An Efficient Residual-Based Method for Railway Image Dehazing



Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Rail Residual Block
3.2. Network Architecture and Optimization Procedure
| Listing 1 Model optimization for railway image dehazing |
| Input: hazy images and corresponding haze-free images |
| Output: and |
| Number of epochs |
| Initialize weight and parameters |
| repeat |
| while all samples do |
| //Forward Propagation |
| Extract initial features using Equation(5) |
| Extract coarse-grained features using Equation (6) and Equation (5) and Equation (8) |
| Extract fine-grained features using Equation (7) and Equation (5) and Equation (9) |
| Fusion feature using Equation (10) |
| Nonlinear regression using Equation (11) |
| Compute loss between and using Equation (12) |
| //Back propagation |
| Compute derivative of loss function Equation (12) |
| Compute derivative of Equation (5) |
| Update and |
| End |
| Return and |
| until reaches the maximum value |
3.3. Network Parameters Configuration and Mathematical Models
3.4. Loss Functions
4. Dataset and Experiment Set
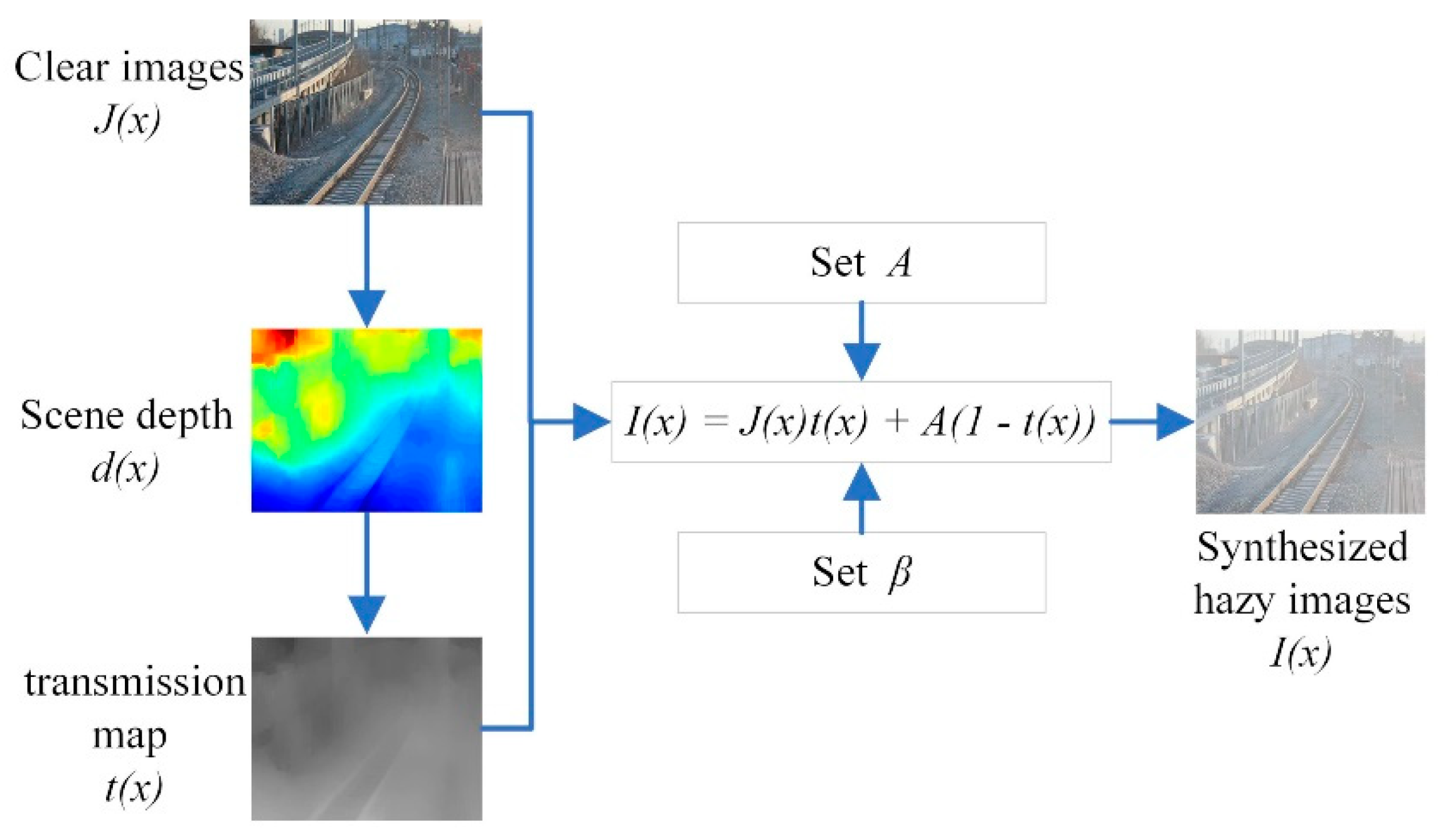
4.1. Synthesized Railway Test Dataset
4.2. Dataset and Details
5. Experiment and Analysis
5.1. Full-Reference Criterion
5.2. Object Detection on Haze Removal Images
5.3. Running Time
5.4. Benchmark Dataset Dehazing Results
5.5. Effect of Combined Loss Function
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, Z.; Jia, L.; Kou, L.; Qin, Y. Spectral kurtosis entropy and weighted SaE-ELM for bogie fault diagnosis under variable conditions. Sensors 2018, 18, 1705. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.; Wang, Z.; Zhang, Z.; Jia, L.; Qin, Y. A semi-supervised approach to bearing fault diagnosis under variable conditions towards imbalanced unlabeled data. Sensors 2018, 18, 2097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, X.; Yang, Z.; Liu, Y.; Wei, D.; Jia, L.; Li, Y. Railway track fastener defect detection based on image processing and deep learning techniques: A comparative study. Eng. Appl. Artif. Intell. 2019, 80, 66–81. [Google Scholar] [CrossRef]
- Liu, Q.; Qin, Y.; Xie, Z.; Yang, T.; An, G. Intrusion Detection for High-Speed Railway Perimeter Obstacle. In Proceedings of the International Conference on Electrical and Information Technologies for Rail Transportation, Changsha, China, 20–22 October 2017; pp. 465–473. [Google Scholar]
- Tan, R.T. Visibility in bad weather from a single image. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Fattal, R. Single image dehazing. ACM Trans. Graph. 2008, 27, 1–9. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [PubMed]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. 2014, 34, 1–14. [Google Scholar] [CrossRef]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.-H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 154–169. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4780–4788. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Joint transmission map estimation and dehazing using deep networks. arXiv 2017, arXiv:1708.00581. [Google Scholar] [CrossRef] [Green Version]
- Chen, D.; He, M.; Fan, Q.; Liao, J.; Zhang, L.; Hou, D.; Yuan, L.; Hua, G. Gated context aggregation network for image dehazing and deraining. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1375–1383. [Google Scholar]
