Mask-Refined R-CNN: A Network for Refining Object Details in Instance Segmentation




Abstract
1. Introduction
2. Related Works
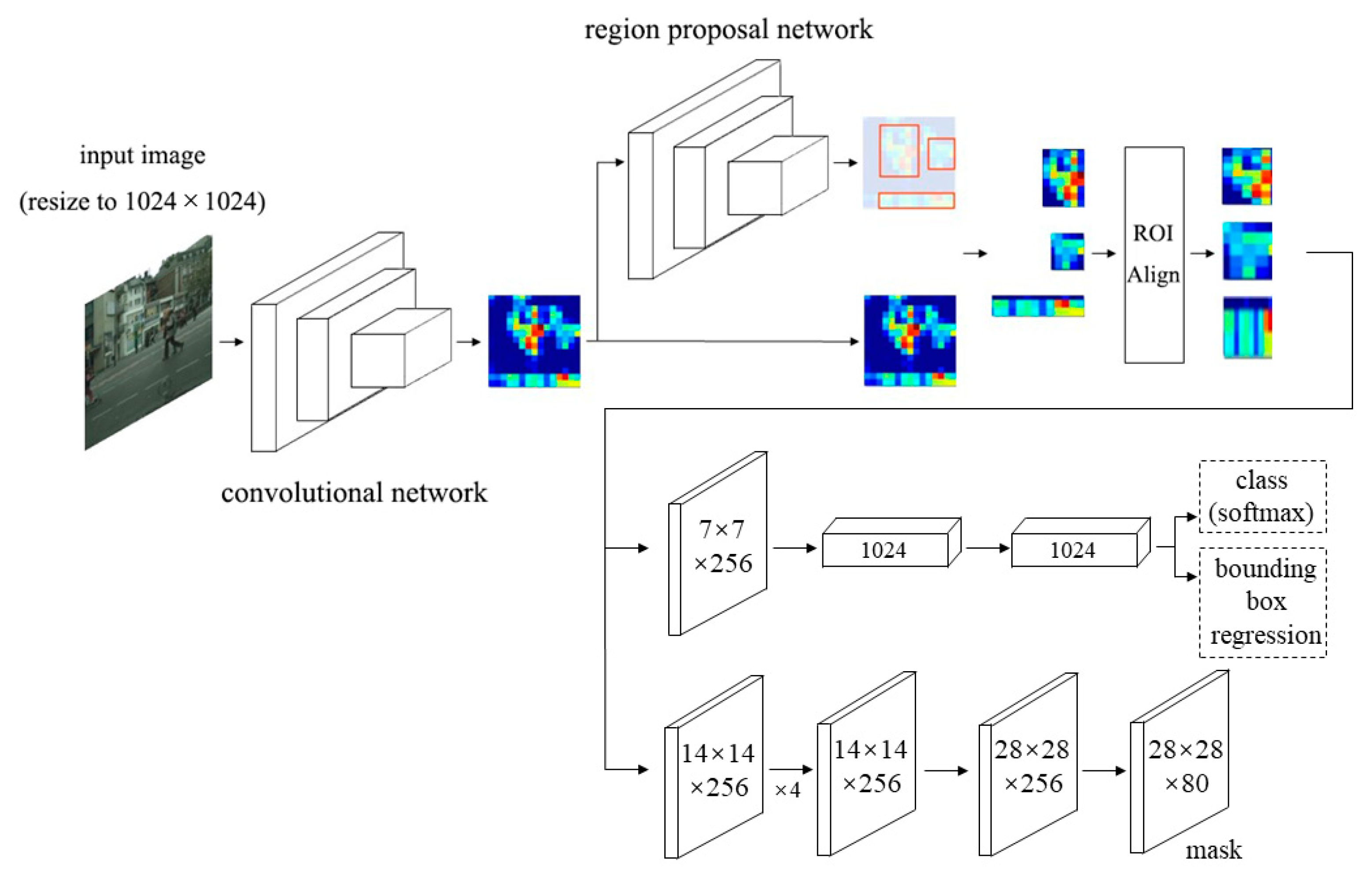
2.1. Instance Segmentation
2.2. Multi-Feature Fusion
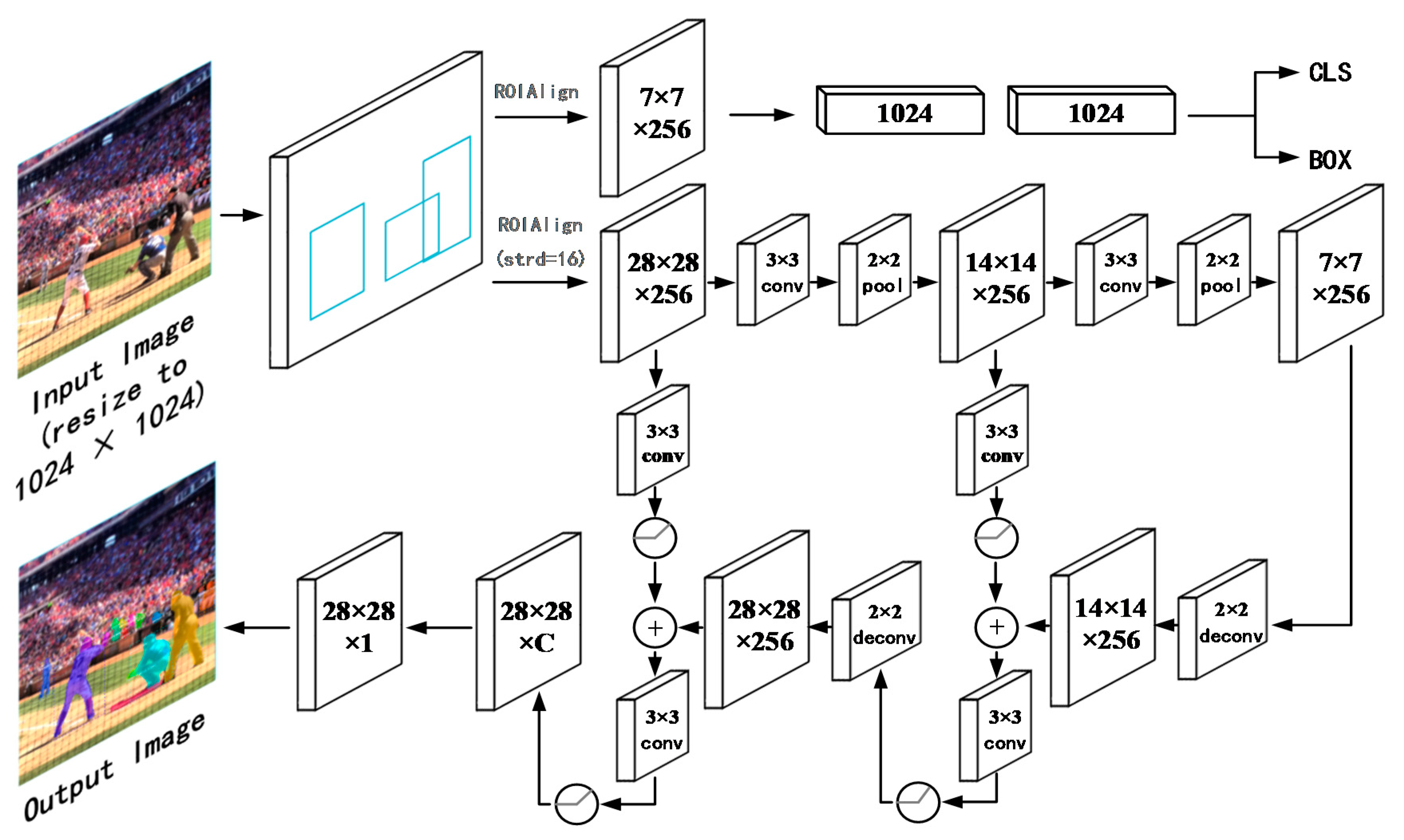
3. Proposed Method
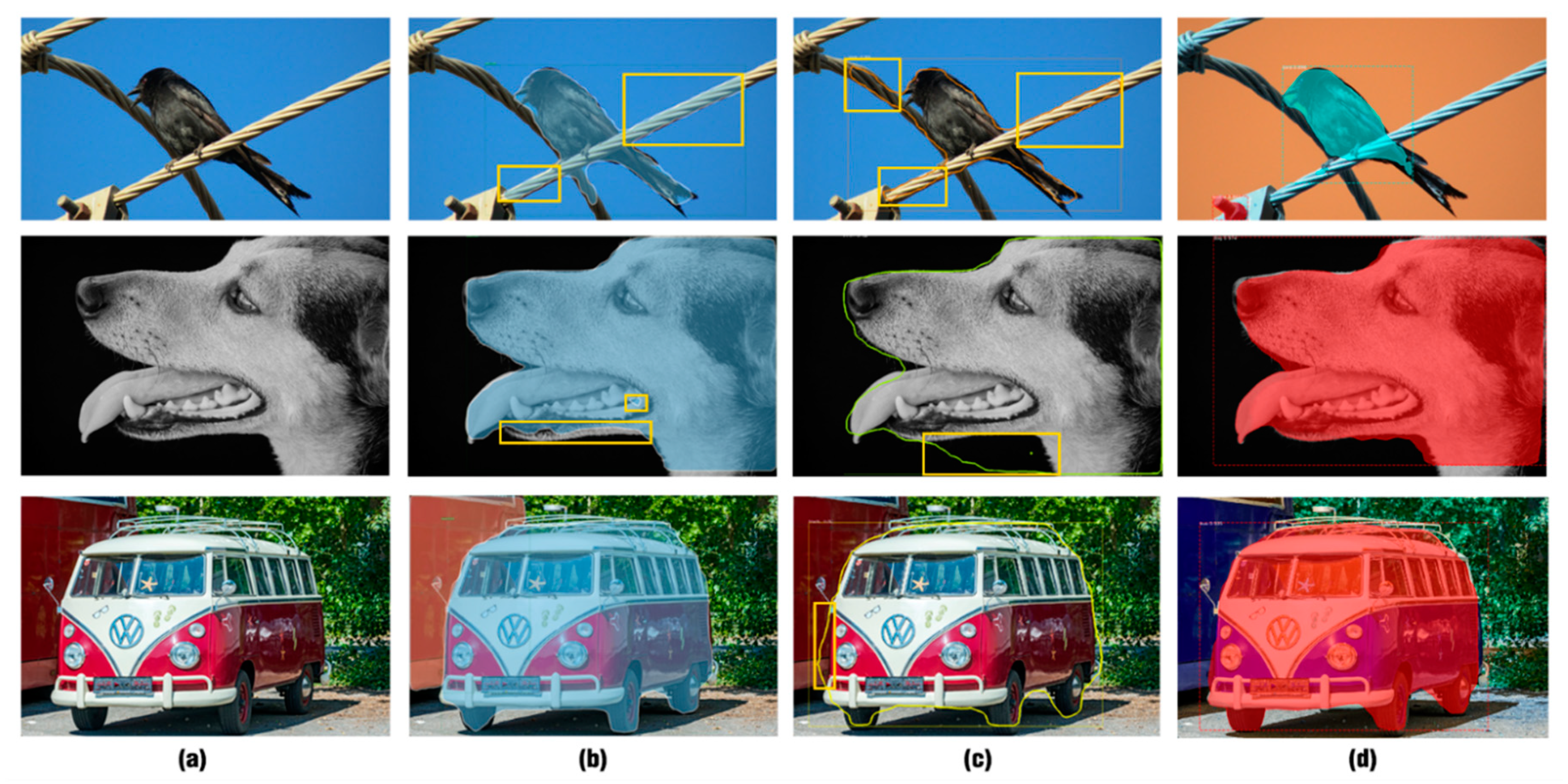
3.1. Motivation
3.2. Mask-Refined Region-Convolutional Neural Network (MR R-CNN)
4. Experiments and Results
4.1. Dataset and Evaluation Indices
4.2. Implementation Details
4.3. Quantitative Results
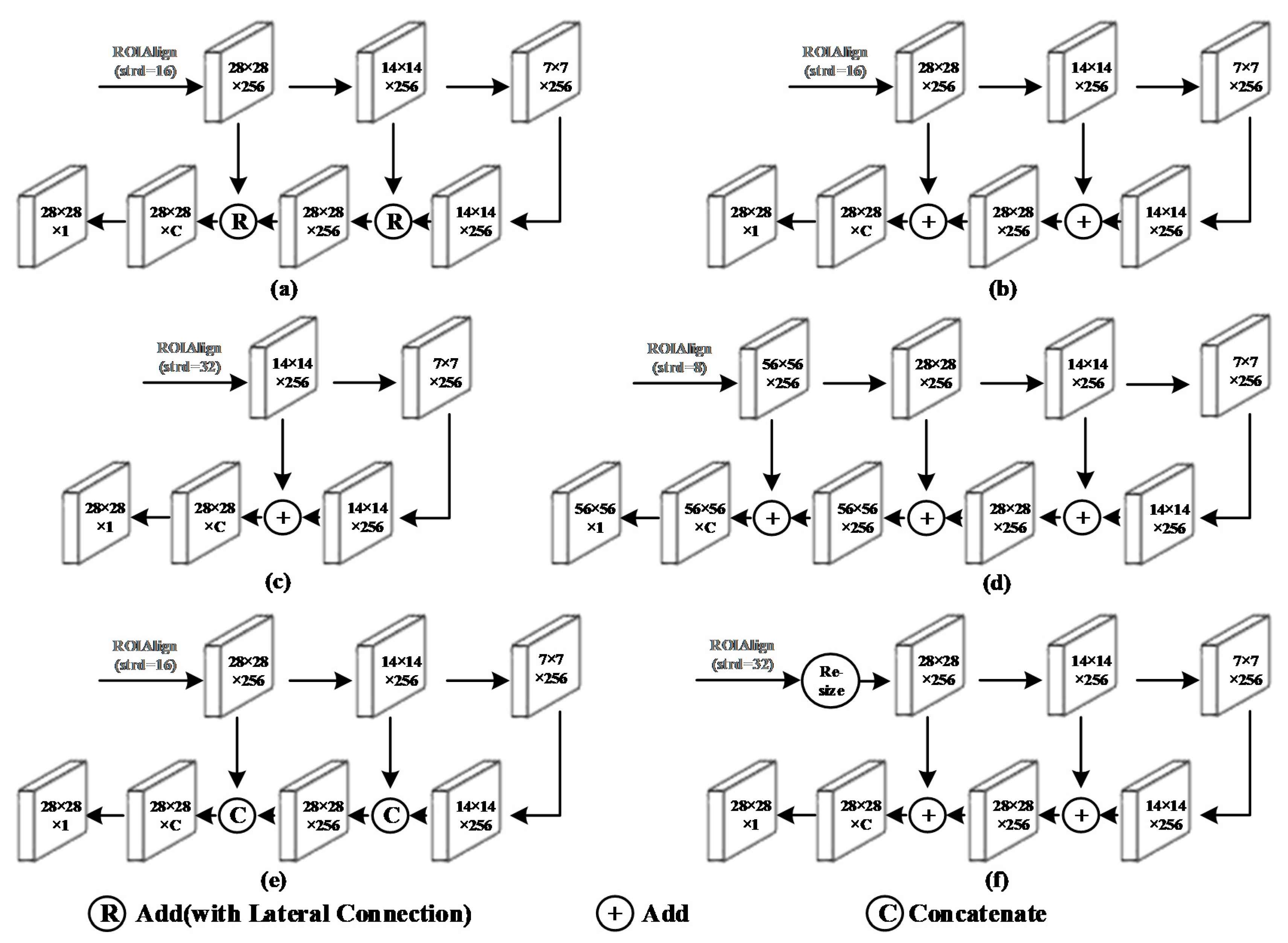
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, B.-G.; Hong, G.-S.; Kim, J.-H.; Choi, Y.-J. An Efficient Vision-based Object Detection and Tracking using Online Learning. J. Multimed. Inf. Syst. 2017, 4, 285–288. [Google Scholar]
- Kim, J.-H.; Kim, B.-G.; Roy, P.-P.; Jeong, D.-M. Efficient Facial Expression Recognition Algorithm Based on Hierarchical Deep Neural Network Structure. IEEE Access. 2019, 7, 41273–41285. [Google Scholar] [CrossRef]
- Kahaki, S.M.; Nordin, M.J.; Ahmad, N.S.; Arzoky, M.; Ismail, W. Deep convolutional neural network designed for age assessment based on orthopantomography data. Neural Comput. Appl. 2019, 1–12. [Google Scholar] [CrossRef]
- Lee, Y.-W.; Kim, J.-H.; Choi, Y.-J.; Kim, B.-G. CNN-based approach for visual quality improvement on HEVC. In Proceedings of the IEEE Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018. [Google Scholar]
