Abstract
The assessment of transformations in the retinal vascular structure has a strong potential in indicating a wide range of underlying ocular pathologies. Correctly identifying the retinal vessel map is a crucial step in disease identification, severity progression assessment, and appropriate treatment. Marking the vessels manually by a human expert is a tedious and time-consuming task, thereby reinforcing the need for automated algorithms capable of quick segmentation of retinal features and any possible anomalies. Techniques based on unsupervised learning methods utilize vessel morphology to classify vessel pixels. This study proposes a directional multi-scale line detector technique for the segmentation of retinal vessels with the prime focus on the tiny vessels that are most difficult to segment out. Constructing a directional line-detector, and using it on images having only the features oriented along the detector’s direction, significantly improves the detection accuracy of the algorithm. The finishing step involves a binarization operation, which is again directional in nature, helps in achieving further performance improvements in terms of key performance indicators. The proposed method is observed to obtain a sensitivity of 0.8043, 0.8011, and 0.7974 for the Digital Retinal Images for Vessel Extraction (DRIVE), STructured Analysis of the Retina (STARE), and Child Heart And health Study in England (CHASE_DB1) datasets, respectively. These results, along with other performance enhancements demonstrated by the conducted experimental evaluation, establish the validity and applicability of directional multi-scale line detectors as a competitive framework for retinal image segmentation.
1. Introduction
Retinal fundus images provide a key insight into the various entities within the human retina. Any abnormal changes in these features point towards the type and seriousness of numerous eye diseases such as Diabetic Retinopathy (DR) and Diabetic Maculopathy (DM), both of which are main contributors towards global blindness. These diseases stealthily manifest themselves, and are usually not diagnosed until they have progressed to more advanced stages where their treatment becomes both costly and ineffective. One of the dominating feature in fundus images is the vessel tree structure, referred to as vasculature. Therefore, accurate detection of vaculature is the primary step as its detection acts as a reliable biomarker towards classification of both the retinal features and any associated pathologies [1].
Recent advancements in medical imaging technology have guided the scientists in the image processing community to focus on analyzing these medical images so as to mimic the diagnostic process of a medical professional. The computerized analysis of bio-medical images has found numerous uses in different medicinal applications ranging from diagnosis, progression monitoring, and treatment. Every passing day sees advances in digital image processing with expansion in both efficiency and the precision of such methods [2]. The data in bio-medical images is generally unbalanced (disease appears in small percentage of dataset) [3,4], unstable (variations in surface response due to uneven illumination) [5], and characterized by a high degree of complexity [3]. In this kind of a scenario, automated extraction of bio-markers in medical images exhibits great potential towards exploiting big data analytics in improving medical practice, and synchronization of diagnosis and prognosis conventions.
A broken bone, for example, is visible through an X-Ray, so researchers have aimed at developing an adaptive threshold that can detect the abnormality intelligently without any human supervision. Detecting retinal features and any associated pathologies is a bit more subtle than X-Rays. Over time, numerous highly sophisticated adaptive filtering techniques have surfaced that can almost match the human expert in the detection of these anomalies. The knowledge gap is still vast in terms of both detection and validation of these complex-shaped pathologies that result in numerous eye diseases every year.
Retinal image processing has attracted tremendous research focus over the years with varying degrees of success. Demarcation of the retinal vessel structure by a human expert is both time-consuming and tedious, thereby augmenting the need for automation of this crucial task to enable mass screenings. Pointing out troublesome features in the retina is a difficult task. For most of the other diseases, predefined lesion patterns help determine with conviction the presence or absence of a disease like cancer. However, DR is different as there can be multiple forms of anomalies associated with it, such as Microaneurysms, Exudates, and Neovascularization, etc., as shown in Figure 1. Each of these types is treated as a separate problem for detection and overall diagnosis. Then, the results from the integration of their outputs constitute the pathology detections in the image.
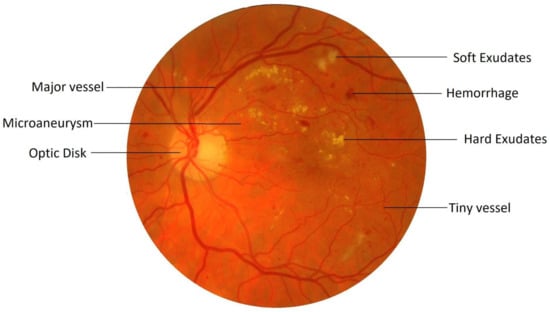
Figure 1.
A retinal fundus image with features of interest.
Automated vessel mapping of the retina is hindered by many factors, such as variations in the shapes, sizes, and direction of the dense vascular network present within the retina. Also, the enhancement of these blood vessels alongside the suppression of background information, plays an important role in increasing the accuracy of such a vessel mapping regimen. During the process of segmentation, all the existing morphological detectors tend to act poorly on vessels of varying sizes. The segmentation process becomes increasingly prone to error, particularly during the binarization phase, due to the changing orientation of vessels and poor contrast among them. Line detectors are one similar form of morphological detectors which have been employed for vessel detection in retinal images.
A basic or fixed-length line detector is based on establishing a correlation with the vessel geometry. A preset line segment is laid over a set of pixels, and a high matched response suggests the presence of a linear structure, or in this case, a vessel. Although line detectors are very efficient at detecting the presence of vessels, they fail to achieve an accurate segmentation due to the choice of length of the line detector. Detectors of smaller lengths or scales tend to produce shadows around vessel regions, and filters of larger length generate fake extensions at vessel endpoints. As there was a strict trade-off between these, this led to the evolution of multi-scale line detectors, which combines the responses of different scales while countering their adverse effects.
A multi-scale line detector identifies vascular structures in an image by iteratively rotating the detector at a pixel to capture the vessels at different angles at that point. With the rotation along some predefined angles, another critical parameter is the choice of detector’s variation in scale, which hunts for corresponding features of comparable lengths. However, this method of using multi-scale detectors had its own set of problems. This detector operates in all directions, and the efficacy of feature extraction in any specific direction is co-variant with the contrast of those features. While scanning multiple angles for the presence of vessels, the vessel features with high contrast dominate those with lower contrast. This results in the highlighting of certain vessel pixels and suppression of others to the extent that, tiny vessels, particularly at the endpoints of the vascular map, are usually the most affected. The tiny vessels are not the only victims to this problem, as the reconstruction of edges of the larger vessels are also affected during the combined binarization process.
To tackle these problems, we propose a three-pronged strategy with a new directional multi-scale line detector that, instead of scanning multiple angles within the whole image, focuses on a fixed direction while scanning a narrow angular range. Such a direction-specific filter will still be burdened by an image having multi-orientation features, thereby causing a loss in the sensitivity indicator. The second prong of this strategy lies in the use of directional images instead of the original image, having only those features or vessels which fall in line with the direction of the angular detector. This strategy is adopted with the expectation that, an image having only directional information will help boost the performance of the angle-specific detector while significantly reducing the false-positives.
