1. Introduction
Face detection is a hot topic in computer vision. It is the basic step for face-related applications, such as face recognition, face attribute classification, face beautification, etc. In the last two decades, many approaches have been proposed to solve it [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13]. The faces in the wild vary in scales and pose, and they usually appear in cluttered backgrounds. These situations increase the difficulty of the face detection.
The two main focuses of the face detection task are the speed and accuracy of the proposed approaches. They are both important. Usually, the approaches with high computational complexity perform better, but they run in a low running speed. Nowadays, most of the face detection applications are deployed on embedded devices. Embedded devices usually have low computation resources. Therefore, building efficient methods with a good balance of speed and accuracy is very important. Another bottleneck of the embedded devices is the limited amount of available system memory, which is discussed in [
14,
15]. Keeping the face detector’s memory complexity low is also important for embedded devices. Fortunately, modern embedded devices usually have large enough memory for high-speed face detectors, for example the Raspberry Pi 3b+, the RK3399, and most recent mobile phones. Therefore, this paper mainly focuses on designing effective strategies for building efficient face detectors with a good balance between speed and accuracy.
Traditional face detection methods usually follow the sliding-window fashion. Viola–Jones [
16] is the pioneering method for face detection. It designs the Haar-like feature and uses the Adaboost algorithm to classify each window on the image pyramid. After that, many traditional methods are proposed. They focus on designing effective hand-craft features and building powerful classifiers. For example, ACF (Aggregated Channel Features) [
17] uses the aggregated channel features and adopts the fast feature pyramid building strategy. These traditional methods could not deal with complex situations because of their weak-semantic features. Moreover, since they usually adopt the image pyramid to deal with the multiple face scales, they have limited advantage in running speed.
Currently, more and more deep learning-based methods are proposed. The state-of-the-art methods usually regard the faces as a special case of general objects, and most of them are inherited from general object detection methods. Some of them are based on faster RCNN (Region-based Convolutional Neural Networks) [
18], they follow the two-stage face detection pipeline. In the first stage, they generate the candidate face proposals to filter out most of the background samples. Then, in the second stage, they get the final detection result by classifying the proposals into faces and non-faces, as well as further regressing them to the ground-truth location. Though there are some works to improve the running efficiency of two-stage methods, the two-stage methods are still not friendly with embedded devices.
On the other hand, most of the current state-of-the-art methods follow the single-stage framework. Methods like SFD (Single Shot Scale-Invariant Face Detector) [
10], SSH (Single Stage Headless Face Detector) [
5], PyramidBox [
7], and FANet (Feature Agglomeration Networks) [
9] are based on SSD (Single Shot Multi-box Detector) [
19] detector. SFD [
10] adopts the VGG-16-based [
20] SSD detector. It proposes several guidelines about the anchor setting strategy to improve the recall rate of the face detector. SSH [
5] removes the fully-connected layers of VGG-16 to speed up the running speed. SSH also designs a context module on the predicting layers to utilize context information. PyramidBox [
7] designs multiple strategies to utilize the context information to improve the face detection results. FANet [
9] designs a novel hierarchical feature pyramid to better merge the feature maps of different stages. Another category of methods are based on RetinaNet [
21], like SRN (Selective Refinement Network) [
2] and FAN (Face Attention Network) [
22]. SRN [
2] is inspired by the RefineDet [
21]. It appends a refinement branch to refine the classification results for small objects and regression results for large objects. FAN [
22] designs the attention module to improve the face detection performance in some hard cases, like occlusions and person wearing masks. These single-stage methods are generally faster than the two-stage methods. However, they tend to use large backbones (like VGG-16 or ResNet [
23]) or design heavy predicting heads to guarantee the performance, which makes them less efficient on embedded devices.
There are only a few works aimed at designing highly efficient face detectors. MTCNN (Multi-Task Convolutional Neural Network) [
24] designs the cascade convolutional neural networks to filter background patches in a coarse to fine way. MTCNN [
24] is feasible to adapt different running speed requirements of different devices, but its performance is not satisfactory in dealing with complex situations. Faceboxes [
25] is based on the SSD framework. They proposed two useful modules for building efficient networks. The modules are the rapidly digested convolutional layers (RDCL) and the multiple scale convolutional layers (MSCL). By designing an efficient face detection backbone based on the two modules, the Faceboxes detector is able to run real-time on the x86 CPU based desktop. However, it still cannot meet the real-time requirement for embedded devices.
Besides the above works that are specific to face detection, there are several works about building efficient classification networks. MobileNet [
26] uses depth-wise convolutions and point-wise convolutions together to replace the regular convolutions. MobileNet-v2 [
27] proposes the inverse residual blocks and linear bottlenecks to improve the accuracy of the depth-wise convolutions based networks (i.e., MobileNet). ShuffleNet [
28] converts the point-wise convolutions in MobileNet to group point-wise convolutions and uses the channel-shuffle operation to exchange information between channels. ShuffleNet-v2 is the improved version of ShuffleNet. ShuffleNet-v2 [
29] find that beyond minimizing the FLOPS, four practical guidelines should be considered for building efficient networks that run fast on real devices. These networks are friendly with embedded devices, but they are mainly designed for classification tasks. Although they can be directly applied in detection tasks, we think that several modifications on them should be considered to build more efficient networks for detecting faces.
An efficient face detection network should achieve a good trade-off between speed and accuracy. To build such an efficient network, we think there are two considerations. On one hand, the architecture of the network should be efficient while it should maintain the necessary network capacity for being accuracy. On the other hand, different from the general strategies proposed in recent face detectors that improve the accuracy at the expense of reducing the speed a lot [
2,
7], the strategies to improve the efficient network’s accuracy should bring less additional computation costs as possible. In this paper, we use the floating-point operations per second (FLOPS) as the index of the detector’s speed, for it reflects the computation complexity of the detection network and it is not affected by specific devices and specific inference libraries. Therefore, the key is to build networks with low FLOPS and enough capacity and propose strategies to improve its accuracy without adding too many FLOPS.
