Impact of Feature Selection Algorithm on Speech Emotion Recognition Using Deep Convolutional Neural Network

 ,
, 
 and
and 
Abstract
:1. Introduction
- An algorithm using a DCNN to extract emotional features for SER is proposed.
- A CFS algorithm, which leads to improved accuracy for SER, is used.
- The proposed method achieves performance improvement over the existing handcrafted and deep learning SER approaches for both speaker-dependent and speaker-independent scenarios.
2. Literature Review
2.1. Emotion Classifier
2.2. Feature Extraction
3. Methodology
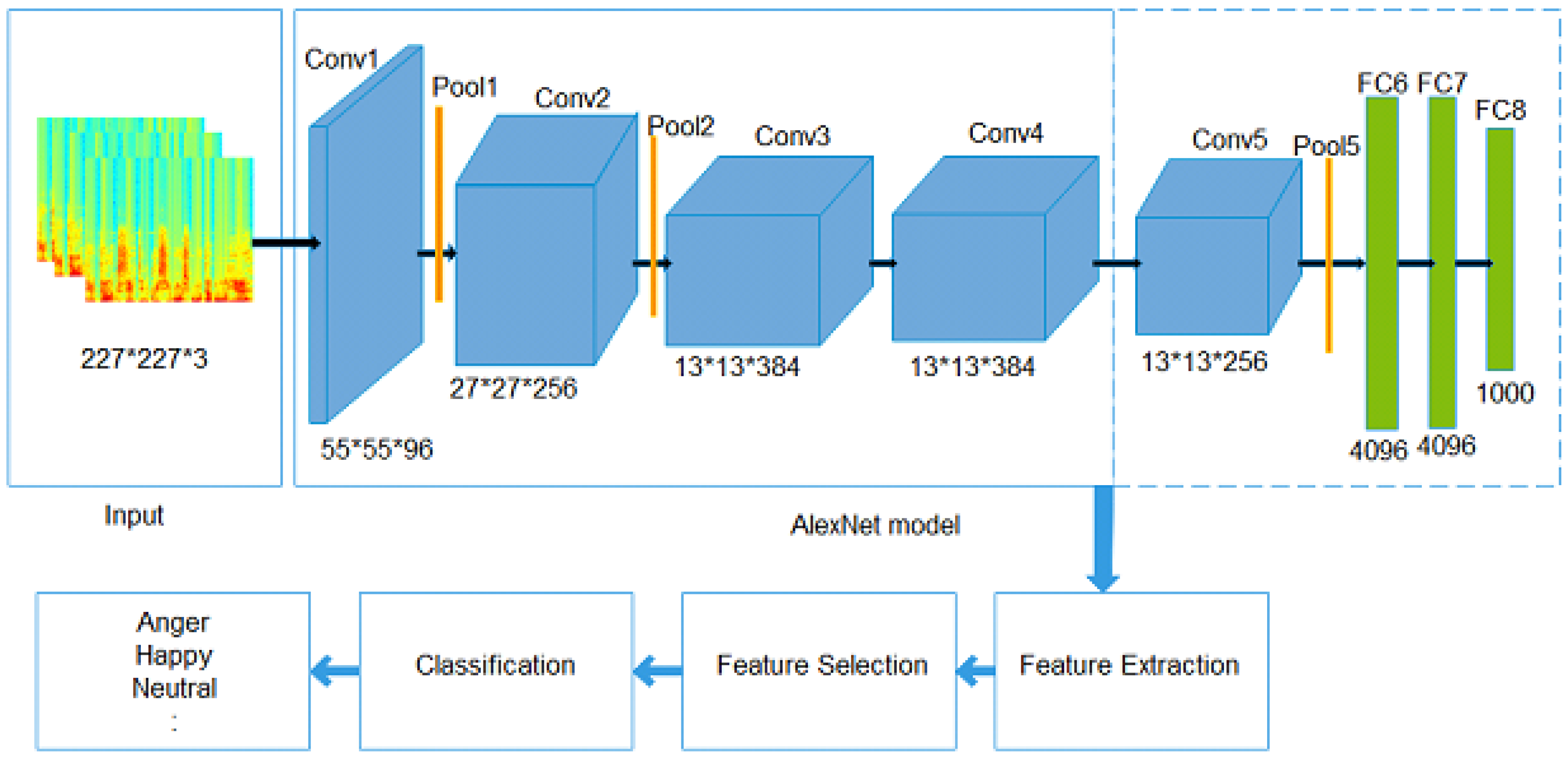
3.1. Speech Emotion Recognition Using a Deep CNN
Features Extraction
- (a)
- Input layerThe first layer is the input layer. The AlexNet model uses an input with a size of . Therefore, we resized the spectrogram of the speech signal into a compatible size of input layer.
- (b)
- Convolutional Layer (CL)The CL is comprised of convolutional filters that are used to extract several local patterns from every local area in the input, and generates several feature maps. There are five convolutional layers, Conv1, Conv2, Conv3, Conv4, and Conv5, in the AlexNet model, and three of them (Conv1, Conv2, and Conv5) are followed by max-pooling. The convolutional layers use the ReLU activation function. The first convolutional layer (Conv1) has 96 kernels of size with a stride of 4 pixels and zero-padding. The second (Conv2) has 256 kernels of size with a stride of 1 and a padding value of 2. The third convolutional layer (Conv3) has 384 kernels of size connected to the outputs of Conv2, and the fourth convolutional layer (Conv4) has 384 kernels of size . The ReLU activation function is adopted at the output of every convolutional layer, which accelerates the training process.
- (c)
- Pooling Layer (CL)The PL is employed after the convolutional layers. The purpose of the PL is to down-sample the feature maps obtained from the preceding convolutional layers to generate a single output convolutional feature map from the local regions. There are two general pooling operators: max-pooling and average pooling. The max-pooling layer generates a reduced resolution form of convolutional layer activations by utilizing maximum filter activation from distinct positions within a quantified window.
