1. Introduction
Traditional clustering methods [
1,
2,
3,
4] usually use a single view to measure the similarity of samples. With the rapid progress of data collection, individual features are not enough to describe data points. Multiple views usually contain supplementary information, which may be beneficial to explore the basic structure of the data. With the development of information technology, data mining and other technologies, many datasets in the real-world can be presented from different perspectives, called multi-view data. For example, the same text can be expressed in various languages. In biometric recognition scope, faces, fingerprints, palm prints and iris could form the different views of multi-view data. In the field of medical diagnosis, different examinations of patients can be regarded as different views. Multi-view data could provide sufficient information than the traditional single feature representation in revealing the underlying clustering structure. Furthermore, distinct views contain specific information of intra-view and complementary information of inter-view, which are negotiated with each other to boost the performance of clustering [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14].
Based on different mechanisms, we can divide the existing multi-view clustering methods into four categories. The first category methods refer to multi-kernel clustering. These methods usually combine multiple pre-defined kernels to reach optimal clustering results [
12,
15,
16,
17]. The second kind of approach is co-training and co-regularized [
18,
19]. They iteratively learn multiple clustering results that can provide predicted clustering indices for the unlabeled data from different views. In this way, the clustering results are forced to be consistent across views. The third strategy collaboratively transforms the multi-view information into a compact common binary code space. Then, the clustering process is measured in the Hamming space and enjoys superior algorithm acceleration [
20,
21]. The last mechanism is the subspace-based multi-view clustering method. It assumes that high-dimensional data points are drawn from various low-dimensional subspaces, and each cluster can be drawn from one of the subspaces [
22,
23,
24,
25]. The essential idea is to find several low-dimensional representations embedded in latent spaces and finally attain a united representation for downstream clustering tasks [
26]. Besides, aiming at finding a shared low-dimensional latent representation via matrix decomposition, the non-negative matrix factorization (NMF) [
27]-based multi-view clustering methods [
28,
29,
30,
31] can also be seen as a branch of the subspace-based multi-view clustering method.
Although the algorithms mentioned above have achieved great success in different scenarios, these traditional multi-view clustering algorithms cannot effectively deal with multi-view data with incomplete features. Therefore, the incomplete multi-view clustering algorithms [
32,
33,
34] have attracted extensive attention. To the best of our knowledge, existing incomplete multi-view clustering algorithms can be classified into two categories: non-negative matrix factorization based methods and graph-based methods. The NMF-based methods aim at directly obtaining a common low-dimensional representation through non-negative matrix decomposition. Most of them take the strategy of combining view-specific and common representations into a unified one [
35,
36,
37]. Another representative approach of the NMF-based method is to fill the missing data with average feature values and then use the weighted non-negative matrix factorization to reduce the impact of the missing samples [
38]. These NMF-based methods can directly obtain a consistent representation with incomplete samples. However, it is limited to the following two points: (1) when the number of views is more than two, the common parts of views will be significantly reduced and cannot be learned a shared representation between views; (2) NMF-based methods usually neglect the intrinsic structure of data, resulting in an uncompacted representation.
The graph-based incomplete multi-view clustering algorithms are more effective in exploring the geometric structure of data than NMF-based methods. The construction of the graph is essential for the success of clustering. However, it is impossible to construct a complete graph connecting all samples due to the lack of partial samples in incomplete multi-view clustering. To cover this problem, Gao et al. [
39] first fill the missing parts and then learn graphs and representations. Zhao et al. [
36] utilize NMF to obtain consistent representations to guide the generation of graphs with local structures. However, when the missing rate is high, the filling strategy will dominate the learning of the representation, resulting in the filled samples being connected with each other. Moreover, information fusion refers to fusing multiple sources to achieve consistency. In this stage, multiple views are treated equally, which is unreasonable in real applications.
