3.1. Overall Flow and Dataset Preparation
Figure 4 shows the overall flowchart of the proposed methodology. The left-hand side of the flowchart shows the test pattern generation process in which failure log datasets are generated on the generated test patterns. A target circuit is synthesized, and scan chains are inserted into the target circuit using a Synopsys design compiler. Next, an ATPG is executed on the scan-chain insertion circuit under test. Subsequently, the test patterns for the target circuit are produced, and failure log datasets are generated to obtain the training and test datasets for the target circuit. Moreover, a fault model is defined similar to the SA fault, slow, and fast models. Furthermore, an intermittent fault simulation is executed to produce the failure log datasets of the defined fault model.
The right-hand side of the flowchart shows the failure feature vector generation process in which the ANN of each scan chain is constructed with the failure feature vectors. First, during test pattern generation, a hierarchical cell report and scan-chain report are generated, and thereby, fan-in and fan-out filters are generated. Next, failure features are extracted using the failure log datasets, fan-in filters, and fan-out filters, to generate failure feature vectors. Subsequently, ANNs are trained for each chain using the failure feature vectors. Finally, the scan-chain diagnosis using the ANNs infer the defective scan cells in each scan chain.
The failure log datasets—comprising failure logs and output labels (the position of the defective cell)—are generated using the following three parameters: (1) fault model, (2) fault location, and (3) fault probability.
Fault model: A modeled fault that is one of the following fault types: SA0, SA1, slow-to-rise, slow-to-fall, fast-to-rise, fast-to-fall, fast, or slow.
Fault location: A modeled fault is generally assumed to occur in the input wire or output wire of the scan cells or scan cell logic. Therefore, the output of the scan cell can be affected by the modeled faults. The fault location is the location of the scan cell, and it is labeled by the chain and cell numbers. For example, if the third cell in the second chain has a fault, the output label becomes (2, 3).
Fault probability: A modeled fault may occur during the processing time. We determined the probability of the fault occurring during the generation of the failure log dataset. For example, assume that a scan chain has seven cells. If the probability of an SA0 fault occurring in Cell 3 is 20%, then each test stimulus at Cells 4–7 may have a 20% probability of failure. By contrast, the test response of Cells 1, 2, and 3 may have a 20% probability of failure.
The fault probability is determined as 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, and 100%. Depending on the probability, the failures are injected in the test stimulus and the test response, as shown below.
Perform ATPG and obtain the standard test interface language (STIL) file that contains the test patterns of the target circuit.
Inject errors to the test stimulus of the target scan chain with the determined fault probability.
Perform fault simulation with the failure-injected STIL file and obtain the failure log datasets through the errors in the test stimulus.
Inject errors in the test response of the target chain with the determined fault probability.
In the failure log datasets, various failure cases can be generated even for the same probability. Hence, various vectors can be obtained in the same group of probabilities through 10 iterations.
3.2. Failure Feature Extraction
There are two kinds of failures due to the scan-chain faults: test stimulus failure and test response failure. The test stimulus failures are the polluted values of the test stimulus during the shift sequence. Because the value of the test stimulus is loaded serially into the scan chain through a scan-in port-by-shift sequence, the test stimulus values of upstream scan cells of the defective cell are polluted by the defective cell during the shift sequence. This test stimulus failure can cause multiple failures in the fault-free chain through the connected combinational circuits during the capture sequence. Meanwhile, the test response failures are the failures in the test response of the defective chain during shift sequence. In the shift sequence, the state of the scan chain by the capture sequence (test response) is shifted out through scan-out port. Therefore, the test response values of the downstream cells of the defective cell are polluted by the defective cell during the shift sequence. This test response failure can cause only one failure. Therefore, test stimulus failure can cause more failures than test response failure.
Therefore, a fault that occurs near the scan-in cell can cause more test stimulus failures than the test response failures, increasing the number of failures in the failure log. On the other hand, a fault that occurs near the scan-out cell can cause fewer errors in the test stimulus and increase the number of errors in the test response of the defective scan chain, decreasing the number of failures in the failure log.
