Abstract
(1) Background: Patients with respiratory conditions typically exhibit adventitious respiratory sounds (ARS), such as wheezes and crackles. ARS events have variable duration. In this work we studied the influence of event duration on automatic ARS classification, namely, how the creation of the Other class (negative class) affected the classifiers’ performance. (2) Methods: We conducted a set of experiments where we varied the durations of the other events on three tasks: crackle vs. wheeze vs. other (3 Class); crackle vs. other (2 Class Crackles); and wheeze vs. other (2 Class Wheezes). Four classifiers (linear discriminant analysis, support vector machines, boosted trees, and convolutional neural networks) were evaluated on those tasks using an open access respiratory sound database. (3) Results: While on the 3 Class task with fixed durations, the best classifier achieved an accuracy of 96.9%, the same classifier reached an accuracy of 81.8% on the more realistic 3 Class task with variable durations. (4) Conclusion: These results demonstrate the importance of experimental design on the assessment of the performance of automatic ARS classification algorithms. Furthermore, they also indicate, unlike what is stated in the literature, that the automatic classification of ARS is not a solved problem, as the algorithms’ performance decreases substantially under complex evaluation scenarios.
1. Introduction
Respiratory diseases are among the most significant causes of morbidity and mortality worldwide [1] and are responsible for a substantial strain on health systems [2]. Early diagnosis and routine monitoring of patients with respiratory conditions are crucial for timely interventions [3]. Health professionals are trained to listen to and to recognize respiratory pathological findings, such as the presence of adventitious respiratory sounds (ARS) (e.g., crackles and wheezes), commonly in the anterior and posterior chest of the patient [4].
Respiratory sounds have been validated as an objective, simple, and noninvasive marker to check the respiratory system [5]. In clinical practice they are commonly assessed with pulmonary auscultation using a stethoscope. Despite the technological advances in auscultation devices, which have enabled the storing, analysis, and visualization of respiratory sounds in computers, digital auscultation is not yet entirely computational. Conventional auscultation is usually employed but has some drawbacks that limit its expansion in clinical practice and suitability in research due to: (i) the necessity of an expert to annotate the presence/absence and clinical meanings of normal/abnormal respiratory sounds [6]; (ii) the unfeasibility of providing continuous monitoring; (iii) its inherent inter-listener variability [7]; (iv) human audition and memory limitations [8]; and (v) as demonstrated during the COVID-19 crisis, it might not be viable in highly contagious situations, as stethoscopes can be a source of infection and need to be constantly sanitized [9]. These limitations could potentially be surmounted by automated respiratory sound analysis.
Respiratory sounds can be normal or abnormal. Normal respiratory sounds are nonmusical sounds provided by breathing and heard over the trachea and chest wall [10]. They show different acoustic properties, such as duration, pitch, and sound quality depending on the characteristics and position of subjects, respiratory flow, and recording location [6,11]. On the other hand, ARS are abnormal sounds that are overlayed on normal respiratory sounds [10]. ARS can be categorized into two main types: continuous and discontinuous [12]. The nomenclature recognized by the European Respiratory Society Task Force on Respiratory Sounds [13] is that continuous ARS are called wheezes, and discontinuous ARS are called crackles, which will be followed in this study.
Crackles are explosive, short, discontinuous, and nonmusical ARS that are attributed to the sudden opening and closing of abnormally closed airways [14]. They usually last less than 20 ms and can be classified as fine or coarse depending on their duration and frequency. Fine crackles have short duration and high frequency, whereas coarse crackles have longer duration and lower frequency [15]. Although the frequency range of crackles is bounded by 60 Hz and 2 kHz, most of their energy is concentrated between 60 Hz and 1.2 kHz [16]. The characteristics of crackles, such as number, regional distribution, timing in the respiratory cycle, and especially the distinction between fine and coarse, can all be used in the diagnosis of various types of lung diseases, such as bronchiectasis or pneumonia [15]. In contrast, wheezes are musical respiratory sounds usually longer than 100 ms. Their typical frequency range is between 100 and 1000 Hz, with harmonics that occasionally exceed 1000 Hz [17]. Wheezes occur when there is flow limitation and can be clinically defined by their duration, intensity, position in the respiratory cycle (inspiratory or expiratory), frequency (monophonic or polyphonic), number, gravity influence, and respiratory maneuvers [14]. Health professionals have utilized wheezes for diagnosing various respiratory conditions in adults (e.g., chronic obstructive pulmonary disease) and in children (e.g., bronchiolitis) [14].
Several authors have reported excellent performance on ARS classification. However, a robust experimental design is lacking in many studies, leading to overestimated results. To determine if a system is relevant, we need to understand the extent to which the characteristics it is extracting from the signal are confounded with the ground truth [18]. In the case of ARS classification, we argue that results in the literature are overestimated because little attention has been dedicated to the design of the negative classes; i.e., the classes against which the wheeze or crackle classification algorithms learn to discriminate.
The main objective of this study was to understand, through a set of experiments with different tasks, how experimental design can impact classification performance. We used four machine learning algorithms in the experiments: linear discriminant analysis (LDA), support vector machines with radial basis function (SVMrbf), random undersampling boosted trees (RUSBoost), and convolutional neural networks (CNNs). The LDA, SVMrbf, and RUSBoost classifiers were fed features extracted from the spectrograms, including some novel acoustic features. On the other hand, the CNNs received spectrogram and mel spectrogram images as inputs.
