1. Introduction
In order to asses water safety and quality, it is necessary to perform toxic phytoplankton analysis and quantification. This procedure is usually performed by expert taxonomists by manual counting on the microscope. Expert assessment usually achieves low recall rates (75%) in water samples with high debris concentration [
1], and mean species identification rates below 73.7% [
2]. Manual phytoplankton analysis also shows lack of agreement between experts and criteria discrepancies of the same expert in different conditions. The variation among experts is reported to be approximately 42% or 43% [
3,
4]. The disparity in the assessment of the same expert has been measured to be between 67% and 83% [
3]. These procedures may be automated to improve the objectivity and repeatability of the process, releasing the experts from tedious and time-consuming work.
The state of the art automatic procedures are focused on several stages of the process: (1) the sample gathering, (2) the automatic detection and segmentation of the specimens, and (3) the identification and counting of species. This work is focused on providing a novel solution to the automatic detection and segmentation of phytoplankton specimens is conventional microscope images, aiming at the application of automatic identification and quantification techniques using readily available equipment in the laboratories.
Data gathering in state-of-the-art solutions usually relies on robotic contraptions that can capture images of plankton specimens in the water without human intervention. Some notable examples are Shadowed Image Particle Profiling and Evaluation Recorder (SIPPER) [
5], Video Plankton Recorder (VPR) [
6,
7], FlowCytobot [
8] and KRIP [
9] or FlowCam [
3,
10,
11], among others [
12,
13,
14].
On the other hand, the automatic detection and segmentation of phytoplankton specimens is approached in a different way depending on the kind of images acquired from each device. In this regard, some of the previous devices, like VPR [
6,
7] or KRIP [
9], provide images with multiple specimens. In these works, simple image processing approaches have been proposed to detect and segment each separate specimen in the images. However the detection and segmentation methods used are usually designed ad-hoc for the imaging features of each device. Differently, other devices like FlowCytobot [
8], FlowCam [
3,
10,
11] and others [
5,
12,
14] use flow cytometry imaging techniques to directly obtain single specimen images during the imaging process. Cytometry works by passing the water sample through a thin tube in which only a single specimen can fit, and performing the microscopic imaging there. While these techniques allow to separate each specimen in a single image, they require to change of the flow cell depending on the size of the specimens to be analysed [
15]. Moreover, an additional classification stage is necessary to differentiate between target phytoplankton specimens and other objects in the water sample, which are also detected and imaged.
Finally, the taxonomic identification and counting of the phytoplankton species is usually approached using machine learning approaches applied to single-specimen images [
16,
17,
18,
19,
20,
21,
22]. Most of the existent works use images obtained with flow imaging approaches, like FlowCytobot [
21,
22], FlowCam [
16] or other types of cytometer [
20,
23].
The taxonomic identification from single-specimen images has experimented a remarkable research interest in many recent works, and achieved satisfactory results on several identification targets. In this sense, some works have focused on the phytoplankton identification at the genus level [
22,
24], while others are focused on the accurate identification of a limited set of target species [
20,
21]. It is also common to focus on only identifying members of a single group like diatoms [
17,
18,
19].
In these works, several machine learning approaches have been explored, ranging from classical approaches to deep learning. For example, in regards to classical machine learning methods, several works have explored SVMs [
24,
25] as well as a variety of other methods [
2,
19,
22]. Deep learning has also been tested in this topic, particularly CNNs of various designs [
17,
20]. Moreover, transfer learning was also successfully applied to taxonomic identification of phytoplankton [
21].While there are still some open issues in the taxonomic identification of single-specimen phytoplankton images, these are out of the scope of this paper. Nevertheless, it should be noted that most of the identification advances of the existent approaches, especially the most recent works based on deep learning, can be directly applied to any single-specimen image regardless of its imaging source.
