On the Application of Time Frequency Convolutional Neural Networks to Road Anomalies’ Identification with Accelerometers and Gyroscopes



Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
3.1. Materials
3.2. Methodology
- Normalization and synchronization: As a first step, the data collected from the IMU in each of the 12 vehicles were synchronized among the 20 laps and normalized. A GNSS receiver was also installed in the vehicle and synchronized with the IMU. This process was repeated for different sampling rates: 50, 100, 150, 200 and 250 Hz. All these sampling rates were obtained by downsampling by the related factor (e.g., a factor of 10 for 200 Hz) the initial data collected at 2000 Hz from the IMU. In this paper, we consider only the analysis of the accelerometer data in the Z direction (the vertical direction) and the gyroscope in the Y direction (in the direction of the vehicle). The reason for this choice was to minimize the degrees of freedoms in the analysis and because a heuristic analysis of the data related to the other axes of the accelerometers and gyroscopes showed that the obtained accuracy was inferior to the one obtained using the accelerometer in the Z direction and the gyroscope in the Y direction. This is to expected because the IMUs were mostly stimulated for those axes by the roughness of the road surface, and this is also consistent with literature [11]. In the rest of this paper, the Accelerometer data in the Z direction is called AccZ, and the Gyroscope data in the Y direction is called GyroY. The relationship between the RPY angles and the ENU coordinates was the same as described in [16]. The synchronization was performed by applying the moving variance to the data from the accelerometer and by correlating the results across the laps and the vehicle. As is well known in the literature, full synchronization is not always possible because the vehicles move at different speeds over the road anomalies, and each vehicle has its response to the stimulus created by the road anomaly. On the other side, these are problems derived from data collection in a realistic environment, and such processing issues are likely to be present in any real scenario.
- The entire loop was divided into three different types of segments, and each segment was labeled with type normal, road anomaly identifier (e.g., an asphalt break is RF15), and obstacle identifier (e.g., SB01). There were 4 obstacles (identified with SB01, SB02, SB03 and SB04), 15 road anomalies or road features (identified with RFX and X = 01, …, 15), and 22 normal segments (identified with NORM), which were obviously the majority in the entire loop. Each segment had a time duration of 4 s. This time duration was chosen because it was long enough to include the driving time of a vehicle over each of the road anomalies/obstacles considered in the study. The approach was tested on different driving speeds since each vehicle (of the dataset of 12 vehicles) was driving at a different speed and the speed was different in each loop (20 loops), even for the same vehicle. Then, the data collection was representative of the real-world conditions when vehicle speeds may be different. Indeed, this was the focus of the study to evaluate if the proposed approach was able to compensate the data taken with different speeds. As the segment duration was fixed, the sample length of each segment was obviously longer for higher sampling rates (e.g., a segment was 200 samples long for a sampling rate of 50 Hz). The labels were generated by using the GNSS position and by manually checking for each segment that the road anomaly and the obstacle were correctly assigned to each segment. This manual step was needed because the GNSS accuracy may not be precise enough to identify the precise location of the road anomaly/feature.As we had 12 vehicles for 20 loops, the analysis took into consideration a total of 12 × 20 × 41 segments = 9840 segments based on (4 + 15 + 1) = 20 different classes.