Figure 5 shows some relevant examples. To simplify the explanation, defective cells are marked by gray boxes; the cells in which errors occur at the test stimulus are marked by the dot patterned boxes; the cells in which failure is observed at the test response are marked by diagonally lined boxes. As shown in the upper part of
Figure 5a, assume that an SA fault exists in Cell 10 in the defective chain. This SA fault will affect the test stimulus of Cells 11 and 12 in the defective chain. Therefore, errors will only spread to sensitive Cells 10, 11, and 12 in the fault-free chains. In contrast, assume that an SA fault exists in Cell 2 in the defective chain, as illustrated at the bottom of
Figure 5a. This SA fault affects the test stimulus in Cells 2–12 in the defective chain. Hence, several more errors appear in the fault-free chains at the scan output compared with the case in Cell 10. However, the number of failures in the defective chain decreases as the defective scan cell approaches the scan-in cell and increases as the defective scan cell approaches the scan-out cell, as shown in
Figure 5b.
These effects are more prominent in the sensitive cells of each cell. Therefore, a shorter vector that contains all the failure information would be generated by vectorizing the tendencies of the failures based on an investigation of all the sensitive cells in each chain. Consequently, filters are necessary to generate a vector that can train these tendencies from the raw failure log datasets.
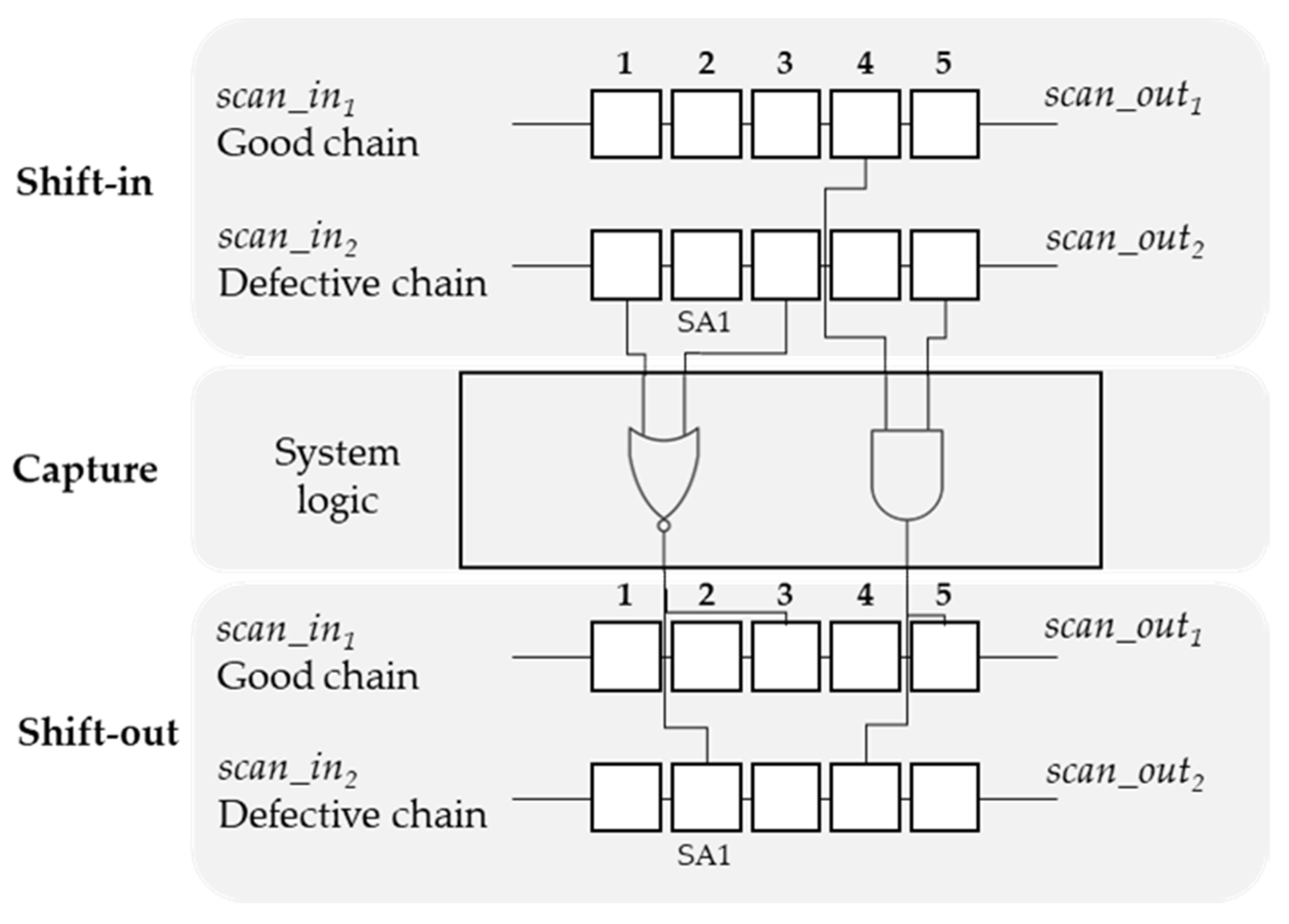
The sensitive cells are categorized into two types. The first type includes the fan-out cells, which are the affected cells in all the chains that are connected to the cell of the defective chain. Therefore, if an error occurs at a cell, the observed responses of one or more of the fan-out cells will contain errors. For example, as shown in
Figure 3, if an error occurs in the test stimulus at Cell 0 in Chain 1, the test response of Cell 0 in Chain 1 and that of Cell 1 in Chain 2 may lead to failures in these cells. Therefore, Cell 0 and Cell 1 in Chain 2 are the fan-out cells of Cell 0 in Chain 1, in contrast to the fan-in cells. Similar to this example, the fan-out filters identify the fan-out cells in the defective chain.
