A Framework for Human-Robot-Human Physical Interaction Based on N-Player Game Theory



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- N-player differential game theory is firstly used to model the human-robot-human interaction system.
- (2)
- An online estimation method to identify unknown humans’ control objectives based on the recursive least squares algorithm is presented.
- (3)
- A general adaptive optimal control framework for human-robot-human physical interaction is propose based on (1) and (2).
- (4)
- The effectiveness of the proposed method is demonstrated by rigorous theoretical analysis and simulation experiments.
2. Problem Formulation
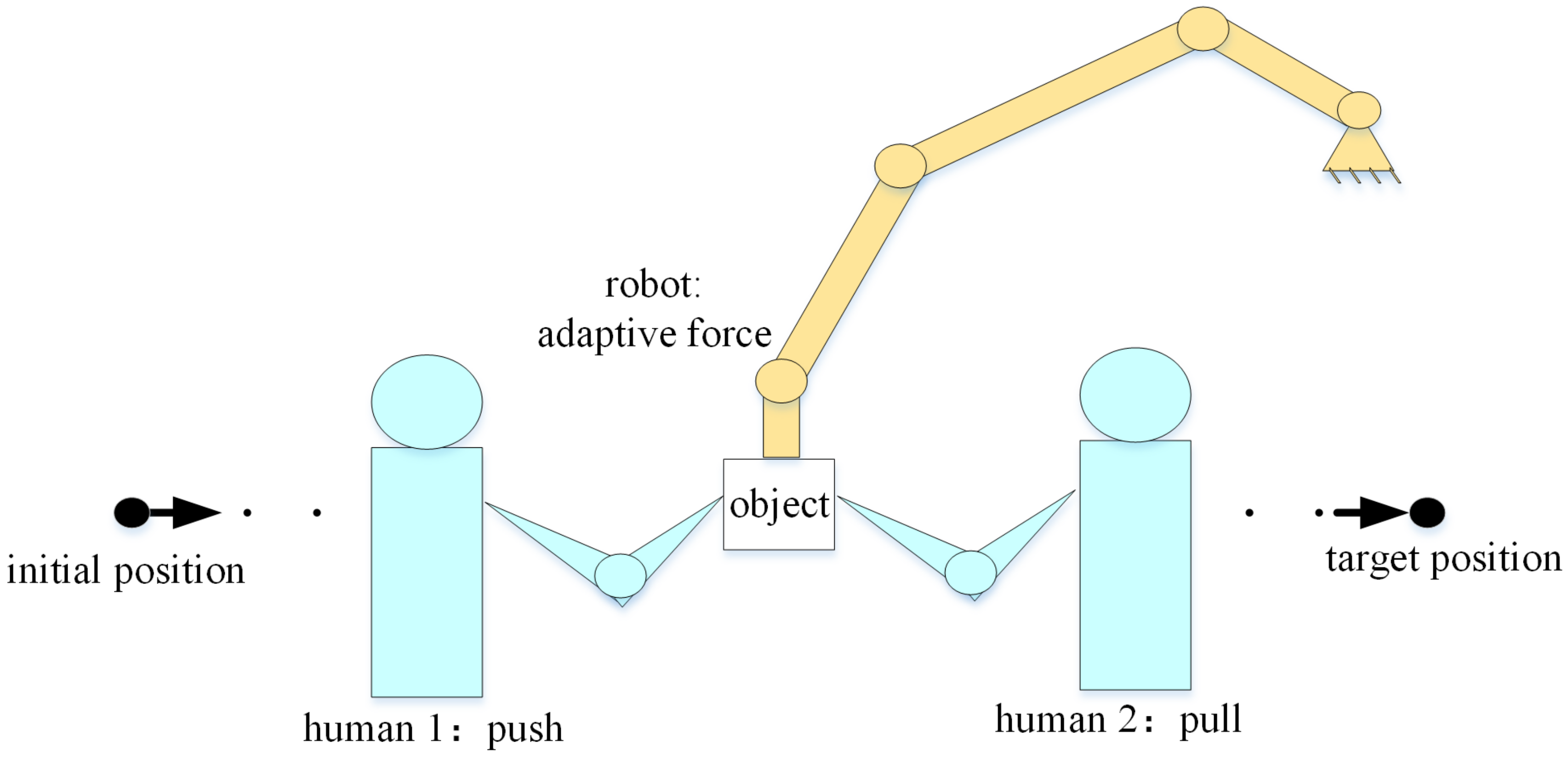
2.1. System Description
2.2. Problem Formulation
2.3. N-Player Differential Game Theory
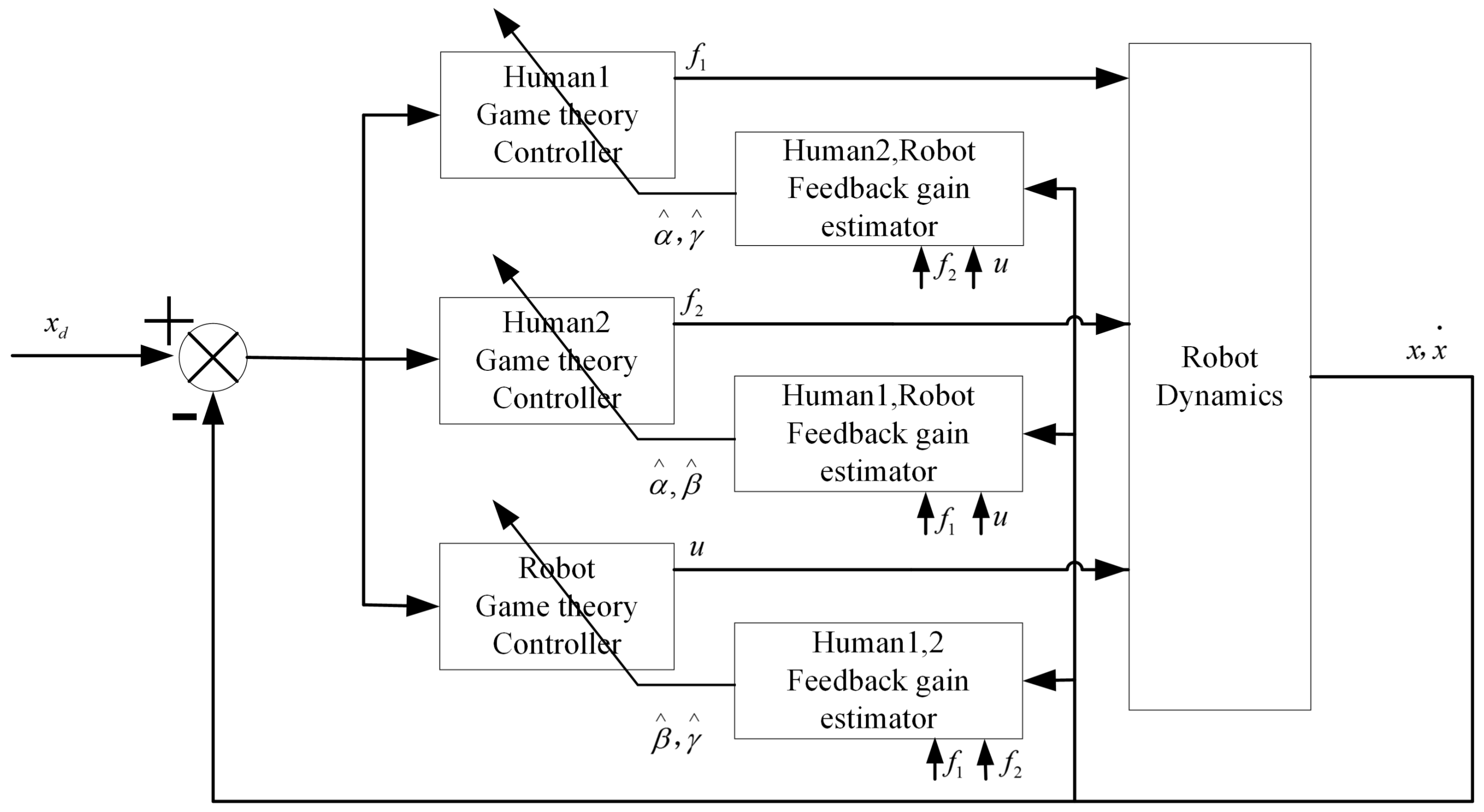
3. Adaptive Optimal Control
| Algorithm 1 Adaptive optimal control algorithm based on N-player game |
| Input: Current state z, target . |
| Output: Robot’s control input u, estimated the humans’ cost function state weight in Equation (10e,f). |
| Begin |
| Define , initialize , set in Equation (13), in Equation (18), C in Equation (21), the terminal time of one trial. |
| While do |
| Measure the position , velocity , and form z. |
| Update using Equations (13) and (15), Update using Equations (18) and (20). |
| Solve the Riccati equation in Equation (10d) to obtain P, and calculate the robot’s control input u. |
| Calculate estimated the humans’ cost function state weights in Equation (10e,f) using the Riccati equation. |
| Compute robot’s cost function state weight Q according to Equation (21). |
- The closed-loop system is stable, and are bounded.
