Combining Weighted Contour Templates with HOGs for Human Detection Using Biased Boosting

Abstract
:1. Introduction
2. Template-Based Classifier
2.1. Problem Formulation
2.2. Expectation Maximization (EM)-Based Formulation
2.3. Template Construction Algorithm
| Algorithm 1: Algorithm for Weighted Template Construction |
Input: A set of training samples Output: A set of weighted templates
repeat
m ← m+1 Until |
2.4. Classifier Formation and Analysis
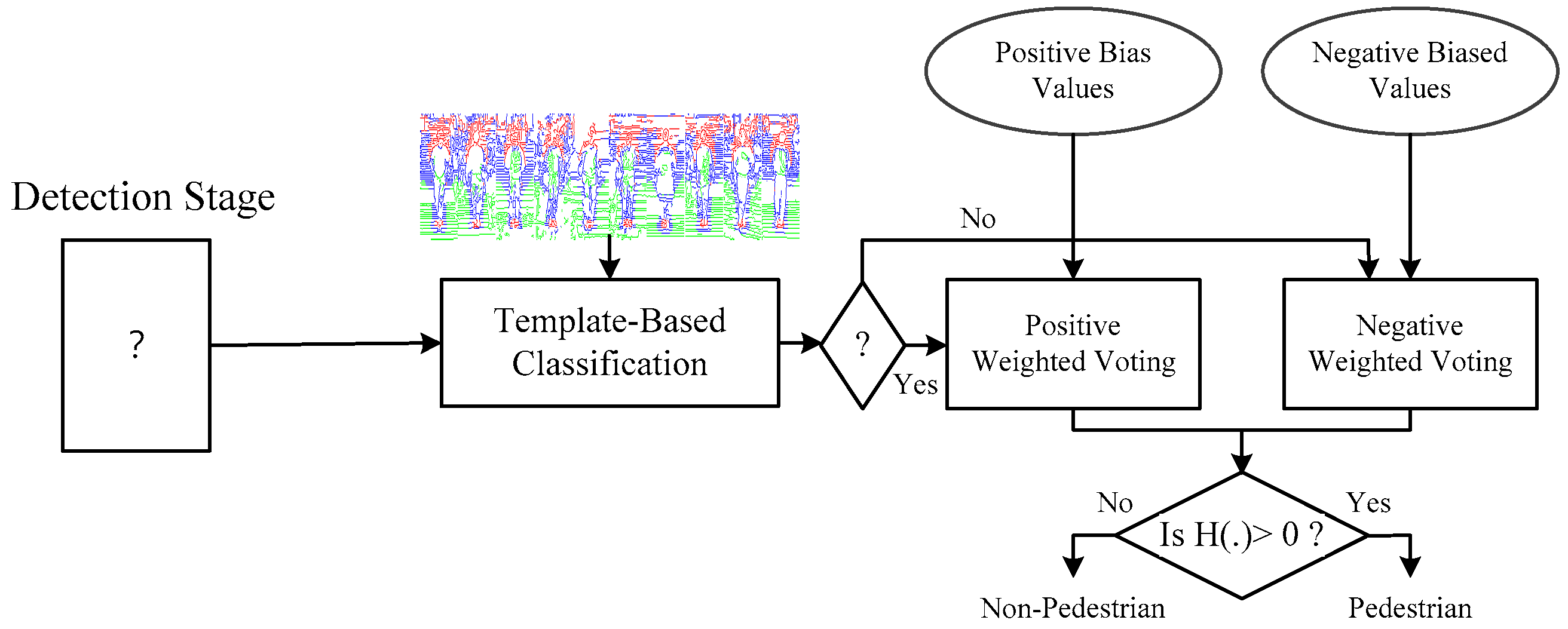
3. Training Framework
3.1. Biased Boosting
| Algorithm 2: Biased Boosting Algorithm |
Input: A set of training samples Output:
end for |
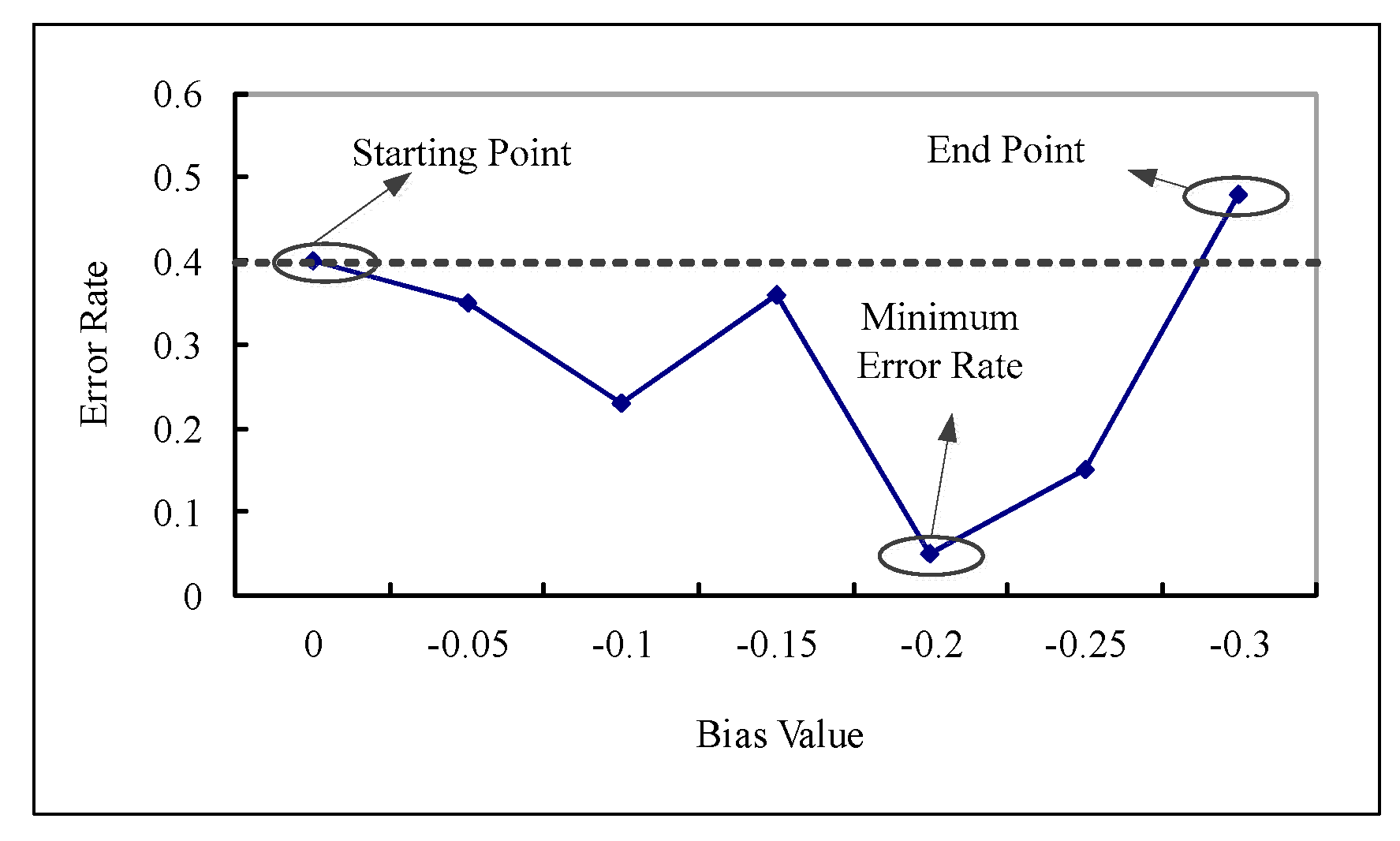
3.2. Bias Determination
3.3. Bias Determination
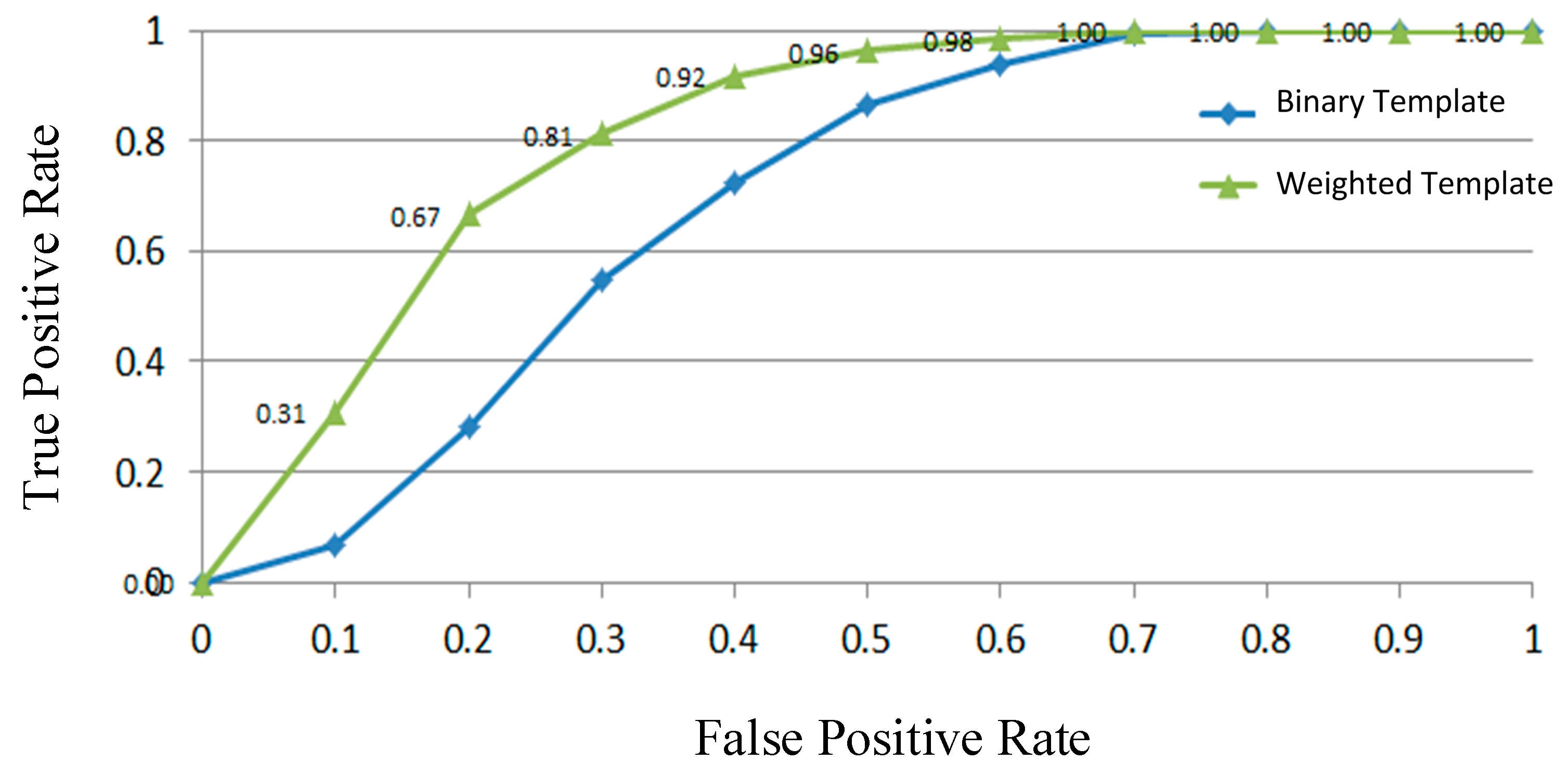
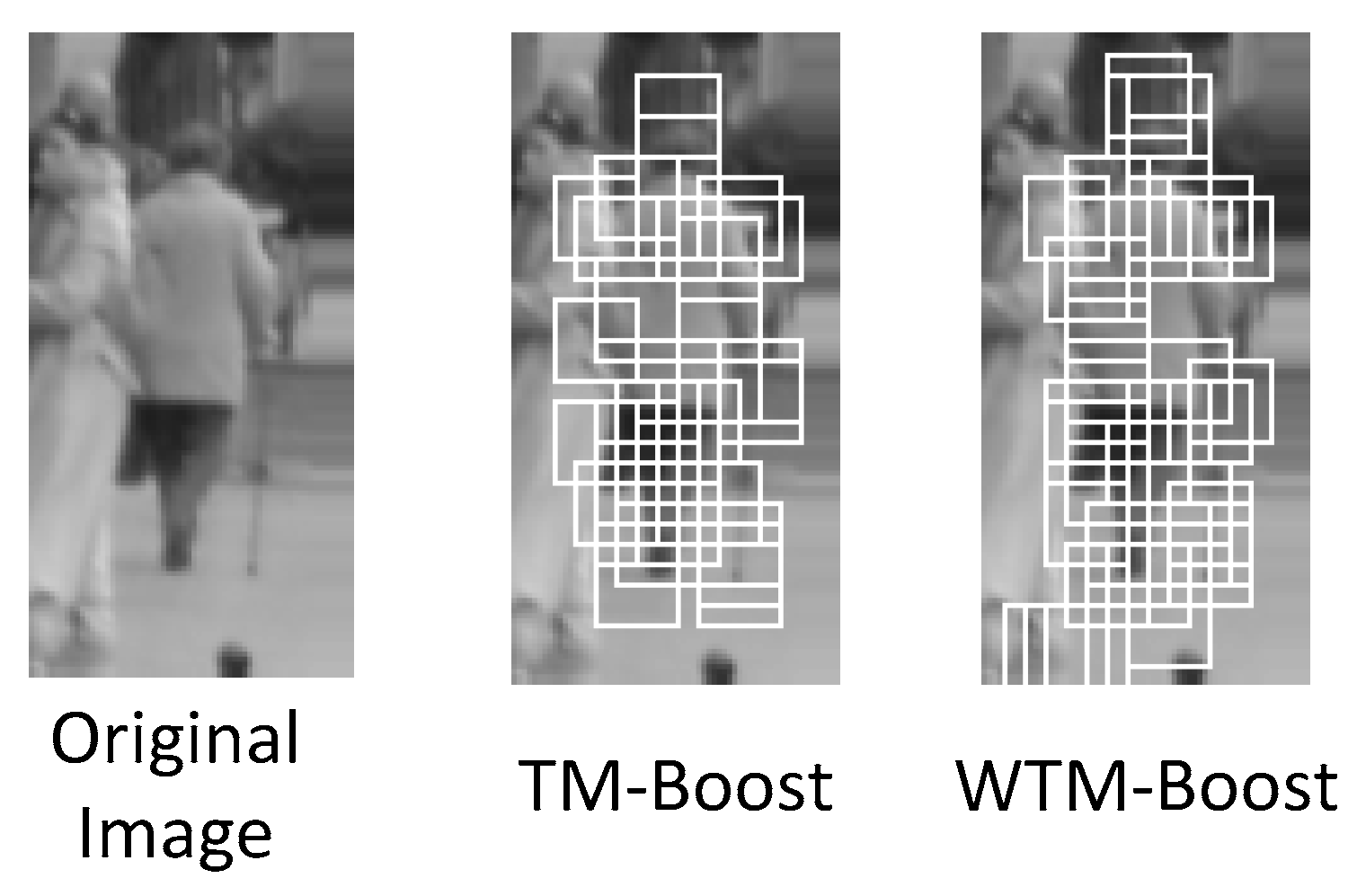
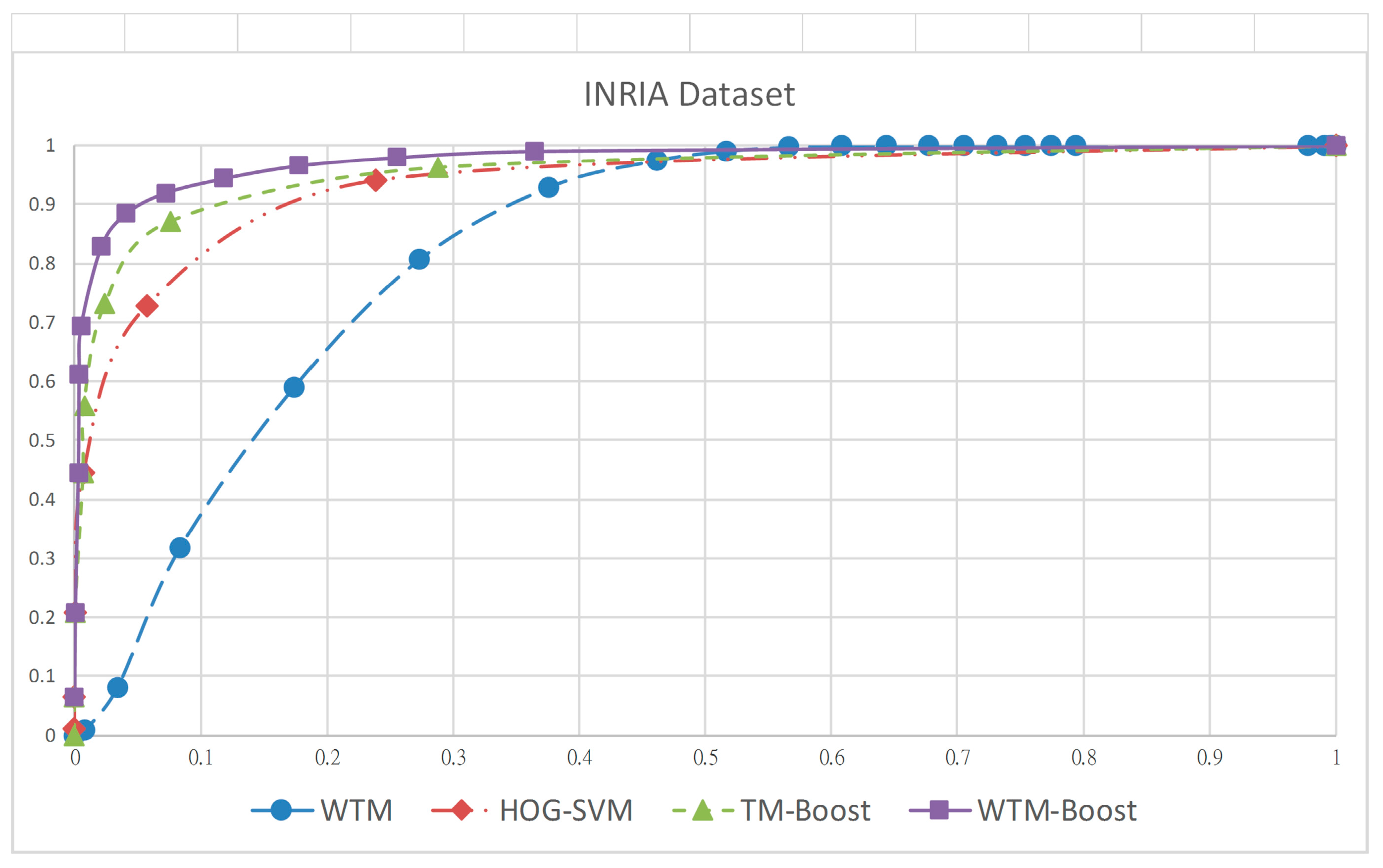
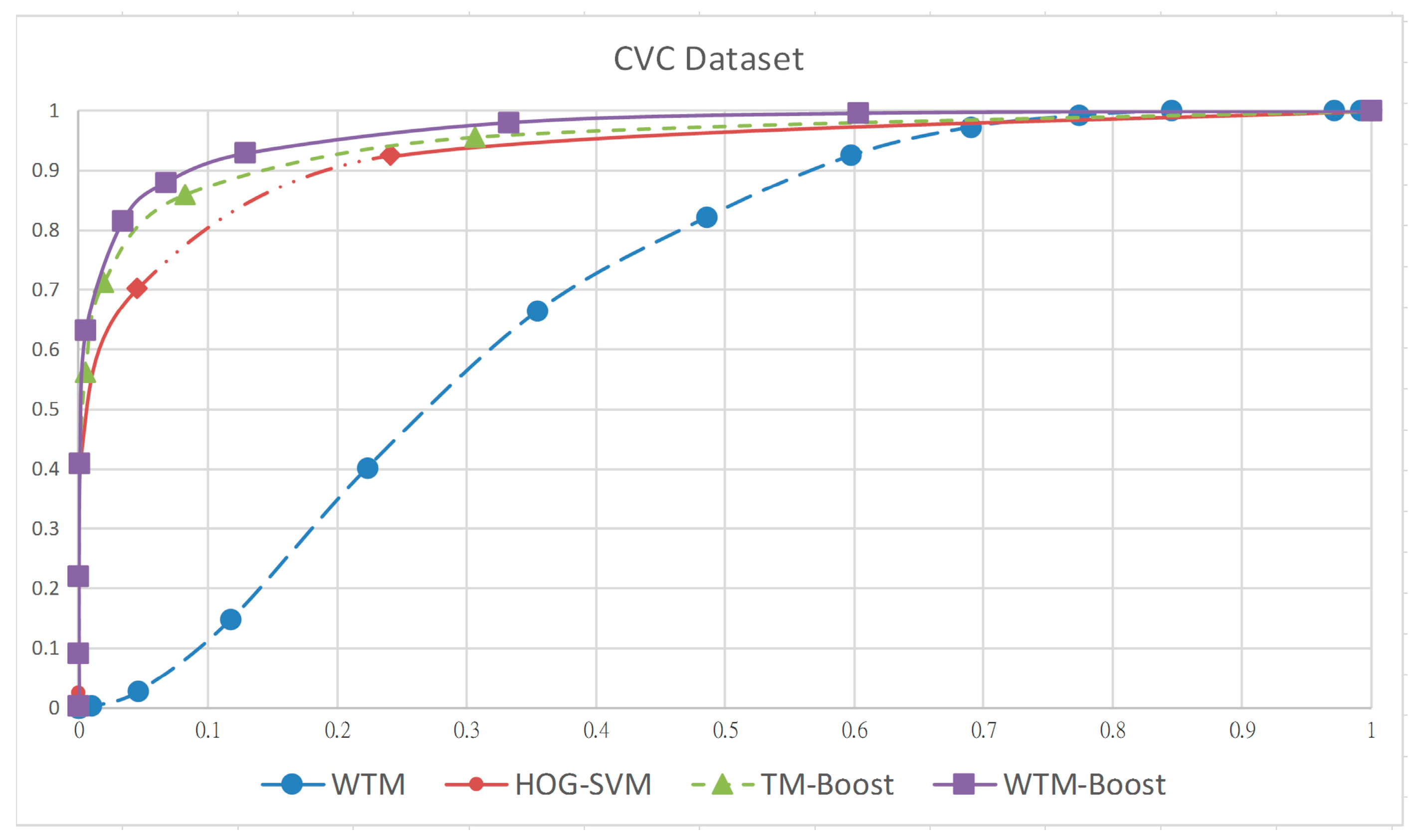
4. Experiment
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Enzweiler, M.; Gavrila, D.M. Monocular Pedestrian Detection: Survey and Experiments. IEEE Trans. Pattern Recognit. Mach. Intell. 2009, 1, 2179–2195. [Google Scholar] [CrossRef] [PubMed]