The second type is the fan-in cells, which are the affected scan cells at the defective chain that are connected to the cell of the fault-free chain. If there is an error in the response of a cell in a chain other than the detective chain, this error must have originated from the error stimulus of a cell in the defective chain. The fan-in cells are the cells observed by backtracking the cells that are connected. Therefore, an error occurring at a cell results in errors in the test stimulus of one or more of the fan-in cells of the cell. For example, Cell 1 in Chain 1 and Cell 0 in Chain 2 are connected to an AND gate cell, which is connected to Cell 0 in Chain 1 and Cell 1 in Chain 2. Consequently, Cell 1 in Chain 1 and Cell 0 in Chain 2 are the fan-in cells of Cell 0 in Chain 1 and Cell 1 in Chain 2.
The fan-in and fan-out filters are generated by analyzing the circuit logic structure to extract the failure feature from the failure logs. First, the hierarchical cell and scan-chain reports are analyzed. The hierarchical cell report details the connection of each cell, such as the input pins, output pins, net driver pins, and net load pins, whereas the scan-chain report shows the name of the scan cell belonging to each scan chain. Accordingly, the fan-in and fan-out filters are generated by searching all the fan-in and fan-out cells of each cell.
3.2.1. Fan-In Filters
The fan-in filter accumulates the number of errors affected by the fan-in cells in the defective chain. Hence, each element of a vector reflects the number of errors affected by each cell in the defective chain. Therefore, the length of the fan-in vector is the same as that of the defective chain. First, the fan-in filters detect the fan-in cells of all the scan cells in the defective chain. Subsequently, the number of errors in the fan-in cells of each cell is applied to the element reflecting the cell of the fan-in vector.
To apply the number of errors, failure log datasets are analyzed. If an error exists at the location of a cell in the failure log dataset, this information is applied in the elements of the fan-in cells in the fan-in vectors, if no error occurs in the test response of the fan-in cells. Because, if a failure occurs on the test stimulus of the defective chain, failure does not occur again on the test response of the chain except the defective cell. Therefore, each element of fan-in vectors reflects the number of errors in the fault-free chain caused by each cell in the defective chain. This operation is performed for all failure log datasets. By adding all vectors investigated in this manner, a fan-in vector is created.
An example of the fan-in filters is demonstrated in
Figure 6 and
Table 1. The target circuit comprises three scan chains, each containing seven cells. For ease of explanation, Cell B in Chain A is referred to as S
AC
B. If an SA0 fault occurs at Cell 5 in scan chain 2 (S
2C
5), then errors occur at Cells 1, 2, and 6 in scan chain 1 (S
1C
1, S
1C
2, S
1C
6), Cells 1–5 in scan chain 2 (S
2C
1, S
2C
2, S
2C
3, S
2C
4, S
2C
5), and Cells 1, 2, and 6 in scan chain 3 (S
3C
1, S
3C
2, S
3C
6) in the observed responses of test pattern 0.
