Depth Estimation for Light-Field Images Using Stereo Matching and Convolutional Neural Networks




Abstract
:
1. Introduction
2. Related Work
2.1. Conventional Computer-Vision Methods
2.2. Deep-Learning-Based Methods
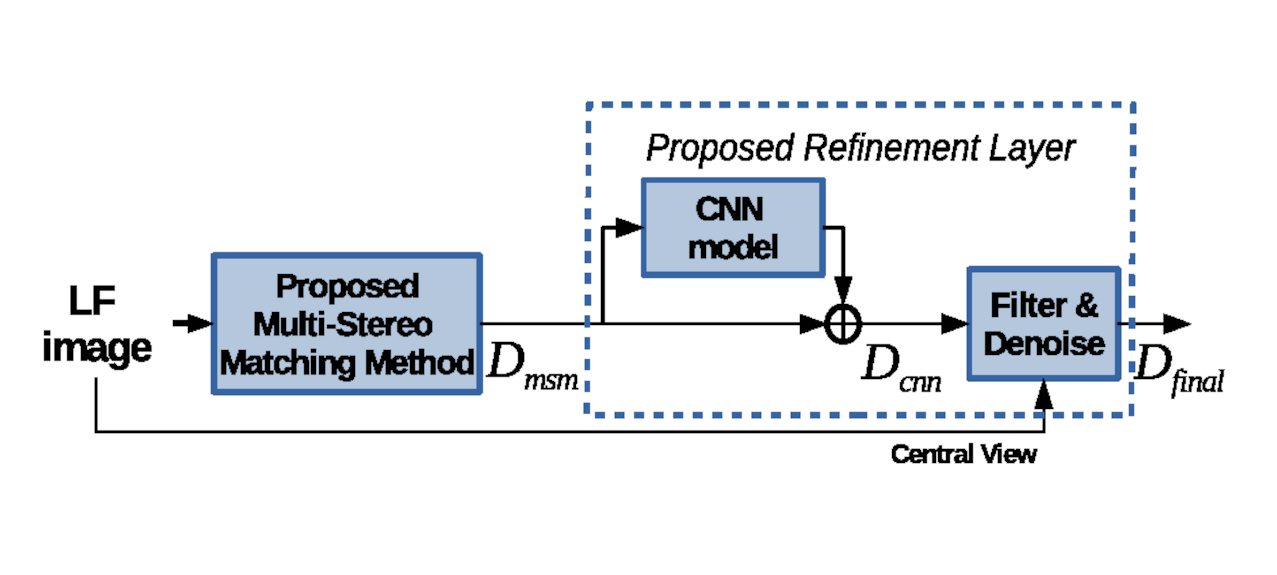
3. Proposed Method
3.1. Multi-Stereo Matching Method
3.1.1. Neighborhood Window Selection
3.1.2. Fusion Algorithm
| Algorithm 1 Disparity maps fusion algorithm |
