Estimation of Flat Object Deformation Using RGB-D Sensor for Robot Reproduction



Abstract
1. Introduction
- (1)
- The first proposal is based on a weighted graph for non-rigid point matching and clustering to find potential planes and establish the correspondence between each pair of planes on two RGB images. Compared to previous methods, it can preserve the neighborhood structure and has better robustness under changing conditions, where an object is deformed with various folding angles or in a complex environment such as with occlusions.
- (2)
- The second proposal uses a refined region growing method for the plane detection which is based on an offset error defined by ourselves. Compared to previous methods, it can detect a 3D plane from depth data and avoid overgrowing without increasing the computational load, thereby improving accuracy.
- (3)
- The third proposal is the development of a novel sliding checking model which consists of four three-dimensional (3D) points and three line segments. The checking model can confirm the adjacent relationship between each pair of planes. Therefore, it is possible to estimate the deformation process based on the obtained information and reproduce the same deformation.
2. Previous Works and Related Studies
2.1. Deformable Surface 3D Reconstruction
2.1.1. RGB Image Only
2.1.2. Data from RGB-D Cameras
2.2. Important Technique for Understanding the Deformed Object
2.2.1. Non-Rigid Point Matching
2.2.2. Plane Detection on Depth Data
3. Methodology
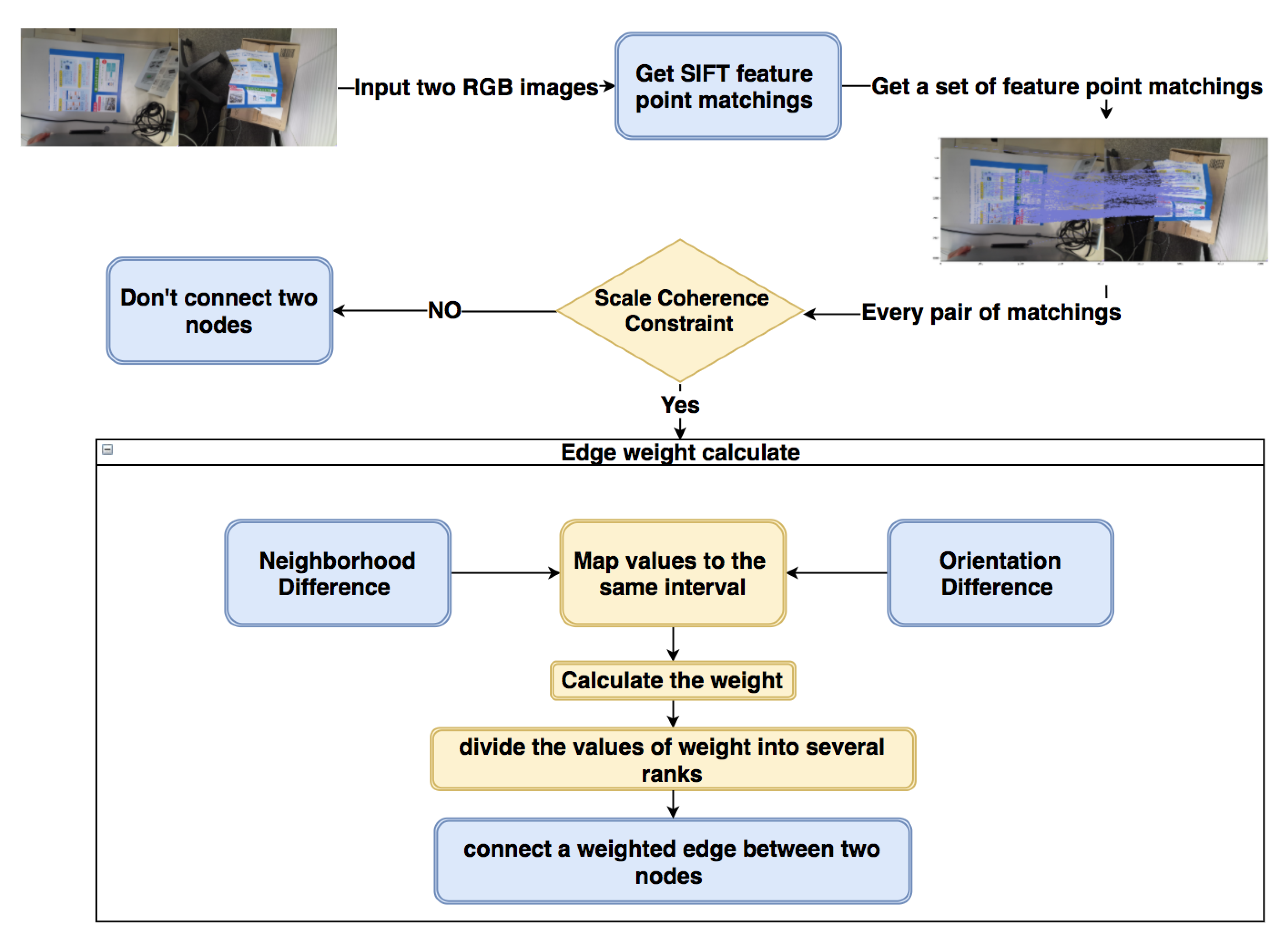
- The blue blocks of Figure 1 use the weighted graph clustering method to find potential planes and establish the correspondence between each pair of planes on two RGB images. Here, a weighted graph is built based on the dense feature point matchings performed by SIFT (Scale-Invariant Feature Transform) [32] and clustered by the Markov Cluster Algorithm [42] so that the points in each cluster belong to the same plane. The detailed process will be explained in Section 3.1.
