A Deep Machine Learning Method for Concurrent and Interleaved Human Activity Recognition


Abstract
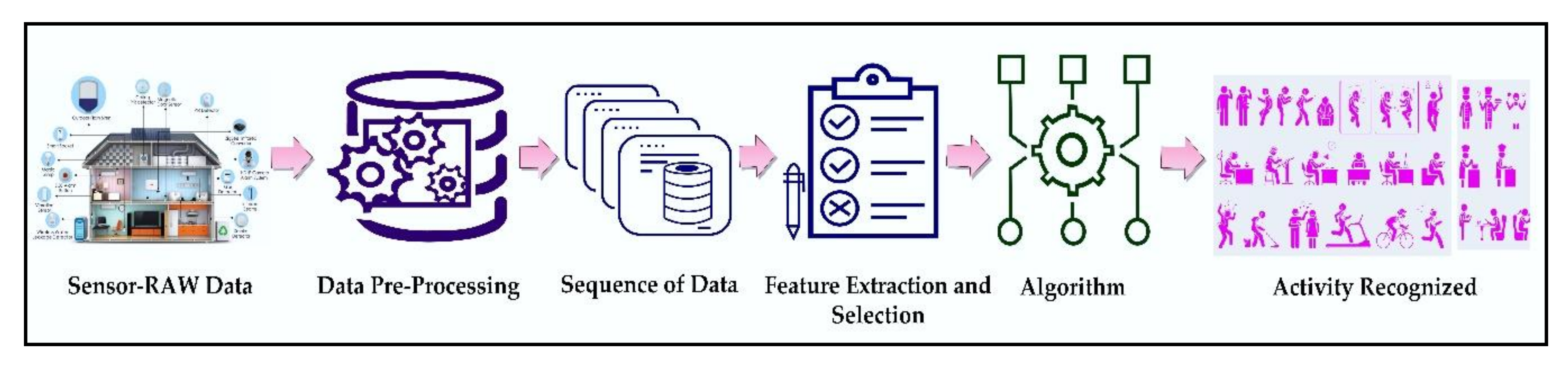
:1. Introduction
- We present the two-phase recognition method. The first phase is capable of automatically learning concurrent feature representations and modeling the temporal dependencies between their activation to detect the concurrent activity with a deep learning framework composed of Bi-directional LSTM. The second phase explicitly models dependencies between distant activity and turns out to be particularly useful in interleaved activity detection using SCCRF.
- A feature-learning structure can directly learn spatial-temporal features from the raw data via LSTM structures, which requires neither manual feature selection nor classifier selection.
- The proposed framework can be applied seamlessly to different recognition modalities and other recognition platforms.
- The system adopts the raw sensor data with less preprocessing, which makes it exceptionally comfortable and general.
- We compare the performance of our framework to publically available datasets from Kasteren and Kyoto (WSU).
- The results depicted by our proposed framework outperforms published results on recognition of concurrent and interleaved activity.
- The proposed approach can classify the variable window ranges of human activities. Utilizing the LSTM to read variable window ranges, sequences of input sensors data can later recognize the entire window segment’s activity.
