1. Introduction
In recent years, with the rapid development of cloud computing and artificial intelligence technology, the Internet of Things technology has also ushered in vigorous development. Various intelligent devices can receive a large amount of information through data exchange and interconnection. The popularity of the Internet of Things technology and the intelligence of devices have brought great convenience to people, but the use of new technologies and smart devices has also brought new security and privacy risks [
1,
2,
3]. As the Internet of Things nodes collect and store large amounts of user privacy data, Internet of Things systems have become important targets for cyber attackers. In this case, protecting personal privacy and data security is very important [
4,
5,
6].
With the progress of technology and the continuous reduction in manufacturing costs, the Internet of Things system composed of unmanned aerial vehicles (UAVs) has entered industrial production and people’s daily life from the military field. Nowadays, UAVs have been widely used in film and television shooting, agricultural monitoring, meteorological monitoring, forest fire detection, emergency rescue, and other fields. However, while UAVs bring various conveniences to our production and life, the network security problems they face have been gradually exposed [
7,
8].
When multiple UAVs cooperate to perform tasks, it is necessary to build information connection channels between them to form a mobile self-organizing network of UAVs. The UAVs in the network realize the real-time sharing of information through this mobile network, which no longer needs to be forwarded by a ground station, and this effectively improves the survivability and combat ability of the UAV group. As a UAV network is a subclass of the mobile ad hoc network, the common attacks in the mobile ad hoc network will also threaten the UAV network.
Due to the diversity of network access methods and the openness of networks, UAV networks are facing inevitable security threats [
9,
10,
11,
12]. The defense function of traditional network security technology is mostly passive, and it is difficult to resist network attacks with changeable technology. As an active defensive network security technology, intrusion detection technology makes up for the shortcomings of traditional security technology [
13,
14,
15,
16].
While intrusion detection systems have attracted much attention from users, there are still some problems to be improved in their practical application. Traditional intrusion detection systems generally suffer from an insufficient performance and inefficiency, especially in modern computer networks with high bandwidth and large traffic. In the face of attacks, which are becoming more and more complex, automated, and distributed, traditional intrusion detection systems cannot meet the needs of current network security. In order to improve the detection efficiency and reduce the false alarm rate of intrusion detection systems, more and more researchers have introduced machine learning algorithms into the field of intrusion detection and have made good progress [
17,
18,
19,
20,
21].
Shah et al. [
22] investigated the performance of two open-source intrusion detection systems, Snort and Surcata. The results show that using an optimized support vector machine (SVM) and firefly algorithm can achieve the best detection effect. Kabir et al. [
23] proposed a new method based on a least-squares support vector machine (LS-SVM) for an intrusion detection system. Wang et al. [
24] proposed an intrusion detection framework based on the SVM, with feature augmentation. By transforming the logarithmic marginal density ratio to form original features, new and better transform features can be obtained, which greatly improves the detection ability of the model. Ahmed et al. [
25] proposed a learning algorithm for an intrusion detection system based on a neural network (NN), which has a good performance in terms of its convergence speed and learning time. Hu et al. [
26] proposed a distributed intrusion detection framework, in which a local parameterized detection model is constructed in each node using the online Adaboost algorithm. Ma et al. [
27] proposed a novel approach called SCDNN, which combines spectral clustering (SC) and deep neural network (DNN) algorithms. The experimental results indicate that the SCDNN classifier performs better than the back-propagation neural network and support vector machine.
However, with the deepening of research, deep learning has gained wider application and a more outstanding performance in massive data analysis, which can be used to solve intrusion detection problems of massive, high-dimensional, and nonlinear data. By constructing a nonlinear network structure with multiple hidden layers, low-dimensional features, which are easier to classify in the data, can be obtained, and the accuracy of intrusion detection is improved [
28,
29,
30,
31,
32]. Hinton et al. [
33] proposed a deep learning method, called a deep belief network, which has attracted wide attention in academic circles. The deep belief network can transform high-dimensional and nonlinear data features into abstract features, which are more suitable for pattern classification, through layer-by-layer feature extraction. Qu et al. [
34] proposed an intrusion detection model based on a deep belief network, which effectively improves the detection of abnormal data. Liang et al. [
35] proposed an intrusion detection method based on a deep belief network and extreme learning machine, which improves the recognition rate of intrusion detection and the efficiency of the algorithm operation.
