Design and Analysis of a Lightweight Context Fusion CNN Scheme for Crowd Counting



Abstract
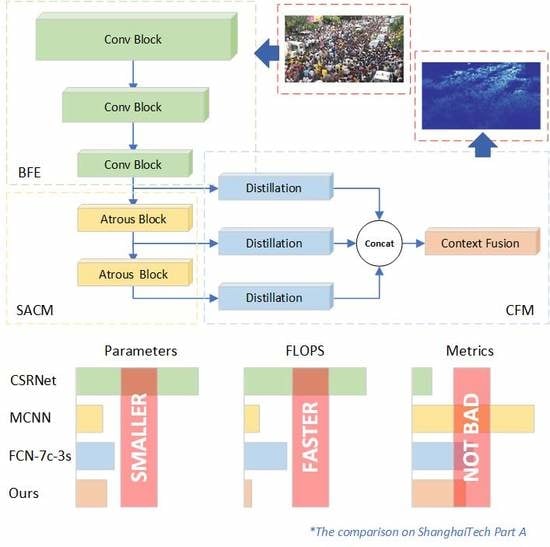
:
1. Introduction
2. Related Work
3. Method
3.1. Architecture
- Single-column style
- A minimum sufficient receptive size
- Context embedding
3.1.1. Backbone
3.1.2. Context Fusion Module
3.2. Training Details
3.2.1. Data Augmentation
3.2.2. Ground Truth
3.2.3. Object Function
4. Experimental Results and Discussions
4.1. Metrics
4.2. Ablation Study and Comparisons
4.3. Performance Evaluation
4.3.1. ShanghaiTech Dataset
4.3.2. UCF_CC_50 Dataset
4.3.3. The WorldExpo’10 Dataset
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Huang, S.; Li, X.; Zhang, Z.; Wu, F.; Gao, S.; Ji, R.; Han, J. Body Structure Aware Deep Crowd Counting. IEEE Trans. Image Process. 2018, 27, 1049–1059. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Chang, H.; Nian, F.; Wang, Y.; Li, T. Dense Crowd Counting from Still Images with Convolutional Neural Networks. J. Vis. Commun. Image Represent. 2016, 38, 530–539. [Google Scholar] [CrossRef]
- Idrees, H.; Saleemi, I.; Seibert, C.; Shah, M. Multi-source Multi-scale Counting in Extremely Dense Crowd Images. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2547–2554. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. CNN-Based cascaded multi-task learning of high-level prior and density estimation for crowd counting. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Herath, S.; Harandi, M.; Porikli, F. Going deeper into action recognition: A survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef]
- Smeulders, A.W.M.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual Tracking: An Experimental Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1442–1468. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Chang, H.; Wang, M.; Ni, B.; Hong, R.; Yan, S. Crowded Scene Analysis: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 367–386. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. Generating High-Quality Crowd Density Maps Using Contextual Pyramid CNNs. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1879–1888. [Google Scholar] [CrossRef]
- Kang, D.; Chan, A. Crowd Counting by Adaptively Fusing Predictions from an Image Pyramid. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle upon Tyne, UK, 3–6 September 2018. [Google Scholar]
- Oñoro, D.; J López-Sastre, R. Towards Perspective-Free Object Counting with Deep Learning. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 615–629. [Google Scholar]
- Sam, D.B.; Surya, S.; Babu, R.V. Switching Convolutional Neural Network for Crowd Counting. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4031–4039. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; Volume 1802. [Google Scholar] [CrossRef]
- Cong, Z.; Hongsheng, L.; Wang, X.; Xiaokang, Y. Cross-scene crowd counting via deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 833–841. [Google Scholar] [CrossRef]
- Chen, C.L.; Chen, K.; Gong, S.; Xiang, T. Crowd Counting and Profiling: Methodology and Evaluation. In Modeling, Simulation and Visual Analysis of Crowds: A Multidisciplinary Perspective; Springer: New York, NY, USA, 2013; pp. 347–382. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian Detection: An Evaluation of the State of the Art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Zhang, Z.; Huang, K.; Tan, T. Estimating the number of people in crowded scenes by MID based foreground segmentation and head-shoulder detection. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, S.; Zhai, S.; Li, C.; Tang, J. An effective approach to crowd counting with CNN-based statistical features. In Proceedings of the 2017 International Smart Cities Conference (ISC2), Wuxi, China, 14–17 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Gall, J.; Yao, A.; Razavi, N.; Gool, L.V.; Lempitsky, V. Hough Forests for Object Detection, Tracking, and Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2188–2202. [Google Scholar] [CrossRef] [PubMed]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Chan, A.B.; Vasconcelos, N. Bayesian Poisson regression for crowd counting. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 545–551. [Google Scholar] [CrossRef]
