Weak Signal Enhance Based on the Neural Network Assisted Empirical Mode Decomposition


Abstract
:1. Introduction
2. Weak Signal Reconstruction Method under EMDNN Model
2.1. Original Signal Pre-Processing
2.2. Empirical Mode Decomposition
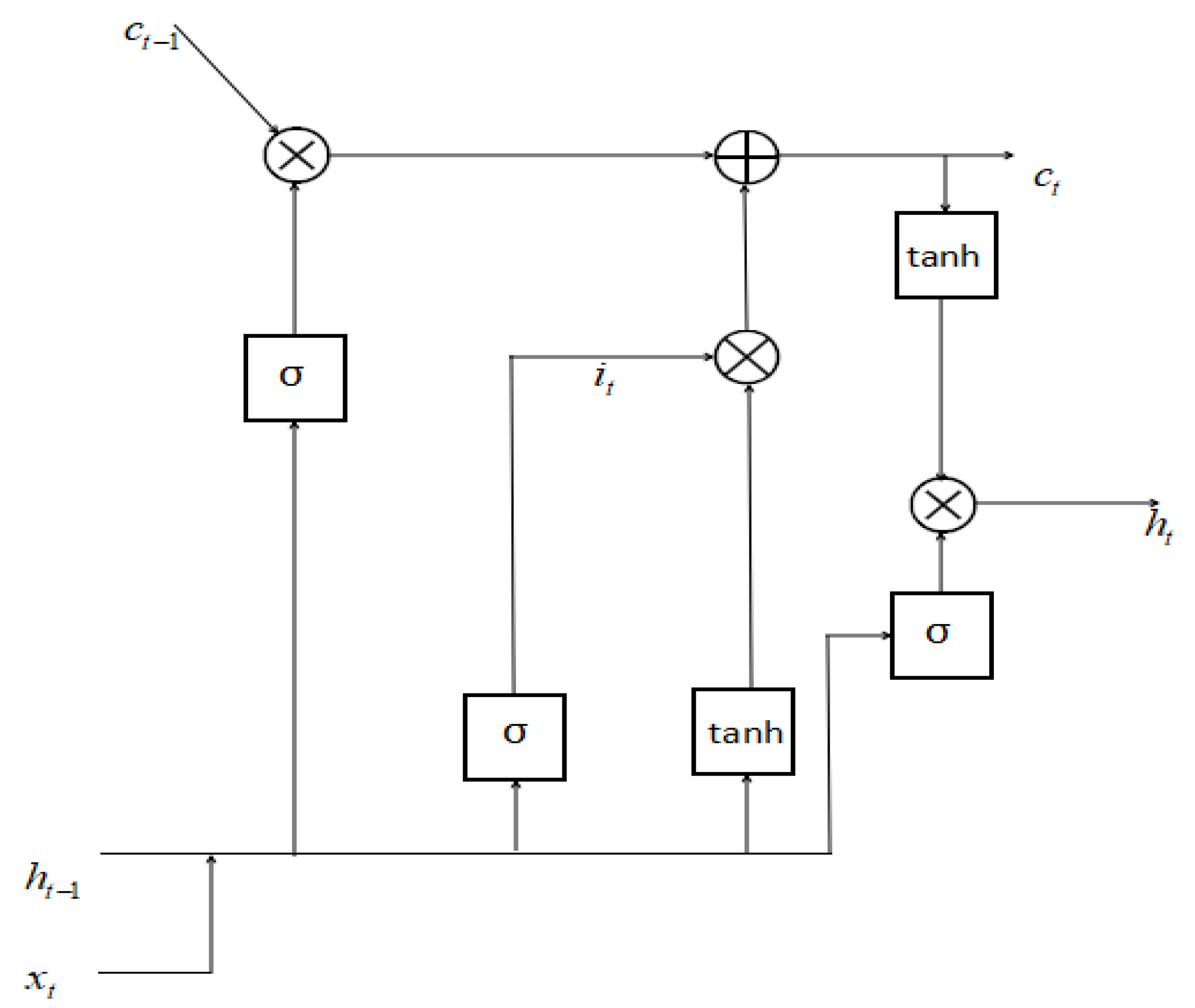
2.3. Adaptive Selection of Effective Inherent Modal Components by Using LSTM Model
2.4. Reconstructing and Enhancing Weak Signals
3. Experimental Results and Discussion
3.1. Training Detail
3.2. Contrast and Verification
3.2.1. Experimental Results and Analysis of Synthetic Weak Signal Data
3.2.2. Experiment and Analysis of Actual Weak Signal Data
3.2.3. Parallel Processing Experiments and Analysis
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. KL Divergence Formula
References
- Galiana-Merino, J.J.; Rosa-Herranz, J.L.; Rosa-Cintas, S.; Martinez-Espla, J.J. SeismicWaveTool: Continuous and discrete wavelet analysis and filtering for multichannel seismic data. Comput. Phys. Commun. 2013, 184, 162–171. [Google Scholar] [CrossRef]
- Qin, S.; Xia, X.; Yin, H. Denoising of nonlinear wavelet transform threshold value method in engineering. Shanxi Arch. 2008, 34, 120–122. [Google Scholar]
- Beenamol, M.; Prabavathy, S.; Mohanalin, J. Wavelet based seismic signal de-noising using Shannon and tsallis entropy. Comput. Math. Appl. 2012, 64, 3580–3593. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, M.Z.; Ghafoor, A.; Siddiqui, A.M.; Riaz, M.M.; Khalid, U. Dual-tree complex wavelet transform and SVD based medical image resolution enhancement. Signal Process. 2014, 105, 430–437. [Google Scholar] [CrossRef]
- Qin, Y.; Tang, B.; Mao, Y. Adaptive signal decomposition based on wavelet ridge and its application. Signal Process. 2016, 120, 480–494. [Google Scholar] [CrossRef]
- Yan, J.; Lu, L. Improved Hilbert-Huang transform based weak signal detection methodology and its application on incipient fault diagnosis and ECG signal analysis. Signal Process. 2014, 98, 74–87. [Google Scholar] [CrossRef]
- Carbajo, E.S.; Carbajo, R.S.; Goldrick, C.M.; Basu, B. ASDAH: An automated structural change detection algorithm based on the Hilbert-Huang transform. Mech. Syst. Signal Process. 2014, 47, 78–93. [Google Scholar] [CrossRef]
- Chu, P.C.; Fan, C.; Huang, N. Derivative-optimized empirical mode decomposition for the Hilbert-Huang transform. J. Comput. Appl. Math. 2014, 259, 57–64. [Google Scholar] [CrossRef] [Green Version]
- Al-Marzouqi, H.; AlRegib, G. Curvelet transform with learning-based tiling. Signal Process. 2017, 53, 24–39. [Google Scholar] [CrossRef]
- Jero, S.E.; Ramu, P.; Ramakrishnan, S. ECG steganography using curvelet transform. Biomed. Signal Process. Control 2015, 22, 161–169. [Google Scholar] [CrossRef]
