1. Introduction
Nowadays, intelligent sensors such as the Microsoft Kinect can perform human body motion recognition and have been successfully used in various applications such as human–computer interaction, virtual reality, and intelligent robots. Moreover, the recent rapid development of data-driven approaches, including deep learning, has made it possible to use more general red, green, and blue (RGB) image sensors for human body motion analysis than depth sensors such as the Microsoft Kinect. In this paper, we address the problem of 3D human pose and shape reconstruction using a single monocular RGB sensor.
In the area of computer vision, research on 2D and 3D human pose estimation from a single RGB image have been improved considerably in recent years [
1,
2]. However, these studies only generate sparse keypoints of the human subject. We need dense shape information on the target subject to obtain a deeper understanding of the human image. Most recent studies use the 3D morphable model (3DMM) called skinned multi-person linear model (SMPL) [
3] to reconstruct the 3D shape of a person from an image. SMPL parameterizes the variation of the 3D human mesh using low-dimensional latent variables, such as pose and shape.
The recent 3D human body mesh reconstruction method based on SMPL is typically classified into two classes. The first is an optimization-based method that minimizes the energy function to fit the parameterized body model to the 2D features extracted from the input image. This method has the advantage of accurately obtaining a human body mesh without training with a dataset. However, this method has the following disadvantages. First, the optimization algorithm is sensitive to the initial point. If an appropriate initial point is not given, the optimization algorithm may fall into the local minima, which prevents a satisfactory reconstruction result. Second, the optimization process is generally very slow.
Methods using deep-learning-based regression networks have been proposed recently to overcome the disadvantages of the optimization-based approach. Deep learning networks run faster than optimization-based methods but have the following disadvantages. In most deep-learning-based methods, the network is trained using many pairs of inputs and outputs. Therefore, training a 3D human mesh reconstruction network based on SMPL requires a large dataset that includes many input images and their corresponding SMPL parameters. However, obtaining ground-truth SMPL parameters