Walking Recognition in Mobile Devices

 , , , , and
, , , , and
Abstract
:1. Introduction
2. State of the Art
2.1. Heuristic Methods
2.2. Feature-Based Approach
2.3. Shape-Based Approach
3. Signal Preprocessing
3.1. Attitude Estimation
3.2. Estimation of the Acceleration in the Earth Frame
3.3. Signal Filtering and Centering
4. Walking Recognition
4.1. Feature-Based Classification
4.1.1. Classification Methods Using Manual Feature Selection
- : the energy of the vertical component of the projected acceleration;
- : the energy of the gyroscope norm;
- : the variance of the gyroscope norm;
- , and : the standard deviation for each axis of the acceleration;
- , and : the standard deviation for each axis of the projected acceleration;
- : the zero-crossing rate of the acceleration norm;
- : the peak count of the acceleration norm;
- : the peak count of the vertical projected acceleration;
- : the skewness of the vertical projected acceleration;
- : the skewness of the gyroscope norm;
- : the kurtosis of the vertical projected acceleration.
- : the mean frequency of the vertical component of the projected acceleration;
- : the standard deviation of the previous mean frequency;
- : the median frequency of the vertical projected acceleration;
- : the modal frequency of the vertical projected acceleration;
- : the modal frequency of the acceleration norm;
- : the kurtosis of the spectrum of the vertical projected acceleration.
4.1.2. Deep Learning
4.2. Shape-Based Classification
- support vectors of an SVM trained using as training set (Section 4.2.1),
- medoids obtained after using a clustering algorithm (PAM), over the original training data (Section 4.2.2), and
- most representative patterns found through a supervised summarization procedure (Section 4.2.3).
4.2.1. Support Vectors of a SVM as Representative Patterns
4.2.2. PAM Medoids as Representative Patterns
| Algorithm 1: Partitioning Around Medoids (PAM). |
 |
4.2.3. Supervised Summarization
| Algorithm 2: Supervised summarization. |
 |
5. Experimental Analysis and Results
5.1. Ground Truth
5.2. Performance Analysis
5.2.1. Feature-Based Classification
5.2.2. Shape-Based Classification
5.2.3. Combination of Classifiers
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dutta, S.; Chatterjee, A.; Munshi, S. An automated hierarchical gait pattern identification tool employing cross-correlation-based feature extraction and recurrent neural network based classification. Expert Syst. 2009, 26, 202–217. [Google Scholar] [CrossRef]
- Lu, H.; Huang, J.; Saha, T.; Nachman, L. Unobtrusive gait verification for mobile phones. In Proceedings of the 2014 ACM International Symposium on Wearable Computers, Seattle, WA, USA, 13–17 September 2014; pp. 91–98. [Google Scholar]
- Ren, Y.; Chen, Y.; Chuah, M.C.; Yang, J. User verification leveraging gait recognition for smartphone enabled mobile healthcare systems. IEEE Trans. Mob. Comput. 2015, 14, 1961–1974. [Google Scholar] [CrossRef]
- Teixeira, T.; Jung, D.; Dublon, G.; Savvides, A. PEM-ID: Identifying people by gait-matching using cameras and wearable accelerometers. In Proceedings of the IEEE Third ACM/IEEE International Conference on Distributed Smart Cameras, Como, Italy, 30 August–2 September 2009; pp. 1–8. [Google Scholar]
