1. Introduction
Gliomas are the most common brain tumours that are believed to derive from neuroglial stem cells. On the basis of their histological features, they have been classified as astrocytic, oligodendroglial, or ependymal tumours, and have been assigned World Health Organization (WHO) grades I to IV, which represent the malignant degrees [
1]. Huge progress in genetic profiling in brain tumor has recently led to changes in classification and treatment [
2]. Therefore, the new (2016) WHO classification of tumors of the central nervous system ends the era of traditional diagnostic approaches that are based on histologic criteria only and incorporates molecular biomarkers [
3]. Over 75% of the diffuse gliomas in adults are astrocytic. Oligodendroglial tumors account for less than 10% of the diffuse gliomas [
4].
The classification of glioma subtype is a key diagnostic process, because the available treatment options, including conventional chemotherapy and targeted therapies, differ between Astrocytoma, Glioblastoma, and oligodendroglioma (ODG) patients. As for gliomas, prominent examples include the Isocitrate Dehydrogenase 1 (IDH1) mutation in diffuse gliomas [
5,
6], O6-methylguanine–DNA methyltransferase (MGMT) promoter methylation status in Glioblastomas [
7] and 1p/19q codeletion in ODGs [
8,
9]. Especially, the 1p 19q codeletion is the genetic hallmark of ODGs with IDH1/IDH2 mutation [
10,
11]. The codeletion of chromosomal arms 1p 19q is a characteristic and early genetic event in ODGs, and patients with 1p 19q codeleted tumors showed a better prognosis, increased survival, and enhanced response to chemotherapy. Information on the 1p 19q status is a useful diagnostic assessment in morphologically challenging cases to substantiate the diagnosis of an ODG [
12].
Histologic typing and the grading of diffuse gliomas is challenging task for pathologists, because tumor cell diversity of gliomas make it difficult to discriminate in precise microscopic criteria. This tendency resulted in a high rate of interobserver variation in the diagnosis of diffuse glioma, including oligodendroglioma (ODG) [
13]. AI-based automated solution is a must-have system for the accurate diagnosis of diffuse glioma for pathologists. Pathology has a long history of artificial intelligence (AI) as much as any other field of medicine. For example, digital pathology is a system that digitizes glass slides into binary files, and then analyzes pathology information with AI algorithms. For the analysis of pathology images, an AI algorithm, such as deep convolutional neural network, has been used for the detection of tumor cells, classification of tumor subtype, and diagnosis of disease [
