
Are UX Evaluation Methods Providing the Same Big Picture?

Abstract
:1. Introduction
- We report on a longitudinal analysis of the outcomes from three different UX evaluation methods and interviews with developers, providing empirical evidence on the impact of these outcomes in the development process.
- Based on our results, we outline implications for practitioners and researchers, and provide suggestions to improve the UX evaluation methods to get more comprehensive and consistent results.
2. Related Work
3. Methodology
3.1. UX Evaluation Methods
3.2. Participants and Material
3.3. Procedure
3.3.1. Longitudinal Study
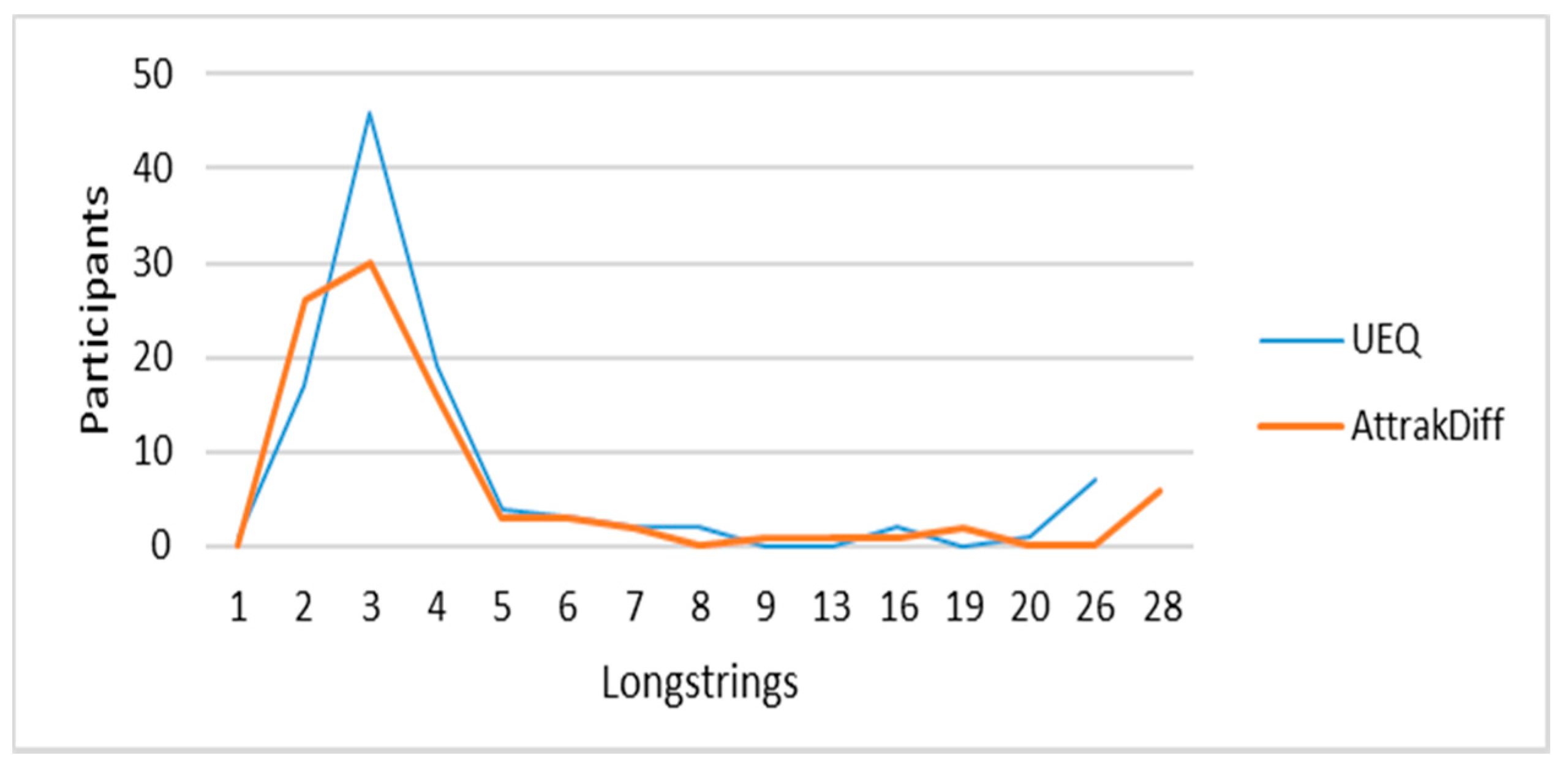
3.3.2. Identifying Careless Respondents
3.3.3. Interviews with the Stakeholders
4. Results
4.1. Reliability of the Instruments
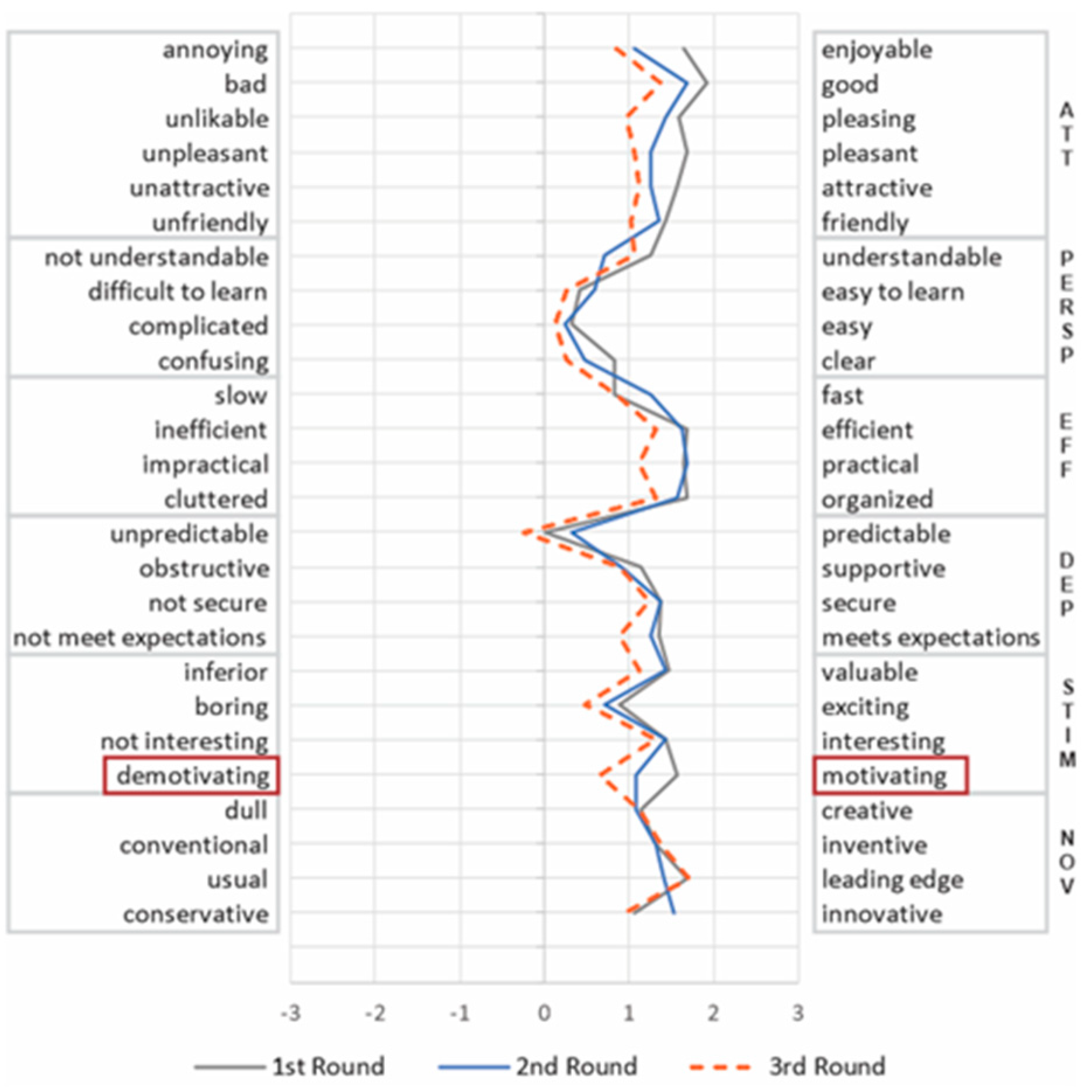
4.2. Within UX Dimensions over Time
4.3. Sentence Completion Results
4.3.1. UEQ Group
4.3.2. AttrakDiff Group
4.4. Interviews with the Stakeholders
5. Discussion
5.1. Contrasting Results
5.2. UX Dimensions
5.3. Reliability of the Instruments
5.4. Implications
5.4.1. Implications for Practitioners
5.4.2. Implications for Researchers
6. Threats to Validity
7. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bargas-Avila, J.A.; Hornbæk, K. Old wine in new bottles or novel challenges: A critical analysis of empirical studies of user experience. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, USA, 7–12 May 2011; pp. 2689–2698. [Google Scholar]
- Law, E.L.C.; Roto, V.; Hassenzahl, M.; Vermeeren, A.P.O.S.; Kort, J. Understanding, scoping and defining user experience: A survey approach. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 719–728. [Google Scholar]
- Cockburn, A.; Quinn, P.; Gutwin, C. The effects of interaction sequencing on user experience and preference. Int. J. Human Comput. Stud. 2017, 108, 89–104. [Google Scholar] [CrossRef] [Green Version]
- Pettersson, I.; Lachner, F.; Frison, A.K.; Riener, A.; Butz, A. A Bermuda triangle? A Review of method application and triangulation in user experience evaluation. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 21–26 April 2018; p. 461. [Google Scholar]
- Ardito, C.; Buono, P.; Caivano, D.; Costabile, M.F.; Lanzilotti, R. Investigating and promoting UX practice in industry: An experimental study. Int. J. Human Comput. Stud. 2014, 72, 542–551. [Google Scholar] [CrossRef]
- Rivero, L.; Conte, T. A systematic mapping study on research contributions on UX evaluation technologies. In Proceedings of the XVI Brazilian Symposium on Human Factors in Computing Systems—IHC 2017, Joinville, Brazil, 23–27 October 2017; pp. 1–10. [Google Scholar]