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; John Wiley and Sons, Inc.: New York, NY, USA, 1976; 421p. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Chromatic framework for vision in bad weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head Island, SC, USA, 15 June 2000; pp. 598–605. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Vision and the Atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- Kim, T.K.; Paik, J.K.; Kang, B.S. Contrast enhancement system using spatially adaptive histogram equalization with temporal filtering. IEEE Trans. Consum. Electron. 1998, 44, 82–87. [Google Scholar]
- Stark, J.A. Adaptive image contrast enhancement using generalizations of histogram equalization. IEEE Trans. Image Process. 2000, 9, 889–896. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eschbach, R.; Kolpatzik, B.W. Image-Dependent Color Saturation Correction in a Natural Scene Pictorial Image. U.S. Patent 5,450,217, 12 September 1995. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Contrast restoration of weather degraded images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 713–724. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Li, G.; Fan, H. Image dehazing using residual-based deep CNN. IEEE Access 2018, 6, 26831–26842. [Google Scholar] [CrossRef]
- Li, R.; Pan, J.; Li, Z.; Tang, J. Single image dehazing via conditional generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8202–8211. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11908–11915. [Google Scholar]
- Kratz, L.; Nishino, K. Factorizing scene albedo and depth from a single foggy image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 1701–1708. [Google Scholar]
- Gibson, K.B.; Vo, D.T.; Nguyen, T.Q. An investigation of dehazing effects on image and video coding. IEEE Trans. Image Process. 2011, 21, 662–673. [Google Scholar] [CrossRef] [PubMed]
- Tarel, J.-P.; Hautiere, N. Fast visibility restoration from a single color or gray level image. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 2201–2208. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Levin, A.; Lischinski, D.; Weiss, Y. A closed-form solution to natural image matting. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 30, 228–242. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, K.; Yang, J.; Wang, J. Investigating haze-relevant features in a learning framework for image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2995–3000. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar] [PubMed] [Green Version]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3194–3203. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Multi-scale single image dehazing using perceptual pyramid deep network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 902–911. [Google Scholar]
- Deng, Q.; Huang, Z.; Tsai, C.; Lin, C. HardGAN: A Haze-Aware Representation Distillation GAN for Single Image Dehazing, ECCV. 2020. Available online: https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123510715.pdf (accessed on 15 September 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Nah, S.; Kim, T.H.; Lee, K.M. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Gross, S.; Wilber, M. Training and Investigating Residual Nets. 2016. Available online: http://torch.ch/blog/2016/02/04/resnets.html (accessed on 10 October 2019).