| Input:k disparity maps , k reliability masks , and k baselines Output: disparity map
|
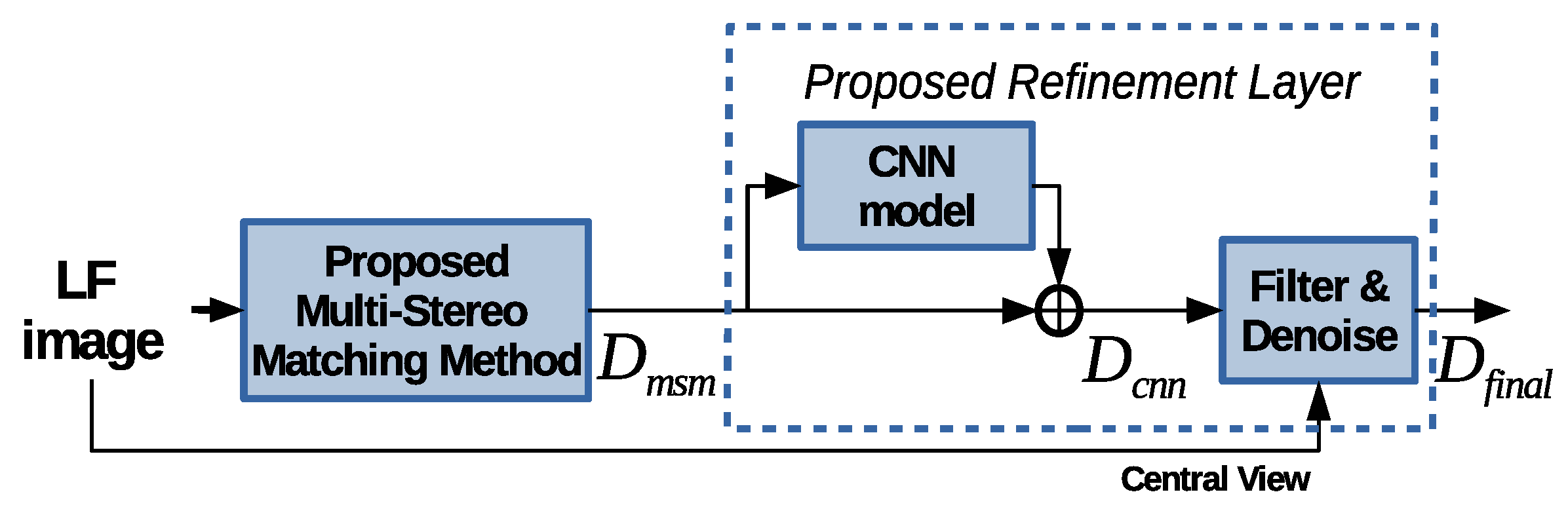
3.2. Deep-Learning-Based Refinement
3.2.1. Training Strategy
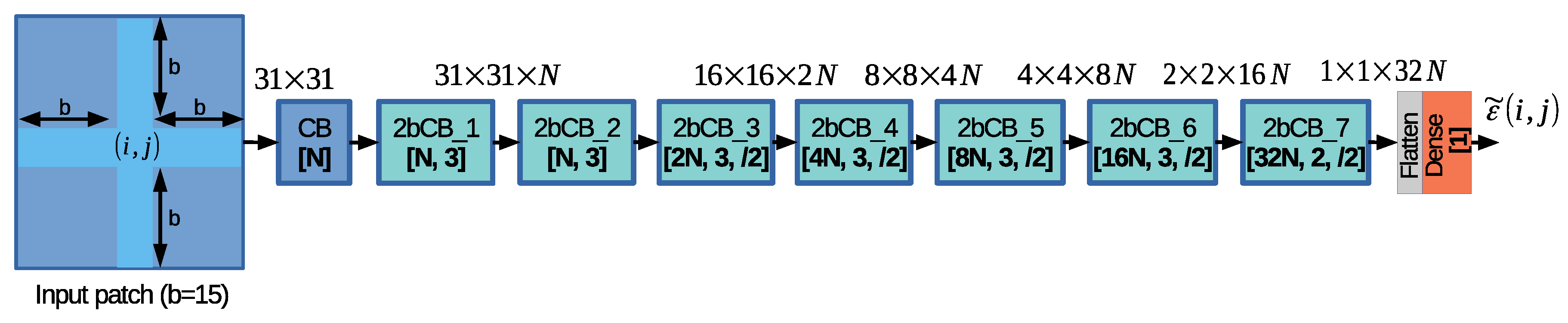
3.2.2. Proposed Neural Network Design
3.2.3. Loss Function Formulation
- (a)
- is the loss term computed as the MSE between and as follows:where m is the number of samples in the batch.
