Abstract
Computer vision is used in this work to detect lighting elements in buildings with the goal of improving the accuracy of previous methods to provide a precise inventory of the location and state of lamps. Using the framework developed in our previous works, we introduce two new modifications to enhance the system: first, a constraint on the orientation of the detected poses in the optimization methods for both the initial and the refined estimates based on the geometric information of the building information modelling (BIM) model; second, an additional reprojection error filtering step to discard the erroneous poses introduced with the orientation restrictions, keeping the identification and localization errors low while greatly increasing the number of detections. These enhancements are tested in five different case studies with more than 30,000 images, with results showing improvements in the number of detections, the percentage of correct model and state identifications, and the distance between detections and reference positions.
1. Introduction
Lighting is one of the most important aspects in the design, cost and maintenance of a building. Approximately, one-third of the electricity consumed in buildings corresponds to artificial lighting [1,2,3], with a global demand that represents 19% of all the electricity used in the world [4]. Recently, this consumption has increased at 2.4% per year [4]. These figures evidence the need for a more efficient use of the lighting resources, which requires a complete and precise inventory of the state of the lighting elements.
The collected lighting information has to be integrated in the digital representation of the building, and building information modelling (BIM) is one of the most studied and used technologies to achieve this [5,6], integrating design and project data throughout the entire lifecycle of the building [7]. Formats like industry foundation classes (IFC) [8] and green building XML schema (gbXML) [9] provide the means to manage the digital representation of all the characteristics of the building, including lighting as one of the main aspects [6,10,11]. This is useful not only to store the new information of the lighting elements, but also to provide automatic systems with the necessary information to perform accurate detections of these elements in a given construction. In fact, the accuracy of the data is one of the main concerns in modelling and simulation [10], and using the available BIM information as much as possible to improve this aspect should be a priority.
Automatic identification of lighting and lighting elements have been the focus of previous works. Elvidge et al. [12] analyzed the optimal spectral bands for the identification of lighting types and Liu et al. [13] proposed an imaging sensor-based intelligent light emitting diode (LED) lighting system to obtain a more precise lighting control. Automatic detection systems can be implemented with different methods, but one of the most commonly used is computer vision. Computer vision systems (CVSs) can be applied to a wide variety of recognition problems; some of the methods use additional depth data, with RGB-D sensors or LiDAR technology, but the cost of the equipment required for these systems is higher and the performance can still be comparable or even better with methods that only rely on image information [14].
Lighting elements fall into the category of texture-less objects. The detection and localization of this kind of objects is specially challenging, since the distinctive features that works on highly-textured objects are not present. Therefore, traditional object detection methods such as scale-invariant feature transform (SIFT) [15] and speeded-up robust features (SURF) [16] do not work in this case. Thus, many alternatives have appeared to solve this problem based on edge information, and can be categorized into three groups: keypoint-based, shape-based and template-based.
First, keypoint-based algorithms, with a similar philosophy to SIFT and SURF, tries to generate descriptors incorporating invariant properties from keypoints in the image. Among these algorithms, Tombari et al. presented the bunch of lines descriptor (BOLD) features [17], using a compact and distinctive representation of groups of neighboring line segments. Later, Chan et al. developed the bounding oriented-rectangle descriptors for enclosed regions (BORDER) [18], where they introduced a modified line-segment detection technique called Linelets, and more recently they introduced the binary integrated net descriptors (BIND) [19], that encode multi-layered binary-represented nets for high precision edge-based description. Also in this category, Damen et al. [20] used a system based on a constellation of edgelets, which was later improved [21].
The shape-based methods try to learn the shape of the object from the edge information. Ferrari et al. [22,23] introduced a method to learn the shape model of an object with a Hough-style voting for object localization. Moreover, Carmichael and Hebert [24] trained a classifier cascade to recognize complex-shaped objects in cluttered environments based on shape information.
Finally, the template-based methods were the first to provide good results for texture-less objects. Barrow et al. first introduced the chamfer matching [25]. Later, Borgefors [26] improved the correspondence measure and embedded the algorithm in a resolution pyramid, reducing the number of false matches and increasing the speed of the method. After that, many methods based on the chamfer matching appeared, including the work of Shotton et al. [27], introducing an automatic visual recognition system based on local contour features with an additional channel for the edge orientation. There is also the work of Hinterstoisser et al. [28], with a gradient-based template approach yielding faster and more robust results with respect to background clutter. Later, Liu et al. [29] presented the fast directional chamfer matching (FDCM), using a joint location/orientation space to calculate the 3D distance transform, reducing its computational time from linear to sublinear. Based on this work, Imperoli and Pretto [14] introduced the direct directional chamfer optimization (D2CO) for object registration using the directional chamfer distance. The works of Liu et al. [29] and Imperoli and Pretto [14] were used by Troncoso et al. to create a framework for the detection, identification and localization of lighting elements in buildings [30], which was later improved to work with any lamp shape [31].
