1. Introduction
Recent years have seen the gradual maturing of sensory, machine vision, and control technology in smart robots. Several domestic and foreign studies explored the applicability of robots to sports. KUKA AG Robotics once made a commercial in which one of their robots played table tennis against a human, and Omron once gave a demonstration with one of their suspended robotic arms playing table tennis against a human at an automation exhibition. Table-tennis robots use a wide range of technologies, including object recognition, object tracking, 3D reconstruction, object trajectory prediction, robot motion planning, and system integration. This as well as the fact that they are easy to showcase attracted the attention of many researchers.
A ping-pong ball trajectory system combines vision, 3D space, and prediction algorithms, none of which are dispensable. The vision system must be able to detect and position the ball [
1,
2]. The data captured by cameras are two-dimensional (2D), so three-dimensional (3D) data cannot be derived by simply searching for the locations of object pixels. Wei et al. [
3] proposed a method that uses a single camera to calculate object positions. In addition to using image recognition to locate the current pixels of the ball, they also used the shadow of the flying ball on the table to triangulate the spatial location of the ball. However, it is difficult to detect the shadow of a sphere, and the sources of light in general environments are complex and unpredictable. Their proposed approach was only useful if there was only a single clear light source in the environment with no sunlight or other light sources. The installation of two or more cameras can be used to establish stereopsis. Detection of an object from multiple perspectives can increase the dimensions of the image data and enable simple calculations of 3D data. Refs. [
4,
5] both adopted two cameras to track the ball in their vision system. To increase the visual coverage and accuracy of the vision system, Chen et al. [
6] installed two high-speed cameras above the robot and above the opponent, which amounted to four cameras covering the entire table. Yang et al. [
7] used six cameras to cover the table (three on each side) to achieve high precision for every possible location of the ball.
The processing speed of the vision system is another key factor because it indirectly affects prediction of the direction of the ball, particularly in prediction methods using physical models. Liu [
8] proposed an onboard stereo camera system to estimate ping-pong ball trajectories in real time under the asynchronous observations from different cameras. Graphics processing units (plGPU) have become popular computer components in the recent trend of deep learning in image classification because they make the graphics card less dependent on the central processing unit (CPU) and improve the performance of graphics computing. Lampert et al. [
9] employed an NVIDIA GeForce GTX280 graphics card and a CUDA framework to accelerate image processing and used four cameras to establish 3D space. Their system needed only 5 ms to process a 3D location. Furthermore, German company Nerian launched a real-time 3D stereo vision core that uses a field-programmable gate array (FPGA) as the hardware for parallel computation [
10]. It can complete more tasks per clock cycle, send the computation results to a personal computer, and presents good performance in object recognition and 3D computation. Several studies used camera arrays to realize high-speed real-time object tracking and trajectory prediction. Zhang et al. [
11] used a total of three cameras, one of which was a pan-tilt camera with a resolution of 640 × 480 pixels; its sampling frequency could reach less than 5 ms, and it could simultaneously follow a flying ball and analyze its status.
Accurate prediction of the ball trajectory is vital to the capacity of the robot to hit the ball. Existing prediction methods can be divided into two categories: physical models and machine learning. Physical models assess the external forces affecting the trajectory of the ball, such as constant gravity and air resistance. Balls with self-rotation are subject to a lateral force perpendicular to the plane formed by the angular velocity vector and the motion velocity vector of the rotation. This force, known as the Magnus effect, causes deflection in the flight trajectory of the ball. Ping-pong balls are not heavy, so the deflection is greater than that it would be with heavier objects [
12,
13]. Wang et al. [
14] proposed a physical model to predict ball trajectories of topspin, backspin, rightward spin, leftward spin, and combined spin. Huang et al. [
15] proposed a physical model that considers the self-rotation of the ball. It uses a real-time vision system to obtain a series of trajectory points and a camera system combining DSP and FPGA and fits the 3D data into a quadratic polynomial, which is then used to obtain the current flying velocity. In their experiments, their proposed method had good predictive abilities when the sampling time was 1 ms. However, if the consecutive trajectory points were not dense enough or if the sampling frequency was too low, the accuracy of current velocity estimates is affected. Inputting these estimates into complex formula calculations would then increase distortion in the final results. Zhang et al. [
11] used two high-resolution cameras to analyze the self-rotation of the ball. Zhao et al. [
16] used an ultrahigh-speed camera to analyze the collision between a ping-pong ball and the table and developed a physical model for self-rotation and collision effects. Ball status estimates can also be obtained using various filters, such a fuzzy filter [
17], an extended Kalman filter [
18], and an unscented Kalman filter [
19]. Other studies presented analyses of the aerodynamics and the friction between ping-pong balls and tables [
20,
21].
