Abstract
To solve the problem of passive sensor data association in multi-sensor multi-target tracking, a novel linear-time direct data assignment (DDA) algorithm is proposed in this paper. Different from existing methods which solve the data association problem in the measurement domain, the proposed algorithm solves the problem directly in the target state domain. The number and state of candidate targets are preset in the region of interest, which can avoid the problem of combinational explosion. The time complexity of the proposed algorithm is linear with the number of sensors and targets while that of the existing algorithms are exponential. Computer simulations show that the proposed algorithm can achieve almost the same association accuracy as the existing algorithms, but the time consumption can be significantly reduced.
1. Introduction
The problem of passive sensor data association, that is, deciding which measurement derived from which target in a multi-sensor multi-target tracking problem has been investigated for many years in radar, reconnaissance and wireless communications [1,2,3,4,5], etc. The objective of multi-sensor multi-target tracking is to detect an unknown number of targets and estimate their states using measurements from multiple passive sensors, such as the angle of arrival (AOA) [6,7]. Because of the mutual interference among multiple targets, data association becomes extremely important and essential.
However, the problem is especially complex and difficult. Because of the unknown corresponding relationship between measurements and targets, measurements from multiple passive sensors have to be first assigned to each possible target, which will lead to a combinatorial explosion as the number of senors and measurements increasing. Furthermore, in the presence of spurious measurements and missed detections of targets, a generalized association algorithm must allow for partial association and for unassigned measurements.
The traditional data association problem can generally be solved in the measurement domain with two steps. First, the data association problem is formulated as an S-dimensional (where S is the number of sensors) assignment problem [8,9,10], name as SDA problem. Then, the resulting SDA problem is solved by some optimal algorithms. However, the SDA problem is NP-hard for S ≥ 3 [11,12,13]. Therefore, the optimal solution algorithms, requiring an unacceptably long time, are of little practical value. Instead, suboptimal algorithms are more desirable.
One class of suboptimal algorithm to solve the SDA problem is the greedy heuristic algorithm. For example, the nearest neighbor (NN) heuristic algorithm [14] selects the assignment result with minimum cost in every loop. The tabu search algorithm [15] for the 3-D assignment problem introduces a so-called tabu list to store assignment results that are forbidden (i.e., tabu). The row-column algorithm [16,17] first arranges the cost vector of the SDA problem as a matrix and then finds the assignment result with the least value in a particular column.
Another alternative is the relaxation algorithm. Ref. [18] proposed a branch-and-band algorithm for the 3D assignment problem by using a Lagrangian relaxation. Refs. [19,20,21] developed a new iterative Lagrangian relaxation algorithm for the SDA problem. It introduced unconstrained Lagrangian multipliers to relax the SDA problem as a series of 2-D assignment subproblems, which can be solved in (n is the number of measurements from each sensor) time using the modified auction algorithm [22,23].
These traditional SDA algorithms described above, solve the passive data association problem in the measurement domain. They follow the estimation and association steps to solve the problem. Estimation is to estimate all possible candidate target states by using measurements from all sensors. Association is the decision process of linking candidate targets of a common origin (true target). The performance of these algorithms is application condition related and the time complexity of these algorithms is at least . This is because that formulate the SDA problem needs to traverse all possible measurements to measurements combinations to estimate all possible candidate targets states, whose time complexity is . It typically takes only about 10% CPU time for solving the SDA problem when compared with the time for formulating the SDA problem [19]. Therefore, these SDA algorithms will be time-consuming when the number of sensors and targets are large.
To solve this problem, one obvious idea is to discard some false candidate targets when formulating the SDA problem, but it also takes extra time to decide which candidate target is false. Motivated by this fact, a new direct data assignment (DDA) algorithm is proposed in this paper. The major contributions and innovations of this paper can be concluded as follows:
- The passive data association problem is solved in the target state domain. The estimation process is replaced with assumed known candidate target states. The time complexity of the proposed DDA algorithm is linear with the number of sensors and targets. This means that the proposed DDA algorithm is more efficient compared with existing SDA algorithms when the number of sensors and targets are large.
- The number and states of the candidate targets are preset in the proposed DDA algorithm by the definition of region of interest. The costs and assignment results associated with the candidate targets are calculated by using the known states. Thus, the combinatorial explosion problem can be avoided.
- The number of candidate targets and measurements decreases as the number of iterations increases in the proposed DDA algorithm. This will make the time consumption for each iteration less and less.
The rest of this paper is organized as follows. We formulate the passive sensor data association problem in consideration in Section 2. The generalized SDA problem is discussed in Section 3. The proposed DDA algorithm is illustrated in Section 4. Simulation results and conclusions are given in Section 5 and Section 6 respectively.
2. Problem Formulation
The passive sensor data association scenario is shown in Figure 1. There are T (T unknown) targets and S bearings-only sensors in the region of interest. The positions of target t and sensor s are and respectively. We wish to associate the measurements from S sensors of measurements to decide which measurement came from which target. The AOA measurements from sensor s are ,
where is the additive measurement noise of sensor s. We assume that is Gaussian white noise with zero mean and covariance . Considering the missed detections, a target may not be detected by sensor s. We usually add dummy measurements to each sensor. A dummy measurement from sensor s assigned to target means that this target was not detected by sensor s.
