1. Introduction
Structures suffer from varying levels of damage during their lifespan due to aging, external forces, and environmental changes. The implementation of damage detection for structures, known as structural health monitoring (SHM), is key for both preventing unexpected failures and optimizing the maintenance of existing structures [
1,
2,
3]. As a result, SHM is indispensable for the sustainability of structures and therefore attracts extensive attention in both the industry and academia. The goals of SHM can be classified into four categories [
4]: (1) to determine whether the structure is in a healthy state, (2) to identify the location of damage, (3) to quantify the level of damage, and (4) to estimate the remaining service life of the structure.
One common approach to SHM is the vibration-based method, where the response to an excitation is analyzed [
4,
5,
6,
7,
8,
9] The underlying assumption is that the change in the level of damage can be observed as a change in the structure’s responses, such as natural frequencies and damping ratios. It follows that the primary task for vibration-based approaches is to quantify the difference between responses. This type of SHM is performed with the aid of various sensors, such as accelerometers, displacement transducers, and strain gauges, to measure the time-history response of the structure in question.
Vibration-based methods can be further separated into two categories: model-based and feature-based methods. Model-based methods correlate the state of the structure with a predetermined model for structural health diagnosis [
10]. Some common models are the autoregressive and moving average (ARMA) model [
11,
12] and the Hidden Markov Model (HMM). Feature-based methods are generally performed in two steps: feature extraction and feature comparison [
10]. Among these methods, modal analysis is the most common method for extracting features, such as the use of natural frequency, modal shape, and modal damping [
13,
14,
15,
16]. All these methods are based on a comparison of the global properties of the collected data. However, it has been reported that SHM based on modal analysis is insensitive to minor local damage in practice [
17]. A review on the modal analysis approach can be found in [
18,
19].
Another property used by feature-based approaches is the attractor of the system. The advantage of attractor-based methods (categorized as feature-based methods) is in their independence from a predetermined model, since the attractor itself is the model [
20]. Various metrics are used in these methods, including prediction error [
21], local attractor variance [
22], and continuity [
23]. Each metric requires iteration over the data points in the attractor. According to Nichols [
24], the number of points required to accurately describe (i.e., populate) an attractor is proportional to a power of the number of degrees-of-freedom (DOF). Not only does this imply the necessity of extensive observation, but it also implies that these methods are efficient only for a small number of DOFs. Consequently, these methods implement dimension reduction before construction of the attractor, which inevitably reduces the amount of information available. In addition to the issue of dimension reduction, these methods are proposed under the assumption that the system is deterministic—only then do attractors exist. To obtain a deterministic system, specific excitations must be prescribed. However, this is not generally applicable.
The extensibility of attractor-related vibration-based methods to stochastic systems with pullback attractors was investigated by Overbey et al. [
25], where it was found that vibration-based methods are applicable to stochastic excitation, including band-limited white noise. Since the main concern in using ambient excitation as input is the signal being neither ergodic nor stationary, this finding raises the possibility of its usage. This signal is inexpensive and has the additional benefit of being available at any time. Despite the ease of application, caution is needed when employing ambient signals. As ambient excitation varies as a function of environmental properties such as temperature and humidity, the suitable technique also changes depending on the properties of the entire system [
26].
Ever-increasing computational power has allowed the current mainstream machine learning techniques, in particular deep neural networks (DNNs). The major advantages of machine learning-based techniques focus on two steps: (1) feature extraction and (2) feature discrimination in the SHM process [
27]. In recent years, both one- and two-dimensional convolutional neural networks (CNNs) have shown superiority over conventional methods in accuracy and efficiency, largely due to the combination of feature extraction and feature discrimination steps into a single learning block [
28].
Extending the concept of comparing attractors, a useful feature of DNNs is their large number of nodes, making DNNs readily available for the large number of points required to accommodate an attractor with high dimensions. Taking into consideration the recent success and ease of implementation of CNNs, we ask the following questions: Is there a reasonable method for converting a high-dimensional attractor into a matrix, such that no information is lost? Furthermore, can a CNN be readily used to distinguish between healthy and non-healthy structures?