- After getting a set of clusters, the yellow blocks in Figure 1 use a refined region growing method to estimate each plane and calculate possible bending lines and folding angles between each pair of planes. The details of this part will be explained in Section 3.2.
- The green parts of Figure 1 confirm the adjacent relationship between each pair of planes by a novel sliding checking model. There are more details of sliding checking model in Section 3.3. In the red blocks, a projection method is used to check the performance of the entire system, which will be explained in Section 4.3.1.
3.1. Non-Rigid Point Matching and Clustering Based on the Weighted Graph
3.1.1. Weighted Graph Construction
- (1)
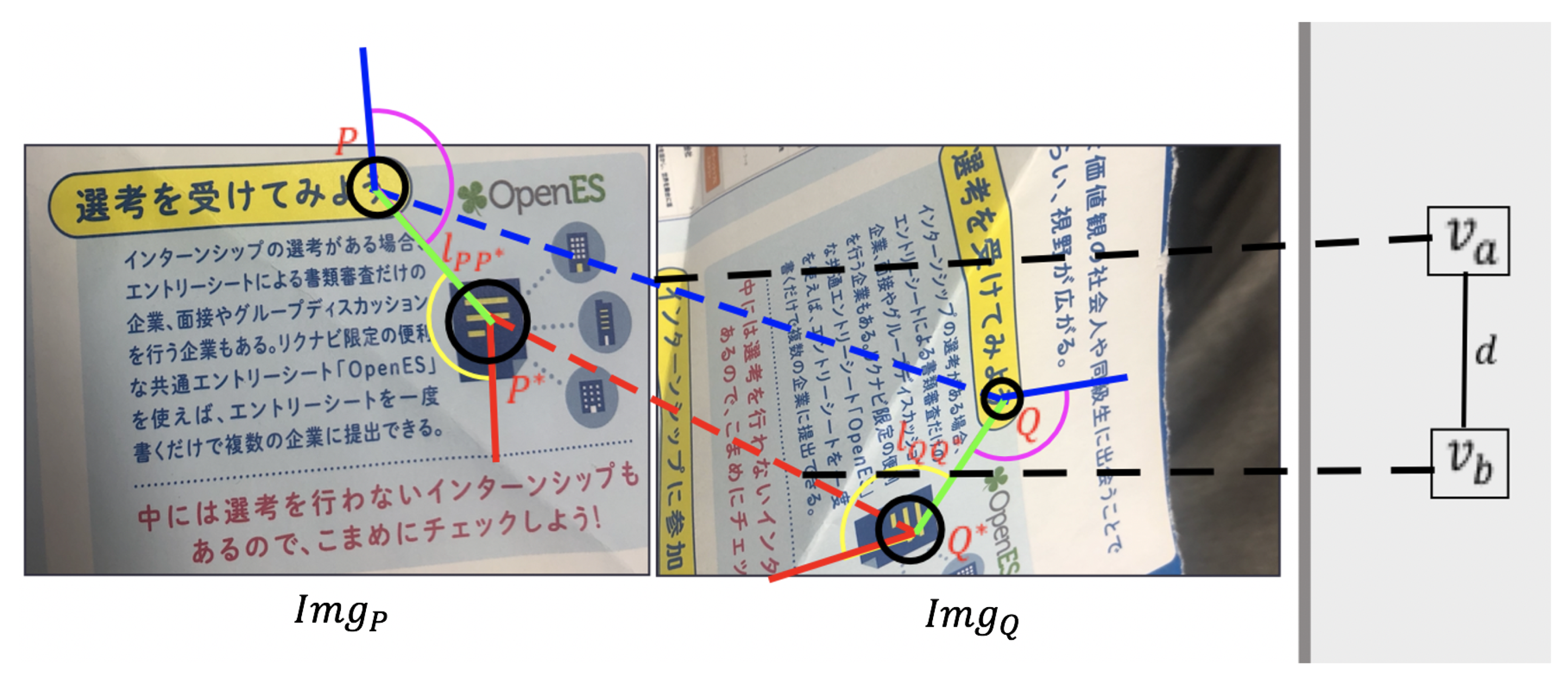
- Calculate the Scale CoherenceFor each pair of and , the scale of feature points will be consistent with the scale of the image they belong to, so we use Equation (1) to evaluate the scaling consistency. According to it, some bad matchings that don’t satisfy the scaling consistency can be distinguished and removed. Therefore, if a pair of matchings and don’t pass the scale coherence checking, we will not use an edge to connect these two nodes:In Figure 3, and are the spatial distances of two feature points in each image. With those spatial distances and the scale of the feature points in each image, we estimate an error like to check the scaling consistency. is a threshold which is set to . If and satisfy the Equation (1) on the scale coherence, there will be an edge between the nodes and in the weighted graph.