- (b)
- is the regularization term computed as follows:
3.2.4. Final Post-Processing
4. Experimental Evaluation
4.1. Experimental Setup
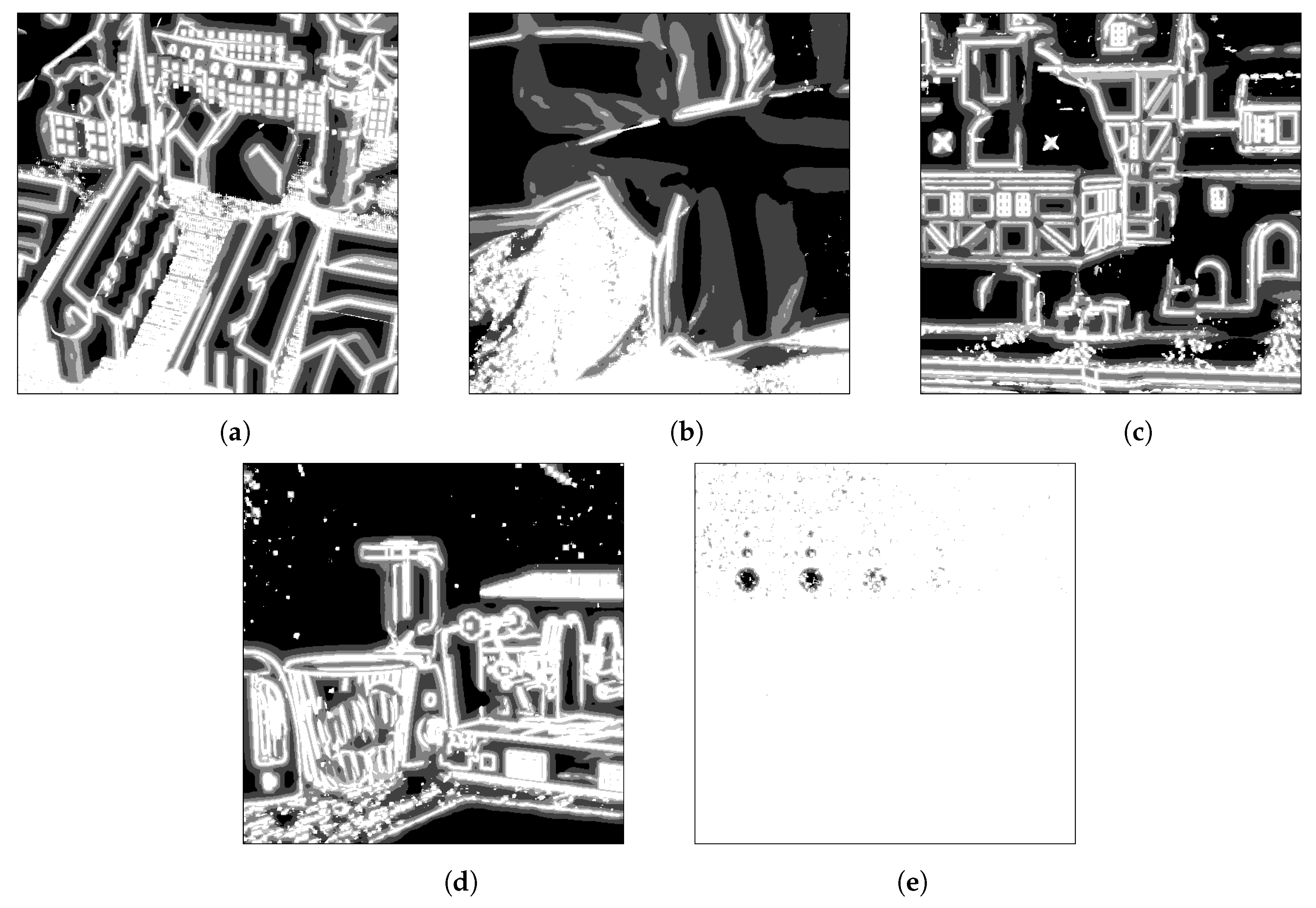
4.2. Experimental Results
4.3. Ablation Study
4.4. Time Complexity
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lin, H.; Chen, C.; Bing Kang, S.; Yu, J. Depth recovery from light field using focal stack symmetry. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3451–3459. [Google Scholar]
- Wang, T.-C.; Efros, A.A.; Ramamoorthi, R. Occlusion-aware depth estimation using light-field cameras. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3487–3495. [Google Scholar]
- Wang, T.-C.; Efros, A.A.; Ramamoorthi, R. Depth estimation with occlusion modeling using light-field cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 2170–2181. [Google Scholar] [CrossRef] [PubMed]
- Jeon, H.-G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.-W.; Kweon, I.S. Accurate depth map estimation from a lenslet light field camera. Comput. Vision Pattern Recognit. 2015, 1547–1555. [Google Scholar] [CrossRef] [Green Version]
- Jeon, H.-G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.-W.; Kweon, I.S. Depth from a light field image with learning-based matching costs. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 297–310. [Google Scholar] [CrossRef]
- Ng, R. Fourier slice photography. ACM Trans. Graph. 2005, 24, 735–744. [Google Scholar] [CrossRef]
- Dansereau, D.G.; Pizarro, O.; Williams, S.B. Decoding, calibration and rectification for lenselet-based plenoptic cameras. Comput. Vis. Pattern Recognit. 2013, 1027–1034. [Google Scholar] [CrossRef]
- Bok, Y.; Jeon, H.-G.; Kweon, I.S. Geometric calibration of microlens-based light field cameras using line features. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 287–300. [Google Scholar] [CrossRef] [PubMed]
- Jarabo, A.; Masia, B.; Bousseau, A.; Pellacini, F.; Gutierrez, D. How do people edit light fields. ACM Trans. Graph. 2014, 33, 4. [Google Scholar] [CrossRef]
- Cho, D.; Kim, S.; Tai, Y.-W. Consistent matting for light field images. In European Conference on Computer Vision, Proceedings of the ECCV 2014: Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Part of the Lecture Notes in Computer Science Book Series; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8692, pp. 90–104. [Google Scholar]
- Galdi, C.; Chiesa, V.; Busch, C.; Correia, P.; Dugelay, J.; Guillemot, C. Light Fields for Face Analysis. Sensors 2019, 19, 2687. [Google Scholar] [CrossRef] [Green Version]