Towards the end, a novel binarization technique based on the standard deviation of the directional line filter is used to eliminate the false extensions introduced by the larger-scale line filters. All the resultant features evolved from different directions, are recombined to yield the overall retinal vessel map. Therefore, directional segmentation and binarization of target features produces significantly improved results, as the detector becomes more immune to the omni-directional present in the input image. The proposed method is also notably faster as sensitivity, specificity, and accuracy of the vessel segmentation are enhanced without the use of any denoiser or advanced thresholding techniques such as region growing or overlaying.
The remaining portion of this paper is organized as follows: Section 2 summarizes the related work followed by Section 3, describing each step of the proposed technique in detail. Section 4 contains the experimental results elaborating the tested retinal image databases, algorithm’s performance judging criteria, and comparison with state-of-the-art techniques. Section 5 concludes the paper by discussing the key findings of this study, followed by recommendations for potential future research work.
2. Literature Review
Pointing out the features and troublesome lesions in the retina is a challenging task. Many research groups around the globe have been studying techniques to help determine these retinal features, and to maximize progress and collaboration, it has been turned into international competitions such as the STructured Analysis of the Retina (STARE) [6] and Digital Retinal Images for Vessel Extraction (DRIVE) [7] databases, etc. Many algorithms have surfaced that although not being applied in clinical practice yet, have provided unique insights into the solution of the problem at hand. A usual concern with any automated system is the accuracy and precision of the data it learns from. So, retinal images with all their differences in vessel size, contrast, presence of pathologies, and noisy vessel boundary problems make vascular segmentation an increasingly daunting task.
The vessel detection approaches using image processing, are categorized as either supervised or unsupervised learning techniques. Supervised methods identify the vessel pixels based on machine learning algorithms that use expert-marked ground truth samples to train a classifier. Unsupervised methods are the more popular choice, as they require no such pre-labeled training data and patterns of blood vessels hard-coded into the algorithm’s structure to obtain accurate segmentation.
2.1. Supervised Learning Methods
These techniques require a set of training data and relevant feature extraction followed by classification for vessel segmentation. First of all, constraints such as a viable training set (manually labeled into foreground and background), and the number of training data sets available, dictate the efficiency of the classification. Secondly, a feature index is created that helps differentiate between the vessel and non-vessel pixels which are later utilized by the classifier for the overall segmentation of vessels. The requirement of training data, large feature index and considerable classifier training time are the main drawbacks of supervised methods. On the other hand, ample training data coupled with a powerful classifier can lead to a significantly accurate segmentation of blood vessels.
Niemeijer et al. [8] used a multi-scale Gaussian feature vector followed by a K-Nearest-Neighbors (KNN) classifier for supervised vessel segmentation. Staal et al. [7] built a feature set evolved from 27 different attributes using the abstraction of image ridges, and fed them to a KNN classifier for calculating the probability of a pixel being a vessel entity. Ricci and Perfetti [9] used two orthogonal line operators and SVM on the green channel of retinal images to improve the accuracy and Area Under the Curve (AUC) parameters of their method. They reduced the false-positives and false-negatives by assignment of different weights to the errors of both categories, respectively. Marin et al. [10] utilized a grey-level and moment invariants-based feature set to train a multi-layer Neural Network (NN) to differentiate between the vessel and non-vessel pixels. You et al. [11] constructed a Support Vector Machine (SVM) and a feature vector by using radial projections from large and tiny vessels separately to recognize the retinal vasculature.
Fraz et al. [12] used an ensemble classification-based technique relying on orientation and morphological analysis of vessels. A multi-scale Gabor filter helped extract these features and a decision tree classifier was used in this approach, but it failed to report any objective quality measures. Franklin et al. [13] used all three-color planes of a fundus image to extract vessel features, eventually classifying through a multi-layer perceptron NN. Li et al. [14] proposed a cross modality learning approach without involving any preprocessing steps to induce robustness towards the training set. Their method was tested on DRIVE, STARE and CHASE_DB1 datasets with excellent results for both normal and pathological retinal fundus images.
Orlando et al. [15] used fully connected conditional random field method that worked with a structured SVM to achieve a high specificity score of 0.9870. They randomized the training process by taking random sample of pixels from different sets of images from the STARE dataset for efficient elongated structure segmentation through a machine learning approach. Dasgupta and Singh [16] also employed a FCCN to segment the vessels as a multi-label inference task. They used CLAHE during the preprocessing stage followed by 7 CNN layers on only the DRIVE dataset, to achieve remarkable sensitivity and accuracy scores of 0.9691 and 0.9533, respectively.
Alom et al. [17] used a Recurrent Residual Convolutional Neural Network (RRCNN) to take advantage of both residual and recurrent CNN for training deep architectures and better feature representation, respectively. They tested their technique on a wide variety of bio medical images including retinal fundus images with the same degree of efficiency. Oliveira et al. [18] used multi-scale Fully Convolutional Neural Networks (FCNN) that employ varying angles and branching patterns of vessels as the basis for data augmentation and prognosis. The Stationary Wavelet Transform explores the vessel rotation information to give the multi-scale tortuosity features that help the learning phase during training to refine the vascular map.
Li et al. [19] constructed a new DR dataset known as DDR, in which they compiled 13,673 retinal images from a wide variety of fundus imaging devices and hospitals across China. Many recent deep learning models were tested on this dataset to evaluate their efficacy in vessel and small lesion recognition. Li et al. [20] employed a connection sensitive loss model along with a attention gate NN to improve the accuracy of vessel detection. Segmenting thin vessels and boundaries was made more efficient by concatenating attention weights to features as this method reported an accuracy of 0.9563 and 0.9673 for the DRIVE and STARE datasets, respectively.
Jiang et al. [21] used extensive pre-processing and denoising for image cleanup, followed by a combined dilated convolution technique for data augmentation. A Deep Convolutional Neural Network (DCNN) was constructed with the use of skip layer connection during decoding, which helped their method achieve an impressive accuracy score of 0.9709. Guo et al. [22] proposed the use of multi-level features through a multi-scale Deeply Supervised Network (DSN) to achieve high AUC scores on the DRIVE, STARE and CHASE_DB1 datasets. The method used deep supervision by information exchange among higher and lower level layers for better fusion result, leading to effective retinal vessel segmentation and noise suppression.
Considering the disadvantages of supervised learning methods, a set of pre-labeled data, significant training computation times and complex feature vectors reduce the overall system efficiency in a real-world scenario. Also, the features of interest must be manually fed to the classifier as compared to the unsupervised learning methods, where the features are acquired by the algorithm itself. This causes a problem when the classifier is presented with a feature it is not already trained for. Therefore, the system may put that feature in the wrong class, or in this case, label a vessel pixel as non-vessel and vice-versa.