- Marques, L.C.; Nakamura, W.T.; Valentim, N.; Rivero, L.; Conte, T. Do scale type techniques identify problems that affect user experience? User experience evaluation of a mobile application (S). In Proceedings of the the 30th International Conference on Software Engineering and Knowledge Engineering, Redwood, CA, USA, 1–3 July 2018; pp. 451–501. [Google Scholar]
- Nakamura, W.T.; Marques, L.C.; Rivero, L.; De Oliveira, E.H.T.; Conte, T. Are scale-based techniques enough for learners to convey their UX when using a learning management system? Rev. Bras. Inf. Educ. 2019, 27, 104. [Google Scholar] [CrossRef]
- de Andrade Cardieri, G.; Zaina, L.M. Analyzing user experience in mobile web, native and progressive web applications: A User and HCI specialist perspectives. In Proceedings of the 17th Brazilian Symposium on Human Factors in Computing Systems-IHC 2018, Belém, Brazil, 22–26 October 2018; pp. 1–11. [Google Scholar]
- Borsci, S.; Federici, S.; Bacci, S.; Gnaldi, M.; Bartolucci, F. Assessing user satisfaction in the era of user experience: Comparison of the SUS, UMUX, and UMUX-LITE as a function of product experience. Int. J. Human Comput. Interact. 2015, 31, 484–495. [Google Scholar] [CrossRef]
- Bruun, A.; Ahm, S. Mind the gap! Comparing Retrospective and concurrent ratings of emotion in user experience evaluation. In Proceedings of the Human-Computer Interaction—INTERACT 2015; Abascal, J., Barbosa, S., Fetter, M., Gross, T., Palanque, P., Winckler, M., Eds.; Springer: Cham, Switzerland, 2015; pp. 237–254. [Google Scholar]
- Soleimani, S.; Law, E.L.C. What can self-reports and acoustic data analyses on emotions tell us? In Proceedings of the 2017 Conference on Designing Interactive Systems, Edinburg, UK, 10–14 June 2017; pp. 489–501. [Google Scholar]
- Lallemand, C.; Koenig, V. Lab testing beyond usability: Challenges and recommendations for assessing user experiences. J. Usability Stud. 2017, 12, 22. [Google Scholar]
- Hassenzahl, M.; Burmester, M.; Koller, F. AttrakDiff: Ein fragebogen zur messung wahrgenommener hedonischer und pragmatischer qualität. In Mensch & Computer 2003; Szwillus, G., Ziegler, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 187–196. [Google Scholar]
- Laugwitz, B.; Held, T.; Schrepp, M. Construction and evaluation of a user experience questionnaire. In HCI and Usability for Education and Work; Holzinger, A., Ed.; Springer: Berlin/Heidelberg, Gemany, 2008; pp. 63–76. ISBN 978-3540893493. [Google Scholar]
