1. Introduction
Image set matching (ISM) or image set classification, which regards one set of images as a sample, has recently attracted considerable attention due to its widespread applications such as video-based face recognition, multi-view object recognition, dynamic scene classification [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10]. Compared with traditional single image based classification, ISM has the merit of incorporating information from multiple images of one set to provide all-sided description for a subject and thus achieve better matching accuracy.
Most of the existing ISM methods roughly fall into two categories, parametric and non-parametric. Parametric methods [
11,
12] try to model image sets with certain statistical distributions and then evaluate the similarities among those distributions. Non-parametric methods tend to assume that the image sets have underlying linear or nonlinear geometric structures and construct global set models, such as subspaces [
2,
13,
14], manifolds [
6,
15,
16] and affine/convex hulls [
8,
9,
17,
18,
19,
20,
21], etc. Non-parametric methods have shown superior performance in the cases when the data distributions do not meet the models estimated by the parametric methods. Recently, some methods [
1,
10,
22,
23] have presented various further improvements following conventional non-parametric methods. Ref [
22] proposes Nonlinear Subspace Feature Enhancement (NSFE) for nonlinearly embedding image sets into a space where they adhere to a more discriminative subspace structure. Ref. [
23] combines multiple manifolds as the features of the original image sets, utilizing well-studied Riemannian kernels to map the original Riemannian spaces into high dimensional Hilbert spaces. In [
1], aiming at alleviating the handicap that over-large affine hull usually fails in mathcing when two hulls is overlapped, Learning of Reduced Prototypes and Local Metric (LRPLM) is proposed to acquire powerful discriminative ability. Ref. [
10] uses the mean vector, subspace and covariance matrix which lie on different spaces (Euclidean or manifold) to jointly represent an image set, and develops a multimodel fusion metric learning (MMFML) framework to reduce the dissimilarity between the heterogeneous spaces.
Many of the methods mentioned above, however, describe the query and gallery sets separately, and then measure the query-to-gallery distances/similarities using nearest neighbor or subspace classifiers. Firstly, they do not explore the relationships among the gallery sets which are helpful for improving ISM accuracy. Secondly, such a way of modeling separately followed by matching the models is less straightforward, or even unfair in terms of distance measurement. Finally, existing methods often depend heavily on the extracted features, i.e., different feature extraction techniques make big difference to the final matching performance. In recent years, deep learning-based image set classification methods [
3,
7,
24,
25,
26] are proposed where feature extraction plays a significant role in the deep neural networks. Ref. [
27] models a set of Convolutional Neural Network (CNN) features (as inputs) by a convex cone and measure the geometric similarity of convex cones for image set classification. Even some deep learning-based methods need to use extra hand-crafted features, e.g., in the method of Deep Reconstruction Models (DRM) [
3], the first step of learning DRM is to compute Local Binary Pattern (LBP) features [
28].
Sparse Representation has been very popular in many fields such as image classification [
29,
30], dictionary learning [
31], color image restroation [
32], recovery of remote sensing contaminated products [
33], missing information reconstruction of remote-sensing images [
34,
35]. Sparse representation classification (SRC) [
29] and Collaborative Representation Classification (CRC) [
30] are two well-known classifiers which can bridge the testing sample and the training samples together under a unified framework, achieving impressive performance for single image based classification. In the unified framework, SRC or CRC implicitly describes the relationships (competition and collaboration) among the training samples while measuring directly the distances/similarities between testing and training samples. Furthermore, such methods are not sensitive to the feature extraction techniques, i.e., whatever kind of extracted feature is fed to the models based on SRC or CRC leads to good performances. Studies [
36,
37] either utilize the mean of the images within the query set or choose a candidate image by clustering the query set to conduct basic (single image based) SRC for image set based applications, but the basic SRC used can not exploit the rich information involved in image sets, especially in the query sets.
To accurately measure the distances between the query and gallery sets, some methods attempt to project all the sets into a collaborative or joint sparse representation framework for image set classification [
19,
38,
39] and multimodal/multi-task recognition [
40,
41]. Image set based collaborative representation and classification (ISCRC) [
19] describes the query set as a convex or regularized hull and represents the hull collaboratively over all the gallery sets. Group Collaborative Representation (GCR) [
39] takes advantage of the relationships among gallery image sets to capture the inter-set and intra-set variations, and determines the characteristic subspaces of all the gallery sets. Methods [
38,
40,
41] jointly represent the query set (or multiple testing features) over the gallery sets (or multiple training features) with different constraints imposed on the representation coefficients. These methods mainly explore the relationships (competition and collaboration) among different gallery sets, and even correlations and variations within gallery sets, without carefully looking into the inter-instance relationships within the query set. However, the commonality and variations within the query set are also important clues for accurate ISM tasks. In addition, existing methods are not robust to corruptions of large magnitude mixed in the query sets. Once the query sets are grossly corrupted by outliers or partial perturbations of large magnitude (e.g., occlusions), the performances of many methods will degrade drastically.