2.2. Unsupervised Learning Methods
These methods try to identify features of interest based on the similarity criteria and intrinsic attributes, without the need for manual intervention. These methods owe their popularity in literature to the independence from training data and faster execution times and therefore, learning is limited or altogether absent. Vessel detection in unsupervised methods is done at individual pixel-level, and the complicated nature of retinal vascular map combined with the presence of noise and pathologies implies that reliable segmentation remains a challenging problem. Unsupervised methods are further categorized into five groups: morphological approaches, matched filtering algorithms, vessel tracking, multi-scale processes, and model-based techniques.
Miri and Mahloojifar [23] presented the use of Fast Discrete Curvelet Transform (FDCT) alongside multidimensional morphological processing for retinal vasculature extraction. Vessel boundary was tediously revised utilizing a layered morphological system, where the wrongly detected boundaries were deleted during this revision process, allowing for efficient reconstruction of small and tiny vessels. Xu et al. [24] used elongation-based morphological shape detectors of retinal vessels by employing a twin attribute system that used geometric morphology alongside connected-tree branching methods, resulting in prominent vessel contrast enhancement.
Moghimirad et al. [25] proposed the detection of midpoints of a vessel through the weighted medialness 2-D functions, resulting in high accuracy figures for vessel radius evaluation in a broad range of noisy and pathological images. Nguyen et al. [26] suggested multiscale line identification, relying upon varying the length of a fundamental line detector to extract a threshold vessel image. A localized thresholding filter was stated by Ravichandran et al. [27] for detection of vessels built on the entropy of that region. Contrast Limited Adaptive Histogram Equalization (CLAHE) followed by Wiener filter was used to denoise the image followed by a 2-D Gabor filter for additional vasculature refinement.
Martínez-Pérez et al. [28] employed Region Growing (RG) technique to populate a scale-space representation of varying contrast via derivatives. The first and second derivative predictors helped cater for the contrast variation in the input image, resulting in superior segmentation results. Sofka et al. [29] segmented retinal vessels by developing a Likelihood Ratio Vesselness (LRV) value to assess the worth of matched filter responses. Kar S and Maity S [30] exhibited superior accuracy figures by using Curvelet function based on Fuzzy C-Means (FCM) architecture to detect blood vessels and the Optic Disc (OD). Amin and Yan [31] presented a robust vessel identification method in the form of sorted log-Gabor wavelets. The high paced wavelets exhibited noticeable immunity against the contrast and phase variations through a calibrated threshold.
Palomera-Pérez et al. [32] suggested a collateral setup which used a single plane (horizontal) and blended plane (horizontal plus vertical) feature markers for the evaluation of information within the retinal images. This parallel setup allowed for faster and effective feature extraction, and RG based vascular segmentation with a high degree of accuracy. Cinsdikici and Aydin [33] designed the combination of matched filtering with ANT colony algorithms to extract the entire vessel map. Some preprocessing followed by length sifting is utilized for vessel and capillary recognition, which became unproductive in cases with pathology.
Zhang et al. [34] used wavelet transform to convert standard images into 3D rotating orientation scores, which were further refined by multi-scale second-order Gaussian derivatives. This method was tested on six different retinal datasets and showed competitive results, especially with difficult cases like vessel crossings. Neto et al. [35] aimed to tackle the central vessel reflex by Gaussian smoothing and top-hat transformation. A curvature analysis followed by adaptive local thresholding resulted in excellent all-round performance parameters on both DRIVE and STARE datasets. Karn et al. [36] constructed a hybrid active contour model based on a Gradient Vector Flow (GVF) framework to focus on tiny blood vessels. A novel preprocessing technique coupled with phase-based binarization helped this method report high accuracy scores and effective vessel segmentation.
Aguirre et al. [37] utilized the removal of the OD and low-pass radius filter in preprocessing before employing a 30-element Gabor filter for vessel segmentation. Morphology-based decision rules and fractional derivatives helped this method achieve competitive performance parameters on the DRIVE database. Sundaram et al. [38] used a hybrid vessel segmentation algorithm based on morphological operators coupled with multi-scale vascular refinement. They used bottom-hat transform alongside fusion of resultant multi-scale images to tackle discontinuities at the boundaries of vessels. This method reported significant improvement in detection results, particularly on the High-Resolution Fundus (HRF) database but under-performed on the DRIVE and CHASE_DB1 databases.
3. Proposed Method
The main goal of this study is to enhance vessel detection by employing an improved version of multi-scale line detector, with emphasis on tiny vessels whose detection causes the most false positives during segmentation. Figure 2 depicts the overall flowchart of the proposed technique. The major building blocks of the proposed methodology are outlined as follows:
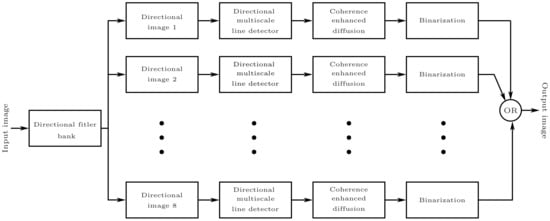
Figure 2.
Block diagram of proposed method.
- Creation of direction-specific image array using bandpass Directional Filter Bank (DFB) on the green channel of a RGB retinal image.
- Employing multi-scale line detection at the orientated image array.
- Using the Coherence-Enhancing Diffusion (CED) technique to enhance the sharpness of the segmented directional vessels.
- Individual binarization of these directional images followed by linear recombination to efficiently threshold the vascular structures.
3.1. Bandpass Directional Filtering for Direction-Specific Vessel Isolation
Orientation-selective linear filters can mirror the localized flow of the direction of lines in a sub-region of interest, such as ridge patterns and retinal vascular networks [39]. Directional Filter Bank (DFB) is a similar kind of structure, which divides an image into corresponding set of orientation-field images. Each subsequent orientation-selective image relates to a discrete set of line segments with a narrow radial range. The frequency response of such an oriented bandpass filter can be further decomposed into its radial () and angular () components by the following equation:
Butterworth filter is selected to evolve as:
where denotes the bandwidth or the angular width. depicts the center frequency, and gave suitable results for the experiment. was set up by a directional kernel suggested by Knutsson et al. [40] as follows:
where is the filter’s desired bandwidth. The span of desirable orientations is set in such a way that , following which , where k represents the decomposed distinct directional images. sets the filter’s orientation such that . The scope of these directional filters is from 0 to as they sum to unity. An example of a directional filter is shown in Figure 3. To deal with the retinal images, radial center frequency is set to a pixel width of 30, with a bandwidth of 60 pixels for vessel segmentation. In other words, a span of is the preset angular width iteration with center frequencies placed in the middle of these bandwidths at , and so on.