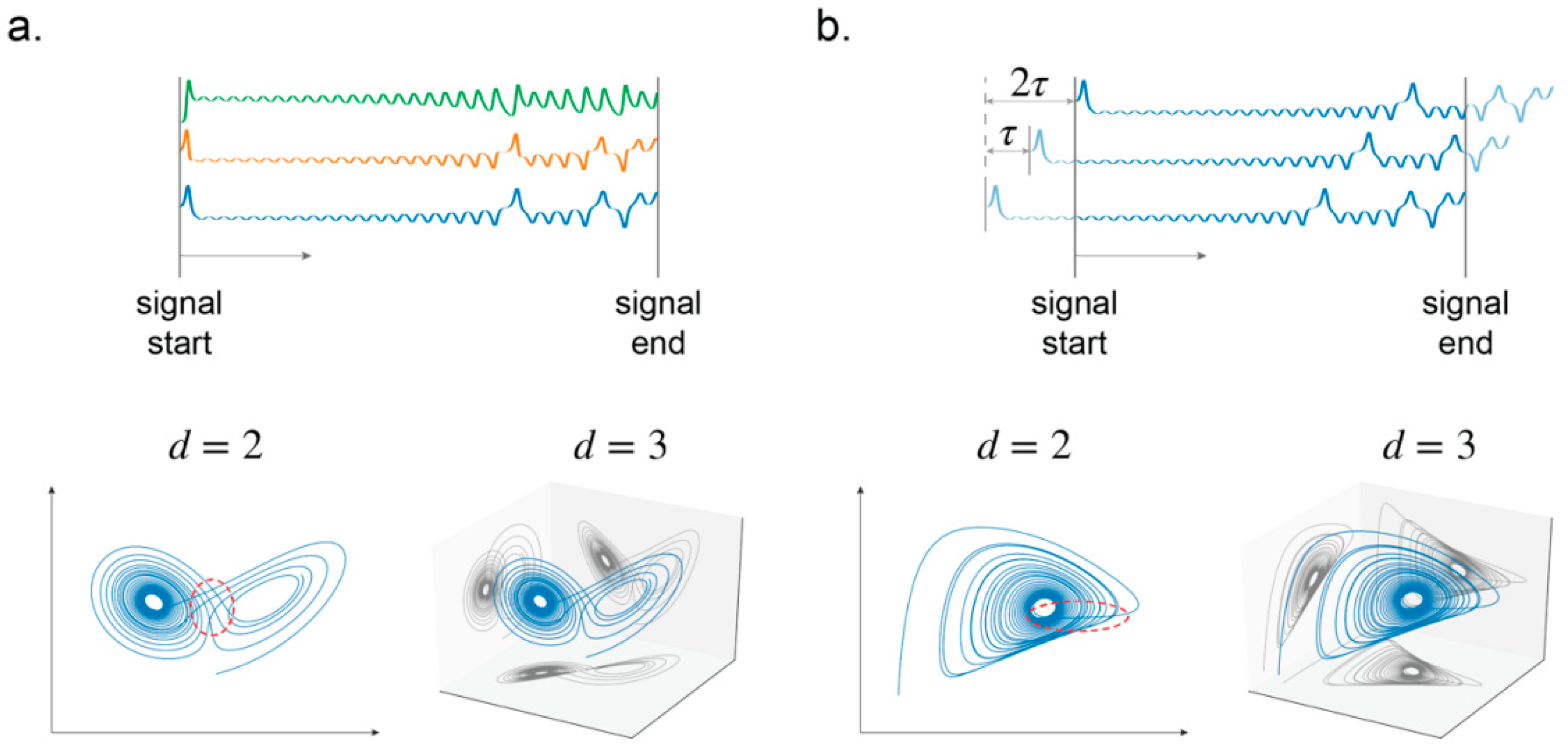
To tackle these questions, Takens’ embedding theorem [
29] is utilized to recover a high-dimensional attractor representative of the system from data collected by a single sensor in the structure. The method converts this attractor into a matrix/image. The converted product is then fed into a CNN for the diagnosis of the health of the structure (
Figure 1). Our results demonstrate that reconstructed attractors of different damage cases can be discriminated by the CNN model. The proposed combinatorial numerical framework therefore provides a novel and reliable method for SHM and furthers the progress toward future SHM schemes that lack prescribed damage data.
2. Materials and Methods
The proposed SHM method is based on two ingredients: A high-dimensional attractor from a single sensor is first reconstructed on the basis of Takens’ embedding theorem. Then the reconstructed attractor is converted into two-dimensional images and is identified by the CNN to obtain the features of attractors. Details of each step are discussed in this section. Moreover, to test the proposed computational framework, a three-story shear frame with varying damage magnitude and location was constructed to generate the time-history responses.