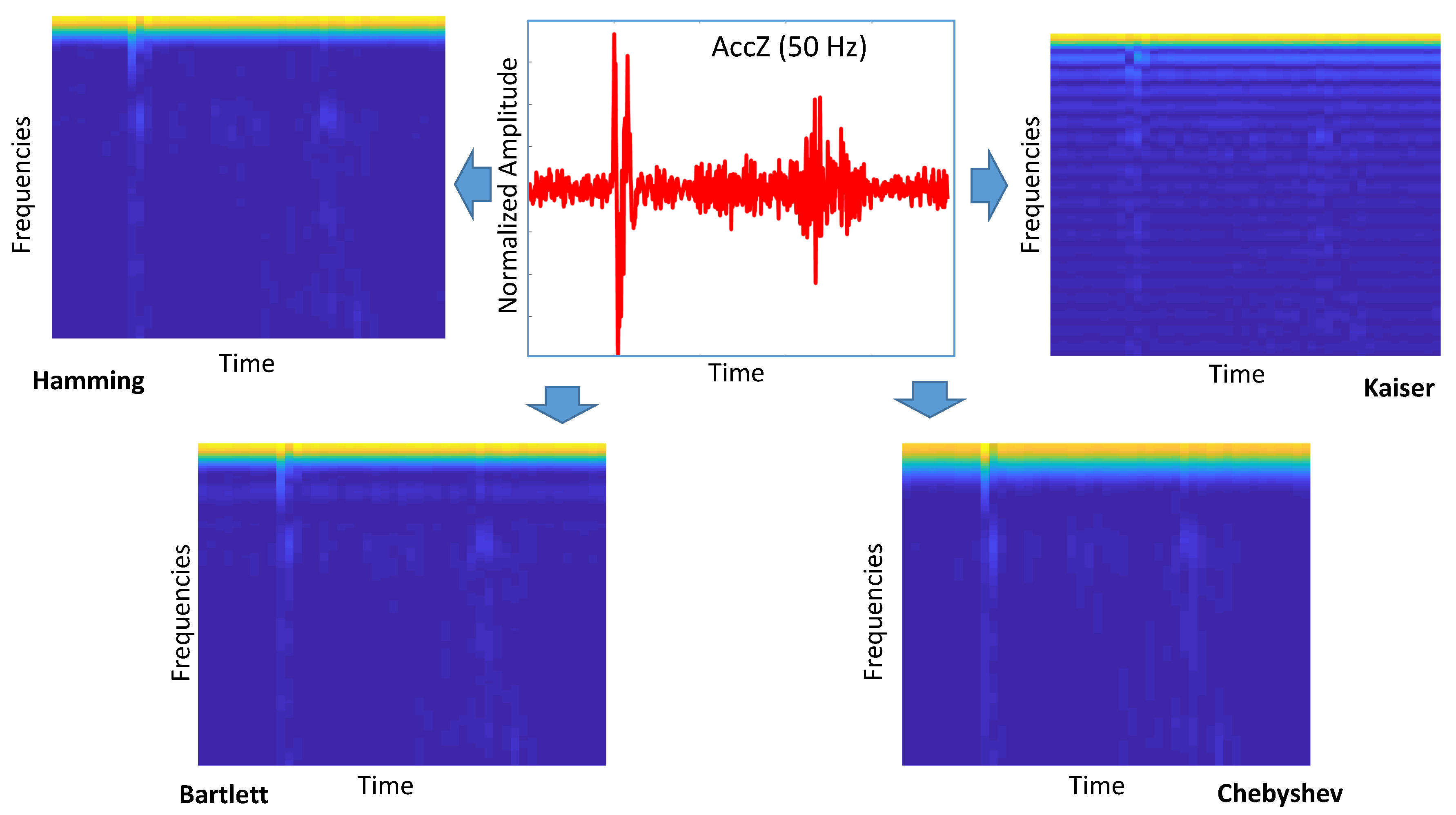
- The spectrogram was applied to the time domain digital output from the IMU (AccZ and GyroY) for the considered sampling rates and by using different values of the hyperparameter. The definition of the spectrogram and its hyperparameters is provided in Section 3.4.