The number of nodes in the hidden layer of a deep belief network is not easy to determine. In this paper, the particle swarm optimization (PSO) algorithm is used to find the optimal number of hidden layer nodes. Common intelligent search algorithms include the genetic algorithm [
36,
37], ant colony algorithm [
38,
39], simulated annealing algorithm [
40], and particle swarm optimization. The genetic algorithm cannot effectively converge in a limited time. The ant colony algorithm is slow in terms of its solving time and is prone to prematurity. The actual effect of the simulated annealing algorithm is greatly affected by the parameters, including the global optimization and calculation efficiency. The Bayesian optimization algorithm [
41] is also commonly used for hyperparameter optimization. Its advantage is that it has fewer iterations, but it is easy to fall into local optimization. The PSO algorithm is easy to understand, easy to implement, fast in convergence, and can obtain the global optimal solution. Therefore, the PSO algorithm is selected as the optimization algorithm. The PSO algorithm is a kind of evolution algorithm based on a population. Through individual cooperation and group sharing, particles find the optimal solution of individuals and the optimal solution of the whole community to complete the optimization. Aburomman et al. [
42] proposed a novel ensemble construction method that uses PSO-generated weights to create an ensemble of classifiers, which has a better accuracy in intrusion detection. Bamakan et al. [
43] proposed an attack detection method based on multi-criteria linear programming and the PSO algorithm to improve the accuracy of attack detection.
In this paper, the deep learning method of the deep belief network (DBN) and the parameter optimization method of the PSO are introduced into the field of intrusion detection, and an intrusion detection model based on the PSO-DBN is proposed. The model uses the PSO algorithm to optimize the number of nodes in the DBN hidden layer to obtain the optimal network structure. Then, each restricted Boltzmann machine (RBM) network is trained from the bottom to the top, and the low-dimensional representation of the original data is obtained in the unsupervised learning process, which significantly reduces the dimensionality of the data, retains key features of the data, and removes the redundancy features. Finally, the back-propagation (BP) algorithm is used to classify the low-dimensional representation and fine-tune the RBM network at the same time. The PSO-DBN method, proposed in this paper, is compared to the artificial neural network (ANN), SVM, Adaboost, and DNN methods using the KDD Cup 99 dataset [
44]. The experimental results show that the optimization effect of PSO is better than those of the genetic algorithm, simulated annealing algorithm, and Bayesian optimization algorithm, and the PSO-DBN model is superior to other machine learning methods, which effectively improves the accuracy of intrusion detection.
The remaining sections of this paper are organized as follows.
Section 2 describes the principle of the DBN.
Section 3 describes the parameter optimization based on the PSO algorithm.
Section 4 describes the intrusion detection based on the PSO-DBN.
Section 5 describes the experimental results and discussion, including the dataset, evaluation indicators, results, and comparison. Finally,
Section 6 summarizes the paper.
2. Principle of the DBN
The detection model based on the DBN method is shown in
Figure 1. The input layer includes five types of network data, including the Normal, Probing, DoS, U2R, and R2L data. A DBN is a neural network model, composed of multiple RBMs. When applying a DBN network in intrusion detection, the network structure should be trained first, to determine the connection weight and neuron bias of the network. The DBN mainly includes pre-training and reverse fine-tuning in the process of training the model. First, each layer of the RBM network is trained independently and unsupervised in the pre-training process to ensure that as much feature information as possible is retained when the feature vectors are mapped to different feature spaces. Then, the BP network is set-up in the last layer of the DBN, and the output eigenvector of the RBM is received as its input eigenvector. Then, supervised training is conducted for the entity relationship classifier. Moreover, each layer of the RBM network can only ensure that the weights in its own layer are optimal for the feature vector mapping of that layer, not for the whole DBN. Therefore, it is necessary for the BP network to spread error information, from top to bottom, in each layer of the RBM and fine-tune the DBN network. The process of training the model of the RBM network can be regarded as the initialization of the weights of a deep BP network, which makes the DBN overcome the shortcomings of the BP network, which easily falls into the local optimum due to the random initialization of weights.