Thus, the access to most of the recent advances in automatic phytoplankton analysis is tied to ability to automatically obtain single-specimen images of phytoplankton. However, the state of the art is dominated by the use of automatic imaging devices which are not readily available in most of laboratories worldwide. Instead, the most prevalent phytoplankton analysis method is to manually gather and process the water samples and manually inspect them using regular light microscopes. In this sense, as regular microscopes equipped with digital cameras are widely available, it is relatively affordable to obtain digital images of water samples from the routine work of laboratory technicians. Thus, it would be desirable to provide automatic analysis solutions that can take advantage of these conventional microscope images, so that an automatic analysis solution, aiming at releasing the expert taxonomists from tedious identification and counting works, can be made available at low cost. However, to the best of our knowledge, these images have not been the target of automated analyses, with the exception of some few related works [
26,
27,
28].
Some of these related works propose to use fluorescence imaging and the integration of images with multiple focal points [
26,
27], or even multiple magnifications [
27]. While this eases the detection and segmentation of phytoplankton specimens, it involves a complicated imaging protocol, which probably requires the use of computerised microscopes [
26,
27]. In other works [
28], the proposed imaging method can not even be performed in a systematic way, as they require an human expert to select the appropriate focal point and magnification used for each of the imaged species. Conversely, this work is focused on the analysis of conventional microscope images that are acquired using a systematic imaging protocol aiming at minimising the required human intervention. Specifically, the images are captured at a fixed magnification and focal point which could allow its application without the intervention of an expert taxonomist.
In this work, we propose a novel fully automatic computational approach to detect and separate the individual phytoplankton specimens that are present on multi-specimen microscope images. The proposed solution aims to be a preliminary approach that aims being able to systematically apply the most recent advances in automatic phytoplankton identification using conventional microscopy. Detecting separate specimens in microscope water samples is a challenging task due to the high variability of the phytoplankton species, specially in fresh water samples, and the presence of diverse types of debris.
The proposed preliminary approach consists in a fully automatic pipeline based on classical algorithms for segmentation and novel methods for the fusion of specimens. This method also makes use of machine learning approaches capable of differentiating phytoplankton from the many spurious objects present in the images like zooplankton, garbage or minerals by exploiting texture and colour information. This preliminary approach is a baseline for further research that intends to continue advancing in this area.
3. Experimental Setup
3.1. Phytoplankton Sampling and Microscopy
A 2 L water sample was collected at a depth of 3 m using a van Dorn bottle in the coastal freshwater lake of Doniños (Ferrol, Galicia, Spain) (UTM 555593 X, 4815672 Y; Datum ETRS89) on 16 November 2017. The phytoplankton sample was concentrated by filtering volume of
L through GF/F glass fiber filters and was then resuspended in 50 mL. Phytoplankton samples were preserved using 5% (
v/
v) glutaraldehyde, because it is efficient at preserving both cellular structures and pigment [
45,
46,
47,
48]. The fixed sample was stored in the dark at constant temperature (10 °C) until analysis.
The phytoplankton sample was homogenised for 2 min prior to microscopic examination. In addition, the sample was subjected to vacuum for one minute to break the vacuoles of some cyanobacterial taxa and prevent them from floating. The data on the taxonomic composition and abundances of the different taxa in the water sample, characterised by quantitative analysis in a Ütermohl sedimentation chamber [
49] using a Nikon TMD inverted microscope equipped with a Plan Phase Contrast
objective (N.A. 0.60), is detailed in
Table S1. In summary, the sample had a density of 9018 cells per ml, with a total of 51 taxa and the following relative abundances of the main taxonomic groups: Chlorophyceae 56.77% (i.a.
Botryococcus braunii Kützing,
Volvox aureus Ehrenberg,
Dictyosphaerium pulchellum H.C. Wood), Cyanobacteria 24.95% (i.a.
Woronichinia naegeliana (Unger) Elenkin,
Microcystis flos-aquae (Wittrock) Kirchner,
Anabaena spiroides Klebahn) and Bacillariophyceae (diatoms) 15.29% (i.a.
Aulacoseira granulata var.
armata (Ehrenberg) Simonsen,
Fragilaria crotonensis Kitton).
3.2. Digital Image Dataset
Aliquots of the phytoplankton sample with a total volume of 1 mL were examined under light microscopy using a Nikon Eclipse E600 equipped with an E-Plan objective (N.A. 0.25). Light microscopy images were taken with an AxioCam ICc5 Zeiss digital camera (12 Megapixels), maintaining the same illumination and focus throughout the image acquisition process and following regular transects until the entire surface of the sample was covered.