These methods provide good detection results, but they do not fully utilize the available BIM information of the building, yielding intermediate values that are not tailored to the specific features of the given building space. Using the framework presented and later generalized in our previous works [30,31], we tackle this problem by introducing two enhancements to the internal algorithms of the system: first, a new pose filter based on the reprojection error is used to discard erroneous poses; second, the optimization methods used in the initial estimation and in the refinement step are modified to force an orientation alignment based on the geometric data in the BIM of the building. These modifications lead to better results in terms of the following three relevant metrics: total number of detections, identification performance, and distance to reference values.
The rest of the paper is structured as follows: Section 2 contains the description of the methodology proposed in this work with the new additions to the system. Section 3 explains the experimental system used to evaluate the contributions, with the relevant results presented in Section 4. Finally, Section 5 contains the main conclusions of this work.
2. Materials and Methods
The modifications proposed in this work were incorporated in the first part of the complete detection system [30,31]: the image and geometric processing, previous to the clustering and BIM insertion. The updated diagram of steps is depicted in Figure 1. An in-depth description of this process can be found in [30], but we include here a brief explanation for the sake of completeness. The first step corresponds to the extraction of initial pose candidates, where the image was analyzed to extract blobs and then obtain simplified shapes, either polygonal or elliptical. The shapes were used to estimate candidate poses, and the set of candidates was filtered based on different thresholds. The second step corresponds to the model selection, where the region of interest (ROI) was determined for each candidate, and the best model from the database was selected based on the fast directional chamfer matching (FDCM) [29] computed in the ROI. Finally, in the last step the poses were refined based on the direct directional chamfer optimization (D2CO) [14], and a score was obtained that is used to discard false positives.
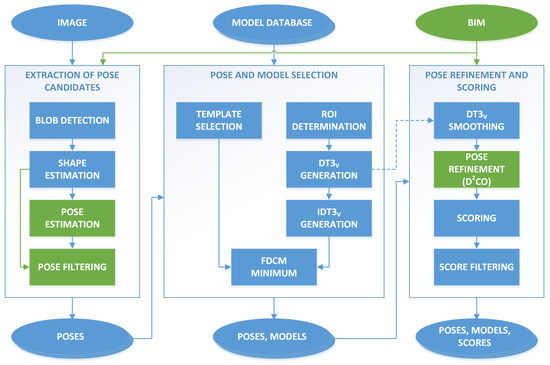
Figure 1.
Diagram of the modified detection system, with the inclusion of building information modelling (BIM) data in the first and third steps. The modified parts with respect to [30] are highlighted in green.
The main contribution with respect to the system presented in [30,31] focuses on the use of BIM information of the building to align the orientations of the detections with the closest surface of the model. This introduces new restrictions in the extraction of pose candidates as well as the pose refinement, where both the initial pose estimation and the optimized version of this pose has to lie in a subset of the 3D rotation group.
This restrictions forced the estimates to be geometrically viable in much more cases than the original system. This was positive when the projection did not modify the original pose greatly, as it can compensate imprecisions in the original shape estimation, but it can also introduce errors when the modifications are too high, resulting in inaccurate detections that ended up falling inside the valid geometric limits. Thus, a new constraint was introduced to check the pose against the original light shape by means of the reprojection error.
The relevant altered steps to incorporate these enhancements are displayed in green in Figure 1. The rest of this section describes in detail these modifications: the orientation alignment, that changes the pose estimation and pose refinement methods, and the pose filtering with the new reprojection error threshold.
2.1. Orientation Alignment in Optimization Problems
The pose estimation and pose refinement steps were based on optimization problems that involve projections of points from model coordinates to homogeneous camera coordinates to evaluate their position in the image plane. Omitting the non-linear distortion effects for the sake of simplicity, this transformation process from a point to a projected point is a well-known problem defined by the model , view and projection matrices, as presented in (1):
In the new system, we restricted the original problem to produce object poses that keep the orientation aligned with a given plane. This plane corresponds to the closest ceiling in the BIM model of the building in the case of embedded lamps, or the plane in the case of hanging lamps, as the ceiling orientation does not influence the orientation of the lamps for this type of models. This means that we needed to (a) force the initial orientation to have the z axis parallel to the normal vector of the plane, and (b) restrict the possible orientation changes to only one degree of freedom, corresponding to rotations along this z axis.
