 | 0.668 |
| 1 pg | 0.456 | 0.456 | 0.438 | 0.472 | 0.426 |
| 100 fg | 0.246 | 0.242 | 0.212 | 0.226 | 0.176 |
| 10 fg | 0 | 0 | 0 | 0 | 0 |
Table 3.
Calculated T/C ratio for LFA set #3.
Table 3.
Calculated T/C ratio for LFA set #3.
| Test Class | Reading 1 | Reading 2 | Reading 3 | Reading 4 | Reading 5 |
|---|
| 100 pg | 0.796 | 0.828 | 0.882 | 0.64 | 0.798 |
| 10 pg | 0.634 | 0.61 | 0.608 | 0.722 | 0.64 |
| 1 pg | 0.426 | 0.5 | 0.496 | 0.416 | 0.476 |
| 100 fg | 0.238 | 0.204 | 0.208 | 0.194 | 0.22 |
| 10 fg | 0 | 0 | 0 | 0 | 0 |
Table 4.
Mean, std. deviation and coefficient of variation of test to control line signal intensity (T/C) ratios for each of the analyte quantities of the LFA sets.
Table 4.
Mean, std. deviation and coefficient of variation of test to control line signal intensity (T/C) ratios for each of the analyte quantities of the LFA sets.
| Analyte Quantity | Mean T/C Ratio | Std. Deviation of T/C Ratio | CV (%) |
|---|
| 100 pg | 0.791502 | 0.055011 | 6.950253 |
| 10 pg | 0.624684 | 0.055213 | 8.838581 |
| 1 pg | 0.440393 | 0.035544 | 8.070897 |
| 100 fg | 0.211211 | 0.021829 | 10.33506 |
| 10 fg | 0 | 0 | 0 |
Table 5.
Confusion matrix for the training sets obtained by the linear support vector machine (SVM) model. The asterisk sign (*) denotes the misclassified analyte quantity for the training LFA sets.
Table 5.
Confusion matrix for the training sets obtained by the linear support vector machine (SVM) model. The asterisk sign (*) denotes the misclassified analyte quantity for the training LFA sets.
| | Predicted Class |
|---|
| Actual Class | 100 pg | 10 pg | 1 pg | 100 fg | 10 fg |
|---|
| 100 pg | 10 | 0 | 0 | 0 | 0 |
| 10 pg | 1 * | 9 | 0 | 0 | 0 |
| 1 pg | 0 | 0 | 10 | 0 | 0 |
| 100 fg | 0 | 0 | 0 | 10 | 0 |
| 10 fg | 0 | 0 | 0 | 0 | 10 |
Table 6.
Confusion matrix for testing the method with the SVM. The asterisk sign (*) denotes the misclassified analyte quantity for the test LFA set.
Table 6.
Confusion matrix for testing the method with the SVM. The asterisk sign (*) denotes the misclassified analyte quantity for the test LFA set.
| | Predicted Class |
|---|
| Actual Class | 100 pg | 10 pg | 1 pg | 100 fg | 10 fg |
|---|
| 100 pg | 10 | 0 | 0 | 0 | 0 |
| 10 pg | 1 * | 9 | 0 | 0 | 0 |
| 1 pg | 0 | 0 | 10 | 0 | 0 |
| 100 fg | 0 | 0 | 0 | 10 | 0 |
| 10 fg | 0 | 0 | 0 | 0 | 10 |
Table 7.
Performance comparison between ImageJ software and our proposed method.
Table 7.
Performance comparison between ImageJ software and our proposed method.
| | Proposed Method | ImageJ Method |
|---|
| LOD | 0.000026 nM (1.71 pg/mL) | 0.000077 nM (5.12 pg/mL) |
| LOQ | 0.00039 nM (26.48 pg/mL) | 0.31158 nM (20,720.4 pg/mL) |
Table 8.
Method comparison between existing methods and the proposed method.
Table 8.
Method comparison between existing methods and the proposed method.
| | Ruppert et al. [45], Roda et al. [48], Balaji et al. [23] | Mokkapati et al. [49], RDS 2500 LFA Reader, Detekt Biomedical LLC. [25] | Preechaburana et al. [50] | Proposed Method |
|---|
| Uses smartphone | Yes | No | Yes | Yes |
| Requires external device | Yes | N/A | No | No |
| Works in varying lighting conditions | N/A | N/A | No | Yes |
| Approximates analyte quantity | Yes | Yes | Yes | Yes |
| Predicts based on machine learning | No | No | No | Yes |






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}