Motivated by the above insights, in this paper, we propose a new joint representation model to highlight the inter-instance relationships within the query set for improving ISM. To emphasize the inter-class discrimination among gallery sets, a class-level sparsity constraint is imposed. While for the gallery set, it is exactly the class-level sparsity constraint that implicitly connives even enlarges the variations across the instances within the query set. Therefore a constraint is imposed on the representation model by low rank regularization, to eclectically embody the commonality among instances within the query set. The combination of the two constraints explores fully both the inter-set and intra-set relationships among the query and gallery sets. The main contributions of this paper are summarized as follows:
A joint sparse representation model with class-level sparsity constraint is chosen for ISM problem and then a low rank regularization is added to reveal thoroughly the intra-set and inter-set relationships to improve the ISM performance. To deal with nonlinear data in real scenarios, the kernelized variant of our method is presented.
For the problem of grossly corrupted data encountered in real scenarios, which is rarely mentioned in existing ISM methods, the proposed model is extended to its robust versions to tackle different types of gross corruptions.
The optimization challenge is solved efficiently by employing singular value thresholding and block soft thresholding operators in an alternating direction manner. The optimization algorithms for the kernelized and extended versions are modified accordingly.
Experiments on five public datasets demonstrate that the proposed method compares favorably with competing state-of-the-art methods.
The remaining of this paper is organized as follows.
Section 2.1 reviews some related work, comparing and analyzing several different joint representation models.
Section 3 proposes the improved joint representation model and its kernelized version, and describes the optimization procedures for solving the objective functions. Robust extension of the proposed model and the corresponding optimization are presented in
Section 4. Experimental results and analyses are showed in
Section 5.
Section 6 concludes this paper.
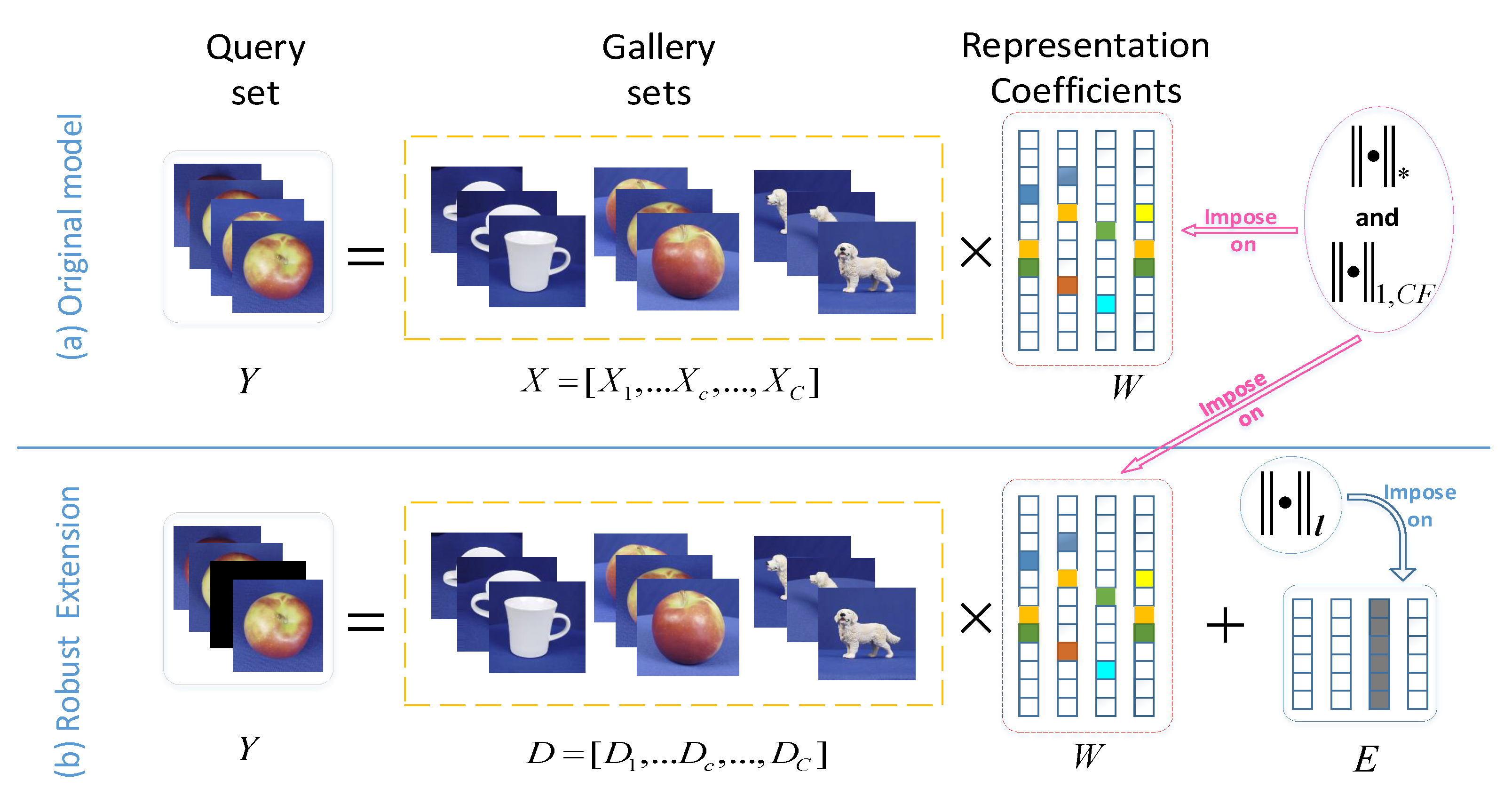
4. Robust LRCS for Image Set Corruptions
When the query sets are corrupted heavily, the initially proposed model will degenerate just like most of the existing ISM methods. In this section, the proposed LRCS is extended to robust LRCS, performing against two different corruptions of large magnitude mixed in the query sets.
As shown in
Figure 1b, in the case that the images within the query set are perturbed by gross corruptions, namely
, where
E could be random sparse corruptions or image-specific corruptions, we should consider modifying the originally proposed model to different corruption types. As illustrated in
Figure 3a, random sparse corruptions indicate that a fraction of random entries of
Y are grossly corrupted, such as partial blurs or occlusions in some images within the query set. In other words,