- (d)
- Fully Connected Layers (FCLs)This layer combines the features obtained from the preceding layers and produces a feature representation for the classification task. The outcome from the convolutional and pooling layers is given to the FCL. In the AlexNet model, there are three FCLs: FC6, FC7, and FC8. FC6 and FC7 produce a 4096-dimensional feature vector, whereas FC8 yields a 1000-dimensional feature vector.
3.2. Feature Selection
Correlation-Based Feature Selection (CFS) Method
3.3. Classification Algorithms
Support Vector Machine (SVM)
3.4. Random Forests
3.5. k-Nearest Neighbors Algorithm
3.6. Multilayer Perceptron
4. Experiments
4.1. Datasets
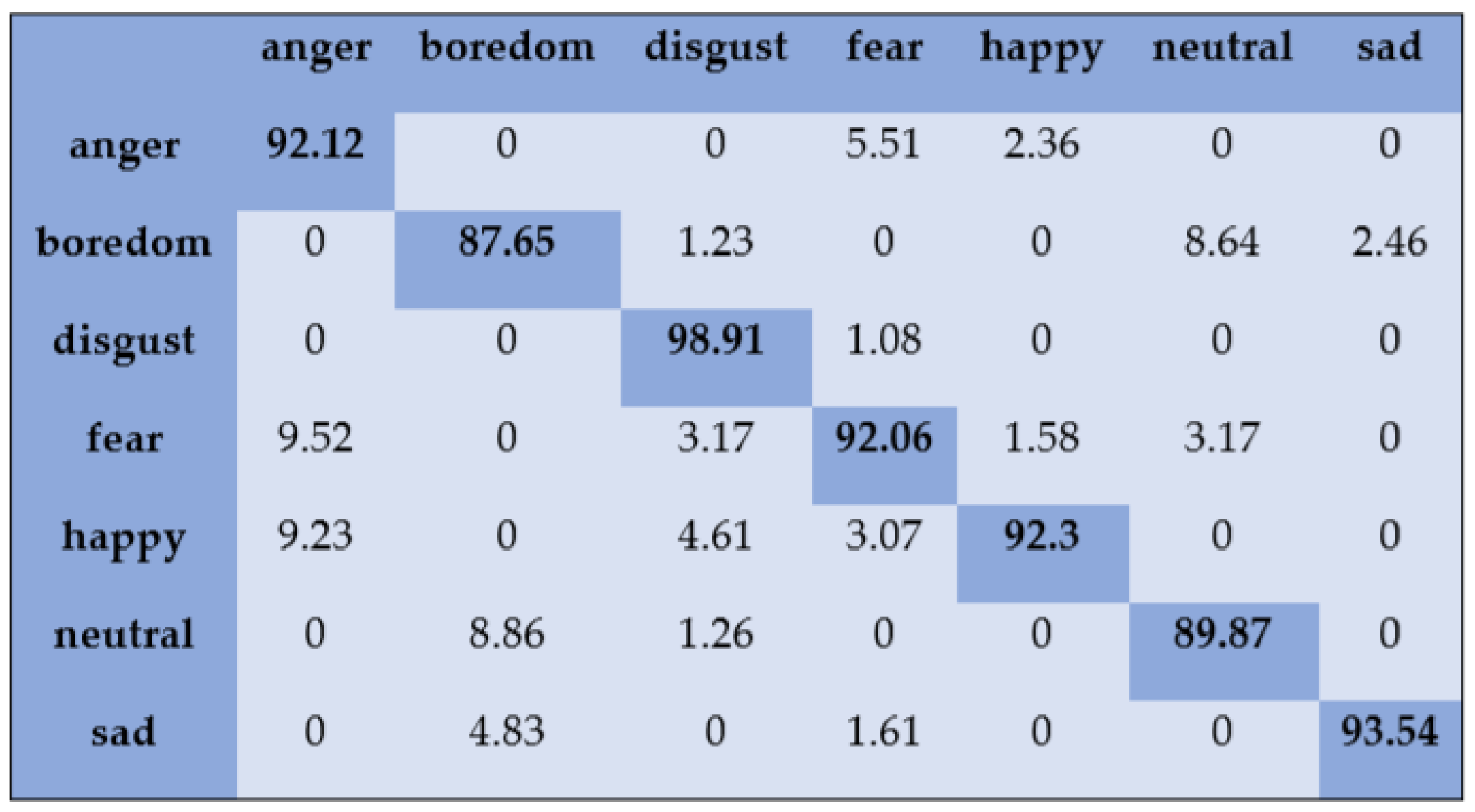
- Emo-DB: The Emo-DB speech corpus consists of seven acted emotional states: angry, disgust, boredom, joy, sad, neutral, and fear. It has 535 emotional utterances in the German language collected from ten native German actors. Among them, five are female actors and the remaining five are male actors. The audio files have a sampling frequency of 16 kHz and have 16-bit resolution. The average time period of the audio files is 3 s.