However, taking images at this magnification complicates the systematic application of an automatic approach due to several reasons. First, because there is size heterogeneity and diversity of taxa inherent to phytoplankton samples, which prevents the observation of whole organisms of some species at magnification. This also means that careful ad-hoc framing of the imaging field by the microscope operator for most specimens would be required. Second, the aperture of large magnification objectives is usually larger, resulting in a much lower depth of focused plane. Thus, using magnification would usually require varying the focus while examining each individual. Finally, the larger magnification also means a smaller field of view. Therefore, the use of objectives would require the imaging of a larger number of transects to cover the whole sample field. Reducing the magnification to minimises all these drawbacks and provides more suitable images for the automatic analysis.
The resulting digital image dataset is comprised of 211 digital microscopy images obtained from the described water sample. The 12 Mpx at magnification result in an approximate resolution of pixels per μm. Each of these images contain several phytoplankton specimens of varying taxa. Overall, the set of images contains 1209 true phytoplankton specimens that can be divided among 51 different species along with a significant amount of other objects like zooplankton, inert organic matter, minerals, etc, which are identified as non-phytoplankton.
A random subset of 50 images was used for training while the rest were reserved for testing. The ground truth consists of bounding boxes enclosing the phytoplankton specimens, which were marked by an expert.
3.3. Experimental Evaluation
The experimentation consisted in the evaluation of the initial candidate detection, quality of segmentation and the final phytoplankton detection.
The candidate detection stage is evaluated in terms of false negative rates (FNR). Detections are counted as positive when their bounding box overlaps at least 50% of the true specimen. The parameters of the foreground-background separation and the initial candidate detection stage are empirically optimised to minimize the FNR by only observing the training set.
The quality of the segmentation is evaluated by the production of over and undersegmentations. Oversegmentation occurs when two or more boxes cover a specimen that should only be detected by one. Undersegmentation is the opposite, two or more specimens are enclosed in the same bounding box. This evaluation also serves to measure the impact of the novel colony merging stage. To that end, the parameters of the colony merging are selected to provide a satisfactory under/over-segmentation balance in the training set.
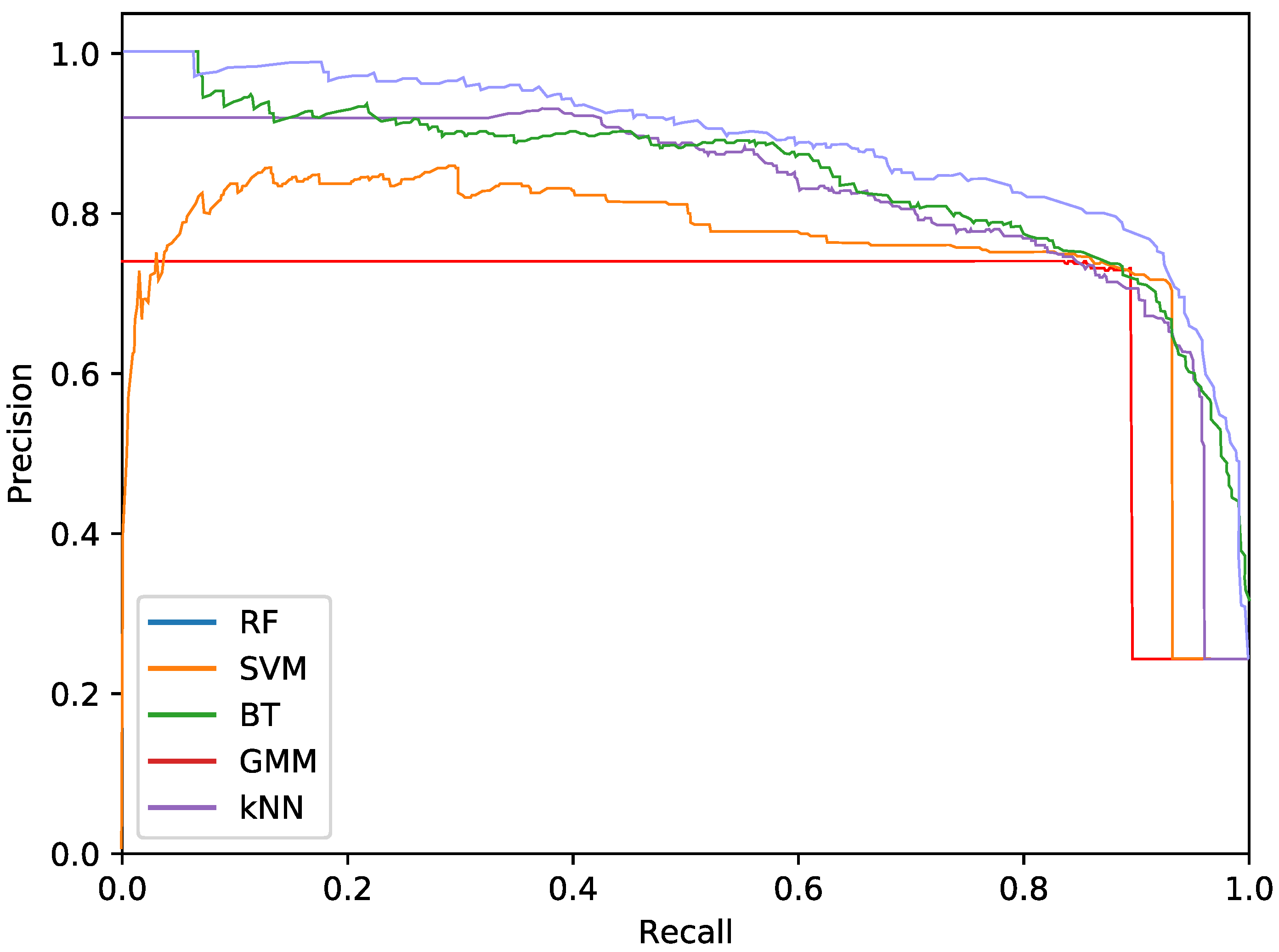
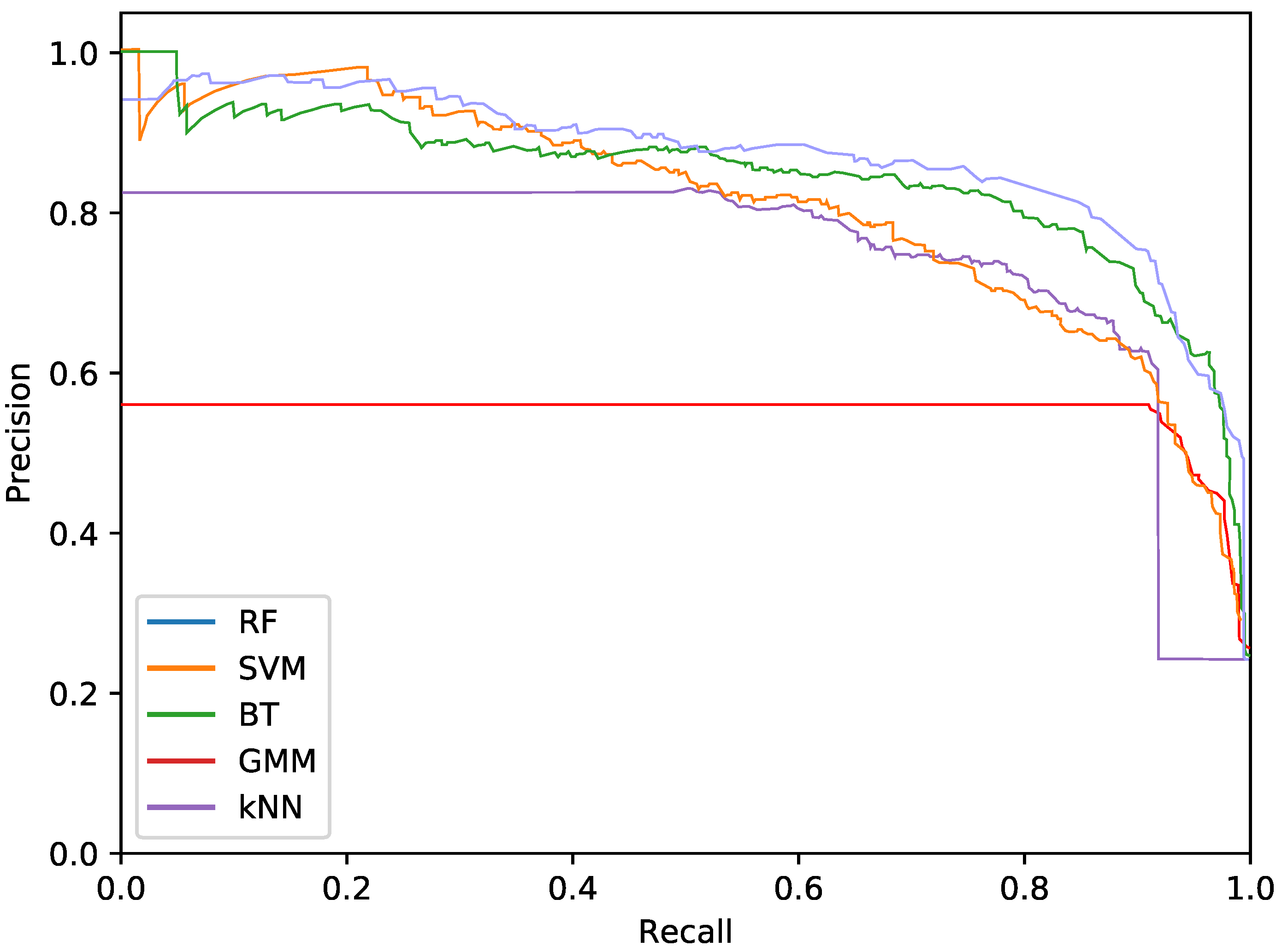
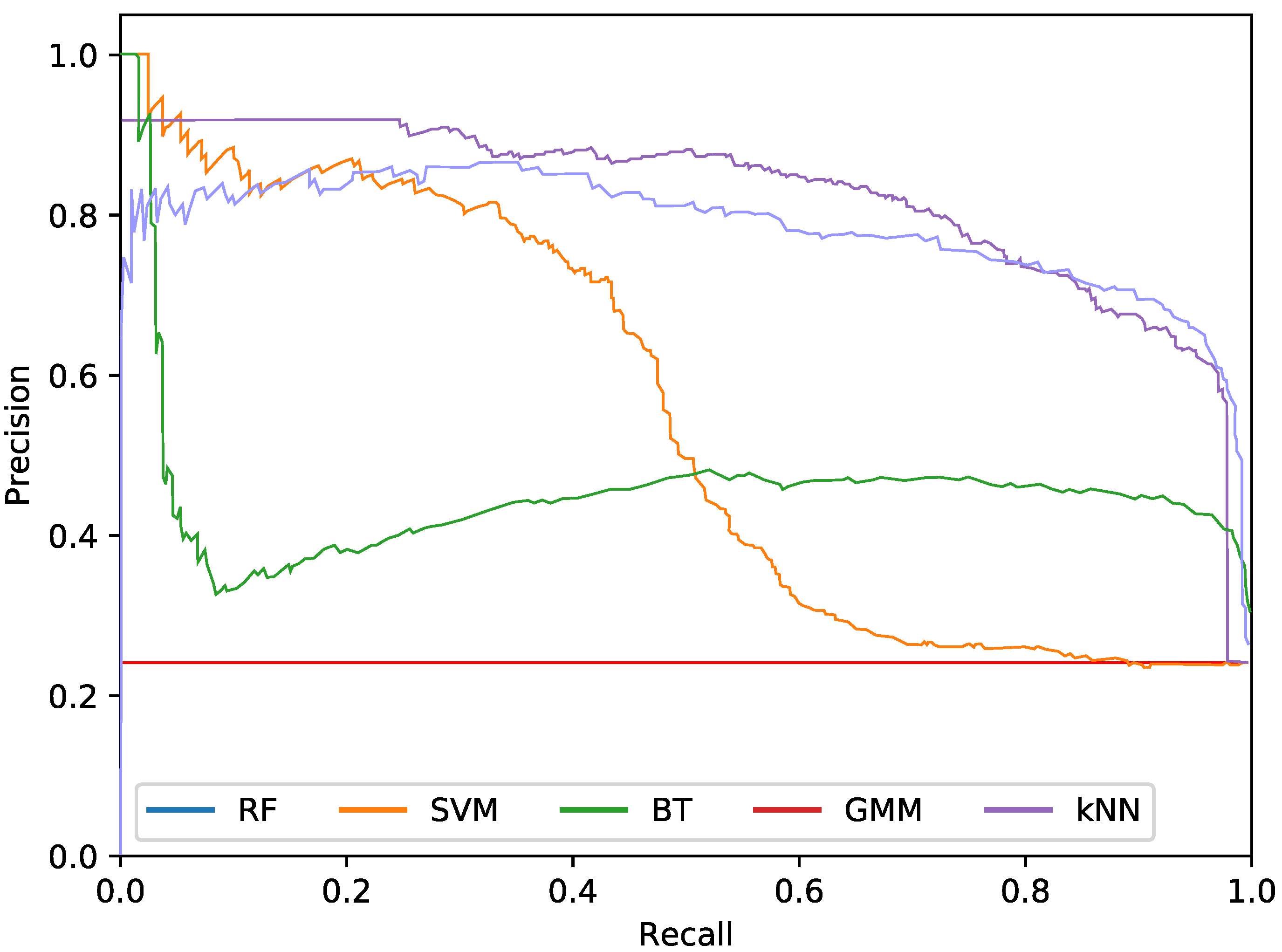