E is a spare error so that we consider adding a sparse constraint term
to the original model. It can be convex relaxed into
. Image-specific corruptions, e.g., outliers as illustrated in
Figure 3b, indicate the phenomena that a fraction of images within the query set (i.e., some columns of
Y ) are entirely corrupted. We consider adding a column-sparse constraint term to the original model, namely
, and convexly relax it into
. Based on the previous analyses, the extended robust model is formulated as follows:
where
is a positive parameter controlling the degree of corruption, and
indicates a certain regularization. The
-norm is used for characterizing the random sparse corruptions, and the
-norm is for dealing with image-specific corruptions.
As for the optimization to solve the problem (19), one can still employ similar procedures introduced in
Section 3.2. Specifically, by introducing an auxiliary variable then we can have the augmented Lagrangian form of the objective function as follows:
where the problem (20) will be solved iteratively in which each iteration will be updated alternately while keeping the other variables fixed.
- (1)
Update
W: this procedure is almost the same to the procedure (1) in
Section 3.2, and we just need to replace
with
and go on subsequent computing.
- (2)
Update
P: this procedure is just the same to the procedure (2) in
Section 3.2.
- (3)
Update
E: the subproblem for updating
E has the following form
where if
is
-norm, the solution to problem (21) can be computed by the soft thresholding operator
:
if
is
-norm, the solution to problem (21) can be computed via:
- (4)
Update
T: this procedure is just the same to the procedure (3) in
Section 3.2.
Once
W and
E are obtained, ISM can be done by assigning the class label by
We call Equation (
19) together with Equation (
24) Robust Low Rank regularization on Class-level Sparse joint representation model (R-LRCS). The proposed robust algorithm is summarized in Algorithm 2. The complexity analysis of Algorithm 2 is analog to that of Algorithm 1 as stated in
Section 3.3.
5. Experiments
In this section, extensive experiments on five datasets are run to demonstrate the efficacy of the proposed model and its extensions. The joint representation models with different constraints are first compared showing the significance of the proposed model. Then, the comparisons with other state-of-the-art methods are presented for different ISM tasks, and finally, the impressive robustness of R-LRCS to different corruptions is verified.
5.1. Datasets and Preprocessing
Honda dataset: The Honda dataset [
12] consists of 59 face video sequences which are collected from 20 different subjects. In each video sequence, there are a number of frames ranging from 12 to 645. The face images in the frames are automatically detected,cropped, and resized to 20 × 20. Finally, each video is processed to get an image set. For each class (subject), one image set is randomly selected as the gallery set for training while the rest ones are the query sets for testing.