2. Related Work
3. Materials and Method
3.1. Long-Short Term Memory (LSTM)
3.2. Bi-Directional LSTM
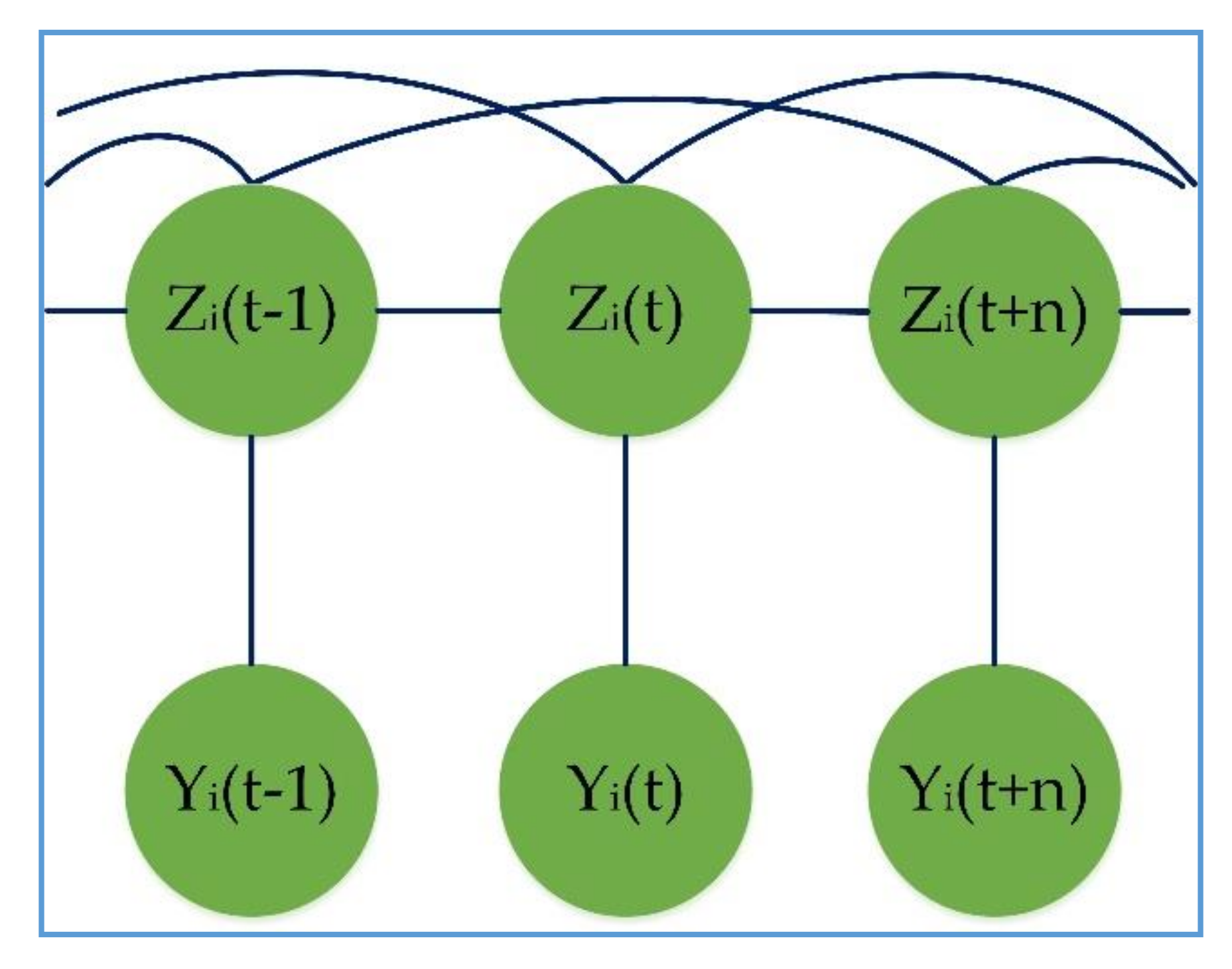
3.3. Skip Chain CRFs
3.4. Proposed Method
| Algorithm 1 pseudocode for the proposed algorithm |
| 1. initialize network 2. reset : inputs = 0, Activations = 0 forward propagation: 3. initialize the inputs do 4. roll over: Activations; cell states 5. loop over a cell, end for 6. do for t=0 to n do Calculates the gate values : inputs gates: forget gates: loop over the cells is block now output gates: update the cell: final hidden state/ final output : end for 7. Single activity detect 8. do Update the weight end for 9. backward propagation do for t=0 to n inputs gates: forget gates: output gates: cell output: 10. Hidden state / final output : end for 11. do z = and Concurrent activity detect end For 12. do for t=0 to n, k = 0 to n-1 do end for 13. Interleaved activity detect 14. end for 15. end for 16. end |
4. Experimental Configuration
4.1. Benchmark Datasets
4.2. Parameter Setup and Training
4.3. Analysis Metrics
5. Activity Recognition Performance Analysis
5.1. Concurrent Activity Recognition Analysis
5.2. Interleaved Activity Recognition Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Van Kasteren, T.L.M.; Englebienne, G.; Kröse, B.J.A. An activity monitoring system for elderly care using generative and discriminative models. Pers. Ubiquitous Comput. 2010, 14, 489–498. [Google Scholar] [CrossRef] [Green Version]
- Rialle, V.; Duchêne, F.; Noury, N.; Bajolle, L.; Demongeot, J. Health “Smart” Home: Information technology for patients at home. Telemed. e-Health 2002, 8, 395–409. [Google Scholar] [CrossRef] [PubMed]
- Fiorini, L.; Bonaccorsi, M.; Betti, S.; Dario, P.; Cavallo, F. Ambient Assisted Living. Ital. Forum Ambient Assisted Living 2016, 426, 251. [Google Scholar]
- Rashidi, P.; Cook, D.J. Keeping the resident in the loop: Adapting the smart home to the user. IEEE Trans. Syst. Man, Cybern. Part A Syst. Humans 2009, 39, 949–959. [Google Scholar] [CrossRef]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. Lect. Notes Comput. Sci. 2004, 3001, 158–175. [Google Scholar]
- Kim, E.; Helal, S.; Cook, D. Human activity recognition and pattern discovery. IEEE Pervasive Comput. 2010, 9, 48–53. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, D.H.; Yang, Q. CIGAR: Concurrent and interleaving goal and activity recognition. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Malcolm, P.; Michael, W.; Viv, J.S.; Rebecca, L.; Sally, M.; David, L.R.; Jeremy, D.; Alison, W. Development and validation of an organizational climate measure. J. Organ. Behav. 2011, 10–26. [Google Scholar] [CrossRef]
- Vail, D.L.; Veloso, M.M.; Lafferty, J.D. Conditional random fields for activity recognition. In Proceedings of the 6th International Joint Conference on Autonomous agents and Multiagent Systems—AAMAS’07, Honolulu, HI, USA, 14–18 May 2007. [Google Scholar]