- Casado, F.E.; Regueiro, C.V.; Iglesias, R.; Pardo, X.M.; López, E. Automatic Selection of User Samples for a Non-collaborative Face Verification System. In Proceedings of the Iberian Robotics Conference 2017, ROBOT 2017, Seville, Spain, 22–24 November 2017; Springer: New York, NY, USA; pp. 555–566. [Google Scholar]
- Zhu, C.; Sheng, W. Recognizing human daily activity using a single inertial sensor. In Proceedings of the 2010 8th World Congress on Intelligent Control and Automation (WCICA), Citeseer, Jinan, China, 7–9 July 2010; pp. 282–287. [Google Scholar]
- Olivares, A.; Ramírez, J.; Górriz, J.M.; Olivares, G.; Damas, M. Detection of (in) activity periods in human body motion using inertial sensors: A comparative study. Sensors 2012, 12, 5791–5814. [Google Scholar] [CrossRef] [PubMed]
- Mathie, M.J.; Coster, A.C.; Lovell, N.H.; Celler, B.G. Accelerometry: Providing an integrated, practical method for long-term, ambulatory monitoring of human movement. Physiol. Meas. 2004, 25, R1. [Google Scholar] [CrossRef] [Green Version]
- Harle, R. A survey of indoor inertial positioning systems for pedestrians. IEEE Commun. Surv. Tutor. 2013, 15, 1281–1293. [Google Scholar] [CrossRef]
- Kourogi, M.; Ishikawa, T.; Kurata, T. A method of pedestrian dead reckoning using action recognition. In Proceedings of the 2010 IEEE/ION Position Location and Navigation Symposium (PLANS), Indian Wells, CA, USA, 3–6 May 2010; pp. 85–89. [Google Scholar]
- Vathsangam, H.; Emken, A.; Spruijt-Metz, D.; Sukhatme, G.S. Toward free-living walking speed estimation using Gaussian process-based regression with on-body accelerometers and gyroscopes. In Proceedings of the 4th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Munchen, Germany, 22–25 March 2010; pp. 1–8. [Google Scholar]
- Mautz, R.; Tilch, S. Survey of optical indoor positioning systems. In Proceedings of the IEEE 2011 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Guimaraes, Portugal, 21–23 September 2011; pp. 1–7. [Google Scholar]
- Randell, C.; Muller, H. Low cost indoor positioning system. In Proceedings of the International Conference on Ubiquitous Computing, Atlanta, Georgia, 30 September–2 October 2001; pp. 42–48. [Google Scholar]
- Liu, H.; Darabi, H.; Banerjee, P.; Liu, J. Survey of wireless indoor positioning techniques and systems. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 1067–1080. [Google Scholar] [CrossRef]
- Steinhoff, U.; Schiele, B. Dead reckoning from the pocket-an experimental study. In Proceedings of the 2010 IEEE International Conference on Pervasive Computing and Communications (PerCom), Mannheim, Germany, 29 March–2 April 2010; pp. 162–170. [Google Scholar]
- Yang, J.; Lu, H.; Liu, Z.; Boda, P.P. Physical activity recognition with mobile phones: Challenges, methods, and applications. In Multimedia Interaction and Intelligent User Interfaces: Principles, Methods and Applications; Springer: London, UK, 2010; pp. 185–213. [Google Scholar]
- Li, F.; Zhao, C.; Ding, G.; Gong, J.; Liu, C.; Zhao, F. A reliable and accurate indoor localization method using phone inertial sensors. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing (UbiComp ‘12), Pittsburgh, PA, USA, 5–8 September 2012; pp. 421–430. [Google Scholar]