- Farhood, H.; Perry, S.; Cheng, E.; Kim, J. Enhanced 3D Point Cloud from a Light Field Image. Remote Sens. 2020, 12, 1125. [Google Scholar] [CrossRef] [Green Version]
- Tao, M.W.; Srinivasan, P.P.; Malik, J.; Rusinkiewicz, S.; Ramamoorthi, R. Depth from shading, defocus, and correspondence using light-field angular coherence. Comput. Vision Pattern Recognit. 2015, 1940–1948. [Google Scholar] [CrossRef]
- Tao, M.W.; Srinivasan, P.P.; Hadap, S.; Rusinkiewicz, S.; Malik, J.; Ramamoorthi, R. Shape estimation from shading, defocus, and correspondence using light-field angular coherence. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 546–560. [Google Scholar] [CrossRef]
- Schindler, G.; Dellaert, F. 4D Cities: Analyzing, Visualizing, and Interacting with Historical Urban Photo Collections. J. Multimedia 2012, 7. [Google Scholar] [CrossRef] [Green Version]
- Doulamis, A.; Doulamis, N.; Ioannidis, C.; Chrysouli, C.; Nikos, G.; Dimitropoulos, K.; Potsiou, C.; Stathopoulou, E.; Ioannides, M. 5D Modelling: An Efficient Approach for Creating Spatiotemporal Predictive 3D Maps of Large-Scale Cultural Resources. In Proceedings of the ISPRS Annals of Photogrammetry, Remote Sensing and Spatial Information Sciences, Taipei, Taiwan, 31 August–4 September 2015; pp. 61–68. [Google Scholar]
- Bonatto, D.; Rogge, S.; Schenkel, A.; Ercek, R.; Lafruit, G. Explorations for real-time point cloud rendering of natural scenes in virtual reality. In Proceedings of the International Conference on 3D Imaging, Liège, Belgium, 13–14 December 2016; pp. 1–7. [Google Scholar]
- Doulamis, A.; Doulamis, N.; Protopapadakis, E.; Voulodimos, A.; Ioannides, M. 4D Modelling in Cultural Heritage. In Advances in Digital Cultural Heritage; Ioannides, M., Martins, J., Žarnić, R., Lim, V., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10754. [Google Scholar]
- Istenič, K.; Gracias, N.; Arnaubec, A.; Escartín, J.; Garcia, R. Scale Accuracy Evaluation of Image-Based 3D Reconstruction Strategies Using Laser Photogrammetry. Remote Sens. 2019, 11, 2093. [Google Scholar] [CrossRef] [Green Version]
- Bellia-Munzon, G.; Martinez, J.; Toselli, L.; Peirano, M.; Sanjurjo, D.; Vallee, M.; Martinez-Ferro, M. From bench to bedside: 3D reconstruction and printing as a valuable tool for the chest wall surgeon. J. Pediatr. Surg. 2020, in press. [Google Scholar] [CrossRef] [PubMed]