- (2)
- Calculate the Neighborhood Difference and Orientation DifferenceThe weight of the edge between each pair of nodes will be calculated based on the neighborhood difference and the orientation difference. For each pair of nodes, the more significant the neighborhood difference and orientation difference are, the less likely that they belong to the same plane. Therefore, those two differences and the weight of the edge between the two nodes are positively correlated. Firstly, we need to calculate the neighborhood difference and the orientation difference separately.The neighborhood difference is calculated by Equation (2):where represents the number of the feature points which are closer to point P than point in the image , and represents the number of the feature points which are closer to point Q than point in the image . For each pair of P and , we save the value of in a set ; for each pair of Q and , the value of is saved in another set .In Equation (2), to make the and have the same level of influence, we map the and to the same interval , where is the number of possible edges. For example, if the quantity of the weighted graph’s nodes is N, then .The orientation difference is calculated by Equation (3):In Equation (3), , , , and are the orientation of the feature points shown in Figure 3. The is the orientation from to , so represents the pink angle around point P in Figure 3, and represents the yellow angle around the point in Figure 3.To make the orientation difference have the same level of influence as the neighborhood difference, we also map the orientation difference to the interval by Equation (4):
- (3)
- Weight Generation.After getting the neighborhood difference and orientation difference, which are mapped to the same interval, we will use them to generate the weight of the edge by Equation (5):where we use the product of the neighborhood difference and orientation difference to represent the distance between two nodes and . Then, the value of each will be saved in a set . With the , we use Equation (6) to map the weight to the interval , which is same as the one in Equations (2) and (4):By Equation (6), we can get the final weight of each edge. However, the clustering algorithm will fail while dealing with a large number of continuous values with low discrimination. To avoid the failure of clustering, we need to pre-process the weight before applying the clustering algorithm. Therefore, a is defined in Equation (7) to divide the weight into several ranks:In Equation (7), is equal to the maximum value of , and is the quantity of ranks we want to divide. The value of can determine the clustering result by affecting the tightness of the connection in the graph: if is too big, a large cluster may be divided into several small clusters; if is too small, several different small clusters may be combined into the same cluster. Obviously, too big will only increase the subsequent calculation load but will not cause errors, but too small can cause worse effects. Through the experiments in different situations similar to Section 4.2.1, we find the in the interval can almost avoid the situation where the is too small. For the case of too large , which still may happen, the secondary clustering in Section 3.2.4 can eliminate its influence. Therefore, this assumption can handle most general situations.For example, Figure 4a is the histogram of the we have gotten. Then, we use the to divide the set of the into seven ranks, where the ranks will be . Weight values in each rank will be set to the same value, only the first rank is set to 1, and the rest of the ranks are set to the lower limit of the interval. Then, the weight values of 7 ranks are like , which is shown in Figure 4b. However, in the Markov Cluster Algorithm [42], the weight of an edge is the reciprocal of distance, so we take the inverse of ranks to be the final weights. The final weight ranks of the weighted graph are . After setting the weight to each edge, the Markov Cluster Algorithm will be applied to get the clusters in the next step.
