Abstract
The time spent in glucose ranges is a common metric in type 1 diabetes (T1D). As the time in one day is finite and limited, Compositional Data (CoDa) analysis is appropriate to deal with times spent in different glucose ranges in one day. This work proposes a CoDa approach applied to glucose profiles obtained from six T1D patients using continuous glucose monitor (CGM). Glucose profiles of 24-h and 6-h duration were categorized according to the relative interpretation of time spent in different glucose ranges, with the objective of presenting a probabilistic model of prediction of category of the next 6-h period based on the category of the previous 24-h period. A discriminant model for determining the category of the 24-h periods was obtained, achieving an average above 94% of correct classification. A probabilistic model of transition between the category of the past 24-h of glucose to the category of the future 6-h period was obtained. Results show that the approach based on CoDa is suitable for the categorization of glucose profiles giving rise to a new analysis tool. This tool could be very helpful for patients, to anticipate the occurrence of potential adverse events or undesirable variability and for physicians to assess patients’ outcomes and then tailor their therapies.
1. Introduction
Type 1 diabetes (T1D) is an autoimmune disease characterized by the destruction of pancreatic beta cells. Individuals with T1D rely on external insulin to regulate blood glucose (BG) levels. Insulin infusion can be performed either with multiple daily injections (MDI) or with continuous subcutaneous insulin infusion (CSII). To avoid both high and low levels of BG (hyper- and hypoglycemia, respectively), insulin must be properly infused. Both hyper- and hypoglycemia lead to several complications over time: blindness, kidney failure, cardiovascular complications, and even death [1].
Insulin dosing is usually adjusted by physicians according to patient’s characteristics, such as carbohydrate intake and body weight [2]. Even though current T1D technology allows the combination of continuous glucose monitoring (CGM) and CSII, achieving optimal glycemic control is very complicated due to large intra-patient variability [3]. Changes in glycemia are consequences of the circadian rhythm of hormones responsible for the glucose metabolism and carbohydrate intake, and glycemic variability is increased in people with diabetes [4]. Dealing with the complex behavioral characteristics of patients with T1D makes it difficult for physicians to adjust proper insulin dosing profiles to handle patient’s activities. The effective integration of relevant clinical data in a decision support system (DSS) would be able to relieve the burden that affects physicians in taking clinical decisions during consultations of patients with T1D and would help optimize insulin delivery therapy [5]. The automatic adaptation of insulin therapy based on information from continuous glucose monitoring has been the subject of many developments in the field of DSSs and the artificial pancreas [6,7].
The time spent in, above and below the target glucose range are commonly presented for descriptive purposes and to encourage patients with T1D to increase the time spent in their target ranges, which would improve the quality of glucose control. According to Tyler and Jacobs (2020), increasing from 50% to 60% the amount of time in a day that a person’s glucose is within the target glucose range would be considered to be impressive performance for a DSS [7]. The time spent in different glucose ranges indicate the occurrence of different levels of hypo- and hyperglycemic events, and these times, during a day, are relative contributions to the 24-h time budget. Several works presented approaches for different activities performed during a 24-h period using Compositional Data (CoDa) analysis [8,9,10,11,12,13,14,15]. Since times spent in different glucose ranges are codependent and carry only relative information, log-ratio techniques for CoDa are appropriate to deal with this type of data.
Recently, a methodology based on CoDa analysis for the categorization of daily glucose profiles patients with T1D has been presented in [13]. Glucose profiles of 6-h duration have also been categorized using CoDa [15]. In this work, we aim to present a methodology for the categorization of 24-h and 6-h periods of glucose data, also based on a CoDa approach. It is an improved and extended version of the works presented in [13,14,15]. Moreover, this work also proposes a discriminant model able to predict the category of the last 24-h glucose composition at different times of the day. In addition, it is introduced a probabilistic model of transition between categories from the previous 24-h period to the subsequent 6-h period, based on the retrospective analysis of the glucose data. The idea is to introduce a new tool that would allow patients to know the category of their current glucose profile, and that could be used to help physicians to provide individualized adjustments in patients’ therapies according to each possible scenario of transition between categories of profiles. This work is organized as follows: Section 2 briefly explains some concepts of CoDa. Section 3 summarizes the dataset used and the methodology considered for the analysis of glucose profiles and obtainment of the probabilistic model. In Section 4 the results are discussed. Finally, in Section 5, conclusions are provided.
2. Compositional Data Analysis
A compositional vector of D parts is described as:
where are positive components and , where C is a non-informative closure constant. The simplex () is the set of real positive vectors closed to a constant. Unconstrained multivariate data should be analyzed through standard multivariate analysis, which is not valid for compositional data [16]. It was only in 1982 that John Aitchison [17] proposed a methodology for the analysis of compositional data, which considers that the relevant information of a composition consists of the ratios between its components.