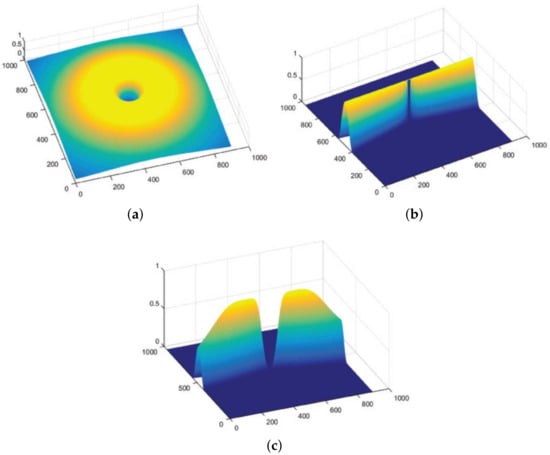
Figure 3.
Setting up of the directional bandpass filter: (a) Exhibits ; (b) Shows ; (c) Depicts the complete bandpass directional filter .
A retinal image is fragmented into its constituent directional filter bank involving numerous images , where . Here i denotes the iterative increase in angle of the directional images spanning from 0 to 180 degrees. For our experiment, these orientations are given by which cover the complete angular width at an interval of 22.5 degrees, thus constituting a total of 8 images. Following this regimen leads to the constituent directional images with a high vessel response in only the specified orientation and a dull response elsewhere. DFB technique thus helps decompose an input retinal image into a diverse set of directional images, thereby highlighting all vessels corresponding to their specific angles only. The directional filter bank similar to Figure 3 was employed to help develop the direction-specific vessel images shown in Figure 4.
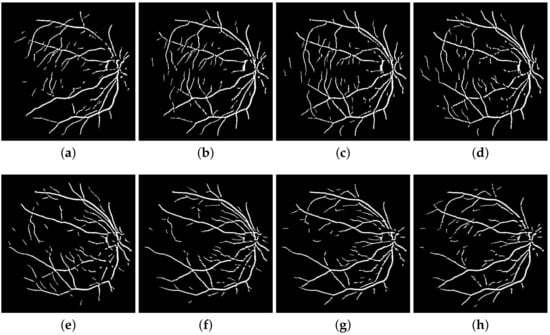
Figure 4.
Directional image array built using the Bandpass Directional Filter Bank: (a) through (h) depict vessel responses corresponding to 8 iterations of 22.5 degrees from 0 to 180 degrees.
3.2. Multi-Scale Line Detector
A rudimentary line detector works by matching the average grey-level response of a possible vascular segment with 12 scanning lines oriented at 15 degrees to each other. This 180-degrees scan investigates a sub-image of a particular window size (usually 15 pixels). The line with the highest intensity response is labeled as the ‘winning line’, which depicts the presence and orientation of a vessel whereas lower responses confirm their absence. Therefore, any arbitrary pixel is classified as either a vessel or non-vessel pixel depending upon its variance from the winning line.
Another critical issue where line detectors excelled over other techniques, is the problem of central light reflex. It occurs when the edges of vessels exhibit a heightened intensity as compared to their mid-lines. This reflex causes a lot of false positives as the pixels near the center of vessels get misclassified as background. Line detectors, on the other hand, remain largely unaffected due to the winning line methodology. However, there are some major drawbacks with the basic line detector, the most important of which is its tendency to combine close vessels. Also, vessel crossover points induce false vessel augmentations, and edges of major vessels cause misclassification of background pixels as foreground.
To mitigate these negative effects, Nguyen et al. [26] suggested varying the scales of the scanning lines to distinguish vessel and background pixels, a technique he named as multi-scale line detectors. This was done by adjusting the length of the scan line L from 1 to the window size W, with the expectation that this would help alleviate the problems discussed above. Two intensity responses labeled as (maximum line response), and (average window response) were used to calculate the multi-scale line detector as:
This detector works brilliantly in all three problems faced by the basic line detector but reducing the detector’s line length introduces noise artifacts. This addition of noise comes from a narrower range of line detectors, leading to a weaker contrast among vessel and non-vessel pixels. To enhance the contrast, these raw response values are recombined in linear order to standardize these values to zero mean and unit standard deviation distribution as follows:
where and M are the standard and raw responses, respectively. The statistical values of and (mean and standard deviation of the raw values, respectively) help keep the distribution of intensity values in check. Therefore, these intensity values are extended over a broader range to significantly improve the contrast between the vessels and background, thereby reducing false positives.
Previously, the multi-scale line detectors were used to scan all the angles, and were not focused on any single direction. The method still worked remarkably well at detecting retinal vessels, but output response varied in contrast, making the detection process harder with a single threshold. This was due to the reason that, for an area having both types, the high contrast vessels dominated the detector’s focus and the weak contrast vessels got suppressed. Also, during the combined binarization process, tiny vessels, especially of 1-pixel width got wiped out. Not only the tiny vessels, but this difference in contrast also affected the major vessels as their borders were misclassified and thus narrowed down. Major vessels are often overlooked, but they are important as well when considering the overall efficiency of the segmentation process. For a major vessel having a width of 10 pixels, if the detector classifies 8 vessels correctly, that is still a loss of 2 pixels. Now looking at the percentage of major vessel pixels as compared to the tiny vessels in a retinal image, this loss of 2 pixels becomes a huge cumulative loss for the detector’s sensitivity.
Here lies the novelty claim in this method such that, multi-scale detectors are made to operate in a narrower directional range instead of the whole 180 degrees. Not only this, the images these detectors work on are also directional in nature as acquired from the DFB technique as shown in Figure 5. This is done with the anticipation that, when both the image and filter’s directions are aligned, the filter’s response would be far superior, and features will be picked up more efficiently as depicted in Figure 6. To top it all off, the binarization is also done within these distinct directions to achieve improved vascular segmentation as shown in Figure 7.
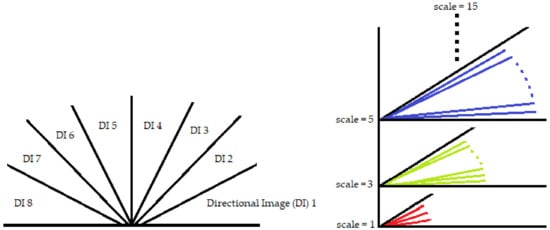
Figure 5.
Left image shows 8 directional images of 22.5 degrees each, where every such image gets scanned by 11 line detectors of similar orientation while being scaled from 1 to 15 as shown on the right.
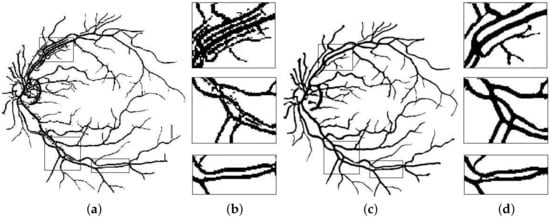
Figure 6.
Segmentation results of: (a) Basic line detector; (b) Poor response at major vessels and vessel crossings; (c) Proposed method; (d) Improved response at critical points. This shadow removal happens largely due to alignment of line filter orientation with that of directional image it is operating on.