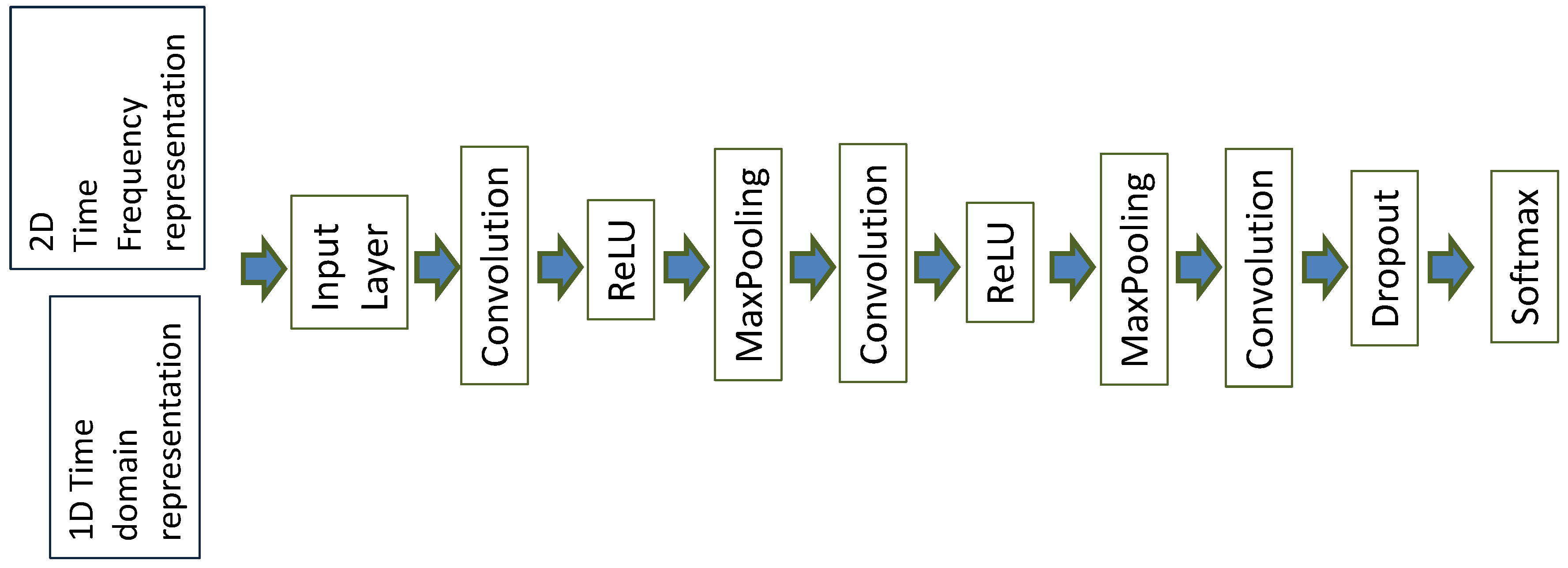
- The segments of the different representations were used as an input to a CNN, which is described in Section 3.3. The initial time segment was also used as the input to three machine learning algorithms, also described in Section 3.3. We note that all the data measurements from the 12 vehicles were used for classification. Then, the classification using CNN was performed on a model based on the data from all 12 vehicles, which enhanced the generalization of the proposed approach in comparison to models based on the data collected by a single vehicle.
3.3. Machine Learning
3.4. Time Frequency Transforms
4. Results
4.1. Optimization of the Spectrogram Hyperparameters
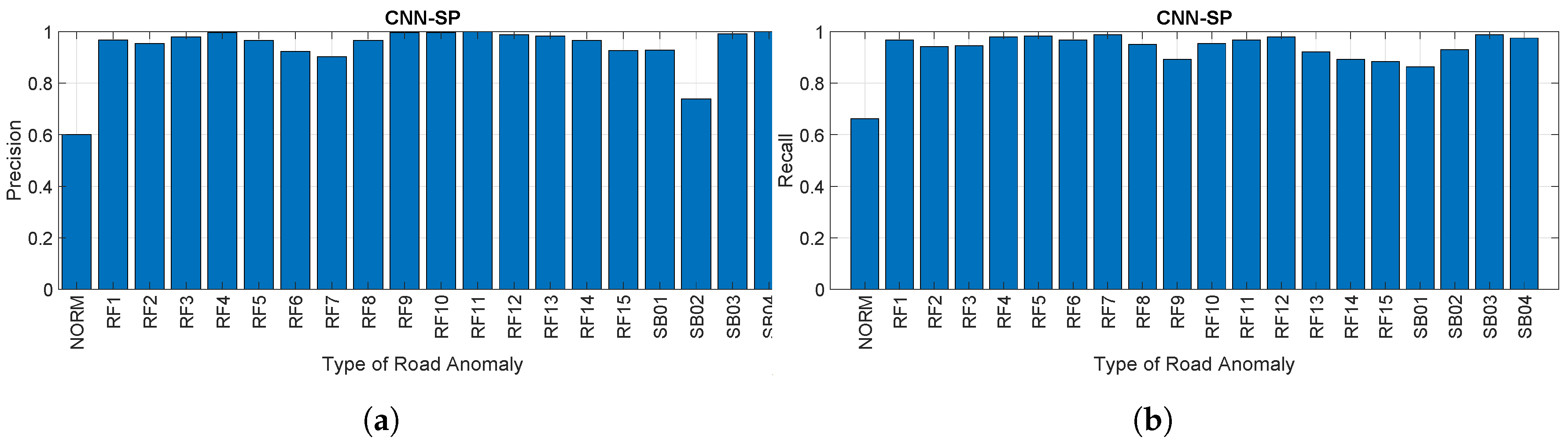
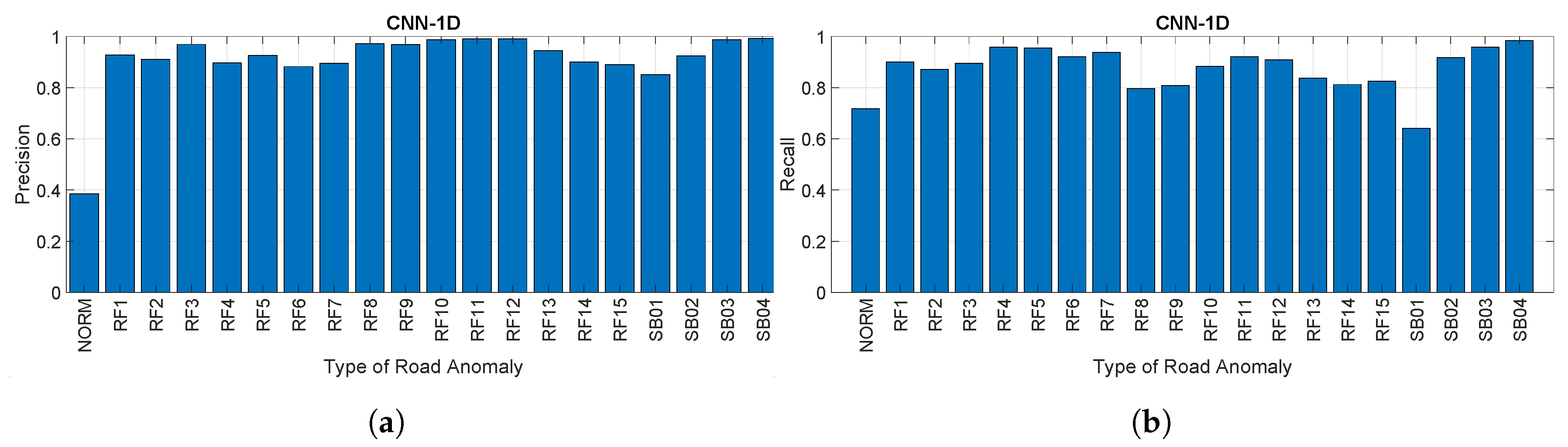
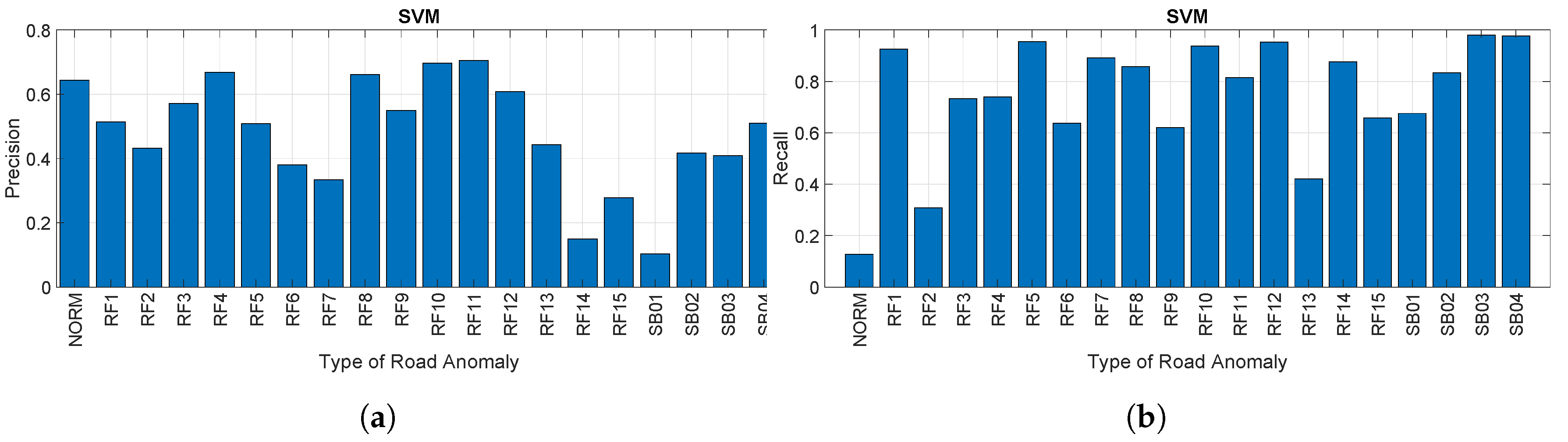
4.2. Analysis and Comparison of the Approaches
4.3. Discussion
5. Conclusions and Future Developments
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| 1D-T | One-Dimensional Time domain |
| CNN | Convolutional Neural Network |
| CNN-1D | Convolutional Neural Network-One-Dimensional |
| CNN-SP | Convolutional Neural Network-Spectrogram |
| CWT | Continuous Wavelet Transform |
| ECOC | Error-Correcting Output Codes |
| FP | False Positive |
| FN | False Negative |
| ENU | East-North-Up |
| GNSS | Global Navigation Satellite System |
| IMU | Inertial Measurement Unit |
| KNN | K Nearest Neighbor |
| LiDAR | Light Detection And Ranging |
| RPY | Role-Pitch-Yaw |
| RBF | Radial Basis Function |
| RF | Road Feature |
| SB | Speed Bump |
| STFT | Short Time Fourier Transform |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True Positive |
References
- Luettel, T.; Himmelsbach, M.; Wuensche, H.J. Autonomous ground vehicles—Concepts and a path to the future. Proc. IEEE 2012, 100, 1831–1839. [Google Scholar] [CrossRef]