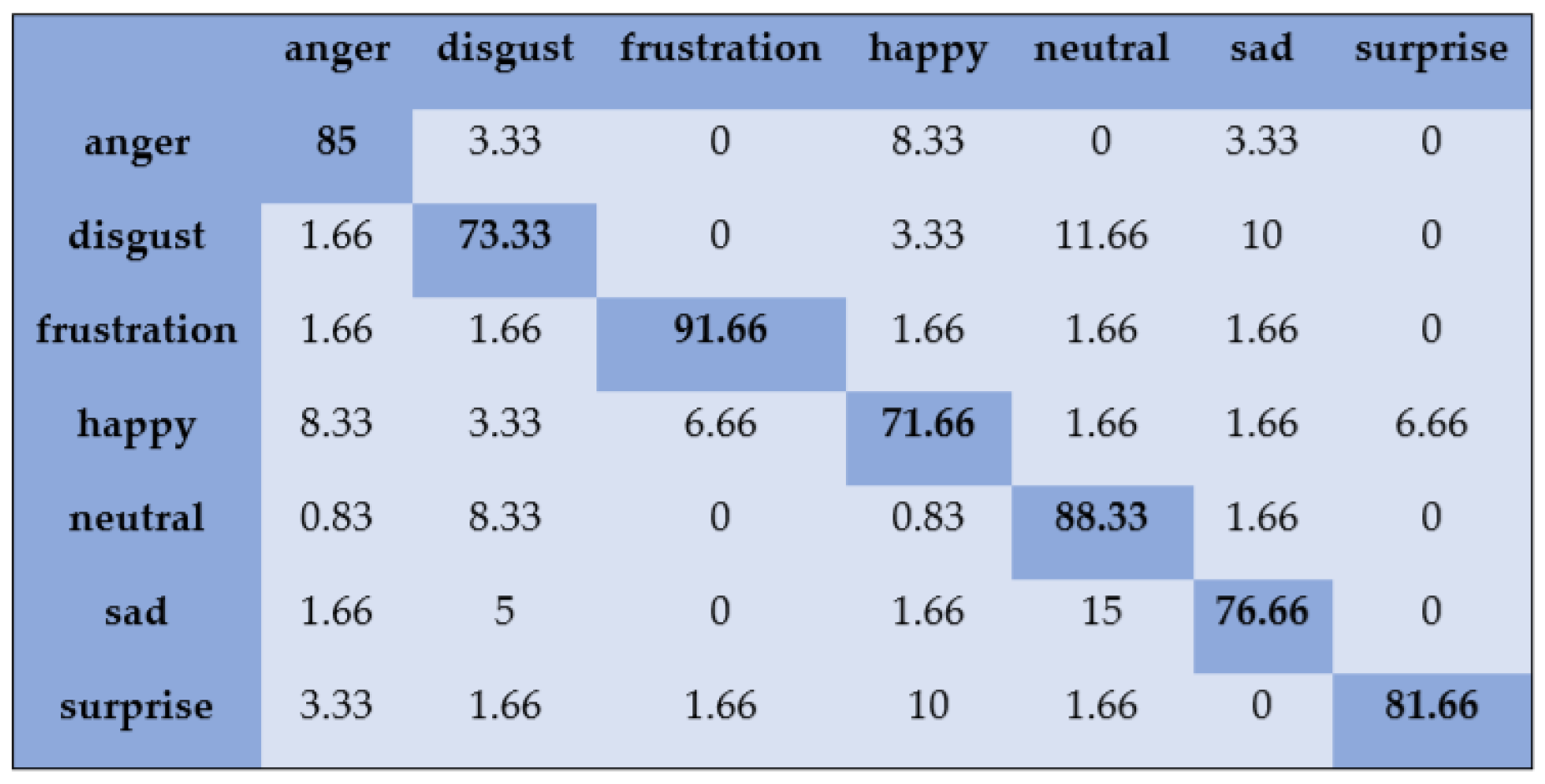
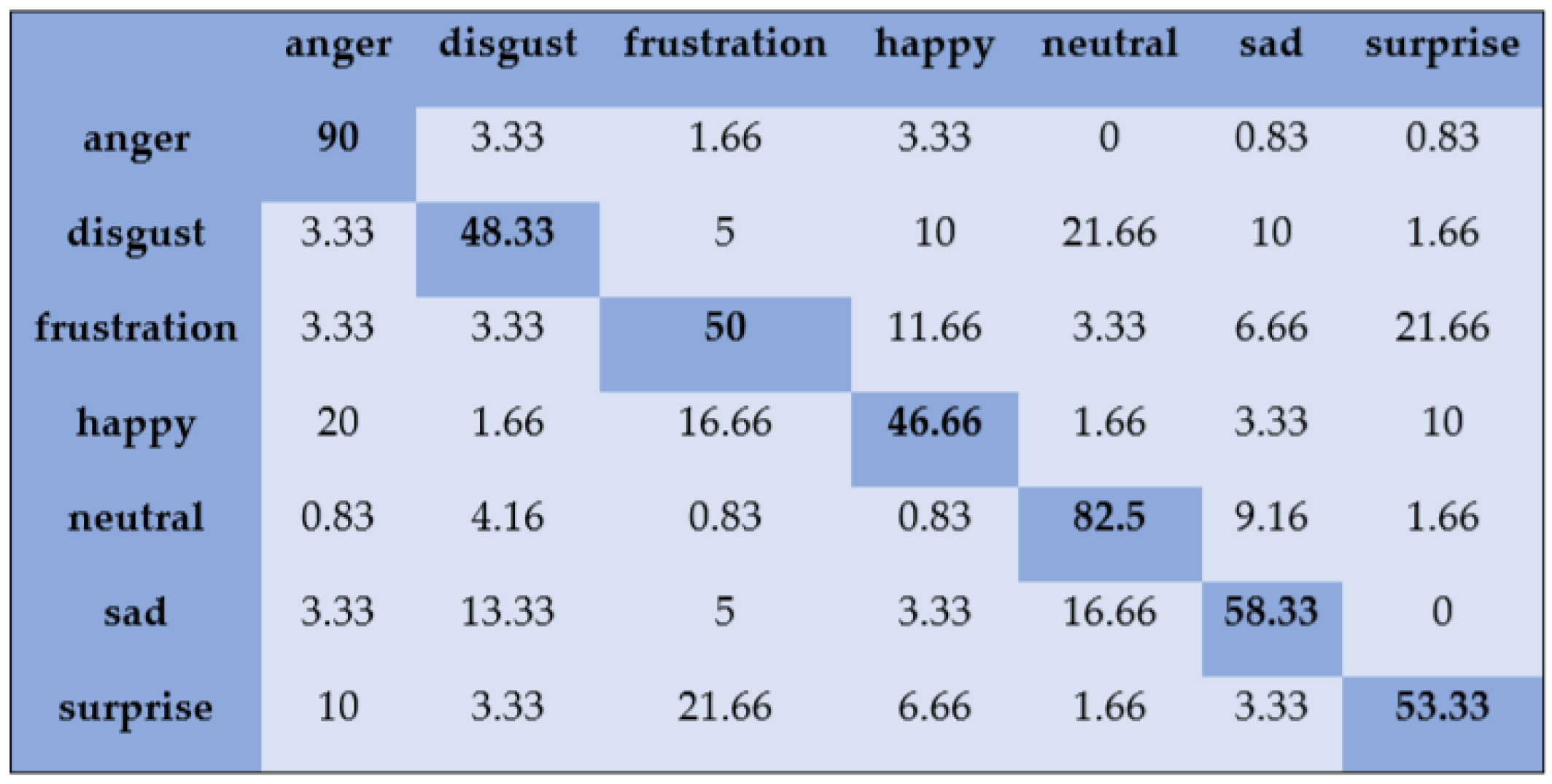
- SAVEE: The SAVEE dataset was recorded with a high-quality audio–visual apparatus in a visual media laboratory. It has 480 British English emotional utterances recorded from four male actors. It consists of seven emotional states: anger, frustration, happiness, disgust, neutral, surprise, and sadness. The audio files had a sampling frequency of 44.1 kHz, and the recorded data were evaluated by ten subjects.