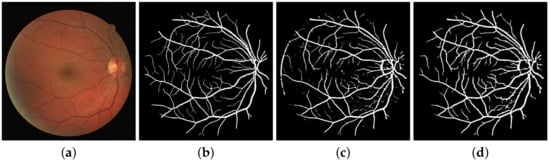
Figure 7.
Response of directional multi-scale line detector: (a) Shows the original image; (b) Shows the ground truth; (c) Depicts the response of simple multi-scale line detector; (d) Shows the response of directional multi-scale line detector.
The multi-scale line responses of every individual pixel are linearly recombined as:
Combined responses of each of the 8 directional images are calculated separately where d depicts the direction. These directional responses go through the binarization process before being accumulated into the final segmented image. The window size is taken as 15 in which each scale is averaged using the same weight. The parameter represents the scale depth which is iterated from 1 till 15 with a step size of 2, thus resulting in a total of 8 scales. represents individual scale responses calculated from Equation (5), and is the inverted green channel response of each pixel in the RGB image. The parameter is included because the green channel information offers better contrast of the vessels as compared to other background entities such as OD and lesions [26]. In an original green channel, the vessels are dark on a light background, whereas this paper makes use of inverted green channel where vessels are light on a dark background for better visibility. This linear recombination scheme results in the reduction of background noise in the proximity of vessels.
3.3. Coherence-Enhancing Diffusion (CED)
Regularization of variations in elongated structures is done by applying anisotropic diffusion through a diffusion matrix, also known as Coherence-Enhancing Diffusion (CED). This filter is nonlinear but isotropic in nature and is dictated by the diffusivity parameter which allows or denies the diffusion at every point of an input image. This diffusion is done based on the feature’s orientation at that point in such a manner so as to avoid smoothing across the edges and thus, preserve sharpness in the image. In other words, the diffusion or smoothing is to be guided parallel to the edges rather than over them. The efficiency of this process is monitored through the development of the Orientation Field (OF) on a point-to-point basis and thus, an accurate OF is crucial to the whole CED regimen. The diffusion matrix calculates the diffusivity parameters by observing the local image structure alongside the alignment towards clean directions at each diffusion step. Each valid change is noted in a secondary matrix known as a second-moment matrix (or structure tensor), which is an established method for enhancing flow-like structures. Assuming a retinal image , the anisotropic scale-space for is defined as:
where D is the diffusion matrix of order . This diffusion matrix is adjusted to the area under consideration by the symmetric structure tensor , defined as:
where , and represent the Gaussian derivative functions in both axes. The tuning parameter is defined as:
Using this parameter, the two dominant eigenvalues become:
The expression comprehensively depicts the local variation of the gray values around a locality as follows:
- ; constant areas.
- or ; straight edges.
- ; corners.
- ; flat regions.
The last pieces of the puzzle are the eigenvectors which are later integrated with the eigenvalues to reconstruct the diffusion matrix D. One is the normalized eigenvector , and the other is the orthogonal eigenvector . The eigenvalues of the diffusion matrix are taken as:
where , and . The diffusion matrix D can be recreated with its eigenvalues and eigenvectors as:
Overall, the diffusion process advances in the following four pivotal steps:
- 1.
- Evaluate the second-moment matrix according to Equation (8).
- 2.
- Eigen-directions are computed using Equation (10), and diffusion matrix is constructed using Equations (12), (13), and (14).
- 3.
- Calculating change in intensity of each pixel based on its local neighborhood according to partial differential equation as .
- 4.
- Update image using the diffusion equation:
3.4. Binarization
It is a thresholding technique that converts a gray-scale image to a binary image and therefore, is a crucial step in the effective segmentation and classification of foreground features. A threshold value dictates this binarization phase, where a value greater than a carefully calibrated threshold allocates that pixel position to foreground and other values are classified as background or vice versa. As discussed during the line-detector phase, different lengths of detectors produce different artifacts (shadows and extensions) within the image. Method in [26] opted for multi-scale detectors as the detector had to move in all directions from 0 to 180 degrees. When a small length filter is aligned across a vessel, it produces shadows which cause false positives. This is not the case with our directional filter as the direction of the line filter is limited. However, the problem of extensions, which is caused by the larger scale filters still remains and is dealt with using traditional Niblack image thresholding [41].
Extensions can be avoided by using a better binarization scheme that involves the line filter’s standard deviation. A 2-D fissure likelihood measure [42], used to guide binarization process is defined as:
- If <−k×: Classify pixel as background (this step removes the extensions).
- Else: Leave pixel unchanged.
Here, represents the line response of any arbitrary pixel while and depict the line filter’s mean and standard deviation at that point, respectively. The bias parameter k is used to stabilize the impact of standard deviation from vessels of different sizes and Niblack proposed its value to be kept at −0.2. However, due to the sensitivity of the binarization process to this parameter, its values were tested from the range of −0.3 to 0.3, and the value of −1.5 was found to be suitable for this experiment. Figure 8 depicts the effectiveness of this step towards mitigating the effects of extensions created by the line filter.
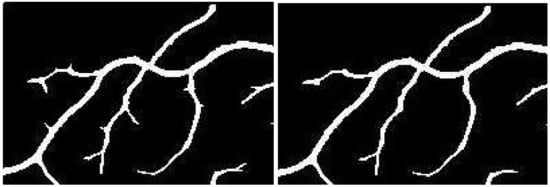
Figure 8.
Removal of extensions: (a) Image shows extensions caused by large line filters; (b) Extensions removed by the Niblack adaptive threshold.
The extension removal process is followed by the Linde–Buzo–Gray (LBG) algorithm for scalar values [43]. However, the initial cluster information is fed with Otsu method [44] to avoid trapping in local minimum. The steps for LBG algorithm for our application are as follows:
- Input pixel intensity values .
- Initialize a codebook C= using Otsu method.
- The initial codebook is split to create two values as and , where △ is a small positive number.
- Classify the image pixels into two clusters according to if for .
- Update cluster centers , by:
- Set and compute the distortion as:
- If (a small positive number), repeat step 4 to step 6.
- The final threshold value is:
4. Experimental Results
This section presents the conducted experimental results. A comprehensive analysis on the achieved results is also presented in this section.
4.1. Materials
Three standard publicly available databases: DRIVE [7], STARE [6], and CHASE_DB1 [45] were used for experiments in this work.
- Digital Retinal Images for Vessel Extraction (DRIVE): part of a screening program in 400 diabetic retinopathy patients, aged 25–90 years in the Netherlands. It has 20 test and training images with a resolution of pixels
- Structured Analysis of the Retina (STARE): 20 images having a resolution of pixels where half are normal, and half have pathologies such as hemorrhages, exudates and microaneurysms.
- Child Heart And health Study in England (CHASE_DB1): 28 images acquired from both eyes of 14 multiethnic children in England. It also boasts a high resolution of pixels.