- , , which indicate that converge to the correct values , if z is persistently exciting.
- The Nash equilibrium is achieved for th human-robot-human interaction system.
4. Simulations and Results
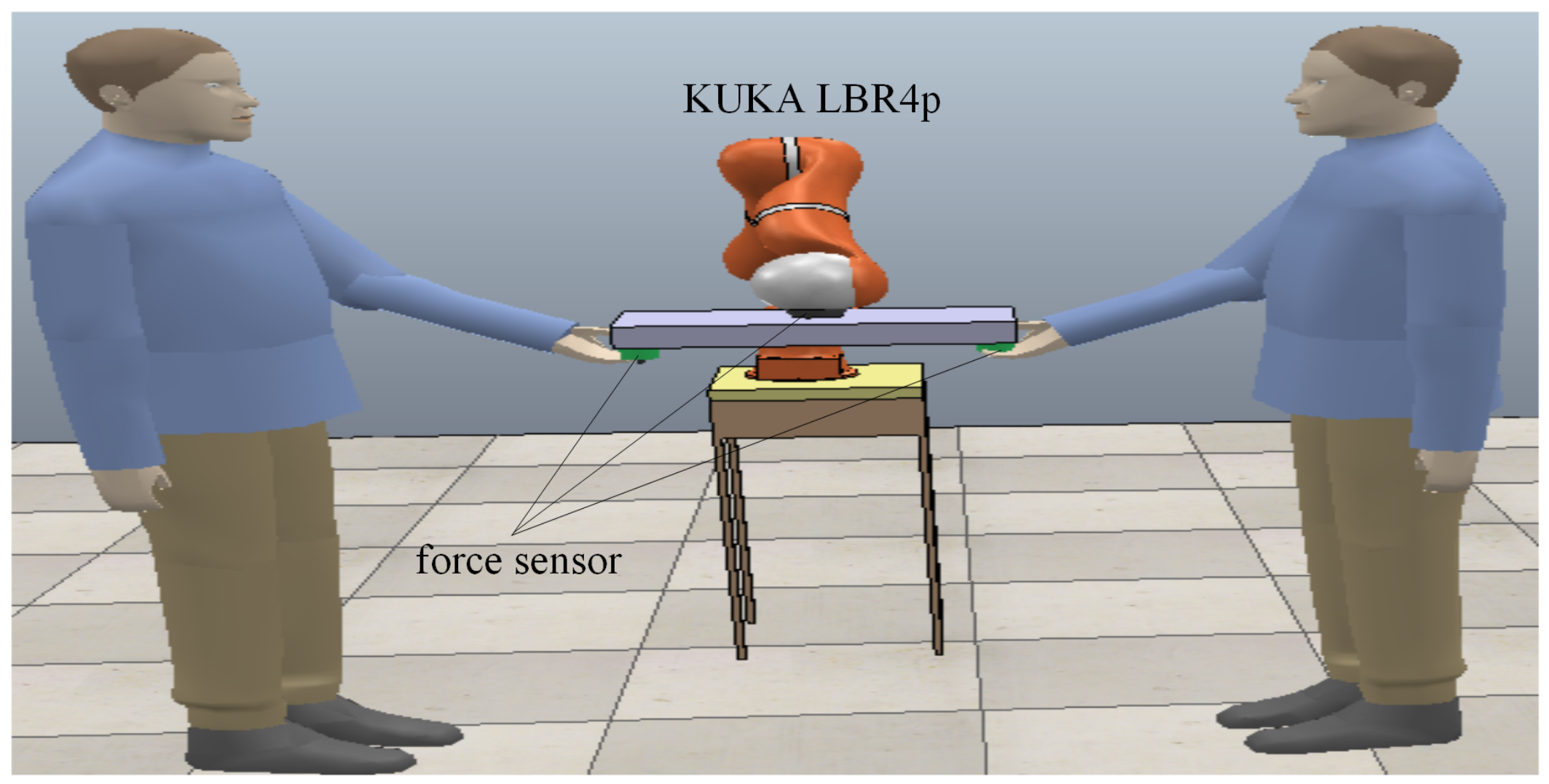
4.1. Experimental Design and Ssimulation Settings
4.2. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- De Santis, A.; Siciliano, B.; De Luca, A.; Bicchi, A. An atlas of physical human-robot interaction. Mech. Mach. Theory 2008, 43, 253–270. [Google Scholar] [CrossRef] [Green Version]
- Carolina, P.; Angelika, P.; Martin, B. A survey of environment-, operator-, and task-adapted controllers for teleoperation systems. Mechatronics 2010, 20, 787–801. [Google Scholar]
- Losey, D.P.; McDonald, C.G.; Battaglia, E.; O’Malley, M.K. A review of intent detection, arbitration, and communication aspects of shared control for physical human-robot interaction. Appl. Mech. Rev. 2018, 70, 010804. [Google Scholar] [CrossRef] [Green Version]
- Aslam, P.; Jeha, R. Safe physical human robot interaction-past, present and future. J. Mech. Sci. Technol. 2008, 22, 469. [Google Scholar]
- Li, Y.; Ge, S.S. Human–robot collaboration based on motion intention estimation. IEEE-ASME Trans. Mechatron. 2013, 19, 1007–1014. [Google Scholar] [CrossRef]
- Li, Y.; Ge, S.S. Force tracking control for motion synchronization in human-robot collaboration. Robotica 2016, 34, 1260–1281. [Google Scholar] [CrossRef] [Green Version]
- Sandra, H.; Martin, B. Human-oriented control for haptic teleoperation. Proc. IEEE 2012, 100, 623–647. [Google Scholar]
- Chen, Z.; Huang, F.; Yang, C.; Yao, B. Adaptive fuzzy backstepping control for stable nonlinear bilateral teleoperation manipulators with enhanced transparency performance. IEEE Trans. Ind. Electron. 2019, 67, 746–756. [Google Scholar] [CrossRef]
- Liu, C.; Masayoshi, T. Modeling and controller design of cooperative robots in workspace sharing human-robot assembly teams. In Proceedings of the IROS 2014, Chicago, IL, USA, 14–18 September 2014; pp. 1386–1391. [Google Scholar]
- Zanchettin, A.M.; Casalino, A.; Piroddi, L.; Rocco, P. Prediction of human activity patterns for human-robot collaborative assembly tasks. IEEE Trans. Ind. Inform. 2018, 15, 3934–3942. [Google Scholar] [CrossRef]
- Alexander, M.; Martin, L.; Ayse, K.; Metin, S.; Cagatay, B.; Sandra, H. The role of roles: Physical cooperation between humans and robots. Int. J. Robot. Res. 2012, 31, 1656–1674. [Google Scholar]