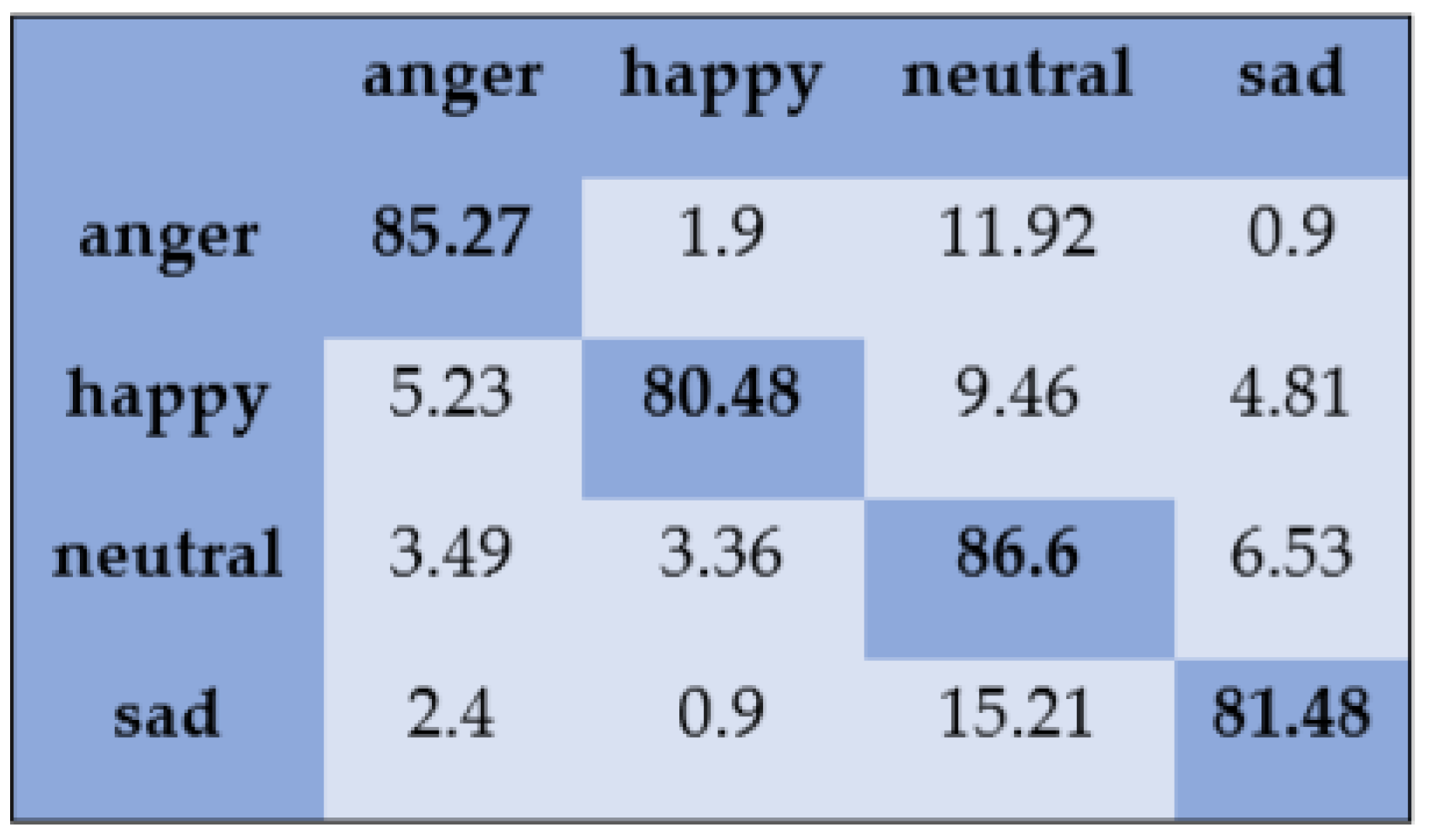
- IEMOCAP: This is an acted and multi-speaker dataset that was collected at the Signal Analysis and Interpretation Laboratory at the University of Southern California. The dataset consists of five sessions, and in each session, two English-speaking actors (one male and one female) are engaged in scripted or improvized scenarios to elicit desired emotions. The recorded audio has a sampling frequency of 16 kHz. Multiple professional annotators have annotated the IEMOCAP database into categorical labels. Each utterance was assessed by three different annotators. We assigned labels to the utterances on which at least two annotators agreed. In this study, four emotional classes are employed: happiness, sadness, neutral, and angry.