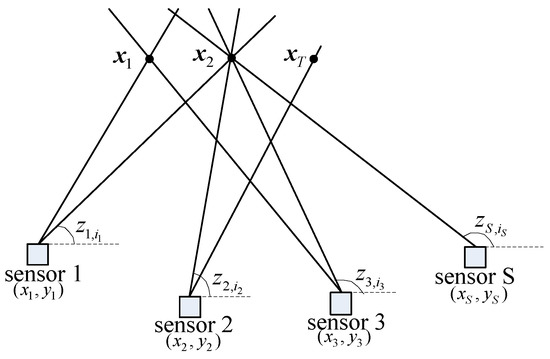
Figure 1.
Passive sensor data association scenario.
An S-tuple of measurements can be built by taking a measurement from each sensor, and the likelihood that originated from target t, with known target position , is
where is the probability of detection of sensor s, is an indicator function, and is the probability density function of measurement originated from ,
The likelihood that are all spurious or unrelated to target is
where is the field of view of sensor s.
The problem at hand now is to find the most likely set of S-tuples so that each measurement is assigned to at most one target or declared false, and each target receives at most one measurement from each sensor.
3. Generalized DA Problem
The existing SDA algorithms solves the passive sensor data association problem by first reformulating it as an SDA problem, which is given by [19] as follows:
subject to
where is the number of measurements by sensor s. is a binary variable such that if the S-tuple is included in the solution set. Otherwise, it is set to zero. is the cost of associating the S-tuple to target which can be calculated as follows according to [24]:
where is usually replaced by its maximum likelihood estimate .
The resulting SDA problem described above is NP-hard for , which can be solved by using the greedy heuristic algorithm or relaxation algorithm. It can be seen from (6) that the operation involved in constructing the SDA problem is , where n is the average number of measurements from each sensor and is the average time used to compute one cost of the S-tuple in (8). Therefore, the time complexity of the generalized SDA algorithms are at least , which is exponential with the number of targets and sensors.
Besides, as the actual position in (8) is unknown, it is usually replaced by the maximum likelihood estimate. This is a nonlinear optimization problem and can be solved by the iterative least squares (ILS) algorithm [25]. However, the ILS algorithm may converge to a local minimum solution when the measurement noise is at a high level, which can deteriorate the performance of the association results.
4. Linear-Time DDA Algorithm
The goal of passive sensor data association is to find the correct set of S-tuples such that all measurements from the same target are in the same S-tuple. The correct S-tuples are then used to determine the positions of the targets. Since the number and the positions of the targets are unknown, the generalized SDA algorithms follow the estimation and association steps to solve the problem. Estimation is to estimate all possible candidate targets and costs, which has a time complexity of . Association is the decision process of linking candidate targets of a common origin (true target).
It can be seen that the main reason for the high time complexity of the SDA algorithms is that the passive sensor data association problem is solved in the measurement domain. In contrast, the proposed DDA algorithm described below solves the association problem in the target state domain by first presetting candidate targets with known positions in the region of interest and then calculating the costs and S-tuples associated with the candidate targets. The assignment results are obtained by finding the candidate target with the minimum cost. It will be found that the time complexity of the proposed DDA algorithm is linear with the number of sensors and targets.
4.1. Mechanism of DDA Algorithm
Without loss of generality, it is assumed that there are two targets whose positions are and in the region of interest. Each sensor has a detection probability of and one spurious measurement per scan. If we have only one sensor to detect the targets, as shown in Figure 2a, only one measurement is assigned to the true target. We can just get the AOA measurements of the two targets.
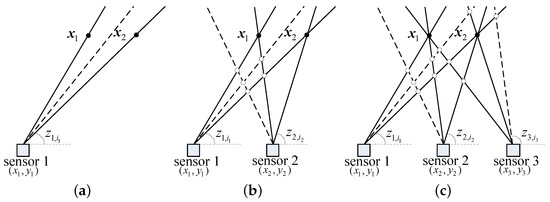
Figure 2.
Mechanism of the direct data assignment (DDA) algorithm. (a) One sensor to detect targets. (b) Two sensors to detect targets. (c) Three sensors to detect targets. — true measurement, - - - spurious measurement, • true target, ∘ false target.
If there are two sensors, as shown in Figure 2b, two true measurements from the two sensors are assigned to one of the true targets and then the position can be obtained using the triangulation algorithm [26]. Unfortunately, spurious and true measurements will also be assigned to some false targets. Thus, the true targets and false targets can not be distinguished if there is no prior information.
When the number of sensors increases to three, as shown in Figure 2c, three true measurements are assigned to the true target and only two spurious and true measurements are assigned to the false target. Therefore, the true target can be distinguished according to the number of assigned measurements.
As the number of sensors increases, the difference between true targets and false targets becomes more and more obvious.