is generally very difficult. Therefore, most existing studies train the network indirectly using 3D poses instead of SMPL parameters. However, even 3D human poses are not easy to acquire in an in-the-wild environment. Hence, in this study, we propose a method to train a 3D human mesh reconstruction model without paired 2D and 3D data to solve the 3D data acquisition difficulty. Our method includes the following two contributions.
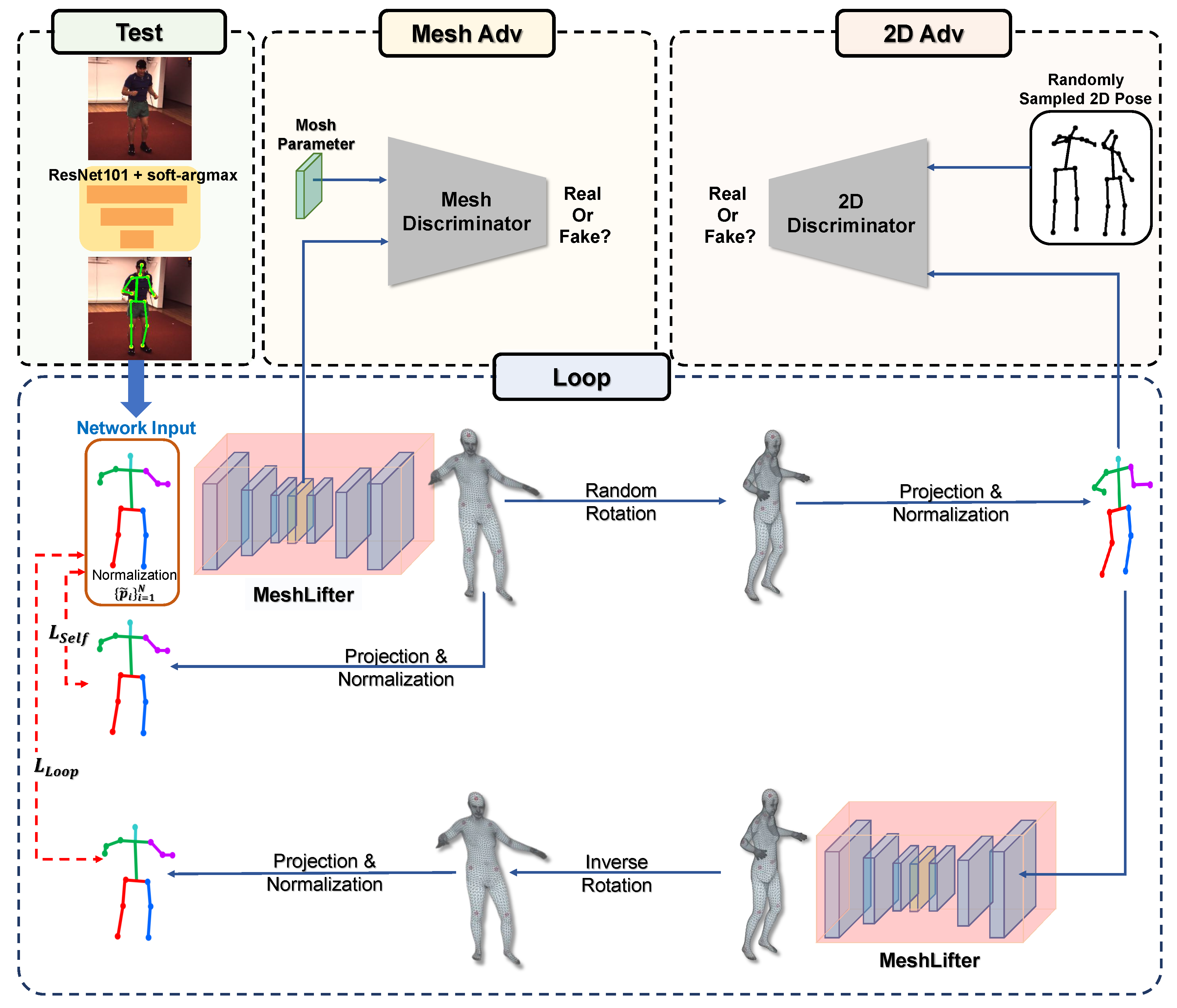
The first is MeshLifter, which is a deep learning model that outputs a 3D human mesh from an input 2D human pose and has the encoder–decoder structure. The encoder composed of residual blocks and fully connected layers outputs SMPL parameters from the input 2D human pose. The decoder with SMPL layer outputs 3D human mesh from the SMPL parameters generated from the encoder. A 3D pose can be also obtained from a 3D mesh using the pre-trained regression matrix included in the SMPL layer. Therefore, we can obtain the 3D mesh and 3D pose simultaneously from the input 2D human pose through the MeshLifter.
The second is a weakly supervised learning method based on a loop structure. The loop structure was first proposed in [
4] to solve projection ambiguity where multiple 3D poses can be mapped to one 2D human pose. In [
4], through the proposed loop structure, a lifting network that estimates a 3D pose from a 2D pose is trained without a 3D pose dataset. Our research goes further and proposes a method to learn MeshLifter, a model that can estimate 3D pose and 3D mesh from a single 2D pose. In the loop structure proposed in this study, 3D mesh lifting from a 2D pose through the MeshLifter and random rotation and 2D projection of a 3D pose computed through the MeshLifter are repeated, thereby providing a novel loop loss using only 2D pose data.
We reconstruct the 3D mesh by feeding the 2D pose estimated from the input image and not the ground-truth 2D pose into the MeshLifter to show the effectiveness of the proposed method. We use a general 2D human pose estimator based on a convolutional neural network (CNN). Through this experiment, we show that the MeshLifter can successfully reconstruct a 3D human mesh from a noisy input 2D human pose. In addition, through experiments using various datasets, such as Human3.6M [
5], MPI-INF-3DHP [
6], and MPII [
7], we show that the proposed method achieves comparable performance with existing state-of-the-art methods. An overview of the proposed method is illustrated in
Figure 1.