- Li, X.; Shang, X.; Morales-Esteban, A.; Wang, Z. Identifying P phase arrival of weak events: The Akaike Information Criterion picking application based on the Empirical Mode Decomposition. Comput. Geosci. 2017, 100, 57–66. [Google Scholar] [CrossRef]
- Xie, K.; Bai, Z.; Yu, W. Fast Seismic Data Compression Based on High-efficiency SPIHT. Electron. Lett. 2014, 50, 365–367. [Google Scholar] [CrossRef]
- Hadizadeh, H. Multi-resolution local Gabor wavelets binary patterns for gray-scale texture description. Pattern Recog. Lett. 2015, 65, 163–169. [Google Scholar] [CrossRef]
- Liu, Z.; Chai, T.; Yu, W.; Tang, J. Multi-frequency signal modeling using empirical mode decomposition and PCA with application to mill load estimation. Neurocomputing 2015, 169, 392–402. [Google Scholar] [CrossRef]
- Bakker, O.J.; Gibson, C.; Wilson, P.; Lohse, N.; Popov, A.A. Linear friction weld process monitoring of fixture cassette deformations using empirical mode decomposition. Mech. Syst. Signal Process. 2015, 63, 395–414. [Google Scholar] [CrossRef] [Green Version]
- Colominas, M.A.; Schlotthauer, G.; Torres, M.E. Improved complete ensemble EMD: A suitable tool for biomedical signal processing. Biomed. Signal Process. Control 2014, 14, 19–29. [Google Scholar] [CrossRef]
- Cao, Y.J.; Jia, L.L.; Chen, Y.X.; Lin, N.; Li, X.X. Review of computer vision based on generative adversarial networks. J. Image Graph. 2018, 23, 1433–1449. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhang, H.; Chi, Y.; Zhou, Y.; Ren, T. Three Dimensional Seismic Signal Denoising Based on Four-Dimensional Block Matching Cooperative Filtering Combined with Principle Component Analysis. Laser Optoelectron. Prog. 2018, 55, 041007. [Google Scholar] [CrossRef]
- Wen, C.; Li, L.; Xie, K. Fast visualisation of massive data based on viewpoint motion model. Electron. Lett. 2017, 53, 1038–1040. [Google Scholar] [CrossRef]
- Chen, F.M.; Wen, C.; Xie, K.; Wen, F.-Q.; Sheng, G.-Q.; Tang, X.-G. Face liveness detection: Fusing colour texture feature and deep feature. IET Biom. 2019, 8, 369–377. [Google Scholar] [CrossRef]
- Wen, C.; Hu, Y.; Xie, K.; He, J.B. Fast recovery of weak signal based on three-dimensional curvelet transform and generalized cross validation. IET Signal Process. 2018, 12, 149–154. [Google Scholar] [CrossRef]
- Tero, K.; Timo, A.; Samuli, L.; Jaakko, L. PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION. arXiv 2018, arXiv:1710.10196. [Google Scholar]
- Lin, D.C.; Guo, Z.L.; An, F.P.; Zeng, F.L. Elimination of end effects in empirical mode decomposition by mirror image coupled with support vector regression. Mech. Syst. Signal Process. 2012, 31, 13–28. [Google Scholar] [CrossRef]