The article is organized as follows: in Section 2, we provide a general overview of the state-of-the-art on algorithms that have been used in similar works to automatically classify wheezes and crackles; in Section 3, we provide information regarding the dataset, and all the methods used in the different stages of the classification process; in Section 4, the obtained results are presented; and lastly, in Section 5, the results are analyzed and a global conclusion is presented. This paper expands previously published work [19] that focused only on wheeze classification.
2. Related Work
Several features and machine learning approaches have been proposed to develop methods for the automatic classification of respiratory sounds [20,21,22,23,24]. In most systems, suitable features are extracted from the signal and are subsequently used to classify ARS (i.e., crackles and wheezes). The most common features and machine learning algorithms employed in the literature to detect or classify ARS have been reported [6], including spectral features [25], mel-frequency cepstral coefficients (MFCCs) [26], entropy [27], wavelet coefficients [28], rule-based models [29], logistic regression models [30], support vector machines (SVM) [31], and artificial neural networks [32]. More recently, deep learning strategies have also been introduced, where the feature extraction and classification steps are merged into the learning algorithm [33,34,35].
Over the years, several authors have reported excellent results on ARS classification (Table 1). However, one crucial problem of this field has been its reliance on small or private data collections. Moreover, public repositories that have been commonly used in the literature (e.g., R.A.L.E. [36]) were designed for teaching, typically including a small number of ARS, and usually not containing environmental noise. Therefore, we chose to perform the evaluation on the Respiratory Sound Dataset (RSD), the largest publicly available respiratory sound database, which is described in Section 3.1.

Table 1.
Summary of selected works.
3. Materials and Methods
3.1. Database
The ICBHI 2017 Respiratory Sound Database (RSD) is a publicly available database with 920 audio files containing a total of 5.5 h of recordings acquired from 126 participants of all ages [44]. The database (Table 2) contains audio samples collected independently by two research teams in two different countries. It is a challenging database, since the recordings contain several types of noises, background sounds, and different sampling frequencies; 1898 wheezes and 8877 crackles, which are found in 637 audio files, are annotated. The training set contains 1173 wheezes and 5996 crackles distributed among 203 and 311 files, respectively. The test set includes 725 wheezes and 2881 crackles distributed among 138 and 190 files, respectively. Moreover, patient-based splitting was performed following the split suggested by the RSD authors [45].
Table 2.
Demographic information of the database.
3.2. Random Event Generation
We created a custom script to randomly generate events with fixed durations of 50 ms and 150 ms. This procedure was followed to reproduce “Experiment 2” [44], an experiment where ARS events were classified against other events. By employing this process we were able to establish a fair comparison with other methods that were tested on the same database. To simultaneously guarantee variation and reproducibility, the seed for the random number generator changed for each file but was predetermined. The number of randomly generated events (RGE) of each duration is displayed in Table 3, along with the number of annotated events.
Table 3.
Number of randomly generated events (RGE) with fixed durations in the training and test sets.
An alternative approach to generate the random events was then employed to study the impacts of event duration on the performance of the classifiers. For this approach, we started by visually inspecting the distribution of the annotated crackles’ and wheezes’ durations and found that a Burr distribution [46] provided a good fit for both distributions. The Burr distribution used to generate the events with durations shorter than 100 ms (otherCrackle) had probability density function
with , , and . Durations longer than 100 ms were discarded. The Burr distribution used to generate the events with durations longer than 100 ms (otherWheeze) had probability density function:
with , , and . Durations longer than 2 s were discarded. The number of events with durations belonging to each distribution is displayed in Table 4, and the number of annotated events. Figure 1 displays both histograms with the according durations for each class and the Burr distributions used to generate the new random events.
Table 4.
Number of RGE with variable durations in the training and test sets.
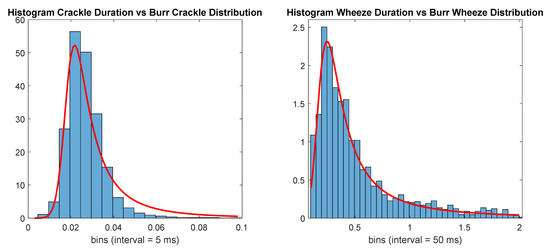
Figure 1.
Histogram of adventitious respiratory sounds (ARS) events’ durations versus Burr distributions (red line).
3.3. Preprocessing
The audio files in RSD were recorded with different sampling rates. Therefore, we resampled every recording at 4000 Hz, the lowest sampling rate in the database. As the signal of interest was below 2000 Hz, this was considered a good resolution for Fourier analysis.
3.4. Time Frequency Representations
To generate the time frequency (TF) images of the audio events, three different representations were used: spectrogram, mel spectrogram, and scalogram. All images obtained with the different methods were normalized between 0 and 1. Moreover, TF representations were computed using MATLAB 2020a. We present only the descriptions and results for the two best performing TF representations, which were the spectrogram and the mel spectrogram.
The spectrogram obtained using the short-time Fourier transform (STFT) is one of the most used tools in audio analysis and processing, since it describes the evolution of the frequency components over time. The STFT representation (F) of a given discrete signal is given by [35]:
where is a window function centered at instant n.
The mel scale [47] is a perceptual scale of equally spaced pitches, aiming to match the human perception of sound. The conversion from Hz into mels is performed using Equation (4):
The mel spectogram displays the spectrum of a sound on the mel scale. Figure 2 presents an example of both TF representations.