- Ryan, D.; Denman, S.; Fookes, C.; Sridharan, S. Crowd Counting Using Multiple Local Features. In Proceedings of the 2009 Digital Image Computing: Techniques and Applications, Melbourne, VIC, Australia, 1–3 December 2009; pp. 81–88. [Google Scholar] [CrossRef]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature Mining for Localised Crowd Counting. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar] [CrossRef]
- Lempitsky, V.S.; Zisserman, A. Learning To Count Objects in Images. In Proceedings of the 23rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; Volume 1, pp. 1324–1332. [Google Scholar] [CrossRef]
- Pham, V.; Kozakaya, T.; Yamaguchi, O.; Okada, R. COUNT Forest: CO-Voting Uncertain Number of Targets Using Random Forest for Crowd Density Estimation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3253–3261. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, Y. Fast visual object counting via example-based density estimation. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3653–3657. [Google Scholar] [CrossRef]
- Xu, B.; Qiu, G. Crowd density estimation based on rich features and random projection forest. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, H.; Yang, L.; Liu, S.; Cao, X. Deep People Counting in Extremely Dense Crowds. In Proceedings of the 23rd ACM International Conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1299–1302. [Google Scholar] [CrossRef]
- Walach, E.; Wolf, L. Learning to Count with CNN Boosting. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 660–676. [Google Scholar]
- Shang, C.; Ai, H.; Bai, B. End-to-end crowd counting via joint learning local and global count. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1215–1219. [Google Scholar] [CrossRef]
- Boominathan, L.; Kruthiventi, S.S.S.; Babu, R.V. CrowdNet: A Deep Convolutional Network for Dense Crowd Counting. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 640–644. [Google Scholar] [CrossRef]
- Kumagai, S.; Hotta, K.; Kurita, T. Mixture of counting CNNs. Mach. Vis. Appl. 2018, 29, 1119–1126. [Google Scholar] [CrossRef]
- Sam, D.B.; Sajjan, N.N.; Babu, R.V.; Srinivasan, M. Divide and Grow: Capturing Huge Diversity in Crowd Images with Incrementally Growing CNN. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3618–3626. [Google Scholar] [CrossRef]
- Marsden, M.; McGuiness, K.; Little, S.; O’Connor, N. Fully Convolutional Crowd Counting On Highly Congested Scenes. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISAPP), Porto, Portugal, 27 February–1 March 2017; Volume 5, pp. 27–33. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, H.; Zhao, R.; Wang, X. Crossing-Line Crowd Counting with Two-Phase Deep Neural Networks. In European Conference on Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 712–726. [Google Scholar]