- Costa, M.J.; Dieter, C.; Veronique, L.; Johannes, C.; El-Houssaine, A. A structured methodology for the design of a human-robot collaborative assembly workplace. Int. J. Adv. Manuf. Technol. 2019, 102, 2663–2681. [Google Scholar]
- Daniel, N.; Jan, K. A problem design and constraint modelling approach for collaborative assembly line planning. Robot. Comput. Integr. Manuf. 2019, 55, 199–207. [Google Scholar]
- Selma, M.; Sandra, H. Control sharing in human-robot team interaction. Annu. Rev. Control 2017, 44, 342–354. [Google Scholar]
- Mahdi, K.; Aude, B. A dynamical system approach to task-adaptation in physical human-robot interaction. Auton. Robot. 2019, 43, 927–946. [Google Scholar]
- Roberto, C.; Vittorio, S. Rehabilitation Robotics: Technology and Applications. In Rehabilitation Robotics; Colombo, R., Sanguineti, V., Eds.; Academic Press: London, UK, 2018; pp. xix–xxvi. [Google Scholar]
- Colgate, J.E.; Decker, P.F.; Klostermeyer, S.H.; Makhlin, A.; Meer, D.; Santos-Munne, J.; Peshkin, M.A.; Robie, M. Methods and Apparatus for Manipulation of Heavy Payloads with Intelligent Assist Devices. U.S. Patent 7,185,774, 6 March 2007. [Google Scholar]
- Zoss, A.B.; Kazerooni, H.; Chu, A. Biomechanical design of the Berkeley lower extremity exoskeleton (BLEEX). IEEE-ASME Trans. Mechatron. 2006, 11, 128–138. [Google Scholar] [CrossRef]
- Li, Y.; Carboni, G.; Gonzalez, F.; Campolo, D.; Burdet, E. Differential game theory for versatile physical human-robot interaction. Nat. Mach. Intell. 2019, 1, 36–43. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Tee, K.P.; Yan, R.; Chan, W.L.; Wu, Y. A framework of human-robot coordination based on game theory and policy iteration. IEEE Trans. Robot. 2016, 32, 1408–1418. [Google Scholar] [CrossRef]
- Nathanaël, J.; Themistoklis, C.; Etienne, B. A framework to describe, analyze and generate interactive motor behaviors. PLoS ONE 2012, 7, e49945. [Google Scholar]
- Li, Y.; Tee, K.P.; Yan, R.; Chan, W.L.; Wu, Y.; Limbu, D.K. Adaptive optimal control for coordination in physical human-robot interaction. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 20–25. [Google Scholar]
- Kirk, D.E. Optimal control theory: An introduction. In Optimal Control Theory; Dover Publications: Mineola, NY, USA, 2004. [Google Scholar]
- Li, Y.; Tee, K.P.; Chan, W.L.; Yan, R.; Chua, Y.; Limbu, D.K. Continuous role adaptation for human-robot shared control. IEEE Trans. Robot. 2015, 31, 672–681. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D. Reinforcement learning and adaptive dynamic programming for feedback control. IEEE Circuits Syst. Mag. 2009, 9, 32–50. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L. Multi-player non-zero-sum games: Online adaptive learning solution of coupled Hamilton–Jacobi equations. Automatica 2011, 47, 1556–1569. [Google Scholar] [CrossRef]