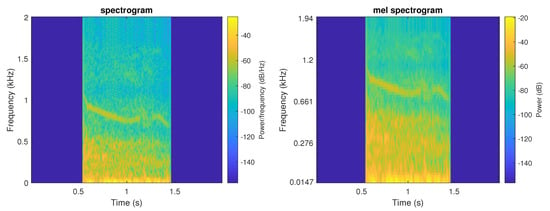
Figure 2.
Example of both TF representations of a wheeze event (left—spectrogram, right—mel spectrogram).
Since the database events have a wide range of durations, a maximum time for each event was defined according to Equation (5):
with x corresponding to the durations of annotated wheeze events. Thus, the maximum length per event was established as 2 s, and smaller events were centered and zero-padded. The database also contained annotated events with more than 2 s (87 events). For these cases, only the first 2 s were considered, as we observed that the annotation of these longer events was less precise.
The TF representations were obtained with three windowing methods and three different window lengths: Hamming, Blackman–Harris, and rectangular windows with the respective sizes of 32, 64 ms and 128 ms. We decided to only report the results for the best performing windowing method and window length, the Blackman–Harris window with a size of 32 ms. Moreover, 512 points with 75% overlap were employed to compute the STFT and obtain both TF representations. For the mel spectrogram, 64 mel bandpass filters were employed. The resulting spectrogram and mel spectrogram images were 1 × 247 × 257 and 1 × 247 × 64.
3.5. Feature Extraction
To study how frame lengths influence spectrogram computation, a multiscale approach was followed for feature extraction. We computed spectrograms with three windowing methods and six window lengths: Hamming, Blackman–Harris, and rectangular windows with window lengths of 16, 32, 64, 128, 256, and 512 ms with 75% overlap. Then, 81 features were extracted from each frame of the spectrogram: 25 spectral features, 26 MFCC features, and 30 melodic features. Sensitivity analysis on the most realistic task, the 3 Class task with variable durations, revealed that the Hamming window produced slightly better results. Therefore, all the results obtained with the traditional approach of feature extraction, feature selection, and classification, were computed using the Hamming window. Most features were extracted using the MIR Toolbox 1.7.2 [48]. Table 5 provides a small description of all the employed features. For each event, five statistics of each feature were calculated: mean, standard deviation, median, minimum value, and maximum value. Therefore, the total number of features fed to the classifiers was 2430.
Table 5.
Small description of each feature.
3.5.1. Spectral Features
We estimated several features from the spectrograms. To begin with, the first four standardized moments of the spectral distributions were computed: centroid, spread, skewness, and kurtosis. Then, we extracted other features that are commonly employed for characterizing the timbre of a sound, such as zero-crossing rate, entropy, flatness, roughness, and irregularity. The spectral flux (SF), which measures the Euclidean distance between the magnitude spectrum of successive frames, gave origin to three other features: SF inc, where only positive differences between frames were summed; SF halfwave, a halfwave rectification of the SF; SF median, where a median filter was used to remove spurious peaks. Finally, the amount of high-frequency energy was estimated in two ways: brightness, the high-frequency energy above a certain cut-off frequency; rolloff, which consists of finding the frequency below which a defined percentage of the total spectral energy is contained [48]. Brightness was computed at four frequencies: 100, 200, 400, and 800 Hz. Furthermore, we calculated the ratios between the brightnesses at 400 and 100 Hz, and between the brightnesses at 800 and 100 Hz. Rolloff was computed for the percentages of 95, 75, 25, and 5. Moreover, two novel features were computed: the outlier ratio between rolloffs at 5 and 95%; the interquartile ratio between rolloffs at 25 and 75%.
3.5.2. MFCC Features
The most common features used to describe the spectral shape of a sound are the MFCCs [49]. The MFCCs are calculated by converting the logarithm of the magnitude spectrum to the mel scale and computing the discrete cosine transform (DCT). As most of the signal information is concentrated in the first components, it is typical to extract the first 13 [48]. A first-order temporal differentiation of the MFCCs was also computed to understand the temporal evolution of the coefficients.
3.5.3. Melodic Features
Fundamental frequency, henceforth referred to as pitch, was the basis for computing the 30 melodic features. We computed the cepstral autocorrelation of each frame to estimate each event’s pitch curve. The maximum allowed pitch frequency was 1600 Hz, the highest fundamental frequency reported in the literature about wheezes [50]. The inharmonicity and the voicing curves were then computed based on the pitch curve. Next, we applied moving averages with durations 100, 250, 500, and 1000 ms to the time series to understand trends at different lengths and smooth the curves, giving origin to a total of 15 features. Finally, the same features were computed for a 400 Hz high-pass filtered version of the sound events. The rationale for this filter was the removal of the respiratory sounds, whose energy typically drops at 200 Hz [17], reaching insignificant levels at 400 Hz [50].
3.6. Feature Selection
After preliminary experiments, the minimum redundancy maximum relevance (MRMR) algorithm was chosen to perform feature selection. This algorithm provides ranks to the features that are mutually and maximally dissimilar and can represent the response variable effectively [51] The MRMR algorithm ranks features by calculating the mutual information quotient of the relevance and redundancy of each feature. For each experiment, three subsets of features were selected: the best 10 features selected by MRMR (10MRMR), the best 100 features selected by MRMR (100MRMR), and all 2430 features.
Table 6 and Table 7 list the 10 most relevant features as ranked by the MRMR algorithm on both fixed durations (FD) and variable durations (VD) sets. The first noteworthy fact is that, while features from every frame length were selected for all the tasks in the VD set, features extracted with the longest window size (512 ms) were not selected for any task in the FD set. Comparing the feature sets selected for the 3 Class tasks, while the best 2 features on the FD set were melodic features, the best 2 features and 3 of the best 10 features for the variable durations dataset were spectral. In both cases, 7 MFCC features were present in the 10 highest-ranked features. The novel brightness ratios turned out to be important features, as they were selected for every task in both sets. In the VD set, while no melodic features were selected for the 3 Class and 2 Class Crackles tasks, two of the smoothed inharmonicities we introduced were selected for the 2 Class Wheezes task.