- Marsden, M.; McGuinness, K.; Little, S.; Connor, N.E.O. ResnetCrowd: A residual deep learning architecture for crowd counting, violent behaviour detection and crowd density level classification. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Lecce, Italy, 29 August–1 September 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Li, J.; Yang, H.; Chen, L.; Li, J.; Zhi, C. An end-to-end generative adversarial network for crowd counting under complicated scenes. In Proceedings of the IEEE International Symposium on Broadband Multimedia Systems and Broadcasting, Cagliari, Italy, 7–9 June 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Shen, Z.; Xu, Y.; Ni, B.; Wang, M.; Hu, J.; Yang, X. Crowd Counting via Adversarial Cross-Scale Consistency Pursuit. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5245–5254. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network forMobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Gholami, A.; Kwon, K.; Wu, B.; Tai, Z.; Yue, X.; Jin, P.; Zhao, S.; Keutzer, K. SqueezeNext: Hardware-Aware Neural Network Design. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1719–171909. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention (MICCAI); Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Martín, A.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Output Size | Configuration |
|---|---|---|
| Conv Block 1 | ||
| Conv Block 2 | ||
| Conv Block 3 | ||
| Transition | ||
| Atrous Block 1 | ||
| Atrous Block 2 | ||
| Distillation | ||
| Context Fusion |
| Methods | Parameters | FLOPS | MAE | RMSE |
|---|---|---|---|---|
| Config.A | 130.40 k | 2040 m | 78.5 | 126.4 |
| Config.B | 119.60 k | 1911 m | 92.1 | 142.0 |
| Config.C | 223.46 k | 3389 m | 78.1 | 129.2 |
| Methods | Parameters | FLOPS | MAE | RMSE |
|---|---|---|---|---|
| MCNN [8] | 127.95 k | 5384 m | 110.2 | 185.9 |
| CSRNet [13] | 16.26 m | 82,889 m | 68.2 | 115.0 |
| FCN-7c-3s [10] | 150.92 k | 14,327 m | 80.6 | 126.7 |
| Ours | 130.40 k | 2040 m | 78.5 | 126.4 |
| Part A | Part B | |||
|---|---|---|---|---|
| Method | MAE | RMSE | MAE | RMSE |
| MCNN [8] | 110.2 | 173.2 | 26.4 | 41.3 |
| Cascaded-MTL [4] | 101.3 | 152.4 | 20.0 | 31.1 |
| FCN-7c-3s [10] | 80.6 | 126.7 | 10.2 | 18.3 |
| Ours | 78.5 | 126.4 | 12.8 | 22.1 |
| Switching-CNN [12] | 90.4 | 135.0 | 21.6 | 33.4 |
| CP-CNN [9] | 73.6 | 106.4 | 20.1 | 30.1 |
| CSRNet [13] | 68.2 | 115.0 | 10.6 | 16.0 |
| IG-CNN [36] | 72.5 | 118.2 | 13.6 | 21.1 |
| ACSCP [42] | 75.7 | 102.7 | 17.2 | 27.4 |
| Method | MAE | RMSE |
|---|---|---|
| Onoro et al. [11] | 465.7 | 371.8 |
| MCNN [8] | 377.6 | 509.1 |
| Cascaded-MTL [4] | 322.8 | 341.4 |
| Ours | 299.1 | 391.8 |
| Switching-CNN [12] | 318.1 | 439.2 |
| CP-CNN [9] | 295.8 | 320.9 |
| IG-CNN [36] | 291.4 | 349.4 |
| ACSCP [42] | 291.0 | 404.6 |
| Method | Sce.1 | Sce.2 | Sce.3 | Sce.4 | Sce.5 | Avg. |
|---|---|---|---|---|---|---|
| Zhang et al. [14] | 9.8 | 14.1 | 14.3 | 22.2 | 3.7 | 12.9 |
| MCNN [8] | 3.4 | 20.6 | 12.9 | 13.0 | 8.1 | 11.6 |
| FCN-7c-3s [10] | 2.5 | 16.5 | 12.2 | 20.5 | 2.9 | 10.9 |
| Ours | 2.4 | 27.0 | 7.9 | 8.4 | 3.1 | 9.76 |
| Switching-CNN [12] | 4.2 | 14.9 | 14.2 | 18.7 | 4.3 | 11.2 |
| CP-CNN [9] | 2.9 | 14.7 | 10.5 | 10.4 | 5.8 | 8.9 |
| CSRNet [13] | 2.9 | 11.5 | 8.6 | 16.6 | 3.4 | 8.6 |
| IG-CNN [36] | 2.6 | 16.1 | 10.15 | 20.2 | 7.6 | 11.3 |
| ACSCP [42] | 2.8 | 14.05 | 9.6 | 8.1 | 2.9 | 7.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; Huang, J.; Du, W.; Xiong, N. Design and Analysis of a Lightweight Context Fusion CNN Scheme for Crowd Counting. Sensors 2019, 19, 2013. https://doi.org/10.3390/s19092013
Yu Y, Huang J, Du W, Xiong N. Design and Analysis of a Lightweight Context Fusion CNN Scheme for Crowd Counting. Sensors. 2019; 19(9):2013. https://doi.org/10.3390/s19092013
Chicago/Turabian StyleYu, Yang, Jifeng Huang, Wen Du, and Naixue Xiong. 2019. "Design and Analysis of a Lightweight Context Fusion CNN Scheme for Crowd Counting" Sensors 19, no. 9: 2013. https://doi.org/10.3390/s19092013
APA StyleYu, Y., Huang, J., Du, W., & Xiong, N. (2019). Design and Analysis of a Lightweight Context Fusion CNN Scheme for Crowd Counting. Sensors, 19(9), 2013. https://doi.org/10.3390/s19092013