Let be the orientation vector of the model transformation , i.e., the transformation from model coordinates to world coordinates. Let be the orientation vector corresponding to a rotation that aligns the z axis with the plane normal , obtained as in Equations (2) and (3), with a corresponding transformation matrix :
Then, to restrict the optimization problem we can transform the coordinate system inside the optimization problem and force the first two components of to be zero, because a rotation vector of the form corresponds a rotation along the z axis. The required steps, depicted in Figure 2, are as follows:
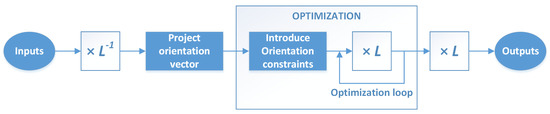
Figure 2.
Sequence of steps required to adapt the optimization problem with the orientation alignment. This adaptation is required in both the initial pose estimation and the final pose refinement.
- Calculate an aligned model matrix , with a corresponding orientation vector .
- Project the vector to the z axis, setting the first two components to zero. The result is , as presented in Equation (4), with the corresponding transformation matrix , being a unit normal vector along the z axis:
- Use in the optimization problem, constraining it to changes only in the third component of this vector and performing the projections as presented in (5):Thus, the degrees of freedom for the problem were reduced from six to four.
- Calculate the final optimized model pose from the result of the optimization process, : .
To solve the optimization problem, we employed the same iterative method used in our previous work [30,31] based on Levenberg-Marquardt optimization [32,33]. Figure 3 shows a diagram of the different transformations that are performed during the detection process, including the original model and aligned model transformations.
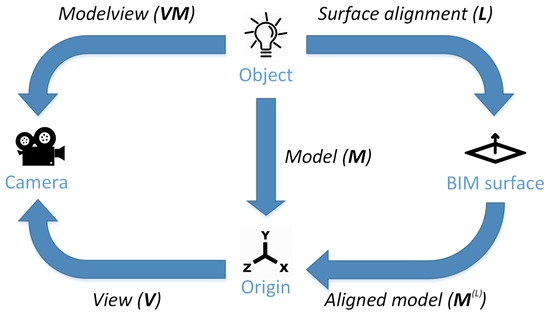
Figure 3.
Transformations between coordinate systems involved in the detection process.
2.2. Pose Estimation
To force the orientation of the final detected poses, the first step was to modify the initial estimations based on the shapes in the image. We had to use different algorithms for polygonal and for circular shapes, as described below.
2.2.1. Polygonal Shapes
For polygonal shapes we solved the original perspective-n-point (PnP) problem as explained in [30] to obtain the initial pose. Then, as described in Section 2.1, we transformed the pose and project the orientation vector to the plane normal. This first estimation was a good starting point for the second PnP problem, that tried to minimize the reprojection error of the object pose in the camera plane, using the traditional expression presented in (6), with and being the i-th pair of object and camera points, respectively:
Using this optimization problem with the method in Section 2.1 we obtain a pose that is aligned with the plane and has an expected low reprojection error.
2.2.2. Circular Shapes
For circular shapes, we used a modified version of the algorithm presented in [31], following analogous reasoning to that of Section 2.1. First, we changed the reference coordinate system with respect to [31]: instead of the camera coordinates, we used the coordinates of the rotated object to be able to force the orientation of the normal vector. Then, we had to project all the points in the object coordinate system to the coordinate system aligned with the plane normal. To denote this transformation, we use the following notation: .
Using the equations of the projection line from the camera origin to the image point, and the circle plane , we can obtain the projected point on as in Equation (7), being the camera center, the circle center, the unit normal vector of , and :
With Equation (7), and following the same procedure as the one presented in [31], we solved the minimization problem based on the distance to the circumference of radius to obtain the optimal values of and . This is presented in Equations (8) and (9):
2.3. Pose Refinement
The refinement step must also be restricted to produce poses aligned with the appropriate surface in the BIM. In this case, the constraints are imposed on the input orientation vector for the direct directional chamfer optimization (D2CO) method [14]. In this case there is no difference between polygonal and circular shapes since the cost function is based on edge information from the image instead of point-to-point correspondences.
2.4. Pose Filtering
Forcing the orientation of the detected objects has the negative side effect of introducing potentially very different poses that do not match the original estimation. Therefore, an additional filter was required to discard these erroneous poses. We used the reprojection error to verify this similarity: the error function is given in Equation (12) as the average squared reprojection error between the N pairs of object and camera points . The shape area A is introduced to normalize the error depending on the size and proximity of the object.