Table 6.
Ten highest-ranked features (fixed durations).
Table 7.
Ten highest-ranked features (variable durations).
3.7. Classifiers
We used four machine learning algorithms to classify the events: linear discriminant analysis (LDA), SVM with radial basis function (SVMrbf), random undersampling boosted trees (RUSBoost), and convolutional neural networks (CNNs). All the classifiers were trained 10 times with different seeds, and their hyperparameters were optimized on a validation set containing 25% of the training set. The models with the best hyperparameters were then applied to the test set. Bayesian optimization [52] was used to optimize the following hyperparameters of each traditional machine learning algorithm: delta for LDA; box constraint and kernel scale for SVMrbf; learning rate, number of variables to sample, number of learning cycles, minimum leaf size, and maximum number of splits for RUSBoost.
Three different CNN models were considered with regard to deep learning approaches: a model with a dual input configuration, using the spectrogram and mel spectrogram as inputs, and two other models using each of the TF representations individually as input. The architecture of the dual input model and the parameter for each of the layers is represented in Figure 3. The architecture of the models with a single input is the same as the one represented in Figure 3, considering the respective branch before the concatenation and the remaining layer afterwards. To train all the deep learning models, a total of 30 epochs were used with a batch size of 16 and 0.001 learning rate (Adam optimization algorithm). The early stopping strategy [53] was used to avoid overfitting during the training phase, i.e., stopping the training process after 10 consecutive epochs with an increase in the validation loss (validated in 25% of the training set).
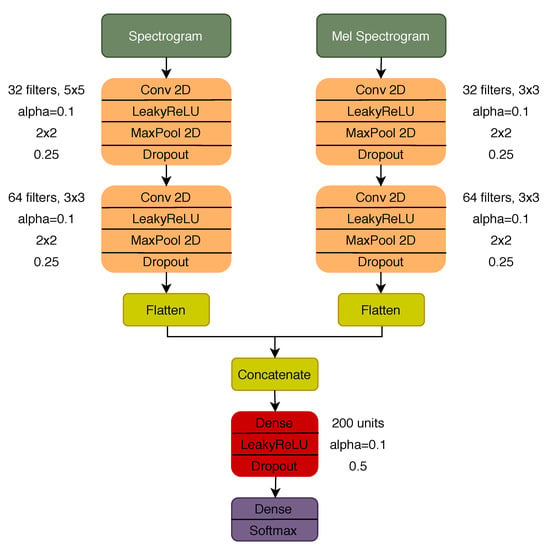
Figure 3.
Dual input CNN architecture.
3.8. Evaluation Metrics
We used the following measures to evaluate the performance of the algorithms:
where TP (True Positives) are events of the relevant class that are correctly classified; TN (True Negatives) are events of the other classes that are correctly classified; FP (False Positives) are events that are incorrectly classified as the relevant class; FN (False Negatives) are events of the relevant class that are incorrectly classified. The area under the ROC curve (AUC) was also computed for the binary cases. For multi-class classification, the evaluation metrics were computed in a one-vs-all fashion. Precision and sensitivity were not included in the tables of Section 4 to improve legibility.
4. Evaluation
In this section, we analyze the performance of the algorithms in three experiments that are detailed in the following subsections. Each experiment is composed of three tasks: one problem with three classes, i.e., crackles, wheezes, and others (3 Class); and two problems with two classes, i.e., crackles and others (2 Class Crackles), and wheezes and others (2 Class Wheezes). Each experiment is divided into three tasks in order to study how the performance of the algorithms are affected by having to classify each type of ARS against events of the same range of durations. By partitioning the RGE into two sets, we can determine whether the performance in the 3 Class problem is inflated.
4.1. Fixed Durations
Table 8 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 3 Class task with fixed durations. Results achieved by the best performing algorithm in "Experiment 2" of [44], SUK [41], are also shown as a baseline for comparison. Table 9 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 2 Class Crackles task with fixed durations. Table 10 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 2 Class Wheezes task with fixed durations.
Table 8.
Performance results obtained with 3 classes (crackle vs. wheeze vs. other)—training: fixed duration; testing: fixed duration.
Table 9.
Performance results obtained with 2 classes (crackle vs. other)—training: fixed duration; testing: fixed duration.
Table 10.
Performance results obtained with 2 classes (wheeze vs. other)—training: fixed duration; testing: fixed duration.
With an accuracy of 95.8%, SVMrbf_MFCC was the best traditional classifier in the 3 Class task, surpassing the baseline accuracy of 91.2%. Nevertheless, the CNNs achieved even better results, with several reaching 96.9% accuracy. Given such great results, we decided to investigate whether the performance would be the same for two-class tasks, i.e., wheezes vs. 150 ms RGE, and crackles vs. 50 ms RGE. Surprisingly, while the traditional classifiers’ performance did not improve, the CNNs achieved better results in both tasks, with CNN_dualInput reaching 99.6% accuracy and 99.6% AUC in the 2 Class Crackles task, and 98.6% accuracy and 98.4% AUC in the 2 Class Wheezes task.