- Gavrila, D.M. A Bayesian, Exemplar-Based Approach to Hierarchical Shape Matching. IEEE Trans. Pattern Recognit. Mach. Intell. 2007, 29, 1408–1421. [Google Scholar] [CrossRef] [PubMed]
- Thanh, N.D.; Li, W.; Ogunbona, P. A Novel Template Matching Method for Human Detection. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 2549–2552. [Google Scholar]
- Wang, G.; Liu, Q.; Zheng, Y.; Peng, S. Far-Infrared Pedestrian Detection Based on Adaptive Template Matching and Heterogeneous-Feature-Based Classification. In Proceedings of the 2016 IEEE International Instrumentation and Measurement Technology Conference Proceedings, Taipei, Taiwan, 23–26 May 2016; pp. 1–6. [Google Scholar]
- Arie, M.; Shibata, M.; Terabayashi, K.; Moro, A. Fast Human Detection Using Template Matching for Gradient Images and ASC Descriptors Based on Subtraction Stereo. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 3118–3122. [Google Scholar]
- Wu, P.; Cao, X.-B.; Xu, Y.-W.; Qiao, H. Representative Template Set Generation Method for Pedestrian Detection. In Proceedings of the 2008 Fifth International Conference on Fuzzy Systems and Knowledge Discovery, Jinan, China, 18–20 October 2008; pp. 101–105. [Google Scholar]
- Rogez, G.; Rihan, J.; Orrite-Urunuela, C.; Torr, P.H.S. Fast Human Pose Detection Using Randomized Hierarchical Cascades of Rejectors. Int. J. Comput. Vis. 2012, 99, 25–52. [Google Scholar] [CrossRef]
- Hao, Z.; Wang, B.; Teng, J. Fast Pedestrian Detection Based on Adaboost and Probability Template Matching. IEEE Int. Adv. Comput. Control 2010, 2, 390–394. [Google Scholar]
- Nguyen, T.; Ogunbona, D.P.; Li, W. Human Detection Based on Weighted Template Matching. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, Cancun, Mexico, 28 June–2 July 2009; pp. 634–637. [Google Scholar]
- Lee, H.J.; Hong, K.-S. Class-Specific Weighted Dominant Orientation Templates for Object Detection. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 97–110. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Fua, P.; Navab, N. Dominant Orientation Templates for Real-Time Detection of Texture-Less Objects. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2257–2264. [Google Scholar]