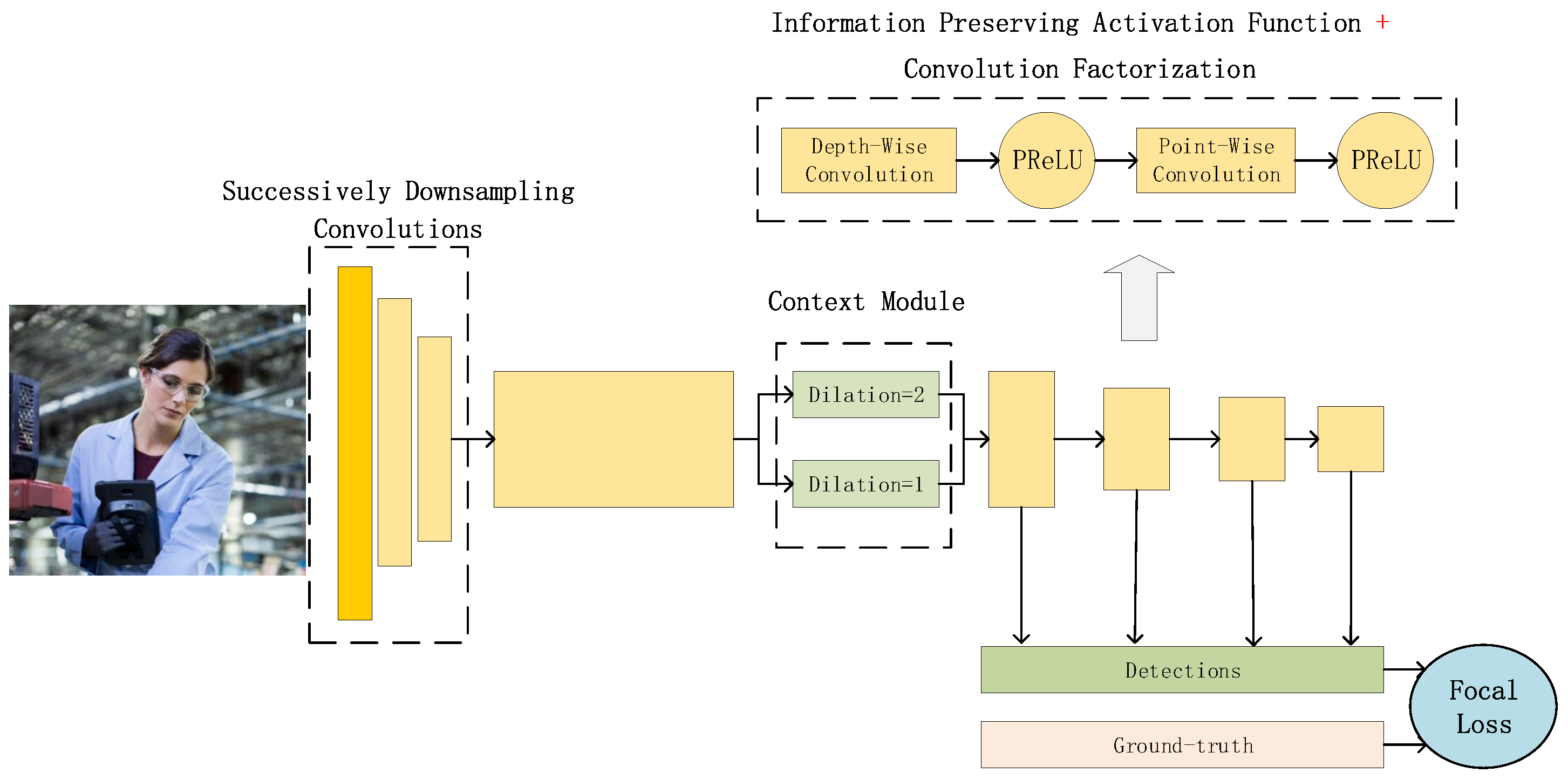
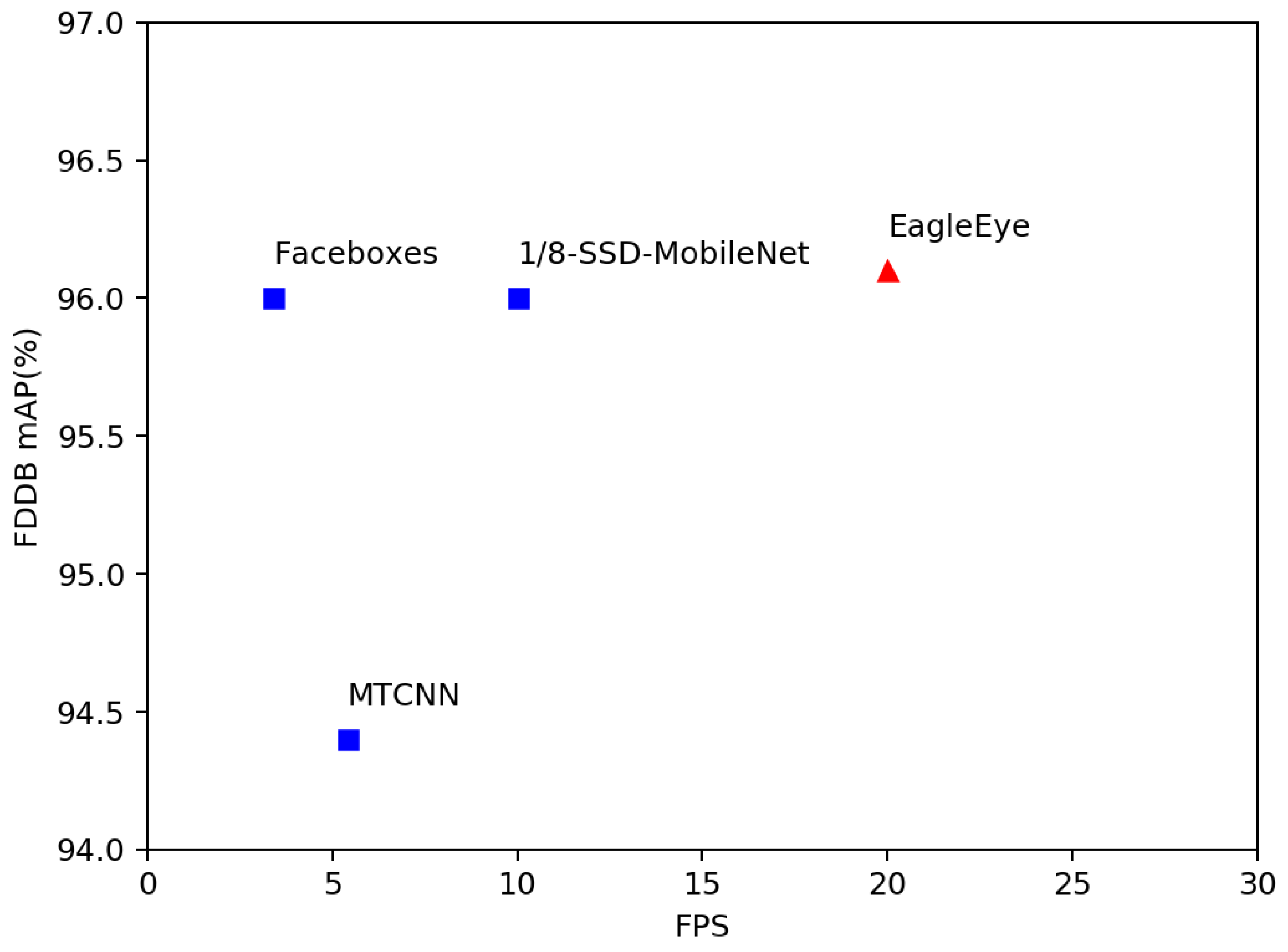
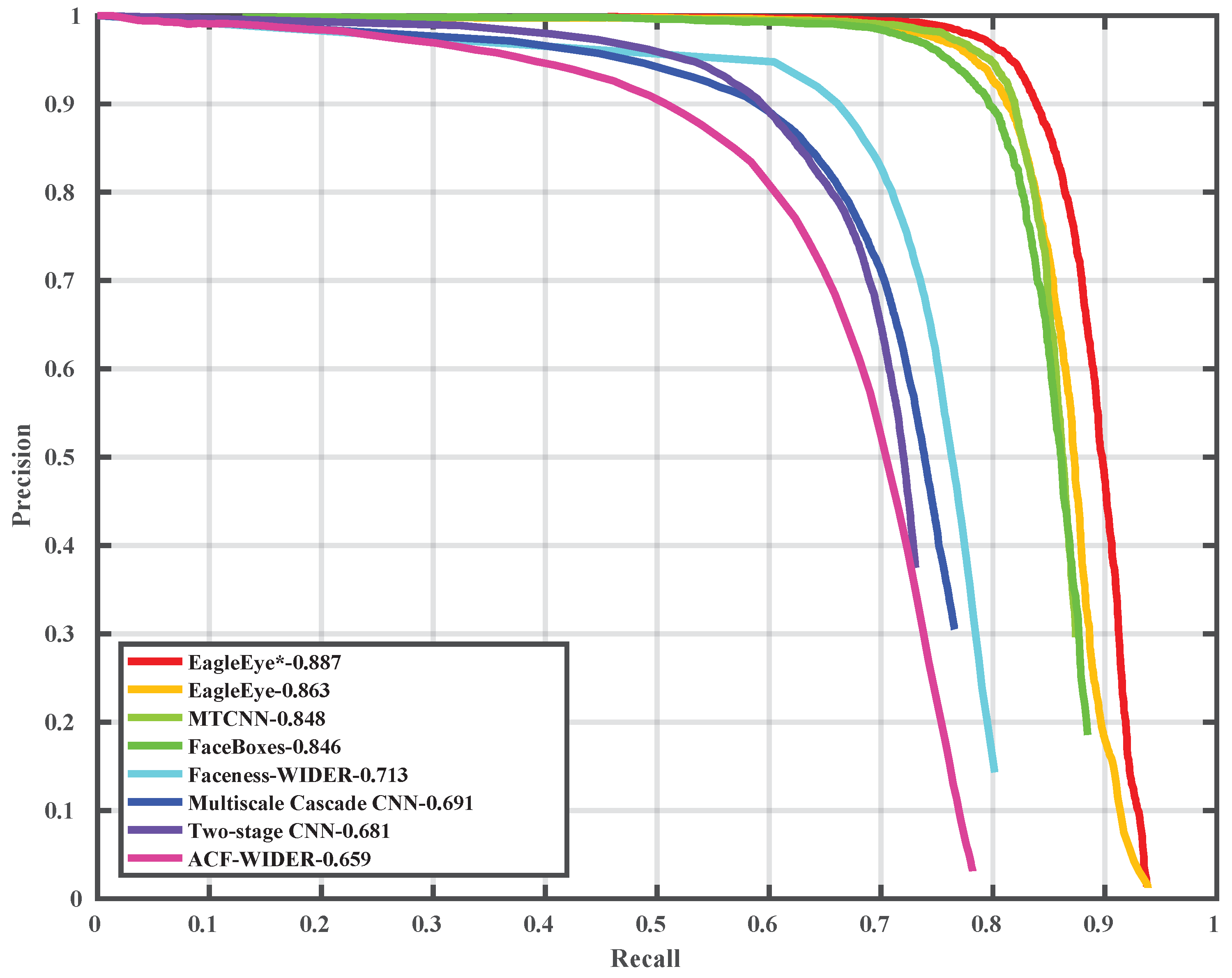
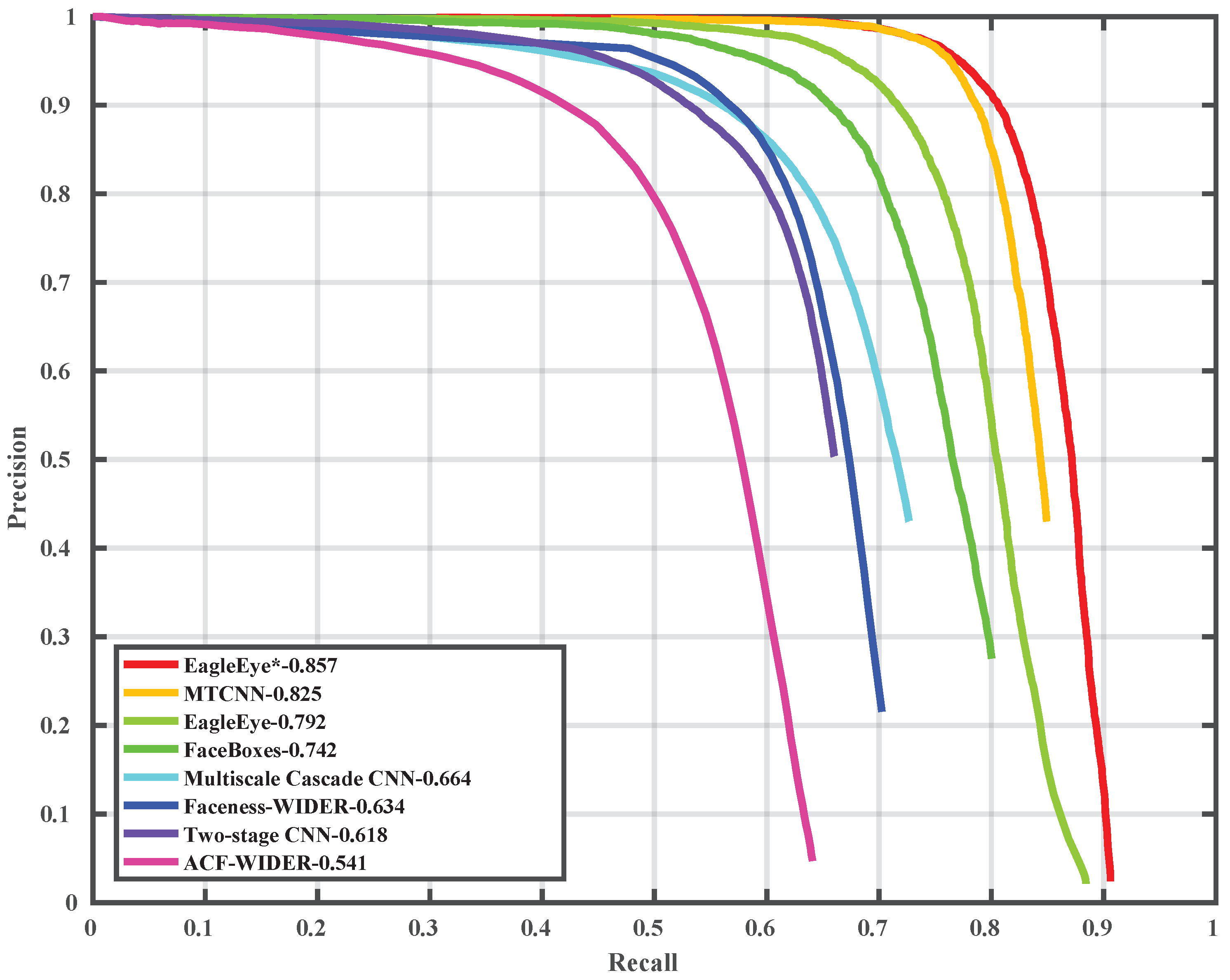
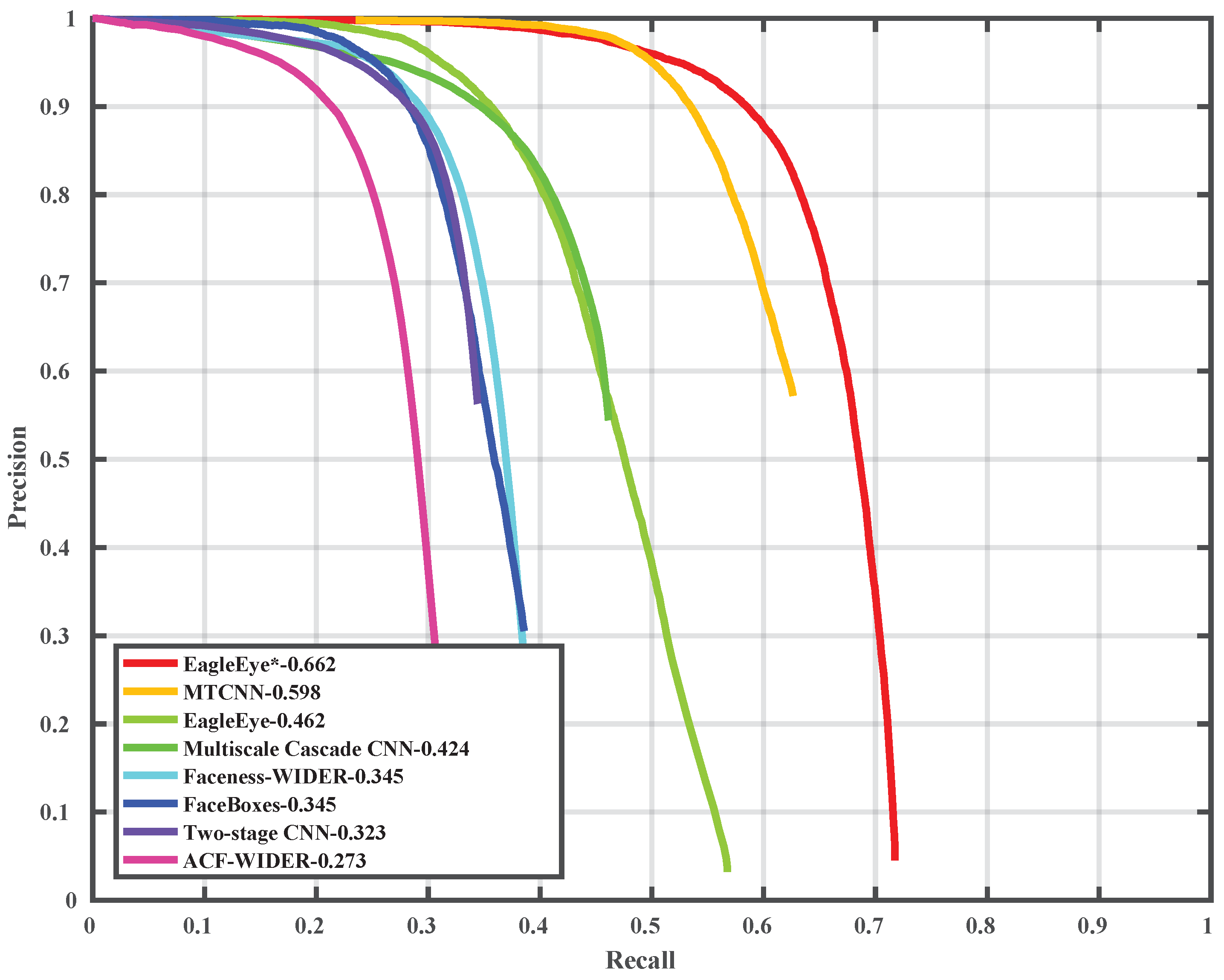
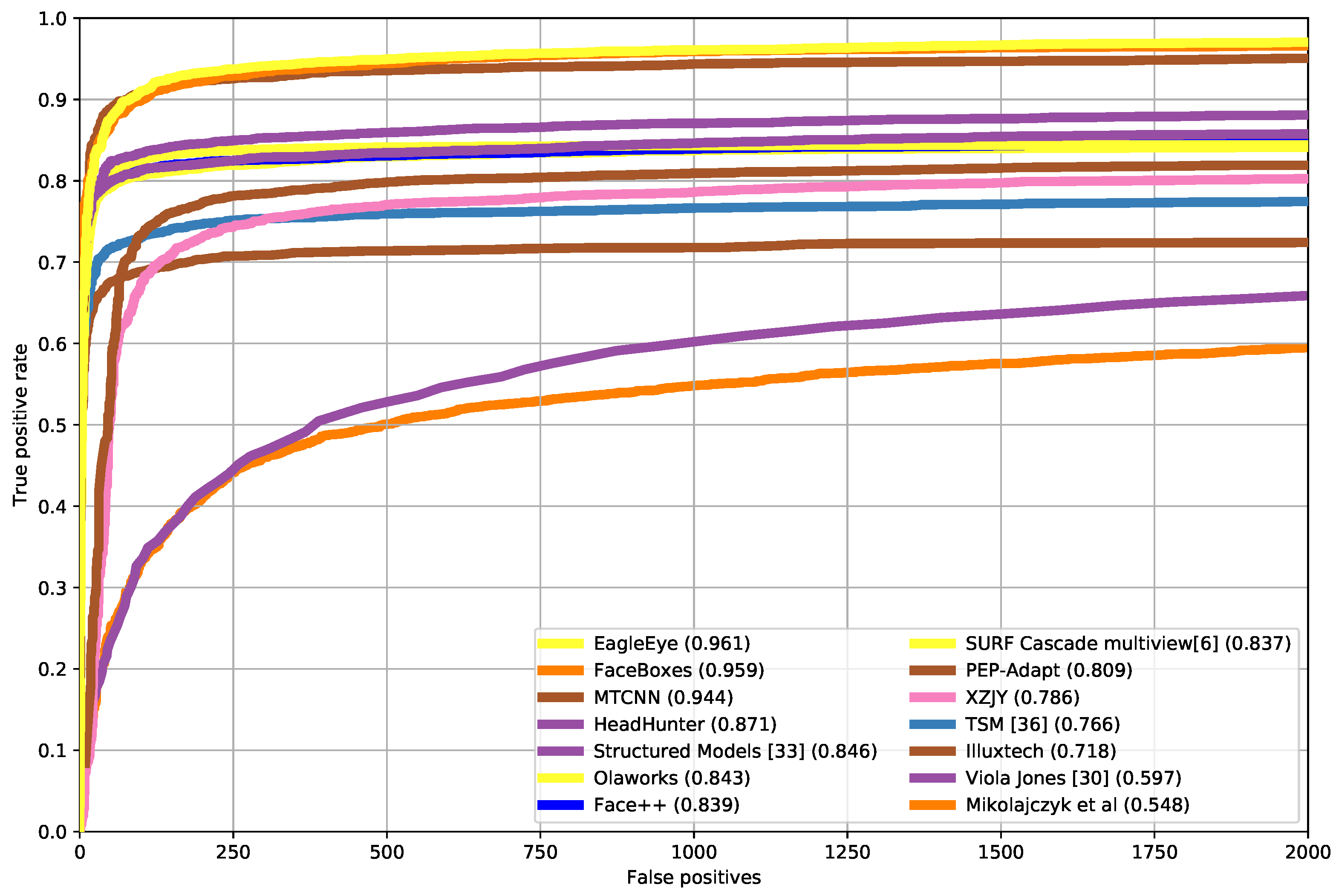
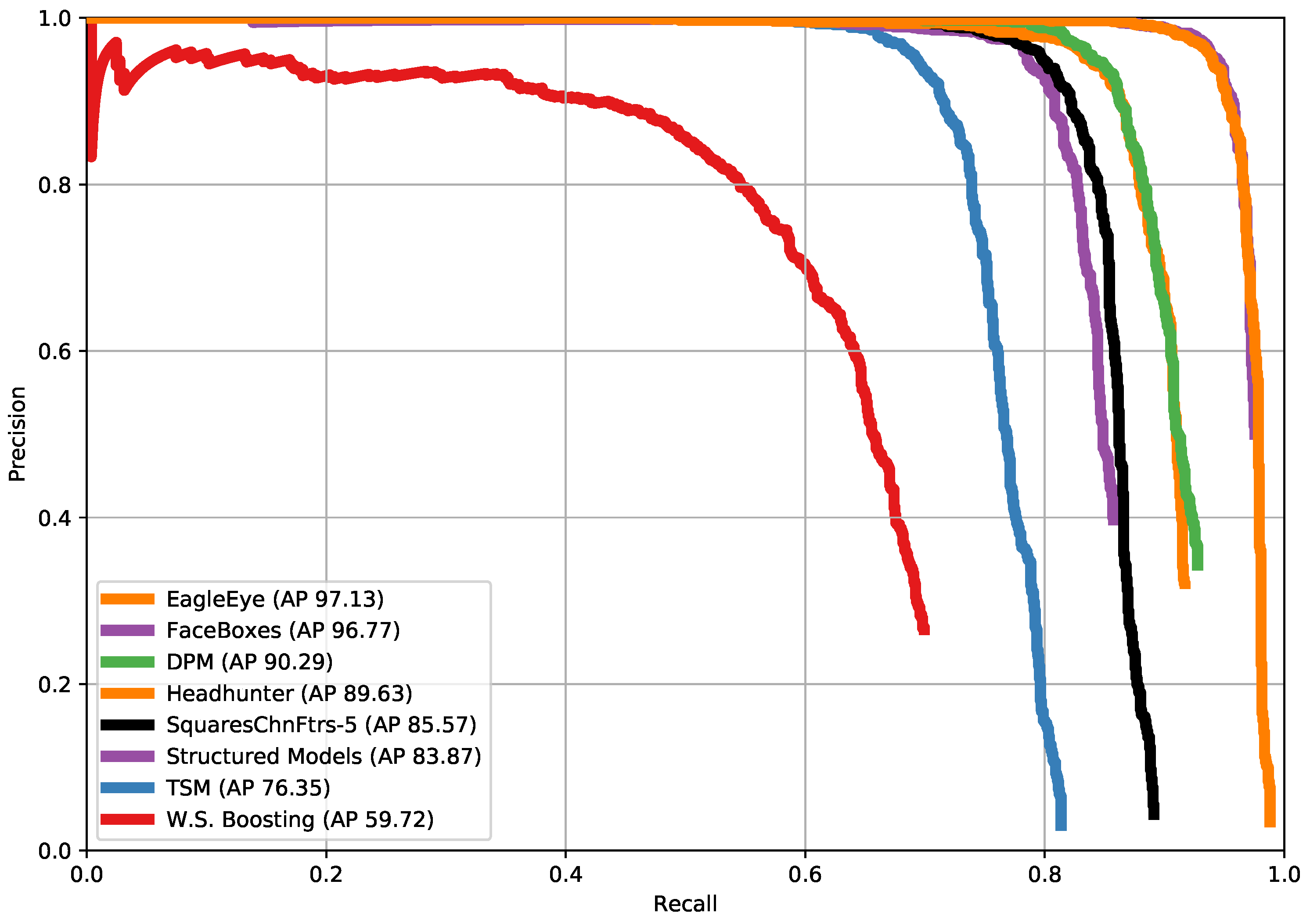
In this paper, to solve the problem that current face detectors could not reach a good balance of speed and accuracy on embedded devices, we propose an arm based embedded devices oriented face detector, EagleEye. The overview architecture of EagleEye is shown in
Figure 1. EagleEye is inspired by many of the above works. We first propose two strategies to reduce the computation cost without reducing the accuracy too much. Then we propose three strategies to improve the accuracy without adding too much computation cost. To reduce the FLOPS without sacrificing too much capacity, firstly, we adopt the convolution factorization module to use the depth-wise convolutions and point-wise convolutions to build the whole detector as efficient as possible; secondly, we set the successive downsampling convolutions in the