14,
15].
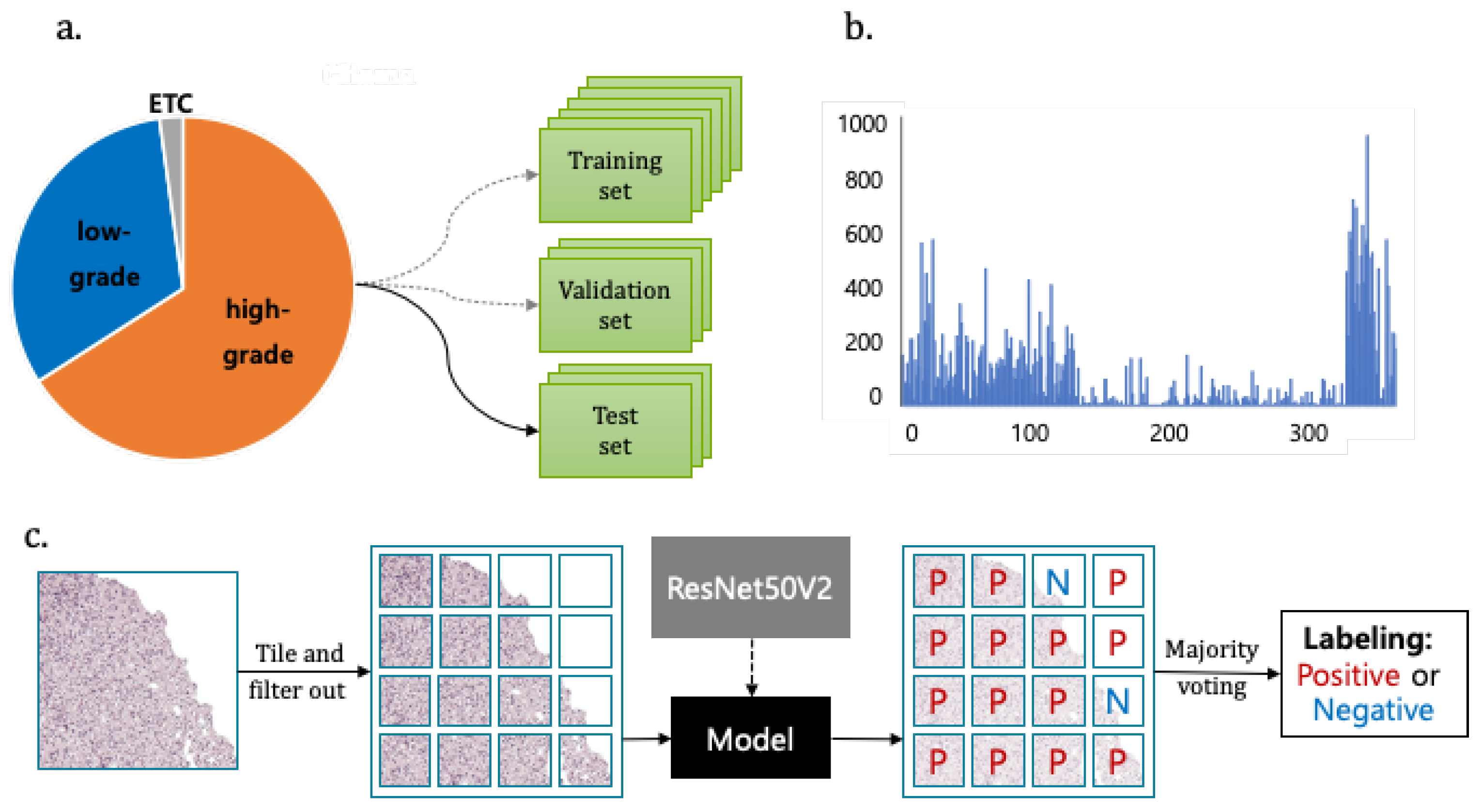
The deep learning based convolutional neural network (CNN) model has recently shown high performance in the field of image classification and object detection. To achieve high performance, a large amount of training dataset is required for training CNN-based deep learning model. However, it is difficult to collect a large amount of datasets in the clinical domain, and they usually have an imbalanced data problem between the disease-positive and disease-negative groups. To solve this problem, we used the transfer learning method for classifying gliomas subtypes and the grading of diffuse gliomas. As far as we know, this is the first study for deep learning aided classification of diffuse gliomas using real world digital pathology images that are generated from routine clinical practice, specifically in the cases according to the updated 2016 WHO classification for diffuse glioma.
4. Discussion
Recent advances in genetics in brain tumors have provided profound insights into the biology of gliomas, associating specific genetic aberrations with histopathological classification. Such changes provide critical information regarding the outcomes of the ODG patient treated with radiotherapy and adjuvant chemotheapy when compared to non-1p/19q codeleted glioma [
32]. However, in the view point of testing and diagnosis, it is challenging to change the classification to include diagnostic categories that depend on genetype [
33]. These challenges include the surrogate genotyping that may need to be taken by institutions without genotyping capabilities and the integrated diagnosis formats [
33]. Thus, we aimed to show the possibility of automated classification in diffuse glioma, which may affect this complex format of diagnosis and molecular test platform, as well as facilitate routine initial diagnosis. Furthermore, the main hypothesis that is addressed in this work is that clinical-grade performance can be reached using ROI images without annotating WSIs. Furthermore, turnaround times for confirmatory molecular study are required up to a few weeks and they may result in a delay in diagnosis. The processing time of a slide using our model only takes a few seconds to calculate per classification probability on two NVIDIA Tesla V100 GPUs. When considering the possibility of using multiple GPUs to process patches in parallel, classification using our model can be executed in a few minutes.