3.1.2. Applying Markov Cluster Algorithm to the Graph
3.2. Plane Detection on Depth Data
3.2.1. Coordinate Conversion
3.2.2. Find a Seed Patch
3.2.3. Iterative Region Growing Process
3.2.4. Combine the Clusters on the Same Plane
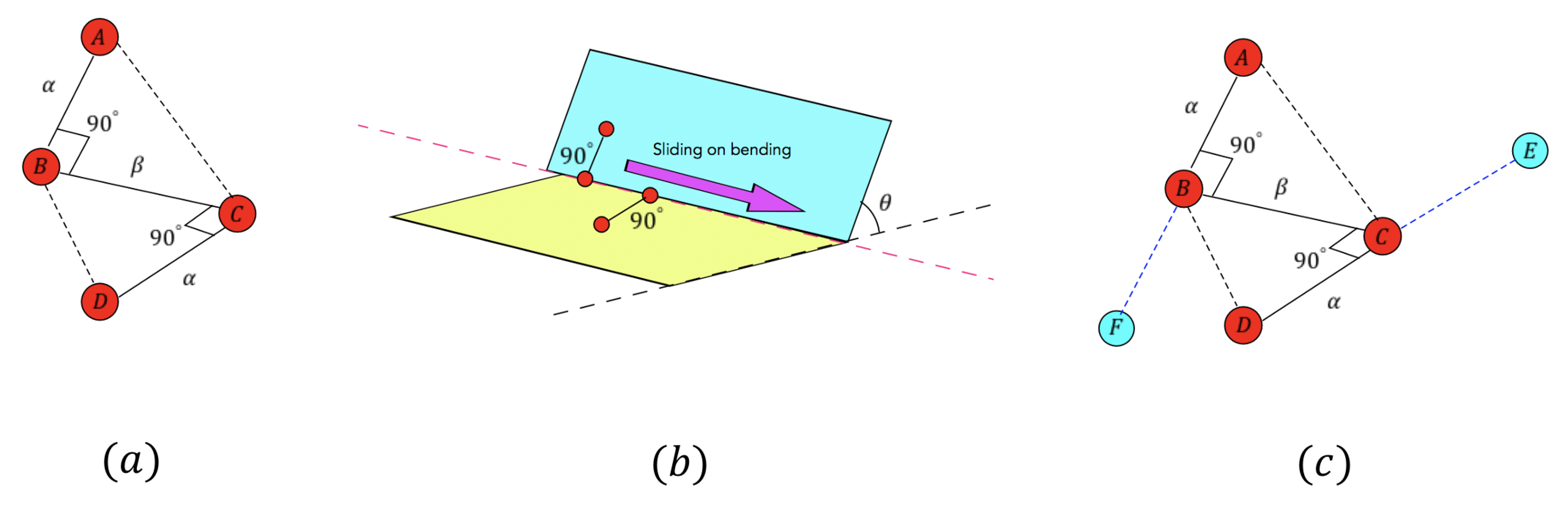
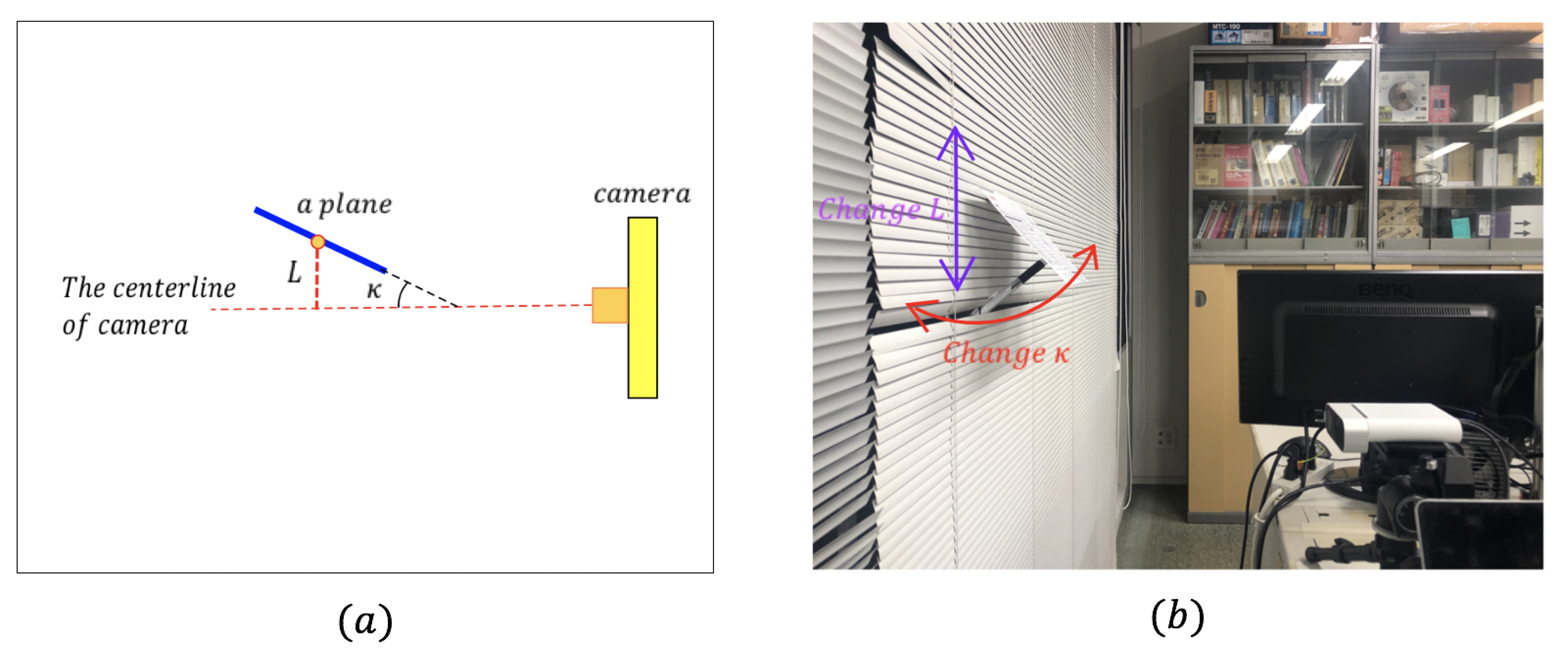
3.3. Sliding Checking Model
3.3.1. Initializing Sliding Checking Model
3.3.2. Sliding the Model
4. Experimental Setup and Evaluation Results
4.1. Experimental Setup
4.2. Evaluation of Improved Techniques
4.2.1. Clustering
4.2.2. Region Growing Comparison
4.3. Evaluation of Total Performance
4.3.1. Total Performance
4.3.2. Discussion of Working Conditions
4.4. Data for Reproduction by a Robot
5. Conclusions
- (a)
- The comparison of clustering in Section 4.2.1 shows that our weighted graph approach has better robustness than the old method of [41] when the object is deformed with various folding angles or in a complex environment such as with occlusions.
- (b)
- The experiment of region growing in Section 4.2.2 shows that our refined region growing approach can avoid overgrowing without any additional process. It can reduce the time cost in calculation and improve the accuracy and speed of the total system.
- (c)
- In Section 4.3.1, we have evaluated the total performance and confirmed that its performance with around average angular error is acceptable based on which a robot would be able to reproduce the same deformation by folding the paper.
- (d)
- Section 4.3.2 has discussed the conditions for the entire system to work effectively. Our system can have good performance when the following two conditions are met: Deformation is only caused by folding. Each potential plane can be detected by the non-rigid point matching method from the RGB image. In addition, the object with the following surface texture can’t be supported: monochromatic and no pattern, the same pattern is repeated, and the pattern has little change.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cohen, L.D.; Cohen, I. Finite-element methods for active contour models and balloons for 2-D and 3-D images. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1131–1147. [Google Scholar] [CrossRef]
- Metaxas, D.; Terzopoulos, D. Shape and nonrigid motion estimation through physics-based synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 580–591. [Google Scholar] [CrossRef]
- Urtasun, R.; Fleet, D.J.; Hertzmann, A.; Fua, P. Priors for people tracking from small training sets. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 403–410. [Google Scholar] [CrossRef]
- Perriollat, M.; Bartoli, A. A Quasi-Minimal Model for Paper-Like Surfaces. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–7. [Google Scholar] [CrossRef]
- McInerney, T.; Terzopoulos, D. A finite element model for 3D shape reconstruction and nonrigid motion tracking. In Proceedings of the 1993 (4th) International Conference on Computer Vision, Berlin, Germany, 11–14 May 1993; pp. 518–523. [Google Scholar] [CrossRef]
- Malti, A.; Bartoli, A.; Collins, T. A pixel-based approach to template-based monocular 3D reconstruction of deformable surfaces. In Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 1650–1657. [Google Scholar]