several beginning stages of the network which remove the unnecessary layers. To improve the accuracy without adding too much computational cost, firstly, we design an efficient multi-scale context module to utilize context information to improve the detection accuracy; secondly, we use the information-preserving activation function to increase the capacity of the network; thirdly, we introduce the focal loss to help the light-weight network to deal with the class-imbalance problem during the training process. We build the EagleEye face detector with the above four strategies. It achieves 50 ms per frame on an ARM A53 based embedded device, the Raspberry Pi 3b+. It also achieves 96.1 mAP on FDDB dataset.
The contributions of this paper are two-fold. Firstly, we propose five guidelines for building efficient face detectors. Secondly, we design the EagleEye face detector, which achieves good performance on ARM devices.
2. Related Work
Our EagleEye detector is inspired by many previous works. MobileNet [
26], MobileNet-v2 [
27], Xception [
30], ShuffleNet [
28], and ShuffleNet-v2 [
29] also adopts the depthwise convolution for efficient running on devices, but they are created as classification networks. We adopt the depth-wise convolution to build more efficient networks and extend it to dilated depth-wise convolutions to extract context information with little computation costs.
The Faceboxes [
25] use a rapidly digested convolutional layers (RDCL) module to quickly reduce the resolution of feature maps. This is similar to our successive downsampling convolutions module. However, there are several differences between them. Firstly, EagleEye does not have the pooling layer for it would decrease the accuracy of small faces. Secondly, we do not adopt the C.ReLu layer for its limited improvements as shown in Faceboxes. Thirdly, we do not use the large kernel sizes of seven or five in building EagleEye, for they are usually ignored by many the implement of deep learning inference libraries and they would increase the number of parameters of the detector.
The dilation convolution is widely used in semantic segmentation to increase the scale of the receptive field and introduce more context information, like the ASPP (Atrous Spatial Pyramid Pooling) in DeepLab [
31] method. In object detection tasks, RFBNet (Receptive Field Block Networks) [
32] use multiple dilation convolutions at each of the predicting branches. However, we think that adding a multiple-dilation-convolution module at each of the predicting branches is not efficient enough, so we propose to add it at the middle of the backbone to compute it only once. After that, the context information is continuously fed into the following layers. Using multiple dilation convolutions in the backbone as a context module is also proposed in ISSD (Improved Single Shot Object Detector) [
33]. ISSD uses four split-dilatedConv-sum (dilatedConv means the dilated convolution operation) branches to extract multi-scale information. Because ISSD is for general object detection in scenes and EagleEye is for face detection, we remove the two branches with large dilation rates because only the human body regions are helpful in detecting faces. Moreover, we use the slice-dilatedConv-concat branches to reduce the input channels of each branch.
