1. Introduction
Since imbalanced data can be found in any area, effective classification of imbalanced data has become critical for many applications. The classification results of imbalanced data generated by existing classification algorithms are usually significantly affected by the majority class, resulting in low accuracy in classification of the minority class. For example, the sensor network can accurately achieve target recognition under the assumption of data distribution equilibrium. However, in practical applications, the filed environment is complex and variable, and the difficulty of obtaining samples is different, which results in imbalanced data. It is easy to ignore samples of minority class in this case, resulting in incorrect classification. In the intrusion alarm application, misclassification of samples of minority class means false alarm of system, which will cause very serious consequences.
Existing approaches processing imbalanced data can be generally divided into two categories [
1,
2]. The first category is based on resampling at the data level, which either (i) increases the number of samples using upsampling by synthesizing new data or copying the original data, or (ii) reduces the number of samples using subsampling by extracting a small amount of data. Although resampling can improve the accuracy of minority class classification, there are some challenges. It is impossible to properly interpret the synthetic new data generated by upsampling. In addition, important information may be lost during the subsampling process. The second category is based on the ensemble and cost-sensitive approaches at the algorithm level [
3,
4], which increases the weights of the misclassified samples, thus improving the classification performance. The ensemble approaches that currently widely used are typically based on Boosting [
5,
6,
7,
8] or Bagging [
9,
10,
11]. AdaBoost is a boosting algorithm and is widely used to process imbalanced data. It uses a single-layer decision tree as a weak classifier. In each training iteration, the weight of the misclassified samples generated by the previous iteration is increased, and the weight of the correctly classified samples is reduced, improving the significance of the misclassified samples in the next iteration. Although the AdaBoost algorithm can be directly used to process imbalanced data, the algorithm focuses more on the misclassified samples than samples of minority class. In addition, it may generate many redundant or useless weak classifiers, increasing the processing overhead and causing performance reduction.