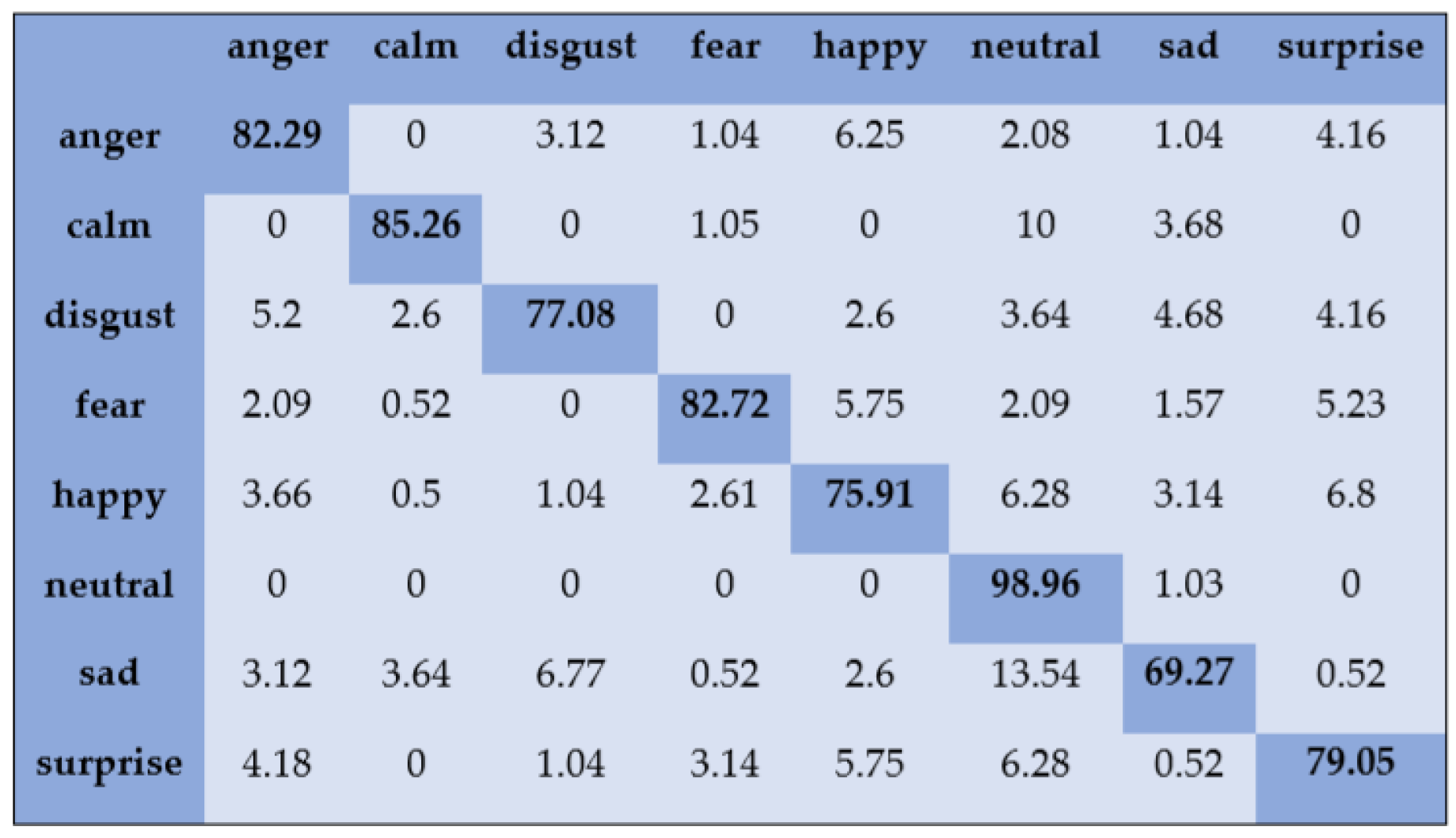
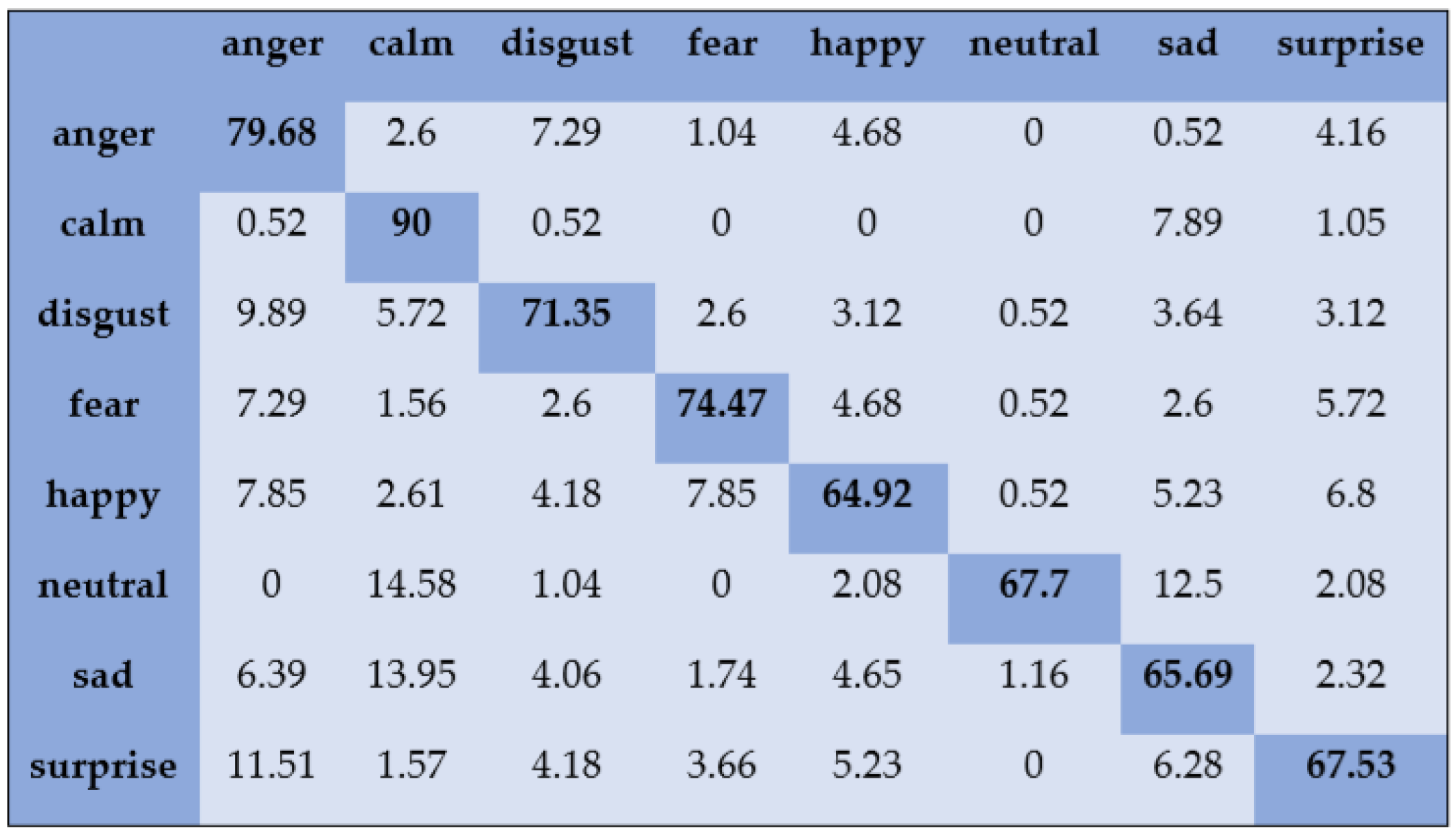
- RAVDESS: RAVDESS is an audio and visual emotion dataset that contains eight emotional states: angry, neutral, calm, happy, sadness, fear, disgust, and surprise. The emotional utterances were recorded in a North American accent from 24 professional actors, in which 12 are female actors and 12 are male actors. The audio files have a sampling frequency of 48 kHz with 16-bit resolution.