- Bregler, C.; Hertzmann, A.; Biermann, H. Recovering non-rigid 3D shape from image streams. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No.PR00662), Hilton Head Island, SC, USA, 15 June 2000; Volume 2, pp. 690–696. [Google Scholar] [CrossRef]
- Torresani, L.; Hertzmann, A.; Bregler, C. Nonrigid Structure-from-Motion: Estimating Shape and Motion with Hierarchical Priors. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 878–892. [Google Scholar] [CrossRef] [PubMed]
- Akhter, I.; Sheikh, Y.; Khan, S. In defense of orthonormality constraints for nonrigid structure from motion. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1534–1541. [Google Scholar] [CrossRef]
- Gotardo, P.F.U.; Martinez, A.M. Kernel non-rigid structure from motion. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 802–809. [Google Scholar] [CrossRef]
- Varol, A.; Salzmann, M.; Tola, E.; Fua, P. Template-free monocular reconstruction of deformable surfaces. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1811–1818. [Google Scholar] [CrossRef]
- Taylor, J.; Jepson, A.D.; Kutulakos, K.N. Non-rigid structure from locally-rigid motion. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2761–2768. [Google Scholar] [CrossRef]
- Russell, C.; Fayad, J.; Agapito, L. Energy based multiple model fitting for non-rigid structure from motion. CVPR 2011, 3009–3016. [Google Scholar] [CrossRef]
- Salzmann, M.; Hartley, R.; Fua, P. Convex Optimization for Deformable Surface 3-D Tracking. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Wang, C.; Li, X.; Liu, Y. Monocular 3D Tracking of Deformable Surfaces Using Linear Programming. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1710–1713. [Google Scholar]
- Tsoli, A.; Argyros, A.A. Patch-Based Reconstruction of a Textureless Deformable 3D Surface from a Single RGB Image. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 4034–4043. [Google Scholar]
- Bednarik, J.; Fua, P.; Salzmann, M. Learning to Reconstruct Texture-Less Deformable Surfaces from a Single View. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 606–615. [Google Scholar]
- Ye, G.; Liu, Y.; Hasler, N.; Ji, X.; Dai, Q.; Theobalt, C. Performance capture of interacting characters with handheld kinects. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 828–841. [Google Scholar]
- Elanattil, S.; Moghadam, P.; Denman, S.; Sridharan, S.; Fookes, C. Skeleton Driven Non-Rigid Motion Tracking and 3D Reconstruction. In Proceedings of the 2018 Digital Image Computing: Techniques and Applications (DICTA), Canberra, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Lim, J.; Yang, M.-H. A direct method for modeling non-rigid motion with thin plate spline. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 1196–1202. [Google Scholar] [CrossRef]
- Kozlov, C.; Slavcheva, M.; Ilic, S. Patch-Based Non-rigid 3D Reconstruction from a Single Depth Stream. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 42–51. [Google Scholar] [CrossRef]
- Tsoli, A.; Argyros, A.A. Tracking Deformable Surfaces That Undergo Topological Changes Using an RGB-D Camera. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 333–341. [Google Scholar] [CrossRef]
- Paulus, C.J.; Haouchine, N.; Cazier, D.; Cotin, S. Augmented Reality during Cutting and Tearing of Deformable Objects. In Proceedings of the 2015 IEEE International Symposium on Mixed and Augmented Reality, Fukuoka, Japan, 29 September–3 October 2015; pp. 54–59. [Google Scholar] [CrossRef]