YTC dataset: The YouTube Celebrity (YTC) dataset [
45] is collected from YouTube, including 1910 videos from 47 celebrities. The face images in this dataset show large variations in expression, illumination and pose, as shown in
Figure 4. Moreover, since the image compression rate is high, the resolution and quality of the images are extremely low. We extract a maximum of clearly detected face images from each video and resize them to 30 × 30 to form an image set. The dataset is equally divided into five folds, and in each fold there are nine image sets for each subject, of which three are used for training and six for testing.
ETH-80 dataset: The ETH-80 dataset [
46] contains eight categories of objects: cups, dogs, horses, apples, cars, cows, tomatoes and pears, as shown in
Figure 5. Each category is divided into ten subcategories, each of which involves plenty of images under 41 orientations with various brands or breeds are exhibited. The images are cropped and resized to 32 × 32. Each subcategory is processed to obtain an image set and therefore there are 80 sets in total. For each object, half of the sets are randomly selected for training and the remaining are used for testing.
UCSD Traffic dataset: The UCSD Traffic dataset [
47] contains 254 video sequences of highway traffic with varying patterns (i.e., light, medium and heavy) in various weather conditions (e.g., cloudy, raining, sunny). HoG features [
48] are used to describe each frame. The experiments are performed using the splits provided with the dataset [
47].
Maryland dataset: The Maryland dataset [
49] contains 13 different classes of dynamic scenes with ten videos per class, such as avalanches and tornados. We use the last convolutional layer of the Convolutional Neural Network (CNN) model [
50] as the frame descriptors. Then the dimensionality of the CNN output is reduced into 400 using Principal Component Analysis (PCA). We randomly choose seven image sets (videos) of each class for training and the remaining three for testing.
These datasets cover different sub-tasks of image set matching. The first two are for face identification, ETH-80 is for object categorization, and the last two are for scene classification. For all the datasets, the color images are converted to gray scale levels. In order to examine the anti-interference of various methods to illumination variations, histogram equalization is not used in the preprocessing stage for all the datasets. For Honda, YTC and ETH-80 datasets, we use the raw pixel values directly as features while employing different extracted features for the rest. All the features are normalized into vectors of unit one except for the query set features in the corruption experiments.
5.2. Experiment Setup
As for the experimental settings of the proposed method, we first compress each gallery set using a dictionary learning method such as KSVD [
31] to a sub-dictionary with atoms of fixed number and stack them up to form a combined dictionary. The number is set as 50,10,20,5 on Honda, YTC, ML, Traffic datasets respectively. The gallery sets of ETH-80 are stacked up directly as a dictionary without compressing, as their sizes are already small. The balance parameters
,
,
are often chosen among three different orders of magnitude
. Detailed analyses on the sensitivity of parameters are described in
Section 5.3. For the kernelized version of experiments, we choose the polynomial kernel.
We compare the proposed LRCS and its kernelized extension K_LRCS with some representative ISM methods, including several methods aiming at data nonlinearity, such as kernelized versions of several existing linear models and deep learning-based DRM [
3]. Their abbreviations and names are shown in
Table 1. For all the methods, their parameters are tuned for the best performances.
Specifically, for the MSM and linear AHISD, the thresholds for determining the subspace size are both set as 0.98. For the KAHISD, we set the bounds as
, where the value of
is chosen to be 5. The upper bounds of the CHISD and KCHISD are set to
. For the SANP, the same weighing parameters as in [
9] are taken to implement convex optimization. For the RHISCRC, we choose the
-norm regularized hull, and adopt the same parameter setting as in [
19] for the RHISCRC and KCHISCRC. For the NN_H and NN_J, the bandwidth parameter of the KDE kernels are chosen among
for different datasets. For the PDL, GCR, DRM and KRCHISD, we have the same parameter setting as in their originally proposed papers respectively. For all the kernelized methods, we use the Gaussian or polynomial kernels.
Ten-fold cross validation experiments are run for each kind of test, except on YTC dataset (five-fold) and Traffic dataset (four-fold).
5.3. Sensitivity of the Parameters
There are two positive parameters controlling the balance among different terms in the objective functions of the proposed model and its kernelized extension.
controls the class-level sparsity while
decides the low-rankness. Classification results of LRCS and K-LRCS with different parameter settings of
and
on the Traffic dataset are provided in
Table 2 and
Table 3 respectively.
The kernelized version shows more stable average recognition rates than the LRCS model, but in general, both their recognition performances do not change much. When fixing a parameter and fine tuning the other, the best performance often occurs when the two parameters are in the same order of magnitude. This implies that both of the class-level sparsity and low-rankness are at work, and they are complementary.