4.2. Experimental Setup
4.2.1. Data Pre-Processing
4.2.2. Evaluation Parameters
5. Results Analysis and Discussion
5.1. Speaker-Dependent Experiments
5.2. Speaker-Independent Experiments
5.3. Comparison with State-of-the-Art Approaches
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 41st IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Twenty-Sixth Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Jackson, P.; Haq, S. Surrey Audio-Visual Expressed Emotion (Savee) Database; University of Surrey: Guildford, UK, 2014. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schuller, B.; Rigoll, G.; Lang, M. Speech emotion recognition combining acoustic features and linguistic information in a hybrid support vector machine-belief network architecture. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; Volume 1, p. I-577. [Google Scholar]
- Noroozi, F.; Sapiński, T.; Kamińska, D.; Anbarjafari, G. Vocal-based emotion recognition using random forests and decision tree. Int. J. Speech Technol. 2017, 20, 239–246. [Google Scholar] [CrossRef]
- Pao, T.L.; Chen, Y.T.; Yeh, J.H.; Cheng, Y.M.; Lin, Y.Y. A comparative study of different weighting schemes on KNN-based emotion recognition in Mandarin speech. In Proceedings of the International Conference on Intelligent Computing (ICIC), Qingdao, China, 21–24 August 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 997–1005. [Google Scholar]
- Nwe, T.L.; Foo, S.W.; De Silva, L.C. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Nicholson, J.; Takahashi, K.; Nakatsu, R. Emotion recognition in speech using neural networks. Neural Comput. Appl. 2000, 9, 290–296. [Google Scholar] [CrossRef]
- Ververidis, D.; Kotropoulos, C. Emotional speech classification using Gaussian mixture models and the sequential floating forward selection algorithm. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; pp. 1500–1503. [Google Scholar]
- Rao, K.S.; Koolagudi, S.G.; Vempada, R.R. Emotion recognition from speech using global and local prosodic features. Int. J. Speech Technol. 2013, 16, 143–160. [Google Scholar] [CrossRef]
- Sheikhan, M.; Bejani, M.; Gharavian, D. Modular neural-SVM scheme for speech emotion recognition using ANOVA feature selection method. Neural Comput. Appl. 2013, 23, 215–227. [Google Scholar] [CrossRef]
- Koolagudi, S.G.; Rao, K.S. Emotion recognition from speech using source, system, and prosodic features. Int. J. Speech Technol. 2012, 15, 265–289. [Google Scholar] [CrossRef]
- Hu, H.; Xu, M.X.; Wu, W. Fusion of global statistical and segmental spectral features for speech emotion recognition. In Proceedings of the 8th Annual Conference of the International Speech Communication Association (Interspeech), Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- Steidl, S. Automatic Classification of Emotion Related User States in Spontaneous Children’s Speech; University of Erlangen-Nuremberg: Erlangen, Germany, 2009. [Google Scholar]
- Fu, L.; Mao, X.; Chen, L. Speaker independent emotion recognition based on SVM/HMMs fusion system. In Proceedings of the 2008 International Conference on Audio, Language and Image Processing, Shanghai, China, 7–9 July 2008; pp. 61–65. [Google Scholar]
- Zhang, S. Emotion recognition in Chinese natural speech by combining prosody and voice quality features. In Proceedings of the 5th International Symposium on Neural Networks, Beijing, China, 24–28 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 457–464. [Google Scholar]
- Tawari, A.; Trivedi, M.M. Speech emotion analysis: Exploring the role of context. IEEE Trans. Multimed. 2010, 12, 502–509. [Google Scholar] [CrossRef] [Green Version]
- Ding, N.; Sethu, V.; Epps, J.; Ambikairajah, E. Speaker variability in emotion recognition-an adaptation based approach. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5101–5104. [Google Scholar]
- Lee, C.M.; Narayanan, S.S. Toward detecting emotions in spoken dialogs. IEEE Trans. Speech Audio Process. 2005, 13, 293–303. [Google Scholar]
- Schmitt, M.; Ringeval, F.; Schuller, B.W. At the Border of Acoustics and Linguistics: Bag-of-Audio-Words for the Recognition of Emotions in Speech. In Proceedings of the 17th Annual Conference of the International Speech Communication Association (Interspeech), San Francisco, CA, USA, 8–12 September 2016; pp. 495–499. [Google Scholar]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A. The interspeech 2009 emotion challenge. In Proceedings of the Tenth Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.; Narayanan, S.S. The INTERSPEECH 2010 paralinguistic challenge. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Vinciarelli, A.; Scherer, K.; Ringeval, F.; Chetouani, M.; Weninger, F.; Eyben, F.; Marchi, E.; et al. The Interspeech 2013 computational paralinguistics challenge: Social signals, conflict, emotion, autism. In Proceedings of the Interspeech 2013 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Hirschberg, J.; Burgoon, J.K.; Baird, A.; Elkins, A.; Zhang, Y.; Coutinho, E.; Evanini, K.; et al. The interspeech 2016 computational paralinguistics challenge: Deception, sincerity & native language. In Proceedings of the 17th Annual Conference of the International Speech Communication Association (INTERSPEECH 2016), San Francisco, CA, USA, 8–12 September 2016; pp. 2001–2005. [Google Scholar]