However, using the number of assigned measurements to distinguish the true targets from the false targets may be inappropriate because of the the measurement noise. To overcome this problem, we can first define a cost function (similar to (8)) to evaluate the cost of the the th measurement of sensor s assigned to target , and then choose the -th measurement with the minimum cost . For S sensors, the S-tuple assigned to is , and the total cost of is
with
where is the measurement threshold, which can usually be set to . It can be seen that the measurement threshold is determined by the noise level of each sensor. When the noise level is high, the threshold is relatively large. Thus, measurements with large noise can also be assigned to the target. Besides, using the threshold can also abandon false measurements or measurements from other targets that are too far from the target. In this way, the mutual influence of measurements between the targets can be avoid. This will make the proposed algorithm still effective in low detection probability and high clutter density conditions.
According to (9), (11) and (12), the true targets can be easily distinguished from the false targets, since the true targets has a cost less than the false targets. The cost of false targets can be calculated through the false targets positions in (11) and (12).
The position of target is usually unknown in reality. However, the region of interest (i.e., all the detected targets are in this region) is generally known, as shown in Figure 3. K candidate targets with known positions can be preset in the region of interest, and then the cost in (9) is calculated using the candidate position . Thus, each candidate target corresponds to one association hypothesis. The candidate position with the minimum cost and desired associated S-tuple is obtained by traversing all candidate positions. The passive sensor data association problem is converted to a linear minimization problem in the target state domain. If there are multiple targets, we need to execute the above operations iteratively until all the measurements are assigned to a candidate target or some prespecified threshold.
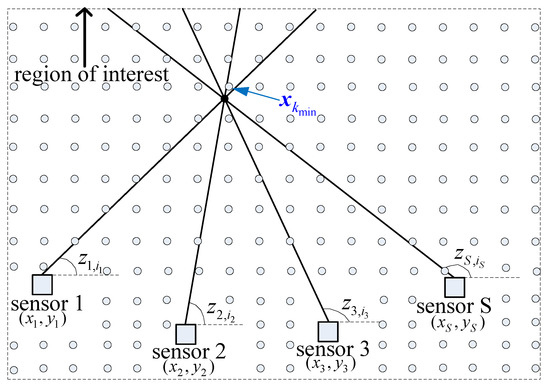
Figure 3.
Mechanism of the DDA algorithm. — true measurement, • true target, ∘ candidate target.
In addition, under the constraint that each measurement is assigned to at most one target or declared false, the assigned measurements after every iteration must be deleted from the measurement lists. Details of the DDA algorithm are shown in Algorithm 1.
From Algorithm 1, it can be found that the operations involved in each iteration are as follows: (1) operations for computing all possible costs in step 2, where is the average time used to compute one candidate cost using (11) and n is the average number of measurements from each sensor. (2) operations for computing in step 3, (3) operations for finding the candidate with minimum cost and delete related measurements in step 4.
Thus, the time complexity of the proposed DDA algorithm is ( is the number of iterations), which is linear with the number of sensors and targets.
| Algorithm 1. (DDA algorithm). |
| Step 1—initialization: |
| Construct the candidate target positions in the region of interest, |
| ; ; Total cost . |
| Step 2—compute all possible costs : |
| do |
| is computed using (11) through candidate target . |
| end do |
| Step 3—compute candidate cost and associated S-tuple: |
| do |
| . |
| where . |
| end do |
| Step 4—find candidate association with minimum cost and iteration: |
| if ; go to Step 5 |
| ; ; . |
| Delete related from measurement lists. |
| Go to Step 2. |
| Step 5—final result: |
| Number of Targets ; |
| S-tuples ; |
| Total cost . |
4.2. Termination Condition
It can be seen from Algorithm 1 that the S-tuple assigned to candidate target is . The likelihood that originated from is
The likelihood that are all spurious is
The negative log-likelihood ratio [24] can be defined as
If , the probability of originated from is smaller than the probability of are all spurious. In this case, the S-tuple may generate a false target.
Besides, will be updated at Step 2 and Step 3 of Algorithm 1 in every iteration. According to (9), (10) and (11), it can be found that
where and are the numbers of iterations in Algorithm 1. This is because that measurements assigned to candidate will be deleted in every iteration, and less measurements may makes a bigger with a bigger .
Therefore, the iteration of Algorithm 1 can be terminated if , and the total cost in Algorithm 1 is minimum. Besides, candidate targets with can be deleted in the process of iteration. Thus, the number of candidate targets and measurements decreases as the number of iterations increases, and the running time for each iteration will reduce.
4.3. Performance Analysis
In this subsection, we analyze the performance of the proposed DDA algorithm and the SDA algorithm. It can be seen from (15) and (8) that the cost of candidate target in the proposed DDA algorithm is similar to that in the SDA algorithm. However, the difference is obvious.
In the generalized SDA algorithm, the passive sensor measurements assignment problem is solved in the measurement domain. The position of candidate target is unknown before the association process. It can only be estimated after obtaining the associated S-tuple , and then the cost is calculated. The time complexity of this process is , which is exponential with n and S. Besides, the candidate position estimate may be inaccurate when the measurement noise is at a high level, which will deteriorate the performance of the algorithm.