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 694–711. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. Learning depth from single monocular images using deep convolutional neural fields. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Layer | Input Size | Output Size | Number | Input Channels | Output Channels | Filters | Pad | Stride | Scale Factor |
|---|---|---|---|---|---|---|---|---|---|---|
| Initial Feature Extraction | Convolution | 512 × 512 | 512 × 512 | 1 | 3 | 64 | 3 × 3 | 1 | 1 | - |
| Coarse-grained Feature Extraction | Average Pool | 512 × 512 | 128 × 128 | 2 | 64 | 64 | 2 × 2 | 0 | 2 | - |
| RResblock | 128 × 128 | 128 × 128 | 23 | 64 | 64 | 3 × 3 | 1 | 1 | - | |
| Up-sample | 128 × 128 | 512 × 512 | 2 | 64 | 64 | 2 × 2 | 0 | - | 2 | |
| Fine-grained Feature Extraction | Average Pool | 512 × 512 | 256 × 256 | 1 | 64 | 64 | 2 × 2 | 0 | 2 | - |
| RResblock | 256 × 256 | 256 × 256 | 27 | 64 | 64 | 3 × 3 | 1 | 1 | - | |
| Up-sample | 256 × 256 | 512 × 512 | 1 | 64 | 64 | 2 × 2 | 0 | - | 2 | |
| Feature Aggregation | Concatenation | 512 × 1024 | 512 × 512 | 1 | 128 | 64 | 3 × 3 | 1 | 1 | - |
| Convolution | 512 × 512 | 512 × 512 | 3 | 64 | 64 | 3 × 3 | 1 | 1 | - | |
| Convolution | 512 × 512 | 512 × 512 | 1 | 64 | 3 | 3 × 3 | 1 | 1 | - | |
| Nonlinear Regression | Tanh | 512 × 512 | 512 × 512 | 1 | - | - | - | - | - | - |
| Method | He et al. [7] | Berman et al. [32] | Ren et al. [10] | Li et al. [11] | Zhang et al. [33] | Chen et al. [13] | Ours |
|---|---|---|---|---|---|---|---|
| PSNR | 21.0334 | 14.4275 | 21.2306 | 14.4963 | 20.1738 | 22.1744 | 24.0997 |
| SSIM | 0.9166 | 0.7319 | 0.9148 | 0.7987 | 0.8971 | 0.9228 | 0.9233 |
| Method | Haze | He et al. [7] | Berman et al. [32] | Ren et al. [10] | Li et al. [11] | Zhang et al. [33] | Chen et al. [13] | Ours |
|---|---|---|---|---|---|---|---|---|
| Map@.75 | 0.3942 | 0.4308 | 0.4272 | 0.4111 | 0.4241 | 0.4229 | 0.4311 | 0.4325 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Qin, Y.; Xie, Z.; Cao, Z.; Jia, L. An Efficient Residual-Based Method for Railway Image Dehazing. Sensors 2020, 20, 6204. https://doi.org/10.3390/s20216204
Liu Q, Qin Y, Xie Z, Cao Z, Jia L. An Efficient Residual-Based Method for Railway Image Dehazing. Sensors. 2020; 20(21):6204. https://doi.org/10.3390/s20216204
Chicago/Turabian StyleLiu, Qinghong, Yong Qin, Zhengyu Xie, Zhiwei Cao, and Limin Jia. 2020. "An Efficient Residual-Based Method for Railway Image Dehazing" Sensors 20, no. 21: 6204. https://doi.org/10.3390/s20216204
APA StyleLiu, Q., Qin, Y., Xie, Z., Cao, Z., & Jia, L. (2020). An Efficient Residual-Based Method for Railway Image Dehazing. Sensors, 20(21), 6204. https://doi.org/10.3390/s20216204