5.4. Comparisons among the Different Joint Representation Models
To compare the performances of various aforementioned joint representation models, we choose Maryland dataset as a representative to run experiments, due to the abundance of its data quantity and diversity covering many potential data structures. For convenience, we denote these models by some abbreviations as shown in
Table 1. We also add a low rank regularization to a row-level sparse joint representation model, denoted by LR+L12, to participate in the comparisons.
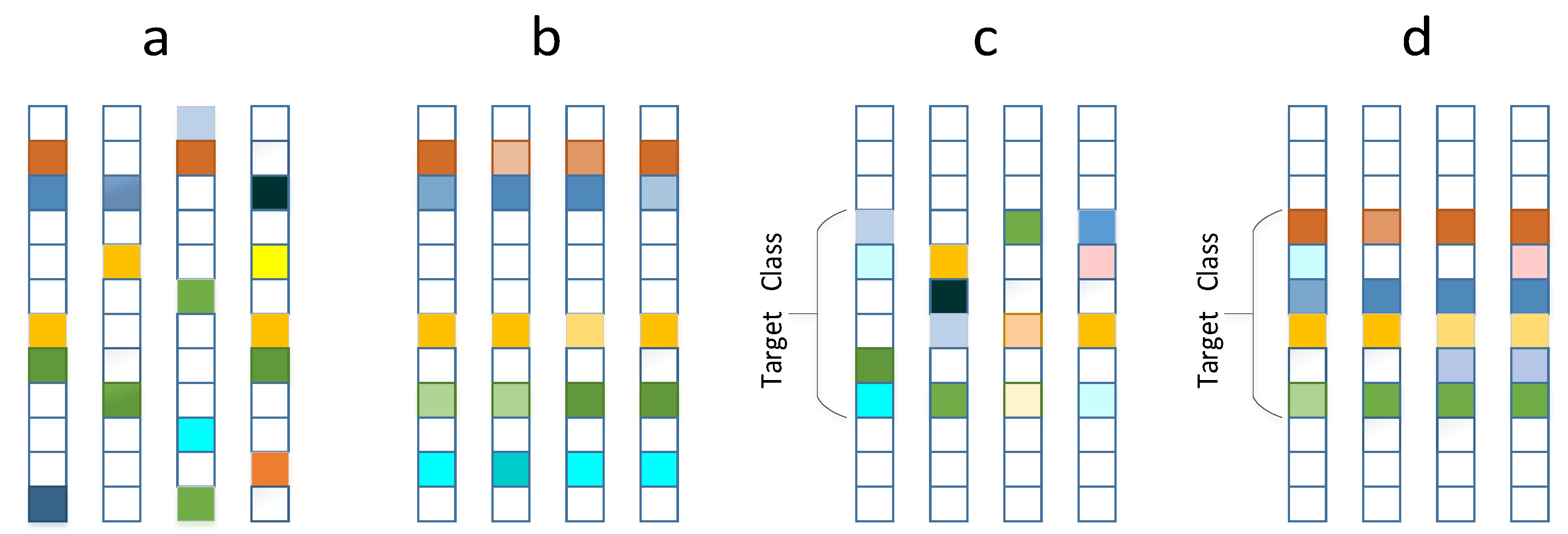
Table 4 shows the recognition rates of various joint representation models with 10 times of testing on Maryland dataset. Form the table, it is observed that L1 has an ordinary performance since it does not highlight any relationship within the query sets. CS enhances the inter-class discrimination utilizing class label prior, so it is supposed to perform always better than L12. At test no. 1,4,5 and 10, however, the recognition rates of CS are not higher (even lower) than that of L12. The reason is that the non-zero coefficients recovered by CS distribute rather chaotically in the potential targeted class (as shown in
Figure 2c, which connives even enlarges the variations across the images within the query set so that the inherent commonality (similarity) among the images is weakened. In fact, in terms of query set, L12 highlights similarity, implying extremely low rank, while probably CS has higher rank than the truth, due to the disordered distribution of the non-zero coefficients. In contrast to that, the proposed LRCS explores low-rankness with the class-level sparsity constraints. Realizing not only enhanced inter-class discrimination by class-level sparsity constraint, but also intra-set trade-off between commonality and variations by adding a low rank regularization, the proposed LRCS model performs better for ISM.