The DRIVE and CHASE_DB1 datasets have distinct image sets to test and train the detector so the efficiency of the segmentation techniques can be judged. However, the manually segmented vessel tree for STARE dataset is only available for 20 images, and these were used as test images to evaluate the proposed methodology. Also, the Field Of View (FOV) images are given with the DRIVE dataset, but are not available for STARE and CHASE_DB1 datasets. The FOV for these two datasets was created using the image segmenter tool in MATLAB.
4.2. Evaluation Criterion
To gauge the efficiency of the proposed method, a resultant segmented image is compared with its corresponding ground truth. The ability to differentiate between vessel and non-vessel or background pixels, determines the effectiveness of a method at mapping the retinal vessel structure. Considering only the pixels inside the image’s FOV, classifications in both ground truth and segmented images were compared. This comparison results in two correct and two incorrect classifications. Segmentation results labeled as “positive” point towards foreground or vessel pixels, and “negative” suggests background or non-vessel pixels. Similarly, the phrase “positive” depicts a correct segmentation of a pixel while “negative” suggests a misclassification. Following this convention, True Positive (TP) is a pixel correctly classified as a vessel, and a False Positive (FP) is background pixel mistakenly classified as vessel. A True Negative (TN) is a pixel correctly identified as background, and a False Negative (FN) is a vessel pixel classified as background. These four possible results contribute towards the calculation of the following benchmark-specific test sets based on the interpretation of classifier decisions as:
Sn depicts the ability of a method to segment vessels effectively while Sp represents background classification strength. Acc is a global ratio operator defined as pixels correctly classified as either vessel or background pixels divided by all pixels within the image. Area Under the Curve (AUC) is another commonly used parameter that is used to score binary classification methods. AUC integrates the area under the Receiver Operating Characteristic (ROC) curve to give a value of 1 for a perfect classifier and 0.5 for a totally random classifier. This is not applicable to this technique, as different directional images are individually binarized and recombined towards the end.
4.3. Comparison with State-of-the-Art
For the quantitative performance evaluation of our method, testing was carried out on the DRIVE, STARE, and CHASE_DB1 datasets with segmentation results as shown in Figure 9, Figure 10 and Figure 11, respectively. Performance measures such as Sn, Sp, and Acc for these databases are listed separately and compared with those of state-of-the-art techniques in Table 1, Table 2 and Table 3. Also, the computation time for the proposed method on MATLAB 2018b, comes out to 5 seconds per image on a Core i7 CPU (2.21 GHz, 16 GB RAM).
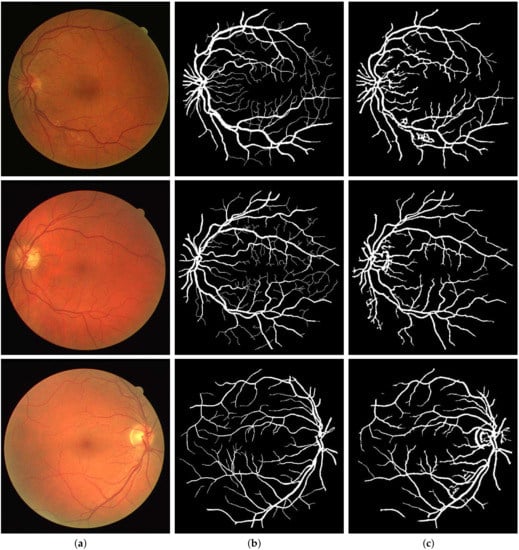
Figure 9.
Segmentation results of DRIVE: (a) Color fundus images 3, 5 and 18; (b) Ground truths; (c) Binarization results.
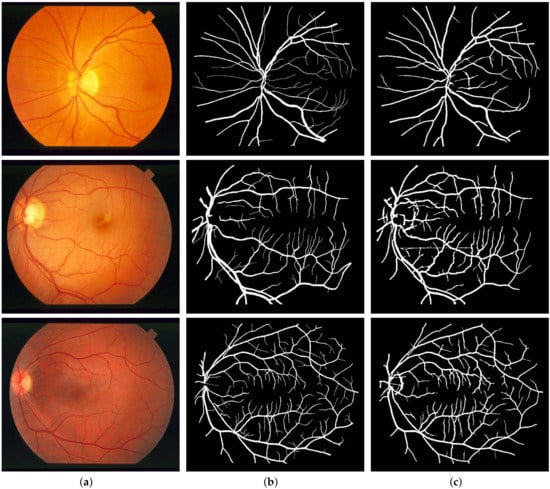
Figure 10.
Segmentation results of STARE: (a) Color fundus images 12, 14 and 17; (b) Ground truths; (c) Binarization results.
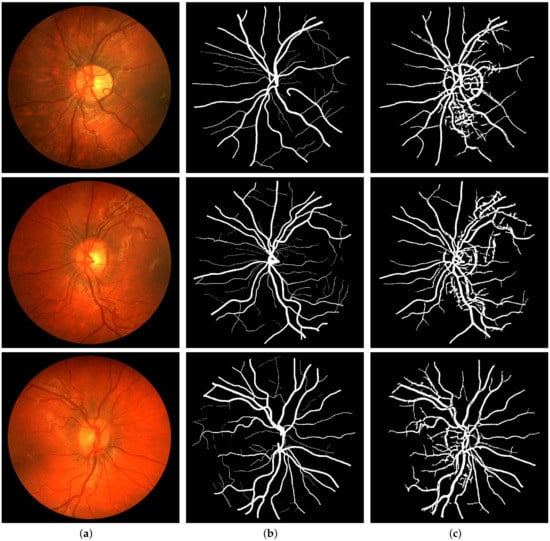
Figure 11.
Segmentation results of CHASE_DB1: (a) Color fundus images 1, 5, and 10; (b) Ground truths; (c) Binarization results.

Table 1.
Comparison with state-of-the-art techniques on the DRIVE database.
Table 2.
Comparison with state-of-the-art techniques on the CHASE_DB1 database.
Table 3.
Comparison with state-of-the-art techniques on the STARE database.
It can be observed from these results that the proposed strategy of using directional multi-scale line detectors yields performance parameters that are at par with all the top-performing techniques in their respective categories. Most importantly, this method is equally potent irrespective of the benchmark dataset it is tested on, and produces all-round efficient results as shown in the quality measure graphs in Figure 12.
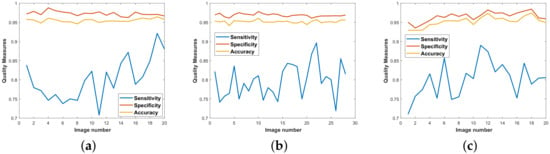
Figure 12.
Quality measures for datasets: (a) DRIVE; (b) CHASE; (c) STARE.