The absence of satisfactory parametric classes of distributions and the lack of meaningful definitions of independence for sets of proportions makes it difficult to handle statistics in the simplex [17]. Compositional data in the simplex can be transferred to the real space through the expression in coordinates, on which traditional statistical methods can be applied [18]. These coordinates can be obtained through the centered log-ratio (clr) transformation and isometric log-ratio (ilr) transformation:
where is the geometric mean of x. This transformation was introduced by [18] and projects to the real space The ilr vector can be viewed as the coordinates of a composition with respect to an orthonormal basis on the simplex [19].
where is an orthonormal basis in .
The Aitchison distance [20] between compositions is equal to the Euclidean distance between coordinates, which allows the usage of distance-based clustering techniques in compositional data [21].
3. Materials and Methods
3.1. Dataset
Data from six T1D patients who wore for approximately eight weeks the Paradigm Veo system with the second generation of the Enlite CGM sensor (Medtronic Minimed, Northridge, CA, USA) were analyzed in this work. Data were collected during a clinical trial that aimed to assess an artificial pancreas system during aerobic and anaerobic physical activity [22]. Demographic characteristics are shown in Table 1. All patients provided written informed consent for research participation.

Table 1.
Demographic characteristics for the dataset used.
Patients used a CGM system which recorded BG measurements every five minutes. Periods of different duration were selected for analysis at different times of the day. Glucose time-series of 24-h and 6-h duration starting at different times (00:00, 06:00, 12:00, and 18:00) were analyzed considering the standardized clinical levels of hypo- and hyperglycemia presented in Table 2.
Table 2.
Standardized clinical levels of hypo- and hyperglycemia [23,24].
The four levels of hypo- and hyperglycemia presented on Table 2 and the range related to normoglycemia (70 mg/dL ≤ BG ≤ 180 mg/dL) defined the five glucose ranges considered for the analysis of time-series, which allowed the obtainment of the composition:
Both 6-h and 24-h periods of glucose data were split into time spent in the five preceding glucose ranges. However, either periods of 6-h or 24-h sometimes presented a non-uniform number of samples, due to missing values related to CGM malfunction. For a 24-h period to be considered valid, each one of its four 6-h periods must contain at least 70% of valid data. In the case of profiles with missing CGM samples, the amounts of time corresponding to the number of missing samples were assumed to be evenly distributed between the existing ranges of the period in analysis. Time spent in different ranges during a finite period of 24-h or 6-h are relative contributions to glucose profiles, codependent, and therefore, should be analyzed as CoDa.
Initially, 24-h periods of glucose data, starting at 00:00 and ending at 24:00 were analyzed, following an adaptation of the methodologies presented in [13,14]. Table 3 reports the average amounts of time spent in each glucose range per patient in minutes/period, considering the profiles from 00:00 to 24:00. These values were obtained by adjusting the geometric means of the components to 1440 min (24-h period). Due to the difference in patients’ central tendency of the compositions of days from 00:00 to 24:00, shown in Table 3, it was performed an individualized analysis of each patient’s profiles.
Table 3.
Compositional center of each patient. Analysis of 24-h periods from 00:00 to 24:00. Geometric mean of the amounts of time spent in each glucose range, obtained by adjusting the geometric means of the components to 1440 min (24-h).
After the analysis of 24-h periods from 00:00 to 24:00, 24-h glucose time-series starting at 06:00, 12:00, and 18:00 were also analyzed, following the same missing data exclusion criteria as aforementioned. Table 4 shows the quantity of 24-h periods followed by a 6-h period at different times for each patient.
Table 4.
Quantity of 24-h periods followed by a 6-h period at each time of analysis available per patient.
3.2. Data Analysis
The steps for the analysis and categorization of both 24-h and 6-h periods are presented in Figure 1. The first part of the figure shows the development stage, in which preprocessing and selection of valid days for analysis occur. The second part consists of the zero analysis, followed by CoDa analysis and clustering. The third part consists of the presentation of results obtained in the CoDa analysis in terms of clinical outcomes, the discriminant model to categorize the previous 24-h period at different times of the day, and a transition model to predict the future 6-h period. On the right bottom, a potential application of the methodology is presented.