Machine learning has also tended towards table-tennis research in recent years. Some of the table-tennis robots developed in these studies employed locally weighted regression algorithms to learn hitting movements [
22,
23]. In machine learning algorithms, machines analyze data to find regularities and then use the regularities to make predictions of unknown data. Zhao et al. formulated the likelihood of ping-pong ball motion state as a Gaussian Mixture Model (GMM) [
24]. Deng et al. [
25] proposed a ball-size likelihood to estimate the ball position. Payeur et al. [
26] used an artificial neural network (ANN) to learn and predict the trajectories of moving objects; however, they merely performed simulation experiments of simple trajectories and did not develop a novel vision system or robot. Nakashima et al. Nakashima et al. [
27] used a back-propagation artificial neural network (BPANN) to learn striking points. The inputs are the initial location and velocity difference of the ball in a free-fall model, and the outputs are the striking point and displacement between striking points estimated using simple physics. Although their simulation results were good, the model requires 20 trajectory points for fitting, which implies that the sampling frequency of the vision system must be high. Zhang et al. [
3] also made an attempt with four initial trajectory points and time stamps as the inputs of the network and the location and velocity of the striking point as the outputs.
Our objective is to track and predict ping-pong ball trajectories for a robot to hit the ball. Due to the facts that physical models for ball flight prediction require advanced vision equipment and that most physical models are fairly complex, we adopted machine learning to achieve prediction of ping-pong ball trajectories with limited equipment. To achieve better prediction, this study included a ball tracking system, 3D reconstruction, and ball trajectory prediction. The novelty of this work is that the flight trajectory between the serving point and the end of the robotic arm was viewed as two parabolas and two separate ANNs were used to learn these two parabolas. The ball trajectory prediction strategy proposed in this study makes the following contributions:
We propose an ANN-based approach to learn historical trajectory data, thereby doing away with the need for a complex flight trajectory model.
The proposed method can swiftly predict where the robot should strike the ball based on the ball location data from only a few instants after it is served, thereby giving the robot time to react.
The inputs of ANNs are generally accompanied by time stamp data. We verified that removing the time stamp data reduces the parameter demand of the entire network and greatly shortens network training time.
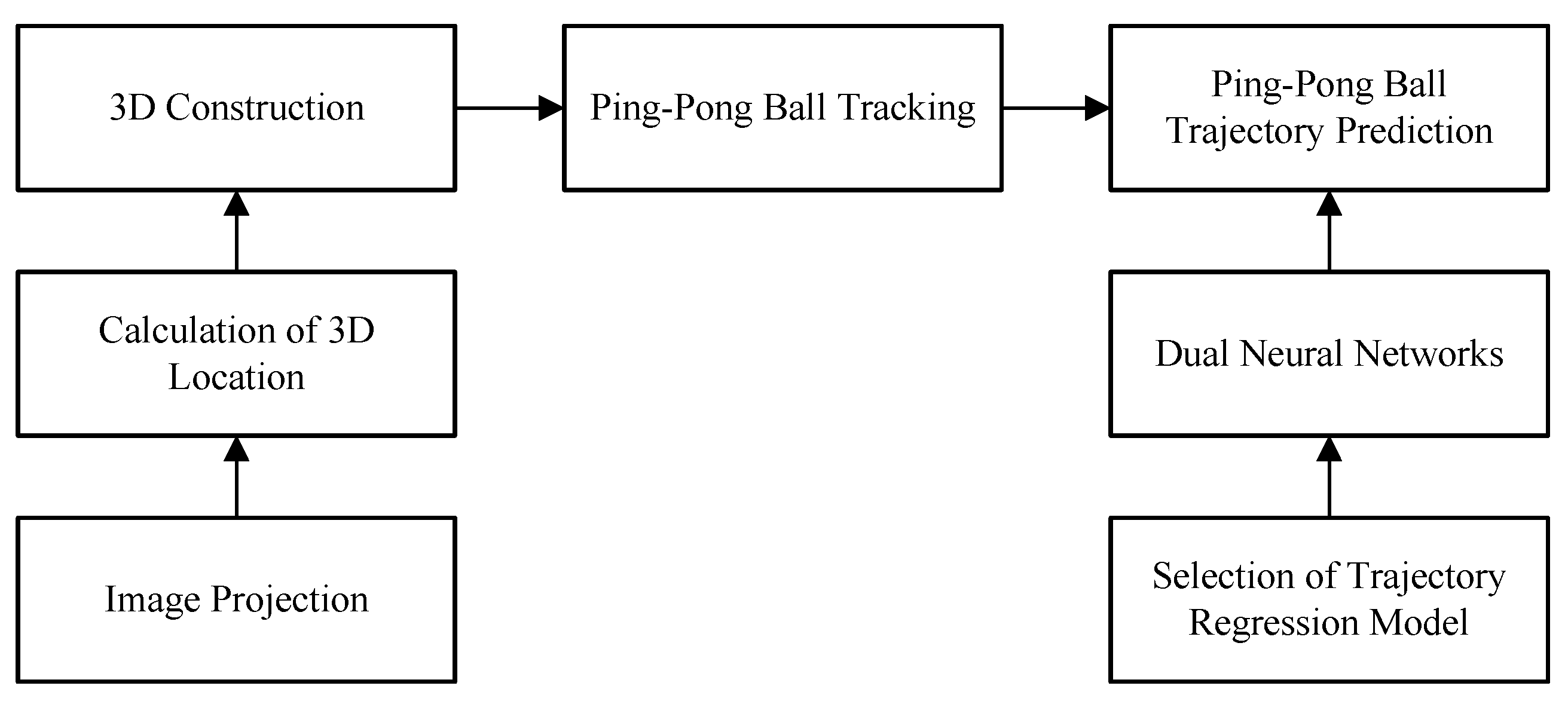
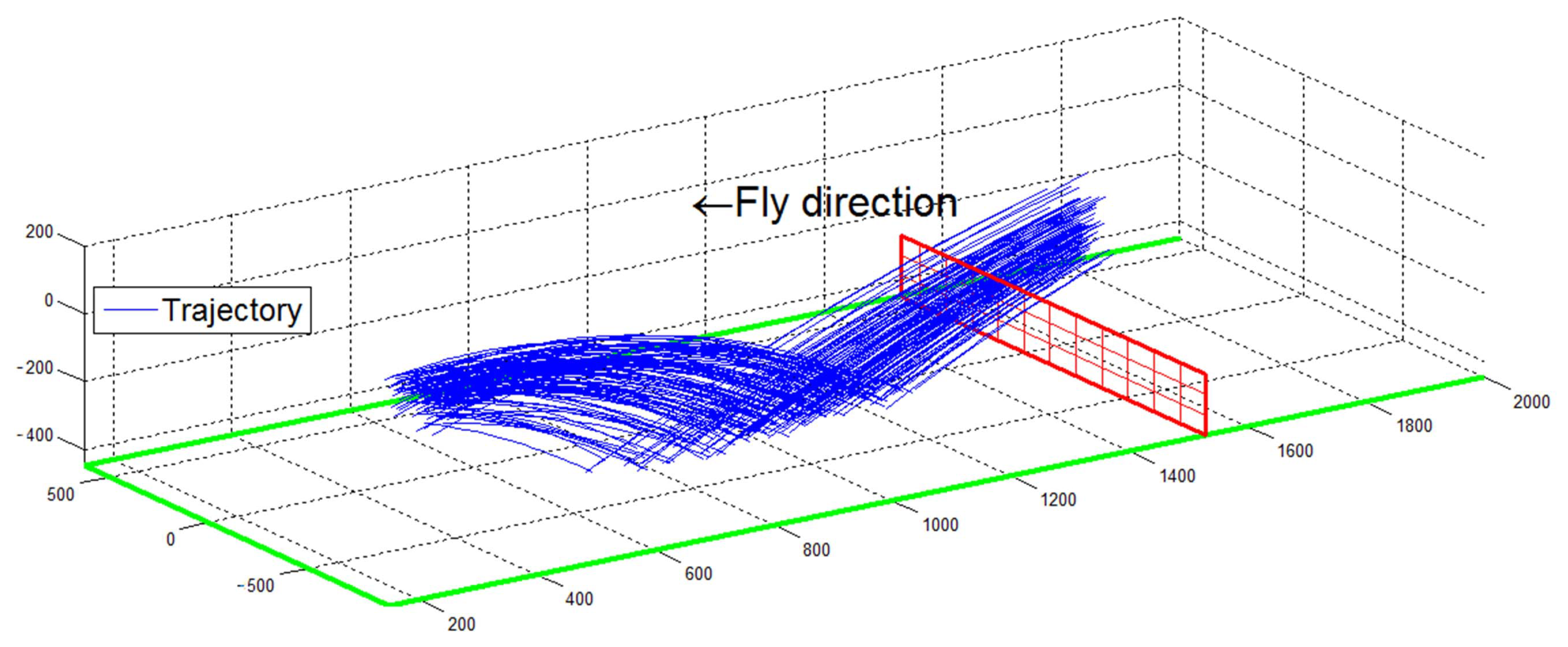
Figure 1 shows the flow of the proposed method. There are three main parts: 3D construction, ping-pong ball tracking, and ping-pong trajectory prediction. 3D construction and ping-pong ball tracking are used to obtain the accurate ball current position. To hit the ball, we propose the dual neural networks to predict the ball position on the hitting plane. These three parts are explained in
Section 2.
The remainder of this paper is organized as follows.
Section 2 introduces the framework for 3D reconstruction, and
Section 3 explains the ball trajectory prediction method proposed in this study.
Section 4 presents the experiment results, and
Section 5 contains our conclusion.
3. Ping-Pong Ball Trajectory Prediction
If a table-tennis robot wants to hit the ball, it must be able to accurately predict where the ball is flying. When people play table tennis, the ball is subjected to various external forces that impact its flight direction and velocity, including air resistance, the Magnus effect, gravity, and the rebound force of collision. Thus, calculating the various physical forces with precision and then predicting the flight trajectory is difficult. In this section, we present a machine learning approach that enables robots to predict trajectories. In this section, we demonstrate that the coefficients of a polynomial regression model are advantageous to represent and predict ball trajectories.