The non-saturated activation functions, like ReLU (Rectified Linear Unit), are the key to making deep convolutional neural networks outstanding. As discussed in [
34], the non-saturated activation functions could solve the “exploding/vanishing gradient” problem and accelerate the convergence speed. Besides the most widely used method ReLU [
35], its variants like leaky ReLU [
36], PReLU (Parametric Rectified Linear Unit) [
37], ELU (Exponential Rectified Linear Unit) [
38], and Swish [
39] are also proposed. The ReLU has the dead region below 0, thus it limited the capacity of the network. Many of these variants like ELU and Swish use the exponential function, which runs slowly on CPU. To improve the capacity of the network as well as keep the network efficient, the leaky ReLU and PReLU are suitable to be adopted to build the network. We find their effects are similar and choose the PReLU in EagleEye.
The class imbalance is a traditional problem in machine learning and object detection. It is usually alleviated by hard example mining [
19,
40] or re-weighting the loss values for different categories [
41,
42]. Lin et al. [
43] proposed the Focal Loss for dealing with the class imbalance in one-stage detectors. In this paper, to achieve faster running speed, we design a one-stage face detector. In the proposed face detector, most of the anchors are in background regions. To make the gradient caused by different classes more balanced, we introduce the focal loss in training the light-weight face detector.
3. EagleEye
In this section, we give a detailed description of the proposed face detector, EagleEye, as shown in
Figure 1. We use five key components for building it. Firstly, we adopt the depth-wise convolutions for building it. Secondly, we design a successive strided convolution layers module for downsampling the resolution of feature maps rapidly. Thirdly, we use dilated depth-wise convolutions for increasing the context information. Fourthly, we use the information preserving activation functions to increase the network’s capacity. Finally, we introduce the modified focal loss to improve the detector’s performance by handling the class imbalance better.
3.1. Baseline Detector
To better demonstrate the evolution of EagleEye, we firstly build a baseline backbone network.
Backbone. The baseline backbone network is built following the VGG-style, which is widely used in single stage face detection methods. Its architecture is shown in
Table 1. It consists of seven stages. Like SSD and FPN, we predict the objects of different scales at multiple network layers with different depth and different strides. Specifically, we choose one layer from each of the stages four to seven as the predicting layers for four different face scales. These layers have the stride of 16, 32, 64, 128.
Multi-scale anchor Boxes. Following the strategy used in RPN (Region Proposal Networks) [
44], SSD [
19], and Faceboxes [
25], we use predefined multi-scale anchor boxes to predict the faces with various scales. For each pixel on the feature maps of the predicting layer, we set two anchor boxes to it. By matching the ground-truth face boxes to the anchor boxes, each ground-truth face box would be matched with at least one anchor box. The scales of anchor boxes of each predicting layer are shown in the last column of
Table 1. Moreover, since the faces tend to be a square shape, we set the anchors of the unified aspect ratio of 1:1.
As for the matching rules, we use the widely used IoU-based (IoU: Intersection over Union) matching rules. According to this rule, an anchor is matched to a ground-truth box if the IoU overlap between them is higher than a threshold. The definition of IoU is demonstrated in Equation (
1).
According to many previous works, like YOLOv2 ( You Only Look Once, Version 2) [
45] and S3FD (Single Shot Scale-Invariant Face Detector) [
10], the average number of matched anchor boxes of each ground truth box should be high enough. This is the key to keep a high recall rate of detection results. Therefore, we set a relatively low matching threshold.
Predicting targets. In EagleEye, we use a
convolutional layers on the output feature maps of each predicting layer to generate a five-element vector (
) for each anchor which is assign to each one of its pixels.
is the confidentce that the anchor (
) is assigned to a face box. (
) is the offset between the anchor box with the ground-truth box. We could recover the detected bounding box (
) by:
After getting all predicted face bounding boxes, we use a standard greedy non-maximum suppression (NMS) algorithm to generate the final detection results.
Loss function. The output five-element vector () consists of two parts. The is a classification task and the () is the regression task. For the classification task, we use the two-class cross entropy loss. Because the number of the positive samples is far lower than that of the negative samples, in the baseline detector, we use the online hard negative mining strategy to balance the ratio of them. For the regression task, we use the smooth-L1 loss for it is more robust.
Data augmentation. Data augmentation is widely used in single-stage object detection methods to improve their performance. In this paper, we use three kinds of augmentation methods to make the detectors fully trained.
First, we randomly pad the sampled training images with 0 s to generate images with a larger size. Then use the randomly cropping method to crop the image patches and resize them to the unified size 512 × 512 as the training samples. When cropping, we make sure each cropped patch would have at least one face in it. This would augment the faces of various scales to make each predicting layer fully trained.
Second, we randomly flip the images in the horizontal direction with a probability of 0.5 to generate new samples.
Third, we distort the image in various color spaces. This could increase the robustness of the detector to illumination changes.
3.2. Convolution Factorization
Convolution factorization is the first strategy to reduce the computation complexity of the face detection network. The convolution factorization means that we factorize each standard convolution layer into a depth-wise convolution layer and a following point-wise convolution layer. The depth-wise convolution is firstly proposed in Xception [
30], and is adopted as the core element of MobileNet [
26]. The point-wise convolution is the regular 1 × 1 convolution.
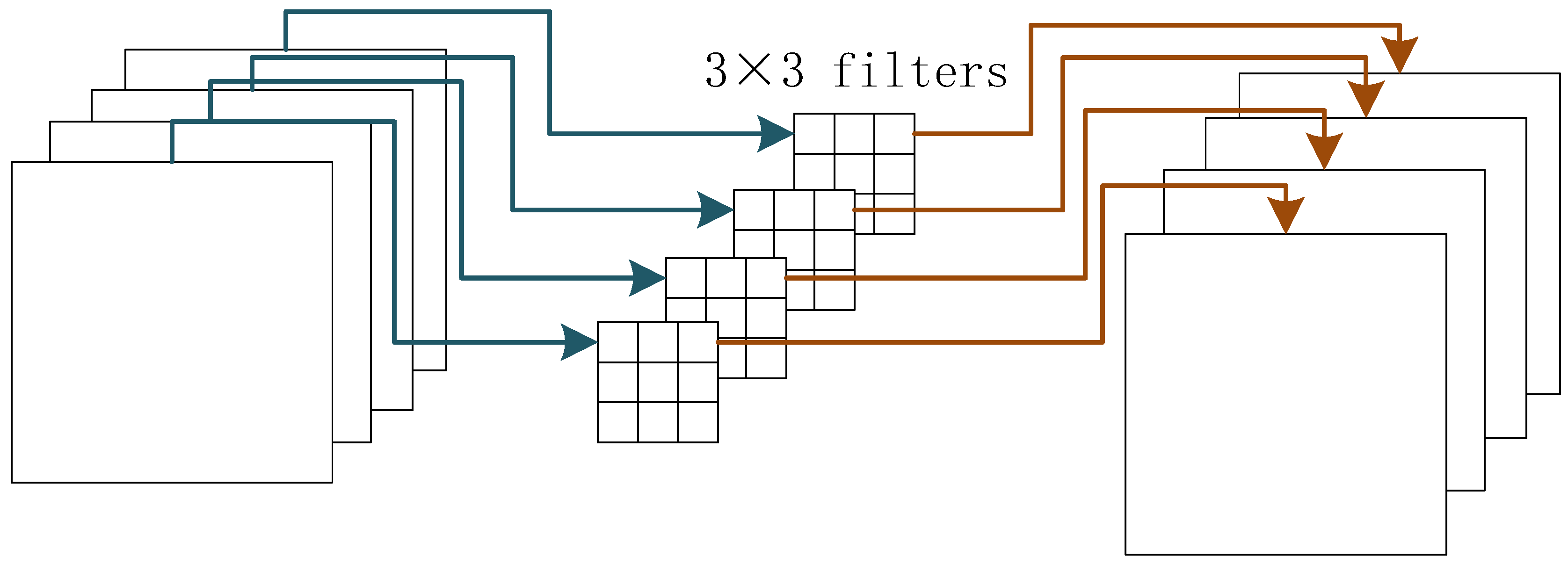
Depth-wise convolution.