- Ding, Z.; Liu, S.; Liao, L.; Zhang, L. A digital construction framework integrating building information modeling and reverse engineering technologies for renovation projects. Autom. Construct. 2019, 102, 45–58. [Google Scholar] [CrossRef]
- Feng, M.; Wang, Y.; Liu, J. Benchmark data set and method for depth estimation from light field images. IEEE Trans. Image Process. 2018, 27, 3586–3598. [Google Scholar] [CrossRef]
- Shin, C.; Jeon, H.; Yoon, Y.; Kweon, I.S.; Kim, S.J. EPINET: A Fully-Convolutional Neural Network Using Epipolar Geometry for Depth From Light Field Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4748–4757. [Google Scholar]
- Rogge, S.; Ceulemans, B.; Bolsée, Q.; Munteanu, A. Multi-stereo matching for light field camera arrays. In Proceedings of the IEEE European Signal Processing Conference, Rome, Italy, 3–7 September 2018; pp. 251–255. [Google Scholar]
- Schiopu, I.; Munteanu, A. Deep-learning based depth estimation for light field images. Electron. Lett. 2019, 55, 1086–1088. [Google Scholar] [CrossRef]
- Schiopu, I.; Munteanu, A. Residual-error prediction based on deep learning for lossless image compression. IET Electron. Lett. 2018, 54, 1032–1034. [Google Scholar] [CrossRef]
- Schiopu, I.; Munteanu, A. Deep-Learning based Lossless Image Coding. IEEE Trans. Circ. Syst. Video Technol. 2019, 30, 1829–1842. [Google Scholar] [CrossRef]
- Tao, M.; Hadap, S.; Malik, J.; Ramamoorthi, R. Depth from combining defocus and correspondence using light-field cameras. In Proceedings of the International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 673–680. [Google Scholar]
- Tao, M.; Ramamoorthi, R.; Malik, J.; Efros, A.A. Unified Multi-Cue Depth Estimation from Light-Field Images: Correspondence, Defocus, Shading and Specularity; Technical Report No. UCB/EECS-2015-174; University of California: Berkeley, CA, USA, 2015. [Google Scholar]
- Buades, A.; Facciolo, G. Reliable Multiscale and Multiwindow Stereo Matching. SIAM J. Imaging Sci. 2015, 8, 888–915. [Google Scholar] [CrossRef]
- Navarro, J.; Buades, A. Robust and dense depth estimation for light field images. IEEE Trans. Image Process. 2017, 26, 1873–1886. [Google Scholar] [CrossRef] [PubMed]
- Williem, W.; Park, I.K.; Lee, K.M. Robust Light Field Depth Estimation Using Occlusion-Noise Aware Data Costs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2484–2497. [Google Scholar] [CrossRef]
- Huang, C. Empirical Bayesian Light-Field Stereo Matching by Robust Pseudo Random Field Modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 552–565. [Google Scholar] [CrossRef] [PubMed]