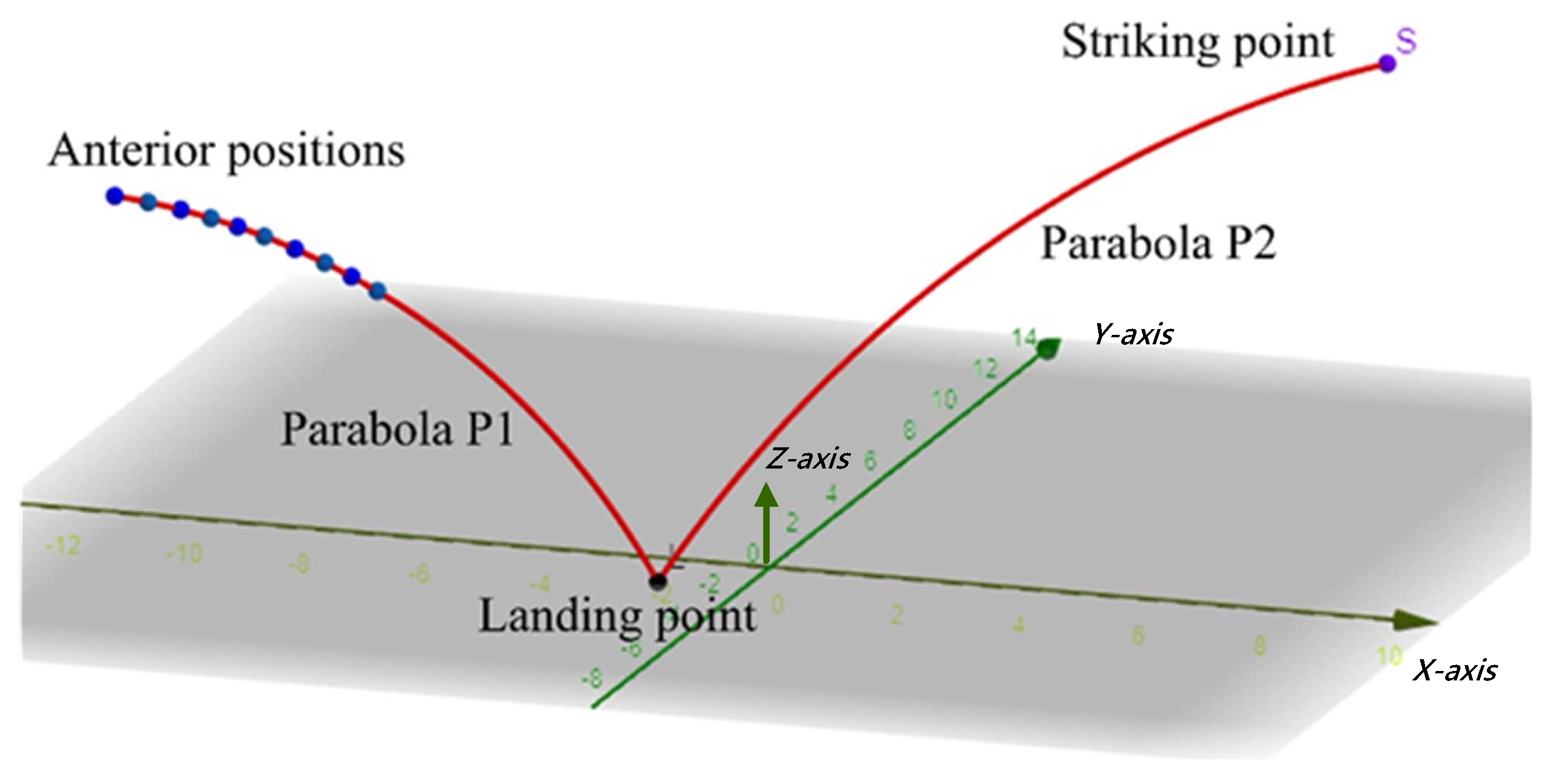
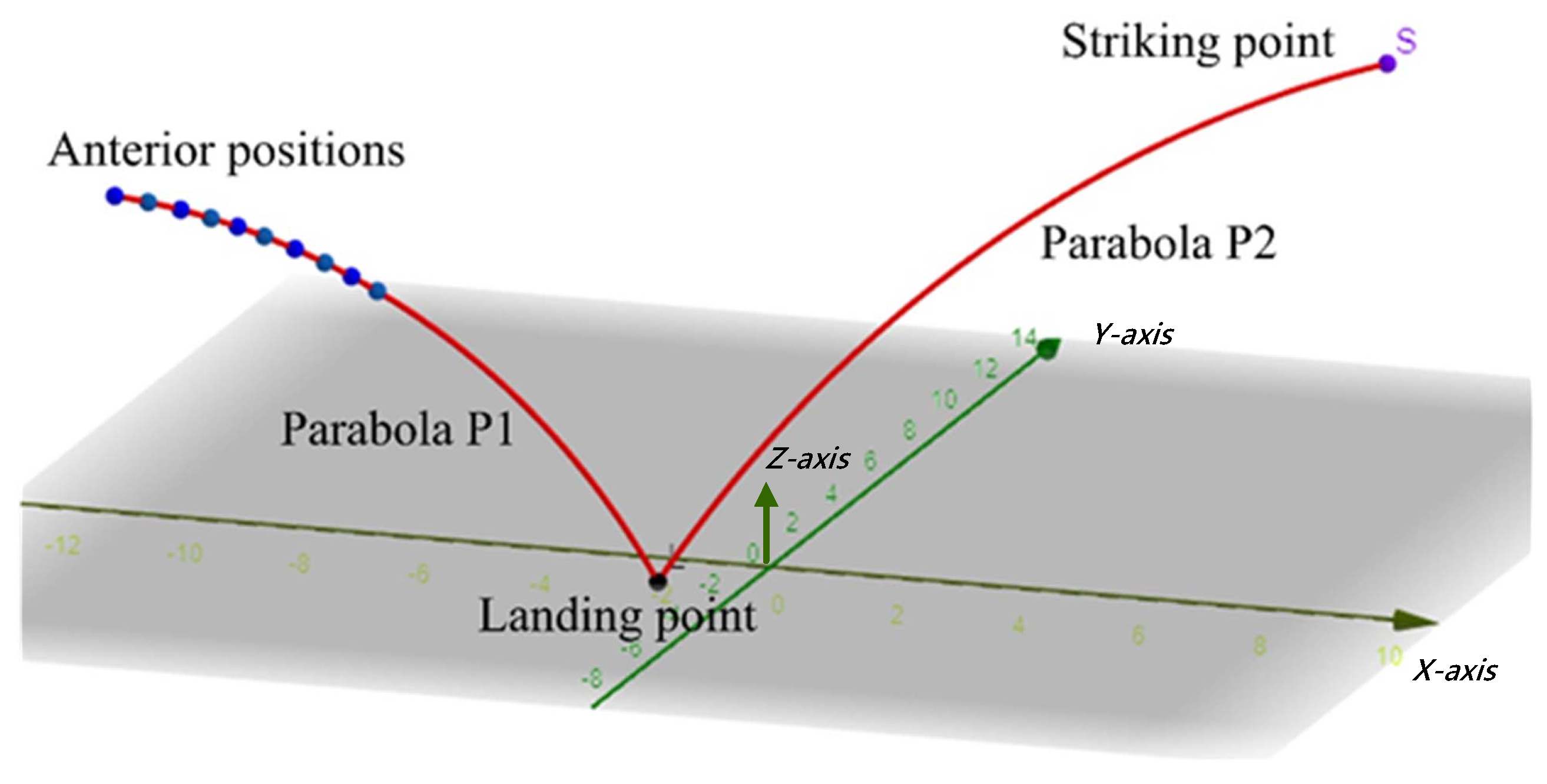
Figure 10 shows the flight trajectories of a ping-pong ball. The flight trajectories are divided into two parabolas P1 and P2. The first ANN is responsible for learning the parabola P1 in the figure, with the anterior positions as the input and the regression coefficient of P1 as the output. The second ANN learns parabola P2, with the regression coefficient of P1 as the input and the regression coefficient of P2 as the output. The trajectory coefficients above are the parameters of their mathematical expressions. Once the vision system detects the anterior positions, the system will immediately derive the coefficient P2 of the trajectory after the ball’s landing point on the table and then calculate a designated striking point. Suppose
,
, and
denote the mathematical regression formulas of trajectory P2 along the
x,
y, and
z axes. Using
, the timing
t of the designated striking point (
x axis) is first derived. The resulting
t is then substituted into
and
to obtain the
y and
z coordinates of the striking point.
Since the regression model should be chosen to predict the ball trajectory, we evaluate several models such as exponential, Fourier, Gaussian, and polynomial curve fitting methods in
Section 3.1. The result shows that polynomial curve fitting is the most suitable model to predict the ball trajectory. In
Section 3.2, we also theoretically verify the existence of the relationship between the polynomial coefficients and ball trajectory. However,
Section 3.2 shows that curve fitting is highly sensitive to noise in the input data. Thus, we propose two ANNs to model the relationship in
Section 3.4.
3.1. Selection of Trajectory Regression Model
The data of any parabolic trajectory include time stamps and location data. Thus, we must decide which type of regression model to use to express the trajectory data. This process mainly involves finding the relationship between a set of independent and dependent variables and then establishing an appropriate mathematical equation, which is referred to as a regression model. Below, we investigate which type of regression model is more suitable for the trajectory data.