Figure 2 shows the computing process of the depth-wise convolution. The input feature map and the output feature map have the same number of channels. Each channel of the input feature map has a corresponding channel of the convolutional filters. Each filter only operates on one input channel. Comparing the standard convolutions that each filter operates on all input channels, the depth-wise convolution is very sparse, thus saving a lot of computation costs.
Point-wise Convolution. The point-wise convolution is the standard convolution. It is used to aggregate the information among different channels. The standard convolution convolves the input feature map both in the spatial-wise and the channel-wise dimensions. The depth-wise convolution could convolve the input feature map in the spatial-wise dimension, but it loses the information exchange among the different channels. Therefore, depth-wise convolutions and point-wise convolutions are complementary to each other.
Effects of convolution factorization. By using convolution factorization, we factorize each standard convolution layer of the baseline detection network into a depth-wise convolution layer and a point-wise convolution layer. The convolution factorization has two advantages over directly adopting standard convolutions. Firstly, the parameters of the network becomes much less. We suppose the input channels is and the output channels is , the regular convolution has parameters. After convolution factorization, the parameters become parameters. Secondly, the computation complexity is largely reduced. We use FLOPS as the index of computation complexity. We suppose the above convolution layer’s input and output feature maps’ spatial resolution are both . The FLOPS of regulation convolution would be , while after convolution factorization, the FLOPS would be × H × W.
Since the convolution factorization could reduce much computation costs, we adopt it in all convolutional layers of the face detection network except conv1, including the backbone and the predicting layers. The regular convolutions with the same number of input and output channels can easily be factorized into depth-wise and point-wise convolutions. For the convolution which has a different number of channels between its input and output feature maps, the channel number transformation is accomplished at the point-wise convolutions.
3.3. Successive Downsampling Convolutions
Successive downsampling convolutions is the second strategy to reduce the computation complexity of the face detection network. There are two key considerations when designing the network architectures, the network width, and network depth. Almost all base networks are like a pyramid. In other words, the resolutions of network layers are successively shrunk. The shrinking is usually done by a strided convolution layer or a pooling layer. We find that the pooling layers are not suitable for small objects, because they would lose much detailed information. Therefore, we do not use any pooling layer in building the backbone network of EagleEye.
The layers with the same output resolution are usually called a stage. In the popular network architectures, it is common that in each stage, each downsampling layer () is followed by several stride–1 () layers. This is to increase the depth of each stage. Each stage extracts features of different levels of semantic representation ability. By increasing the depth of a stage, the features it focuses on become finer. In this paper, since we are constrained by the low computation ability of embedded devices, we should keep the computation complexity of the backbone network low and reduce the number of the layers which come with fewer benefits. We think the stride–1 layers in the first several stages are less important because the features output by downsampling layers are already semantic strong enough to be input into their following stages. Therefore, we remove the stride–1 layers in the first two stages to reduce the computation costs. The third stage has only one stride–1 layer. We reserve it to prevent losing too much network capacity. Then we keep the stage depth of the following stages unchanged. The faces start to be predicted on stage 4, so stage 4’s features used for detecting faces should be semantic strong enough.
3.4. Context Module
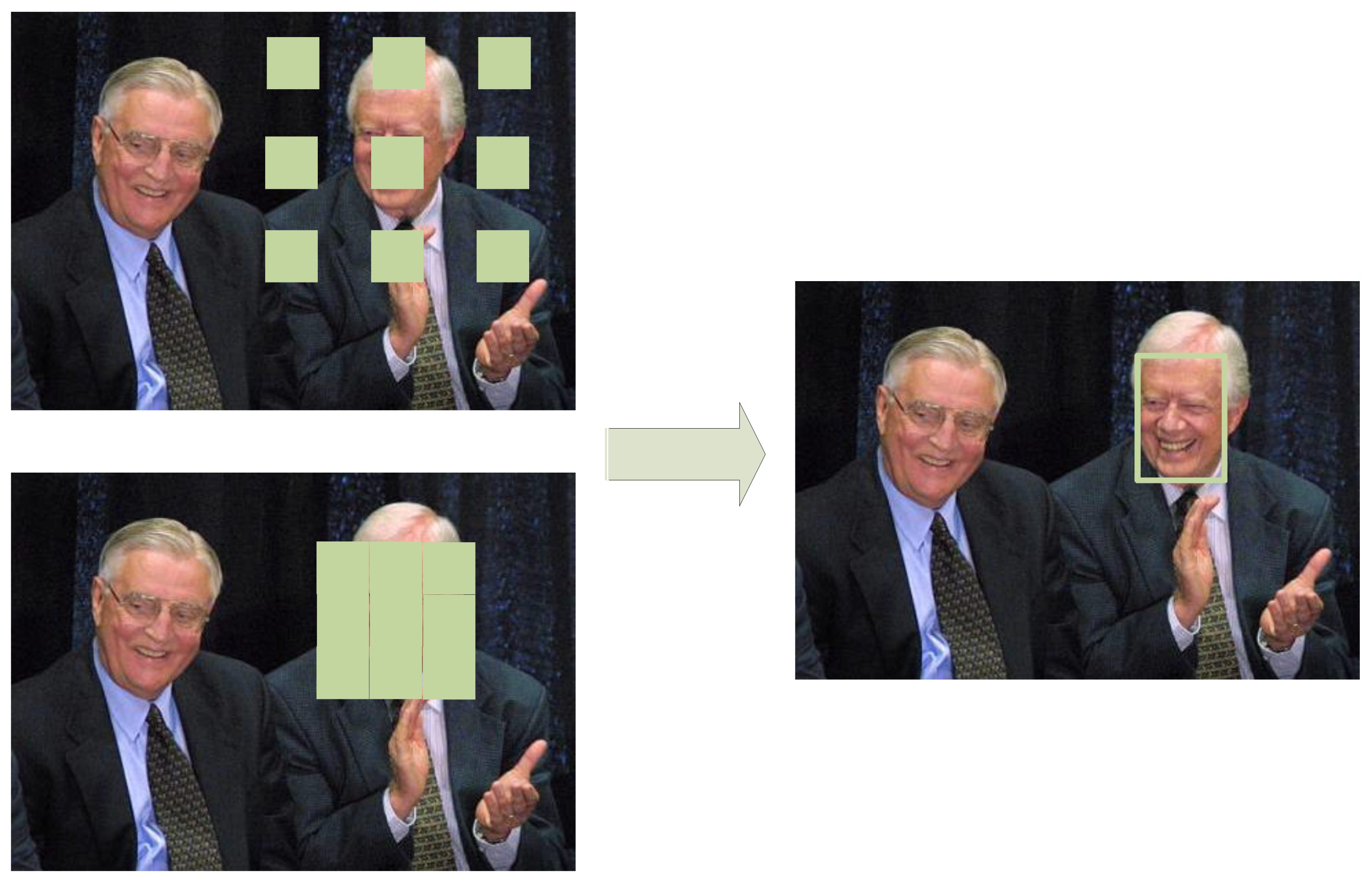
The context module is the first strategy to improve the detection accuracy without adding too much additional computation costs of the face detection network. To reduce the computation complexity of the designed network, we have to limit the capacity of the network. Therefore, the detection results may become inaccurate. To make up for the decrease of accuracy, we introduce the context information to help the network locate the faces. For example, the head–shoulder features are usually the indicator of the existing of faces above the bodies, as shown in
Figure 3.