2.1. Attractor Reconstruction
In SHM, a structure can be seen as a function that takes the excitation (either ambient or prescribed) as input and outputs a response that can be picked up by sensors, typically in the form of displacement or acceleration. This dynamic system can be completely described by its phase space representation of m dimensions, where m is the number of DOFs of the system. For deterministic systems, its trajectory in the phase space asymptotically approaches a certain system-dependent manifold: the attractor. However, obtaining the trajectory in the phase space requires m sensors, one for each DOF. This is improbable in most cases and thus some alternative method for obtaining the attractor of the system is necessary. The goal of such a method is to construct an attractor in an alternative space (different from that constructed from m independent sensors), such that the new attractor is completely unfolded (i.e., no overlapping points exist on the attractor).
The time delay method is the most common approach for attractor reconstruction. At the core of this method is Takens’ embedding theorem, which states that the time-history response collected from just one sensor is sufficient for the reconstruction. Interested readers are referred to the original study [
29], as well as an alternative proof [
30].
To reconstruct the attractor using a single sensor (observation function), the dimension of the space must be expanded. The necessity of such an expansion in dimension is illustrated in
Figure 2. Time delay vectors
are created for this purpose, given by
where
denotes the observation at time
,
is the delay time, and
is the embedding dimension. Here, both
and
are yet to be chosen. A trajectory approximating the attractor is constructed by plotting the sequence
in the d-dimensional space, also known as the reconstruction space. Here,
is the time of the first observation in the whole sequence,
is the sample interval of each vector, chosen to be sufficiently small so as to preserve the local pattern of the trajectory, and
determines the length of the reconstructed trajectory, which has to be sufficiently large for the geometry of the attractor to be observable. Both the sample interval
and the trajectory length
are chosen by taking the characteristic time of the system into consideration. Hence, an understanding of the governing physics is necessary.
In practice,
is usually taken as a multiple of
, such that most observations between Equations (1) and (2) are shared to reduce the number of observations required. It must also take into consideration the sample rate of the sensor, since no sensor records in continuous time. The ideal choice of
is one that maximizes the information gained from the time delay vector. Practical choices for
are the first minimum of the average mutual information (AMI) function or the first zero of autocorrelation. An illustration of the reconstruction is given in
Figure 2b.
Unlike the delay time that has an optimal value, there is only a lower bound for the embedding dimension . The goal is to choose a sufficiently large , such that the attractor is completely unfolded in the reconstruction space. In Whitney’s embedding theorem, 2+1 dimensions suffice, where m is the number of DOFs of the system. However, since the actual number of DOFs of the system is unknown in practice, has to be chosen experimentally, for instance, by making use of the false nearest neighbor (FNN) method. The concept of FNN is straightforward: true neighbors on an attractor remain close even if the attractor is reconstructed in a higher dimension, and those that become separated in a higher dimension only seem close due to projection onto a lower dimension. Using this concept, this method constructs the attractor in spaces of increasing dimension, and the iteration terminates when all nearest neighbors remain close after the dimension increment. The final dimension thus gives the minimum value for unfolding the attractor and is taken as the embedding dimension .
2.2. Attractor Matrix for SHM
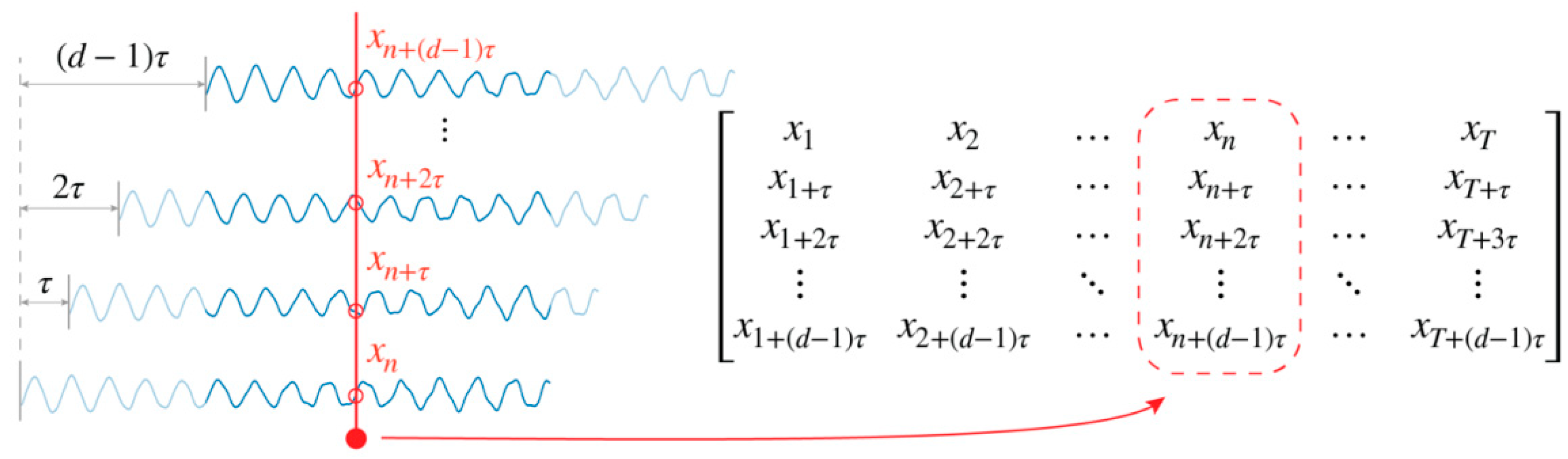
With the above theory, a method is proposed for converting the time-history response into a matrix. The goal is to preserve the information on attractors; , , and have to be determined beforehand. Differing from the methods given above, the value of both and can be chosen without significant consideration of computational expense since the matrix is to be processed with machine learning techniques. That is, values for and can be chosen such that the practitioner is confident in their magnitude. With these values determined, the matrix is constructed as follows.