An analysis of the circuit structure in
Table 1 shows that S
1C
1 is affected by S
2C
1, S
2C
3, and S
2C
6; S
1C
2 is affected by S
2C
5; S
1C
6 is affected by S
2C
4, S
2C
5, and S
2C
7; S
3C
1 is affected by S
2C
2 and S
2C
5; S
3C
1 is affected by S
2C
5 and S
2C
6; S
3C
2 is affected by S
2C
7. In pattern 0, the failure at the S
1C
1 is applied to the fan-in vector of S
2C
1, S
2C
3, and S
2C
6. There are failures on the test responses of S
2C
1 and S
2C
3. Therefore, only the element of S
2C
6 counts, <0 0 0 0 0 1 0>. The failure of S
1C
2 is applied to S
2C
6, <0 0 0 0 0 2 0>. The failure of S
1C
6 is applied to S
2C
7, <0 0 0 0 0 2 1>. The failure of S
3C
1 is applied to S
2C
2 and S
2C
5, but there are failures on the test response of S
2C
2 and S
2C
5, <0 0 0 0 0 2 1>. The failure of S
3C
2 is applied to S
2C
5 and S
2C
6, but there is failure on the test response of S
2C
5, <0 0 0 0 0 3 1>. The failure of S
3C
6 is applied to S
2C
7, <0 0 0 0 0 3 2>. Therefore, the fan-in vector of scan chain 2 becomes <0 0 0 0 0 3 2>. This fan-in vector is generated through all the failure log datasets. Subsequently, test patterns 0, 1, 2, and 3 acquire vectors <0 0 0 0 0 3 2>, <0 0 1 1 1 3 3>, <0 1 0 2 0 3 4>, and <0 1 0 0 1 3 2>, respectively. By adding all the vectors, the fan-in vector becomes <0 2 1 3 2 12 11>.
3.2.2. Fan-Out Filters
If a fault occurs near the scan-in cell, the test stimulus will contain more errors than when a fault occurs near the scan-out cell. Therefore, the failure in the test response would have spread more than that in the case where it is close to the scan-out cell.
Hence, the fan-out filter accumulates the number of errors at the fan-out cells in all the chains. Therefore, each element of a vector reflects the number of errors in the fan-out cells. Accordingly, the length of the fan-out vector is the same as the number of cells. First, the fan-out filters detect the fan-out cells of all the scan cells. Subsequently, the number of errors in the fan-out cells of each cell is applied to the element reflecting the cell of the fan-out vector.
To obtain the features from the failure log dataset, the fan-out filters track the spreading cells of the shift-out failures from all chains using a circuit structure similar to that of the fan-in filter. Resembling the fan-in vector, each element of a vector reflects the number of errors in the fan-out cells in the defective chain. The failure log datasets are analyzed to calculate the number of errors in the fan-out cells. The fan-out cells of each cell are searched, and the total number of errors that exist at all fan-out cells is accumulated in the elements of the cell in the fan-out vectors. Therefore, the element of the fan-out vectors reflecting a cell becomes the sum of the number of errors at all the fan-out cells of the cell. Moreover, all the failure log datasets are summed. This operation is performed for all the scan chains. Subsequently, a fan-out vector is created by adding all the vectors investigated thus.
Figure 7 and
Table 2 demonstrate the fan-out filters, where the target circuit comprises three scan chains, each containing seven cells. If an SA fault occurs at Cell 3 in scan chain 2 (S
2C
3), then test pattern 0 acquires the failure at Cells 3, 4, and 7 in scan chain 1 (S
1C
3, S
1C
4, S
1C
7); Cells 3, 4, 5, and 7 in scan chain 2 (S
2C
3, S
2C
4, S
2C
5, S
2C
6, S
2C
7); and Cells 5 and 7 in scan chain 3 (S
3C
5, S
3C
7).
In this circuit structure as shown in
Table 2, S
2C
2 is affected by S
2C
3; S
2C
3 is affected by S
1C
2 and S
2C
3; S
2C
4 is affected by S
3C
5; S
2C
5 is affected by S
2C
3, S
1C
4, S
1C
7, and S
3C
7; S
2C
6 is affected by S
3C
2, S
3C
4, and S
3C
5; and S
2C
7 is affected by S
1C
7, S
2C
7, and S
3C
7. In this case, in pattern 0, the fan-out vector of S
2C
1 is 0 due to the absence of a fan-out cell in Cell 0; that of S
2C
2 and S
2C
3 is 1 due to failure at the fan-out cell S
2C
3; that of S
2C
4 is 1 due to failure at the fan-out cell S
3C
5. Finally, the fan-out vector of scan chain 2 becomes 0 1 1 1 3 1 3. These fan-out vectors are generated using all the failure log datasets. Subsequently, test patterns 0, 1, 2, and 3 acquire vectors <0 1 1 1 3 1 3>, <0 0 2 1 2 3 3>, <0 1 2 2 4 3 4>, and <0 1 3 0 5 3 2>, respectively. By adding all the vectors, the fan-out vector of scan chain 2 becomes <0 3 7 4 13 10 12>.