4.2. Fixed and Variable Durations
After noticing the CNNs had achieved almost perfect performance on the fixed durations experiment, we suspected the algorithms might be implicitly learning the duration of each event instead of the underlying characteristics of each type of sound. To test this, we designed a new experiment with a different approach to random event generation, detailed in Section 3.2. In this experiment, the training set was the same as before—i.e., the RGE had fixed durations—but the test set’s RGE had variable durations. Table 11 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 3 Class task with variable durations. As a baseline, we computed SUK’s results on this test set with the same training model as before. Table 12 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 2 Class Crackles task with variable durations. Table 13 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 2 Class Wheezes task with variable durations.
Table 11.
Performance results obtained with 3 classes (crackle vs. wheeze vs. other)—training: fixed duration; testing: variable duration.
Table 12.
Performance results obtained with 2 classes (crackle vs. other)—training: fixed duration; testing: variable duration.
Table 13.
Performance results obtained with 2 classes (wheeze vs. other)—training: fixed duration; testing: variable duration.
Looking at the results of the 3 Class task, the decline in performance is quite salient, with the accuracy decreasing by more than 30% for the best classifiers. The bulk of this decline was due to the class other, as can be seen in the last three columns of Table 11. With this experiment, we were able to grasp that classifiers were implicitly learning the duration of the events, rather than relevant characteristics of the classes. The performance did not improve in the 2 Class tasks. In the 2 Class Crackles task, the highest AUC, reached by SVMrbf_100MRMR, was 68.4%, whereas the AUC attained by the CNNs was close to 50%, thereby not being better than random. In the 2 Class Wheezes task, the best AUC, reached by SVMrbf_Full, was 57.2%, also close to random.
4.3. Variable Durations
Finally, in this experiment we examined whether the algorithms’ performance improved when training with RGE with variable durations. This experiment arguably represents the more realistic setup to evaluate the performance of the classifiers, as we aimed to remove the bias introduced by the generation of random events with fixed sizes. Table 14 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 3 Class task with variable durations. Table 15 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 2 Class Crackles task with variable durations. Table 16 displays the results achieved by all the combinations of classifiers and feature sets on the test set of the 2 Class Wheezes task with variable durations.
Table 14.
Performance results obtained with 3 classes (crackle vs. wheeze vs. other)—training: variable duration; testing: variable duration.
Table 15.
Performance results obtained with 2 classes (crackle vs. other)—training: variable duration; testing: variable duration.
Table 16.
Performance results obtained with 2 classes (wheeze vs. other)—training: variable duration; testing: variable duration.
While the accuracy reached by the best traditional classifier RUSBoost_Full increased by 6.2% in the 3 Class task, the improvement in performance was especially appreciable in the CNNs, with CNN_dualInput reaching 81.8% accuracy an 20.3% increase in accuracy. Figure 4 displays confusion matrices for the best traditional and deep learning models. In the 2 Class Crackles task, CNN_dualInput achieved the best AUC, 84.9%, not much higher than the best AUC reached by a traditional classifier, SVMrbf_100MRMR, 80.1%. In the two-class wheezes task, traditional and deep learning classifiers attained similar results, 68.5% (SVMrbf_Full) and 72.7% (CNN_dualInput), respectively.
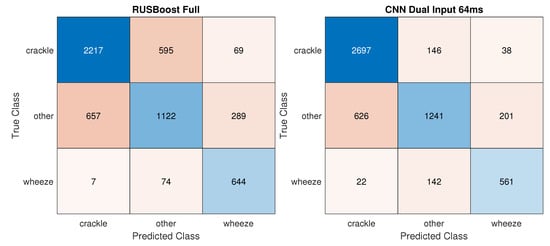
Figure 4.
Confusion matrices for the best traditional and deep learning models on the 3 Class task––training: variable duration; testing: variable duration.
5. Discussion
In this work, we proposed a set of experiments that can be used to evaluate ARS classification systems. We demonstrated how random event generation can have a significant impact on the automatic classification of ARS through the evaluation of several classifiers on those experiments. As the performance of the algorithms presented in Section 4 shows, methods that seem to achieve promising results can fail if we change the way the other class is designed. This can happen even if the dataset where the systems are evaluated does not change. The substantial variance in performance between experiments might indicate that the generation of the random events with fixed durations introduces a considerable bias. Classifiers might be implicitly learning to identify the durations of the events. It is important to consider how data are used to train, validate, and test a trained model. Such a model should encode some essential structure of the underlying problem [54]. When a highly specified artificial system appears to give credence to the allegation that it is addressing a complex human task, the default position should be that the system relies upon characteristics confounded with the ground truth and is not actually addressing the problem it appears to be solving [18]. Our findings corroborate the need to test models on realistic and application-specific tasks [54].
Nevertheless, it is important to reiterate that the performance of the evaluated systems may have been influenced by the limitations of this dataset. As previously pointed out [44], these include the shortage of healthy adult participants and the unavailability of gold standard annotations, (i.e., annotations from multiple annotators). A future update of the database should also check for possible errors.
Automatic classification of ARS is a complex task that is not yet solved, despite the claims made in the literature. It may be particularly hard when algorithms are evaluated on challenging datasets, such as the RSD. Though significant work has been developed to classify ARS, none has been widely accepted [55]. While CNNs have become state-of-the-art solutions in several tasks [34], they were not enough to tackle this problem. Therefore, accelerating the development of machine learning algorithms is critical to the future of respiratory sounds analysis. Future work on ARS classification should focus on improving three crucial steps of the methodology: (i) TF representations; (ii) deep learning architectures; and (iii) evaluation. Other TF representations have been proposed for ARS classification, such as the wavelet transform [28], the S-transform [43], and the scalogram [56], but better denoising methods would allow us to extract more meaningful features. Hybrid deep learning architectures that combine convolutional layers with recurrent layers that learn the temporal context have been shown to perform well in other sound event classification tasks [57] and could be successfully applied in ARS classification. Finally, ARS classification systems should be evaluated on realistic datasets containing several noise sources.