Given a system, first define an observation function that returns a value
when called at time
. Collect the sequence consisting of
time delay vectors as in Equation (2) by the observation function. Taking each time delay vector in the sequence as single-column vectors, a matrix in the
space is formed:
where the notation follows
Section 2.1. This matrix is referred to here as the “attractor matrix”. The scheme of the conversion is illustrated in
Figure 3.
To further present the matrix as an image, the values in the matrix are shifted and scaled to 0–255. Each element of the matrix then represents a pixel in a grayscale image. For a set with multiple attractor matrices, the information on relative amplitude will be lost if the shifting and scaling is done independently on each individual matrix. When this is not the desired effect, the shifting and scaling should be done with respect to the entire dataset. Instead of finding the maximum and minimum values with respect to each matrix for shifting and scaling, these two values should be found with respect to the entire dataset, with scaling and shifting done globally as well. This preserves the information on relative magnitude.
2.3. Numerical Model
The phase space reconstruction outlined in
Section 2.1 is designed for deterministic systems with a deterministic attractor. However, as validated experimentally by Overbey et al. [
25], the method can be applied without issue to certain stochastic systems, including structures with band-limited white noise as excitation.
Given that the goal of this work is to establish a method for converting reconstructed attractors into matrices/images without losing details on the level of damage, the purpose of this demonstration is to show that the information regarding the health of the structure is preserved and is readily extractible with CNN. It also aims to show that information regarding the location of damage is included in the matrix. To this end, the conversion–CNN workflow is applied to a simulated system. A simple structure is simulated with varying damage magnitude and location, and the acceleration response to white noise excitation is converted to images using the proposed conversion. These images are then used to train a CNN model under the image classification scheme. This property is considered as properly embedded and readily extractible in the image/matrix if the CNN model is capable of accurately classifying the different damage cases.
2.3.1. Simulation Setup
Figure 4 illustrates the simulated three-story shear frame structure and its healthy state in both the reconstruction space and the image space. Rigid floor diaphragms were considered and the masses were assumed concentrated on the diaphragms. As a result, each floor has only horizontal movement, or one DOF. The mass, stiffness, and height of each story are listed in
Table 1 [
31].
A Gaussian white noise signal with a length of ninety seconds was used for the ground motion excitation of the structure. The peak ground acceleration (PGA) in each ground motion event was scaled to 0.25 m/s
2. A series of dynamic time-history analyses were carried out using the Newmark-
linear acceleration method [
32] implemented in MATLAB. The time increment was set to five milliseconds in the dynamic analysis. The system output was collected on the third floor.
In this study, varying levels of structural damage were simulated through the stiffness reduction factor
, which denotes the remaining stiffness of a certain story. For example, an
of 0.9 on the first floor indicates a reduction of stiffness by 10% on the first floor. A value of 0.9 was used for slightly damaged structures, 0.8 for moderately damaged structures, and 0.7 for a severely damaged structure. Only one story was considered as damaged (
) in each simulation run while the other stories had an
value of 1.0. The damage combinations form the ten classes shown in
Table 2. The case names are also given in the table.