The final phytoplankton detection is evaluated using precision at high levels of recall, namely 90% and 95%. This is due to the intention of preserving most of the phytoplankton specimens in an imbalanced dataset. Additionally, precision-recall (PR) curves are used to illustrate the performance of the optimised systems. PR curves are also used instead of Receiver Operating Characteristic (ROC) curves due to the imbalanced nature of the problem.
For the phytoplankton detection stage, we tested RF, SVM, kNN, BT and GMM classifiers with the described colour and texture feature sets alone or both. For each of these classifiers, using either colour or texture features (i.e., alternatives), we performed a cross-validated grid search over the training set, to select the optimal parameters. To that end, Precision at 90% recall was used as the fitness measurement for the parameter selection. This metric was chosen instead of the more common Area Under Curve (AUC) for the PR curves due to cases where the AUC was misleading, reporting high values for systems with poor precision at high levels of recall. This meant that, even if the overall AUC was high due to the system performing well under lower quantities of recall, it could not be accepted due to the poor performance at the highest levels. As in this work we are focused on detecting the highest amount of true phytoplankton, therefore, precision at 90% recall more akin to our goal.
The grid search included hyper-parameters of the classifiers along with the free parameters of the proposed BoVW descriptors. Specifically, the number of visual words ( and , for colour and texture, respectively) was selected among 100, 50, 20, 10, 8, 5, 3 and 2. Additionally, for the texture descriptors, the centre frequency is selected among 0.5, 0.3535, 0.25, 0.177, 0.125, 0.088, 0.0625, 0.0442, 0.03125, 0.0221, 0.0156 and 0.01105 ; the bandwidth B among 2, 1.5, 1 and 0.5 octaves; and the number of orientations between 4 and 8. Once the best descriptor configurations are found, the BoVW dictionary is computed for each alternative using the whole training set. These BoVW dictionaries are kept fixed to compute the descriptors over the test set.
Finally, a second cross-validated grid search is performed again over the training set to optimize the classifier hyper-parameters with the optimal descriptors. In this case, we consider three descriptor options for each classifier (colour, texture or both concatenated). The results of these classification alternatives are reported to provide a comparison.
The comparison with other methods in the state of the art was not considered in this work due to the novelty of this approach and the relative lack of works treating this issue. This is especially notable when looking at the modality of images we employ since, as far as we know, no other work neither automatic nor semiautomatic makes use of regular microscopy images despite them being common and relatively affordable to obtain. Moreover, the BoVW model allows to integrate feature extraction into the machine learning pipeline, using base features of diverse information sources, as colour or texture. The exhaustive comparison with competing alternative methodologies to represent colour and texture is out of the scope of this preliminary work.