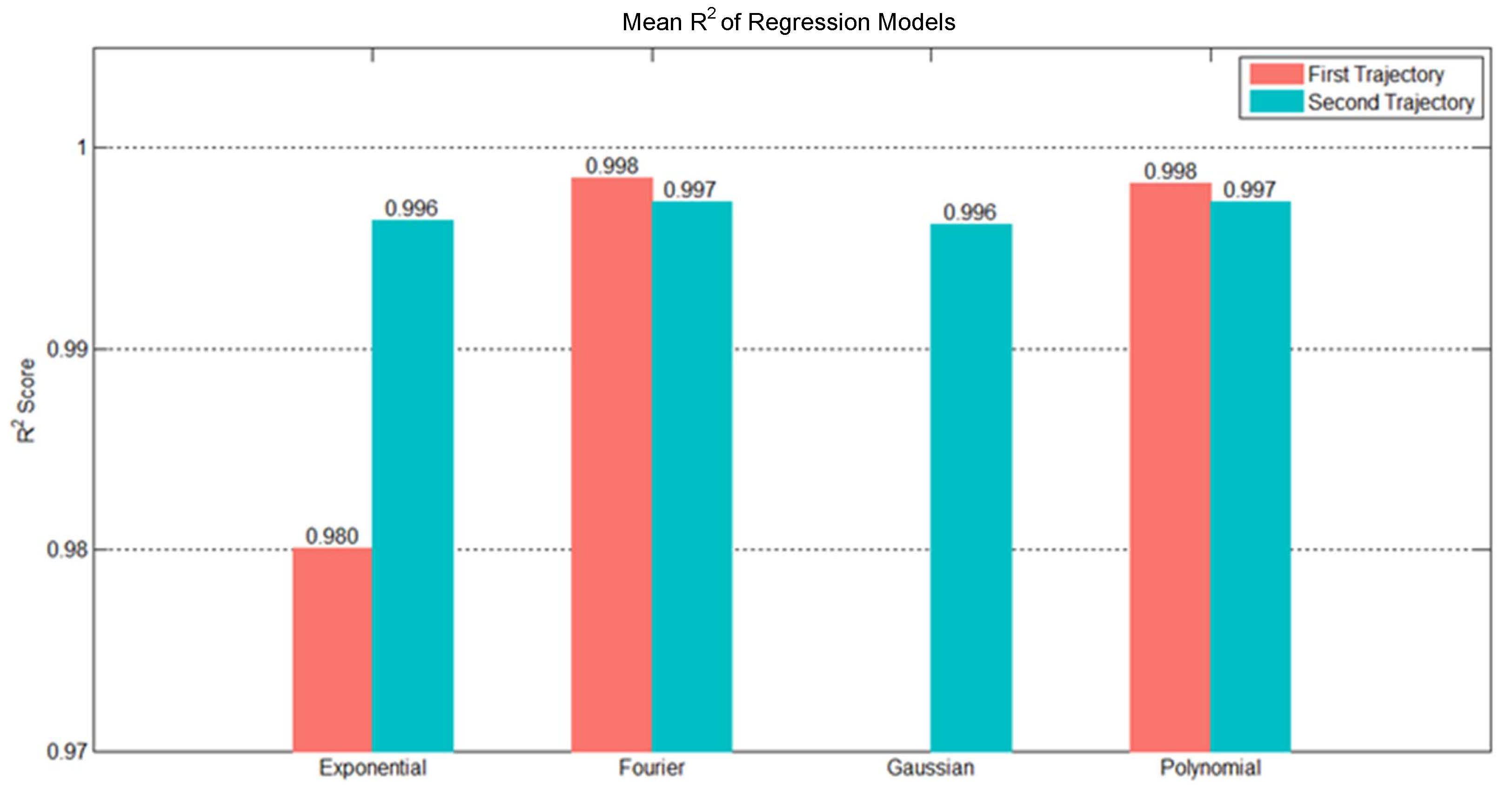
We can use experiment data to determine a minimal number of parameters of suitable regression models. The experiment data comprised 10 random trajectories selected from the training data. Each flight trajectory consists of two parabolic trajectories: the first from the initial point to the landing point and the second from the landing point to the end point. We fitted the two trajectories using four types of regression models, namely, Gaussian, exponential, Fourier, and polynomial, and examined their results. We selected 10 random trajectories from the testing data to test
results of these models. The red and blue bars in
Figure 11 indicate the mean
results. The Fourier and polynomial regression models presented reasonable
results for both trajectories, and their test results were close to each other. However, the polynomial regression model used three parameters, whereas the Fourier regression model used four parameters. With our objective of minimizing the number of parameters, we ultimately chose the polynomial regression model to express the flight trajectory data. The polynomial regression model for the Z axis used three parameters, which was the quadratic polynomial. For the
X and
Y axes,
Figure 12 shows
of each trajectory and the average
of the 10 random trajectories was 0.9903 using the first-order polynomial, which was close to 1. Thus, the
X and
Y axes were represented by the first-order polynomial regression.