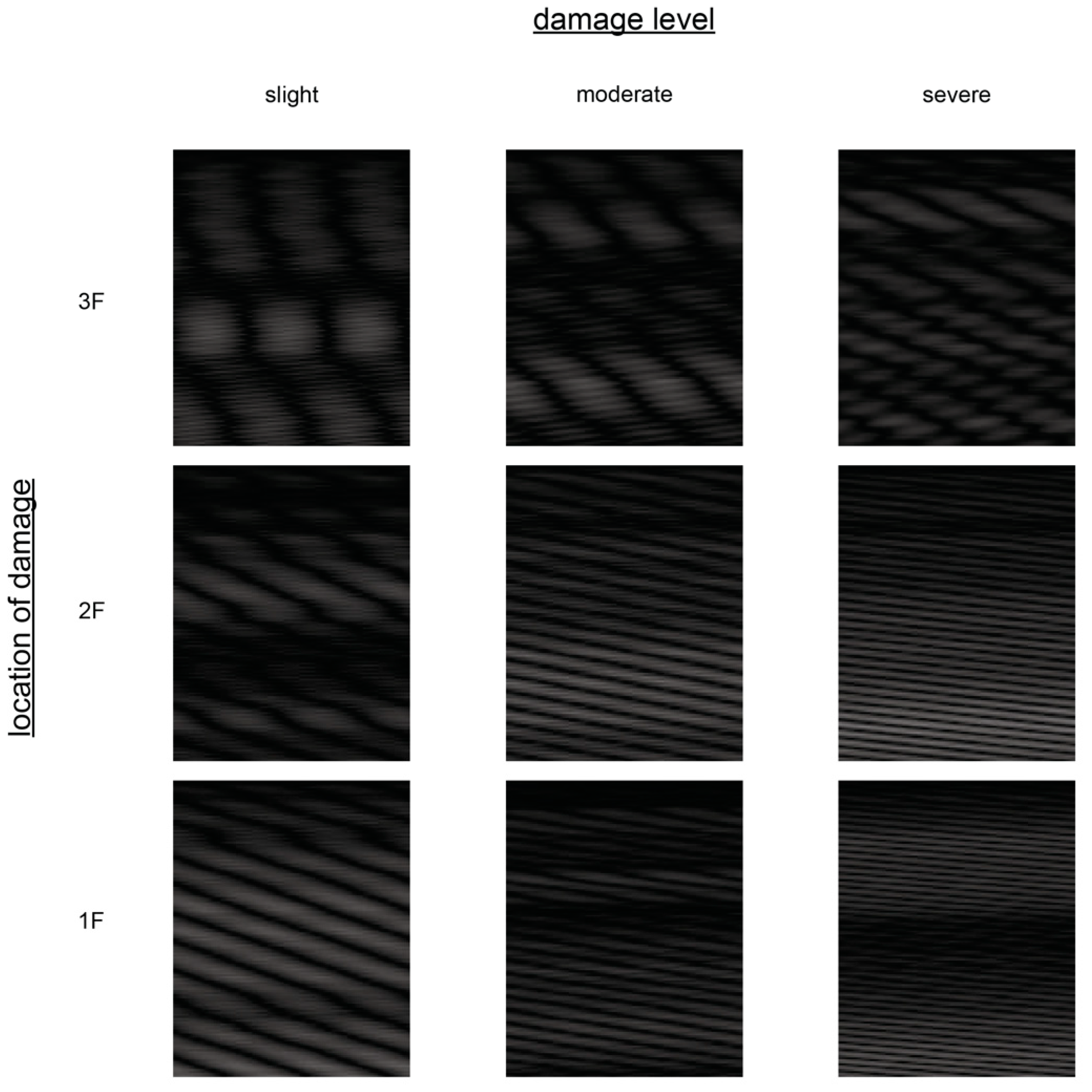
Attractors in a three-dimensional reconstruction space are depicted in
Figure 5. Images converted from attractors with sample interval
, delay time
, trajectory length
, and embedding dimension
are presented in
Figure 6.
2.3.2. Convolutional Neural Network Setup
The CNN model, as illustrated in
Figure 7, consists of two trainable layers: the convolutional layer and the fully connected layer. The convolutional layer has eight kernels, each 3 × 3 in size. This is followed by a 2 × 2 max-pooling layer with the stride set to 2 in both dimensions, and then a dropout layer with a dropout rate of 0.5 and a flattening layer. The fully connected layer follows. Since this fully connected layer is also the output layer of the model, it consists of ten nodes to match the ten damage cases. The output of the ten nodes is fed into a softmax function to give the probability of each class. ReLU activation is used throughout the model, except for the aforementioned softmax at the output end. The ADAM optimizer is used for gradient decent, along with cross-entropy as the loss function. There are 139,796 trainable parameters in total, eighty of which belong to the convolutional kernels. The model was implemented using Python with the open-source Keras library [
33], with Tensorflow as the backend [
34].