- Wanner, S.; Goldluecke, B. Globally consistent depth labeling of 4D light fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 41–48. [Google Scholar]
- Zhang, S.; Sheng, H.; Li, C.; Zhang, J.; Xiong, Z. Robust depth estimation for light field via spinning parallelogram operator. Comput. Vis. Image Understand. 2016, 145, 148–159. [Google Scholar] [CrossRef]
- Mishiba, K. Fast Depth Estimation for Light Field Cameras. IEEE Trans. Image Process. 2020, 29, 4232–4242. [Google Scholar] [CrossRef]
- Spyropoulos, A.; Komodakis, N.; Mordohai, P. Learning to Detect Ground Control Points for Improving the Accuracy of Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1621–1628. [Google Scholar]
- Kim, S.; Min, D.; Ham, B.; Kim, S.; Sohn, K. Deep stereo confidence prediction for depth estimation. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 992–996. [Google Scholar]
- Joung, S.; Kim, S.; Ham, B.; Sohn, K. Unsupervised stereo matching using correspondence consistency. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 2518–2522. [Google Scholar]
- Kim, S.; Min, D.; Ham, B.; Kim, S.; Sohn, K. Unified Confidence Estimation Networks for Robust Stereo Matching. IEEE Trans. Image Process. 2019, 28, 1299–1313. [Google Scholar] [CrossRef]
- Ma, H.; Qian, Z.; Mu, T.; Shi, S. Fast and Accurate 3D Measurement Based on Light-Field Camera and Deep Learning. Sensors 2019, 19, 4399. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Zheng, N.-N.; Suhm, H.-Y. Stereo matching using belief propagation. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 787–800. [Google Scholar]
- Honauer, K.; Johannsen, O.; Kondermann, D.; Goldluecke, B. A dataset and evaluation methodology for depth estimation on 4D light fields. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 19–34. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Favaro, P. Recovering thin structures via nonlocal-means regularization with application to depth from defocus. Comput. Vis. Pattern Recognit. 2010, 1133–1140. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J.-M. Nonlocal image and movie denoising. Int. J. Comput. Vis. 2008, 76, 123–139. [Google Scholar] [CrossRef]
- Kwon, H.; Tai, Y.-W.; Lin, S. Data-driven depth map refinement via multi-scale sparse representation. Comput. Vis. Pattern Recognit. 2015, 159–167. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]


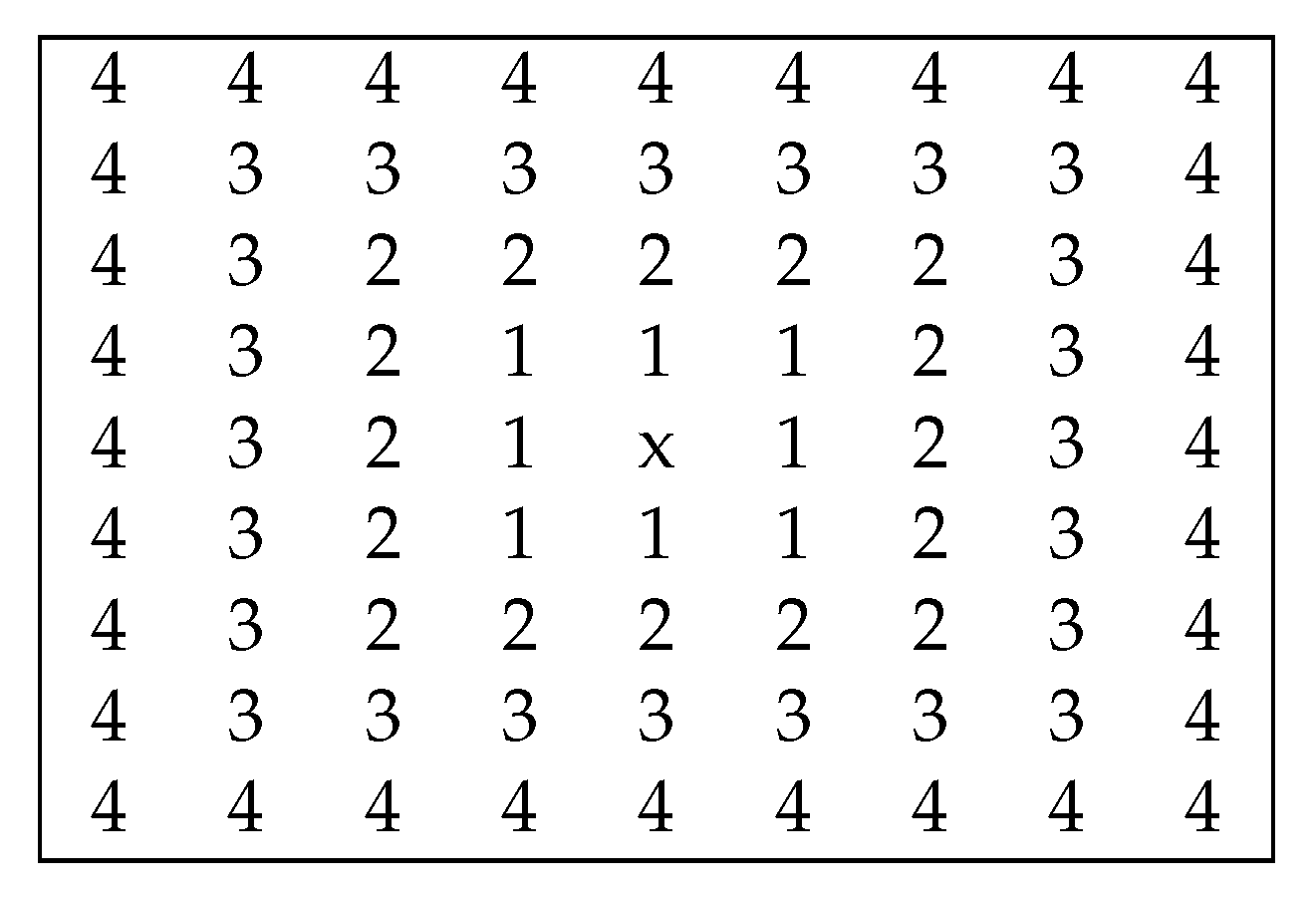