- Yuan, B.; Li, Y.; Jiang, F.; Xu, X.; Guo, Y.; Zhao, J.; Zhang, D.; Guo, J.; Shen, X. MU R-CNN: A Two-Dimensional Code Instance Segmentation Network Based on Deep Learning. Future Internet. 2019, 11, 197. [Google Scholar] [CrossRef]
- Liu, G.; He, B.; Liu, S.; Huang, J. Chassis Assembly Detection and Identification Based on Deep Learning Component Instance Segmentation. Symmetry 2019, 11, 1001. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the Twenty-sixth Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuillel, A. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar]
- Wang, R.; Xu, Y.; Sotelo, M.; Ma, Y.; Sarkodie, T.; Li, Z.; Li, W. A Robust Registration Method for Autonomous Driving Pose Estimation in Urban Dynamic Environment Using LiDAR. Electronics 2019, 8, 43. [Google Scholar] [CrossRef]
- Chu, J.; Guo, Z.; Leng, L. Object Detection Based on Multi-Layer Convolution Feature Fusion and Online Hard Example Mining. IEEE Access. 2018, 6, 19959–19967. [Google Scholar] [CrossRef]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, SU, USA, 18–22 June 2018. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scor-ing R-CNN. arXiv 2019, arXiv:1903.00241. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Bai, M.; Urtasun, R. Deep Watershed Transform for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Uhrig, J.; Cordts, M.; Franke, U.; Brox, T. Pixel-Level Encoding and Depth Layering for Instance-Level Semantic Labeling. In Proceedings of the IEEE Conference on German Conference on Pattern Recognition (GCPR), Hannover, Germany, 14–25 September 2016. [Google Scholar]