- Zhang, H.; Wei, Q.; Liu, D. An iterative adaptive dynamic programming method for solving a class of nonlinear zero-sum differential games. Automatica 2011, 47, 207–214. [Google Scholar] [CrossRef]
- Liu, D.; Li, H.; Wang, D. Online synchronous approximate optimal learning algorithm for multi-player non-zero-sum games with unknown dynamics. IEEE Trans. Syst. Man Cybern. Syst. 2014, 44, 1015–1027. [Google Scholar] [CrossRef]
- Albaba, B.M.; Yildiz, Y. Modeling cyber-physical human systems via an interplay between reinforcement learning and game theory. Annu. Rev. Control 2019, 48, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Music, S.; Hirche, S. Haptic Shared Control for Human-Robot Collaboration: A Game-Theoretical Approach. In Proceedings of the 21st IFAC World Congress, Berlin, Germany, 12–17 July 2020. [Google Scholar]
- Turnwald, A.; Wollherr, D. Human-like motion planning based on game theoretic decision making. Int. J. Soc. Robot. 2019, 11, 151–170. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Liu, Q.; Xu, W.; Zhou, Z.; Pham, D.T. Human-robot collaborative manufacturing using cooperative game: Framework and implementation. Procedia CIRP 2018, 72, 87–92. [Google Scholar] [CrossRef]
- Bansal, S.; Xu, J.; Howard, A.; Isbell, C. A Bayesian Framework for Nash Equilibrium Inference in Human-Robot Parallel Play. arXiv 2020, arXiv:2006.05729. [Google Scholar]
- Antonelli, G.; Chiaverini, S.; Marino, A. A coordination strategy for multi-robot sampling of dynamic fields. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 1113–1118. [Google Scholar]
- Yan, Z.; Jouandeau, N.; Cherif, A.A. A survey and analysis of multi-robot coordination. Int. J. Adv. Robot. Syst. 2013, 10, 399. [Google Scholar] [CrossRef]
- Martina, L.; Alessandro, M.; Stefano, C. A distributed approach to human multi-robot physical interaction. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019. [Google Scholar]
- Kim, W.; Marta, L.; Balatti, P.; Wu, Y.; Arash, A. Towards ergonomic control of collaborative effort in multi-human mobile-robot teams. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019. [Google Scholar]
- Starr, A.W.; Ho, Y.-C. Nonzero-sum differential games. J. Optim. Theory Appl. 1969, 3, 184–206. [Google Scholar] [CrossRef]