The implications of these results are wide ranging. The possibility of the dataset without annotation allows our algorithm to learn from the full files of slides that are presented to clinicians from real-world clinical practice, representing the full wealth of biological and technical variablitiy [
34]. To the best of our knowledge, only robust studies were conducted with the deep learning approach using the publicly available digital WSI dataset in The Cancer Genome Atlas (TCGA) or The Cancer Imaging Archive (TCIA) to automate the classification of grade II, III glioma versus grade IV glioblastoma, which demonstrated up to 96% accuracy [
35,
36,
37] However, the datasets used in the above studies are composed of many cases diagnosed before the application of the WHO’s new 2016 classification; therefore, the algorithm that was developed using the public database might not be suitable for the current WHO classification system. A recent study tried deep learning approaches for subtype classification according to the 2016 WHO classification and survival prediction using multimodal magnetic resonance images of a brain tumor [
38]. Their experimental data were obtained from the Multimodal Brain Tumor Segmentation Challenge 2019. However, they did not address the dataset’s information regarding molecular work to fulfill the requirement of the 2016 WHO classification and they did not include pathology images in their analysis. In order to generate predictive model using deep learning technique, sample size is important for classification performance and sample size. We included the dataset of diffuse glioma diagnosed after 2017 and all of the included cases were diagnosed according to the integrative molecular guideline of 2016 WHO classification. Interestingly, recent advanced biochemical spectroscopy enabled machine learning to discriminate between glioma and normal tissue by observing spectra shift within fresh tissue biopsies [
39]. Such algorithms lay a potential scenario in performing biomolecular diagnosis at frozen diagnosis during surgery. The task of classifying the type and grade of glioma uses pre-defined image features, characterizing the image and predicting the classification level, which is not unlike other types of machine learning problem where the substantial disadvantage of pre-defined features is the need to know those that are most informative in the classification task. Often, the best features are hard to know, and a method of unsupervised feature learning can be advantageous if datasets were abundant [
35].
The results of our evaluation of accuracy for ODG classification on real world data (87%) is promising, but it leaves room for improvement. There are several potential reasons for this performance. First, the orgin dataset of data set are HE slides and they vary in terms of coming from multiple institutions. tissue processing protocol, staining, and image acquisition were not uniform, which can bias the performance estimates of predictive models [
40]. Second, the dataset of this cohort is imbalanced and each training set is small. Transfer learning is novel deep learning method that transfers pre-trained models from large datasets to new domains of interest with small datasets achieving good performance [
41,
42].
The accuracy for grading of diffuse glioma dataset (0.68%) is a reasonably preliminary result. The reason might be related to the difficulties in the interpretation of histologic criteria used to classify and grade the diffuse gliomas [
43]. The main change in the 2016 WHO classification for diffuse glioma is providing powerful prognostic information from molecular parameters. The histologic grading system for diffuse glioma in current WHO scheme is three-tiered. Grade II is defined as tumors with cytological atypia alone. Grade III is considered to be tumors showing anaplasia and mitotic activity. Grade IV tumors show microvascular proliferation and/or necrosis. A variation in nuclear shape and size with accompanying hyperchromasia is defined as atypia. Unequivocal mitoses but not significant in their number or morphology are required. The finding of solitary mitosis is not sufficient for grade III, in such case, additional MIB1 proliferation index can be useful for the grading. Microvascular proliferation is defined as the multilayering of endothelium or glomeruloid vasculature. Any type of necrosis may enough for grade IV; palisading, simple apposition of cellular zone with intervening palor [
44]. Thus, the crucial diagnostic component of WHO grading scheme is not always diffuse, but rather focal microscopic finding, and important information for tumor grading cannot be evenly included in patches made from the original pathology image. We expect that larger sample will improve the accuracy of our module.