- Qian, J.; Ma, J.; Ying, R.; Liu, P.; Pei, L. An improved indoor localization method using smartphone inertial sensors. In Proceedings of the 2013 IEEE International Conference on Indoor Positioning and Indoor Navigation (IPIN), Montbeliard-Belfort, France, 28–31 October 2013; pp. 1–7. [Google Scholar]
- Susi, M.; Renaudin, V.; Lachapelle, G. Motion mode recognition and step detection algorithms for mobile phone users. Sensors 2013, 13, 1539–1562. [Google Scholar] [CrossRef]
- Brajdic, A.; Harle, R. Walk detection and step counting on unconstrained smartphones. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 225–234. [Google Scholar]
- Rodríguez, G.; Casado, F.E.; Iglesias, R.; Regueiro, C.V.; Nieto, A. Robust Step Counting for Inertial Navigation with Mobile Phones. Sensors 2018, 18, 3157. [Google Scholar] [CrossRef] [Green Version]
- Zou, Q.; Wang, Y.; Zhao, Y.; Wang, Q.; Shen, C.; Li, Q. Deep Learning Based Gait Recognition Using Smartphones in the Wild. arXiv 2018, arXiv:1811.00338. [Google Scholar]
- Chen, L.; Özsu, M.T.; Oria, V. Robust and fast similarity search for moving object trajectories. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 491–502. [Google Scholar]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series; KDD Workshop: Seattle, WA, USA, 1994; pp. 359–370. [Google Scholar]
- Vlachos, M.; Kollios, G.; Gunopulos, D. Discovering similar multidimensional trajectories. In Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 673–684. [Google Scholar]
- Titterton, D.; Weston, J.L.; Weston, J. Strapdown Inertial Navigation Technology; Amercian Institute of Aeronautics and Astronautics: Reston, VA, USA, 2004. [Google Scholar]
- Grewal, M.S.; Weill, L.R.; Andrews, A.P. Global Positioning Systems, Inertial Navigation, and Integration; John Wiley & Sons: Hoboken, GA, USA, 2007. [Google Scholar]
- Kuipers, J.B. Quaternions and Rotation Sequences; Princeton University Press: Princeton, PJ, USA, 1999. [Google Scholar]
- Madgwick, S.O. An Efficient Orientation Filter for Inertial and Inertial/Magnetic Sensor Arrays; Technical Report; University of Bristol: Bristol, UK, 2010; Volume 25, pp. 113–118. [Google Scholar]
- Madgwick, S.O.; Harrison, A.J.; Vaidyanathan, R. Estimation of IMU and MARG orientation using a gradient descent algorithm. In Proceedings of the IEEE International Conference on Rehabilitation Robotics (ICORR 2011), Zurich, Switzerland, 29 June–1 July 2011; pp. 1–7. [Google Scholar]
- Zijlstra, W.; Hof, A.L. Displacement of the pelvis during human walking: Experimental data and model predictions. Gait Posture 1997, 6, 249–262. [Google Scholar] [CrossRef]
- Renaudin, V.; Susi, M.; Lachapelle, G. Step length estimation using handheld inertial sensors. Sensors 2012, 12, 8507–8525. [Google Scholar] [CrossRef] [PubMed]
- Avci, A.; Bosch, S.; Marin-Perianu, M.; Marin-Perianu, R.; Havinga, P. Activity recognition using inertial sensing for healthcare, wellbeing and sports applications: A survey. In Proceedings of the 23rd international conference on Architecture of computing systems (ARCS), Hannover, Germany, 22–25 February 2010; pp. 1–10. [Google Scholar]