- Liu, S.; Jia, J.; Fidler, S.; Urtasun, R. SGN: Sequential Grouping Networks for Instance Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Kirillov, A.; Levinkov, E.; Andres, B.; Savchynskyy, B.; Rother, C. InstanceCut: From Edges to Instances with MultiCut. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Arnab, A.; Torr, P. Pixelwise Instance Segmentation with a Dynamically Instantiated Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Romera-Paredes, B.; Torr, P. Recurrent Instance Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Ren, M.; Zemel, R. End-To-End Instance Segmentation with Recurrent Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Han, J.; Zhang, D.; Cheng, G.; Liu, N.; Xu, D. Advanced deep-learning techniques for salient and category-specific object detection: A survey. IEEE Signal Process. Mag. 2018, 35, 84–100. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Xu, D. Learning rotation-invariant and fisher discriminative convolutional neural networks for object detection. IEEE Trans. Image Process. 2018, 28, 265–278. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully Convolutional Instance-Aware Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-sensitive fully convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Leng, L.; Li, M.; Kim, C.; Bi, X. Dual-source discrimination power analysis for multi-instance contactless palmprint recognition. Multimed. Tools Applic. 2017, 76, 333–354. [Google Scholar] [CrossRef]
- Leng, L.; Zhang, J. PalmHash Code vs. PalmPhasor Code. Neurocomputing 2013, 108, 1–12. [Google Scholar] [CrossRef]
- Leng, L.; Teoh, A.B.; Li, J.M.; Khan, M.K. A remote cancelable palmprint authentication protocol based on multi-directional two-dimensional PalmPhasor-fusion. Securit. Commun. Netw. 2014, 7, 1860–1871. [Google Scholar] [CrossRef]
- Lin, T.; Collobert, R.; Dollár, P. Learning to Refine Object Segments. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Ghiasi, G.; Fowlkes, C. Laplacian Pyramid Reconstruction and Refinement for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the IEEE Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A. DSSD: Deconvolutional Single Shot Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zeiler, M.; Fergus, G. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Leng, L.; Zhang, J.; Xu, J.; Khan, M.K.; Alghathbar, K. Dynamic weighted discrimination power analysis in DCT domain for face and palmprint recognition. In Proceedings of the International Conference on Information and Communication Technology Convergence IEEE(ICTC), Jeju, Korea, 17–19 November 2010. [Google Scholar]
- Leng, L.; Zhang, J.; Khan, M.K.; Chen, X.; Alghathbar, K. Dynamic weighted discrimination power analysis: A novel approach for face and palmprint recognition in DCT domain. Int. J. Phys. Sci. 2010, 5, 2543–2554. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In International Symposium on Visual Computing; Springer: Bayern/Cham, Germany, 2016; pp. 234–244. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Introduction | Shortcoming |