Author Contributions
Conceptualization, B.M.R., D.P., and R.P.P.; data curation, B.M.R., D.P., and A.M.; formal analysis, B.M.R. and D.P.; funding acquisition, P.C. and R.P.P.; methodology, B.M.R. and D.P.; supervision, A.M., P.C., and R.P.P.; writing—original draft, B.M.R. and D.P.; writing—review and editing, B.M.R., D.P., A.M., P.C., and R.P.P. All authors reviewed and edited the manuscripts. All authors have read and agreed to the published version of the manuscript.
Funding
This research is partially supported by Fundação para a Ciência e Tecnologia (FCT) Ph.D. scholarship SFRH/BD/135686/2018 and by the Horizon 2020 Framework Programme of the European Union under grant agreement number 825572 (project WELMO) for the authors with affiliation 1. This research is partially supported by Fundo Europeu de Desenvolvimento Regional (FEDER) through Programa Operacional Competitividade e Internacionalização (COMPETE) and FCT under the project UID/BIM/04501/2013 and POCI-01-0145-FEDER-007628—iBiMED for the author with affiliations 2 and 3.
Data Availability Statement
The data used in this study are available in a publicly accessible repository: https://bhichallenge.med.auth.gr/ICBHI_2017_Challenge.
Conflicts of Interest
The authors declare no conflict of interest.
References
- The Top 10 Causes of Death. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 10 December 2020).
- Gibson, G.J.; Loddenkemper, R.; Lundbäck, B.; Sibille, Y. Respiratory health and disease in Europe: The new European Lung White Book. Eur. Respir. J. 2013, 42, 559–563. [Google Scholar] [CrossRef] [PubMed]
- Marques, A.; Oliveira, A.; Jácome, C. Computerized adventitious respiratory sounds as outcome measures for respiratory therapy: A systematic review. Respir. Care 2014, 59, 765–776. [Google Scholar] [CrossRef] [PubMed]
- Fleming, S.; Pluddemann, A.; Wolstenholme, J.; Price, C.; Heneghan, C.; Thompson, M. Diagnostic Technology: Automated lung sound analysis for asthma. Technology Report 2011.
- Jácome, C.; Marques, A. Computerized Respiratory Sounds in Patients with COPD: A Systematic Review. COPD J. Chronic Obstr. Pulm. Dis. 2015, 12, 104–112. [Google Scholar] [CrossRef] [PubMed]
- Pramono, R.X.A.; Bowyer, S.; Rodriguez-Villegas, E. Automatic adventitious respiratory sound analysis: A systematic review. PLoS ONE 2017, 12, e0177926. [Google Scholar] [CrossRef] [PubMed]
- Gurung, A.; Scrafford, C.G.; Tielsch, J.M.; Levine, O.S.; Checkley, W. Computerized lung sound analysis as diagnostic aid for the detection of abnormal lung sounds: A systematic review and meta-analysis. Respir. Med. 2011, 23, 1396–1403. [Google Scholar] [CrossRef] [PubMed]
- Reichert, S.; Gass, R.; Brandt, C.; Andrès, E. Analysis of Respiratory Sounds: State of the Art. Clin. Med. Circ. Respir. Pulm. Med. 2008, 2, CCRPM.S530. [Google Scholar] [CrossRef]
- Marinella, M.A. COVID-19 pandemic and the stethoscope: Do not forget to sanitize. Heart Lung J. Cardiopulm. Acute Care 2020, 49, 350. [Google Scholar] [CrossRef] [PubMed]
- Sovijärvi, A.R.; Dalmasso, F.; Vanderschoot, J.; Malmberg, L.P.; Righini, G.; Stoneman, S.A. Definition of terms for applications of respiratory sounds. Eur. Respir. Rev. 2000, 10, 597–610. [Google Scholar]
- Oliveira, A.; Marques, A. Respiratory sounds in healthy people: A systematic review. Respir. Med. 2014, 108, 550–570. [Google Scholar] [CrossRef] [PubMed]
- Hadjileontiadis, L.J.; Moussavi, Z.M.K. Current Techniques for Breath Sound Analysis. In Breath Sounds; Springer International Publishing: Cham, Switzerland, 2018; Chapter 9; pp. 139–177. [Google Scholar] [CrossRef]
- Pasterkamp, H.; Brand, P.L.; Everard, M.; Garcia-Marcos, L.; Melbye, H.; Priftis, K.N. Towards the standardisation of lung sound nomenclature. Eur. Respir. J. 2016, 47, 724–732. Available online: https://erj.ersjournals.com/content/47/3/724.full.pdf (accessed on 10 December 2020). [CrossRef] [PubMed]
- Marques, A.; Oliveira, A. Normal Versus Adventitious Respiratory Sounds. In Breath Sounds; Springer International Publishing: Cham, Switzerland, 2018; Chapter 10; pp. 181–206. [Google Scholar] [CrossRef]
- Douros, K.; Grammeniatis, V.; Loukou, I. Crackles and Other Lung Sounds. In Breath Sounds; Springer International Publishing: Cham, Switzerland, 2018; Chapter 12; pp. 225–236. [Google Scholar] [CrossRef]
- Abbas, A.; Fahim, A. An automated computerized auscultation and diagnostic system for pulmonary diseases. J. Med. Syst. 2010, 34, 1149–1155. [Google Scholar] [CrossRef]