- Patterson, D.J.; Liao, L.; Fox, D.; Kautz, H. Inferring high-level behavior from low-level sensors. In Proceedings of the International Conference on Ubiquitous Computing (UbiComp), Seattle, WA, USA, 12–15 October 2003. [Google Scholar]
- Kabir, M.H.; Thapa, K.; Yang, J.-Y.; Yang, S.-H. State-space based linear modeling for human activity recognition in smart space. Intell. Autom. Soft Comput. 2018, 1–9. [Google Scholar] [CrossRef]
- Hoque, M.R.; Kabir, M.H.; Seo, H.; Yang, S.-H. PARE: Profile-Applied Reasoning Engine for context-aware system. Int. J. Distrib. Sens. Netw. 2016, 12, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Sung-Hyun, Y.; Thapa, K.; Kabir, M.H.; Hee-Chan, L. Log-Viterbi algorithm applied on second-order hidden Markov model for human activity recognition. Int. J. Distrib. Sens. Netw. 2018, 14. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Hu, F.; Li, L. Deep Bi-directional long short-term memory model for short-term traffic flow prediction. Lect. Notes Comput. Sci. 2017, 306–316. [Google Scholar] [CrossRef]
- Saon, G.; Kurata, G.; Sercu, T.; Audhkhasi, K.; Thomas, S.; Dimitriadis, D.; Cui, X.; Ramabhadran, B.; Picheny, M.; Lim, L.-L.; et al. English conversational telephone speech recognition by humans and machines. In Proceedings of the Interspeech 2017, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 132–136. [Google Scholar]
- Vaidya, R.; Trivedi, D.; Satra, S.; Pimpale, M. Handwritten character recognition using deep-learning. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 772–775. [Google Scholar]
- Arif, S.; Wang, J.; Ul-Hassan, T.; Fei, Z. 3D-CNN-based fused feature maps with lstm applied to action recognition. Futur. Internet 2019, 11, 42. [Google Scholar] [CrossRef] [Green Version]
- Sutton, C.; McCallum, A. Piecewise pseudolikelihood for efficient training of conditional random fields. Comput. Sci. Dep. Fac. Publ. Ser. 2007, 62, 863–870. [Google Scholar]
- Kautz, R.L. Physics Letters A; Elsevier: Amsterdam, The Netherlands, 1987; Volume 125, pp. 315–319. ISSN 0375-9601. [Google Scholar]
- Maurer, U.; Smailagic, A.; Siewiorek, D.P.; Deisher, M. Activity recognition and monitoring using multiple sensors on different body positions. In Proceedings of the International Workshop on Wearable and Implantable Body Sensor Networks (BSN’06), Cambridge, MA, USA, 3–5 April 2006; Volume 4. [Google Scholar] [CrossRef]
- Ponce, H.; Martínez-Villaseñor, L.; Miralles-Pechúan, L. A Novel wearable sensor-based human activity recognition approach using artificial hydrocarbon networks. Sensors 2016, 16, 1033. [Google Scholar] [CrossRef] [PubMed]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and LSTM recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yalcin, H.; Yalçın, H. Human activity recognition using deep belief networks. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 16–19 May 2016; pp. 1649–1652. [Google Scholar]