However, in the proposed DDA algorithm, the passive sensor measurements assignment problem is solved in the target state domain. The position of candidate target is assumed known before the association process. The assumed known is used to find the associated S-tuple , and calculate the cost accordingly. The time complexity of this process is , which is linear with n and S.
Therefore, the proposed DDA algorithm is more efficient than the SDA algorithm when the number of sensors and targets are large. Besides, because the candidate target position is assumed known in the proposed DDA algorithm, the measurement threshold can be used in (12) to abandon measurements that are far from the candidate target.
For example, there are five sensors and one target in the region of interest, as shown in Figure 4. Senors 1–3 detect the target signal and generate three measurements , and . Sensors 4 and 5 have missed detections and two spurious measurements and , with for . The S-tuple result of the proposed DDA algorithm is . While for SDA algorithm, the the cost of S-tuple may be bigger than the cost of S-tuple in some cases. So the output S-tuple result is .
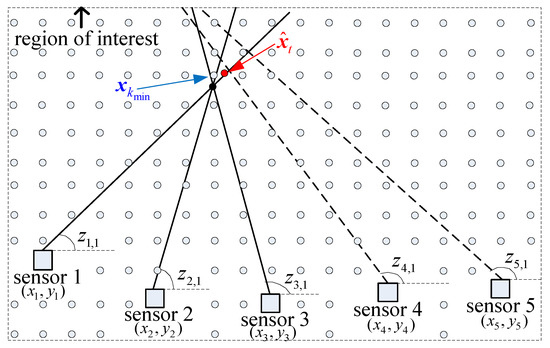
Figure 4.
Threshold to abandon measurements far from the candidate target. — true measurement, - - - spurious measurement, • true target, ∘ candidate target.
4.4. Initialization of Candidate Targets
It can be observed from Figure 4 that the main factors affecting the performance of the proposed DDA algorithm is the number of candidate targets. If we have enough candidate targets in the region of interest, T (T is the number of true targets) candidate targets will be very close to the true targets. The true S-tuples of measurements associated with the T targets can be easily obtained in this case. However, the time complexity of the proposed DDA algorithm is linear with the number of candidate targets. More candidate targets lead to more time consumption.
There are many algorithms that can be used to initialize the positions of candidate targets, such as the multiple grid algorithms [27,28], particle swarm optimization (PSO) algorithms [29], etc. Here, we use the simple grid-based algorithm [30]. The grid spacing , which is the distance between each two candidate targets, is related to the Cramér–Rao lower bound (CRLB) [31] of localization error.
The CRLB is usually used to evaluate the variance lower bound of any unbiased estimator [32]. This means that two targets are theoretically indistinguishable when the distance between them is less than two times of the CRLB. To be more secure, the grid spacing can be approximately set to one time of the CRLB,
where denotes the trace of a matrix. The derivation of is given in Appendix A.
In this way, the grid spacing strictly depends on the position of the candidate target which is known in advance. In practice, we can randomly select an initial candidate target in the region of interest, and the position of the next candidate target is determined by the CRLB of the current candidate target, as shown in Figure 5. It can be seen that the closer to the sensors, the higher the density of candidate targets. This is because the CRLB is smaller when the candidate target is closer to the sensors.
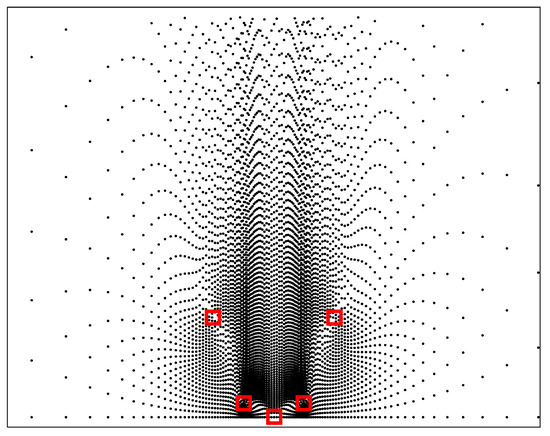
Figure 5.
Geometry of candidate targets. □ sensor, · candidate target.
Besides, the system observability [33,34] may affect the performance of the proposed algorithm. For example, if the sensors and targets are distributed on a line, as shown in Figure 6, the position of the target is theoretically unavailable.
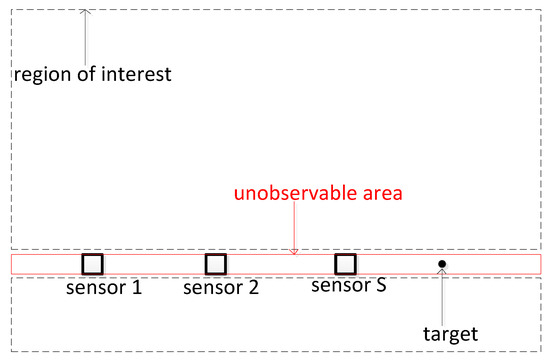
Figure 6.
Geometry of unobservable area and region of interest.
In order to avoid producing incorrect assignment results from the absence of system observability, a feasible solution is to first remove the unobservable area from the region of interest in our proposed algorithm. Thus, the wrong assignment results can be avoided in the absence of observability, as shown Figure 6.