We can directly use (12) with polygonal shapes; however, with circular shapes there are no direct correspondences of object points for the given camera points. Thus, for each camera point , we calculate the virtual object point by choosing the closest point in the circumference to the projected camera point. We used the object coordinate system to simplify the expressions, performing the relevant transformations when necessary. The sequence of operations is:
- First, the projected camera point on the plane was obtained, again, using the equations of the projection line and the circle plane . This equation system is presented in Equation (13), with the camera center and :
- The intersection between the line and the circumference with radius was obtained by solving the system of equations in (14), comprising the line from the circle center to , and the circumference of the object:
- Choosing the result in the same quadrant gives the closest intersection that is used as the corresponding object point for .
In our experiments, we used a threshold of 0.015 and 0.035 for polygonal and for circular shapes, respectively, based on experimental results.
3. Experimental System
The main contributions presented in Section 2 were evaluated in five case studies, each with a different lamp model. These five areas, shown in Figure 4, correspond to the five lamp models of the database presented in [31] that is used for the experiments. The acquisition of the images was performed at a walking speed of ≈1 m/s, with a pitch of ≈60° with respect to the horizontal plane and positioning the camera at 1.5 m from the floor. The 1920 × 1080 images were extracted using a Lenovo Phab 2 Pro, with the Google Tango technology [34]. This acquisition protocol was the same as the one described in [31].

Figure 4.
Spaces for the five case studies used to evaluate the system: (a–e) Case studies 1 to 5.
The first three case studies, corresponding to models 1 to 3 of the database, were located in the School of Industrial Engineering of the University of Vigo. The reference values for these areas were obtained using manual inspection of the lamp poses. Case studies 4 and 5 were the same as the ones presented in [31], with data collected in the Mining and Energy Engineering School of the University of Vigo and ground truth values obtained from point clouds extracted with LiDAR sensors [31]. The number of images and lamps of the complete dataset for the experimental system are included in Table 1, with a total of more than 30,000 images.

Table 1.
Description of the complete dataset used, including a description of the physical space, the model number and the number of images, lamps and lamps turned on.
The algorithms described in Section 2 were implemented inside the same C++ framework developed for [30,31], built using several software libraries to solve different problems related to image processing, geometry and optimization [35,36,37,38].
4. Results and Discussion
Using the experimental system described in Section 3, we performed tests with three different versions of the system: (i) the unconstrained original system, that is the same as the one presented in [31], (ii) the system with the additional reprojection error filtering, and (iii) the complete improved system with reprojection error filtering and orientation alignment. Because of the introduction of the three new models, especially model 3 which had the lowest circularity [39] values, we have modified the shape threshold for the experiments with respect to [31], using a value of 14, being this a good tradeoff between circular and polygonal shapes.
Example images with detections for each case study are presented in Figure 5. Moreover, the localized detections in the xy-plane are shown in Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10 with the corresponding reference values. These figures depict the final centers after the clustering operation, showing similar localization values with the three different versions of the system, with the most obvious improvement being the additional two correct detections for case study 5. These results will be discussed in detail in the rest of the section, using three key metrics to evaluate the improvements; total number of detections, identification rate and distance to reference value.

Figure 5.
Detections for each of the case studies in the experiments: (a–e) Case studies 1 to 5.
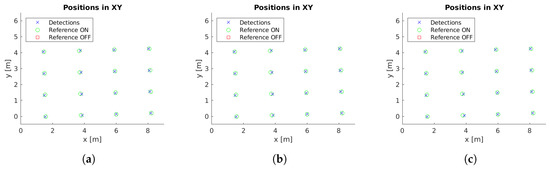
Figure 6.
Cluster centers and reference values for case study 1. (a) Unconstrained system [31], (b) system with reprojection error filtering, and (c) system with filtering and orientation alignment.
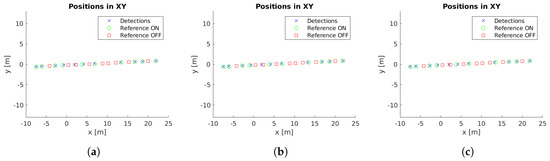
Figure 7.
Cluster centers and reference values for case study 2. (a) Unconstrained system [31], (b) system with reprojection error filtering, and (c) system with filtering and orientation alignment.
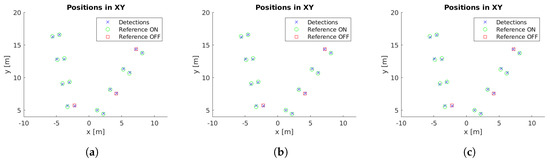
Figure 8.
Cluster centers and reference values for case study 3. (a) Unconstrained system [31], (b) system with reprojection error filtering, and (c) system with filtering and orientation alignment.