|---|---|---|---|
| FCIS | 2017 |
| Poor discrimination ability for overlapping objects. |
| Mask R-CNN | 2017 |
| Weak ability to predict instance details. |
| PAN | 2018 |
| High time cost. |
| MS R-CNN | 2019 |
| Low accuracy for large instance. |
| Method | Backbone | AP | AP50 | AP75 | APS | APM | APL |
|---|---|---|---|---|---|---|---|
| FCIS | ResNet-101 | 29.2 | 49.5 | - | 7.1 | 31.3 | 50.0 |
| FCIS+++ | ResNet-101 | 33.6 | 54.5 | - | - | - | - |
| Mask R-CNN | ResNet-101-C4 | 33.1 | 54.9 | 34.8 | 12.1 | 35.6 | 51.1 |
| Mask R-CNN | ResNet-101 FPN | 35.7 | 58.0 | 37.8 | 15.5 | 38.1 | 52.4 |
| Mask R-CNN | ResNeXt-101 FPN | 37.1 | 60.0 | 39.4 | 16.9 | 39.9 | 53.5 |
| PAN | ResNet-50 FPN | 38.2 | 60.2 | 41.4 | 19.1 | 41.1 | 52.6 |
| MS R-CNN | ResNet-101 | 35.4 | 54.9 | 38.1 | 13.7 | 37.6 | 53.3 |
| MS R-CNN | ResNet-101 FPN | 38.3 | 58.8 | 41.5 | 17.8 | 40.4 | 54.4 |
| MS R-CNN | ResNet-101 DCN-FPN | 39.6 | 60.7 | 43.1 | 18.8 | 41.5 | 56.2 |
| MR R-CNN | ResNet-50 FPN | 35.2 | 53.5 | 39.8 | 13.9 | 38.1 | 52.6 |
| MR R-CNN | ResNet-101 FPN | 37.6 | 56.1 | 41.1 | 16.4 | 40.6 | 54.7 |
| MR R-CNN | ResNet-101 DCN-FPN | 38.8 | 58.0 | 42.7 | 17.2 | 41.8 | 56.6 |
| Method | AP | AP50 | AP75 |
|---|---|---|---|
| Mask R-CNN ResNet-101 FPN | 34.2 | 53.6 | 36.6 |
| PAN ResNet-50 FPN | 37.5 | 56.1 | 40.6 |
| MS R-CNN ResNet-101 FPN | 37.8 | 56.5 | 41.0 |
| MR R-CNN ResNet-101 FPN | 38.2 | 56.7 | 41.6 |
| Method | Average Prediction Time |
|---|---|