5. Computer Simulation
The simulation scenario is shown in Figure 7. There are S sensors at known fixed locations in a semicircle of radius 1000 km, and the position of sensor s is km, . The targets are symmetrically distributed on the x-axis with km, different x. The region of interest is the area with km and km. The candidate targets of the proposed DDA algorithm are uniformly distributed in the region of interest. The sensors are assumed to be forward looking with a field of view of . The detection probability of each sensor is .
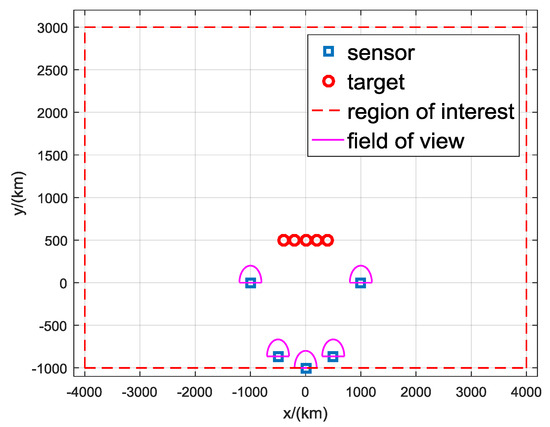
Figure 7.
Geometry used in simulation.
The performance of the proposed DDA algorithm is compared with that of two kinds of SDA algorithms, the row–column algorithm in [16] and the Lagrangian relaxation algorithm in [19]. The positions and costs of the candidate targets in the SDA algorithms are estimated by using the ILS algorithm. Estimated candidate targets with a cost greater than zero are first deleted in the process of forming the SDA problem [19].
Six typical cases are investigated in this section. The first is used to test the performance of proposed algorithm for different grid spacing. The second is carried out for different numbers of sensors. The third is done for different number of targets. The fourth is simulated for different measurement noise levels. The fifth is done in different detection probabilities. The last one is simulated in a challenge scenario. Three kinds of scenarios, normal, high clutter and poor separated, are performed. Details of the three scenarios are shown in Table 1. The number of spurious measurements for each sensor is in the normal scenario, and in the high clutter scenario. The distance between each two targets is about 20% of the distance between sensors and targets in the normal scenario, which is about 4% in the poor separated scenario.

Table 1.
Parameters of three scenarios.
The association accuracy p and root mean square error (RMSE) [32] are computed over ensemble runs, which are defined as follows.
where and are the number of correct associated measurements and all measurements, and is the target position estimate at ensemble i.
The positions of the targets are estimated by using the assignment results. If the association accuracy is low, the estimated positions is far away from positions of the true targets, and the is relatively large. Besides, a lower association accuracy means more false assignment results, which lead to a larger number of false targets.
5.1. Simulation Results of Case 1
The performance affected by the grid spacing was studied in this case. There were five sensors and five targets in the simulation. The measurement noise standard deviation of all sensors were equal to and the grid spacing is from to .a
Simulation results of normal scenario is shown in Table 2. It can be seen that the association accuracy was the same when grid spacing was less than , but the time consumption decreased with the increase of grid spacing.
Table 2.
Simulation results of normal scenario with different grid spacing.
Table 3 and Table 4 illustrate the results of high clutter and poor separated scenario respectively. The conclusions were consistent with that in the normal scenario. When the grid spacing is less than , reducing the grid spacing has no effect on the association accuracy of the proposed DDA algorithm, but it will increase the time consumption.
Table 3.
Simulation results of high clutter scenario with different grid spacing.
Table 4.
Simulation results of poor separated scenario with different grid spacing.
The number of spurious measurements in a high clutter scenario was more than that in the normal scenario, which led to more false intersections and computations. Thus, the association accuracy was lower, while the average run time was greater, as shown in Table 3. Besides, poor separated targets result in a lower measurement discrimination, which leads to a lower association accuracy, as shown in Table 4.
5.2. Simulation Results of Case 2
The performance affected by the number of sensors was studied in this case. Three kinds of scenarios were simulated with 3, 5 and 7 sensors. The number of targets was five and the measurement noise standard deviation was equal to . The grid spacing was .
Simulation results of the normal scenario is shown in Table 5. Evidently, increasing the number of sensors can increase the association accuracy, but it also leads to an increase in time consumption. The association accuracy of the proposed algorithm was almost the same with the relaxation algorithm but a little superior to the row–column algorithm. We think the reason for a little higher association accuracy may be that the threshold has been used in the proposed algorithm. Thus, the spurious measurements that are too far from the candidate targets can be abandoned, which may improve the association accuracy, as shown in Figure 4. The average run time of the proposed algorithm increased from 1.1 s with three sensors to 4.2 s with seven sensors. However, the time consumption of the relaxation algorithm and the row–column algorithm with seven sensors were 407 and 386 s respectively. This is because that the time complexity of the proposed algorithm is linear with the number of sensors while that of the relaxation algorithm and row–column algorithm are exponential.
Table 5.
Simulation results of normal scenario with different number of sensors.
In Table 6, simulation results of high clutter scenario are presented. The time consumption superiority of the proposed algorithm can still be maintained in this scenario. The average run time of the proposed algorithm with seven sensors was 4.6 s. However, the relaxation algorithm had an average run time of 2736 s with seven sensors.