- Bohadana, A.; Izbicki, G.; Kraman, S.S. Fundamentals of Lung Auscultation. N. Engl. J. Med. 2014, 370, 744–751. [Google Scholar] [CrossRef]
- Sturm, B.L. A simple method to determine if a music information retrieval system is a ‘horse’. IEEE Trans. Multimed. 2014, 16, 1636–1644. [Google Scholar] [CrossRef]
- Rocha, B.M.; Pessoa, D.; Marques, A.; Carvalho, P.; Paiva, R.P. Influence of Event Duration on Automatic Wheeze Classification. arXiv 2020, arXiv:2011.02874. [Google Scholar]
- Urquhart, R.B.; McGhee, J.; Macleod, J.E.; Banham, S.W.; Moran, F. The diagnostic value of pulmonary sounds: A preliminary study by computer-aided analysis. Comput. Biol. Med. 1981, 11, 129–139. [Google Scholar] [CrossRef]
- Murphy, R.L.; Del Bono, E.A.; Davidson, F. Validation of an automatic crackle (Rale) counter. Am. Rev. Respir. Dis. 1989, 140, 1017–1020. [Google Scholar] [CrossRef] [PubMed]
- Sankur, B.; Kahya, Y.P.; Çaǧatay Güler, E.; Engin, T. Comparison of AR-based algorithms for respiratory sounds classification. Comput. Biol. Med. 1994, 24, 67–76. [Google Scholar] [CrossRef]
- Du, M.; Chan, F.H.; Lam, F.K.; Sun, J. Crackle detection and classification based on matched wavelet analysis. In Proceedings of the 19th Annual International Conference of the IEEE Engineering in Medicine and Biology Society. ’Magnificent Milestones and Emerging Opportunities in Medical Engineering’ (Cat. No.97CH36136), Chicago, IL, USA, 30 October–2 November 1997; Volume 4, pp. 1638–1641. [Google Scholar] [CrossRef]
- Palaniappan, R.; Sundaraj, K.; Ahamed, N.U. Machine learning in lung sound analysis: A systematic review. Integr. Med. Res. 2013, 33, 129–135. [Google Scholar] [CrossRef]
- Bokov, P.; Mahut, B.; Flaud, P.; Delclaux, C. Wheezing recognition algorithm using recordings of respiratory sounds at the mouth in a pediatric population. Comput. Biol. Med. 2016, 70, 40–50. [Google Scholar] [CrossRef]
- Nakamura, N.; Yamashita, M.; Matsunaga, S. Detection of patients considering observation frequency of continuous and discontinuous adventitious sounds in lung sounds. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Orlando, FL, USA, 16–20 August 2016; pp. 3457–3460. [Google Scholar] [CrossRef]
- Liu, X.; Ser, W.; Zhang, J.; Goh, D.Y.T. Detection of adventitious lung sounds using entropy features and a 2-D threshold setting. In Proceedings of the 2015 10th International Conference on Information, Communications and Signal Processing (ICICS), Singapore, 2–4 December 2015. [Google Scholar] [CrossRef]
- Ulukaya, S.; Serbes, G.; Kahya, Y.P. Overcomplete discrete wavelet transform based respiratory sound discrimination with feature and decision level fusion. Biomed. Signal Process. Control 2017, 38, 322–336. [Google Scholar] [CrossRef]
- Pinho, C.; Oliveira, A.; Jácome, C.; Rodrigues, J.; Marques, A. Automatic crackle detection algorithm based on fractal dimension and box filtering. Procedia Comput. Sci. 2015, 64, 705–712. [Google Scholar] [CrossRef]
- Mendes, L.; Vogiatzis, I.M.; Perantoni, E.; Kaimakamis, E.; Chouvarda, I.; Maglaveras, N.; Henriques, J.; Carvalho, P.; Paiva, R.P. Detection of crackle events using a multi-feature approach. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 3679–3683. [Google Scholar] [CrossRef]
- Lozano, M.; Fiz, J.A.; Jané, R. Automatic Differentiation of Normal and Continuous Adventitious Respiratory Sounds Using Ensemble Empirical Mode Decomposition and Instantaneous Frequency. IEEE J. Biomed. Health Inform. 2016, 20, 486–497. [Google Scholar] [CrossRef] [PubMed]
- Chamberlain, D.; Kodgule, R.; Ganelin, D.; Miglani, V.; Fletcher, R.R. Application of semi-supervised deep learning to lung sound analysis. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Orlando, FL, USA, 16–20 August 2016; pp. 804–807. [Google Scholar] [CrossRef]
- Aykanat, M.; Kılıç, Ö.; Kurt, B.; Saryal, S. Classification of lung sounds using convolutional neural networks. EURASIP J. Image Video Process. 2017, 2017, 65. [Google Scholar] [CrossRef]
- Bardou, D.; Zhang, K.; Ahmad, S.M. Lung sounds classification using convolutional neural networks. Artif. Intell. Med. 2018, 88, 58–69. [Google Scholar] [CrossRef] [PubMed]
- Demir, F.; Sengur, A.; Bajaj, V. Convolutional neural networks based efficient approach for classification of lung diseases. Health Inf. Sci. Syst. 2020, 8. [Google Scholar] [CrossRef] [PubMed]
- Owens, D. Rale Lung Sounds 3.0. CIN Comput. Inform. Nurs. 2002, 5, 9–10. [Google Scholar]