As discussed in [
33], using the dilated convolution is a natural way to introduce context in the single stage detectors. Ref. [
33] use four branches of convolutions with different dilation rates to extract multi-scale context information. Following [
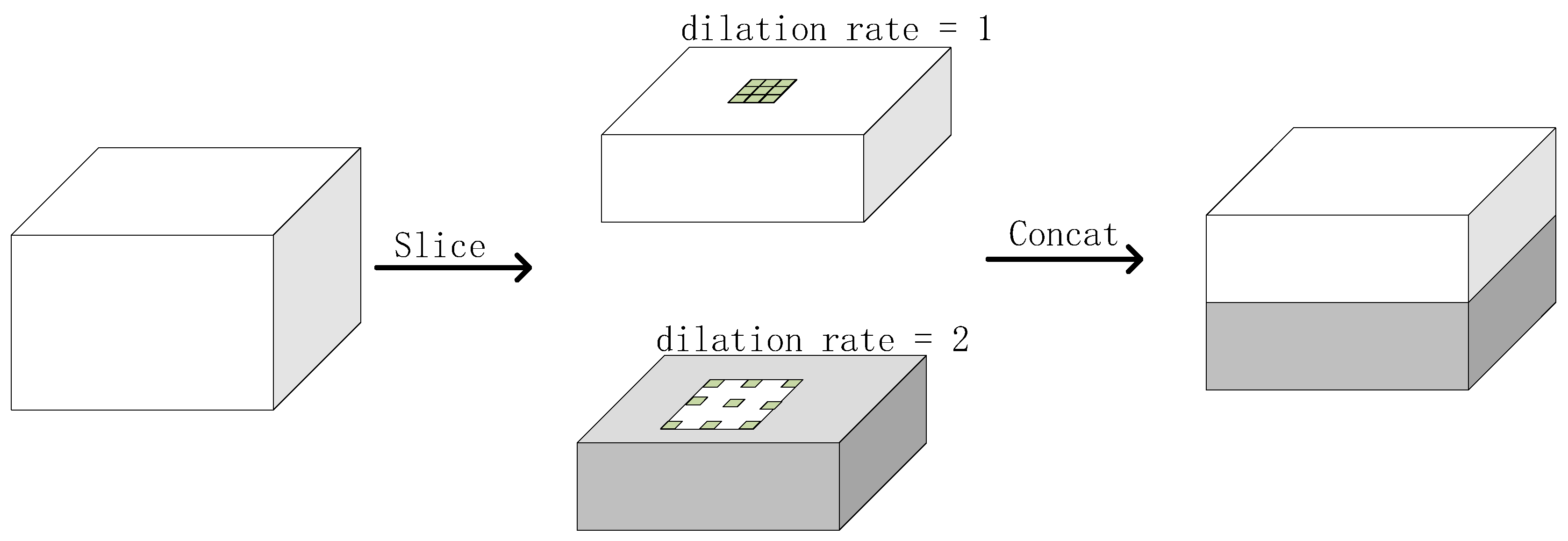
33], we design a multi-branch module to utilize multi-scale context information to improve detection performance. However, since our method is designed to run on embedded devices, we should not increase too much computation cost. Therefore, we made several modifications. Firstly, we use dilated depth-wise convolutions with different dilation rate for each branch. This largely reduces the computation complexity. Secondly, we use slice operation to equally divide the input feature map into two feature maps on the channel-wise dimension. This could reduce the number of channels of each branch. Another choice of the multi-branch module architecture is to make all branches share the same input feature map, as most of the modern networks do, like Inception, ResNet, and Faceboxes. Compared to the latter choice, the slice-branch-concat design leads to smaller inputs of each branch. Moreover, we do not set a large dilation rate for the dilation convolutions. Ref. [
33] use the dilation rates of two, four, six, and eight to extract multi-scale contexts. However, unlike the general object detection tasks in [
33] where the environment in the whole image could give clues for detecting the object, the faces rely less on the whole-image-level context. For example, the boats often appear on rivers, but the faces could appear at many scenes. Therefore, we limit the field of context regions by not using large dilation rates. The proposed context module in this paper is shown in
Figure 4 and how the context module utilizes the head-shoulder region to help the face detection is shown in
Figure 3.
3.5. Information Preserving Activation Function
The information preserving activation function is the second strategy to improve the detection accuracy without adding too much additional computation costs of the face detection network. It is an improvement on the ReLU activation function (Equation (
3)), which is usually regarded to lose some information because of its dead region of (
, 0]. Because the face detection network with low computational cost has limited capacity, we could increase its capacity by reducing the information loss caused by the ReLU activation function. Therefore, we propose to replace the ReLU activation function with Leaky ReLU [
36] or PReLU [
37] in the baseline network. The leaky ReLU is demonstrated in Equation (
4) and PReLU is demonstrated in Equation (
5). Note the
in Equation (
4) is a constant value while the
a in Equation (
5) is the learnable parameter. The
a is a vector whose length is the same as the number of the channels of its input feature maps.
In experiments, we set the
in Equation (
4) to a fixed small value to 0.01. The leaky ReLu increases little additional computation costs. The increased FLOPS is less than the convolutional layers in order of magnitude. Therefore we note it is a good choice for improving the capacity of the light-weight networks.
3.6. Focal Loss
Focal loss is the third strategy to improve the detection accuracy. It is used in the training process and does not add any additional computation costs in the inference process. It improves the detector’s performance by dealing with the class imbalance problem in the training process better. Though the hard negative mining method used in the baseline can solve the class imbalance problem to some extent. The hard negative mining is still sub-optimal since it is hand-craft and discard all not-highest samples without considering whether these samples have high loss values or not. Suppose the output positive probability of sample
t is
, the Focal Loss is shown in Equation (
6). In Equation (
6),
is the weight for the losses of positive samples and
is the scaling factor for downsampling the easy samples. The optimal setting of
and
in [
21] is 0.25 and 2. In the embedded system based face detection task, the extremely hard examples such as heavy occlusions are less important. Therefore, in this paper, we change
to 1 to avoid too much attention to the extremely hard examples.
With the above strategies, we build the EagleEye based on the baseline detector, as shown in
Figure 1 and
Table 2.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}