- Preece, S.J.; Goulermas, J.Y.; Kenney, L.P.J.; Howard, D.; Meijer, K.; Crompton, R. Activity identification using body-mounted sensors—A review of classification techniques. Physiol. Meas. 2009, 30, R1–R33. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.Y.; Wang, J.S.; Chen, Y.P. Using acceleration measurements for activity recognition: An effective learning algorithm for constructing neural classifiers. Pattern Recognit. Lett. 2008, 29, 2213–2220. [Google Scholar] [CrossRef]
- Bernecker, T.; Graf, F.; Kriegel, H.P.; Moennig, C.; Dill, D.; Tuermer, C. Activity recognition on 3d accelerometer data (technical report). Tech. Rep. Inst. Inf. 2012, 23, 1–22. [Google Scholar]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Hall, M.A. Correlation-based Feature Selection for Discrete and Numeric Class Machine Learning. In Proceedings of the 17th international conference on machine learning (ICML-2000), Stanford, CA, USA, 29 June–2 July 2000; pp. 359–366. [Google Scholar]
- Joanes, D.; Gill, C. Comparing measures of sample skewness and kurtosis. J. Stat. Comput. Simul. 1998, 47, 183–189. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T. A comprehensive study on cross-view gait based human identification with deep cnns. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 209–226. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Zeng, M.; Nguyen, L.T.; Yu, B.; Mengshoel, O.J.; Zhu, J.; Wu, P.; Zhang, J. Convolutional neural networks for human activity recognition using mobile sensors. In Proceedings of the 6th International Conference on Mobile Computing, Applications and Services, Austin, TX, USA, 6–7 November 2014; pp. 197–205. [Google Scholar]
- Gudmundsson, S.; Runarsson, T.P.; Sigurdsson, S. Support vector machines and dynamic time warping for time series. In Proceedings of the International Joint Conference on Neural Networks, Hong Kong, China, 1–6 June 2008; pp. 2772–2776. [Google Scholar]
- Lei, H.; Sun, B. A study on the dynamic time warping in kernel machines. In Proceedings of the Third International Conference, Shanghai, China, 16–18 December 2007; pp. 839–845. [Google Scholar]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef] [Green Version]
- Keogh, E.J.; Pazzani, M.J. Derivative dynamic time warping. In Proceedings of the 2001 SIAM International Conference on Data Mining, SIAM, Chicago, IL, USA, 5–7 April 2001; pp. 1–11. [Google Scholar]
- Bahlmann, C.; Haasdonk, B.; Burkhardt, H. Online handwriting recognition with support vector machines-a kernel approach. In Proceedings of the Eighth International Workshop on Frontiers in Handwriting Recognition, Niagara on the Lake, ON, Canada, 6–8 August 2002; pp. 49–54. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Graepel, T.; Herbrich, R.; Bollmann-Sdorra, P.; Obermayer, K. Classification on pairwise proximity data. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999; pp. 438–444. [Google Scholar]
- Bagheri, M.A.; Gao, Q.; Escalera, S. Support vector machines with time series distance kernels for action classification. In Proceedings of the Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–9 March 2016; pp. 1–7. [Google Scholar]