Many approaches have been proposed to improve the performance of AdaBoost. Li et al. [
12] proposed the BPSO-AdaBoost-KNN algorithm for multiclass imbalanced data classification, and this algorithm improves the stability of AdaBoost by effectively extracting key features. Cao et al. [
13] used the gradient descent algorithm to optimize the new loss function based on the Boosting framework, and proposed the AsB and AsBL algorithms, which further verified that this approach can generate cost-sensitive classifiers with lower error cost. Yang et al. [
14] used mathematical analysis and graphical methods to clarify the working principle of multiclass AdaBoost, and proposed a novel approach for processing multiclass data. This algorithm not only reduces the requirements of weak classifiers, but also ensures the effectiveness of the classification. Li et al. [
15] proposed the AdaBoost composite kernel extreme learning machine, by combining the composite kernel method and the AdaBoost framework with the weighted ELM. The proposed algorithm improves performance in hyperspectral image classification. Dou et al. [
16] proposed an improved AdaBoost algorithm that assigns a weight to each individual class and uses weight vectors to represent the recognition power of the base classifiers. This algorithm significantly avoids overfitting and improves classification accuracy. Xie et al. [
17] proposed an ensemble evolve algorithm for imbalanced data classification by introducing the genetic algorithm to the AdaBoost algorithm. Better classifiers are generated using gene evolution and improved fitness functions, and imbalanced data classification is optimized during evolution. Guo et al. [
18] treated samples of majority class that exceeded the threshold during the iteration as noise, and proposed four algorithms (i.e., A-AdaBoost, B-AdaBoost, C-AdaBoost and D-AdaBoost) based on limiting threshold growth and modifying class labels. Results show that these algorithms can effectively process imbalanced data.