A single RBM is a neural network model consisting of a visible layer and a hidden layer [
45].
Figure 1 shows a network structure consisting of 3 layers of the RBM, where
is the visible layer connecting the intrusion detection data,
is the hidden layer, which is used to extract the effective features of the input data, and
is the connection weight of the visible layer and the hidden layer. The neurons of the same layer in the network structure are not connected to each other, and the neurons of the adjacent layers are connected to each other by weights. The inactivated and activated states are represented by a binary, 0 and 1, for neurons in the network.
The RBM is an energy-based model [
46], where
is used to represent the state of neuron
in the visible layer, with corresponding bias
,
is used to represent the state of neuron
in the hidden layer, with corresponding bias
, and the connection weight of neuron
and
is
. The energy of the RBM can be expressed as
In the equation, is the RBM parameter, and and are the number of neurons in the visible layer and hidden layer, respectively.
From the energy function, the joint probability distribution of
can be obtained as follows:
where
is the normalization factor.
For the training sample with the number of
, parameter
is obtained by learning the maximum logarithmic likelihood function of the sample, which is
where
is the likelihood function of
.
In the process of training, due to the complexity of calculating the normalization factor
, Gibbs and other sampling methods are generally used to approximate it [
47]. Hinton proposed a fast learning algorithm using contrast divergence (CD) to train the network parameters, which improves the training efficiency and promotes the development of the RBM. The CD algorithm calculates the state of the neurons in the hidden layer by the vector value of the neurons in the visible layer, and then reconstructs the state of the neurons in the visible layer using the neurons in the hidden layer and calculates the state of the neurons in the hidden layer again using the reconstructed neurons in the visible layer, so that a new state of the neurons in the hidden layer can be obtained.
As the activation states of each neuron in the same layer of the RBM are independent of each other, the
jth neuron in the hidden layer is calculated according to the state of the neurons in the visible layer, and the activation probability is as follows:
where
is the sigmoid activation function.
The
ith neuron in the visible layer is reconstructed by the hidden layer, and the activation probability is as follows:
Further, the updated equations of the RBM weights and bias parameters can be obtained as follows:
Among them, is the distribution, defined by the model of the original intrusion detection data, is the distribution defined by the reconstructed model, is the learning rate, is the number of iterations of the CD algorithm, is the updated weight matrix, and and are the bias vectors, after the visible layer and the hidden layer have been updated.
3. Parameter Optimization Based on the PSO Algorithm
The PSO algorithm is inspired by the behavioral characteristics of bird predation and is used to solve the optimization problem. Each particle in the algorithm represents a potential solution to the problem, and each particle corresponds to a fitness value, which is determined by the fitness function. The velocity of the particle determines the direction and distance of the particle movement. The velocity is dynamically adjusted to the movement experience of the particle itself and other particles, thus realizing the optimization of the individual in the solvable space [
48].
The PSO algorithm first initializes a group of particles in the solvable space, and in each iteration, the particles update themselves by tracking two extreme values. One is the optimal solution found by the particle itself, which is generally called the individual extreme value; the other is the current optimal solution, found by the whole population, which is generally called the global extreme value. The individual extreme value and global extreme value are updated continuously in the iteration process, and the final output global extreme value is the optimal solution, obtained by the algorithm [
49].
It is supposed that in a
-dimensional search space, the population consisting of
particles is
, where the
ith particle represents a
-dimensional vector,
, which represents the position of the
ith particle in the
-dimensional search space and also a potential solution to the problem. According to the fitness function, the fitness value corresponding to the position of each particle can be calculated. The fitness function defined in this paper is as follows:
where correct represents the number of data that are correctly classified, and sum represents the total number of data.
Assuming that the velocity of the
ith particle is
, its individual extreme value is
, and the global extreme value of the population is
. In each iteration, the particle updates its velocity and position through the individual and global extreme value. The updating equation is as follows:
where
represents the
dth dimension of the variable,
;
represents the
ith particle,
;
is the current number of iterations;
is the velocity of the
dth dimension of the
kth iteration of particle
;
is the coordinates of the individual optimal value, found by particle
in the
dth dimension of the
kth iteration;
is the position of the global optimal solution, found by the entire particle swarm in the
dth dimension of the
kth iteration;
and
are learning factors, which are used to adjust the maximum step size for the optimal position of the individual and the optimal position of the group;
and
are random numbers distributed between [0, 1], called inertia factors, and the larger the value, the larger the range of the search; and
is the inertia weight, which is a parameter introduced to balance the global search ability and local search ability. In order to prevent a blind search of particles, it is generally recommended to limit their position and velocity to a certain interval:
and
.