- Han, H.; Fan, Y.; Jiao, L.; Chen, Z. Concatenated Edge and Co-occurrence Feature Extracted from Curvelet Transform for Human Detection. In Proceedings of the 2010 25th International Conference of Image and Vision Computing New Zealand, Queenstown, New Zealand, 8–10 November 2010; pp. 1–8. [Google Scholar]
- Zeng, C.; Ma, H. Robust Head-Shoulder Detection by PCA-Based Multi-Level HOG-LBP Detector for People Counting. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2012; pp. 2069–2072. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition, Salt Lake City, UT, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Paisitkriangkrai, S.; Shen, C.; Zhang, J. Performance Evaluation of Local Features in Human Classification and Detection. IET Comput. Vis. 2008, 2, 236–246. [Google Scholar] [CrossRef]
- Wang, C.C.R.; Lien, J.J. AdaBoost Learning for Human Detection Based on Histograms of Oriented Gradients. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2007; pp. 885–895. [Google Scholar]
- Chuang, C.H.; Huang, S.S.; Fu, L.C.; Hsiao, P.Y. Monocular Multi-Human Detection Using Augmented Histograms of Oriented Gradients. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multi-Resolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Pattern. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Wu, B.; Nevatia, R. Detectiong of Multiple, Partially Occluded Humans in a Single Image by Bayesian Combination of Edgelet Part Detectors. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; pp. 90–97. [Google Scholar]
- Wu, B.; Nevatia, R. Simultaneous Object Detection and Segmentation by Boosting Local Shape Feature Based Classifier. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Sabzmeydani, P.; Mori, G. Detecting Pedestrians by Learning Shapelet Features. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Hurney, P.; Waldron, P.; Morgan, F.; Jones, E.; Glavin, M. Night-Time Pedestrian Classification with Histograms of Oriented Gradients-Local Binary Patterns Vectors. IET Trans. Intell. Transp. Syst. 2015, 9, 75–85. [Google Scholar] [CrossRef]