For the application of deep learning algorithms in pathology image analysis, CNN based models are widely used for classification [
45,
46] and analysis, including the detection of tumor [
47] and metastasis [
48]. CNN can have a series of convolutional and pooling hidden layers [
49]. This structure enables the extraction of representative features for prediction. Because the number of parameters is determined by the size of reception field, CNN layers have fewer parameters than the image size, which greatly improves its computational performance [
50]. In the case of the CNN-based models pre-trained on ImageNet, which consists of about 10 million images that are usually used for a base model of transfer learning, the final feature vector produced by a neural network through serial convolutions often encodes redundant information, given the flexibility of the algorithm to choose any feature necessary to produce accurate classification. CNN have also been implemented for image segmentation [
15]. Image segmentation is important in performing for large data sets, such as WSI. The image is divided into many small patches. CNN are trained to classify these patches. All of the patches are combined into a segmented area. A fine spatial resolution of segmentation is achieved by small size patches. However, in the patholohy image processing, the patch size should be reasonably large enough to be classified accurately. Thus, a review of the representative patches by a pathologist and the determination of proper patch size is recommended [
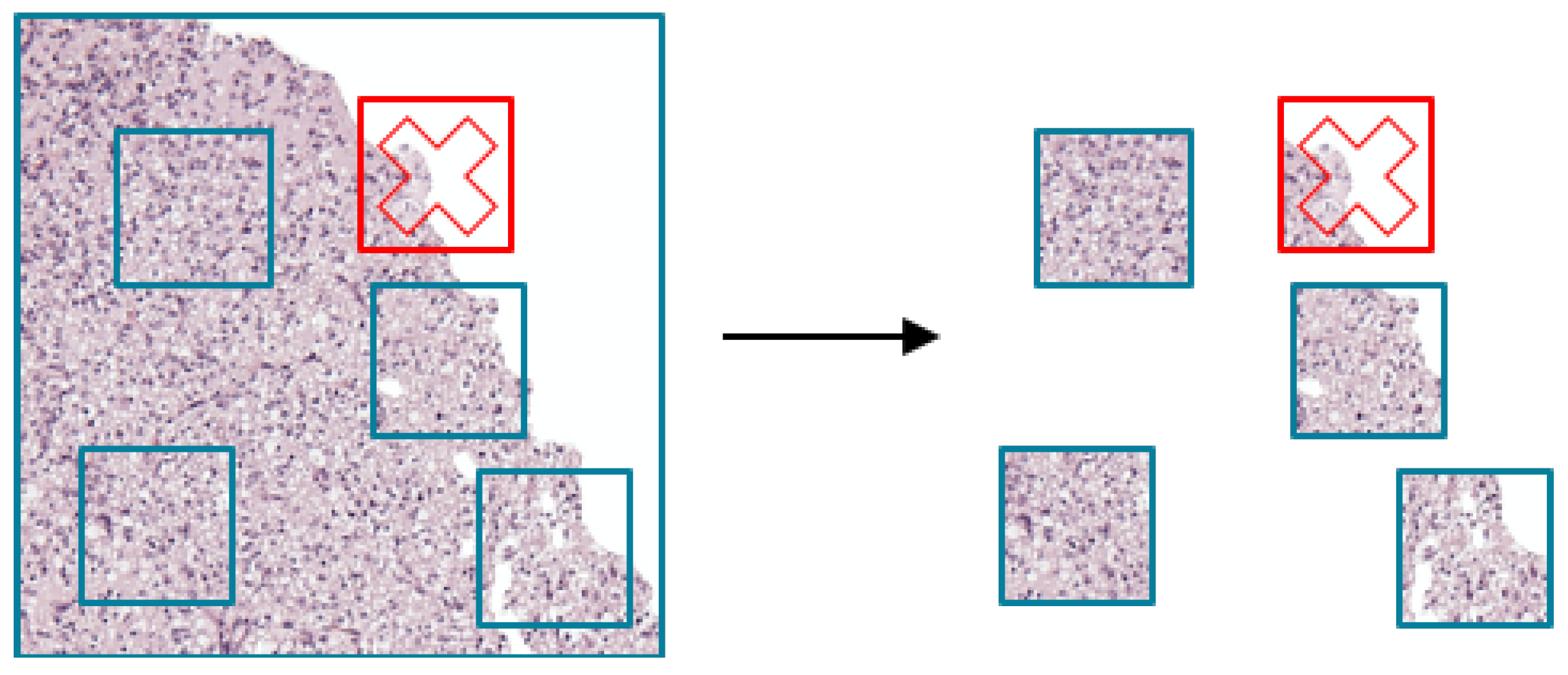
51]. In our study, the proper patch size was determined after a review of representative patch by pathologist. However, this demands a huge computational time and memory, which imits the computational speed. There is always an issue of the tradeoff between resolution of segmentation and patch size. We divide the 224 × 224 pixels sized patches from the original size image of 1024 × 1024 pixels to adjust the image size for ResNet50V2 model and show the best performance in our model.