3. Results
The displacement responses of the structure were converted into matrices with the previous parameters. As a result, the generated images have a dimension of
(width x height). A total of 2000 were generated for each of the 10 damage cases. This dataset was further divided into a training dataset and a validation dataset with 1600 images and 400 images, respectively. The set of images showcased in
Figure 6 is taken from this dataset.
Three different indices are examined to quantify the results: the accuracy, recall, and Cohen’s kappa coefficient. After 20 epochs of training, both the training and validation accuracy plateaued around 99%. No apparent sign of overfitting is present, most likely due to the simplicity of the chosen CNN model.
Some insights can be inferred by a close examination of the confusion matrix. To prevent sporadic results due to stochasticity, the following trends were checked against 29 different runs of the CNN training using the same CNN model with different pseudorandom seeds. Recall, also known as sensitivity, is defined as the proportion of actual positive cases that are correctly classified, given as
where
is the number of true positives that the model correctly classified,
is the number of cases classified as positive by the model, and
is the number of false negatives that the model classified incorrectly. It was found that the recall value was higher than 0.9 for all 10 classes. The results are summarized in
Figure 8. There is a clear trend that when recall is calculated with respect to the level of damage, ease of prediction increases with increasing proximity of damage to the sensor (third floor). By contrast, severely damaged structures are easier to predict than slightly damaged structures, with the exception that healthy structures have the highest recall value.
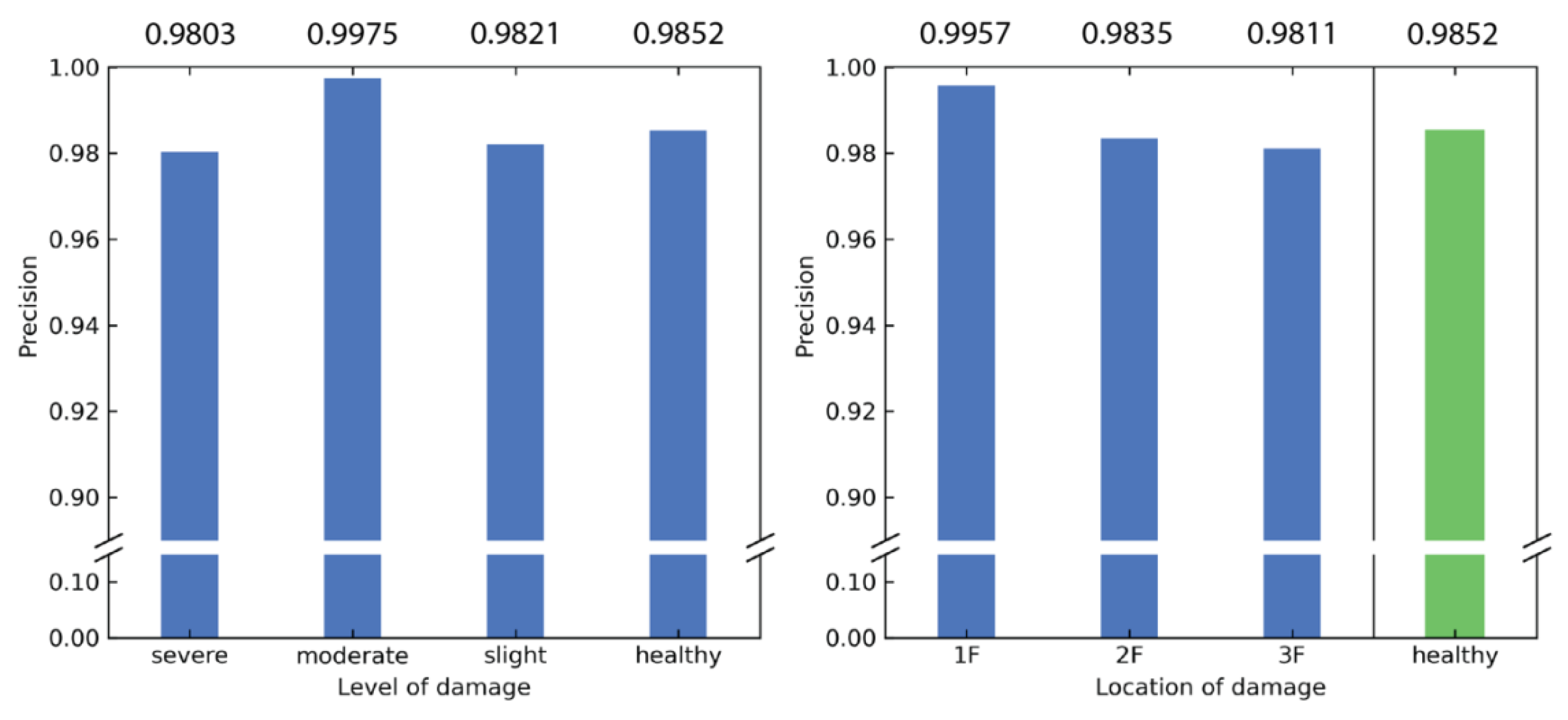
The counterpart of recall is precision, which is given by
where
is defined previously and
is the number of false positives that the model incorrectly classified as positives. Similar to the recall, the precision is high for all 10 classes, with no classes having a precision less than 0.9. The results for the precision are summarized in
Figure 9. It can be interpreted that the predictions are more trustworthy when the model reports damage closer to the ground floor.