- van Schaik, P.; Ling, J. An integrated model of interaction experience for information retrieval in a web-based encyclopaedia. Interact. Comput. 2011, 23, 18–32. [Google Scholar] [CrossRef] [Green Version]
- Van der Heijden, H.; Sørensen, L.S. Measuring attitudes towards mobile information services: An empirical validation of the HED/UT Scale. In Proceedings of the ECIS, 2003, Naples, Italy, 16–21 June 2003; pp. 765–777. [Google Scholar]
- Karapanos, E. Modeling Users’ Experiences with Interactive Systems, 1st ed.; Springer: Berlin/Heidelberg, Gemany, 2013. [Google Scholar]
- Kujala, S.; Roto, V.; Väänänen-Vainio-Mattila, K.; Sinnelä, A. Identifying hedonic factors in long-term user experience. In Proceedings of the 2011 Conference on Designing Pleasurable Products and Interfaces—DPPI 2011, Milano, Italy, 22–25 June 2011; p. 1. [Google Scholar]
- Kim, H.K.; Han, S.H.; Park, J.; Park, W. How user experience changes over time: A case study of social network services: How user experience changes over time. Human Fact. Ergon. Manuf. Serv. Ind. 2015, 25, 659–673. [Google Scholar] [CrossRef]
- Harbich, S.; Hassenzahl, M. User experience in the work domain: A longitudinal field study. Interacti Comput. 2016. [Google Scholar] [CrossRef]
- Roto, V.; Vermeeren, A.; Väänänen-Vainio-Mattila, K.; Law, E. User experience evaluation—Which method to choose? In Human-Computer Interaction—INTERACT 2011; Campos, P., Graham, N., Jorge, J., Nunes, N., Palanque, P., Winckler, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 714–715. ISBN 978-3642237676. [Google Scholar]
- Vermeeren, A.P.O.S.; Law, E.L.C.; Roto, V.; Obrist, M.; Hoonhout, J.; Väänänen-Vainio-Mattila, K. User experience evaluation methods: Current state and development needs. In Proceedings of the 6th Nordic Conference on Human-Computer Interaction, Extending Boundaries, New York, NY, USA, 16–20 October 2010; pp. 521–530. [Google Scholar]
- Díaz-Oreiro, I.; López, G.; Quesada, L.; Guerrero, L.A. Standardized questionnaires for user experience evaluation: A Systematic literature review. Proceedings 2019, 31, 14. [Google Scholar] [CrossRef] [Green Version]
- Michalco, J.; Simonsen, J.G.; Hornbæk, K. An exploration of the relation between expectations and user experience. Int. J. Human Comput. Interact. 2015, 31, 603–617. [Google Scholar] [CrossRef]
- Somrak, A.; Pogačnik, M.; Guna, J. Suitability and comparison of questionnaires assessing virtual reality-induced symptoms and effects and user experience in virtual environments. Sensors 2021, 21, 1185. [Google Scholar] [CrossRef]
- Burger, G.; Guna, J.; Pogačnik, M. Suitability of inexpensive eye-tracking device for user experience evaluations. Sensors 2018, 18, 1822. [Google Scholar] [CrossRef] [Green Version]