- Mangasarian, O. Generalized Support Vector Machines; Technical Report; University of Wisconsin: Madison, WI, USA, 1998. [Google Scholar]
- Müller, M. Dynamic time warping. Inf. Retrieval Music Motion 2007, 2, 69–84. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analsis; John Wiley & Sons: Hoboken, GA, USA, 2009. [Google Scholar]
- Zeidat, N.M.; Eick, C.F. K-medoid-style Clustering Algorithms for Supervised Summary Generation. In Proceedings of the International Conference on Artificial Intelligence, Las Vegas, NV, USA, 21–24 June 2004; pp. 932–938. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: Vietnam, Malaysia, 2016. [Google Scholar]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Bertsimas, D.; Tsitsiklis, J. Simulated annealing. Stat. Sci. 1993, 8, 10–15. [Google Scholar] [CrossRef]
- O’Connell, S.; Olaighin, G.; Quinlan, L.R. When a step is not a step! Specificity analysis of five physical activity monitors. PLoS ONE 2017, 12, e0169616. [Google Scholar] [CrossRef] [PubMed]
- Thomas, M.; Jankovic, J.; Suteerawattananon, M.; Wankadia, S.; Caroline, K.S.; Vuong, K.D.; Protas, E. Clinical gait and balance scale (GABS): Validation and utilization. J. Neurol. Sci. 2004, 217, 89–99. [Google Scholar] [CrossRef]
- Lee, H.H.; Choi, S.; Lee, M.J. Step detection robust against the dynamics of smartphones. Sensors 2015, 15, 27230–27250. [Google Scholar] [CrossRef] [Green Version]
- Naqvib, N.Z.; Kumar, A.; Chauhan, A.; Sahni, K. Step counting using smartphone-based accelerometer. Int. J. Comput. Sci. Eng. 2012, 4, 675. [Google Scholar]
- Lopez-Fernandez, J.; Iglesias, R.; Regueiro, C.V.; Casado, F.E. Inertial Navigation with Mobile Devices: A Robust Step Count Model. In Proceedings of the Iberian Robotics Conference, Seville, Spain, 22–24 November 2017; pp. 666–678. [Google Scholar]
- Caret: Classification and Regression Training. Available online: https://cran.r-project.org/package=caret (accessed on 21 February 2020).
- Keras: R Interface to ‘Keras’. Available online: https://cran.r-project.org/package=keras (accessed on 21 February 2020).
- Borio, D. Accelerometer signal features and classification algorithms for positioning applications. In Proceedings of the 2011 International Technical Meeting, San Diego, CA, USA, 24–26 January 2011; pp. 158–169. [Google Scholar]
- Giorgino, T. Computing and visualizing dynamic time warping alignments in R: The dtw package. J. Stat. Softw. 2009, 31, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Novakovic, J. The impact of feature selection on the accuracy of naïve bayes classifier. In Proceedings of the 18th Telecommunications Forum TELFOR, Belgrade, Serbia, 23–25 November 2010; pp. 1113–1116. [Google Scholar]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Hubert, L.J.; Levin, J.R. A general statistical framework for assessing categorical clustering in free recall. Psychol. Bull. 1976, 83, 1072. [Google Scholar] [CrossRef]
- Baker, F.B.; Hubert, L.J. Measuring the power of hierarchical cluster analysis. J. Am. Stat. Assoc. 1975, 70, 31–38. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. B 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Network Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- LeBlanc, M.; Tibshirani, R. Combining estimates in regression and classification. J. Am. Stat. Assoc. 1996, 91, 1641–1650. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