- Fudenberg, D.; Tirole, J. Noncooperative game theory for industrial organization: An introduction and overview. Handb. Ind. Organ. 1989, 1, 259–327. [Google Scholar]
- Hegan, N. Impedance Control: An Approach To Manipulation: Part I-Theory Part II-Implementation Part III-Applications. J. Dyn. Syst. Meas. Control 1985, 107, 1–24. [Google Scholar] [CrossRef]
- Blank, A.A.; Okamura, A.M.; Whitcomb, L.L. Task-dependent impedance and implications for upper-limb prosthesis control. Int. J. Robot. Res. 2014, 33, 827–846. [Google Scholar] [CrossRef]
- Vogel, J.; Haddadin, S.; Jarosiewicz, B.; Simeral, J.D.; Bacher, D.; Hochberg, L.R.; Donoghue, J.P.; van der Smagt, P. An assistive decision-and-control architecture for force-sensitive hand–arm systems driven by human–machine interfaces. Int. J. Robot. Res. 2015, 34, 763–780. [Google Scholar] [CrossRef]
- Basar, T.; Olsder, G.J. Dynamic Noncooperative Game Theory, 2nd ed.; Society for Industrial and Applied Mathematics; The Math Works Inc.: Natick, MA, USA, 1999. [Google Scholar]
- Shima, T.; Rasmussen, S. UAV cooperative decision and control: Challenges and practical approaches. In UAV Cooperative Decision and Control; SIAM: Philadelphia, PA, USA, 2009. [Google Scholar]
- Hudas, G.; Vamvoudakis, K.G.; Mikulski, D.; Lewis, F.L. Online adaptive learning for team strategies in multi-agent systems. J. Def. Model. Simul. 2012, 9, 59–69. [Google Scholar] [CrossRef]
- Tan, H.J.; Chan, S.C.; Lin, J.Q.; Sun, X. A New Variable Forgetting Factor-Based Bias-Compensated RLS Algorithm for Identification of FIR Systems With Input Noise and Its Hardware Implementation. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 67, 198–211. [Google Scholar] [CrossRef]







© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, R.; Liu, Y.; Zhao, J.; Cai, H. A Framework for Human-Robot-Human Physical Interaction Based on N-Player Game Theory. Sensors 2020, 20, 5005. https://doi.org/10.3390/s20175005
Zou R, Liu Y, Zhao J, Cai H. A Framework for Human-Robot-Human Physical Interaction Based on N-Player Game Theory. Sensors. 2020; 20(17):5005. https://doi.org/10.3390/s20175005
Chicago/Turabian StyleZou, Rui, Yubin Liu, Jie Zhao, and Hegao Cai. 2020. "A Framework for Human-Robot-Human Physical Interaction Based on N-Player Game Theory" Sensors 20, no. 17: 5005. https://doi.org/10.3390/s20175005
APA StyleZou, R., Liu, Y., Zhao, J., & Cai, H. (2020). A Framework for Human-Robot-Human Physical Interaction Based on N-Player Game Theory. Sensors, 20(17), 5005. https://doi.org/10.3390/s20175005