4. Intrusion Detection Based on the PSO-DBN
UAV mobile ad hoc network intrusion detection can be regarded as a classification problem. First, the intrusion detection dataset is preprocessed. The preprocessing process is shown in
Figure 2. Each connection record in the KDD Cup 99 dataset consists of 41 attribute features, including 3 symbolic features and 38 numeric features. In this paper, the attribute mapping method is used to transform symbolic features into numeric features. For example, there are three values for the attribute feature, ‘protocol type,’ in column 2: tcp, udp, and icmp, which can be processed according to tcp = 1, udp = 2, and icmp = 3. Similarly, the 70 symbol values of the attribute feature, ‘service,’ and the 11 symbol values of the ‘flag’ can establish the mapping relationship between the symbol value and the corresponding numerical value.
Then, the obtained data are normalized, and the data are normalized within a range of [0, 1], according to Equation (10), to ensure that the attributes are within the same order of magnitude.
In the equation, is the normalized value of the input variable; is the original value of the input variable; and and are the maximum and minimum values of the original data, respectively.
After preprocessing the intrusion detection data, the DBN network structure is initialized, and then the PSO algorithm is used to optimize the number of nodes in each layer of the DBN hidden layer to obtain an optimal network structure. Common hyperparameters in the DBN include the learning rate, the number of network layers, and the number of nodes in each layer. For the learning rate, it mainly controls the learning progress of the model. The larger the learning rate, the faster the learning speed. Generally speaking, users can intuitively set the optimal value of the learning rate by using experience values or other types of learning materials. For the number of network layers, the larger the number of layers, the more complicated the calculation. Compared to image processing, the dimension of the dataset used in this paper is not very high, and the selected network layers can meet the requirements of intrusion detection. In DBN, the selection of the number of nodes in each layer is very important. It not only has a great impact on the performance of the established DBN network model, but can also easily lead to “over fitting” in training if it is not properly selected. At present, the calculation formulas for determining the number of nodes in each layer proposed in most literatures are for the case of very large training samples, and the obtained results are not necessarily optimal. In fact, the number of nodes in each layer obtained by various calculation formulas greatly varies. In order to avoid “over fitting” during training as much as possible, and to ensure a high enough network performance and generalization ability, it is necessary to optimize the number of nodes in each layer.
The intrusion detection model based on the PSO-DBN is shown in
Figure 3. The process of building the DBN includes pre-training and reverse fine-tuning. First, the forward propagation of the DBN is established through the training of the RBM model, and better initial model parameters are obtained. Then, the output error information of the training samples is calculated by the BP algorithm and propagated, from top to bottom, in each layer of the RBM, and the parameters of the DBN model are finely adjusted.
In the process of optimizing the number of nodes in the hidden layer, the prediction error of the classifier is selected as the fitness function of the model. Through the iteration condition of the PSO, the number of nodes in the hidden layer of the DBN is constantly updated, and the optimized PSO-DBN model is obtained. When the PSO-DBN model is completed, supervised learning is performed using BP to obtain an improved performance in updating the values of the weights of the nodes. Therefore, learning is performed after assigning a suitable number of epochs of the BP.