- Baldini, G.; Giuliani, R.; Dimc, F. Road safety features identification using the inertial measurement unit. IEEE Sens. Lett. 2018, 2, 1–4. [Google Scholar] [CrossRef]
- Wahlström, J.; Skog, I.; Händel, P. Smartphone-based vehicle telematics: A ten-year anniversary. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2802–2825. [Google Scholar] [CrossRef] [Green Version]
- Menegazzo, J.; von Wangenheim, A. Vehicular Perception Based on Inertial Sensing: A Structured Mapping of Approaches and Methods. SN Comput. Sci. 2020, 1, 1–24. [Google Scholar] [CrossRef]
- Allouch, A.; Koubâa, A.; Abbes, T.; Ammar, A. Roadsense: Smartphone application to estimate road conditions using accelerometer and gyroscope. IEEE Sens. J. 2017, 17, 4231–4238. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection and classification using deep neural networks with smartphone images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Xue, G.; Zhu, H.; Hu, Z.; Yu, J.; Zhu, Y.; Luo, Y. Pothole in the dark: Perceiving pothole profiles with participatory urban vehicles. IEEE Trans. Mob. Comput. 2016, 16, 1408–1419. [Google Scholar] [CrossRef]
- Luo, D.; Lu, J.; Guo, G. Road Anomaly Detection Through Deep Learning Approaches. IEEE Access 2020, 8, 117390–117404. [Google Scholar] [CrossRef]
- Sattar, S.; Li, S.; Chapman, M. Road surface monitoring using smartphone sensors: A review. Sensors 2018, 18, 3845. [Google Scholar] [CrossRef] [Green Version]
- Mednis, A.; Strazdins, G.; Zviedris, R.; Kanonirs, G.; Selavo, L. Real time pothole detection using android smartphones with accelerometers. In Proceedings of the 2011 International Conference on Distributed Computing in Sensor Systems and Workshops (DCOSS), Barcelona, Spain, 27–29 June 2011; pp. 1–6. [Google Scholar]