- Zhang, Q.; Fu, B.; Ye, M.; Yang, R. Quality Dynamic Human Body Modeling Using a Single Low-cost Depth Camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Dou, M.; Taylor, J.; Fuchs, H.; Fitzgibbon, A.; Izadi, S. 3D scanning deformable objects with a single RGBD sensor. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 493–501. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, G.; Xia, S. Templateless Non-Rigid Reconstruction and Motion Tracking With a Single RGB-D Camera. IEEE Trans. Image Process. 2017, 26, 5966–5979. [Google Scholar] [CrossRef]
- Slavcheva, M.; Baust, M.; Cremers, D.; Ilic, S. KillingFusion: Non-rigid 3D Reconstruction without Correspondences. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5474–5483. [Google Scholar] [CrossRef]
- Yang, J.; Guo, D.; Li, K.; Wu, Z.; Lai, Y. Global 3D Non-Rigid Registration of Deformable Objects Using a Single RGB-D Camera. IEEE Trans. Image Process. 2019, 28, 4746–4761. [Google Scholar] [CrossRef]
- Cui, C.; Ngan, K.N. Global Propagation of Affine Invariant Features for Robust Matching. IEEE Trans. Image Process. 2013, 22, 2876–2888. [Google Scholar] [CrossRef]
- Chum, O.; Matas, J. Matching with PROSAC - progressive sample consensus. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 220–226. [Google Scholar] [CrossRef]
- Zhu, J.; Lyu, M.R. Progressive Finite Newton Approach To Real-time Nonrigid Surface Detection. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Ma, J.; Zhao, J.; Tian, J.; Yuille, A.L.; Tu, Z. Robust Point Matching via Vector Field Consensus. IEEE Trans. Image Process. 2014, 23, 1706–1721. [Google Scholar] [CrossRef]
- Besl, P.J.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Chui, H.; Rangarajan, A. A new algorithm for non-rigid point matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No.PR00662), Hilton Head Island, SC, USA, 15 June 2000; Volume 2, pp. 44–51. [Google Scholar] [CrossRef]
- Sofka, M.; Yang, G.; Stewart, C.V. Simultaneous Covariance Driven Correspondence (CDC) and Transformation Estimation in the Expectation Maximization Framework. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Zheng, Y.; Doermann, D. Robust point matching for nonrigid shapes by preserving local neighborhood structures. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 643–649. [Google Scholar] [CrossRef]
- Izadi, M.; Saeedi, P. Robust Weighted Graph Transformation Matching for Rigid and Nonrigid Image Registration. IEEE Trans. Image Process. 2012, 21, 4369–4382. [Google Scholar] [CrossRef] [PubMed]
- Leordeanu, M.; Hebert, M. A spectral technique for correspondence problems using pairwise constraints. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 1482–1489. [Google Scholar] [CrossRef]
- Qu, H.; Wang, J.; Li, B.; Yu, M. Probabilistic Model for Robust Affine and Non-Rigid Point Set Matching. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 371–384. [Google Scholar] [CrossRef] [PubMed]
- Tarashima, S.; Shimamura, J.; Kinebuchi, T.; Satah, S. Keypoint Matching for Non-Rigid Object via Locally Consistent Visual Pattern Mining. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 758–762. [Google Scholar]
- Macropol, K. Clustering on Graphs: The Markov Cluster Algorithm (MCL); University of Utrecht: Utrecht, The Netherlands, 2009. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Qian, X.; Ye, C. NCC-RANSAC: A Fast Plane Extraction Method for 3-D Range Data Segmentation. IEEE Trans. Cybern. 2014, 44, 2771–2783. [Google Scholar] [CrossRef] [PubMed]