3.2. Theoretical Verification of Trajectory and Polynomial Coefficients
When the two parts of the ping-pong ball trajectory can be fitted using a polynomial, it means that the coefficients in the polynomial effectively express the trajectory. We could therefore use ANNs to predict the polynomial coefficients of the ball trajectories. The polynomial coefficients and conversion relations between trajectories can be expressed using Equation (
13). Suppose that (
,
) is several sets of data points where
,
is the time value, and
is the positional value. Here there exists a unique polynomial
using the
order. Equation (
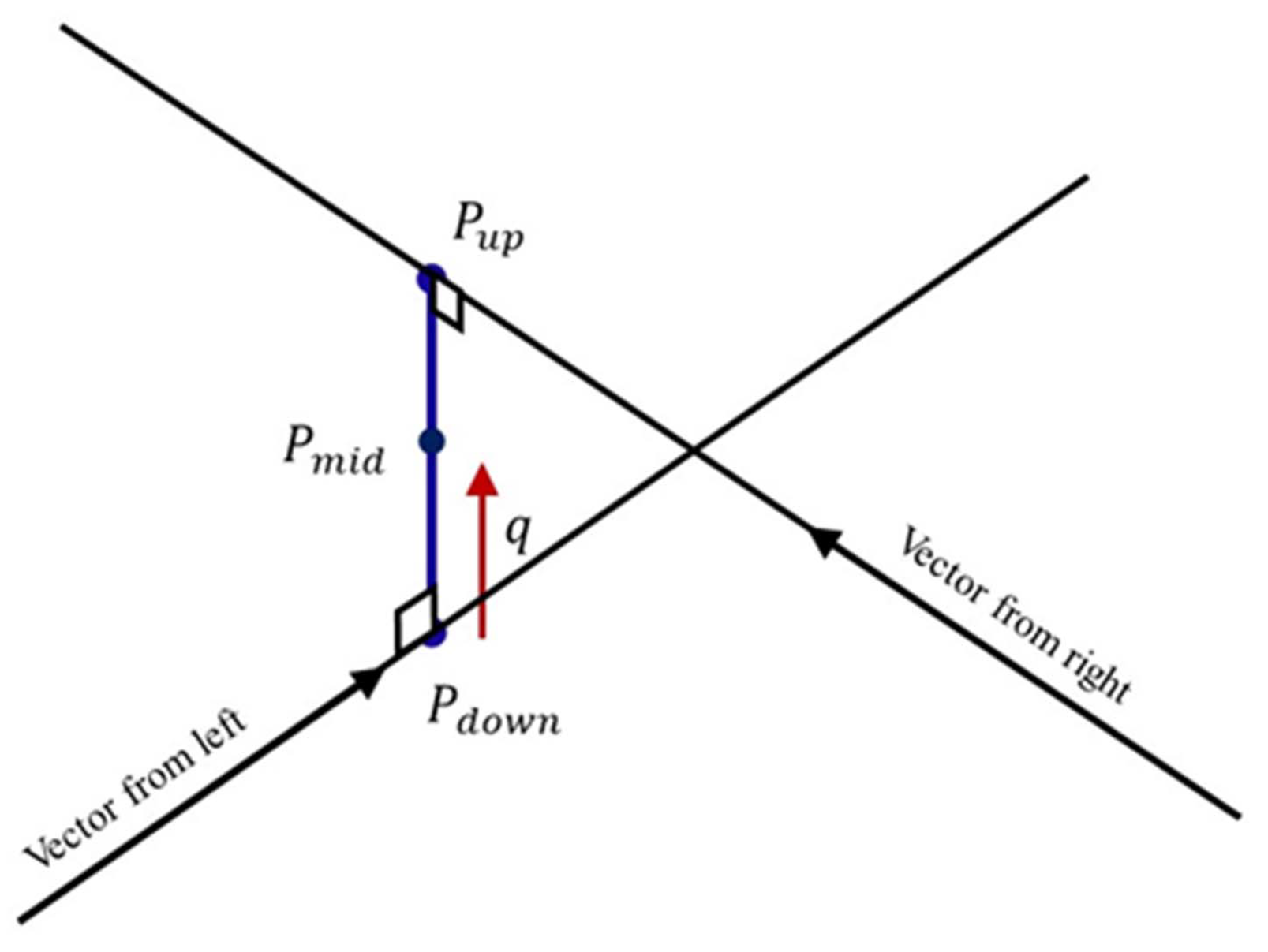
14) establishes the relation matrix pf vectors
q and
a, which is known as the Vandermonde matrix
T [
29]. Using the pseudo inverse matrix of
T, Equation (
15) gives coefficient a where a minimum squared-error exists between the coefficient equation and the trajectory data.
The input and output data of ANNs must be interrelated in a certain way; otherwise, training the model may be too time-consuming, or poor prediction results may be produced. To verify that the use of ANNs to learn trajectories in this study is appropriate. Based on this mathematical theory, the trajectory point data can be mapped onto polynomial coefficient data using the Vandermonde matrix. Thus, a corresponding relationship exists between the elements of these two sets of data. When the trajectory points serve as the inputs of the ANN and the trajectory coefficients are the outputs, then the model has good learning ability.