- Bevilacqua, A.; Macdonald, K.; Rangarej, A.; Widjaya, V.; Caulfield, B.; Kechadi, T. Human activity recognition with convolutional neural networks. In Machine Learning and Knowledge Discovery in Databases. ECML PKDD, 2018. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11053. [Google Scholar]
- Singh, D.; Merdivan, E.; Psychoula, I.; Kropf, J.; Hanke, S.; Geist, M.; Holzinger, A. Human activity recognition using recurrent neural networks. In Machine Learning and Knowledge Extraction. CD-MAKE 2017. Lecture Notes in Computer Science; Holzinger, A., Kieseberg, P., Tjoa, A., Weippl, E., Eds.; Springer: Cham, Switzerland, 2017; Volume 10410. [Google Scholar]
- Bao, L.; Intille, S.S. Activity recognition from user-annotated acceleration data most. In Pervasive Computing; Springer: Berlin, Heidelberg, 2004; pp. 1–17. [Google Scholar]
- Lee, M.-h.; Kim, J.; Kim, K.; Lee, I.; Jee, S.H.; Yoo, S.K. Physical Activity Recognition Using a Single Tri-Axis Accelerometer; MIT Press: Cambridge, MA, USA, 2009; Volume I, pp. 20–23. [Google Scholar]
- Kabir, M.H.; Hoque, M.R.; Thapa, K.; Yang, S.-H. Two-layer hidden markov model for human activity recognition in home environments. Int. J. Distrib. Sensor Netw. 2016, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Nazerfard, E.; Das, B.; Holder, L.B.; Cook, D.J. Conditional random fields for activity recognition in smart environments. In Proceedings of the 1st ACM International Health Informatics Symposium, IHI’10, Arlington, VA, USA, 11–12 November 2010; pp. 282–286. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Li, Q. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Graves, A.; Jaitly, N.; Mohamed, A.-R. Hybrid speech recognition with deep bidirectional LSTM. In Proceedings of the Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop, Olomouc, Czech Republic, 8–12 December 2013; pp. 273–278. [Google Scholar]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Darrell, T.; Saenko, K. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Karpathy, A.; Joulin, A.; Fei-Fei, L. Deep fragment embeddings for bidirectional image sentence mapping. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Galley, M. A skip-chain conditional random field for ranking meeting utterances by importance. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 364–372. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. arXiv 2015, arXiv:1503.04069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hammerle, N.Y.; Halloran, S.; Ploetz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Sutton, C.; McCallum, A. An introduction to conditional random fields for relational learning. In Introduction to Statistical Relational Learning; Getoor, L., Taskar, B., Eds.; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Van Kasteren, T.L.M. Dataset. Available online: https://sites.google.com/site/tim0306/datasets (accessed on 17 September 2020).