- Yue, W.; Lu, J.; Zhou, W.; Miao, Y. A new plane segmentation method of point cloud based on mean shift and RANSAC. In Proceedings of the 2018 Chinese Control And Decision Conference (CCDC), Shenyang, China, 9–11 June 2018; pp. 1658–1663. [Google Scholar] [CrossRef]
- Xu, D.; Li, F.; Wei, H. 3D Point Cloud Plane Segmentation Method Based on RANSAC And Support Vector Machine. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 943–948. [Google Scholar] [CrossRef]
- Hulik, R.; Spanel, M.; Smrz, P.; Materna, Z. Continuous plane detection in point-cloud data based on 3D Hough Transform. J. Vis. Commun. Image Represent. 2014, 25, 86–97. [Google Scholar] [CrossRef]
- Kiryati, N.; Eldar, Y.; Bruckstein, A.M. A probabilistic Hough transform. Pattern Recognit. 1991, 24, 303–316. [Google Scholar] [CrossRef]
- Huang, H.; Brenner, C. Rule-based roof plane detection and segmentation from laser point clouds. In Proceedings of the 2011 Joint Urban Remote Sensing Event, Munich, Germany, 11–13 April 2011; pp. 293–296. [Google Scholar] [CrossRef]
- Fernandes, L.A.; Oliveira, M.M. Real-time line detection through an improved Hough transform voting scheme. Pattern Recognit. 2008, 41, 299–314. [Google Scholar] [CrossRef]
- Hähnel, D.; Burgard, W.; Thrun, S. Learning compact 3D models of indoor and outdoor environments with a mobile robot. Robot. Auton. Syst. 2003, 44, 15–27. [Google Scholar] [CrossRef]
- Poppinga, J.; Vaskevicius, N.; Birk, A.; Pathak, K. Fast plane detection and polygonalization in noisy 3D range images. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3378–3383. [Google Scholar] [CrossRef]
- Xiao, J.; Adler, B.; Zhang, H. 3D point cloud registration based on planar surfaces. In Proceedings of the 2012 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Hamburg, Germany, 13–15 September 2012; pp. 40–45. [Google Scholar] [CrossRef]
- Smisek, J.; Jancosek, M.; Pajdla, T. 3D with Kinect. In Consumer Depth Cameras for Computer Vision; Springer: Berlin/Heidelberg, Germany, 2013; pp. 3–25. [Google Scholar]
- Deng, Z.; Todorovic, S.; Latecki, L.J. Unsupervised object region proposals for RGB-D indoor scenes. Comput. Vis. Image Underst. 2017, 154, 127–136. [Google Scholar] [CrossRef]
- Holz, D.; Behnke, S. Approximate triangulation and region growing for efficient segmentation and smoothing of range images. Robot. Auton. Syst. 2014, 62, 1282–1293. [Google Scholar] [CrossRef]
- Jin, Z.; Tillo, T.; Zou, W.; Zhao, Y.; Li, X. Robust Plane Detection Using Depth Information From a Consumer Depth Camera. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 447–460. [Google Scholar] [CrossRef]
- Sally, S.L.; Gurnsey, R. Orientation discrimination in foveal and extra-foveal vision: Effects of stimulus bandwidth and contrast. Vis. Res. 2003, 43, 1375–1385. [Google Scholar] [CrossRef][Green Version]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Priori Knowledge Based (RGB) | NRSFM (RGB) | Template-Based (RGB-D) | Templateless (RGB-D) | Our Approach (RGB-D) |
|---|---|---|---|---|---|
| Input data | RGB images | RGB images | RGB images with depth data | RGB images with depth data | RGB images with depth data |