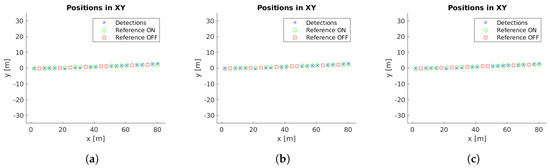
Figure 9.
Cluster centers and reference values for case study 4. (a) Unconstrained system [31], (b) system with reprojection error filtering, and (c) system with filtering and orientation alignment.
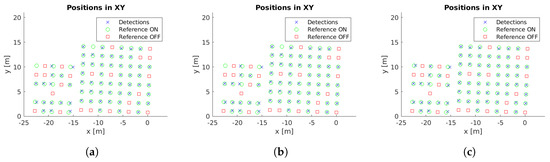
Figure 10.
Cluster centers and reference values for case study 5. (a) Unconstrained system [31], (b) system with reprojection error filtering, and (c) system with filtering and orientation alignment.
4.1. Number of Detections
The total number of detections for the three different modes are presented in Table 2. The use of the reprojection error filtering lowered the number of detections even when the orientation alignment is not used, removing detections whose projected shape on the image is too different from the expected values. The orientation alignment, however, greatly increases the total number of detections, even with the filtering, with an increase of 48.91%. This resulted in a more reliable detection system, as the probability of capturing the object is higher, specially when it is only visible in a small number of frames.
Table 2.
Total number of detections for the unconstrained system [31], the system with reprojection error filtering (REF), and the system with reprojection error filtering and orientation alignment (REF + OA).
The results per cluster evidence the importance of increased reliability, as shown in Table 3. This table shows relevant figures for the number of detections that are used to calculate each cluster center. We can see that there is a great increase in the minimum number of detections, with the original system having only one detection for one cluster in case study 4, while the updated system always has at least 18 detections per cluster.
Table 3.
Statistics of the number of detections per cluster for the unconstrained system [31], the system with reprojection error filtering (REF), and the system with reprojection error filtering and orientation alignment (REF + OA).
4.2. Identification Rate
The correct identification of lamp model and state is crucial for the system. Figure 11, Figure 12 and Figure 13 show the distribution of accumulated lamp model scores identified for each cluster. Each of the bars corresponds to the total sum of scores for the individual detections, with different colors for each lamp model and the final decision for the cluster below.
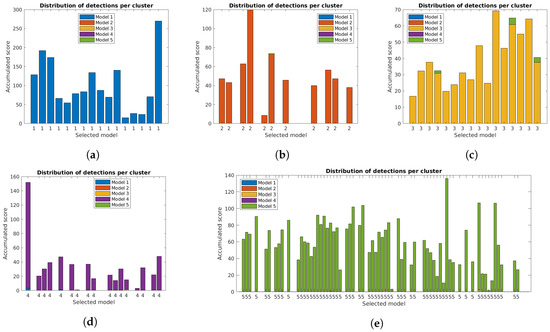
Figure 11.
Accumulated scores for each lamp model in each cluster of the five case studies for the unconstrained system [31]. The model corresponding to the highest value is included below each bar: (a–e) Case studies 1 to 5.
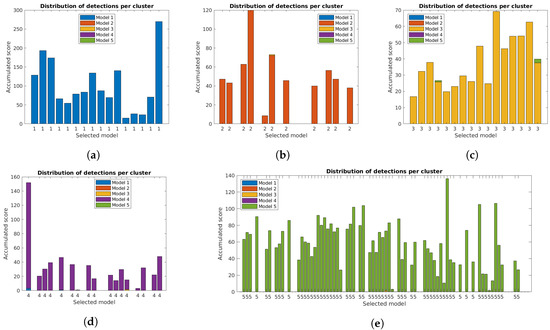
Figure 12.
Accumulated scores for each lamp model in each cluster of the five case studies with reprojection error filtering. The model corresponding to the highest value is included below each bar: (a–e) Case studies 1 to 5.
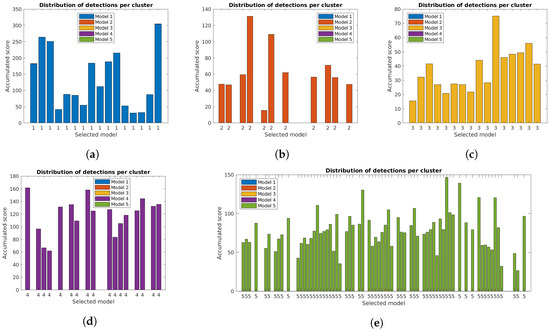
Figure 13.
Accumulated scores for each lamp model in each cluster of the five case studies with filtering and orientation alignment. The model corresponding to the highest value is included below each bar: (a–e) Case studies 1 to 5.