3.2.3. Scan-Chain Diagnosis with Regressions
In this study, linear and logistic regressions were used for scan-chain diagnosis. The proposed scan-chain diagnosis requires only one trained model for the target chain and a target fault type, such as stuck-at 0, stuck-at 1, fast-to-rise, fast-to-fall, slow-to-rise, and slow-to-fall, to determine the accurate candidate of the scan-chain faults. With Nc scan chains and f fault types, models are trained to support the proposed scan-chain diagnosis.
The input vector of the proposed methodology, which is called the failure feature vector, is formed by combining three vectors. The first vector is the fan-in vector from the fan-in filter, the second vector is the fan-out vector from the fan-out filter, and the last vector is the IFV. These failure feature vectors are generated from the failure log datasets using the fan-in and fan-out filters. Furthermore, the generated failure feature vectors are categorized into train and test sets for training and testing, respectively. An example of the training vector is illustrated in
Figure 8.
Linear regression and logistic regression were used as the machine-learning models through scikit-learn [
39]. Linear regression analysis involves quantitatively determining the relation between the D-dimensional vector-independent variable
x and the corresponding scalar-dependent variable
y.
The linear regression model involves obtaining a function
that outputs a value
that is closest to the corresponding dependent variable
y for the independent variable
x, Equation (1).
If the relation between
x and
y is the following linear function
, it is known as a linear regression function Equation (2).
where
, …,
are the coefficients of function
and the parameters of this linear regression model. We considered a linear regression for solving the single-fault problem. The failure log dataset of a scan-chain fault exhibits a failure distribution tendency, and a linear regression is a suitable algorithm for solving this problem.
The logistic regression is used to determine the probability of the existence of a certain class, such as pass/fail, win/lose, or healthy/sick. This scan-chain diagnosis problem can be categorized into a pass/fail class in the output element of each vector, which is the same as the logistic regression problem. This problem is difficult to solve because the output label is only 0/1 in the output vector, as shown in
Figure 9a. Therefore, logistic regression is used to solve the pass/fail problem using logistic functions.
In several natural and social phenomena, the probability value for a specific variable often follows the form of an S-curve rather than a linear one. The logistic function expresses this S-curve as a function. Logistic functions can assume any value as an
x value, but the output is always between 0 and 1. In other words, this function satisfies the requirement of a probability distribution function. The formula (3) is given below:
If the logistic function is used as an activation function in neural networks, we can easily solve the pass/fail problems using the neural networks, as shown in
Figure 9b.
For a future multiple-fault problem, logistic regression is performed to solve a single scan-chain fault problem. If multiple faults occur in a scan-chain diagnosis, an output label cannot be obtained. Alternatively, a binary output label having the same length as that of the target scan chain is obtained. For algorithm optimization, scikit-learn can decide to use various solvers for logistic regression. The solvers used for scan-chain diagnosis are “A library for large linear classification (liblinear)”, “limited-memory Broyden–Fietcher–Goldfarb–Shanno (lbfgs)”, “stochastic average gradient (sag)”, and “saga”. Appropriate solvers for each training case are listed in
Table 3.
The “liblinear” solver uses the coordinate descent algorithm. Hence, it successively solves the problem by performing an approximate minimization along the coordinate directions or hyperplanes. However, it may not be able to solve the nonstationary point or learn a multiclass model.
The “lbfgs” solver uses the Hessian matrix; however, it is approximated using updates specified by gradient evaluations. In addition, its limited memory stores merely a few vectors that represent the approximation implicitly. Therefore, if the training dataset is small, then “lbfgs” delivers the best performance, compared with the other methods. However, it may not converge if it is not safeguarded.
The “sag” solver uses optimization for the sum of a finite number of smooth convex functions. Therefore, its iteration cost is independent from the number of terms in the sum. However, it is faster than the other solvers for large datasets, as it incorporates the memory of previous gradient values when both the numbers of samples and features are large.
Additionally, the “saga” solver is a variant of the sag solver that supports the non-smooth option. This solver is for sparse multinomial logistic regression and is suitable for extremely large datasets, similar to the “sag” solver. An appropriate solver must be used to optimize the accuracy of scan-chain diagnosis. Therefore, the characteristics of the scan-chain failure data must be considered. As listed in
Table 3, the size of the dataset is critical when selecting a solver. The size of the failure log datasets depends on the circuit size. Therefore, the solver for a circuit is selected based on the circuit size.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}