4. Experiments
4.1. Datasets
The Human3.6M [
5] and MPI-INF-3DHP [
6] datasets containing RGB human images and corresponding ground-truth 3D human poses are used for training and evaluation of the proposed method. The Mosh [
14] dataset containing only the ground-truth SMPL parameters without RGB images is also used for discriminator learning. The Human3.6M dataset [
5] provides 3.6 million 2D and 3D human poses and their corresponding RGB images. To construct the dataset, 17 actions (e.g., discussion, smoking, taking the photo, …) of 11 subjects were acquired through a motion capture system using four cameras. We used the subjects S1, S5, S6, S7, and S8 for training and the subjects S9 and S11 for testing according to the conventional protocol. We also sampled one frame every five frames and used it for an experiment to reduce the redundancy of the dataset. The MPI-INF-3DHP dataset [
6] consists of approximately 100,000 learning images acquired through a markerless motion capture system indoors and approximately 3000 test images acquired indoors and outdoors. All images in the MPI-INF-3DHP dataset are annotated with 3D human poses. The Mosh dataset [
14] was constructed by converting 3D human poses of subjects captured using a marker-based motion capture system into SMPL parameters. Approximately 410,000 SMPL parameters were used for our experiment. Lastly, the MPII dataset [
7] containing in-the-wild images is used for the qualitative evaluation of the proposed method. The MPII dataset cannot be used for quantitative evaluation because only 2D poses are annotated. The descriptions of the datasets used in our experiment are summarized in
Table 2.
4.2. Evaluation Metrics
Under the perspective projection assumption, the 3D shape can be reconstructed only up to a scale factor. Therefore, the proposed method cannot be used to determine the actual body size of the human subject. In consideration of this, we use the reconstruction error, which computes the mean per joint position error (MPJPE) after adjusting the scale and global rotation of the predicted 3D pose and ground-truth 3D pose, according to the Procrustes analysis [
15], as the evaluation metric. MPJPE is defined as the average Euclidean distance between the predicted joint
and grount-truth joint
as follows:
where
i denotes the index of the joint.
4.3. Implementation Details
Our code is released at
https://github.com/sunwonlikeyou/MeshLifter. The python 3.6 and PyTorch 1.2.0 [
16] are used to implement the proposed method. The initial learning rate and the number of epochs are set to
and 100, respectively, to learn the MeshLifter and discriminator. The learning rate decays with a rate of 0.1 after the 50th epoch.
Figure 5 shows the curves of all our losses during training. We can observe that the losses except
are minimized and converged. One exception,
, increases with epoch and converges to a value of 1.0. It indicates that the generator, the MeshLifter, fails to produce realistic results that can deceive the 2D pose discriminator. Nevertheless, according to the ablation study in
Section 4.4,
significantly improves the quantitative performance of the proposed method. We believe that this is because
works effectively as a kind of regularization term for plausible 2D poses. The implementation details for MeshLifter and discriminators are as follows.
MeshLifter has an encoder–decoder structure. The encoder consists of linear layer, ReLU [
17], dropout [
18], batch-norm [
19], and residual connection [
20]. The decoder includes an SMPL layer composed of only differentiable operations and thus, its parameters can be updated through back-propagation.
Discriminator for SMPL parameter is composed of two networks,
and
, that correspond to pose and shape parameters as described in
Section 3.
includes two fully connected layers composed of 10 and 5 hidden units and one ReLU layer.
includes a Rodrigues layer, two convolutional layers, and two branches. The Rodrigues layer converts a pose parameter expressed in the axis-angle format to a
rotation matrix according to the Rodrigues formula. The two convolutional layers consist only of
size convolution filters, and the number of input and output channels is (9,32) and (32,32), respectively. The first branch contains fully connected layers composed of 736, 1024, and 1024 hidden units. The second branch contains fully connected layers with 32 hidden units for all joints.
Discriminator for 2D pose consists of two consecutive residual blocks and two fully connected layers for input and output of the network. Each residual block includes fully connected layer with 3000 hidden units, batch-norm, dropout, ReLU, and residual connection.
The 2D pose predicted from the RGB image using CNN is used as the input of MeshLifter for a fair comparison with previous methods. The ResNet101 [
20] model is used as a backbone network for 2D pose estimation, and the last layer is modified to output a heatmap of
resolution. We also added the soft-argmax layer [
21] to obtain continuous 2D joint coordinates free from quantization error from the heatmap. The network outputs the 2D human pose
from an input RGB image of
size.
Table 3 shows the performance of the 2D human pose estimation.
4.4. Ablation Study
An ablation study is performed to investigate the effects of the proposed losses on the performance of our model, and
Table 4 shows its quantitative results. The MeshLifter trained with only
is considered as the baseline. Loop, Mesh, 2D, and Reg indicate
,
,
, and
are used to learn the MeshLifter, respectively.