- Eriksson, J.; Girod, L.; Hull, B.; Newton, R.; Madden, S.; Balakrishnan, H. The pothole patrol: Using a mobile sensor network for road surface monitoring. In Proceedings of the 6th International Conference on Mobile Systems, Applications, and Services, Breckenridge, CO, USA, 17–20 June 2008; pp. 29–39. [Google Scholar]
- Kalim, F.; Jeong, J.P.; Ilyas, M.U. CRATER: A crowd sensing application to estimate road conditions. IEEE Access 2016, 4, 8317–8326. [Google Scholar] [CrossRef]
- Du, R.; Qiu, G.; Gao, K.; Hu, L.; Liu, L. Abnormal road surface recognition based on smartphone acceleration sensor. Sensors 2020, 20, 451. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varona, B.; Monteserin, A.; Teyseyre, A. A deep learning approach to automatic road surface monitoring and pothole detection. Pers. Ubiquitous Comput. 2019, 24, 519–534. [Google Scholar] [CrossRef]
- Baldini, G.; Geib, F.; Giuliani, R. Continuous authentication of automotive vehicles using inertial measurement units. Sensors 2019, 19, 5283. [Google Scholar] [CrossRef] [Green Version]
- Celaya-Padilla, J.M.; Galván-Tejada, C.E.; López-Monteagudo, F.E.; Alonso-González, O.; Moreno-Báez, A.; Martínez-Torteya, A.; Galván-Tejada, J.I.; Arceo-Olague, J.G.; Luna-García, H.; Gamboa-Rosales, H. Speed bump detection using accelerometric features: A genetic algorithm approach. Sensors 2018, 18, 443. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Arel, I.; Rose, D.C.; Karnowski, T.P. Deep machine learning-a new frontier in artificial intelligence research [research frontier]. IEEE Comput. Intell. Mag. 2010, 5, 13–18. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Zhang, M.L.; Zhou, Z.H. A k-nearest neighbor based algorithm for multi-label classification. In Proceedings of the 2005 IEEE International Conference on Granular Computing, Beijing, China, 25–27 July 2005; Volume 2, pp. 718–721. [Google Scholar]
- Oppenheim, A.V. Discrete-Time Signal Processing; Pearson Education India: Delhi, India, 1999. [Google Scholar]