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Metric | LF Image | Average | RG | ||||
|---|---|---|---|---|---|---|---|---|
| Town | Pillows | Medieval2 | Kitchen | Dots | ||||
| Wang et al. [3] | RMSE | 0.3036 | 0.4239 | 0.3874 | 0.4518 | 0.2583 | 0.3650 | 215.19% |
| MAE | 0.2546 | 0.3737 | 0.3040 | 0.3432 | 0.2300 | 0.3011 | 500.54% | |
| SSIM | 0.6897 | 0.7036 | 0.6448 | 0.5823 | 0.7307 | 0.6702 | 22.29% | |
| Williem et al. [32] | RMSE | 0.0826 | 0.0698 | 0.0793 | 0.2818 | 0.2110 | 0.1449 | 25.13% |
| MAE | 0.0410 | 0.0518 | 0.0341 | 0.2109 | 0.1170 | 0.0910 | 81.43% | |
| SSIM | 0.8049 | 0.8327 | 0.8401 | 0.6044 | 0.7075 | 0.7552 | 12.12% | |
| Feng et al. [22] | RMSE | 0.1782 | 0.1403 | 0.1010 | 0.2673 | 0.2127 | 0.1799 | 55.34% |
| MAE | 0.1047 | 0.0971 | 0.0474 | 0.1605 | 0.1282 | 0.1076 | 114.60% | |
| Schiopu et al. [25] | RMSE | 0.1080 | 0.0717 | 0.0928 | 0.2593 | 0.1379 | 0.1339 | 15.65% |
| MAE | 0.0551 | 0.0433 | 0.0540 | 0.1456 | 0.0621 | 0.0720 | 43.62% | |
| SSIM | 0.8175 | 0.9109 | 0.8649 | 0.7107 | 0.7913 | 0.8191 | 5.03% | |
| Proposed Stereo | RMSE | 0.1053 | 0.0756 | 0.0938 | 0.2418 | 0.1493 | 0.1332 | 14.97% |
| MAE | 0.0330 | 0.0309 | 0.0296 | 0.1238 | 0.0903 | 0.0615 | 22.69% | |
| SSIM | 0.8273 | 0.9040 | 0.8850 | 0.6745 | 0.7962 | 0.8174 | 5.22% | |
| Proposed Method | RMSE | 0.0834 | 0.0560 | 0.0819 | 0.2345 | 0.1232 | 0.1158 | anchor |
| MAE | 0.0313 | 0.0302 | 0.0303 | 0.1199 | 0.0390 | 0.0501 | anchor | |
| SSIM | 0.8681 | 0.9232 | 0.9076 | 0.7263 | 0.8869 | 0.8624 | anchor | |
| Method | Metric | LF Image | Average | RG | |||
|---|---|---|---|---|---|---|---|
| Boxes | Boardgames | Tomb | Dino | ||||
| Wang et al. [3] | MAE | 0.3643 | 0.3438 | 0.1942 | 0.3412 | 0.3109 | 363.29% |
| SSIM | 0.4748 | 0.6391 | 0.7212 | 0.5590 | 0.5985 | 26.70% | |
| Williem et al. [32] | MAE | 0.1488 | 0.0296 | 0.0403 | 0.0512 | 0.0675 | 0.54% |
| SSIM | 0.5995 | 0.8082 | 0.8086 | 0.7128 | 0.7323 | 10.32% | |
| Schiopu et al. [25] | MAE | 0.1599 | 0.0423 | 0.0373 | 0.0946 | 0.0836 | 24.52% |
| SSIM | 0.6245 | 0.8647 | 0.8984 | 0.7530 | 0.7852 | 4.00% | |
| Proposed Stereo | MAE | 0.1390 | 0.0225 | 0.0771 | 0.0560 | 0.0737 | 9.77% |
| SSIM | 0.5819 | 0.8614 | 0.8125 | 0.7950 | 0.7627 | 6.60% | |
| Proposed Method | RMSE | 0.1346 | 0.0195 | 0.0693 | 0.0451 | 0.0671 | anchor |
| SSIM | 0.6529 | 0.9305 | 0.8455 | 0.8374 | 0.8166 | anchor | |
| Method | Metric | LF Image | Average | RG | |||
|---|---|---|---|---|---|---|---|