| Priori knowledge | Models or reference point correspondence | Doesn’t require | Pre-defined template | Doesn’t require | Doesn’t require |
| Accuracy | Acceptable | Acceptable | Higher than RGB methods | Higher than RGB methods | Higher than RGB methods |
| Output | Global result in virtual space | Global result in virtual space | Global result in real space | Global result in real space | Segmental elements with their relationship in real space |
| For robot understanding | Hard | Hard | Hard | Hard | Easy |
| Item | Outlier Removal by Constraints | Iteration Based | Previous Graph-Based | Our Approach |
|---|---|---|---|---|
| Robustness | Sensitive to outliers | Sensitive to outliers | Sensitive to changing conditions | Robust with changing conditions |
| Local neighborhood structures | can’t preserve | can’t preserve | can preserve | can preserve |
| Item | RANSAC | Hough Transform | Previous Region Growing | Our Approach |
|---|---|---|---|---|
| Accuracy | High to large planes | High | High | High |
| Computational load | High | Very high | High | High |
| Robustness | Weak to complex planar structures | Robust to noisy environment | Weak to the overgrowing | Avoid overgrowing problem |
| Error between Two Planes | Similarity |
|---|---|
| Around | Around 20 |
| Around | Around 30 |
| Around | Around 50 |
| Around | Around 80 |
| Item | Specification |
|---|---|
| Product | Microsoft Azure Kinect |
| Dimensions | 103 × 39 × 126 mm |
| Weight | 440 g |
| Interface | USB 2.0/3.0 |
| Max Resolution | 1024× 1024(depth)/4096× 3072(RGB) |
| Depth measurable range | 0.25–5.46 m |
| Typical systematic error | <11 mm + 0.1% of distance without multi-path interference |
| Tandom error | ≤17 mm |
| FPS (Frames-per-second) | 0, 5, 15, 30 FPS |
| Power consumption | 5.9 W |
| SDK system requirements | Windows 10 April 2018 (Version 1803, OS Build 17134) release (×64)Linux Ubuntu 18.04 (×64), with a GPU driver that uses OpenGLv4.4 |
| Item | Specification |
|---|---|
| CPU/GPU | Seventh Gen Intel® CoreTM i3 Processor (Dual Core 2.4 GHz with HD620 GPU or faster) |
| Memory | 4 GB Memory |
| Interface | Dedicated USB3 port |
| Graphics driver | Graphics driver support for OpenGL 4.4 or DirectX 11.0 |
| Item | Specification |
|---|---|
| Operating system | Linux Ubuntu 18.04 (×64) |
| Programming language | Python 3.6 or later version |
| Libraries and Packages | Azure Kinect sensor SDKopencv-python, matplotlib pyk4a, numpy, tkinter |
| Programming IDE | PyCharm |
| Case | Average Angular Error |
|---|---|
| (a) | |
| (b) | |
| (c) | |
| (d) | |
| (e) | |
| (f) | |
| Average |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, X.; Matsumaru, T. Estimation of Flat Object Deformation Using RGB-D Sensor for Robot Reproduction. Sensors 2021, 21, 105. https://doi.org/10.3390/s21010105
He X, Matsumaru T. Estimation of Flat Object Deformation Using RGB-D Sensor for Robot Reproduction. Sensors. 2021; 21(1):105. https://doi.org/10.3390/s21010105
Chicago/Turabian StyleHe, Xin, and Takafumi Matsumaru. 2021. "Estimation of Flat Object Deformation Using RGB-D Sensor for Robot Reproduction" Sensors 21, no. 1: 105. https://doi.org/10.3390/s21010105
APA StyleHe, X., & Matsumaru, T. (2021). Estimation of Flat Object Deformation Using RGB-D Sensor for Robot Reproduction. Sensors, 21(1), 105. https://doi.org/10.3390/s21010105