The flexible adjustment of the deep learning process should be performed according to data size and trait, including data preparation, image processing, model selection and construction, post-processing, and feature extraction, as well as the association with the disease [
15]. Class imbalance is a common problem that has been comprehensively studied in classical machine learning. The clinical dataset is inevitably unbalanced because the natural incidence of tumor types dependent on the prevalence of the tumor. Oversampling images to adjust the ratio of each images should especially be performed in the small dataset [
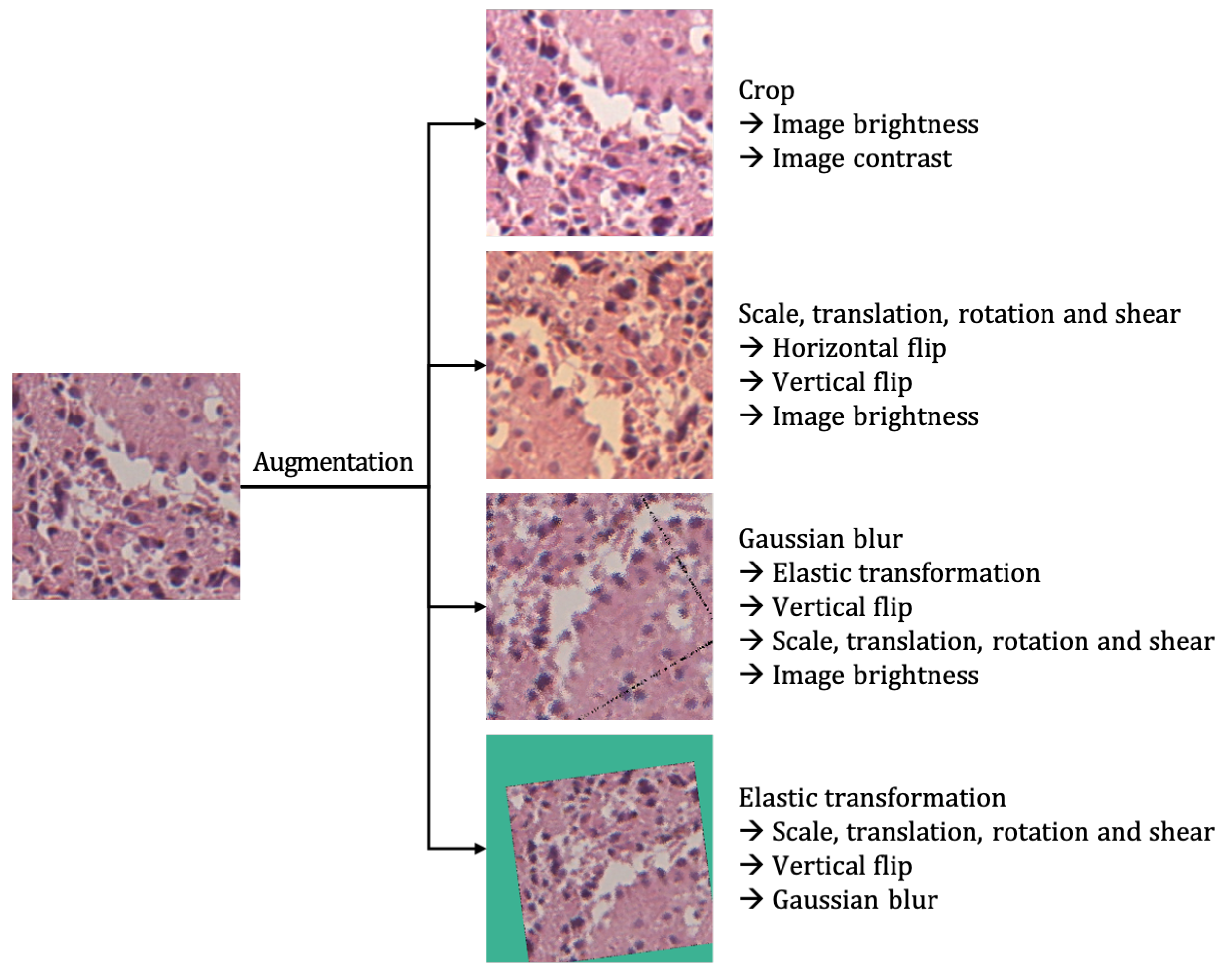
52]. Because pathology images may look very different due to different hematoxylin and eosin staining condition and the thickness of original slide, it is important to make a deep learning algorithm that is adapted to different digital images. Image standardization is needed and color augmentation is the easiest solution among the reported methods [
53]. Model selection is important and the corresponding loss function should be done. We performed training loss from four transfer learning models and four early-stopped validation losses for each model. Our study was performed as an annotation-free WSI training approach for pathological classification of the brain tumor subtype. Deep learning for digital pathology uses the extremely high spatial resolution of WSIs. The image patch usually used in learning needs detailed annotation. However, it is difficult for pathologists to cover all possible samples during annotation due to the highly variable tissue histology. Weak