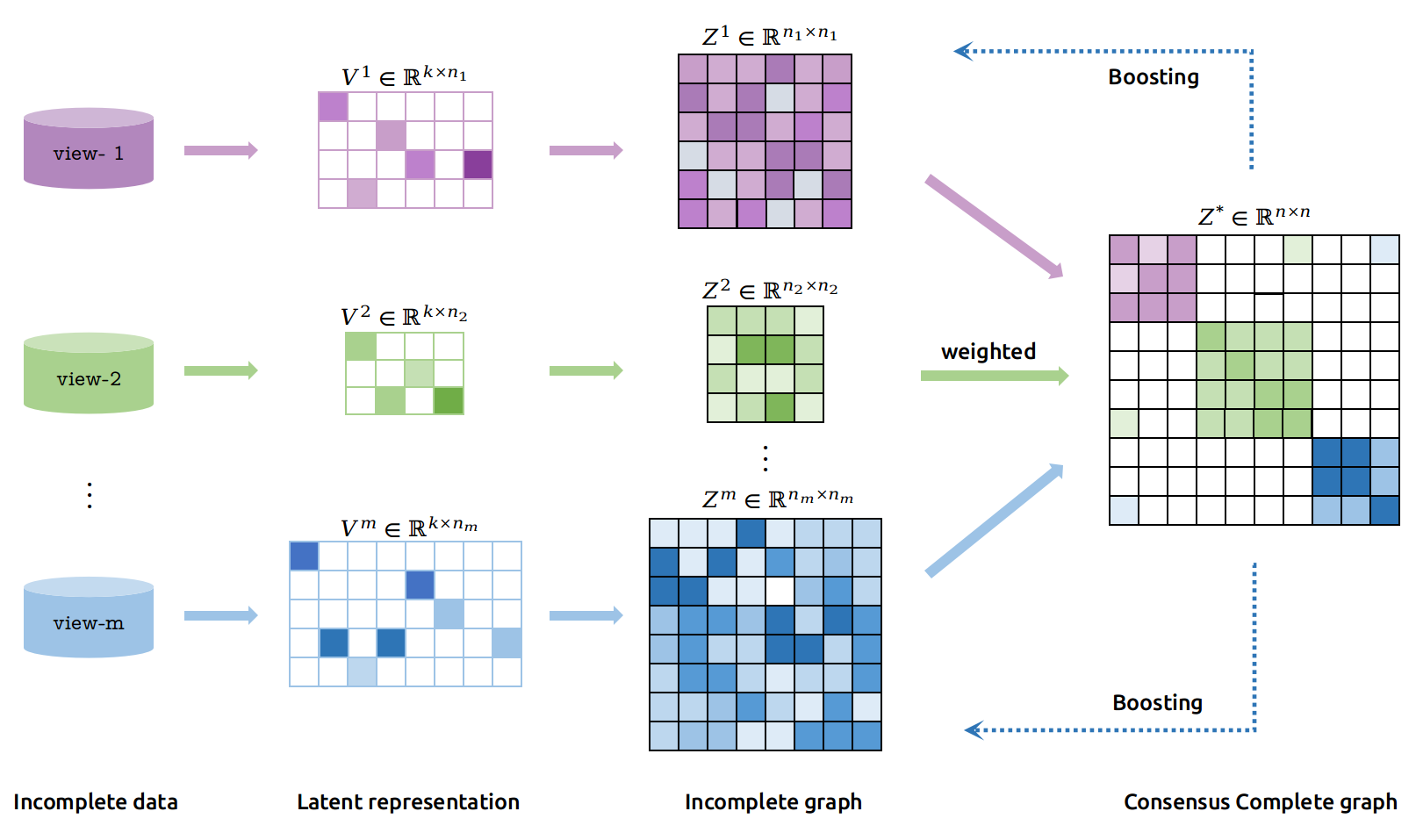
To address the above issues, we propose a novel incomplete multi-view clustering method, constructing the graphs between instances in the latent embedding subspace. In this manner, we can deal with multi-view data with any number of views. Furthermore, an adaptive weighted mechanism is induced to fuse the graphs with local-structure into a complete graph.
In this manner, we establish a relation between missing and unmissing samples. An additional sparse regularization term is imposed on the consensus complete graph to eliminate the adverse effects of inconsistency between views and noise or outliers from each view. Specifically, the framework of this paper is illustrated in
Figure 1.
Compared with existing methods, the proposed adaptive weighted graph fusion incomplete multi-view subspace clustering (AWGF-IMSC) algorithm has the following contributions:
It induces the similarity graph fusion after obtaining latent spaces to extract the local structure of inner views. By virtue of it, noise existing in the original space can be eliminated in latent space and contribute to better graph construction.
It incorporates relations between missing samples and complete samples into the complete graph. The sparse constraint imposed on the complete graph improves the view-inconsistency and reduces the disagreements between views, making the proposed method more robust in most cases.
The importance of each view is automatically learned and adaptively optimized during the optimization. Consequently, the important view has strong guidance in the learning process. Moreover, there is no limitation to the number of views in our approach. The proposed method is applicable to any multi-view datasets.
The rest of the paper is organized as follows. The next
Section 2 denotes the notations and symbols used in this paper.
Section 3 introduces methods mostly related to our work. The proposed algorithm and its optimization process are formulated in
Section 4. Besides, we also give the analysis of convergence and complexity of the proposed algorithm in this part. Extensive experiment results and analysis are shown in
Section 5, before conclusion and prospectives.