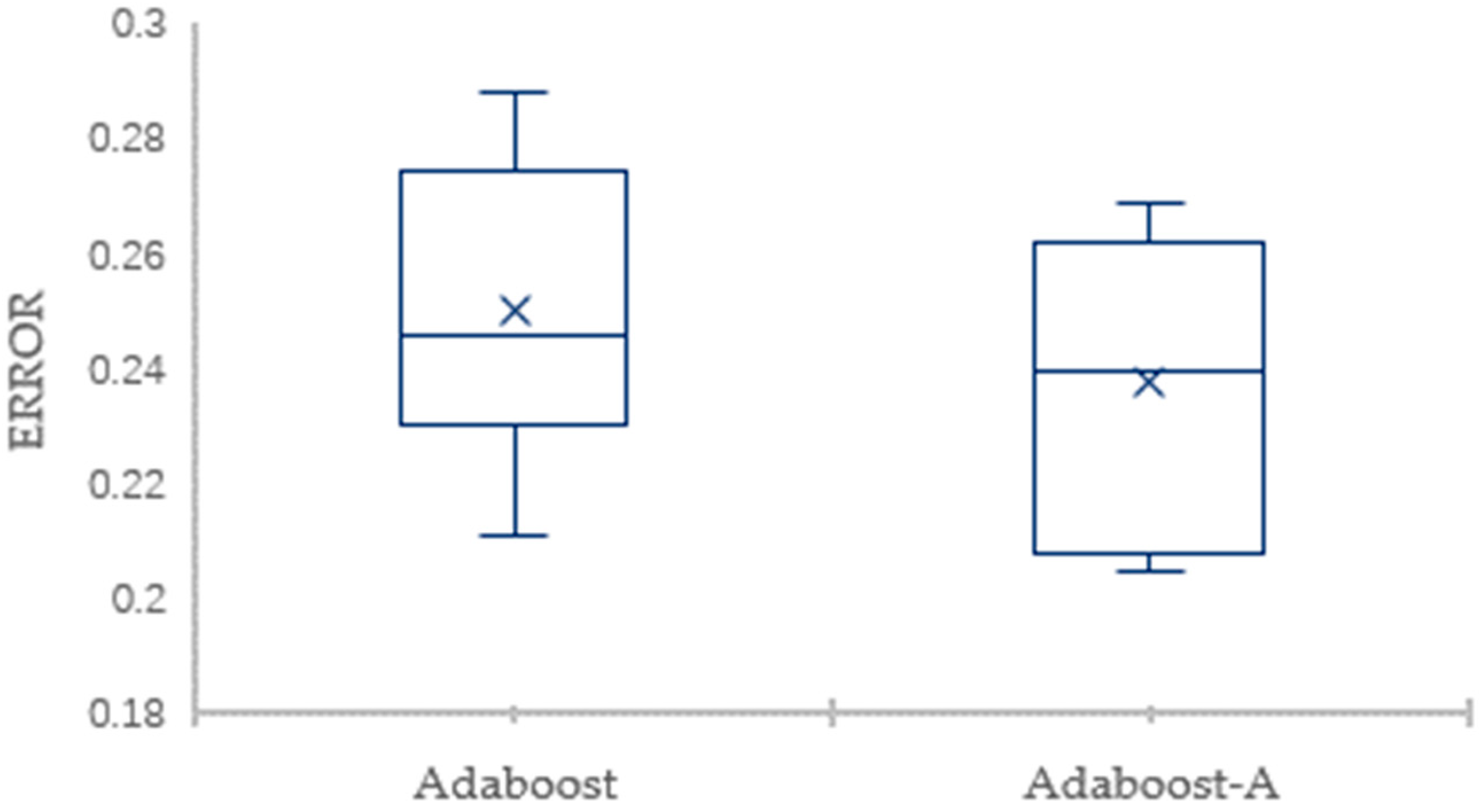
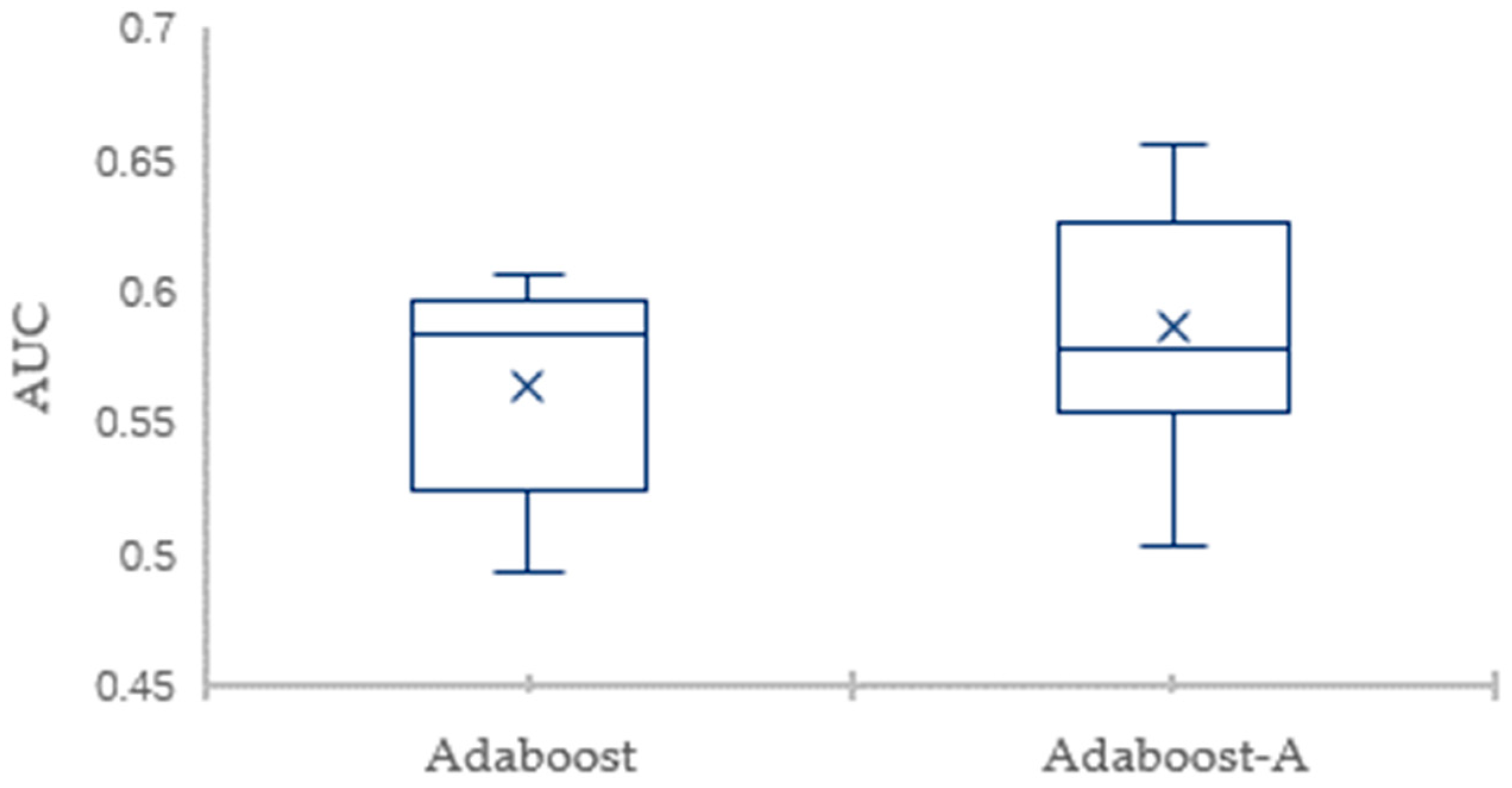
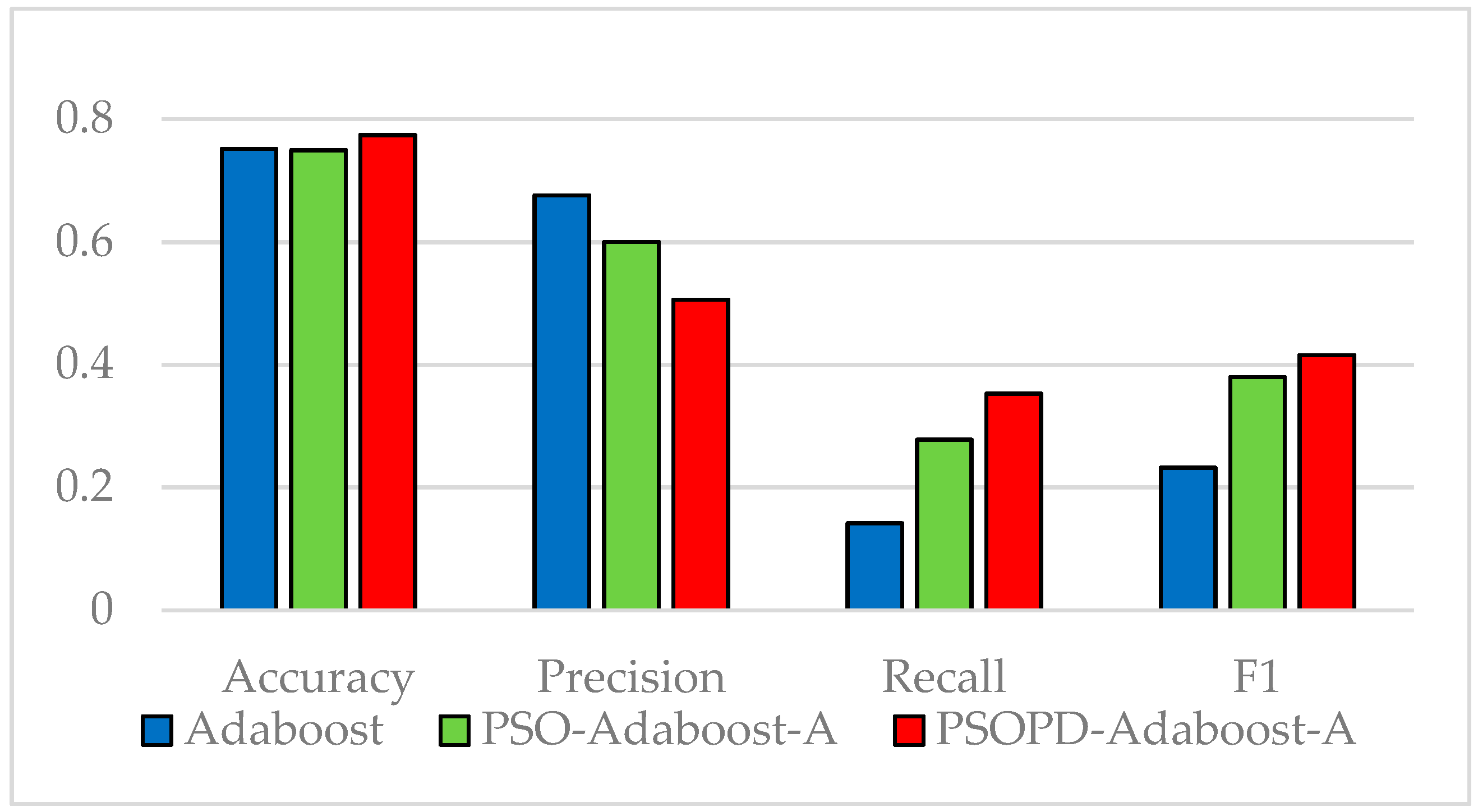
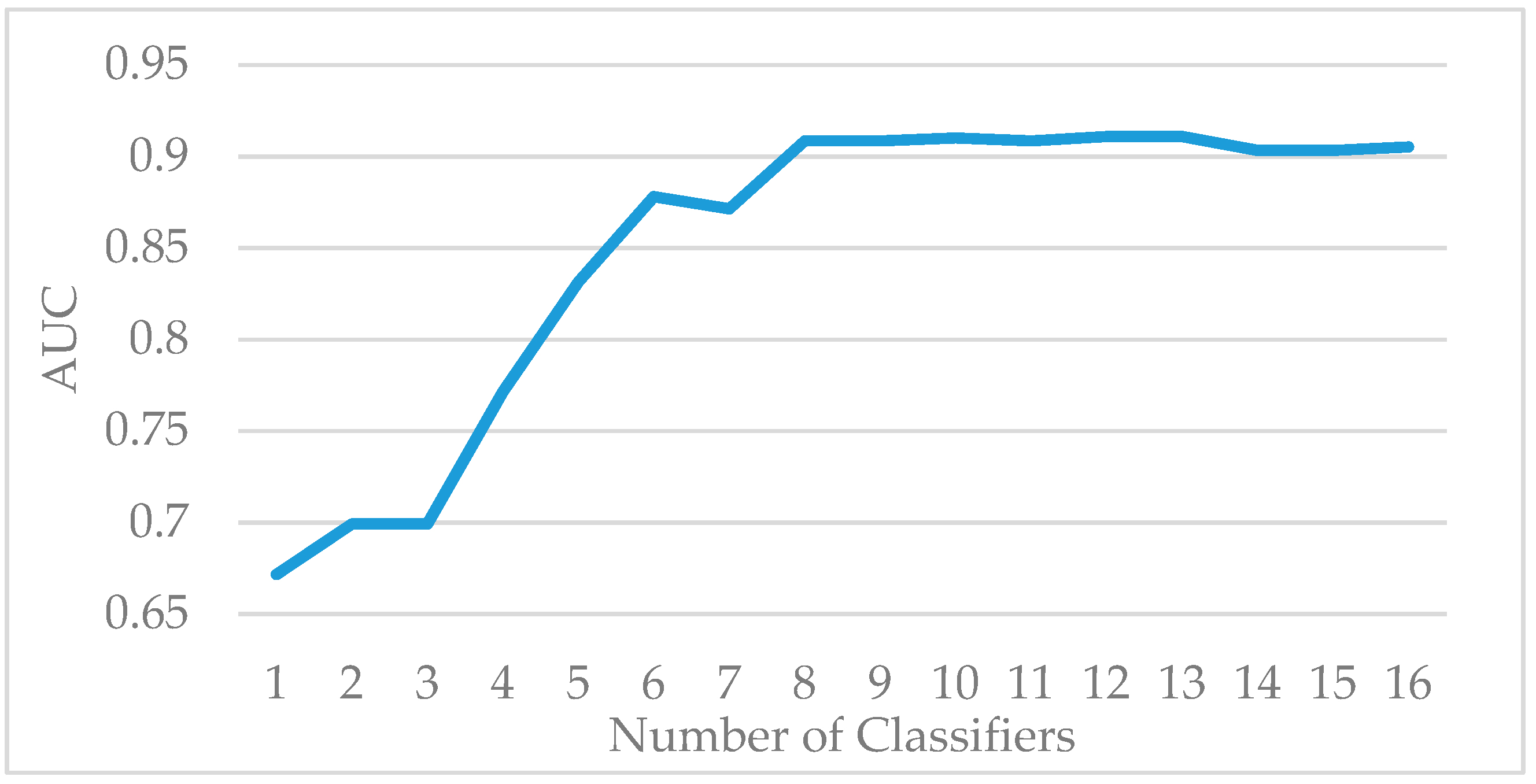
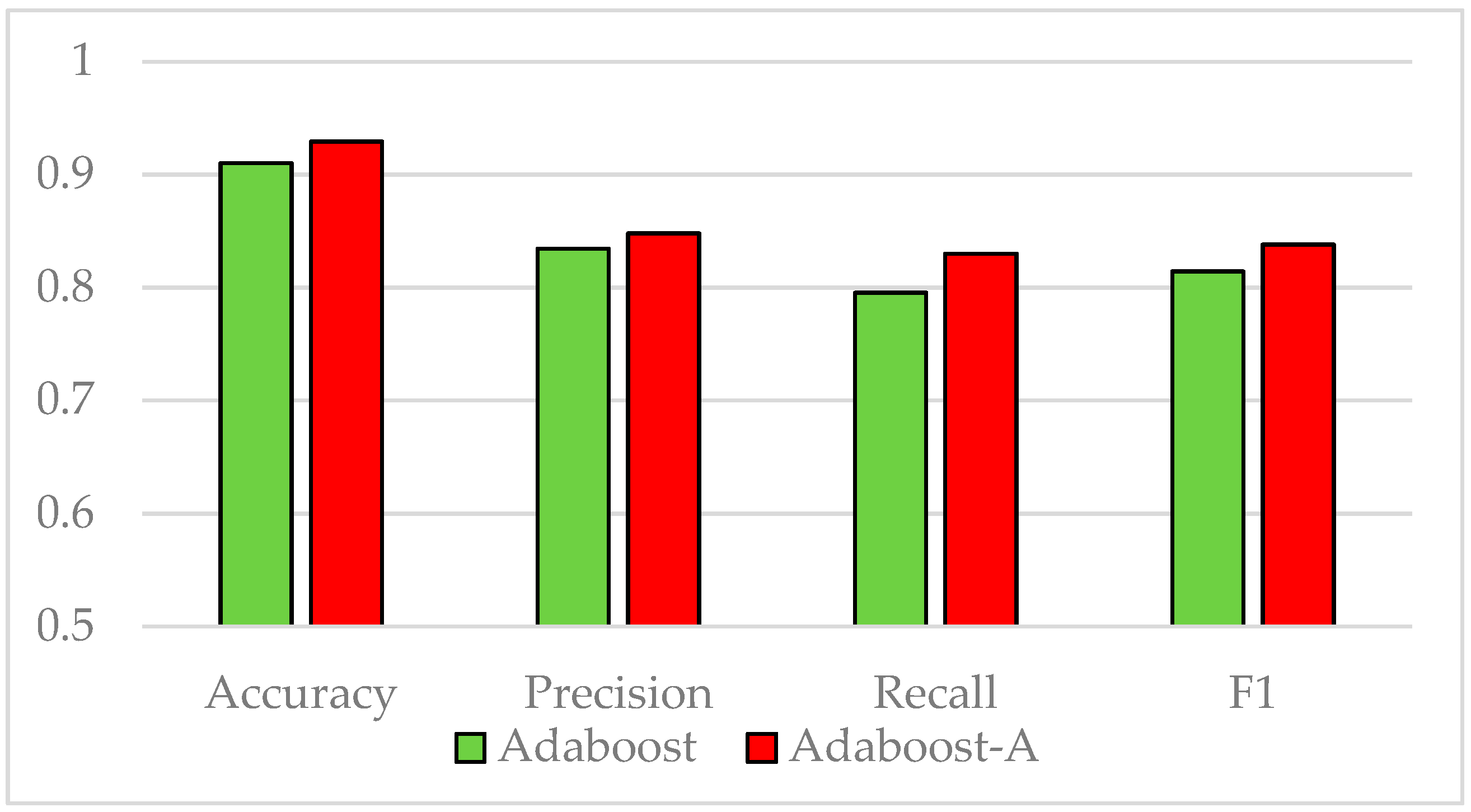
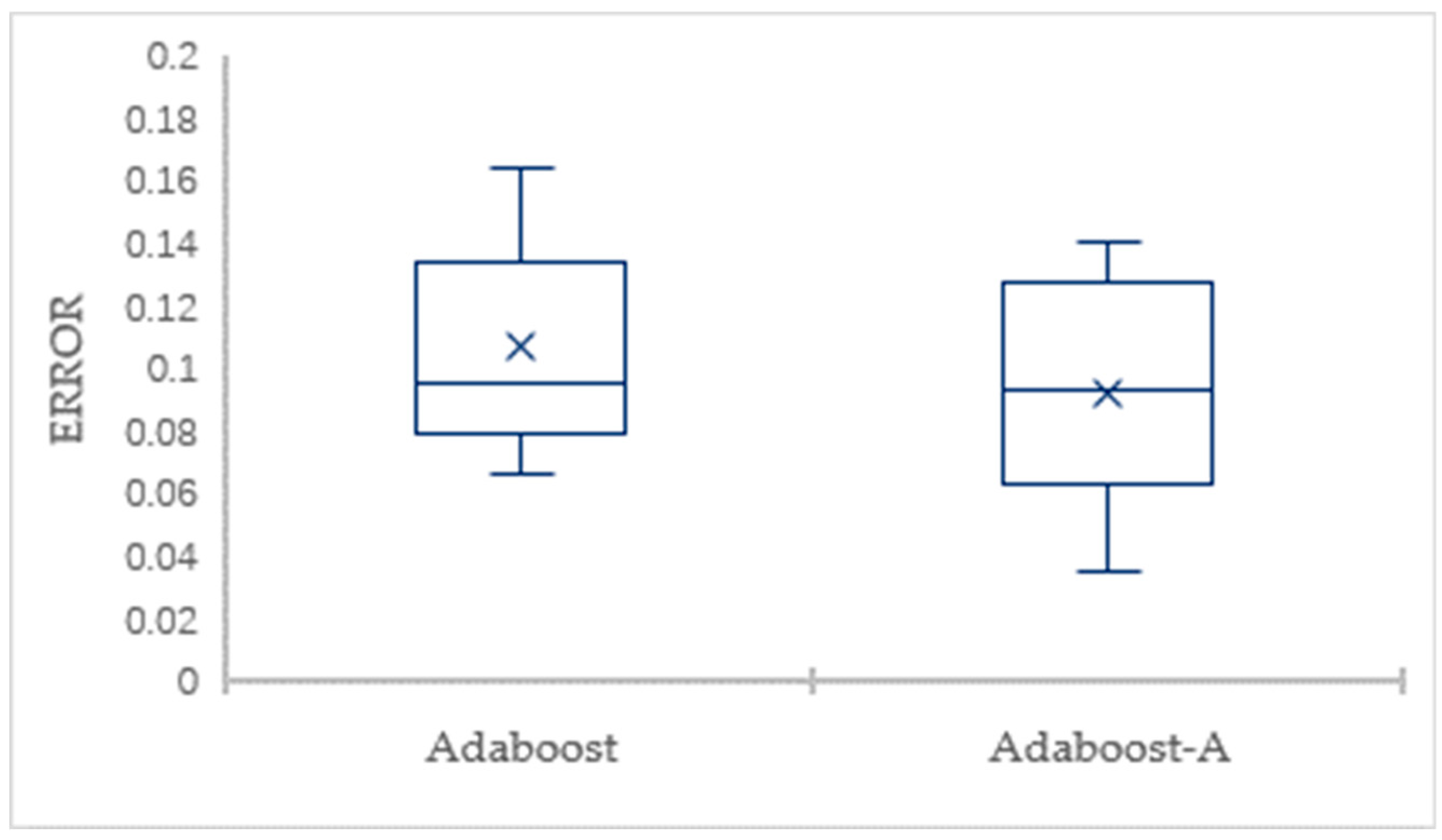
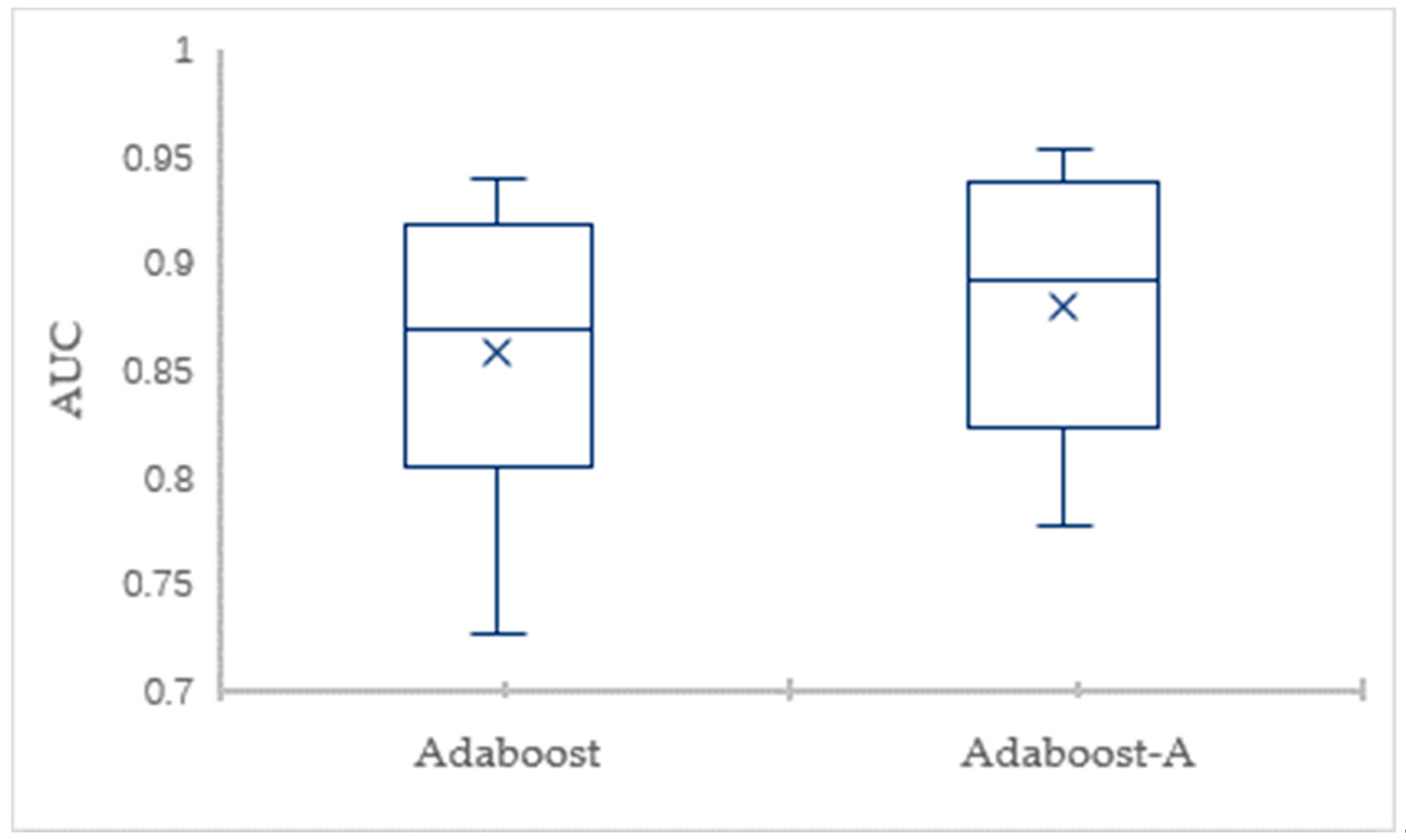
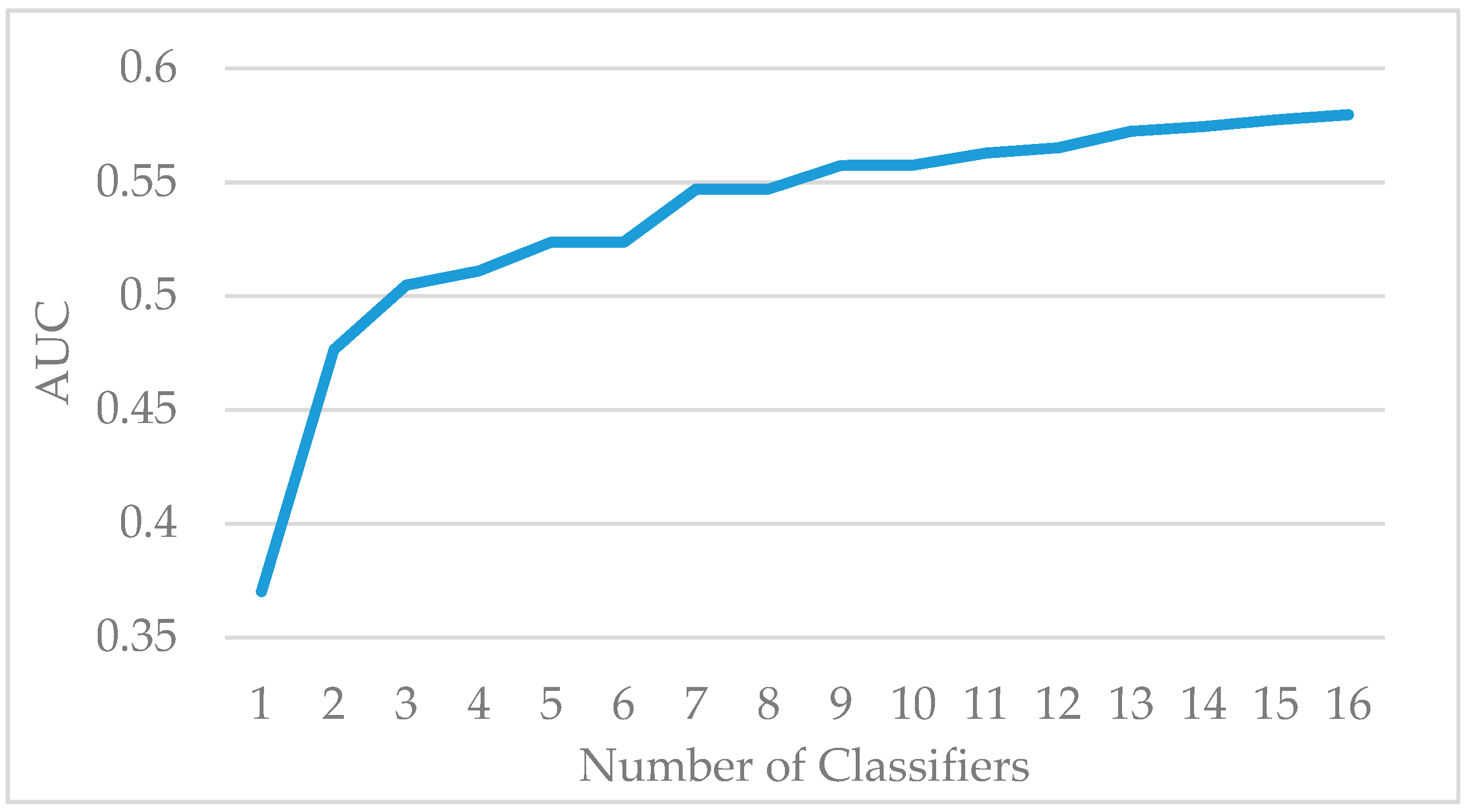
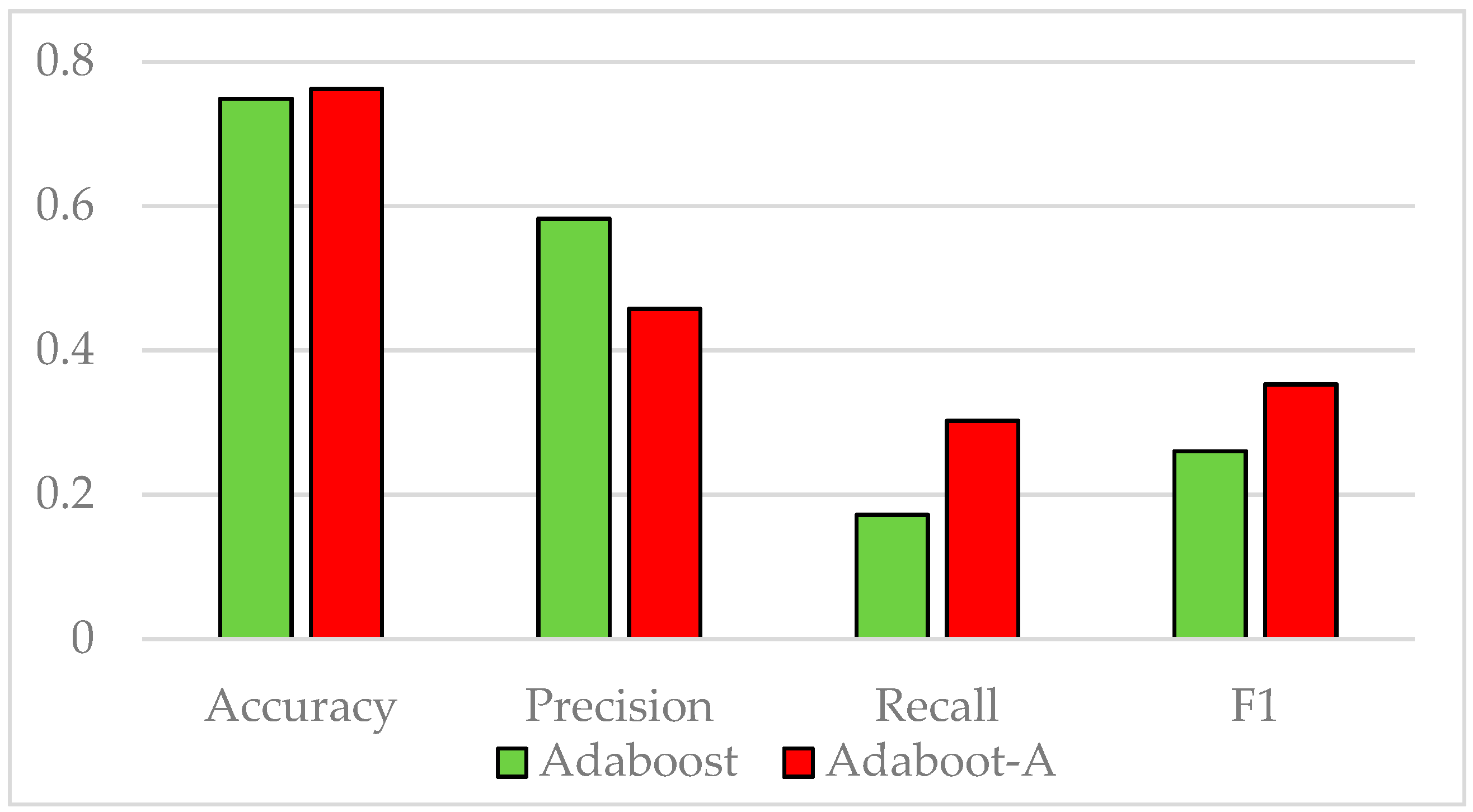
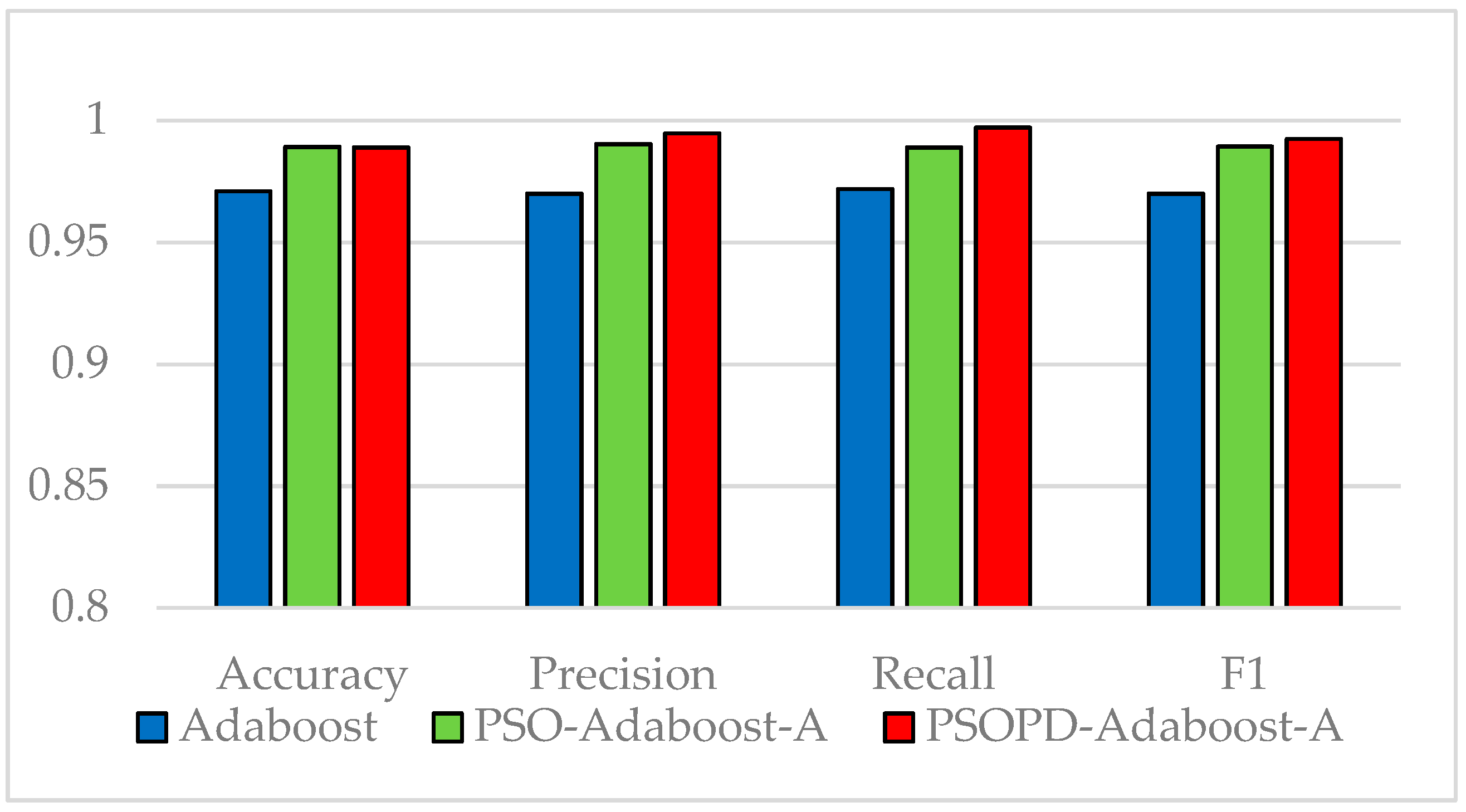
In this paper, we propose AdaBoost-A, an improved AdaBoost algorithm based on AUC. The AdaBoost-A redefines the error calculation formula by introducing the AUC index into the error calculation of the weak classifier. The AUC can evaluate the performance of a classifier, and reflect the effects of imbalanced data on the classifier. As a result, the proposed AdaBoost algorithm can focus more on samples of minority class. In addition, the AdaBoost-A algorithm generates a set of weak classifiers to build a strong classifier, and the improved particle swarm optimization algorithm based on population diversity is used to further optimize the weight of the classifiers, thus decreasing the weight of redundant and useless classifiers and avoiding waste of system resources and time overhead.
The remainder of this paper is organized as follows. In
Section 2, we introduce the basic principles and implementation steps of AdaBoost and Particle Swarm Optimization (PSO) algorithms. In
Section 3, we illustrate the improved AdaBoost-A algorithm and ensemble algorithm PSOPD-AdaBoost-A. In
Section 4, the effectiveness of PSOPD-AdaBoost-A is proved by comparison experiments with traditional AdaBoost algorithm and various improved algorithms. The conclusions are drawn in
Section 5.
2. Background
2.1. Adaptive Boosting (AdaBoost)
AdaBoost (Adaptive Boosting) is an adaptive enhancement technique. It is a typical ensemble algorithm which improves classification performance by combining multiple weak classifiers into one strong classifier. In the beginning, all the samples are assigned the same weight. During the iteration, the weights of samples vary with the coefficients of weak classifiers, and the coefficients of the classifiers are calculated by the error. As a result, the AdaBoost algorithm can increase the weight of the misclassified samples and decrease the weight of the correctly classified samples. In the next iteration, the classifier will focus the misclassified samples more. Finally, all the generated weak classifiers are merged using linear combination to form a strong classifier. The steps of the AdaBoost algorithm [