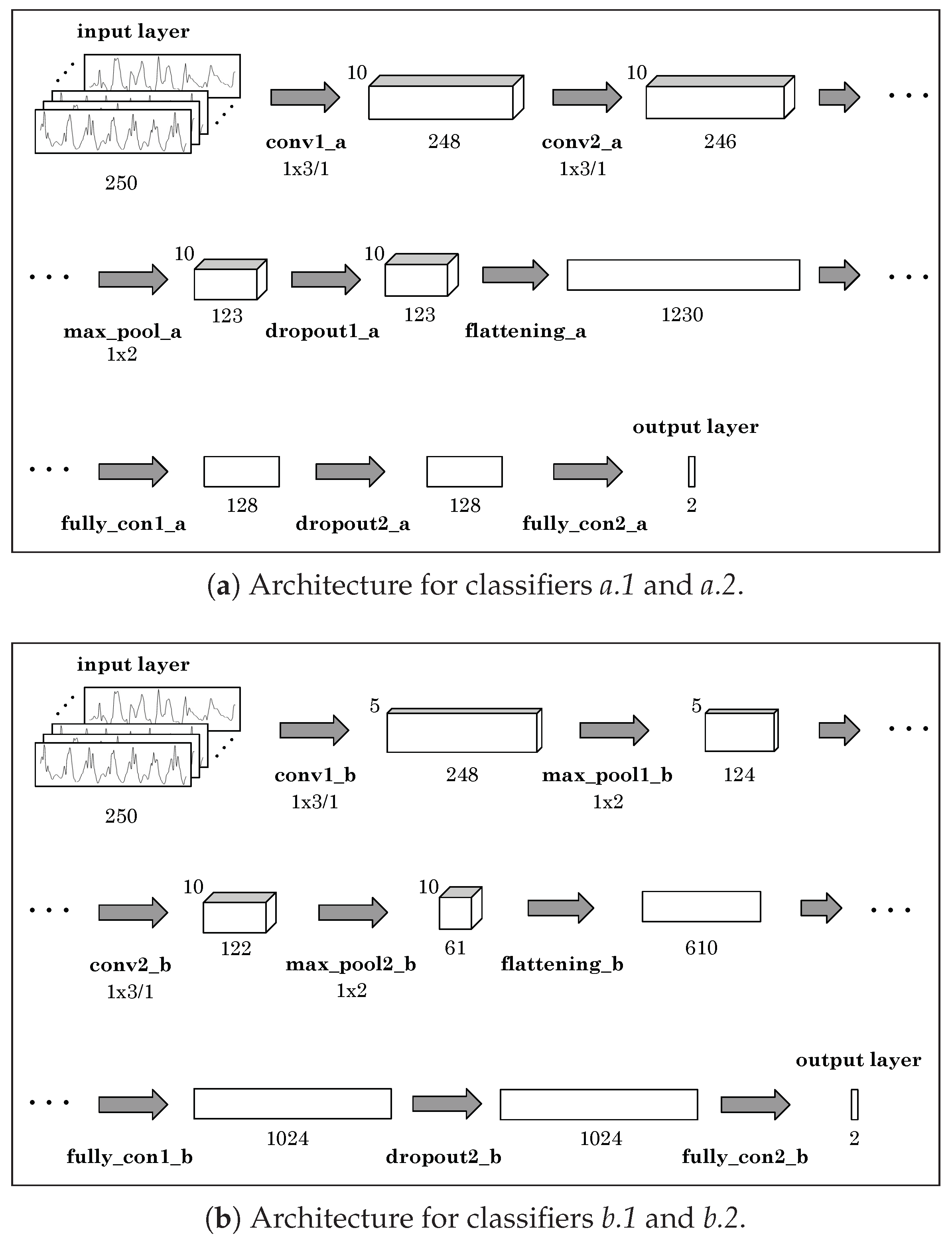
| Layer Name | Kernel Size | # Kernels | Stride | Feature Map. | # Params |
|---|---|---|---|---|---|
| conv1_a | 1 × 3 | 10 | 1 | 1 × 248 × 10 | 40 |
| conv2_a | 1 × 3 | 10 | 1 | 1 × 246 × 10 | 310 |
| max_pool_a | 1 × 2 | - | 1 | 1 × 123 × 10 | 0 |
| dropout1_a | - | - | - | 1 × 123 × 10 | 0 |
| flattening_a | - | - | - | 1 × 1230 × 1 | 0 |
| fully_con1_a | - | - | - | 1 × 128 × 1 | 157,568 |
| dropout2_a | - | - | - | 1 × 128 × 1 | 0 |
| fully_con2_a | - | - | - | 1 × 2 × 1 | 258 |
| Layer Name | Kernel Size | # Kernels | Stride | Feature Map. | # Params |
|---|---|---|---|---|---|
| conv1_b | 1 × 3 | 5 | 1 | 1 × 248 × 5 | 20 |
| max_pool1_b | 1 × 2 | - | 1 | 1 × 124 × 5 | 0 |
| conv2_b | 1 × 3 | 10 | 1 | 1 × 122 × 10 | 160 |
| max_pool2_b | 1 × 2 | - | - | 1 × 61 × 10 | 0 |
| flattening_b | - | - | - | 1 × 610 × 1 | 0 |
| fully_con1_b | - | - | - | 1 × 1024 × 1 | 625,664 |
| dropout_b | - | - | - | 1 × 1024 × 1 | 0 |
| fully_con2 _b | - | - | - | 1 × 2 × 1 | 2050 |
| Feature Selection Method | Classifier | TP | FP | TN | FN | Sensitivity | Specificity | Accuracy |
|---|---|---|---|---|---|---|---|---|
| Manual selection | Random Forests | 4708 | 19 | 500 | 237 | 0.9521 | 0.9634 | 0.9531 |
| RBF SVM | 4703 | 19 | 500 | 242 | 0.9511 | 0.9634 | 0.9522 | |
| GBM | 4707 | 29 | 490 | 238 | 0.9519 | 0.9441 | 0.9511 | |
| kNN () | 4723 | 48 | 471 | 222 | 0.9551 | 0.9075 | 0.9506 | |
| Linear SVM | 4642 | 44 | 475 | 303 | 0.9387 | 0.9152 | 0.9365 | |
| Naïve Bayes | 4654 | 61 | 458 | 291 | 0.9412 | 0.8825 | 0.9356 | |
| C5.0 | 4633 | 48 | 471 | 312 | 0.9369 | 0.9075 | 0.9341 | |
| Deep learning | CNN (architecture a.1) | 4632 | 38 | 481 | 313 | 0.9359 | 0.9282 | 0.9357 |
| CNN (architecture a.2) | 4563 | 50 | 469 | 382 | 0.9210 | 0.9115 | 0.9210 | |
| CNN (architecture b.1) | 4567 | 32 | 487 | 378 | 0.9251 | 0.9211 | 0.9250 | |
| CNN (architecture b.2) | 4596 | 47 | 472 | 349 | 0.9276 | 0.9247 | 0.9275 | |
| Deep learning (oversampling data) | CNN (architecture a.1) | 3100 | 3 | 3003 | 100 | 0.9834 | 0.9819 | 0.9834 |
| CNN (architecture a.2) | 3080 | 17 | 3005 | 92 | 0.9824 | 0.9803 | 0.9824 | |
| CNN (architecture b.1) | 3098 | 5 | 3019 | 84 | 0.9857 | 0.9853 | 0.9857 | |
| CNN (architecture b.2) | 3069 | 28 | 3016 | 81 | 0.9824 | 0.9830 | 0.9824 |
| Pattern Selection Method | Classifier | No. of Patterns | TP | FP | TN | FN | Sensitivity | Specificity | Accuracy |
|---|---|---|---|---|---|---|---|---|---|
| RBF SVM support vectors | RBF SVM | 1551 | 4724 | 33 | 486 | 221 | 0.9553 | 0.9364 | 0.9535 |
| 221 | 4611 | 121 | 398 | 334 | 0.9325 | 0.7669 | 0.9167 | ||
| 5 | 4586 | 126 | 393 | 359 | 0.9274 | 0.7572 | 0.9112 | ||
| Random Forests | 1551 | 4674 | 35 | 484 | 271 | 0.9452 | 0.9326 | 0.9440 | |
| 221 | 4573 | 75 | 444 | 372 | 0.9248 | 0.8555 | 0.9182 | ||
| 5 | 4378 | 109 | 410 | 567 | 0.8853 | 0.7900 | 0.8763 | ||
| GBM | 1551 | 4668 | 37 | 482 | 277 | 0.9440 | 0.9287 | 0.9425 | |
| 221 | 4547 | 82 | 437 | 398 | 0.9195 | 0.8420 | 0.9122 | ||