2. Notation
For clarity, we give the notation used throughout the paper at the beginning. We use bold letters to represent matrices and vectors. For matrix , and represent its j-th column and element, respectively. , and denote the transpose, trace and the inverse operations on matrix , respectively. denotes the Frobenius norm. The norm is denoted as . Moreover, operator turns the negative elements in matrix to 0 while maintaining the non-negative elements, and vice versa. For multi-view datasets , the superscript represents the i-th view. In individual , each column indicates an instance. N is the number of the samples and represents the feature dimension of corresponding i-th view.
3. Related Work
In this section, we will present the work most relevant to the proposed method, i.e., semi-non-negative matrix factorization and subspace learning.
3.1. Semi-Non-Negative Matrix Factorization for Single View
Non-negative matrix factorization (NMF) is a significant branch in the field of matrix factorization. NMF aims at finding two non-negative matrix
and
to roughly approximate the original data matrix, i.e.,
. Since many real-world datasets are usually high-dimensional, the NMF methods have been widely applied in image analysis [
40], data mining, speech denoising [
41] and population genetics, etc. The semi-NMF [
42] is an extension of traditional NMF, which only requires the coefficient matrix to be non-negative. Specifically, given the data matrix
, the semi-NMF utilizes the base matrix
and the non-negative coefficient matrix
to approximate the matrix
:
.
Ding et al. [
42] further propose an iterative optimization algorithm to find the local optimal solution. The updating strategy can be concluded as follows:
With being fixed, can be updated by
With being fixed, can be updated by
The positive and negative elements of matrix are denoted as and . And they hold on the property .
NMF and semi-NMF methods are also employed universally in multi-view clustering. Many of the multi-view clustering (MVC) methods utilize NMF to reduce dimension on each view or directly reach a consistent latent presentation [
28,
43]. Especially in the incomplete multi-view scenario, NMF and semi-NMF play significant roles in achieving a consistent representation from different incomplete views. Li et al. [
35] learn a shared representation for the paired instances and view-specific representations for unpaired instances via NMF. The complete latent representation can be attained by combining shared and view-specific representations. The method in [
44] utilizes weighted semi-NMF to reach a consensus representation. Then, the
norm regularized regression is imposed to align the different basis matrices. Although these NMF-based methods could learn a consensus representation from the incomplete views, the number of views and the absence of local structure limit their performance.
3.2. Subspace Clustering
Subspace clustering is an extension of the traditional clustering method which aims at grouping data in different subspaces [
45,
46]. The self-representation property [
47] of subspace clustering aims to represent data points by the linear combinations of themselves. The formulation can be expressed as:
where
is the original data,
is the self-representation coefficient matrix, with each column being a new representation for corresponding data point.
is a trade-off parameter. Since
reflects the correlations among samples, it can be regarded as a graph and then we can perform spectral clustering algorithm on it to get the final clustering result.
3.3. Incomplete Multi-View Spectral Clustering with Adaptive Graph Learning (IMSC-AGL)
In paper [
48], a novel graph-based multi-view clustering method is proposed to deal with incomplete multi-view scenarios termed incomplete multi-view spectral clustering with adaptive graph learning (IMSC-AGL). IMSC-AGL optimizes the shared graph from the low-dimensional representations individually formed by each view. Moreover, a nuclear-norm constraint is introduced to ensure the low-rank property of the ideal graph. The mathematical formulation can be written as,
where
represents the complete samples in
v-th view.
denotes the respective
-th view’s graph.
represents the clustering indicator matrix with proper size. Moreover,
refers to the final shared clustering indicator matrix. Although IMSC-AGL achieves considerable performance in various applications, it can still be improved from the number of hyper-parameters and considering to fuse multiple information in a weighted manner.
4. Method
4.1. Adaptive Weighted Graph Fusion Incomplete Multi-View Subspace Clustering
In this section, we present our adaptive graph fusion incomplete multi-view subspace clustering method (AWGF-IMSC) in detail and give a unified objective function.