3.3. Comparison of Artificial Neural Network and Polynomial Curve Fitting Predictions
In the prediction procedure of this study, once the vision system receives the data from a few anterior positions, the ANN of the first trajectory can then predict the first trajectory. To demonstrate the inadequacy of curve fitting and the prediction performance of the ANN for the first trajectory, we predicted the landing point of the first trajectory using the proposed method and a quadratic polynomial resulting from curve fitting. We used 30 items of data to train the ANN for the first trajectory and used the trained ANN and the ten anterior positions in the trajectory to predict the polynomial parameters of the first trajectory. The red circles and crosses in
Figure 13 show the trajectory obtained during testing. The blue curve presents the polynomial trajectory output by the trained ANN, and the green curve shows the subsequent trajectory trend after the data from the ten anterior positions were received. The mean error and standard deviation of the quadratic polynomial were 19.2 mm and 11.8 mm, respectively; however, for the ANN, the mean error and standard deviation of the quadratic polynomial were 10.8 mm and 10.0 mm, respectively. The errors in the landing point predictions of the ANN were smaller than those of the quadratic polynomial. Once some errors exist in capturing the ten anterior positions of the ball,
Figure 13 shows that the ANN is resistant to noise; even if an input node contains noise or its data is incomplete, the single data does not greatly impact the overall result.
3.4. Two ANNs in Trajectory Prediction
Three things can be obtained from a complete flight trajectory: the trajectory before landing, the trajectory after landing, and ten anterior positions.
Figure 14 displays the procedure of generating the required training data. First, the lowest point in the overall trajectory along the
z axis is identified, demarcating the data of the first and second trajectory. The first trajectory is between the initial point and the lowest point, and the second trajectory is between the lowest point and the end of the trajectory. Both trajectories are then expressed using polynomial regression to extract the trajectory parameters and the data of the ten anterior positions. The data of the ten anterior positions and the parameters of the first trajectory then serve as the training data for the first ANN (Network Model 1), and the parameters of the first and second trajectories serve as the training data for the second ANN (Network Model 2).
We defined the 3D polynomial of the first trajectory as Equation (
18), where
,
,
,
,
,
,
are the
X-,
Y-, and
Z-axis coefficients of the first trajectory. We defined the 3D polynomial of the second trajectory as Equation (
21), where
,
,
,
,
,
,
are the
X-,
Y-, and
Z-axis coefficients of the second trajectory. Equations (
22) and (
23) are the corresponding inputs and outputs of the two networks.
5. Conclusions
This study developed a ping-pong ball trajectory prediction system that included ball recognition, 3D positioning, and ball trajectory prediction. Trajectory prediction performance is key to whether a table-tennis robot can hit the ping pong ball. However, most existing studies developed physical models for prediction, which can only achieve good prediction effects if they have high-frequency vision systems to analyze ball status in real time. Such advanced equipment is not readily accessible and makes it difficult to conduct fundamental studies. We therefore adopted machine learning to predict the flight trajectories of ping-pong balls, which uses historical data to learn the regularities within. There is no need to establish a complex physical model, and fairly good prediction results can be achieved even with general industrial cameras readily available on the market. Each complete flight trajectory consists of a landing point on the table and two parabolic trajectories. We used two ANNs to learn the features of these flight trajectories. The first ANN learns the first flight trajectory. Once the vision system receives the anterior positions, it can instantly predict the first trajectory. We demonstrated that this approach was superior to curve fitting due to the limited amount of data and noise filtering capabilities. The second ANN learns the second flight trajectory. Once the first trajectory is known, the second flight trajectory can be instantly predicted. The two ANNs were then combined.
A comparison of the ANN and curve fitting approaches revealed that the use of data from ten anterior positions resulted in mean errors of 10.8 mm in the prediction results of the ANN and 19.2 mm in those of the quadratic polynomial resulting from curve fitting. We conducted a simulation experiment using 200 real-world trajectories as training data. The mean errors of the proposed dual-network method and a single-network model were 39.6 mm and 42.9 mm, respectively, and the mean success rates were 88.99% and 86.66%. These results indicate that the prediction performance of the proposed dual-network method is better than that of the single-network approach. We also used a simple physical model to predict striking points. We employed 330 real-world trajectories, and the resulting mean error and success rate were 57.9 mm and 70%. The success rate of 70% of the physical model was worse than 97% of the proposed dual-network method. In the proposed dual-network method, the inputs of the first ANN include time stamps. As our vision system takes samples at fixed time intervals, little variation exists in the time stamp data. We thus tried removing the time stamps from the data. We used 330 trajectories for training. The mean errors of the proposed method with and without the time stamps were 27.5 mm and 26.3 mm, and the mean success rates were 98.67% and 97.33%. The results show that even without the time stamps, the proposed method maintains its prediction performance with the additional advantages of 15% fewer parameters in the overall network and 54% shorter training time. Finally, we tested the striking ability of our robot arm, which produced a mean error and standard deviation of 36.6 mm and 18.8 mm, respectively.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}