Obviously, the performance of the LR+L12 model is inferior to that of LRCS, and it is also not better (even worse) than that of L12. The reason is that the row-level sparsity has already means extreme low-rankness. Adding a low rank regularization leads the coefficients to be far from the truth, bringing worse performance. In addition, there is no significant increase in the recognition rates of K_LRCS over that of LRCS except for the smaller standard deviation meaning higher stability. Probably because the CNN features in this dataset are relatively linearly tractable and thus the linear model LRCS has already been able to present competitive matching performance.
5.5. Comparisons with the State-of-the-Art Methods
As shown in
Table 5, we compare the proposed method with the state-of-the-art in terms of ISM performance (average recognition rates and standard deviations) on the five benchmark datasets. For average recognition rates, both linear and nonlinear versions of the proposed model show the best or near the best performance on all the datasets in comparison to their respective categories of methods. Furthermore, the standard deviations of our proposed models are relatively small on each dataset, indicating the large stability of image set matching.
The KCHISCRC [
19] method performs almost the second best. Just like the proposed models, it also belongs to the category of unified modelling which models query and gallery sets together and measures their distances directly. To some extent, this demonstrates that the superiority of unified modelling over other methods modelling separately each set. Another unified modelling method RHISCRC [
19] also performs well on most datasets but unsatisfactorily on the rest, especially on Traffic. The reason is that the
-norm constraints used both
a and
[
19] assume implicitly that only a few extremely similar images from the query and gallery sets participate in constructing hulls and modelling, where inter-class ambiguities easily cause misclassifications. Notice that sometimes the average recognition rates of K_LRCS has little advantage over (even is inferior to) that of LRCS, just as KAHISD vs. AHISD, and KCHISD vs CHISD. It can be inferred that whether the kernelization operations can help significant improvement of performance also relies on how much nonlinearity is embedded in the features used.
We also observe that many other methods perform well on some datasets while poor on the others. That is to say, their performances are not stable, depending on the datasets. For example, RT-LSVM [
4] almost fails on the Maryland dataset. A probable explanation is that, as analyzed in [
4], this method has rigorous limits to the relationship among the three: the number of class labels, the number of images within the query set, and the number of training images of each class, which Maryland cannot satisfy. In addition, the deep learning-based DRM method does not necessarily outperform other methods especially on the YTC and ETH-80 datasets. For the DRM method, the first step of its model is to extract the LBP features, but for fair comparisons, by removing the feature extraction step, we use the pixel values directly just as other methods on Honda, YTC, and ETH-80 datasets. Since only extracted features rather than LBP are provided on the Maryland and Traffic datasets, DRM code is not run on them. Maybe the mandatory remove of the LBP feature extraction procedure impairs the performance of DRM (the dependence of different methods on features will be further demonstrated in