The additional filtering had a very small impact on the total scores, while the use of the orientation alignment greatly increased the values. As previously mentioned, this is important to guarantee good results in the final clusters, and is specially relevant in some clusters, particularly for case studies 4 and 5, that had low values with the unconstrained system [31].
Based on these accumulated scores, the system was able to identify the correct model for all the clusters independently of the method used, but the number of correct individual identifications is, again, important for the reliability of the identification performance of the system. To provide a more direct analysis of this aspect, the confusion matrices for lamp model and lamp state are presented in Figure 14 and Figure 15, respectively. Here, both the filtering and the alignment had positive effects in the model identification, keeping a very low error rate with orientation alignment even when there are far more detections. The total error decreases from 0.30% with the unconstrained system, to 0.17% reprojection error filtering and, finally, to 0.07% with the complete new system.
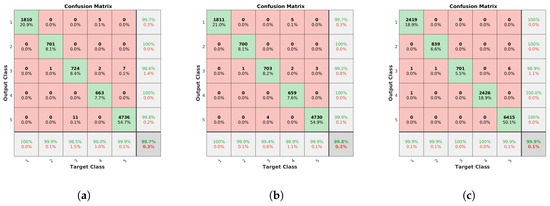
Figure 14.
Confusion matrices for the model classes. Values in the diagonal indicate the number of correct matches for each class, while the rest of the values correspond to incorrect identifications depending on the expected and detected class. Percentages of correct and incorrect identifications are included in the last row and column. (a) Unconstrained system [31], (b) system with reprojection error filtering, and (c) system with filtering and orientation alignment.
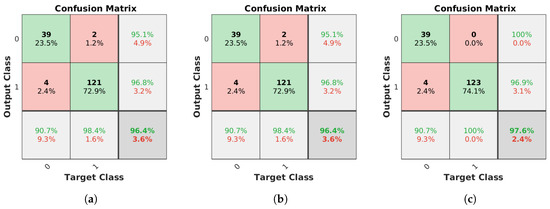
Figure 15.
Confusion matrices for the lamp state, with class 0 and 1 representing the off and on state, respectively. Values in the diagonal indicate the number of correct matches for each class, while the rest of the values correspond to incorrect identifications depending on the expected and detected class. Percentages of correct and incorrect identifications are included in the last row and column. (a) Unconstrained system [31], (b) system with reprojection error filtering, and (c) system with filtering and orientation alignment.
Regarding lamp state, the filtering had no effect on the final error value of 3.61%, but the orientation alignment yields two additional clusters corresponding to lamps that are turned on, improving the final error value to 2.41%.
4.3. Distance to Reference
The final locations of the cluster centers have to match the reference positions to provide an accurate localization of the lamps. While Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10 provide a visual representation of this similarity, Table 4 contains numeric values for the average distances between the position of each cluster center and its corresponding closest reference point. The inclusion of the additional filter provides a marginally worse localization performance, from 14.14 cm to 14.24 cm, but the use of the pose alignment improves the results, lowering the average distance to 13.63 cm.
Table 4.
Average distance between cluster centers and reference positions, in centimeters, for the unconstrained system [31], the system with reprojection error filtering (REF), and the system with reprojection error filtering and orientation alignment (REF + OA).
4.4. Applications and Future Work
The results presented in this section show that the proposed system is valid for the intended use cases, with an increased performance with respect to previous methods. The required steps to leverage this new system include the collection of (i) the geometry of, at least, the ceiling of the spaces that contains the lamps and (ii) a database containing, but not limited to, the expected 3D lamp models, which can be obtained from manufacturers. Moreover, special care must be taken with hanging lamps in the last projection step. In this work, we have used the distance from the ceiling to the lamp plane to generate the final results to validate the contributions, but this variable might not be known beforehand.
Thus, to improve the system and provide a more streamlined solution, we are currently working on methods to estimate this virtual plane automatically from the detection points and the BIM information, removing the requirement of any prior knowledge regarding the configuration of lamp positions.
5. Conclusions
In this work, we have presented two new contributions to our previous system for the detection of lighting elements in buildings: (i) the early use of BIM information to restrict the possible orientation values of the detections and (ii) a reprojection error filter that discards poses that do not match the estimated light surface shape. The new constrained system was tested with a dataset of more than 30,000 images in five case studies with a total of 166 lamps of different models to analyze the quantitative improvements of the proposed modifications.
First, the number of individual detections is increased from 8618 to 12,809, almost 50% higher, making the system more reliable, specially for clusters with a low detection count on the original system. Moreover, the number of incorrect model identifications is reduced from 0.30% to 0.07%, preserving a very low number of errors despite the high increase in the number of detections. Furthermore, the identification of lamp state is also improved, with the error decreasing from 3.61% to 2.41%. Finally, the average distance between the cluster centers and the reference positions is reduced from 14.14 cm to 13.63 cm. These results shows an improvement of the new system with all the metrics used, yielding better detection rate, identification performance and localization accuracy.