6. Conclusions
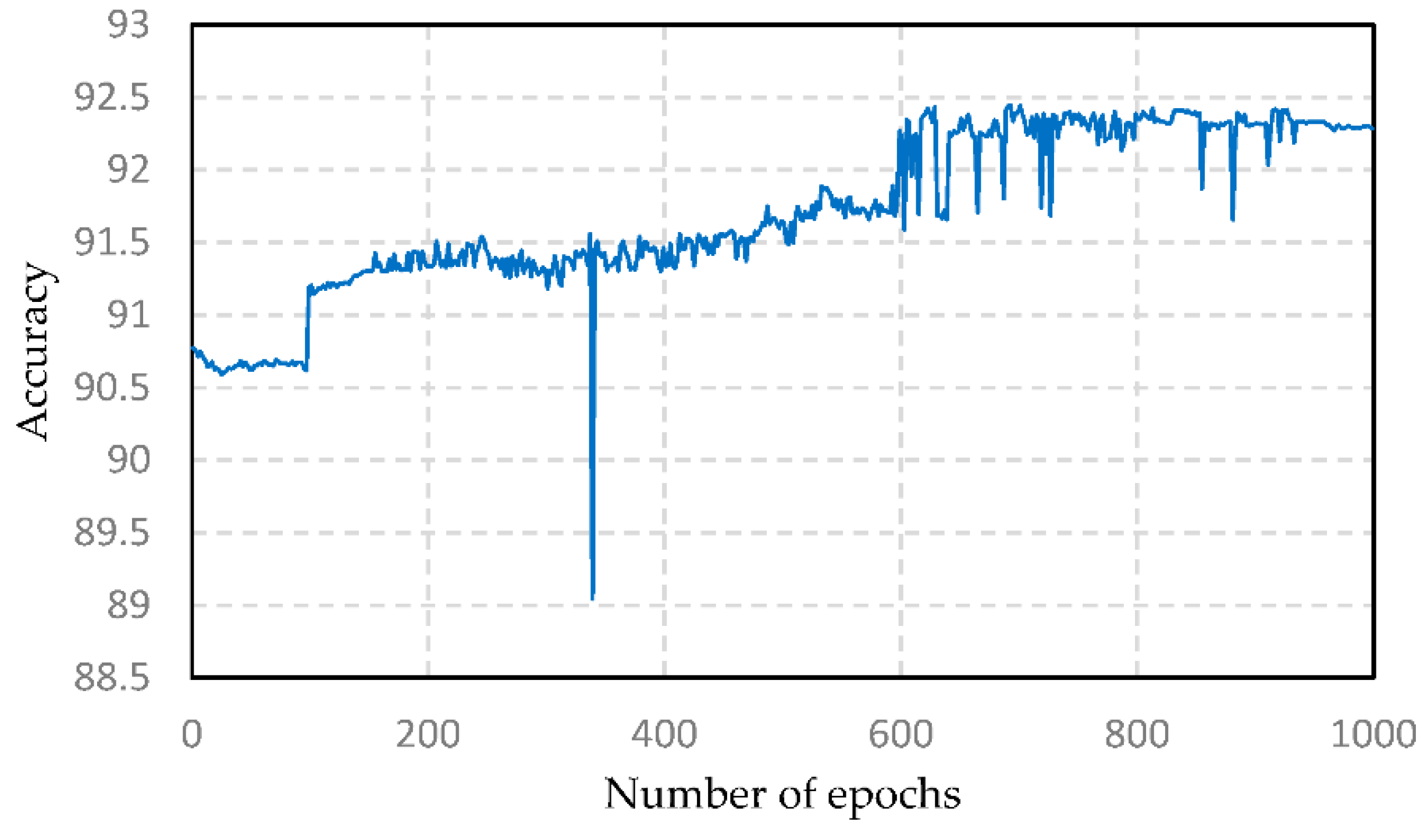
Intrusion detection for UAV networks is an important subject in the field of the security of UAV networks. The deep belief network optimized by PSO is a very effective method. Through the unsupervised learning of the RBM and the supervised learning of the BP, the DBN can effectively solve the intrusion detection problem of massive, high-dimensional, and nonlinear data. The DBN not only has a strong feature extraction ability for high-dimensional feature vectors, but it also has an efficient classification ability. Based on the DBN method, the PSO algorithm is used to optimize the number of hidden layer nodes of the DBN, to optimize its network structure. The experimental results show that the accuracy of the PSO-DBN algorithm, proposed in this paper, reaches 92.44%, which is higher than those achieved by the methods of ANN, SVM, Adaboost, and DNN. In addition, the optimization effect of PSO is better than those of GA, SA, and BOA. The PSO-DBN algorithm is very suitable for the tasks of information extraction in high-dimensional space, improves the intrusion recognition ability, and provides an effective solution to the problem of intrusion detection.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}