Section 5.6). Moreover, the small size of datasets limits the advantages of deep learning. The good news is, our proposed method shows impressive ability of dealing with nonlinearity, which is comparable to the deep model.
In terms of running time, for a normal image set, the average running time of our method varies on different datasets due to their different complexity (data quantity in every set, feature dimension, etc). For example, for LRCS, it is 1.68 s on Honda dataset while 3.38 s on YTC dataset on a PC with Intel(R) Core(TM) i7-3700 CPU and RAM 8GB. Such a running time is common compared to other methods for ISM problem [
21].
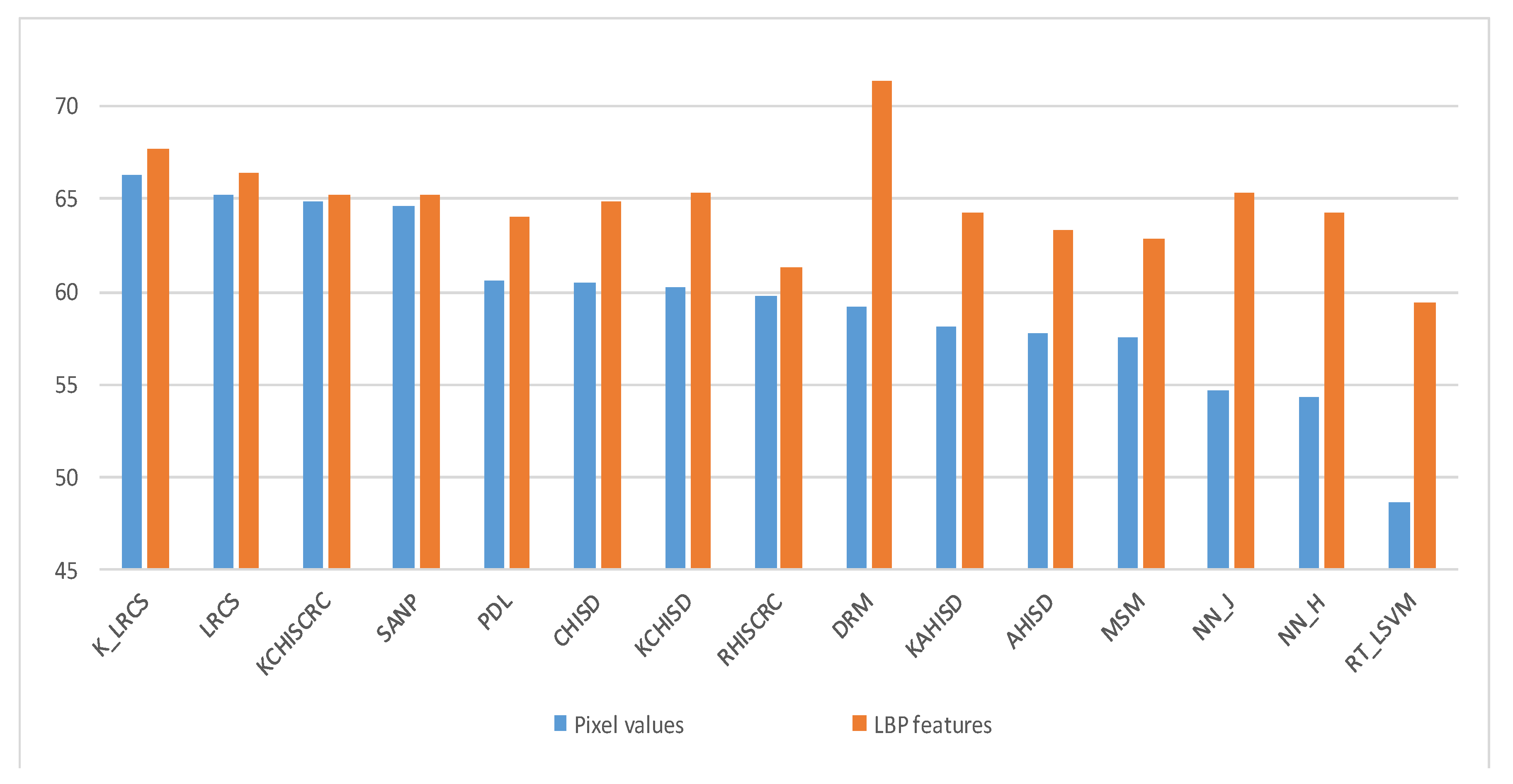
5.6. Dependence on the Features
To investigate the dependence of different methods on features (or feature extraction techniques), we evaluate their recognition performance on YTC dataset using two kinds of features: Pixel values and LBP features. The results are shown in
Figure 6. For the convenience of observation, various methods are sorted according to the recognition rates using pixel feature from the largest to the smallest. Obviously, the proposed models perform well consistently using whatever types of features, and the performance gaps between different features are small. Conversely, most of the methods compared depend heavily on specific kind of features, indicating that it is necessary to choose suitable feature extraction techniques for better performances. For example the DRM method even takes the LBP feature extraction as the first step of its model, the recognition performance drops dramatically once removing or replacing the LBP feature.
5.7. Robustness Comparisons
In this section, experimental results on the Honda and ETH-80 datasets are presented to investigate the robustness of different methods to random sparse corruptions and image-specific corruptions, respectively.
To test the robustness of different methods to random partial occlusions, we choose the Honda dataset for performance evaluation. Three occluded frames from three testing videos with partial occlusion are shown in
Figure 7. Since the number of the occluded videos is small, we supplement some by taking some videos from the clean subset and adding random sparse noise onto their feature (raw pixel) matrices to simulate the occluded videos. The random sparse noise is a matrix, 10% elements of which are randomly distributed values larger than 2 while the rest are all zeros. This is sufficiently gross corruptions for the normalized clean feature matrix whose entries are all between 0 and 1.
To test the robustness of different methods to image-specific corruptions (outliers), we choose the ETH-80 dataset for performance evaluation. The image-specific corruptions are generated by randomly replacing 20% columns of the clean feature matrix of each query set with random noise vectors as outliers. The original feature matrix of query set is full of two or three-digit integers while the outliers are anomalous vectors composed of decimals whose amplitudes do not exceed 3. So the outliers are entirely away from the feature space of query set. Then the corrupted query-set matrices are used for testing.