Author Contributions
Conceptualization, F.T.-P.; Data curation, E.G.-Á. and A.E.; Funding acquisition, E.G.-Á.; Investigation, F.T.-P.; Methodology, F.T.-P.; Resources, E.G.-Á. and A.E.; Software, F.T.-P.; Supervision, P.E.-O. and R.P.D.-R.; Validation, F.T.-P.; Visualization, F.T.-P., P.E.-O. and R.P.D.-R.; Writing—original draft, F.T.-P.; Writing—review and editing, P.E.-O. and R.P.D.-R.
Funding
Authors want to give thanks to the Xunta de Galicia under Grant ED481A and the Spanish Ministry of Economy and Competitiveness under the National Science Program TEC2017-84197-C4-2-R.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| BIM | Building information modelling |
| IFC | Industry foundation classes |
| gbXML | Green Building XML Schema |
| LED | Light emitting diode |
| CVS | Computer vision system |
| SIFT | Scale-invariant feature transform |
| SURF | Speeded-up robust features |
| BOLD | Bunch of lines descriptor |
| BORDER | Bounding oriented-rectangle descriptors for enclosed regions |
| BIND | Binary integrated net descriptors |
| FDCM | Fast directional chamfer matching |
| D2CO | Direct directional chamfer optimization |
| ROI | Region of interest |
| PnP | Perspective-n-point |
References
- Soori, P.K.; Vishwas, M. Lighting control strategy for energy efficient office lighting system design. Energy Build. 2013, 66, 329–337. [Google Scholar] [CrossRef]
- Pérez-Lombard, L.; Ortiz, J.; Pout, C. A review on buildings energy consumption information. Energy Build. 2008, 40, 394–398. [Google Scholar] [CrossRef]
- Baloch, A.; Shaikh, P.; Shaikh, F.; Leghari, Z.; Mirjat, N.; Uqaili, M. Simulation tools application for artificial lighting in buildings. Renew. Sustain. Energy Rev. 2018, 82, 3007–3026. [Google Scholar] [CrossRef]
- Waide, P.; Tanishima, S. Light’s Labour’s Lost: Policies for Energy-Efficient Lighting: In Support of the G8 Plan of Action; OECD/IEA: Paris, France, 2006. [Google Scholar]
- Sanhudo, L.; Ramos, N.; Poças Martins, J.; Almeida, R.; Barreira, E.; Simões, M.; Cardoso, V. Building information modeling for energy retrofitting—A review. Renew. Sustain. Energy Rev. 2018, 89, 249–260. [Google Scholar] [CrossRef]
- Asl, M.R.; Zarrinmehr, S.; Bergin, M.; Yan, W. BPOpt: A framework for BIM-based performance optimization. Energy Build. 2015, 108, 401–412. [Google Scholar] [CrossRef]
- Succar, B. Building information modelling framework: A research and delivery foundation for industry stakeholders. Autom. Constr. 2009, 18, 357–375. [Google Scholar] [CrossRef]
- IFC4 Add2 Specification. Available online: http://www.buildingsmart-tech.org/specifications/ifc-releases/ifc4-add2 (accessed on 27 March 2019).
- gbXML—An Industry Supported Standard for Storing and Sharing Building Properties between 3D Architectural and Engineering Analysis Software. Available online: http://www.gbxml.org/ (accessed on 27 March 2019).