- Schneidermeier, T.; Hertlein, F.; Wolff, C. Changing paradigm—Changing experience? Comparative usability evaluation of Windows 7 and Windows 8. In Design, User Experience, and Usability. Theories, Methods, and Tools for Designing the User Experience; Marcus, A., Ed.; Springer: Cham, Switzerland, 2014; pp. 371–382. ISBN 978-3319076676. [Google Scholar]
- Santoso, H.B.; Schrepp, M.; Isal, R.; Utomo, A.Y.; Priyogi, B. Measuring user experience of the student-centered e-learning environment. J. Educ. Online 2016, 13, 58–79. [Google Scholar]
- Gaeta, E.; Beltrán-Jaunsaras, M.E.; Cea, G.; Spieler, B.; Burton, A.; García-Betances, R.I.; Cabrera-Umpiérrez, M.F.; Brown, D.; Boulton, H.; Arredondo Waldmeyer, M.T. Evaluation of the create@school game-based learning–teaching approach. Sensors 2019, 19, 3251. [Google Scholar] [CrossRef] [Green Version]
- Mast, M.; Burmester, M.; Graf, B.; Weisshardt, F.; Arbeiter, G.; Španěl, M.; Materna, Z.; Smrž, P.; Kronreif, G. Design of the human-robot interaction for a semi-autonomous service robot to assist elderly people. In Ambient Assisted Living; Springer: Berlin/Heidelberg, Germany, 2015; pp. 15–29. [Google Scholar]
- Hassenzahl, M. The hedonic/pragmatic model of user experience. UX Manif. 2007, 10, 10–14. [Google Scholar]
- Kujala, S.; Walsh, T.; Nurkka, P.; Crisan, M. Sentence completion for understanding users and evaluating user experience. Interact. Comput. 2013, 26, 238–255. [Google Scholar] [CrossRef] [Green Version]
- Hassenzahl, M. The thing and I (summer of ’17 remix). In Funology 2: From Usability to Enjoyment; Blythe, M., Monk, A., Eds.; Springer: Cham, Switzerland, 2018; pp. 17–31. ISBN 978-3319682136. [Google Scholar]
- Soley, L.; Smith, A.L. Projective techniques for social science and business research. J. Consum. Mark. 2008, 26, 223. [Google Scholar]
- Maniaci, M.R.; Rogge, R.D. Caring about carelessness: Participant inattention and its effects on research. J. Res. Pers. 2014, 48, 61–83. [Google Scholar] [CrossRef]
- Curran, P.G. Methods for the detection of carelessly invalid responses in survey data. J. Exp. Soc. Psychol. 2016, 66, 4–19. [Google Scholar] [CrossRef] [Green Version]
- DeSimone, J.A.; Harms, P.D.; DeSimone, A.J. Best practice recommendations for data screening: Data screening. J. Organ. Behav. 2015, 36, 171–181. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.L.; Curran, P.G.; Keeney, J.; Poposki, E.M.; DeShon, R.P. Detecting and deterring insufficient effort responding to surveys. J. Bus. Psychol. 2012, 27, 99–114. [Google Scholar] [CrossRef]