For incomplete multi-view data, we remove the incomplete instances and reform as
, where
and
represent the feature dimension and the numbers of visible samples of
i-th view, respectively. We assume that semi-NMF factorizes the input data
into base matrix
and coefficient matrix
.
k is the dimension of target space and is commonly set to the number of the clusters of
. Considering that the missing samples differ in each view, we learn latent representations of the corresponding visible samples in each view. Therefore, the semi-NMF for individual view can be formulated as:
To further exploit the intra-view similarity structure and the underlying subspace structure, we utilize the self-representation property [
47] on the
dimensional latent representation
to construct the graph. Thus, we can obtain the different graphs
of individual views by solving the following problem:
where the constraint
and
guarantee a good probabilistic explanation for
. After obtaining the graphs on each view, the natural idea is to integrate the multiple incomplete information into a complete one. In order to establish the correspondence between the incomplete and complete graphs, we denote the index matrix
. The index matrix
can extract the visible instances of view
i from the complete graph. To be specific, the matrix
is defined as:
Through the index matrix, we can achieve the transformation between complete and incomplete graphs: or . In the second condition, expands the graph into , where has the same size with , but the irrelevant items to view i are zero.
Owing to the size of the graph and the similarity magnitude differing among views, it is unreasonable to directly add up the multiple graphs. Consequently, we aim to integrate the multiple information into a completed graph with adaptive learning weights
. With the help of the index matrix, relevant elements can be extracted from
. Then, we can adaptively fuse
into a complete graph with auto-learning weights, as illustrated in Equation (
6).
where
is the weight for
i-th view. It is automatically learned and optimized to illustrate the importance of
i-th view. In this manner, the complete graph is learned by a weighted combination of incomplete graphs. Besides, with the fusion of beneficial information, the inconsistencies between different views, noise and outliers in individual view are also integrated into the complete graph. Considering that, an additional sparse constraint is added on
. Therefore, integrating the above parts into an unified objective function, we have our optimization goal as:
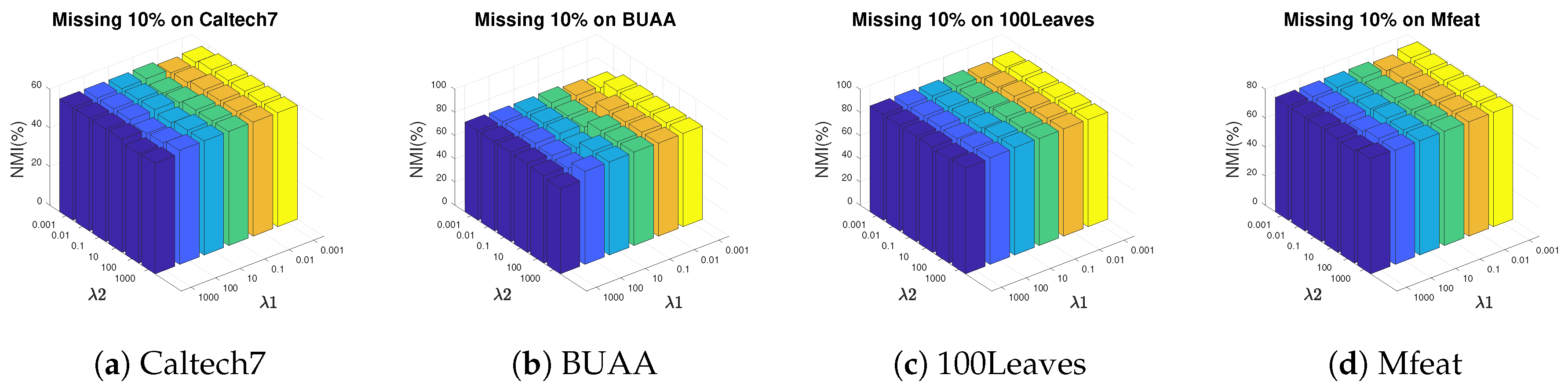
and are non-negative trade-off parameters. In the proposed framework, we have four terms: using semi-NMF to obtain latent representation, conducting graph construction with self-representation, adaptive graph fusion and sparse regularizer. Finally, we get a full-size graph incorporating all the sample information in the latent subspace.
4.2. Optimization Algorithm for AWGF-IMSC
The constraint problem in Equation (
7) is not jointly convex with regard to all the variables. In this section, we propose an alternating iterative algorithm to solve this optimization problem.
4.2.1. Update
With
,
,
and
fixed, for each
, we need to solve the following problem,
Each of
can be solved separately since views are independent from each other. Therefore, the optimization problem that we minimize can be rewritten as:
The solution for
can be easily obtained by setting the derivation w.r.t.
to zero.