- Lu, Y.; Wu, Z.; Chang, R.; Li, Y. Building Information Modeling (BIM) for green buildings: A critical review and future directions. Autom. Constr. 2017, 83, 134–148. [Google Scholar] [CrossRef]
- Welle, B.; Rogers, Z.; Fischer, M. BIM-Centric Daylight Profiler for Simulation (BDP4SIM): A methodology for automated product model decomposition and recomposition for climate-based daylighting simulation. Build. Environ. 2012, 58, 114–134. [Google Scholar] [CrossRef]
- Elvidge, C.D.; Keith, D.M.; Tuttle, B.T.; Baugh, K.E. Spectral Identification of Lighting Type and Character. Sensors 2010, 10, 3961–3988. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, Q.; Yang, J.; Jiang, T.; Liu, Z.; Li, J. Intelligent Luminance Control of Lighting Systems Based on Imaging Sensor Feedback. Sensors 2017, 17, 321. [Google Scholar] [CrossRef]
- Imperoli, M.; Pretto, A. D2CO: Fast and robust registration of 3d textureless objects using the directional chamfer distance. Lect. Notes Comput. Sci. 2015, 9163, 316–328. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Gool, L.V. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Tombari, F.; Franchi, A.; Di, L. BOLD Features to Detect Texture-less Objects. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1265–1272. [Google Scholar] [CrossRef]
- Chan, J.; Lee, J.A.; Kemao, Q. BORDER: An Oriented Rectangles Approach to Texture-Less Object Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2855–2863. [Google Scholar]
- Chan, J.; Lee, J.A.; Kemao, Q. BIND: Binary Integrated Net Descriptors for Texture-Less Object Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3020–3028. [Google Scholar] [CrossRef]
- Damen, D.; Bunnun, P.; Calway, A.; Mayol-Cuevas, W. Real-time learning and detection of 3D texture-less objects: A scalable approach. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Hodaň, T.; Damen, D.; Mayol-Cuevas, W.; Matas, J. Efficient texture-less object detection for augmented reality guidance. In Proceedings of the 2015 IEEE International Symposium on Mixed and Augmented Reality Workshops, Fukuoka, Japan, 29 September–3 October 2015; pp. 81–86. [Google Scholar]
- Ferrari, V.; Fevrier, L.; Schmid, C.; Jurie, F. Groups of adjacent contour segments for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 36–51. [Google Scholar] [CrossRef] [PubMed]
- Ferrari, V.; Jurie, F.; Schmid, C. From Images to Shape Models for Object Detection. Int. J. Comput. Vis. 2010, 87, 284–303. [Google Scholar] [CrossRef]
- Carmichael, O.; Hebert, M. Shape-based recognition of wiry objects. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1537–1552. [Google Scholar] [CrossRef] [PubMed]
- Barrow, H.G.; Tenenbaum, J.M.; Bolles, R.C.; Wolf, H.C. Parametric Correspondence and Chamfer Matching: Two New Techniques for Image Matching. In Proceedings of the 5th International Joint Conference on Artificial Intelligence, Cambridge, MA, USA, 22–25 August 1977; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1977; Volume 2, pp. 659–663. [Google Scholar]
- Borgefors, G. Hierarchical chamfer matching: A parametric edge matching algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 849–865. [Google Scholar] [CrossRef]
- Shotton, J.; Blake, A.; Cipolla, R. Multiscale Categorical Object Recognition Using Contour Fragments. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 1270–1281. [Google Scholar] [CrossRef]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient Response Maps for Real-Time Detection of Textureless Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef]
- Liu, M.Y.; Tuzel, O.; Veeraraghavan, A.; Chellappa, R. Fast Directional Chamfer Matching. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Troncoso-Pastoriza, F.; Eguía-Oller, P.; Díaz-Redondo, R.P.; Granada-Álvarez, E. Generation of BIM data based on the automatic detection, identification and localization of lamps in buildings. Sustain. Cities Soc. 2018, 36, 59–70. [Google Scholar] [CrossRef]
- Troncoso-Pastoriza, F.; López-Gómez, J.; Febrero-Garrido, L. Generalized Vision-Based Detection, Identification and Pose Estimation of Lamps for BIM Integration. Sensors 2018, 18, 2364. [Google Scholar] [CrossRef] [PubMed]
- Levenberg, K. A method for the solution of certain non-linear problems in least squares. Quart. J. Appl. Maths. 1944, II, 164–168. [Google Scholar] [CrossRef]
- Marquardt, D.W. An Algorithm for Least-Squares Estimation of Nonlinear Parameters. SIAM J. Appl. Math. 1963, 11, 431–441. [Google Scholar] [CrossRef]
- Marder-Eppstein, E. Project Tango. In ACM SIGGRAPH 2016 Real-Time Live! ACM: New York, NY, USA, 2016; p. 25. [Google Scholar] [CrossRef]
- Bradski, G.; Kaehler, A. OpenCV. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Available online: https://www.graphics.rwth-aachen.de/media/papers/openmesh1.pdf (accessed on 27 March 2019).
- Ceres Solver. Available online: http://ceres-solver.org (accessed on 27 March 2019).
- Shreiner, D.; Sellers, G.; Kessenich, J.M.; Licea-Kane, B.M. OpenGL Programming Guide: The Official Guide to Learning OpenGL, Version 4.3, 8th ed.; Addison-Wesley Professional: Boston, MA, USA, 2013. [Google Scholar]
- Rosin, P. Computing global shape measures. Handbook of Pattern Recognition and Computer Vision, 3rd ed.; World Scientific Publishing Company Inc.: Singapore, 2005; pp. 177–196. [Google Scholar]















© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).