| Pens | Greek | Dishes | Museum | ||||
| Wang et al. [3] | MAE | 0.2428 | 1.2229 | 1.1973 | 0.1967 | 0.7149 | 548.54% |
| SSIM | 0.6107 | 0.4348 | 0.3544 | 0.7282 | 0.5320 | 32.46% | |
| Williem et al. [32] | MAE | 0.0494 | 0.3568 | 0.0721 | 0.0552 | 0.1334 | 21.02% |
| SSIM | 0.7811 | 0.5986 | 0.6345 | 0.8215 | 0.7089 | 10.00% | |
| Schiopu et al. [25] | MAE | 0.0807 | 0.4104 | 0.1290 | 0.1202 | 0.1851 | 67.89% |
| SSIM | 0.7715 | 0.6577 | 0.7727 | 0.7781 | 0.7450 | 5.42% | |
| Proposed Stereo | MAE | 0.1127 | 0.2516 | 0.0632 | 0.0819 | 0.1273 | 15.53% |
| SSIM | 0.6876 | 0.6438 | 0.7884 | 0.7230 | 0.7107 | 9.77% | |
| Proposed Method | RMSE | 0.0933 | 0.2134 | 0.0571 | 0.0771 | 0.1102 | anchor |
| SSIM | 0.7769 | 0.7358 | 0.8417 | 0.7965 | 0.7877 | anchor | |
| Method | Nr. of Trainable Network Param. | Average | Average Relative Gain | Inference Time (s) | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | SSIM | ||||||
| Proposed Stereo | − | 0.1332 | 0.0615 | 0.8174 | 14.97% | 22.69% | 5.22% | − |
| Classification design | 2.4 M (+4.45%) | 0.1182 | 0.0551 | 0.8528 | 2.11% | 9.94% | 1.11% | 24.06 |
| ResLB-based design | 6.3 M (+173.69%) | 0.1175 | 0.0558 | 0.8604 | 1.45% | 11.36% | 0.23% | 25.09 |
| Reduced quantization step | 2.3 M | 0.1200 | 0.0543 | 0.8587 | 3.63% | 8.39% | 0.43% | 24.06 |
| Quarter patch size (b = 7) | 1.2 M | 0.1195 | 0.0563 | 0.8605 | 3.18% | 12.36% | 0.22% | 7.17 |
| Reduced patch size (b = 11) | 2.3 M | 0.1173 | 0.0548 | 0.8609 | 1.31% | 9.43% | 0.17% | 14.34 |
| Proposed Method | 2.3 M | 0.1158 | 0.0501 | 0.8624 | anchor | anchor | anchor | 24.06 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rogge, S.; Schiopu, I.; Munteanu, A. Depth Estimation for Light-Field Images Using Stereo Matching and Convolutional Neural Networks. Sensors 2020, 20, 6188. https://doi.org/10.3390/s20216188
Rogge S, Schiopu I, Munteanu A. Depth Estimation for Light-Field Images Using Stereo Matching and Convolutional Neural Networks. Sensors. 2020; 20(21):6188. https://doi.org/10.3390/s20216188
Chicago/Turabian StyleRogge, Ségolène, Ionut Schiopu, and Adrian Munteanu. 2020. "Depth Estimation for Light-Field Images Using Stereo Matching and Convolutional Neural Networks" Sensors 20, no. 21: 6188. https://doi.org/10.3390/s20216188
APA StyleRogge, S., Schiopu, I., & Munteanu, A. (2020). Depth Estimation for Light-Field Images Using Stereo Matching and Convolutional Neural Networks. Sensors, 20(21), 6188. https://doi.org/10.3390/s20216188