Table 6.
Simulation results of high clutter scenario with different number of sensors.
Table 7 shows simulation the results of poor separated scenario. It can be seen that the association accuracy of the proposed algorithm is similar to that of the relaxation algorithm and row–column algorithm, but the average run time of the proposed algorithm was significantly less. Interestingly, the association accuracy cannot be significantly improved by increasing the number of sensors. This is because that the distance between every two targets is too small, the measurements come from different targets that are indistinguishable.
Table 7.
Simulation results of poor separated scenario with different number of sensors.
5.3. Simulation Results of Case 3
The performance affected by the number of targets was studied in this case. Three kinds of scenarios were simulated with 5, 7 and 9 targets. The number of sensors was five and the measurement noise standard deviation was equal to . The grid spacing is .
Simulation results of normal scenario are shown in Table 8. It can be seen that the association accuracy decreases as the number of targets increases. This is because more targets generate more measurements, resulting in more measurement interactions and ghosts targets. The association accuracy of the proposed algorithm was still almost the same with the relaxation algorithm but superior to the row–column algorithm. The average run time of the proposed algorithm was still less than that of the relaxation algorithm and arow column algorithm.
Table 8.
Simulation results of normal scenario with different number of targets.
Table 9 and Table 10 show the results of high clutter and poor separated scenarios respectively. The conclusions were consistent with the normal scenario. Since more spurious measurements were generated with higher clutter density, the average run time of high clutter scenario was more than that of normal scenario, and the association accuracy is relatively lower, as shown in Table 9. Since the targets were undistinguishable in poor separated scenario, the three algorithms had almost the same association accuracy, as shown in Table 10.
Table 9.
Simulation results of high clutter scenario with different number of targets.
Table 10.
Simulation results of poor separated scenario with different number of targets.
5.4. Simulation Results of Case 4
To further illustrate the advantage of the proposed algorithm, a comparison between different measurement noise levels was made. This simulation contained five sensors and five targets. The measurement noise standard deviations of all sensors were , and the grid spacing was .
Simulation results of the normal scenario are shown in Table 11. An obvious trend is that the large standard deviation of noise resulted in unreliable data association because a large may cause the measured value to deviate farther from the real one, creating more ghosts. The association accuracy of the proposed algorithm was still almost the same with the relaxation algorithm and higher than the row column algorithm. Because the CRLB increased as the increased, the grid spacing also increased. So the number of candidate targets in the proposed algorithm decreased, resulting in a lower run time.
Table 11.
Simulation results of normal scenario with different .
In Table 12 and Table 13, we present the simulation results of high clutter scenario and poor separated scenario. High clutter density led to a lower association accuracy and more number of false targets. Interestingly, the RMSE in poor separated scenario with and are smaller than those in normal scenario. The reason is that measurements came from adjacent targets are undistinguishable in poor separated scenario. When the measurement noise standard deviation was large, the localization error caused by the measurement noise became larger than the distance from each two targets.
Table 12.
Simulation results of high clutter scenario with different .
Table 13.
Simulation results of poor separated scenario with different .
5.5. Simulation Results of Case 5
To further show the boundary of the proposed algorithm, a comparison between different detection probabilities was made. This simulation contained five sensors and five targets. The detection probability of all sensors are . The measurement noise standard deviation was equal to , and the grid spacing was .a
Simulation results are shown in Table 14. One obvious trend is that the lower detection probability results in lower association accuracy because a lower makes fewer true measurements, creating fewer true targets. The association accuracy of the proposed algorithm was still almost the same with the relaxation algorithm and higher than the row–column algorithm. Because the number of measurements decreased as the decreased, the average run time was also decreased.
Table 14.
Simulation results of normal scenario with different .
5.6. Simulation Results of Case 6
To further verify the performance of the proposed algorithm under challenge scenarios, a comparison with targets was not separated in AOA measurements is made. This simulation contains five sensors with the same positions as noted above. There are five targets with the positions of km, km, km, km, km, as shown in Figure 8. The true AOA measurements of the five targets measured by the five sensors are shown in Table 15. It can be seen that some the five targets are very poor separated in AOA measurements. The clutter density is 0.8/rad and the detection probability is 0.9. Simulations are done with different measurements noise levels .
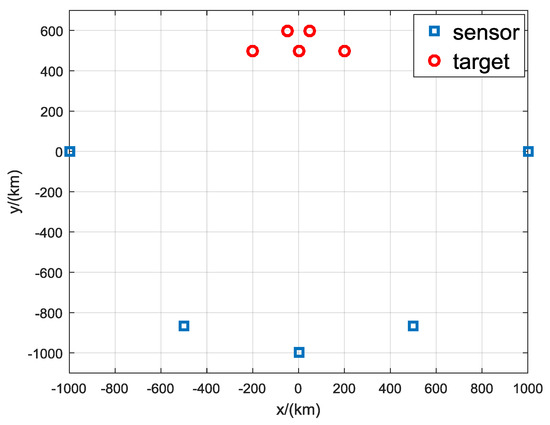
Figure 8.