Cohen’s kappa coefficient
is calculated as
where
denotes the accuracy and
denotes the hypothetical probability of chance agreement, which is
for the present demonstration. It follows that
for this example is
. With the common interpretation of Cohen’s kappa coefficient,
translates to almost perfect agreement with the true value. Concluding the above, the proposed conversion method does effectively embed the structural health data, in such a way that the information can be easily extracted by CNN models.
4. Discussion
The most efficient SHM method is to monitor the natural frequencies variation of considered structures after events.
Table 3 demonstrates the natural frequencies of the three-story shear frame under healthy and different damaged scenarios, while the relative errors of natural frequencies between the healthy and damaged structures are listed in the parentheses. One can find that the more damaged scenario shows the larger frequency variation. For cases of little-damaged structures (with the reduction factor
Rk = 0.9) in
Table 3, the relative errors of the natural frequency for the first mode are less than 3%. In most practical in situ measurements with signal noises and measurement errors, such differences are not easily identified from the measured time-history data. These results reveal the limitation of the frequency-based SHM method and the superiority of the proposed SHM method.
In order to examine whether the damping influences the structural health diagnosis of the proposed method, we consider two cases, including healthy and SE3 with a classical damping matrix C = diag.<200, 200, 100> kN.s/m. Each of the cases includes 2000 images. These data are divided into 1500 training dataset and 500 validation dataset. The CNN model is composed of eight convolutional layers and a fully connected layer. The 8 convolutional kernels are all in the same size of 3 × 3 but with different depth of 32, 32, 16, 16, 8, 8, 4 and 4 sequentially. Relu and softmax functions are chosen as the activation functions for the first four layers and the last four layers, respectively. The fully connected layer consists of two nodes, the healthy case and the damaged case for damage detection. The model with the highest validation loss is stored for tests. Untrained 1000 healthy cases and 1000 damaged cases are used to test the performance of the model. The derived testing accuracy of this model is 96.95%. Furthermore, its recall and precision are 95.30% and 98.55%, respectively. The evaluation index shows the ability to classify the damaged and healthy cases when damping is considered.
As mentioned in the introduction, Overbey et al. [
25] reported the generalization of deterministic attractors to pullback attractors. The importance of this extension is that an exact excitation signal is no longer required. In the present example, it was demonstrated that the time delay method yields the desired and expected results with a stochastic signal as excitation, which further supports the conclusion of the former work. This generality is particularly useful when either the system in question is not suitable for giving a prescribed excitation, or the excitation that led to the gathered response is not available. In both cases, the present findings also suggest that the time delay method can be used without modification.
There are some important implications resulting from the present CNN model successfully classifying the location of damage. Most current SHM methods are unable to extract the location of damage using the time-history data of a single sensor. By successfully differentiating the location, the presence of information on the location of damage in the reconstruction attractor is proven. However, how this information should be extracted in practical usage remains unknown. This is because, in practice, the only data available are those belonging to the healthy state, and so the responses of different damage cases are unknown. Unsupervised CNN learning is therefore required. The health of the structure can only be determined by comparing the response sequence of interest to the healthy response, as commonly seen in other vibration-based damage detection schemes. Without the knowledge of other damage cases, detecting the location of damage would be even more challenging.