supervision methods have been applied in recent studies to avoid the work burden of annotation and selection bias. Training the tumor classifier without annotations in detail reduces the burden on the expert pathologist and allows for the deep learning model to benefit from abundant readily available WSIs [
54].
Our algorithm lets us meet the minimum requirement of the accuracy level that is determined by the context of complex molecular and histologic determination within a multi-class classification scheme. Moreover, as far as we know, our work is the first to get closer to actual practice by exploring how deep transfer learning methods can be used to classify brain tumor according to the new integrated diagnosis of the 2016 WHO classification. There are many factors of deep transfer learning optimization that we have not yet explored. We will also work on improving our accuracy by extra-steps during the pre-processing stage.
The era of big data has produced vast amounts of information that can be used to build deep learning models. However, in many cases, adding more data only marginally increases the model performance. This is especially important for limited labeled data, as the process annotation can be expensive and time consuming. The evaluation of learning curve approximation for large imbalanced biomedical datasets in the context of sample size planning can provide guidance for future machine learning problems that require expensive human labeling of instances. [
55]. On the basis of a systematic study on the sample size prediction for classification [
56], learning curves can be represented using inverse power law functions. By utilizing this, a classifier’s accuracy
can be expressed as a function of the number of training examples:
where
a is the minimum achievable error,
r is the learning rate, and
d is the decay rate.