- Forkheim, K.E.; Scuse, D.; Pasterkamp, H. Comparison of neural network models for wheeze detection. In Proceedings of the IEEE WESCANEX 95. Communications, Power, and Computing, Winnipeg, MB, Canada, 15–16 May 1995; Volume 1, pp. 214–219. [Google Scholar] [CrossRef]
- Riella, R.; Nohama, P.; Maia, J. Method for automatic detection of wheezing in lung sounds. Braz. J. Med Biol. Res. 2009, 42, 674–684. [Google Scholar] [CrossRef]
- Mendes, L.; Vogiatzis, I.M.; Perantoni, E.; Kaimakamis, E.; Chouvarda, I.; Maglaveras, N.; Tsara, V.; Teixeira, C.; Carvalho, P.; Henriques, J.; et al. Detection of wheezes using their signature in the spectrogram space and musical features. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Milan, Italy, 25–29 August 2015; pp. 5581–5584. [Google Scholar] [CrossRef]
- Grønnesby, M.; Solis, J.C.A.; Holsbø, E.; Melbye, H.; Bongo, L.A. Feature extraction for machine learning based crackle detection in lung sounds from a health survey. arXiv 2017, arXiv:1706.00005. [Google Scholar]
- Serbes, G.; Ulukaya, S.; Kahya, Y.P. An Automated Lung Sound Preprocessing and Classification System Based On Spectral Analysis Methods. In Precision Medicine Powered by pHealth and Connected Health. ICBHI 2017. IFMBE Proceedings; Maglaveras, N., Chouvarda, I., de Carvalho, P., Eds.; Springer: Singapore, 2018; Volume 66, pp. 45–49. [Google Scholar]
- Jakovljević, N.; Lončar-Turukalo, T. Hidden Markov Model Based Respiratory Sound Classification. In Precision Medicine Powered by pHealth and Connected Health. ICBHI 2017. IFMBE Proceedings; Maglaveras, N., Chouvarda, I., de Carvalho, P., Eds.; Springer: Singapore, 2018; Volume 66, pp. 39–43. [Google Scholar]
- Chen, H.; Yuan, X.; Li, J.; Pei, Z.; Zheng, X. Automatic Multi-Level In-Exhale Segmentation and Enhanced Generalized S-Transform for wheezing detection. Comput. Methods Programs Biomed. 2019, 178, 163–173. [Google Scholar] [CrossRef]
- Rocha, B.M.; Filos, D.; Mendes, L.; Serbes, G.; Ulukaya, S.; Kahya, Y.P.; Jakovljevic, N.; Turukalo, T.L.; Vogiatzis, I.M.; Perantoni, E.; et al. An open access database for the evaluation of respiratory sound classification algorithms. Physiol. Meas. 2019, 40. [Google Scholar] [CrossRef] [PubMed]
- Rocha, B.M.; Filos, D.; Mendes, L.; Vogiatzis, I.; Perantoni, E.; Kaimakamis, E.; Natsiavas, P.; Oliveira, A.; Jácome, C.; Marques, A.; et al. A respiratory sound database for the development of automated classification. IFMBE Proc. 2018, 66, 33–37. [Google Scholar] [CrossRef]
- Burr, I.W. Cumulative Frequency Functions. Ann. Math. Stat. 1942, 13, 215–232. [Google Scholar] [CrossRef]
- Stevens, S.; Volkmann, J.; Newman, E.B. A Scale for the Measurement of the Psychological Magnitude Pitch. J. Acoust. Soc. Am. 1937, 8, 185–190. [Google Scholar] [CrossRef]
- Lartillot, O.; Toiviainen, P. Mir in matlab (II): A toolbox for musical feature extraction from audio. In Proceedings of the 8th International Conference on Music Information Retrieval (ISMIR 2007), Vienna, Austria, 23–27 September 2007; pp. 127–130. [Google Scholar]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Charbonneau, G.; Ademovic, E.; Cheetham, B.; Malmberg, L.; Vanderschoot, J.; Sovijärvi, A. Basic techniques for respiratory sound analysis. Eur. Respir. Rev. 2000, 10, 625–635. [Google Scholar]
- Ding, C.; Peng, H. Minimum redundancy feature selection from microarray gene expression data. J. Bioinform. Comput. Biol. 2005, 3, 185–205. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 2951–2959. [Google Scholar]
- Prechelt, L. Early Stopping-However, When? In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar] [CrossRef]
- D’Amour, A.; Heller, K.; Moldovan, D.; Adlam, B.; Alipanahi, B.; Beutel, A.; Chen, C.; Deaton, J.; Eisenstein, J.; Hoffman, M.D.; et al. Underspecification Presents Challenges for Credibility in Modern Machine Learning. arXiv 2020, arXiv:2011.03395. [Google Scholar]
- Marques, A.; Jácome, C. Future Prospects for Respiratory Sound Research. In Breath Sounds; Springer International Publishing: Cham, Switzerland, 2018; pp. 291–304. [Google Scholar] [CrossRef]
- Jayalakshmy, S.; Sudha, G.F. Scalogram based prediction model for respiratory disorders using optimized convolutional neural networks. Artif. Intell. Med. 2020, 103, 101809. [Google Scholar] [CrossRef]
- Adavanne, S.; Politis, A.; Nikunen, J.; Virtanen, T. Sound Event Localization and Detection of Overlapping Sources Using Convolutional Recurrent Neural Networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 34–48. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).