19] are as follows:
Input:
Training data set , where , and a weak learning algorithm.
Output:
Final classifier
Initialize the weight distribution of the training samples following Equation (1).
where
represents the number of samples.
For where represents the number of weak classifiers.
Following Equation (2), get the weak classifier based on weight distribution
Calculate the classification error rate of
on the training data set following Equation (3).
Calculate the coefficient of
following Equation (4).
Update the weight distribution of the training samples following Equations (5)–(7).
where
is the normalization factor.
Build a linear combination of basic classifiers and get the final classifier
following Equations (8) and (9).
The advantages of the AdaBoost algorithm are summarized as follows. (1) The AdaBoost algorithm can use various weak classifiers without filtering features. In addition, it delivers high execution efficiency, and can avoid overfitting issues. (2) The AdaBoost algorithm trains the weak classifiers without knowing the prior knowledge. The synthetic strong classifier can significantly improve the classification accuracy, and it is suitable for classification of most types of data. (3) The training of rough weak classifiers is much easier than training of the accurate strong classifiers. It trains multiple weak classifiers to form a strong classifier with better classification performance.
2.2. PSO
PSO was proposed by James Kenney and Russ Eberhart in 1995 [
20]. The algorithm is derived from the study of predation behavior of birds, and it is a method based on iteration. Imagine a scene where there is a piece of food in a certain area and a group of randomly distributed birds are searching for the food. They obtain their distances from the food, but do not get the specific location of the food. The best way to solve this problem is to change the flight path based on the current location of the bird closest to the food and flight experience of each bird, to locate the food.