- Lilly, J.M.; Olhede, S.C. Generalized Morse wavelets as a superfamily of analytic wavelets. IEEE Trans. Signal Process. 2012, 60, 6036–6041. [Google Scholar] [CrossRef] [Green Version]
- Olhede, S.C.; Walden, A.T. Generalized morse wavelets. IEEE Trans. Signal Process. 2002, 50, 2661–2670. [Google Scholar] [CrossRef] [Green Version]
- Harikrishnan, P.; Gopi, V.P. Vehicle vibration signal processing for road surface monitoring. IEEE Sens. J. 2017, 17, 5192–5197. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Car | Manufacturer | Model | Generation | Version |
|---|---|---|---|---|
| 1 | Fiat Automobiles (Turin, Italy) | Panda | 2nd | Active |
| 2 | Fiat Automobiles (Turin, Italy) | Panda | 2nd | Active |
| 3 | Fiat Automobiles (Turin, Italy) | Panda | 2nd | Active |
| 4 | Fiat Automobiles (Turin, Italy) | Panda | 2nd | Active |
| 5 | Fiat Automobiles (Turin, Italy) | Panda | 2nd | Active |
| 6 | Fiat Automobiles (Turin, Italy) | Panda | 2nd | Active |
| 7 | Fiat Automobiles (Turin, Italy) | Punto | 2nd | 3-door |
| 8 | Fiat Automobiles (Turin, Italy) | Doblo | 1st | Facelift |
| 9 | Fiat Automobiles (Turin, Italy) | Tipo | 3rd | Hatchback |
| 10 | Mitsubishi (Tokyo, Japan) | Colt | 6th | CZ3 |
| 11 | Škoda Auto (Mladá Boleslav, Czech Republic) | Octavia | 3rd | Estate |
| 12 | Mazda Motor Corp. (Hiroshima, Japan) | Mazda3 | 4th | Hatchback |
| Accelerometer | ||
| Parameter | Measurement unit | Value |
| Standard full range | m/s | 200 |
| Initial bias error | m/s | 0.05 |
| In-run bias stability | g | 15 |
| Bandwidth (−3 dB) | Hz | 375 |
| Non-linearity | % | 0.01 |
| Gyroscope | ||
| Parameter | Measurement unit | Value |
| Standard full range | /s | 450 |
| Initial bias error | /s | 0.2 |
| In-run bias stability | g | 10 |
| Bandwidth (−3 dB) | Hz | 415 |
| Non-linearity | % | 0.1 |