- Taber, K.S. The use of cronbach’s α when developing and reporting research instruments in science education. Res. Sci. Educ. 2018, 48, 1273–1296. [Google Scholar] [CrossRef]
- Iacobucci, D.; Duhachek, A. Advancing α: Measuring reliability with confidence. J. Consum. Psychol. 2003, 13, 478–487. [Google Scholar] [CrossRef]
- Sheldon, M.R.; Fillyaw, M.J.; Thompson, W.D. The use and interpretation of the friedman test in the analysis of ordinal-scale data in repeated measures designs. Physiother. Res. Int. 1996, 1, 221–228. [Google Scholar] [CrossRef]
- Hsieh, H.F.; Shannon, S.E. Three approaches to qualitative content analysis. Qual. Health Res. 2005, 15, 1277–1288. [Google Scholar] [CrossRef]
- Schrepp, M.; Hinderks, A.; Thomaschewski, J. Design and evaluation of a short version of the user experience questionnaire (UEQ-S). Int. J. Interact. Multimed. Artif. Intell. 2017, 4, 103. [Google Scholar] [CrossRef] [Green Version]
- Zauberman, G.; Diehl, K.; Ariely, D. Hedonic versus informational evaluations: Task dependent preferences for sequences of outcomes. J. Behav. Decis. Making 2006, 19, 191–211. [Google Scholar] [CrossRef]
- Hassenzahl, M. The thing and I: Understanding the relationship between user and product. In Funology 2; Blythe, M., Monk, A., Eds.; Springer: Cham, Switzerland, 2018; pp. 301–313. ISBN 978-3319682136. [Google Scholar]
- Darin, T.; Coelho, B.; Borges, B. Which Instrument should I use? Supporting decision-making about the evaluation of user experience. In Design, User Experience, and Usability. Practice and Case Studies; Marcus, A., Wang, W., Eds.; Springer: Cham, Awitzerland, 2019; pp. 49–67. ISBN 978-3030235345. [Google Scholar]
- Nakamura, W.T.; de Oliveira, E.H.T.; Conte, T. Negative emotions, positive experience: What are we doing wrong when evaluating the UX? In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems—CHI EA ’19; ACM Press: Glasgow, Scotland, UK, 2019; pp. 1–6. [Google Scholar]
- Law, E.L.C.; van Schaik, P.; Roto, V. Attitudes towards user experience (UX) measurement. Int. J. Human Comput. Stud. 2014, 72, 526–541. [Google Scholar] [CrossRef] [Green Version]
- Almeida, R.L.; Andrade, R.M.; Darin, T.G.; Paiva, J.O. CHASE: Checklist to assess user experience in IoT environments. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: New Ideas and Emerging Results, Seoul, Korea, 6–11 July 2020; pp. 41–44. [Google Scholar]
- Lallemand, C.; Gronier, G.; Koenig, V. User experience: A concept without consensus? Exploring practitioners’ Perspectives through an international survey. Comput. Human Behav. 2015, 43, 35–48. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UEQ | AttrakDiff |