- Sun, Y.; Wen, G. Ensemble softmax regression model for speech emotion recognition. Multimed. Tools Appl. 2017, 76, 8305–8328. [Google Scholar] [CrossRef]
- Kim, N.K.; Lee, J.; Ha, H.K.; Lee, G.W.; Lee, J.H.; Kim, H.K. Speech emotion recognition based on multi-task learning using a convolutional neural network. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 704–707. [Google Scholar]
- Le, D.; Provost, E.M. Emotion recognition from spontaneous speech using hidden markov models with deep belief networks. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Olomouc, Czech Republic, 8–12 December 2013; pp. 216–221. [Google Scholar]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 42nd IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2227–2231. [Google Scholar]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech), Stockholm, Sweden, 20–24 August 2017; pp. 1089–1093. [Google Scholar]
- Zeng, Y.; Mao, H.; Peng, D.; Yi, Z. Spectrogram based multi-task audio classification. Multimed. Tools Appl. 2019, 78, 3705–3722. [Google Scholar] [CrossRef]
- Yi, L.; Mak, M.W. Adversarial data augmentation network for speech emotion recognition. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 529–534. [Google Scholar]
- Xia, R.; Liu, Y. A multi-task learning framework for emotion recognition using 2D continuous space. IEEE Trans. Affect. Comput. 2015, 8, 3–14. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, Y.; Zhang, Z.; Wang, H.; Zhao, Y.; Li, C. Exploring Spatio-Temporal Representations by Integrating Attention-based Bidirectional-LSTM-RNNs and FCNs for Speech Emotion Recognition. In Proceedings of the 19th Annual Conference of the International Speech Communication Association (INTERSPEECH), Hyderabad, India, 2–6 September 2018; pp. 1611–1615. [Google Scholar]
- Guo, L.; Wang, L.; Dang, J.; Zhang, L.; Guan, H.; Li, X. Speech Emotion Recognition by Combining Amplitude and Phase Information Using Convolutional Neural Network. In Proceedings of the 19th Annual Conference of the International Speech Communication Association (INTERSPEECH), Hyderabad, India, 2–6 September 2018; pp. 1611–1615. [Google Scholar]
- Neumann, M.; Vu, N.T. Improving speech emotion recognition with unsupervised representation learning on unlabeled speech. In Proceedings of the 44th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7390–7394. [Google Scholar]
- Freitag, M.; Amiriparian, S.; Pugachevskiy, S.; Cummins, N.; Schuller, B. audeep: Unsupervised learning of representations from audio with deep recurrent neural networks. J. Mach. Learn. Res. 2017, 18, 6340–6344. [Google Scholar]
- Zhao, Z.; Zhao, Y.; Bao, Z.; Wang, H.; Zhang, Z.; Li, C. Deep spectrum feature representations for speech emotion recognition. In Proceedings of the Joint Workshop of the 4th Workshop on Affective Social Multimedia Computing and first Multi-Modal Affective Computing of Large-Scale Multimedia Data, Seoul, Korea, 26 October 2018; pp. 27–33. [Google Scholar]
- Fayek, H.M.; Lech, M.; Cavedon, L. Evaluating deep learning architectures for Speech Emotion Recognition. Neural Netw. 2017, 92, 60–68. [Google Scholar] [CrossRef]
- Etienne, C.; Fidanza, G.; Petrovskii, A.; Devillers, L.; Schmauch, B. Cnn+ lstm architecture for speech emotion recognition with data augmentation. arXiv 2018, arXiv:1802.05630. [Google Scholar]
- Chen, M.; He, X.; Yang, J.; Zhang, H. 3-D convolutional recurrent neural networks with attention model for speech emotion recognition. IEEE Signal Process. Lett. 2018, 25, 1440–1444. [Google Scholar] [CrossRef]
- Sajjad, M.; Kwon, S. Clustering-Based Speech Emotion Recognition by Incorporating Learned Features and Deep BiLSTM. IEEE Access 2020, 8, 79861–79875. [Google Scholar]
- Guo, L.; Wang, L.; Dang, J.; Liu, Z.; Guan, H. Exploration of complementary features for speech emotion recognition based on kernel extreme learning machine. IEEE Access 2019, 7, 75798–75809. [Google Scholar] [CrossRef]
- Meng, H.; Yan, T.; Yuan, F.; Wei, H. Speech emotion recognition from 3D log-mel spectrograms with deep learning network. IEEE Access 2019, 7, 125868–125881. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech emotion recognition from spectrograms with deep convolutional neural network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Korea, 13–15 February 2017; pp. 1–5. [Google Scholar]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Transfer learning for improving speech emotion classification accuracy. arXiv 2018, arXiv:1801.06353. [Google Scholar]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching. IEEE Trans. Multimed. 2017, 20, 1576–1590. [Google Scholar] [CrossRef]
- Wang, Y.; Guan, L. Recognizing human emotional state from audiovisual signals. IEEE Trans. Multimed. 2008, 10, 936–946. [Google Scholar] [CrossRef]