| 5 | 4497 | 116 | 403 | 448 | 0.9094 | 0.7765 | 0.8968 | ||
| Linear SVM | 1551 | 4621 | 37 | 482 | 324 | 0.9345 | 0.9287 | 0.9339 | |
| 221 | 4449 | 52 | 467 | 496 | 0.8997 | 0.8998 | 0.8997 | ||
| 5 | 4425 | 115 | 404 | 520 | 0.8948 | 0.7784 | 0.8838 | ||
| kNN () | 1551 | 4703 | 69 | 450 | 242 | 0.9511 | 0.8671 | 0.9431 | |
| 221 | 4563 | 68 | 41 | 382 | 0.9228 | 0.8690 | 0.9176 | ||
| 5 | 4330 | 105 | 414 | 615 | 0.8756 | 0.7977 | 0.8682 | ||
| Naïve Bayes | 1551 | 4660 | 146 | 373 | 285 | 0.9424 | 0.7187 | 0.9211 | |
| 221 | 4607 | 132 | 387 | 338 | 0.9316 | 0.7457 | 0.9140 | ||
| 5 | 4541 | 123 | 396 | 404 | 0.9183 | 0.7630 | 0.9036 | ||
| C5.0 | 1551 | 4400 | 56 | 463 | 545 | 0.8898 | 0.8921 | 0.8900 | |
| 221 | 4176 | 84 | 435 | 769 | 0.8445 | 0.8382 | 0.9439 | ||
| 5 | 4683 | 136 | 383 | 262 | 0.9470 | 0.7380 | 0.9272 | ||
| PAM medoids | RBF SVM | 180 | 4651 | 47 | 472 | 294 | 0.9405 | 0.9094 | 0.9376 |
| 10 | 4555 | 81 | 438 | 390 | 0.9211 | 0.8439 | 0.9138 | ||
| 4 | 4623 | 104 | 415 | 322 | 0.9349 | 0.7996 | 0.9220 | ||
| 2 | 4323 | 149 | 370 | 622 | 0.8742 | 0.7129 | 0.8589 | ||
| Random Forests | 180 | 4633 | 57 | 462 | 312 | 0.9369 | 0.8902 | 0.9325 | |
| 10 | 4513 | 77 | 442 | 432 | 0.9126 | 0.8516 | 0.9068 | ||
| 4 | 4410 | 91 | 428 | 535 | 0.8918 | 0.8247 | 0.8854 | ||
| 2 | 3973 | 126 | 393 | 972 | 0.8034 | 0.7572 | 0.7990 | ||
| GBM | 180 | 4598 | 53 | 466 | 347 | 0.9298 | 0.8979 | 0.9268 | |
| 10 | 4468 | 70 | 449 | 447 | 0.9035 | 0.8651 | 0.8999 | ||
| 4 | 4500 | 94 | 425 | 445 | 0.9100 | 0.8189 | 0.9014 | ||
| 2 | 4229 | 120 | 399 | 716 | 0.8552 | 0.7688 | 0.8470 | ||
| Linear SVM | 180 | 4511 | 38 | 481 | 434 | 0.9122 | 0.9268 | 0.9136 | |
| 10 | 4544 | 89 | 430 | 401 | 0.9189 | 0.8285 | 0.9103 | ||
| 4 | 4496 | 123 | 396 | 449 | 0.9092 | 0.7630 | 0.8953 | ||
| 2 | 4311 | 156 | 363 | 634 | 0.8718 | 0.6994 | 0.8554 | ||
| kNN () | 180 | 4629 | 66 | 453 | 316 | 0.9361 | 0.8728 | 0.9301 | |
| 10 | 4572 | 97 | 422 | 373 | 0.9246 | 0.8131 | 0.9140 | ||
| 4 | 4434 | 92 | 425 | 445 | 0.9100 | 0.8189 | 0.9014 | ||
| 2 | 4117 | 120 | 399 | 828 | 0.8326 | 0.7688 | 0.8265 | ||
| Naïve Bayes | 180 | 4526 | 113 | 406 | 419 | 0.9153 | 0.7823 | 0.9026 | |
| 10 | 4346 | 79 | 440 | 599 | 0.8789 | 0.8478 | 0.8759 | ||
| 4 | 4395 | 85 | 434 | 550 | 0.8888 | 0.8362 | 0.8838 | ||
| 2 | 4172 | 156 | 363 | 773 | 0.8437 | 0.6994 | 0.8300 | ||
| C5.0 | 180 | 4362 | 76 | 443 | 583 | 0.8821 | 0.8536 | 0.8794 | |
| 10 | 4293 | 77 | 442 | 652 | 0.8681 | 0.8516 | 0.8666 | ||
| 4 | 4593 | 109 | 410 | 352 | 0.9288 | 0.7900 | 0.9156 | ||
| 2 | 4200 | 144 | 375 | 745 | 0.8493 | 0.7225 | 0.8373 | ||
| Exhaustive search | RBF SVM | 2 | 4492 | 93 | 426 | 453 | 0.9084 | 0.8208 | 0.9001 |
| Random Forests | 2 | 4179 | 89 | 430 | 766 | 0.8451 | 0.8285 | 0.8435 | |
| GBM | 2 | 4306 | 78 | 441 | 639 | 0.8708 | 0.8497 | 0.8688 | |
| Linear SVM | 2 | 4360 | 85 | 434 | 585 | 0.8817 | 0.8362 | 0.8774 | |
| kNN () | 2 | 4293 | 91 | 428 | 625 | 0.8681 | 0.8247 | 0.8640 | |
| Naïve Bayes | 2 | 4135 | 91 | 428 | 810 | 0.8362 | 0.8247 | 0.8351 | |
| C5.0 | 2 | 4587 | 120 | 399 | 358 | 0.9276 | 0.7688 | 0.9125 | |
| Informed search: Breadth-first search | RBF SVM | 4 | 4526 | 68 | 451 | 419 | 0.9153 | 0.8690 | 0.9109 |