For the DRIVE database, we obtained 0.8043, 0.9730, and 0.9553 for Sn, Sp, and Acc, respectively. The Sn is the highest in its category and shows considerable enhancement over the second-best Aguiree [37], which exhibited a Sn of 0.7854. The highest Sn score is 0.92 for image 19 and lowest score is 0.71 for image 11. The highest Sp score is 0.99 for image 4 while the best Acc is 0.97 for image 19. Talking about Sp, our method just takes the edge over Zhang [34] with 0.9725, but loses the first place to Karn [36] with a Sp of 0.98. The same hybrid active contour technique by Karn [36] scores the highest Acc of all methods (0.97) with our method in second place. It is pertinent to note here that Karn [36] achieved these numbers at the cost of the method’s Sn and also rounded-off his performance parameters in his report to a decimal place accuracy of 2.
For the STARE database having the more challenging pathological images, we obtained averaged scores of 0.8011,0.9694, and 0.9545 for Sn, Sp, and Acc, respectively. The Sn of our method is in second place behind the method by Neto [35], having an impressive score of 0.8344 but his algorithm scored such a high Sn mark by sacrificing the Sp and Acc measures for his method. The highest Sn score for STARE is 0.89 for image 11, and lowest score is 0.71 for image 1. The best Sp score is 0.98 for image 12 while the highest Acc is 0.97 for image 18. The average Sp is almost at par with the first position orientation scores method by Zhang [34] at 0.9758. The average Acc measure of our method lies in third place close behind Karn [36] and Zhang [34] with Acc scores of 0.96 and 0.9554, respectively. Overall, our method consistently ranks in the top tier of all unsupervised vessel segmentation techniques for the STARE dataset.
Considering the CHASE_DB1 dataset, our proposed algorithm reports the highest Sn score which is a significant improvement upon the second place Karn [36] at 0.78. The highest Sn score for this dataset is 0.90 for image 21 and lowest score is 0.71 for image 26. The highest Sp score is 0.98 for image 10 while the best Acc is 0.96 for images 1 and 22. The average Sp score of our method is 0.9697, which barely loses out to the top performing technique in the category by Karn [36] at 0.97. The average Acc of our method stands at second position with a value of 0.9528, tagging behind top-performing algorithm by Karn [36] at 0.97. Comparatively, our directional multi-scale line detector exhibits all-round performance on a variety of databases and performs similar or sometimes superior when compared with the supervised learning algorithms.
5. Conclusions
In this paper, the use of directional multi-scale line detectors was proposed for segmenting directional vessel images extracted from DFB. The evaluation of this technique on three publicly available datasets suggested that this technique not only yielded balanced and robust performance parameters under difficult testing environments, but also competed with supervised learning techniques which are much more computationally intensive. This computational flexibility also gave this technique great leverage while working on considerably large databases with retinal disorders and abnormalities. The intricate geometry of retinal vessels meant that special methods be adopted to successfully segment troublesome areas such as parallel vessels and vessel crossings. The use of an array of directional images acted upon by a directional detector and binarization, helped this method achieve superior sensitivity results of 0.8043 and 0.7974 for the DRIVE and CHASE_DB1 datasets while maintaining decent specificity and accuracy scores.
The potential future research directions of this work include the exploration of combining the directional filters with contrast enhancement and noise cancellation techniques to optimize the performance and reduce the classification inaccuracies during the segmentation process.
Author Contributions
Conceptualization, A.K. and T.M.K.; Methodology, T.M.K. and M.A.U.K.; Validation, T.M.K. and S.J.N.; Formal analysis, A.K. and S.J.N.; Investigation, A.K.; Writing–original draft preparation, A.K.; Writing–review and editing, T.M.K., M.A.U.K. and S.J.N.; Visualization, A.K.; Supervision, T.M.K. and S.J.N.
Funding
The authors would like to acknowledge the partial support by the project MEDiCS, approved under the call ICI-RDO-MoE-KSA-2018.
Acknowledgments
The authors would like to acknowledge the support and facilitates provided by COMSATS University Islamabad (CUI), Pakistan.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lesage, D.; Angelini, E.D.; Bloch, I.; Funka-Lea, G. A review of 3D vessel lumen segmentation techniques: Models, features and extraction schemes. Med. Image Anal. 2009, 13, 819–845. [Google Scholar] [CrossRef] [PubMed]
- Zemouri, R.; Zerhouni, N.; Racoceanu, D. Deep learning in the biomedical applications: Recent and future status. Appl. Sci. 2019, 9, 1526. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from imbalanced data ieee transactions on knowledge and data engineering. IEEE Trans. Knowl. Data Eng. 2009, 21, 9. [Google Scholar]
- Yu, H.; Yang, X.; Zheng, S.; Sun, C. Active learning from imbalanced data: A solution of online weighted extreme learning machine. IEEE Trans. Netw. Learn. Syst. 2018, 30, 1088–1103. [Google Scholar] [CrossRef]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in nonstationary environments: A survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Hoover, A.D.; Kouznetsova, V.; Goldbaum, M. Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans. Med. Imaging 2000, 19, 203–210. [Google Scholar] [CrossRef]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; Ginneken, B.V. Ridge-based vessel segmentation in color images of the retina. IEEE trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Niemeijer, M.; Staal, J.; Ginneken, B.V.; Loog, M.; Abramoff, M.D. Comparative study of retinal vessel segmentation methods on a new publicly available database. In Proceedings of the Medical Imaging 2004: Image Processing, San Diego, CA, USA, 14–19 February 2004. [Google Scholar]
- Ricci, E.; Perfetti, R. Retinal blood vessel segmentation using line operators and support vector classification. IEEE Trans. Med. Imaging 2007, 26, 1357–1365. [Google Scholar] [CrossRef]
- Marín, D.; Aquino, A.; Arias, M.E.G.; Bravo, J.M. A new supervised method for blood vessel segmentation in retinal images by using gray-level and moment invariants-based features. IEEE Trans. Med. Imaging 2010, 30, 146–158. [Google Scholar] [CrossRef]