Becaue we aimed for an accuracy of
and used the learning rate of
and the decay rate of
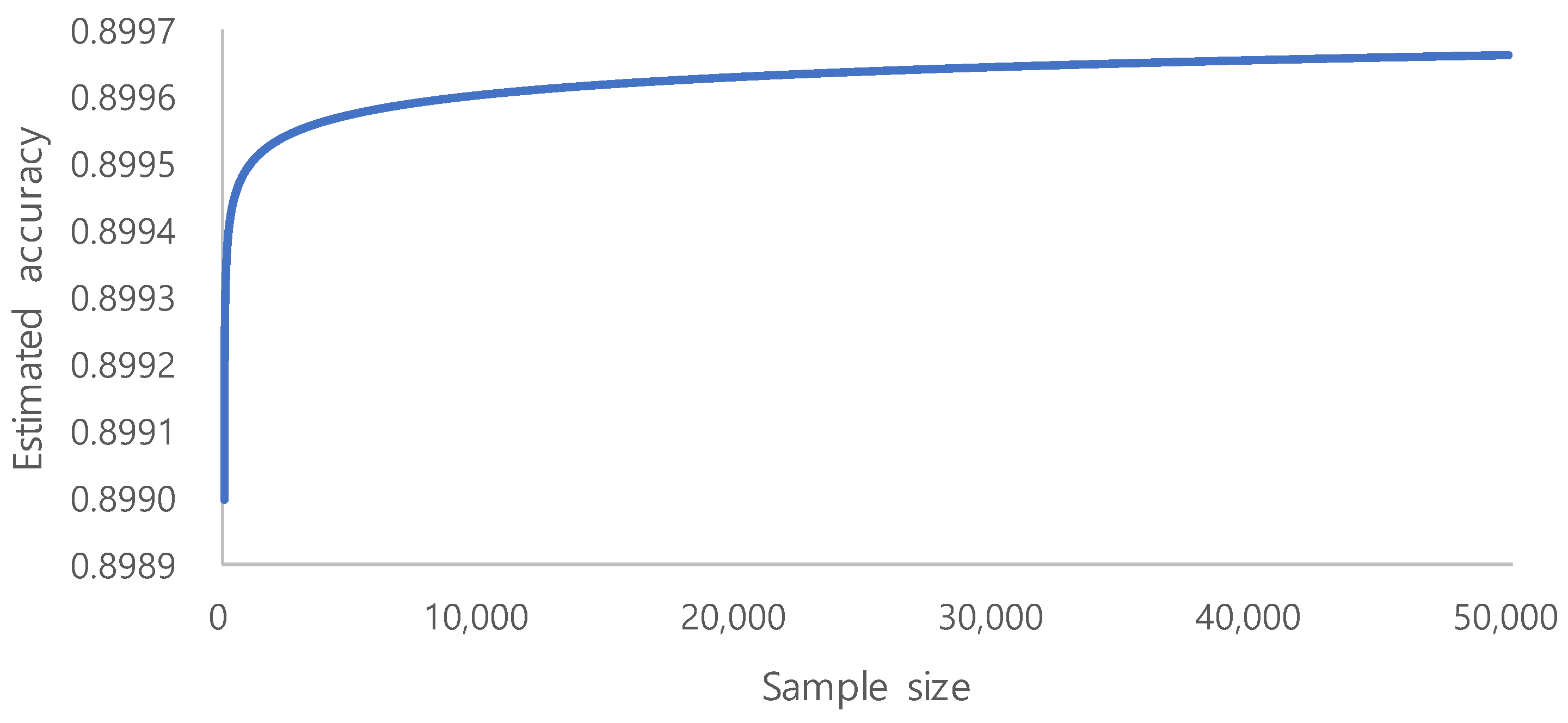
, we could identify the trend of the accuracy, as shown in
Figure 5. From the above accuracy trend, we estimate 10,000 to be the minimum required sample size, because the increase of accuracy is very small after 10,000. Sample number determination is important for model performance, especially in the context of limited labeled data [
55]. However, our ROI image selection and quality control of WSI during routine clinical practice generate a high quality dataset that showed fair performance. Clinically performed quality control could be an alternative to vigorous annotation.




 and
and 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}