| 10 | 4504 | 63 | 456 | 441 | 0.9108 | 0.8786 | 0.9078 | ||
| Random Forests | 4 | 4441 | 68 | 451 | 504 | 0.8981 | 0.8690 | 0.8953 | |
| 10 | 4494 | 60 | 459 | 451 | 0.9088 | 0.8844 | 0.9065 | ||
| GBM | 4 | 4411 | 62 | 457 | 534 | 0.8920 | 0.8805 | 0.8909 | |
| 10 | 4465 | 64 | 455 | 480 | 0.9029 | 0.8767 | 0.9004 | ||
| Linear SVM | 4 | 4376 | 66 | 453 | 569 | 0.8849 | 0.8728 | 0.8838 | |
| 10 | 4443 | 69 | 450 | 502 | 0.8985 | 0.8671 | 0.8955 | ||
| kNN () | 4 | 4434 | 75 | 444 | 511 | 0.8967 | 0.8555 | 0.8928 | |
| 10 | 4430 | 74 | 445 | 515 | 0.8959 | 0.8574 | 0.8922 | ||
| Naïve Bayes | 4 | 4623 | 130 | 389 | 322 | 0.9349 | 0.7495 | 0.9173 | |
| 10 | 4645 | 110 | 409 | 300 | 0.9393 | 0.7881 | 0.9250 | ||
| C5.0 | 4 | 4404 | 86 | 433 | 541 | 0.8906 | 0.8343 | 0.8852 | |
| 10 | 4382 | 64 | 455 | 563 | 0.8861 | 0.8767 | 0.8852 | ||
| Informed search: Simulated Annealing | RBF SVM | 4 | 4656 | 121 | 398 | 289 | 0.9416 | 0.7669 | 0.9250 |
| 10 | 4532 | 92 | 427 | 413 | 0.9165 | 0.8227 | 0.9076 | ||
| Random Forests | 4 | 4414 | 95 | 424 | 531 | 0.8926 | 0.8170 | 0.8854 | |
| 10 | 4496 | 72 | 447 | 449 | 0.9092 | 0.8613 | 0.9046 | ||
| GBM | 4 | 4524 | 110 | 409 | 421 | 0.9128 | 0.7881 | 0.9028 | |
| 10 | 4441 | 83 | 436 | 504 | 0.8981 | 0.8401 | 0.8926 | ||
| Linear SVM | 4 | 4553 | 124 | 395 | 392 | 0.9207 | 0.7611 | 0.9056 | |
| 10 | 4384 | 85 | 434 | 561 | 0.8866 | 0.8362 | 0.8818 | ||
| kNN () | 4 | 4443 | 114 | 405 | 502 | 0.8985 | 0.7803 | 0.8873 | |
| 10 | 4471 | 98 | 421 | 747 | 0.9041 | 0.8112 | 0.8953 | ||
| Naïve Bayes | 4 | 4546 | 142 | 377 | 399 | 0.9193 | 0.7264 | 0.9010 | |
| 10 | 4595 | 135 | 384 | 350 | 0.9292 | 0.7399 | 0.9112 | ||
| C5.0 | 4 | 4413 | 101 | 418 | 535 | 0.8924 | 0.8054 | 0.8842 | |
| 10 | 4134 | 71 | 448 | 811 | 0.8360 | 0.8632 | 0.8386 |
| Ensemble Method | TP | FP | TN | FN | Sensitivity | Specificity | Accuracy |
|---|---|---|---|---|---|---|---|
| Top layer RBF SVM | 4766 | 30 | 489 | 179 | 0.9638 | 0.9422 | 0.9617 |
| Top layer C5.0 | 4746 | 24 | 495 | 199 | 0.9598 | 0.9538 | 0.9592 |
| Logistic Regression WA | 4708 | 19 | 500 | 237 | 0.9521 | 0.9634 | 0.9531 |
| Top layer Naïve Bayes | 4539 | 8 | 511 | 406 | 0.9179 | 0.9846 | 0.9242 |
| Top layer Linear SVM | 4441 | 9 | 510 | 504 | 0.8981 | 0.9827 | 0.9061 |
| Top layer GBM | 4426 | 9 | 510 | 519 | 0.8950 | 0.9827 | 0.9034 |
| Top layer Random Forests | 4419 | 7 | 512 | 526 | 0.8936 | 0.9865 | 0.9025 |
| Top layer kNN () | 4418 | 9 | 510 | 527 | 0.8934 | 0.9827 | 0.9019 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casado, F.E.; Rodríguez, G.; Iglesias, R.; Regueiro, C.V.; Barro, S.; Canedo-Rodríguez, A. Walking Recognition in Mobile Devices. Sensors 2020, 20, 1189. https://doi.org/10.3390/s20041189
Casado FE, Rodríguez G, Iglesias R, Regueiro CV, Barro S, Canedo-Rodríguez A. Walking Recognition in Mobile Devices. Sensors. 2020; 20(4):1189. https://doi.org/10.3390/s20041189
Chicago/Turabian StyleCasado, Fernando E., Germán Rodríguez, Roberto Iglesias, Carlos V. Regueiro, Senén Barro, and Adrián Canedo-Rodríguez. 2020. "Walking Recognition in Mobile Devices" Sensors 20, no. 4: 1189. https://doi.org/10.3390/s20041189