| Mask R-CNN baseline | 0.783s |
| MR R-CNN | 0.828s |
| Framework | AP | AP50 | AP75 |
|---|---|---|---|
| (a) MR R-CNN (with LC) | 37.6 | 56.1 | 41.1 |
| (b) MR R-CNN (without LC) | 37.3 | 55.3 | 41.0 |
| (c) strd=32 + Add | 30.1 | 46.8 | 36.5 |
| (d) strd=8 + Add | - | - | - |
| (e) strd=16 + Concatenate | 33.4 | 53.3 | 37.2 |
| (f) strd=32 + resize + Add | 15.5 | 20.8 | 22.0 |
| Training Object | AP | AP50 | AP75 |
|---|---|---|---|
| (a) Original image | 37.6 | 56.1 | 41.1 |
| (b) Only one object | 37.0 | 53.6 | 42.4 |
| (c) Only small object (area ≤322) | 20.5 | 34.8 | 25.3 |
| (d) Only medium object (322 < area ≤ 962) | 32.2 | 51.9 | 36.1 |
| (e) Only large object (area > 962) | 37.3 | 56.3 | 41.0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Chu, J.; Leng, L.; Miao, J. Mask-Refined R-CNN: A Network for Refining Object Details in Instance Segmentation. Sensors 2020, 20, 1010. https://doi.org/10.3390/s20041010
Zhang Y, Chu J, Leng L, Miao J. Mask-Refined R-CNN: A Network for Refining Object Details in Instance Segmentation. Sensors. 2020; 20(4):1010. https://doi.org/10.3390/s20041010
Chicago/Turabian StyleZhang, Yiqing, Jun Chu, Lu Leng, and Jun Miao. 2020. "Mask-Refined R-CNN: A Network for Refining Object Details in Instance Segmentation" Sensors 20, no. 4: 1010. https://doi.org/10.3390/s20041010
APA StyleZhang, Y., Chu, J., Leng, L., & Miao, J. (2020). Mask-Refined R-CNN: A Network for Refining Object Details in Instance Segmentation. Sensors, 20(4), 1010. https://doi.org/10.3390/s20041010