- Yao, S.; Pan, S.; Wang, T.; Zheng, C.; Shen, W.; Chong, Y. A New Pedestrian Detection Method Based on Combined HOG and LSS Features. Elsevier Neurocomput. 2015, 151, 1006–1014. [Google Scholar] [CrossRef]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP Human Detection with Partial Occlusion Handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 32–39. [Google Scholar]
- Bilmes, J.A. A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models. Int. Comput. Sci. Inst. 1998, 4, 126. [Google Scholar]
- Borgefors, G. Distance Transform in Digital Images. Comput. Vis. Graph. Image Process. 1986, 34, 344–371. [Google Scholar] [CrossRef]
- Young, S.; Arel, I.; Karnowski, T.P.; Rose, D. A Fast and S Incremental Clustering Algorithm. In Proceedings of the IEEE International Conference on Information Technology, Corfu, Greece, 2–5 November 2010; pp. 204–209. [Google Scholar]
- Pedestrian Data. Available online: http://cbcl.mit.edu/software-datasets/PedestrianData.html (accessed on 22 March 2019).
- INRIA Person Dataset. Available online: http://pascal.inrialpes.fr/data/human/ (accessed on 22 March 2019).
- Zhu, Q.; Avidan, S.; Yeh, M.C.; Cheng, K.T. Fast Human Detection Using a Cascade of Histograms of Oriented Gradients. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1491–1498. [Google Scholar]
- Khoussainov, R.; He, A.; Kushmerick, N. Ensembles of Biased Classifiers. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–10 August 2005; pp. 425–432. [Google Scholar]
- Huang, S.S.; Mao, C.Y.; Hsiao, P.Y. Global Template Matching for Guiding the Learning of Human Detector. In Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Seoul, Korea, 14–17 October 2012; pp. 565–570. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28, Proceedings of the Neural Information Processing Systems 2015, Montréal, QC, Canada, 7–12 December 2015; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 2017; pp. 6517–6525. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (ms) | WTM | HOG-SVM | TM-Boost | WTM-Boost |
|---|---|---|---|---|
| Distance Transform Matching Process | 15.6 15.3 | x x | 15.6 14.5 | 15.6 15.4 |
| HOG Descriptor SVM Classification | x x | 24.1 0.5 | 11.1 2.9 | 10.9 3.1 |
| Total Time | 30.9 | 24.6 | 44.1 | 45.0 |