Geometry of a more challenging scenario.
Table 15.
The true AOA measurements of the five targets measured by the five sensors.
Simulation results are shown in Table 16. It can be seen that the association accuracy decreases as the noise levels increase, which is the same as Case 4. The association accuracy of the proposed algorithm is still almost the same with the relaxation algorithm and higher than the row–column algorithm. One may realize that the association accuracy in Table 16 is relatively lower than that in Table 11. This is because some of the targets were not separated in AOA measurements, which will generate some unresolved targets.
Table 16.
Simulation results of a challenging scenario with different .
6. Conclusions
To solve the problem of passive sensor data association, a linear-time DDA algorithm is proposed in this paper. Different from existing algorithms that solve the problem in the measurement domain, the proposed DDA algorithm solves the problem directly in the target state domain. The number and state of candidate targets are preset by the definition of region of interest, which can avoid the problem of combinational explosion. The time complexity of the proposed DDA algorithm is linear with the number of sensors and targets while that of the existing algorithms is exponential. Since the positions of the preset candidate targets are known, the threshold can be used to abandon spurious measurements that are far from the candidate targets. Simulations are performed with three kinds of scenarios; normal, high clutter, and poor separation, which show that the proposed DDA algorithm has a significantly lower run time and can achieve almost the same association accuracy as existing algorithms.
Author Contributions
C.H., M.Z., G.W. and F.G.; data curation, C.H.; formal analysis, C.H.; funding acquisition, M.Z.; investigation, C.H., M.Z. and G.W.; methodology, C.H. and M.Z.; project administration, C.H. and M.Z.; resources, C.H. and G.W.; software, C.H.; visualization, C.H. and F.G.; writing—original draft, C.H.; writing—review and editing, C.H., M.Z., G.W. and F.G.
Funding
This study was supported by the National Natural Science Fund of China (No. 61901494), CASIC Aerospace Science and Technology Fund of China (No. 179000203) and Shanghai Aerospace Science and Technology Innovation Fund of China (No. SAST2015028).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. CRLB of Localization Error
This appendix derives the CRLB of , denoted as . It is defined as the inverse of the Fisher matrix defined as [32]
where is the probability function
where is the measurement vector, and is the covariance matrix. Without loss of generality, it is assumed that the measurement noise of all sensors is independent and the covariance is equal to .
After performing differentiation, the CRLB of is
References
- Yoon, K.; Kim, Y.D.; Yoon, Y.C.; Jeon, M. Data Association for Multi-Object Tracking via Deep Neural Networks. Sensors 2019, 19, 559. [Google Scholar] [CrossRef] [PubMed]
- Singh, G.; Rajan, S.; Majumdar, S. A Fast-Iterative Data Association Technique for Multiple Object Tracking. Int. J. Semant. Comput. 2018, 12, 261–285. [Google Scholar] [CrossRef]
- Xie, Y.; Huang, Y.; Song, T.L. Iterative joint integrated probabilistic data association filter for multiple-detection multiple-target tracking. Digit. Signal Process. 2018, 72, 232–243. [Google Scholar] [CrossRef]
- Liu, M.; Jin, C.; Yang, B.; Cui, X.; Kim, H. Online multiple object tracking using confidence score-based appearance model learning and hierarchical data association. IET Comput. Vis. 2019, 13, 312–318. [Google Scholar] [CrossRef]
- Zhou, B.; Bose, N.K. A comprehensive analysis of ’Neural solution to the multitarget tracking data association problem’ by D. Sengupta and R.A. Iltis (1989). IEEE Trans. Aerosp. Electron. Syst. 1993, 29, 260–263. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, C.; Yu, P.S. Direction-of-Arrival Estimation Based on Deep Neural Networks With Robustness to Array Imperfections. IEEE Trans. Antennas Propag. 2018, 66, 7315–7327. [Google Scholar] [CrossRef]
- Yang, Z.; Xie, L.; Zhang, C. Off-Grid Direction of Arrival Estimation Using Sparse Bayesian Inference. IEEE Trans. Signal Process. 2013, 61, 38–43. [Google Scholar] [CrossRef]
- Blackman, S.S. Multiple hypothesis tracking for multiple target tracking. IEEE Aerosp. Electron. Syst. Mag. 2004, 19, 5–18. [Google Scholar] [CrossRef]
- Popp, R.; Kirubarajan, T.; Pattipati, K. Survey of Assignment Techniques for Multitarget Tracking; Artech House: Norwood, MA, USA, 2000. [Google Scholar]
- Bar-Shalom, Y.; Kirubarajan, T.; Lin, X. Probabilistic data association techniques for target tracking with applications to sonar, radar and EO sensors. IEEE Aerosp. Electron. Syst. Mag. 2005, 20, 37–56. [Google Scholar] [CrossRef]