4. Results and Discussion
The specimen candidate detection step results in a FNR of 0.4% using the test set, which is equivalent to 4 missed specimens among the total of 994 that are present in the test set. The low FNR is motivated by the fact this initial stage aims at identifying as much phytoplankton specimens as possible. Consequently, 851 incorrect detections were also provided, detections that are posteriorly filtered in the corresponding stage. These false positives are zooplankton and inert organic matter that present similar appearances to our phytoplankton. They are visually difficult to classify due to the intra-class heterogeneity of phytoplankton species. In spite of that, phytoplankton shows some distinctive features when compared to the spurious objects in these images. This is why a learning-based approach was used for the candidate refinement stage.
Sparse specimen and colony merging is evaluated by the comparison of the over and undersegmentation metrics before and after the application of this step. In particular, before the colony merging step, we obtained ratios of 20.36% and 8.86% for over and undersegmentation, respectively. Thanks to the application of the merging process, oversegmentation was reduced to a 3.43% while undersegmentation increased to a 12.53%. Thus, the fusion algorithm presents a positive impact given it improves oversegmentation ratio approximately a 17% while only increasing the undersegmentation approximately a 4%. These metrics show that the dataset presents a non-negligible amount of overlapping between specimens, responsible for the original measurement of undersegmentation. The metrics also demonstrate the abundance of sparse specimens and colonies characterised by their transparency and lack a visual connectivity, making them hard to detect as a whole object in the previously stage. These results are satisfactory as some undersegmentation increase is bound to happen when merging specimens, however, it is much lower, than the decrease in oversegmentation. Therefore, we can conclude that the algorithm satisfactorily balances the merging of the oversegmented specimens without resulting in too many false fusions.
Regarding the phytoplankton detection,
Table 1,
Table 2 and
Table 3 show the performance of the tested classifiers with the different feature sets: texture or colour alone or both together. Complementarily,
Figure 5,
Figure 6 and
Figure 7 show the PR curves for the different classifier and feature set combinations.
As it can be observed in the tables and figures, the performance of several combinations of classifiers and feature sets are similar, therefore validating the suitability of our proposed pipeline. We consider these results satisfactory given the high complexity, the heterogeneous classes and the high variability of the specimens that the system is trying to identify (the large diversity of appearance of the different phytoplankton specimens combined with the large variability of other possible present artefacts as sand, garbage, etc.). Furthermore, as demonstrated by the exhaustive experiments, the system is capable of extracting different features that provide reasonable results across a wide variety of representative classifiers.
The best classifier considering precision at 90% of recall is the RF classifier using texture features. In particular, this model obtained a precision of 77.2%. The empirically selected parameters are: number of bins , central frequency , bandwidth , and 8 orientations. Conversely, considering precision at 95% recall, the best system is the SVM using texture features. This model results in a precision of 68.7%. In this case, the selected parameters were , central frequency , bandwidth octaves, and 4 orientations.
The most important difference among the studied classifiers occurs when switching between the input features. Texture features demonstrate the best performances regardless of the classifier. It should be noted that the difference between using only texture or using only colour features is not very relevant for the RF and BT classifiers, which can be quantified as less than a 2% decrease in performance. On the other hand, the rest of the methods present a much higher reduction in performance, when comparing texture with colour features.Remarkably, the GMM approach loses 13% precision at 90% recall when switching from texture to colour features.
In terms of the descriptor size, kNN, BT and RF are favoured using larger configurations (usually ), while SVM and GMM achieve better performances using a lower amount of bins, like 2 or 3. This can also be seen in the amount of orientations, as SVM and GMM tend to make use of 4 instead of 8. This explains the much lower precision that is achieved by these methods using colour and texture features together, as they are more heavily penalised by the larger size of the combined descriptor. Differently, kNN, BT and RF are more suitable for a larger number of features.
While using either colour or texture features show appropriate results, using both together does not provide improvement or even degrades the results. Some classifiers (specially RF) maintained acceptable ratios due to the preference for larger descriptors. SVM and GMM, which favour the opposite, decreased in precision. Nevertheless, the fusion of features has proved useful for slightly improving the RF precision at 95% recall.
Representative examples of final results of the proposed method are depicted in
Figure 8. In particular, several images from the test set are shown with the specimens they contain classified using the top performing system at 90% recall, i.e., RF with the optimal texture features.