Table 6 gives the recognition results of various methods on two datasets of different kinds of corruptions. It is clear that the proposed robust model achieves the best matching performance under two kinds of gross corruptions, with just a little degradation from the non-corruption case. It can be observed that the proposed method has the 8% and 6% performance improvement on Honda and ETH-80 datasets respectively, compared to the second best method RHISCRC [
19]. The success of RHISCRC may come from the
-norm constraints used on both
a and
[
19] which enforce that only a few extremely similar images in query and gallery sets participate in constructing hulls and modelling. Thus the corrupted instances are circumvented. In contrast to the poor performance of RHISCRC on the Traffic dataset mentioned in
Section 5.5, we can see that the
-norm used here has both advantages and disadvantages, depending on different situations of data distribution.
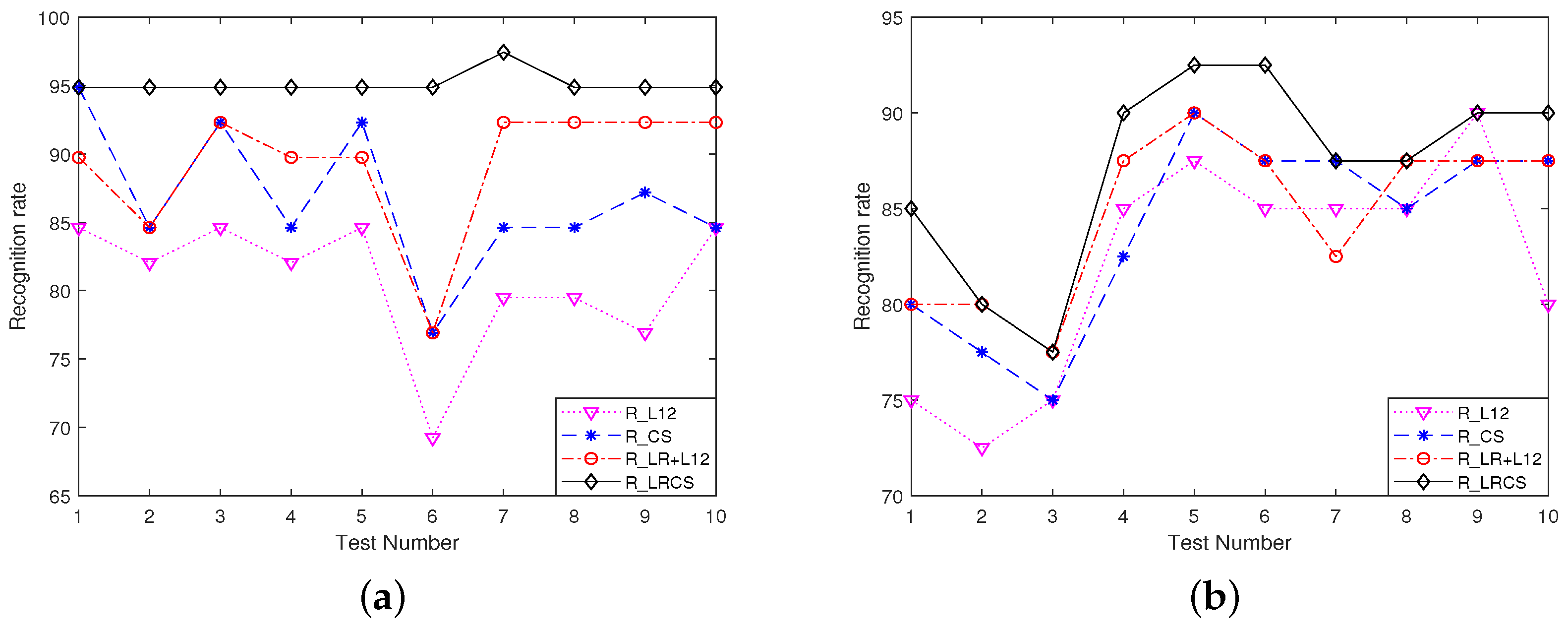
Furthermore, we also compare the robustness of different joint representation models under the two kinds of corruptions. In order to compare with the proposed R_LRCS fairly, we add the constrained terms standing for corruptions to the other competing joint representation models. For convenience, ‘R_’ abbreviation is added to their names. The recognition performances are illustrated in
Figure 8. It can seen that the proposed R_LRCS presents the best recognition rates all the time for two kinds of gross corruptions, indicating the superior robustness of our proposed model. It is also observed that in the majority of the test numbers, the two modified models with low rank regularization added, R_LRCS and R_LR+L12 both perform better than their respective single-constraint models, R_CS and R_L12. The proposed method takes advantage of the competition and collaboration not only within the gallery sets but also considering the inter-instance correlation within the query set. As such, the commonality and variations across the query-set images can be achieved simultaneously through the low rankness and class-level sparsity constraints on the representation coefficients.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}