- You, X.; Peng, Q.; Yuan, Y.; Cheung, Y.; Lei, J. Segmentation of retinal blood vessels using the radial projection and semi-supervised approach. Pattern Recognit. 2011, 44, 2314–2324. [Google Scholar] [CrossRef]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. An ensemble classification-based approach applied to retinal blood vessel segmentation. IEEE Trans. Biomed. Eng. 2012, 59, 2538–2548. [Google Scholar] [CrossRef] [PubMed]
- Franklin, S.W.; Rajan, S.E. Computerized screening of diabetic retinopathy employing blood vessel segmentation in retinal images. Biocybern. Biomed. Eng. 2014, 34, 117–124. [Google Scholar] [CrossRef]
- Li, Q.; Feng, B.; Xie, L.; Liang, P.; Zhang, H.; Wang, T. A cross-modality learning approach for vessel segmentation in retinal images. IEEE Trans. Med. Imaging 2016, 35, 109–118. [Google Scholar] [CrossRef] [PubMed]
- Orlando, J.I.; Prokofyeva, E.; Blaschko, M.B. A discriminatively trained fully connected conditional random field model for blood vessel segmentation in fundus images. IEEE Trans. Biomed. Eng. 2016, 64, 16–27. [Google Scholar] [CrossRef] [PubMed]
- Dasgupta, A.; Singh, S. A fully convolutional neural network based structured prediction approach towards the retinal vessel segmentation. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, Australia, 18–21 April 2017. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Oliveira, A.; Pereira, S.; Silva, C.A. Retinal vessel segmentation based on fully convolutional neural networks. Expert Syst. Appl. 2018, 112, 229–242. [Google Scholar] [CrossRef]
- Li, T.; Gao, Y.; Wang, K.; Guo, S.; Liu, H.; Kang, H. Diagnostic assessment of deep learning algorithms for diabetic retinopathy screening. Inf. Sci. 2019, 501, 511–522. [Google Scholar] [CrossRef]
- Li, R.; Li, M.; Li, J. Connection sensitive attention u-net for accurate retinal vessel segmentation. arXiv 2019, arXiv:1903.05558. [Google Scholar]
- Jiang, Y.; Tan, N.; Peng, T.; Zhang, H. Retinal vessels segmentation based on dilated multi-scale convolutional neural network. IEEE Access 2019, 7, 76342–76352. [Google Scholar] [CrossRef]
- Guo, S.; Wang, K.; Kang, H.; Zhang, Y.; Gao, Y.; Li, T. Bts-dsn: Deeply supervised neural network with short connections for retinal vessel segmentation. Int. J. Med. Inf. 2019, 126, 105–113. [Google Scholar] [CrossRef]
- Miri, M.S.; Mahloojifar, A. Retinal image analysis using curvelet transform and multistructure elements morphology by reconstruction. IEEE Trans. Biomed. Eng. 2011, 58, 1183–1192. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Géraud, T.; Najman, L. Two applications of shape-based morphology: Blood vessels segmentation and a generalization of constrained connectivity. Int. Symp. Math. Morphol. Appl. Signal Image Process. 2013, 7883, 390–401. [Google Scholar]
- Moghimirad, E.; Rezatofighi, S.H.; Zadeh, H.S. Retinal vessel segmentation using a multi-scale medialness function. Comput. Biol. Med. 2012, 42, 50–60. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, U.T.V.; Bhuiyan, A.; Park, L.A.F.; Ramamohanarao, K. An effective retinal blood vessel segmentation method using multi-scale line detection. Pattern Recognit. 2013, 46, 703–715. [Google Scholar] [CrossRef]
- Ravichandran, C.G.; Raja, J.B. A fast enhancement/thresholding based blood vessel segmentation for retinal image using contrast limited adaptive histogram equalization. J. Med. Imaging Health Inf. 2014, 4, 567–575. [Google Scholar] [CrossRef]
- Perez, M.E.M.; Hughes, A.D.; Thom, S.A.; Bharath, A.A.; Parker, K.H. Segmentation of blood vessels from red-free and fluorescein retinal images. Med. Image Anal. 2007, 11, 47–61. [Google Scholar] [CrossRef]
- Sofka, M.; Stewart, C.V. Retinal vessel centerline extraction using multiscale matched filters, confidence and edge measures. IEEE Trans. Med. Imaging 2006, 25, 1531–1546. [Google Scholar] [CrossRef]
- Kar, S.S.; Maity, S.P. Retinal blood vessel extraction and optic disc removal using curvelet transform and morphological operation. Mach. Intell. Signal Process. 2016, 390, 153–161. [Google Scholar]
- Amin, M.A.; Yan, H. High speed detection of retinal blood vessels in fundus image using phase congruency. Soft Comput. 2011, 15, 1217–1230. [Google Scholar] [CrossRef]
- Pérez, M.A.P.; Perez, M.E.M.; Pérez, H.B.; Arjona, J.L.O. Parallel multiscale feature extraction and region growing: application in retinal blood vessel detection. IEEE trans. Inf. Technol. Biomed. 2010, 14, 500–506. [Google Scholar] [CrossRef]
- Cinsdikici, M.G.; Aydın, D. Detection of blood vessels in ophthalmoscope images using mf/ant (matched filter/ant colony) algorithm. Comput. Methods Programs Biomed. 2009, 96, 85–95. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Dashtbozorg, B.; Bekkers, E.; Pluim, J.P.W.; Duits, R.; Romeny, B.M.H. Robust retinal vessel segmentation via locally adaptive derivative frames in orientation scores. IEEE Trans. Med. Imaging 2016, 35, 2631–2644. [Google Scholar] [CrossRef] [PubMed]
- Neto, L.C.; Ramalho, G.L.; Neto, J.F.R.; Veras, R.M.; Medeiros, F.N. An unsupervised coarse-to-fine algorithm for blood vessel segmentation in fundus images. Expert Sys. Appl. 2017, 78, 182–192. [Google Scholar] [CrossRef]
- Karn, P.K.; Biswal, B.; Samantaray, S.R. Robust retinal blood vessel segmentation using hybrid active contour model. IET Image Process. 2018, 13, 440–450. [Google Scholar] [CrossRef]
- Ramos, H.A.; Cervantes, J.B.A.; Aceves, I.C.; Pinales, J.R.; Ledesma, S. Blood vessel segmentation in retinal fundus images using gabor filters, fractional derivatives, and expectation maximization. Appl. Math. Comput. 2018, 339, 568–587. [Google Scholar]
- Sundaram, R.; Ravichandran, K.S.; Jayaraman, P.; Venkatraman, B. Extraction of blood vessels in fundus images of retina through hybrid segmentation approach. Mathematics 2019, 7, 169. [Google Scholar] [CrossRef]
- Kass, M.; Witkin, A. Analyzing oriented patterns. Comput. Vis. Graph. Image Process. 1987, 37, 362–385. [Google Scholar] [CrossRef]
- Knutsson, H.; Wilson, R.; Granlund, G. Anisotropic nonstationary image estimation and its applications: Part i-restoration of noisy images. IEEE Trans. Commun. 1983, 31, 388–397. [Google Scholar] [CrossRef]
- Niblack, W. An Introduction to Digital Image Processing; Strandberg Publishing Company: Birkeroed, Denmark, 1985. [Google Scholar]
- Xiao, C.; Staring, M.; Wang, J.; Shamonin, D.P.; Stoel, B.C. A derivative of stick filter for pulmonary fissure detection in ct images. In Proceedings of the Medical Imaging 2013: Image Processing, Lake Buena Vista, FL, USA, 9–14 February 2013. [Google Scholar]
- Lloyd, S. Least squares quantization in pcm. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Fraz, M.M.; Remagnino, P.; Hoppe, A.; Uyyanonvara, B.; Rudnicka, A.R.; Owen, C.G.; Barman, S.A. Blood vessel segmentation methodologies in retinal images–a survey. Comput. Methods Programs Biomed. 2012, 108, 407–433. [Google Scholar] [CrossRef] [PubMed]












© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).