| Machine Learning Algorithm | Hyperparameter Name | Optimal Hyperparameter Value | Optimal Hyperparameter Range |
|---|---|---|---|
| CNN | Number of filters (Nf) | 20, …, 40 | |
| CNN | Solver | RMSProp | Choice between RMSProp, stochastic gradient descent and stochastic gradient descent with momentum |
| CNN | L2 | 0.001 | 0.0001, …, 0.01 |
| CNN | Batch size | 128 | 64, …, 256 |
| CNN | Number of Convolutional layers (NC) | 2, …, 5 | |
| SVM | Kernel | RBF | Choice between linear, RBF, and polynomial (orders 2 and 3) kernels |
| SVM | RBF scaling factor | , …, | |
| SVM | C factor | , …, | |
| KNN | K factor | 5 | 1, …, 20 |
| KNN | Distance | Euclidean distance | Choice between Euclidean, Manhattan, Chebyschev, and Mahalanobis distances |
| Machine Learning Algorithm and Representation | Accuracy |
|---|---|
| CNN-SP (magnitude) (Hamming window ) | 0.9720 |
| CNN with STFT (phase) (Hamming window ) | 0.8047 |
| CWT-CNN (magnitude and Morlet wavelet) | 0.9421 |
| CWT-CNN (phase and Morlet wavelet) | 0.7812 |
| CNN-1D | 0.9354 |
| SVM | 0.7422 |
| KNN | 0.6728 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baldini, G.; Giuliani, R.; Geib, F. On the Application of Time Frequency Convolutional Neural Networks to Road Anomalies’ Identification with Accelerometers and Gyroscopes. Sensors 2020, 20, 6425. https://doi.org/10.3390/s20226425
Baldini G, Giuliani R, Geib F. On the Application of Time Frequency Convolutional Neural Networks to Road Anomalies’ Identification with Accelerometers and Gyroscopes. Sensors. 2020; 20(22):6425. https://doi.org/10.3390/s20226425
Chicago/Turabian StyleBaldini, Gianmarco, Raimondo Giuliani, and Filip Geib. 2020. "On the Application of Time Frequency Convolutional Neural Networks to Road Anomalies’ Identification with Accelerometers and Gyroscopes" Sensors 20, no. 22: 6425. https://doi.org/10.3390/s20226425