- Zhalehpour, S.; Onder, O.; Akhtar, Z.; Erdem, C.E. BAUM-1: A spontaneous audio-visual face database of affective and mental states. IEEE Trans. Affect. Comput. 2016, 8, 300–313. [Google Scholar] [CrossRef]
- Ajmera, P.K.; Jadhav, D.V.; Holambe, R.S. Text-independent speaker identification using Radon and discrete cosine transforms based features from speech spectrogram. Pattern Recognit. 2011, 44, 2749–2759. [Google Scholar] [CrossRef]
- Hall, M.A.; Smith, L.A. Feature subset selection: A correlation based filter approach. In Proceedings of the International Conference on Neural Information Processing and Intelligent Information Systems; Springer: Berlin, Germany, 1997; pp. 855–858. [Google Scholar]
- MATLAB. Version 7.10.0 (R2010a); The MathWorks Inc.: Natick, MA, USA, 2010. [Google Scholar]
- Chau, V.T.N.; Phung, N.H. Imbalanced educational data classification: An effective approach with resampling and random forest. In Proceedings of the 2013 RIVF International Conference on Computing & Communication Technologies-Research, Innovation, and Vision for Future (RIVF), Hanoi, Vietnam, 10–13 November 2013; pp. 135–140. [Google Scholar]
- Özseven, T. A novel feature selection method for speech emotion recognition. Appl. Acoust. 2019, 146, 320–326. [Google Scholar] [CrossRef]
- Bhavan, A.; Chauhan, P.; Shah, R.R. Bagged support vector machines for emotion recognition from speech. Knowl.-Based Syst. 2019, 184, 104886. [Google Scholar] [CrossRef]
- Haider, F.; Pollak, S.; Albert, P.; Luz, S. Emotion recognition in low-resource settings: An evaluation of automatic feature selection methods. Comput. Speech Lang. 2020, 65, 101119. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | MLP | SVM | RF | KNN |
|---|---|---|---|---|
| Emo-DB | ||||
| SAVEE | ||||
| IEMOCAP | ||||
| RAVDESS |
| Dataset | MLP | SVM | RF | KNN |
|---|---|---|---|---|
| Emo-DB | ||||
| SAVEE | ||||
| IEMOCAP | ||||
| RAVDESS |
| Dataset | MLP | SVM | RF | KNN |
|---|---|---|---|---|
| Emo-DB | ||||
| SAVEE | ||||
| IEMOCAP | ||||
| RAVDESS |
| Dataset | MLP | SVM | RF | KNN |
|---|---|---|---|---|
| Emo-DB | 90.50 ± 2.60 | 85.00 ± 2.95 | 80.15 ± 2.68 | 78.90 ± 2.92 |
| SAVEE | 66.90 ± 5.18 | 65.40 ± 5.21 | 57.20 ± 6.74 | 56.10 ± 6.62 |
| IEMOCAP | 72.20 ± 3.14 | 76.60 ± 3.36 | 71.30 ± 4.31 | 69.28 ± 4.86 |
| RAVDESS | 73.50 ± 3.48 | 69.21 ± 4.69 | 65.28 ± 4.24 | 61.53 ± 4.73 |
| DATASET | Reference | Features | Accuracy (%) |
|---|---|---|---|
| Emo-DB | [59] | openSMILE features | 84.62 |
| [60] | MFCCs, spectral centroids and MFCC derivatives | 92.45 | |
| [40] | Amplitude spectrogram and phase information | 91.78 | |
| [46] | 3-D ACRNN | 82.82 | |
| [49] | ADRNN | 90.78 | |
| Proposed | DCNN + CFS + SVM | 95.10 | |
| SAVEE | [59] | openSMILE features | 72.39 |
| Proposed | DCNN + CFS + SVM | 82.10 | |
| IEMOCAP | [35] | Convolution-LSTM | 68 |
| [39] | Attention-BLSTM | 64 | |
| [45] | CNN + LSTM | 64.50 | |
| [46] | 3-D ACRNN | 64.74 | |
| [49] | ADRNN | 74.96 | |
| Proposed | DCNN + CFS + MLP | 83.80 | |
| RAVDESS | [60] | MFCCs, spectral centroids and MFCC derivatives | 75.69 |
| [36] | Spectrogram + GResNet | 64.48 | |
| Proposed | DCNN + CFS + SVM | 81.30 |
| DATASET | Reference | Features | Accuracy (%) |
|---|---|---|---|
| Emo-DB | [31] | LLDs Stats | 82.40 |
| [61] | Emobase feature set | 76.90 | |
| [37] | OpenSmile features + ADAN | 83.74 | |
| [47] | RESNET MODEL + Deep BiLSTM | 85.57 | |
| [48] | Complementary Features + KELM | 84.49 | |
| [49] | ADRNN | 85.39 | |
| [52] | DCNN + DTPM | 87.31 | |
| Proposed | DCNN + CFS + MLP | 90.50 | |
| SAVEE | [31] | LLDs Stats | 51.50 |
| [61] | eGeMAPs feature set | 42.40 | |
| Proposed | DCNN + CFS + MLP | 66.90 | |
| IEMOCAP | [37] | OpenSmile features + ADAN | 65.01 |
| [38] | IS10 + DBN | 60.9 | |
| [44] | SP + CNN | 64.80 | |
| [47] | RESNET MODEL + Deep BiLSTM | 72.2 | |
| [48] | Complementary Features + KELM | 57.10 | |
| [49] | ADRNN | 69.32 | |
| Proposed | DCNN + CFS + SVM | 76.60 | |
| RAVDESS | Proposed | DCNN + CFS + MLP | 73.50 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farooq, M.; Hussain, F.; Baloch, N.K.; Raja, F.R.; Yu, H.; Zikria, Y.B. Impact of Feature Selection Algorithm on Speech Emotion Recognition Using Deep Convolutional Neural Network. Sensors 2020, 20, 6008. https://doi.org/10.3390/s20216008
Farooq M, Hussain F, Baloch NK, Raja FR, Yu H, Zikria YB. Impact of Feature Selection Algorithm on Speech Emotion Recognition Using Deep Convolutional Neural Network. Sensors. 2020; 20(21):6008. https://doi.org/10.3390/s20216008
Chicago/Turabian StyleFarooq, Misbah, Fawad Hussain, Naveed Khan Baloch, Fawad Riasat Raja, Heejung Yu, and Yousaf Bin Zikria. 2020. "Impact of Feature Selection Algorithm on Speech Emotion Recognition Using Deep Convolutional Neural Network" Sensors 20, no. 21: 6008. https://doi.org/10.3390/s20216008
APA StyleFarooq, M., Hussain, F., Baloch, N. K., Raja, F. R., Yu, H., & Zikria, Y. B. (2020). Impact of Feature Selection Algorithm on Speech Emotion Recognition Using Deep Convolutional Neural Network. Sensors, 20(21), 6008. https://doi.org/10.3390/s20216008