- Elman, J.L. Finding Structure in Time; CRL Technical Report 8801; Center for Research in Language, University of California: San Diego, CA, USA, 1988. [Google Scholar]
- Koutnik, J.; Greff, K.; Gomez, F.; Schmidhuber, J. A Clockwork RNN. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1863–1871. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Jaeger, H.; Haas, H. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E. Learning Distributed Representations of Concepts. In Proceedings of the 8th Annual Conference of the Cognitive Science Society, Amherst, MA, USA, 15–17 August 1986. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Qiu, T.; Wen, C.; Xie, K.; Wen, F.-Q.; Sheng, G.-Q.; Tang, X.-G. Efficient Medical Image Enhancement Based on CNN-FBB Model. IET Image Process. 2019, 13, 1736–1744. [Google Scholar] [CrossRef]
- Li, J.; Qiu, T.; Wen, C.; Xie, K.; Wen, F.-Q. Robust Face Recognition Using the Deep C2D-CNN Model Based on Decision-Level Fusion. Sensors 2018, 18, 2080. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, C.; Yang, Y.; Wen, C.; Xie, K.; Wen, F. Voiceprint Identification for Limited Dataset Using the Deep Migration Hybrid Model Based on Transfer Learning. Sensors 2018, 18, 2399. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.-X.; Wen, C.; Xie, K.; Wen, F.-Q.; Sheng, G.-Q.; Tang, X.-G. Face Recognition Using the SR-CNN Model. Sensors 2018, 18, 4237. [Google Scholar] [CrossRef] [Green Version]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- WANG, B.-l.; ZHU, Z.-l.; MENG, L. CUDA-based Acceleration of Three Dimensional 3D Medical Images Registration. J. Chin. Comput. Syst. 2013, 34, 2621–2625. (In Chinese) [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Data | Data Size (mb) | CPU Program Running Time (s) | GPU Program Running Time (s) | Speed up Ratio |
|---|---|---|---|---|
| Data1 | 43.2 | 32.03 | 12.41 | 2.58 |
| Data2 | 262.8 | 256.15 | 68.49 | 3.74 |
| Data3 | 568.7 | 532.47 | 122.69 | 4.34 |
| Data4 | 1020.3 | 2209.41 | 355.78 | 6.21 |
| Data5 | 14,328.8 | 40,160.92 | 5001.25 | 8.03 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, K.; Xie, K.; Wen, C.; Tang, X.-G. Weak Signal Enhance Based on the Neural Network Assisted Empirical Mode Decomposition. Sensors 2020, 20, 3373. https://doi.org/10.3390/s20123373
Chen K, Xie K, Wen C, Tang X-G. Weak Signal Enhance Based on the Neural Network Assisted Empirical Mode Decomposition. Sensors. 2020; 20(12):3373. https://doi.org/10.3390/s20123373
Chicago/Turabian StyleChen, Kai, Kai Xie, Chang Wen, and Xin-Gong Tang. 2020. "Weak Signal Enhance Based on the Neural Network Assisted Empirical Mode Decomposition" Sensors 20, no. 12: 3373. https://doi.org/10.3390/s20123373