|---|---|
| Attractiveness | Attractiveness |
| Perspicuity, Efficiency, Dependability | Pragmatic Quality |
| Stimulation, Novelty | Hedonic Quality Stimulation |
| Hedonic Quality Identity |
| UEQ Group | |||||
| Mathematics | Mechanical Engineering | Materials Engineering | Physics | Total | |
| Initial | 24 | 29 | 25 | 26 | 104 |
| Longitudinal | 14 | 17 | 20 | 7 | 58 |
| Careless | 6 | 7 | 9 | 2 | 24 |
| Analyzed | 8 | 10 | 11 | 5 | 34 |
| AttrakDiff Group | |||||
| Mathematics | Mechanical Engineering | Materials Engineering | Physics | Total | |
| Initial | 23 | 20 | 20 | 28 | 91 |
| Longitudinal | 14 | 11 | 19 | 12 | 56 |
| Careless | 6 | 3 | 5 | 8 | 22 |
| Analyzed | 8 | 8 | 14 | 4 | 34 |
| ATT | PERSP | EFF | DEP | STIM | NOV | |
|---|---|---|---|---|---|---|
| 1st | 0.899 | 0.830 | 0.795 | 0.464 | 0.877 | 0.737 |
| 2nd | 0.923 | 0.843 | 0.864 | 0.743 | 0.792 | 0.742 |
| 3rd | 0.847 | 0.873 | 0.824 | 0.653 | 0.810 | 0.663 |
| Avg. | 0.890 | 0.849 | 0.828 | 0.620 | 0.826 | 0.714 |
| ATT | PQ | HQS | HQI | |
|---|---|---|---|---|
| 1st | 0.777 | 0.506 | 0.629 | 0.716 |
| 2nd | 0.934 | 0.653 | 0.753 | 0.785 |
| 3rd | 0.949 | 0.771 | 0.796 | 0.874 |
| Avg. | 0.887 | 0.643 | 0.726 | 0.792 |
| UEQ | AttrakDiff | ||
|---|---|---|---|
| Adjective Pairs | Emotional Reaction | Adjective Pairs | Emotional Reaction |
| annoying/enjoyable | Pleasant | unpleasant/pleasant | Pleasant |
| bad/good | Good | ugly/attractive | Attractive |
| unlikable/pleasing | Pleasant | disagreeable/likeable | Pleasant |
| unpleasant/pleasant | Pleasant | rejecting/inviting | Inviting |
| unattractive/attractive | Attractive | bad/good | Good |
| unfriendly/friendly | Pleasant | repelling/appealing | Attractive |
| discouraging/motivating | Motivating | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nakamura, W.T.; Ahmed, I.; Redmiles, D.; Oliveira, E.; Fernandes, D.; de Oliveira, E.H.T.; Conte, T. Are UX Evaluation Methods Providing the Same Big Picture? Sensors 2021, 21, 3480. https://doi.org/10.3390/s21103480
Nakamura WT, Ahmed I, Redmiles D, Oliveira E, Fernandes D, de Oliveira EHT, Conte T. Are UX Evaluation Methods Providing the Same Big Picture? Sensors. 2021; 21(10):3480. https://doi.org/10.3390/s21103480
Chicago/Turabian StyleNakamura, Walter Takashi, Iftekhar Ahmed, David Redmiles, Edson Oliveira, David Fernandes, Elaine H. T. de Oliveira, and Tayana Conte. 2021. "Are UX Evaluation Methods Providing the Same Big Picture?" Sensors 21, no. 10: 3480. https://doi.org/10.3390/s21103480