The PSO algorithm considers each solution as a bird, called a particle. Each particle has an adaptive value that represents the current state of its own solution. In each iteration, each particle adjusts its moving direction and velocity based on the global optimal solution and the optimal solution found by the particle itself, and gradually approaches the optimal particle.
The basic principle of the standard particle swarm algorithm is as follows [
21].
Suppose that there are
particles searching for the optimal solution in an N-dimensional target space and randomly initialize the position and velocity of each particle following Equations (10)–(12). Where the vector
represents the position of particle
, and the vector
represents the flight speed of particle
.
As Equation (13) shows, the current best position
found by particle
is:
As Equation (14) shows, the current best location
found by all particles is:
The position and velocity of particle
is then updated following Equations (15) and (16).
where
is the inertia weight,
, two positive constant, are the acceleration factors,
represents the
-dimensional velocity component generated by the (
+1)th iteration of the
th particle, and
represents the
-dimensional position component generated by the (
+1)th iteration of the
th particle. The position and velocity update formula is divided into three parts. The first part is the inertia part, which indicates the particle’s degree of trust in its own speed. The second part is the self-cognitive part, which indicates the particle’s degree of trust in its own experience. The third part is the social cognitive part, which indicates the degree of trust in the best adaptive particle [
22].
Characteristics of PSO algorithm can be summarized as [
23]:
It is possible to quickly approximate the optimal solution and achieve effective optimization of parameters.
It is suitable for searching within the scope of continuity and solving the maximum and minimum problems of continuous functions.
It is easy to implement with low complexity and requires a small number of parameters.