Then, we can get the optimal closed-form solution:
4.2.2. Update
Fixing
,
,
and
, the minimum problem for optimizing
can be simplified as:
We can update
in Equation (
12) referring to the update strategy in semi-NMF, since the semi-NMF and subspace learning processes are isolated from each other. The partial derivation of
with respect to
can be obtained as:
According to the optimization of semi-NMF and the KKT condition, we can get
where
. Note that
. Based on this, we can achieve the updating rule for
:
4.2.3. Update
When
,
,
and
fixed, the optimization for
can be simplified as:
Denoting
, we can obtain the following equivalent question
Setting the derivative with respect to
to zero, we can get
where
and
. For each view, we can obtain the following closed-form solution
4.2.4. Update
By fixing
,
,
and
and removing other terms, the optimization for
can be transformed into solving Equation (
18).
Note that
. For each view, we can obtain the following Lagrange function:
where
is the Lagrange multipliers. Setting the derivative of
w.r.t.
to zero, we can obtain:
According to the constraint , we can compute and further get each .
4.2.5. Update
With
,
,
and
fixed, we need to minimize the following objective for
.
We can get the equivalent element-wise equation:
Note that
differ in different views.
r is the count of views in which samples
j and
p exist simultaneously. If
and
, the elements
in
are composed of the weighted sum of the corresponding instance
in view
i. Specifically, Equation (
22) obtains a unique solution:
As can be seen in Equation (
23), the solution of optimal
is a weighted combination of self-representation graph over the view which corresponding samples are visible. Moreover, the noise and outliers will be given a very small value to make the
sparse. Therefore, we can get a robust and complete graph revealing all of the relationships of the samples.
4.3. Convergence and Computational Complexity
We end up in this section by analyzing the convergence analysis and computational complexity of our proposed method.
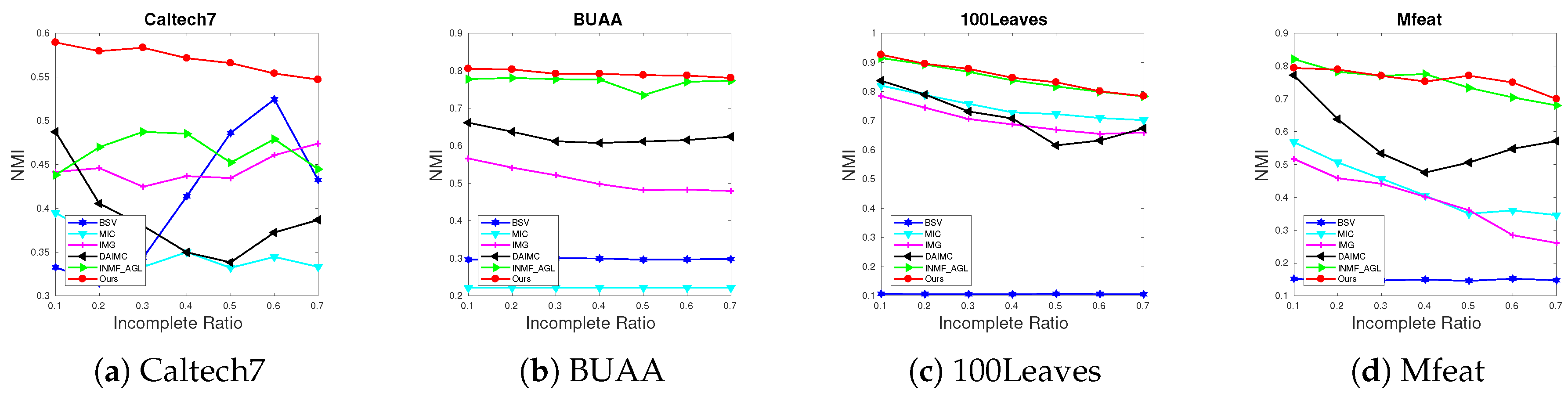
Convergence analysis: We first analyze the convergence of the proposed method. Algorithm 1 is a convex problem during the updating of each variable. Each sub-problem obtains a global optimum solution and the value of the objective function is non-increasing until converges. Experiment results in the next section demonstrate this in practice.
Computational complexity analysis: With the optimization process outlined in Algorithm 1, the total time complexity consists of five parts referring to the alternate steps. For incomplete multi-view setting, dimensionality and the number of complete samples varies across different views. With notations in the following, the first stage for computing
needs
for the
i-th view. The time cost of
dimensional matrix
multiplying
dimensional matrix
is
. Similarly, the time costs of
and
are
and
, respectively. At last, the result of
times
costs
. Therefore the total time cost of updating
is
for each view. Similarly to updating
, the time cost of updating
is
, where q is the number of iterations. The time cost of updating
is
. The time cost of updating
is
. At last, solving
acquires
. After all, the time complexity of our algorithm is
.
| Algorithm 1: AWGF-IMSC |
![Sensors 20 05755 i001]() |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}