- CASAS Dataset. Available online: http://casas.wsu.edu/datasets/ (accessed on 17 September 2020).
- Lee, C. LSTM-CRF Models for Named Entity Recognition. IEICE Trans. Inf. Syst. 2017, D, 882–887. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional lstm-crf models for sequence tagging. In Proceedings of the 21st International Conference on Asian Language Processing, Beijing, China, 26–31 July 2015. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Kasteren House-B | Kyoto 3 |
|---|---|---|
| Setting | Apartment | Apartment |
| Rooms | 2 | 4 |
| Senors | 23 | 76 |
| Activities | 13 | 8 |
| Residents | 1 | 4 |
| Period | 14 d | 15 d |
| Instances | 135 | 178 |
| Activities Performed | Breakfast, Brushing Teeth, Dinner, Drinking, Dressing, Leaving House, Others, Preparing Breakfast, Preparing Dinner, Sleeping, Showering, Toileting, Using Dishwasher | Fill Medication Dispenser, Wash DVD, Water Plants, Answer the Phone, Prepare Birthday Card, Prepare Soup, Clean, Choose Outfit |
| Hyperprameters | Values |
|---|---|
| Time Steps of input | 128 |
| Dropout Rate | 0.5 |
| Initial Learning Rate | 0.001 |
| Learning Rates | 0.005 |
| Optimizer (Bi-LSTM) | Adam |
| Batch Size | 100 |
| Gradient Clipping | 5 |
| Skin-chain parameter θ | |
| SC Optimizer | Quasi-Newton |
| Epochs | 10000 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | Recall | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. Breakfast | 93 | 0 | 0 | 0 | 0.2 | 0.88 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 98.85 |
| 2. Brushing Teeth | 0 | 95 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 94.06 |
| 3. Dinner | 0 | 0 | 91 | 0 | 0 | 0 | 1.9 | 0 | 0 | 0 | 0 | 5.3 | 0 | 92.67 |