Table 4 shows that
,
, and
are significantly helpful for improving the performance of the MeshLifter. According to
Table 4, the results obtained using all loss functions except
show the best quantitative performance. However,
Figure 6 shows that
plays an important role in the qualitative performance of the reconstructed human mesh. The left, middle, and right columns in
Figure 6 show the input image, the 3D mesh output by the MeshLifter trained without
, and the 3D mesh output by the MeshLifter trained with
, respectively. The use of
prevents the monstrous mesh output and helps in reconstructing the anthropometrically plausible human mesh.
4.5. Quantitative Result
Table 5 and
Table 6 provide the quantitative results of the proposed method and recent existing methods for the Human3.6M and MPI-INF-3DHP datasets, respectively. They show the proposed method achieved the state-of-the-art performance among methods that do not use 3D pose data as direct supervision for learning. This result shows that the proposed weakly supervised method based on the loop structure effectively learns our MeshLifter.
4.6. Qualitative Result
Figure 7,
Figure 8 and
Figure 9 show the qualitative results of the proposed method for Human3.6M, MPI-INF-3DHP, and MPII datasets, respectively. The figures show that the proposed method can successfully reconstruct 3D human meshes from various input images acquired in controlled and in-the-wild environments.
4.7. 3D Hand Mesh Reconstruction
Additional experiments for hand mesh reconstruction are conducted to investigate the general applicability of the proposed method. To this end, we used MANO [
24], a 3DMM for human hands, as a decoder for the MeshLifter. For training and evaluation, we used the Rendered Handpose Dataset (RHD) [
25], which includes 24,619 training images and 1459 test images. In the case of hands, a dataset that provides ground-truth 3DMM parameters, such as the Mosh dataset for the body, is not available, and thus, the mesh adversarial training in
Section 3.3 cannot be performed. Therefore, we introduce the following regularization term that constrains pose and shape parameters together:
where
is the MANO shape and pose parameters output from the encoder, and
is the shape and pose parameters of the template hand mesh. Finally we train the MeshLifter for hands using the following loss function:
where
,
, and
are set to 1.0, 0.3, and 0.1, respectively.
Table 7 shows a quantitative comparison between the proposed method and existing studies for 3D hand pose estimation. As an evaluation metric for comparison, the reconstruction error is used as in the body.
Table 7 shows that the proposed method does not achieve the best performance quantitatively. However, all methods except the proposed method train the network in a supervised manner, and output only sparse 3D hand joints. Meanwhile, the proposed method generates a dense 3D hand mesh in a weakly supervised fashion, which shows the effectiveness of the proposed method. In addition,
Figure 10 shows that the proposed method performs qualitatively successful 3D hand mesh reconstruction.
4.8. Discussion
In this subsection, we present the usability of the proposed method, limitations, and future works to overcome them. Our proposed method can reconstruct the 3D mesh of the target human object in the form of SMPL parameters. By using the Equation (4), 3D joints can also be obtained from the reconstructed mesh. This 3D skeleton information is used for gesture or action recognition and can be applied to various fields such as human–computer interaction and visual surveillance. Meanwhile, the SMPL parameters reconstructed by the proposed method directly include 3D rotation information of limbs that make up the body beyond merely 3D coordinates of body joints. The rotation information enables motion retargeting between characters and can be used for computer graphics and augmented/virtual reality.
The proposed method uses a single 2D human pose to reconstruct the 3D mesh of the target person. This 2D pose alone does not provide enough information to obtain reliable body shape information, so the proposed method relies heavily on the regularization term to estimate the SMPL shape parameters encoding human body shape information. Therefore, we plan to investigate how additional image features other than 2D poses can have an advantage in estimating shape parameters. Also, the proposed 3D human reconstruction method relies on a single 2D pose or a single RGB image. It makes the temporal prior, which can alleviate the ambiguity of the 3D reconstruction problem, unavailable in the proposed method. It also makes the proposed method produce results that lack temporal consistency when applied to an input 2D pose or image sequence. Therefore, our next future work is to extend the proposed method to 2D pose sequence input and pursue a method in which the proposed model can adopt the temporal prior.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}