Some properties of the attractor matrix are discussed here. Apart from the evident effect of
and
on the dimensions of the matrix, the combination of
,
, and
affects the uniqueness of each element. More specifically, when
is larger than
, values in the last few columns reappear in the first few columns, shifted down by one row. This has some practical consequences. For the typical case where a lengthy time-history response is collected at sample rate
, the delay time
and the length
of the trajectory must be chosen carefully if the user is to maximize the amount of information in the matrix, i.e., to avoid repeating values. It should be noted that in the special case where the sample rate
is equal to the delay time
, the attractor matrix becomes a Hankel matrix:
Although the attractor matrix is formulated with the time delay vectors as row vectors, other interpretations of the matrix can be made. The CNN can therefore see more than just the attractor that formulates the matrix. As an example, the transpose of the matrix is shown to be a second attractor in the same format as in the proposed method. The original matrix
is constructed with sample rate
, delay time
, trajectory length
, and embedding dimension
. The transpose of
, denoted by
, is
The parameters of reconstruction for
are further denoted with the superscript
. By comparison, it is found that the transposed sample rate
is
, the transposed delay time
is
, the transposed trajectory length
is
, and the transposed embedding dimension
equals
. Conceptually, if the matrix
is analyzed through a horizontally sliding window, the original trajectory that is constructed by the set of un-superscripted parameters
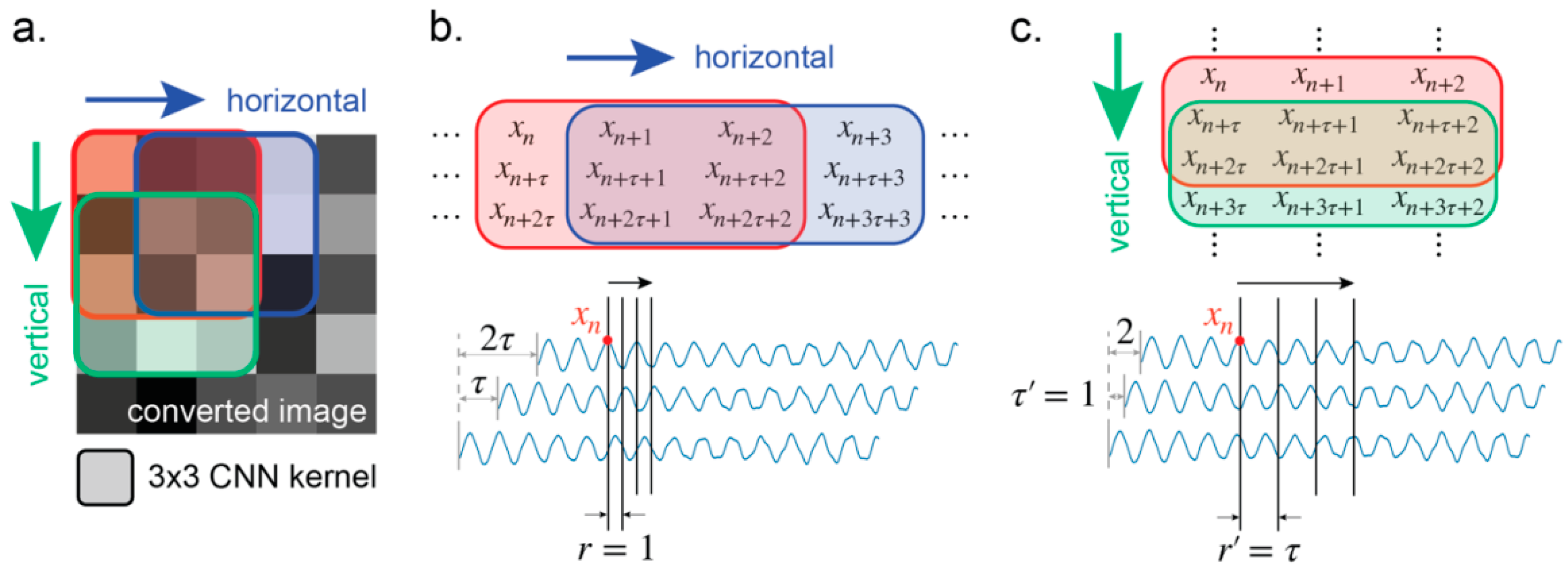
can be seen. By contrast, the trajectory constructed by the set of superscripted parameters
is observed if the window is slid vertically (
Figure 10).


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}