It is easy to fall into local optimum.
5. Conclusions
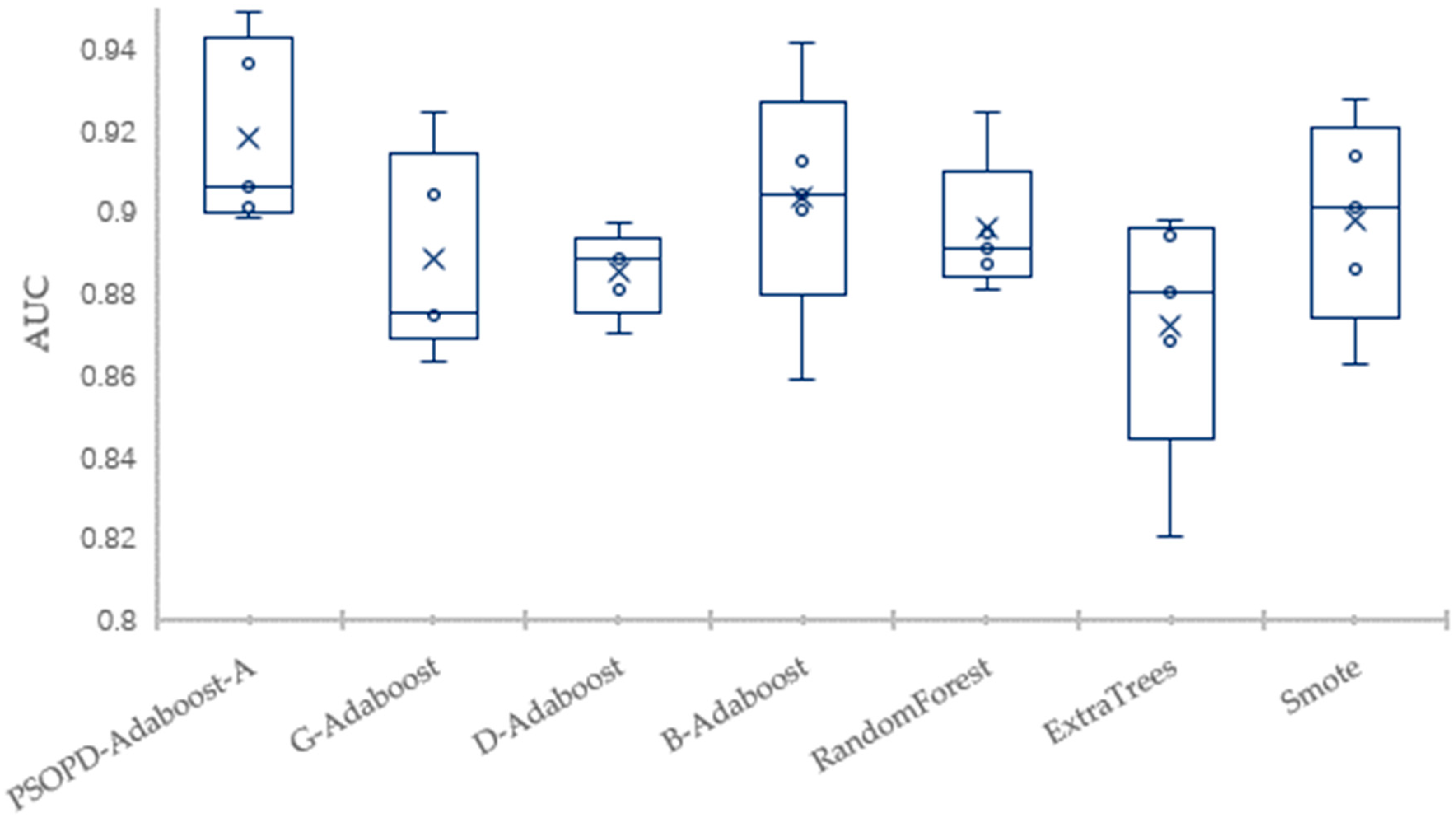
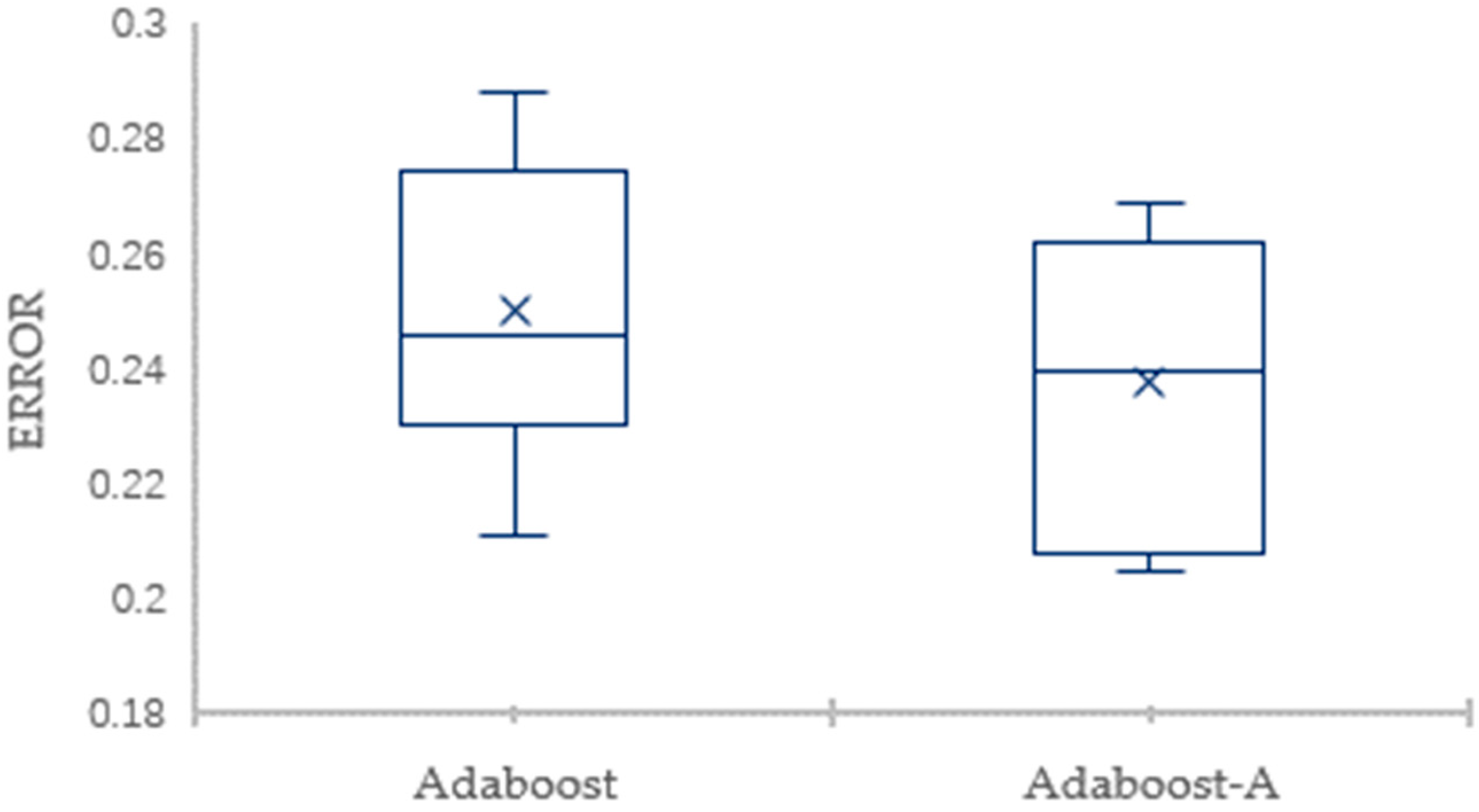
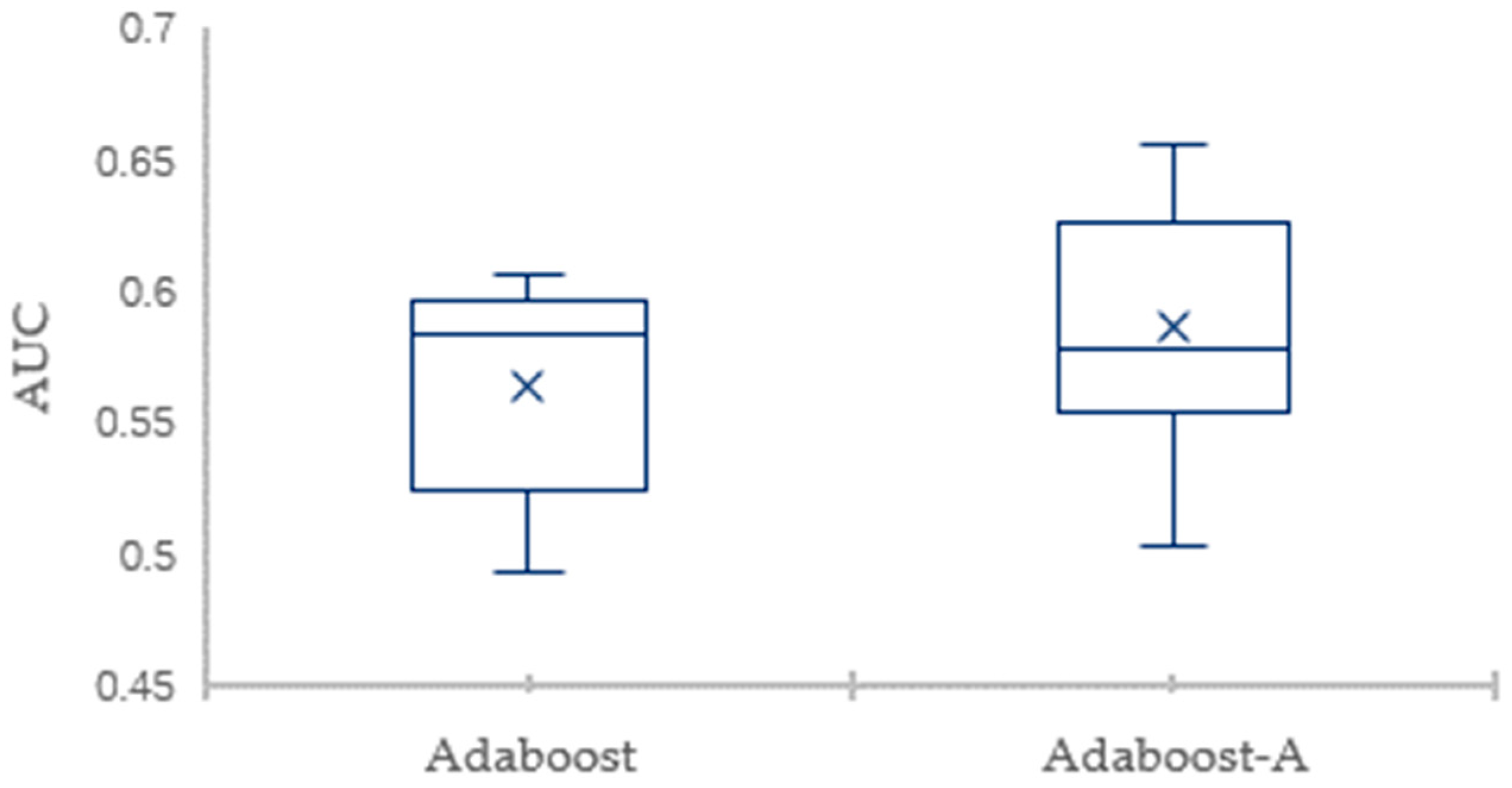
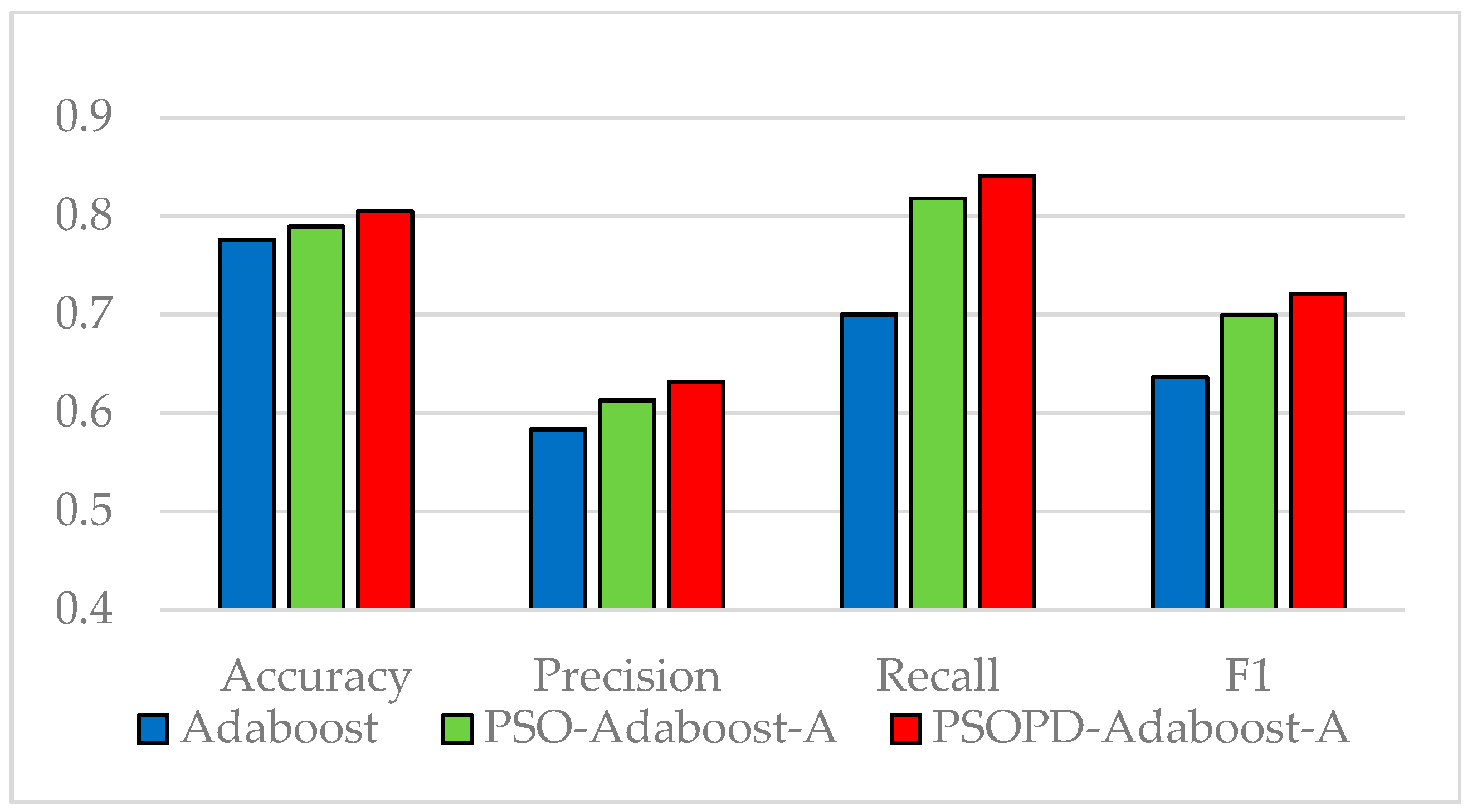
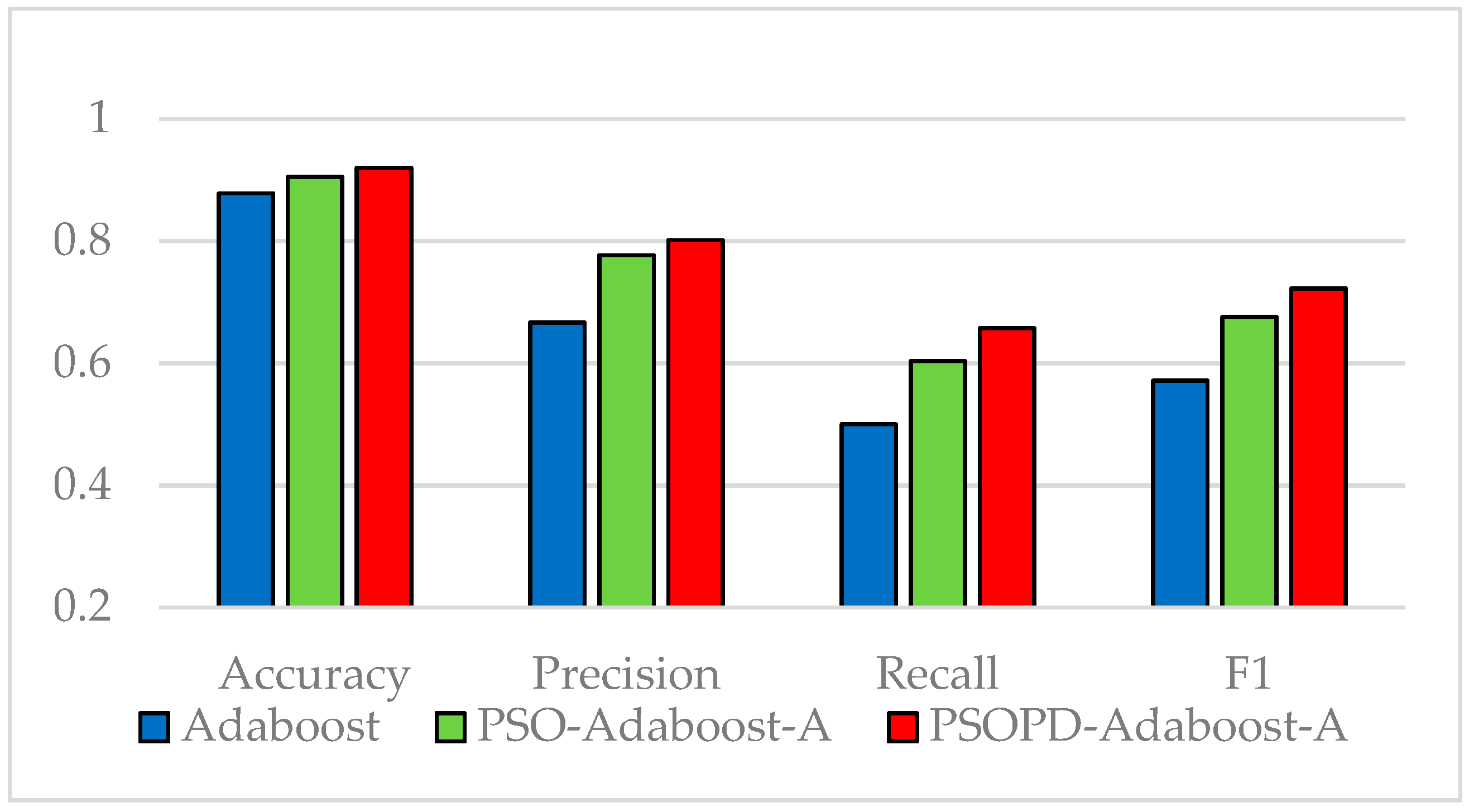
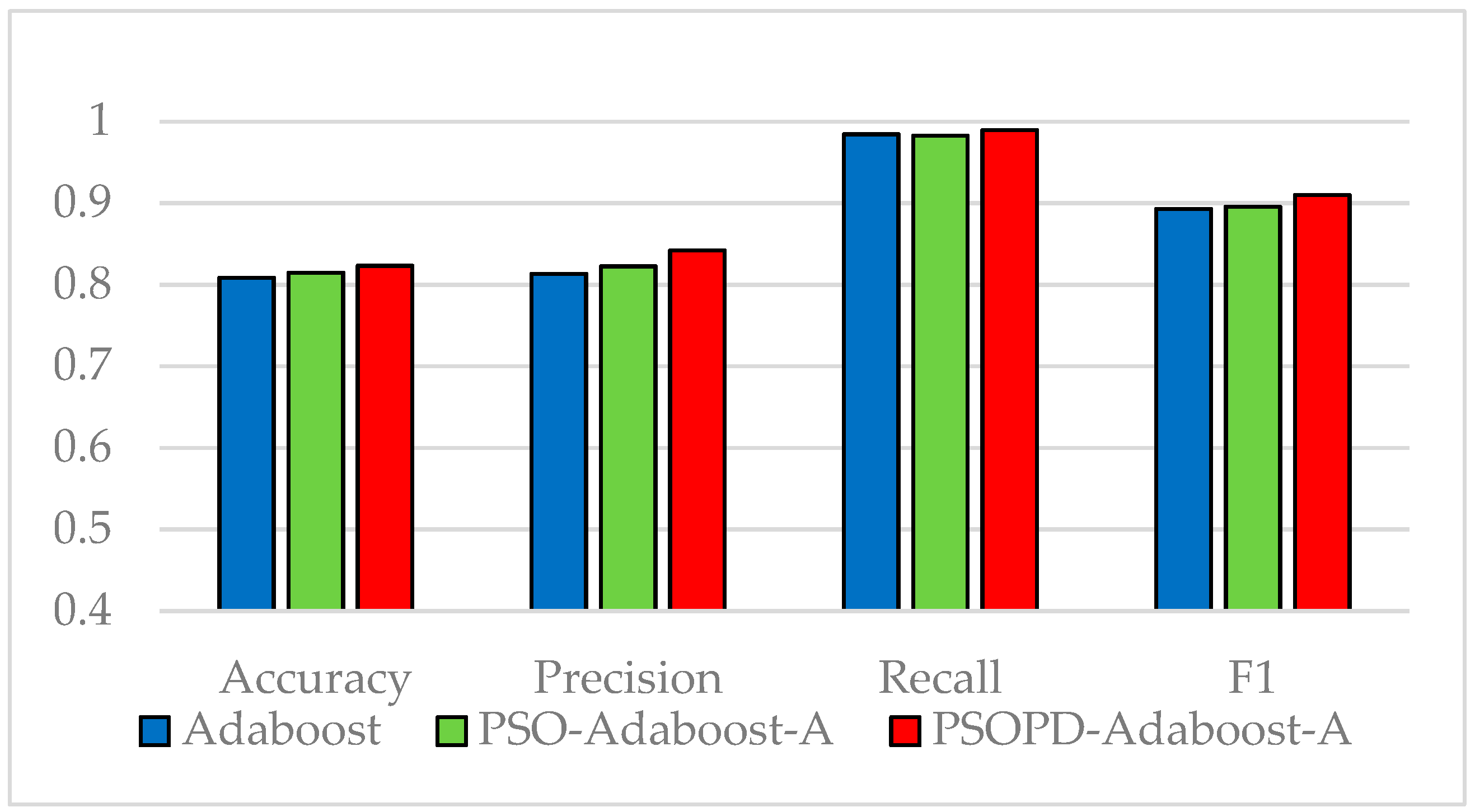
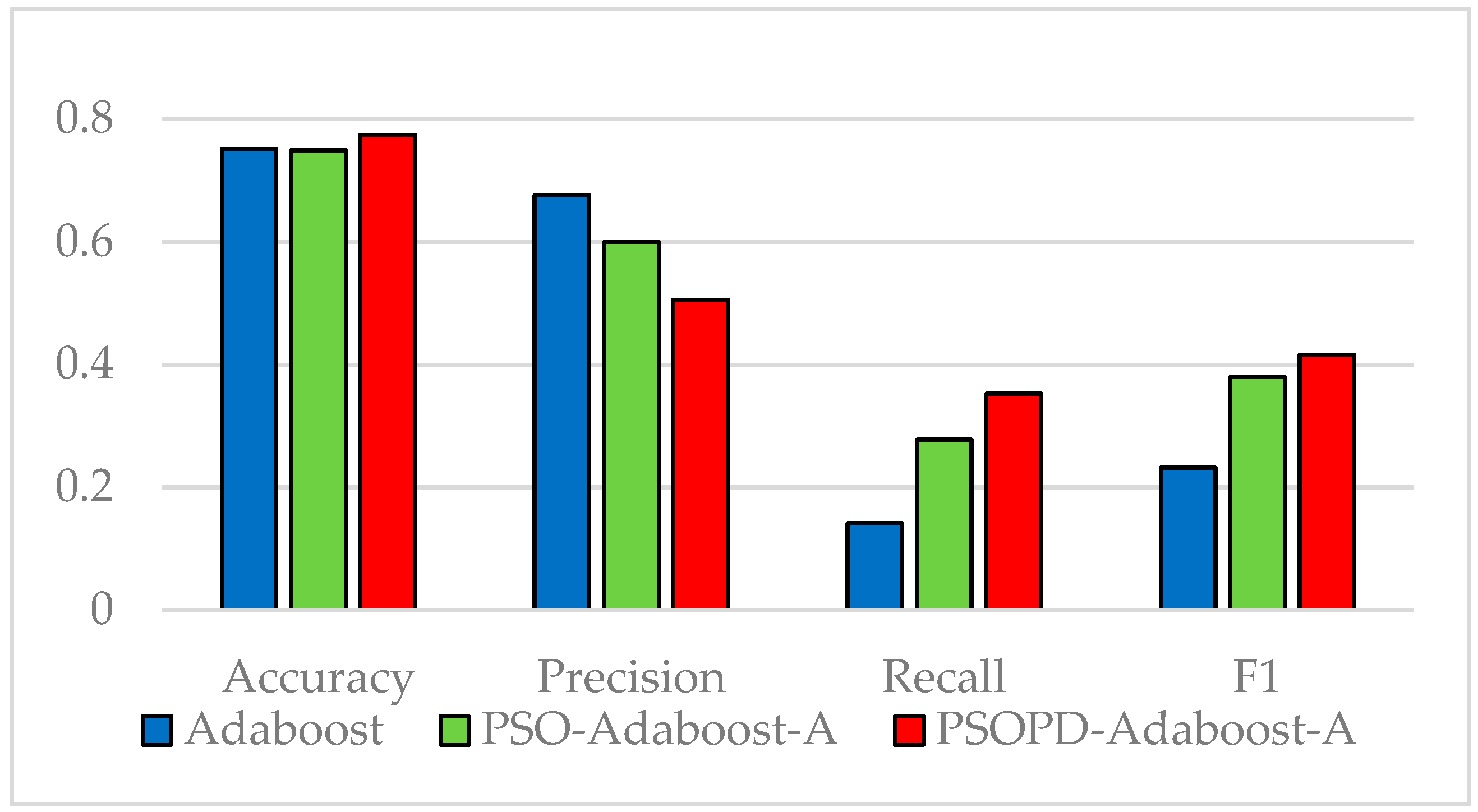
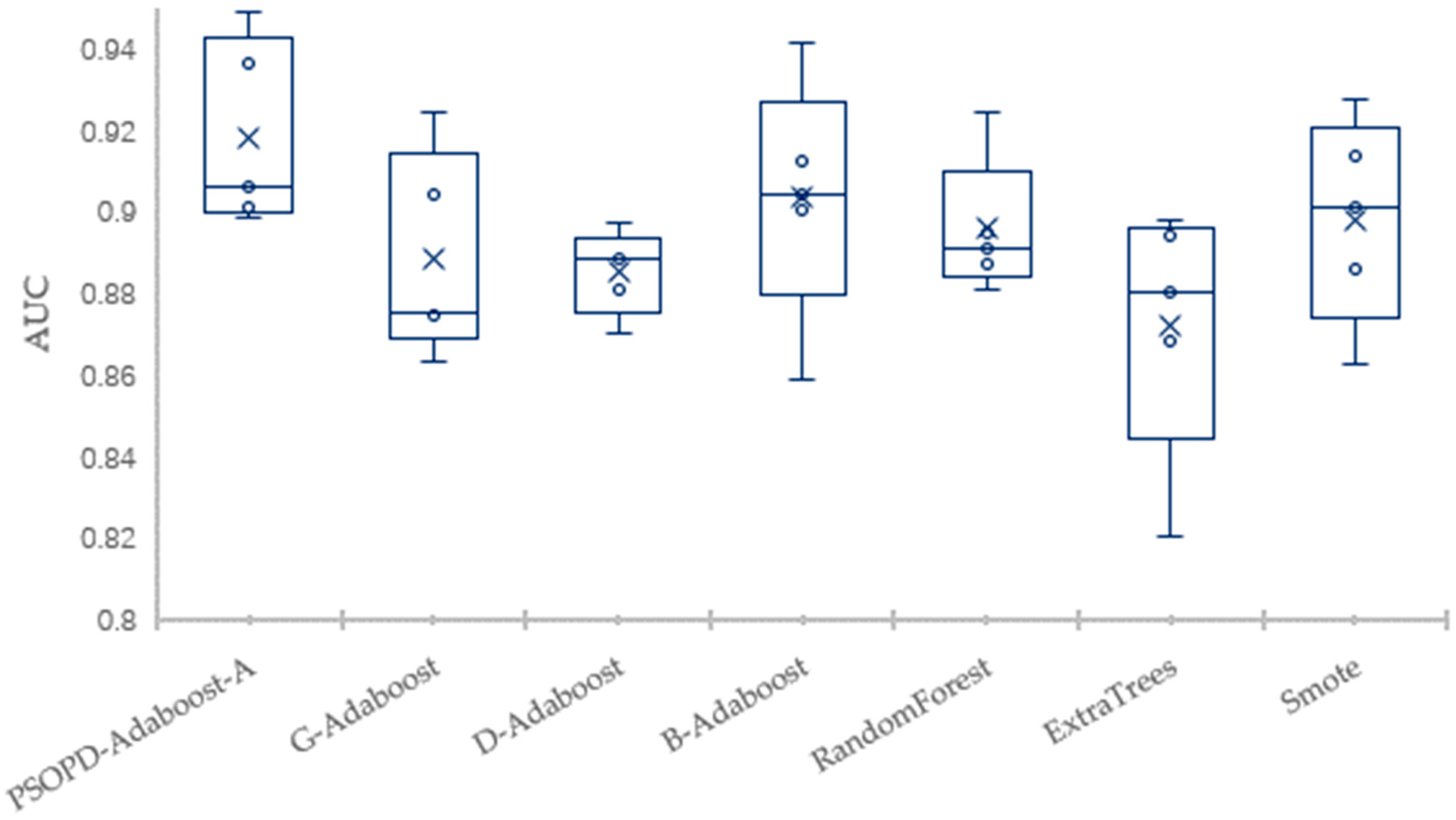
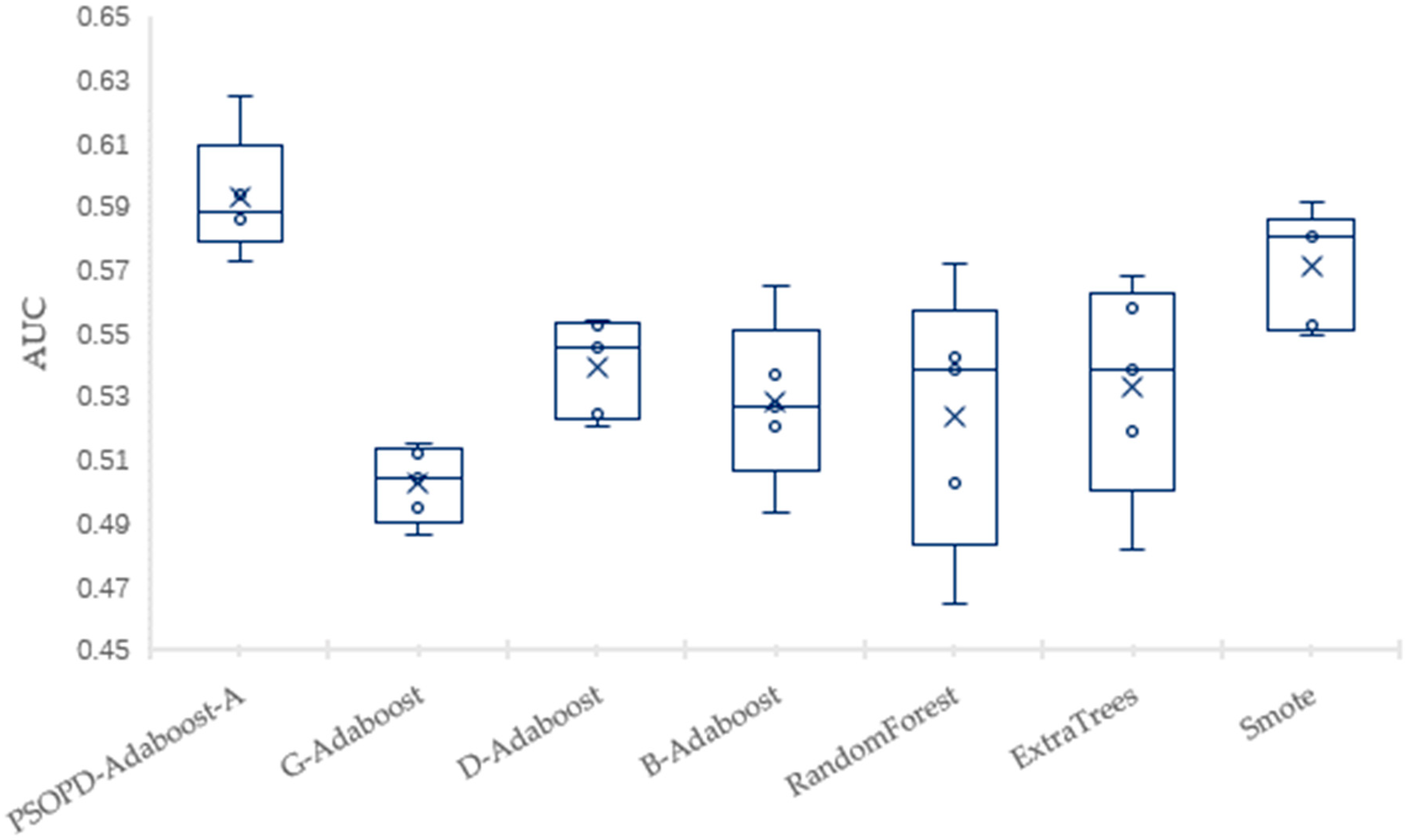
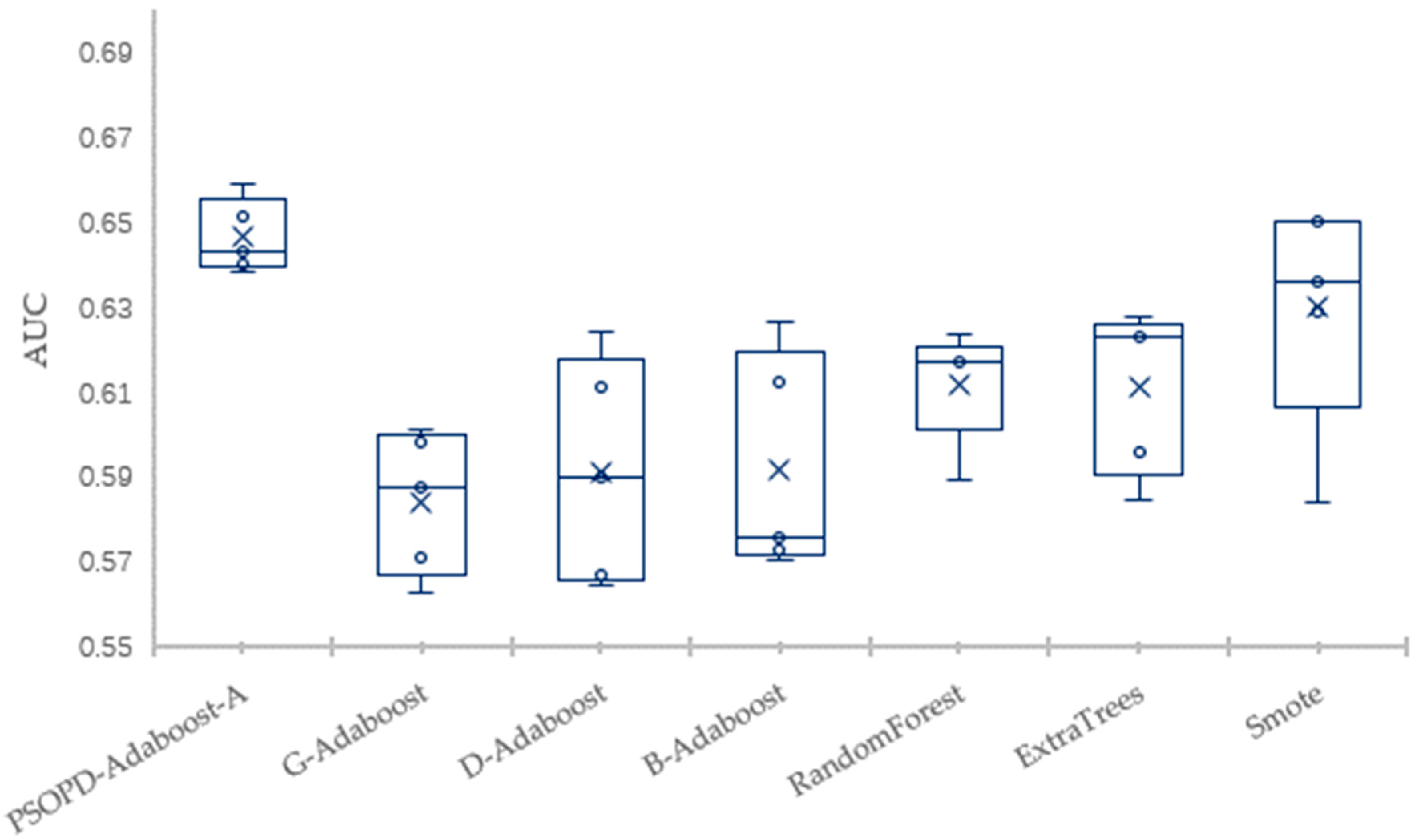
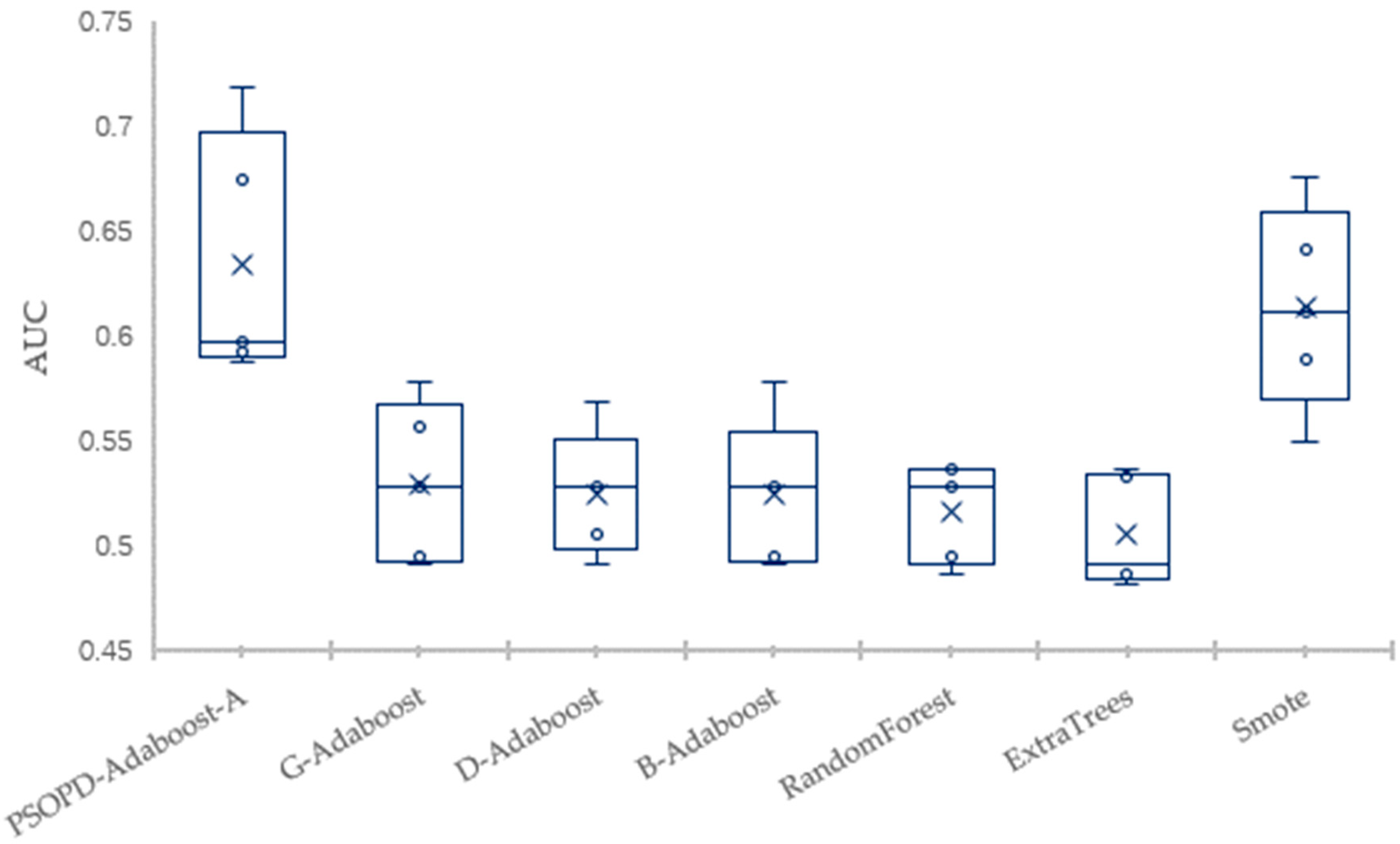
Traditional AdaBoost algorithm focuses on the misclassified samples instead of the samples of minority class. In this paper, we propose an improved AdaBoost algorithm (AdaBoost-A). Since the AUC can effectively reflect the performance of the classifier, we introduce the AUC into error calculation, making the AdaBoost focus more on the classification accuracy of the minority. Furthermore, the AdaBoost algorithm may generate redundant or useless weak classifiers, significantly affecting the readability of the classifier. We propose an ensemble algorithm, PSOPD-AdaBoost-A, which can further optimize the weight of the weak classifiers. Experimental results show that the AdaBoost-A and PSOPD-AdaBoost-A ensemble algorithms can effectively classifying imbalanced datasets, Vehicle, KC1, Horse Colic, Ionosphere, JM1, and Statlog. Next, we compare the imbalanced data classification performance of PSOPD-AdaBoost-A with ensemble algorithms including G-AdaBoost, B-AdaBoost, D-AdaBoost, Random Forest, and Extra Trees, sampling method including Smote, and four datasets with relatively high imbalance rate, Vehicle, PC3, PC5, and CM1 are used in the comparison. The results show that the PSOPD-AdaBoost-A ensemble algorithm is effective in processing data with relatively high imbalance rate compared to other improved algorithms. Our future work is dedicated to applying the proposed algorithm to the field of sensors, accurately achieving classification of targets by processing imbalanced data acquired by sensors.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}