| Training | Testing | |||
|---|---|---|---|---|
| Positive | Negative | Positive | Negative | |
| Exp I | CBCL (924) | INRIA (3342) | INRIA (2416) | INRIA (5561) |
| Exp II | CBCL (924) | INRIA (3342) | CVC (3356) | INRIA (8823) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.-S.; Ku, S.-H.; Hsiao, P.-Y. Combining Weighted Contour Templates with HOGs for Human Detection Using Biased Boosting. Sensors 2019, 19, 1458. https://doi.org/10.3390/s19061458
Huang S-S, Ku S-H, Hsiao P-Y. Combining Weighted Contour Templates with HOGs for Human Detection Using Biased Boosting. Sensors. 2019; 19(6):1458. https://doi.org/10.3390/s19061458
Chicago/Turabian StyleHuang, Shih-Shinh, Shih-Han Ku, and Pei-Yung Hsiao. 2019. "Combining Weighted Contour Templates with HOGs for Human Detection Using Biased Boosting" Sensors 19, no. 6: 1458. https://doi.org/10.3390/s19061458
APA StyleHuang, S.-S., Ku, S.-H., & Hsiao, P.-Y. (2019). Combining Weighted Contour Templates with HOGs for Human Detection Using Biased Boosting. Sensors, 19(6), 1458. https://doi.org/10.3390/s19061458