- Sathyan, T.; Sinha, A. A Two-Stage Assignment-Based Algorithm for Asynchronous Multisensor Bearings-Only Tracking. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 2153–2168. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Blair, W.D. Multitarget-Multisensor Tracking Applications and Advances Vol III; Artech House: Boston, MA, USA, 2000. [Google Scholar]
- Andrijich, S.M.; Caccetta, L. Solving the multisensor data association problem. Nonlinear Anal. 2001, 47, 5525–5536. [Google Scholar] [CrossRef]
- Rong Li, X.; Bar-Shalom, Y. Tracking in clutter with nearest neighbor filters: Analysis and performance. IEEE Trans. Aerosp. Electron. Syst. 1996, 32, 995–1010. [Google Scholar] [CrossRef]
- Magos, D. Tabu search for the planar three-index assignment problem. J. Glob. Optim. 1996, 8, 35–48. [Google Scholar] [CrossRef]
- Deb, S.; Pattipati, K.; bar shalom, Y.; Washburn, R. Assignment Algorithms For The Passive Sensor Data Association Problem. Int. Soc. Opt. Eng. 1989, 1096, 231–246. [Google Scholar] [CrossRef]
- Pattipati, K.R.; Deb, S. Comparison of assignment algorithms with applications to the passive sensor data association problem. In Proceedings of the ICCON IEEE International Conference on Control and Applications, Jerusalem, Israel, 3–6 April 1989; pp. 317–322. [Google Scholar] [CrossRef]
- Poore, A.; Rijavec, N. A Lagrangian relaxation algorithm for multidimensional assignment problems arising from multitarget tracking. Siam J. Optim. 1993, 3, 544–563. [Google Scholar] [CrossRef]
- Somnath, D.; Murali, Y.; Krishna, P.; Bar-Shalom, Y. A generalized S-D assignment algorithm for multisensor-multitarget state estimation. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 523–538. [Google Scholar] [CrossRef]
- Chummun, M.R.; Kirubarajan, T.; Pattipati, K.R.; Bar-Shalom, Y. Fast data association using multidimensional assignment with clustering. IEEE Trans. Aerosp. Electron. Syst. 2001, 37, 898–913. [Google Scholar] [CrossRef]
- Deb, S.; Pattipati, K.R.; Bar-Shalom, Y. Passive-sensor data association for tracking: A PC software. Proc. SPIE Int. Soc. Optim. Eng. 1990, 1305, 274–286. [Google Scholar] [CrossRef]
- Bertsekas, D.P. The auction algorithm: A distributed relaxation method for the assignment problem. Ann. Oper. Res. 1988, 14, 105–123. [Google Scholar] [CrossRef]
- Pattipati, K.R.; Deb, S.; Bar-Shalom, Y.; Washburn, R.B. A new relaxation algorithm and passive sensor data association. IEEE Trans. Autom. Control 1992, 37, 198–213. [Google Scholar] [CrossRef]
- Kaplan, L.M.; Bar-Shalom, Y.; Blair, W.D. Assignment costs for multiple sensor track-to-track association. IEEE Trans. Aerosp. Electron. Syst. 2008, 44, 655–677. [Google Scholar] [CrossRef]
- Torrieri, D.J. Statistical Theory of Passive Location Systems. IEEE Trans. Aerosp. Electron. Syst. 1984, AES-20, 183–198. [Google Scholar] [CrossRef]
- Guo, F.; Fan, Y.; Zhou, Y.; Zhou, C.; Li, Q. Space Electronic Reconnaissance: Localization Theories and Methods; Wiley: Hoboken, NJ, USA, 2014; pp. 47–63. [Google Scholar]
- Ni, R.H. A Multiple-Grid Scheme for Solving the Euler Equations. AIAA J. 1982, 20, 1565–1571. [Google Scholar] [CrossRef]
- Chima, R.; Johnson, G. Efficient solution of the Euler and Navier-Stokes Equations with a vectorized multiple-grid algorithm. AIAA J. 1983, 23. [Google Scholar] [CrossRef]
- Nebro, A.J.; Durillo, J.J.; Garcia-Nieto, J.; Coello Coello, C.A.; Luna, F.; Alba, E. SMPSO: A new PSO-based metaheuristic for multi-objective optimization. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence in Multi-Criteria Decision-Making (MCDM), Nashville, TN, USA, 30 March–2 April 2009; pp. 66–73. [Google Scholar] [CrossRef]
- Yang, S.; Li, M.; Liu, X.; Zheng, J. A Grid-Based Evolutionary Algorithm for Many-Objective Optimization. IEEE Trans. Evol. Comput. 2013, 17, 721–736. [Google Scholar] [CrossRef]
- Li, Y.; Qi, G.; Sheng, A. Performance Metric on the Best Achievable Accuracy for Hybrid TOA/AOA Target Localization. IEEE Commun. Lett. 2018, 22, 1474–1477. [Google Scholar] [CrossRef]
- Kay, S.M. Fundamentals of Statistical Signal Processing, Estimation Theory; Prentice-Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Cadre, J.; Jauffret, C. Discrete-time observability and estimability analysis for bearings-only target motion analysis. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 178–201. [Google Scholar] [CrossRef]
- Nardone, S.; Aidala, V. Observability Criteria for Bearings-Only Target Motion Analysis. IEEE Trans. Aerosp. Electron. Syst. 1981, AES-17, 162–166. [Google Scholar] [CrossRef]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).