By analysing the phytoplankton detection results of the best performing system in the test set, we consider that the proposed approach is satisfactory in differentiating phytoplankton from debris and other objects in the water sample. Specifically, it is remarkable that the number of detected phytoplankton specimens is approximately only half of the detected candidates. Thus, we can conclude that the classification system is robust to the presence of heterogeneous non-target objects in the image. However, these results do not allow to evaluate how robust is the proposed candidate detection mechanism to a very high density of debris and spurious elements in the images. Nevertheless, it should be noticed that the sample concentration can be easily controlled during the water sample preparation through dilution (and the quantitative results corrected consequently) to avoid the exceptionally corrupted samples representing these situations.
One possible limitation of the presented experiments is that the system was tested with images obtained from a single water sample. This implies that the quantity and diversity of non-target objects, as well as the distribution of phytoplankton species and stage of development is biased towards some specific conditions. Nevertheless, we consider that the number of different images is high enough, as well as there is a high number and diversity of both phytoplankton species and non-target objects in the sample to be representative of a realistic scenario. The obtained results, although preliminary, allows us to validate the suitability of the proposed methods, which are to be refined by future research in the same line of work.
Moreover, the present study does not include taxonomic classification and quantification of individual species. Thus, it is not a complete system for phytoplankton analysis. However, such taxonomic classification has been already extensively explored, and successfully approached, in the literature, using the single-specimen images obtained with flow cytometry imaging approaches. The present work allows to obtain single-specimen images from conventional microscopy images that should be readily usable for species classification approaches.
Finally, we have not included a comparison with previous approaches in this work. The reason is that the most related works [
26,
27,
28] do not approach the imaging protocol in a similar way to ours, and thus they are not comparable. Specifically, PlanktoVision [
26] and PLASA [
27] use fluorescence images along with multiple-focus images obtained using computerized microscopes. Additionally, PLASA also used several magnifications in the analysis. On the other hand, in in [
28] the focus and magnification is manually adjusted for each of the imaged species. Thus, in this sense, unlike previous approaches, our method allows to detect single-specimen phytoplankton images from single-focus and magnification images that are systematically obtained using conventional a microscope. Moreover, the comparison with prior species classification approaches is not performed as this classification is out of the scope of this work.
5. Conclusions and Future Work
In this work, we present an innovative way of detecting and separating phytoplankton specimens in multi-specimen microscope images from water samples. The designed preliminary fully automatic methodology is based on an initial detection of candidates based on a foreground-background segmentation and a completely novel colony merging algorithm. Finally, given the complexity of this issue, the detections are refined using a learning-based strategy that aims at detecting true phytoplankton specimens. Several classifiers and a wide variety of feature sets were tested, providing in all the cases satisfactory identifications that validate and corroborate the suitability of the proposed automatic computational pipeline.
The results are satisfactory as baseline for further improvement, given the high complexity of the problem and the domain as well as the lack of comparable methods in the state of the art. While the proposed methods need to be tested over more diverse water samples, they can serve as a stable base for future research. In this sense, these are important initial steps towards automating potability testing and plankton studies using conventional microscopes, which are widely available on laboratories worldwide. Overall, the main advantage of this work when compared to other works in this field is its cost and availability. While flow cytometry imaging approaches are suitable methods for obtaining single-specimen phytoplankton images, they are not often found in laboratories. Meanwhile, the proposed methods in this work can be used with a regular microscopes as long as they are equipped with a digital camera. Moreover, and unlike some previous works, since we have managed to use fixed parameters for both magnification and focal point in the imaging protocol, it is not required that an expert taxonomist supervises the image acquisition process. Finally, although species classification and quantification is not approached in this work, state of the art approaches for single-specimen phytoplankton images classification should be easily adapted to work on top of the proposed analysis pipeline.
Future lines of work include testing the method with more phytoplankton samples to verify its performance with a wider amount of species and images. We intend on creating a new classification step to separate relevant species, with a special focus on those that produce toxins. This is the ultimate goal of this project as toxic phytoplankton monitoring has to be done regularly to ensure water safety. We plan on creating a classifier following the same methodology used in this work to classify the toxic species. Finally, other working lines include the exploration of alternative features or deep learning methods.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}