| 4. Drinking | 0 | 0 | 0 | 95 | 0 | 0 | 0 | 4.6 | 0 | 0 | 0 | 0 | 2.3 | 93.23 |
| 5. Dressing | 0 | 0 | 0 | 0 | 97 | 1.5 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 95.57 |
| 6. Leaving House | 0.3 | 0 | 0 | 2.3 | 2.5 | 90 | 0 | 2.8 | 1 | 0 | 0 | 0 | 3 | 88.32 |
| 7. Preparing Breakfast | 2 | 5.2 | 0 | 0 | 0 | 0 | 92 | 0 | 0 | 0 | 0 | 0 | 0 | 92.74 |
| 8. Preparing Dinner | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 91 | 0 | 2.7 | 0 | 1 | 0 | 96.09 |
| 9. Sleeping | 0 | 5.2 | 0 | 0 | 0 | 0 | 1 | 0 | 97 | 0 | 0 | 0 | 0 | 93.99 |
| 10. Showering | 0 | 0 | 0 | 0.2 | 0 | 0 | 0 | 0 | 0 | 90 | 1.6 | 0 | 0 | 98.04 |
| 11. Toileting | 0 | 0 | 0 | 1.3 | 1.2 | 0 | 0 | 1.6 | 0 | 0 | 92 | 0 | 5 | 91.00 |
| 12. Using Dishwasher | 0 | 0 | 7.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 94 | 0 | 92.89 |
| 13. Others | 3 | 0 | 0 | 0 | 0 | 7.5 | 7 | 0 | 0 | 5 | 3 | 0 | 83 | 76.50 |
| Precision | 94.61 | 90.13 | 92.67 | 96.15 | 96.13 | 90.11 | 90.28 | 91.00 | 93.27 | 92.12 | 92.37 | 93.72 | 88.96 |
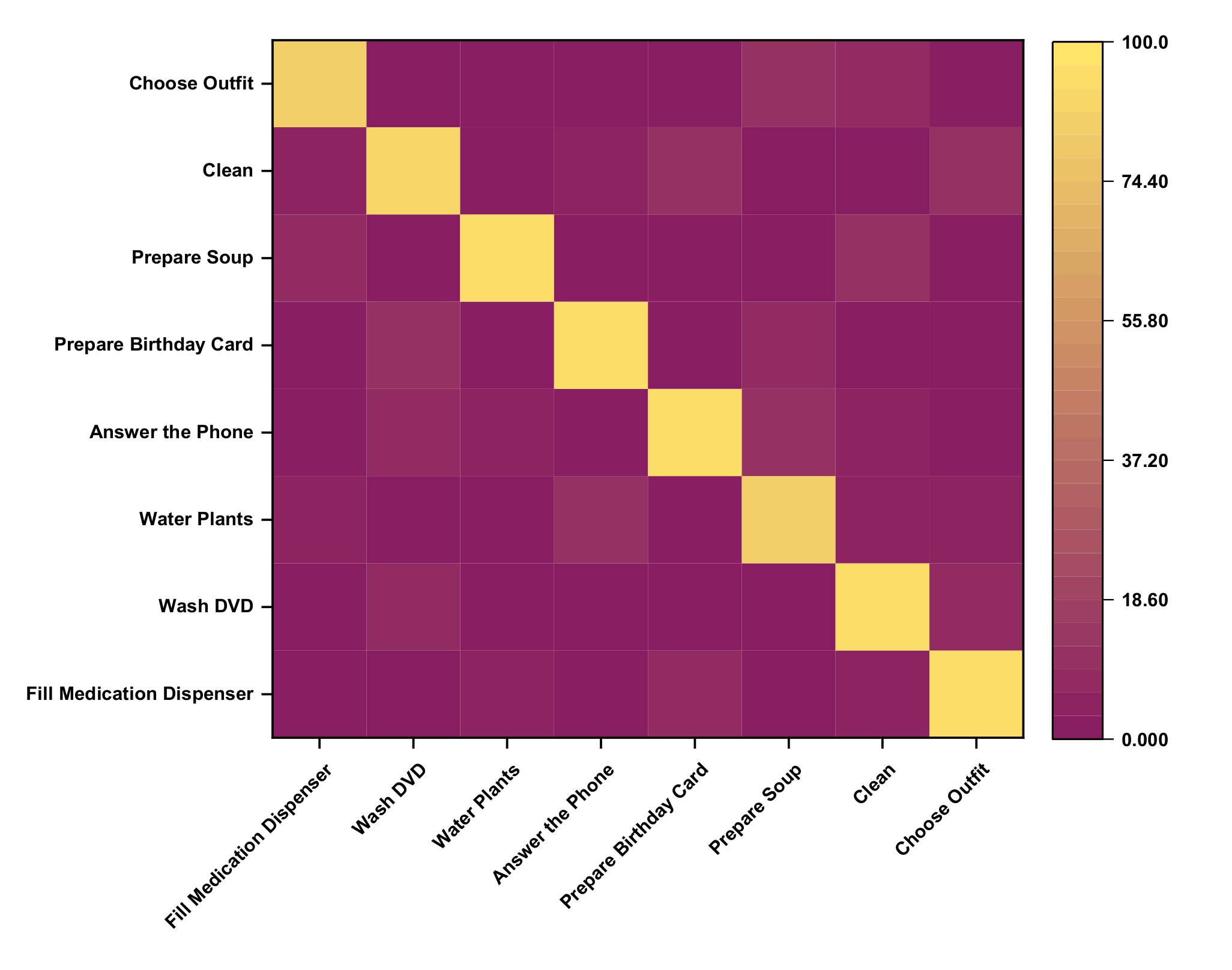
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | Recall | |
|---|---|---|---|---|---|---|---|---|---|
| 1. Fill Medical on Dispenser | 93 | 1.3 | 2.7 | 0 | 0 | 1.6 | 0 | 0 | 94.32 |
| 2. Wash DVD | 0 | 90 | 0 | 4 | 2 | 0 | 2 | 0 | 91.84 |
| 3. Water Plants | 0 | 0 | 92 | 0 | 0 | 0 | 0 | 0 | 100.00 |
| 4. Answer the Phone | 0.6 | 1.2 | 0 | 90 | 0 | 6 | 0 | 0 | 92.02 |
| 5. Prepare Birthday Card | 0 | 3 | 0 | 0 | 91 | 0 | 0 | 2.3 | 94.50 |
| 6. Prepare Soup | 5 | 0 | 0 | 2.3 | 3.2 | 91 | 0 | 0 | 89.66 |
| 7. Clean | 2 | 0 | 5 | 0 | 1.2 | 90 | 1 | 90.73 | |
| 8. Choose Outfit | 0 | 4 | 0 | 0 | 0 | 2 | 2 | 92 | 92.00 |
| Precision | 92.45 | 90.45 | 92.28 | 93.46 | 93.43 | 90.46 | 95.74 | 96.54 |
| Batch Size | 10 | 20 | 50 | 100 |
|---|---|---|---|---|
| Mean (μ) ± SD (σ) | Mean (μ) ± SD (σ) | Mean (μ) ± SD (σ) | Mean (μ) ± SD (σ) | |
| House B | 0.9261 ± 0.0734 | 0.9332 ± 0.0479 | 0.9327 ± 0.0413 | 0.9234 ± 0.0458 |
| Kyoto | 0.9407 ± 0.0620 | 0.9334 ± 0.0479 | 0.9419 ± 0.0413 | 0.9394 ± 0.0458 |
| Epochs | 1000 | 5000 | 8000 | 10000 |
|---|---|---|---|---|
| Mean (μ) ± SD (σ) | Mean (μ) ± SD (σ) | Mean (μ) ± SD (σ) | Mean (μ) ± SD (σ) | |
| House B | 0.9030 ± 0.0655 | 0.930 ± 0.0468 | 0.9295 ± 0.0353 | 0.9103 ± 0.0482 |
| Kyoto | 0.9175 ± 0.0613 | 0.9303 ± 0.0347 | 0.9388 ± 0.0304 | 0.9411 ± 0.0464 |
| Mean ± SD Accuracy | Mean ± SD Error | |
|---|---|---|
| House B | 0.9148 ± 0.0458 | 0.476161 ± 0.15032 |
| Kyoto | 0.9390 ± 0.0455 | 0.31367 ± 0.21140 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thapa, K.; Abdullah Al, Z.M.; Lamichhane, B.; Yang, S.-H. A Deep Machine Learning Method for Concurrent and Interleaved Human Activity Recognition. Sensors 2020, 20, 5770. https://doi.org/10.3390/s20205770
Thapa K, Abdullah Al ZM, Lamichhane B, Yang S-H. A Deep Machine Learning Method for Concurrent and Interleaved Human Activity Recognition. Sensors. 2020; 20(20):5770. https://doi.org/10.3390/s20205770
Chicago/Turabian StyleThapa, Keshav, Zubaer Md. Abdullah Al, Barsha Lamichhane, and Sung-Hyun Yang. 2020. "A Deep Machine Learning Method for Concurrent and Interleaved Human Activity Recognition" Sensors 20, no. 20: 5770. https://doi.org/10.3390/s20205770
APA StyleThapa, K., Abdullah Al, Z. M., Lamichhane, B., & Yang, S.-H. (2020). A Deep Machine Learning Method for Concurrent and Interleaved Human Activity Recognition. Sensors, 20(20), 5770. https://doi.org/10.3390/s20205770