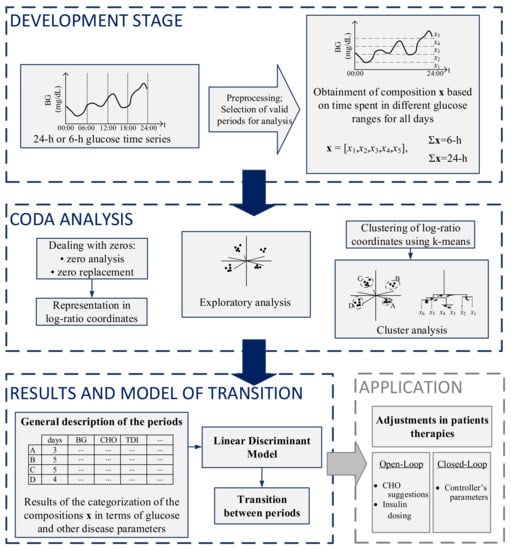
Figure 1.
Summarized methodology for the analysis and categorization of glucose profiles using CoDa.
After the obtainment of the compositions, zero analysis was performed. Since CoDa analysis is based on logarithms of ratios and both operations require non-zero elements in the data matrix, the log-ratio methodology must be preceded by proper handling of zero values, as has been extensively described by [25,26,27,28]. The zero patterns were replaced using the log-ratio Expectation-Maximization algorithm [29]. Given that the CGM records data every 5 min, the matrix of detection limits used in the zero imputation was obtained considering fractions of 5 min, depending on the position of the zero on the compositions, according to [13].
Following the zero replacement, data were represented through coordinates, according to Equations (2) and (3). The orthonormal basis of the ilr-transformation was defined following a sequential binary partition (SBP) [30], presented in Table 5. The SBP was defined following the clinical interpretation of time spent in different glucose ranges which represent different situations (occurrence of hypo- and hyperglycemic events), as has been detailed in [13].
Table 5.
Sequential Binary Partition defined for the log-ratio coordinates.
The first coordinate (ilr1) is calculated following the expression:
The ilr1 can be interpreted as a balance between the log-ratio of the geometric mean of the times spent in <54 and 54–70 mg/dL (with +1 at the first line in the sign matrix of Table 5) and the geometric mean of all the other times (with −1 in the sign matrix). It can be interpreted as the relationship between the time spent in the hypoglycemic ranges and the time spent in the normo- and hyperglycemic ranges.
The ilr2 is equal to the log-ratio of the times spent in <54 and between 54–70 mg/dL and can be interpreted as the balance between the time spent in level 2 and level 1 hypoglyemia.
The ilr3 is the balance between the log-ratio of the geometric mean of the times spent between 180–250 and >250 mg/dL and the geometric mean of the times spent between 70–180 mg/dL, i.e., the balance between time spent in the hyperglycemic and normoglycemic ranges:
The ilr4 is equal to the log-ratio of the times spent in >250 and between 180–250 mg/dL. It is the ratio between the time spent in level 2 and level 1 hyperglycemia:
Figure 2 shows a 24-h period of a glucose time-series, in which the glucose ranges related to normoglycemia and both levels of hypo- and hyperglycemia are highlighted.
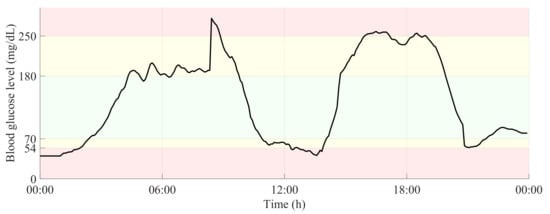
Figure 2.
24-h glucose time-series with delimitation of glucose ranges related to normoglycemia and both levels of hypo- and hyperglycemia.
Following, the vectors corresponding with the composition, obtained from the 24-h time-series. The composition was defined according to Equation (4). First, the distribution of the 288 samples, followed by its equivalent summed to 1440 min (24-h) and last, normalized to unity.
The computation of the clr and ilr transformations for these compositions, according to Equations (2) and (3), defined by Equations (5)–(8).
After the representation in coordinates, an exploratory analysis has been performed. A very useful exploratory tool that allows the discovery of potential clusters of similar compositions and significant statistical relationships between log-ratios of the parts is the clr-biplot [31]. The clr-biplot is an adaptation of the biplot [32] for compositional data.
K-means algorithm [33] was applied to coordinates of 6-h periods at all times to check for different patterns of periods. The algorithm was also applied to the 24-h periods starting at 00:00 and ending at 24:00 to check for different patterns of days. Since the data now is represented through coordinates, the distance between two periods can be easily calculated as the Euclidean distance between two coordinates, meaning that k-means can be directly applied either to the ilr or clr coordinates [34]. The algorithm was tested for several groups considering each time 25 random repetitions of the selection of initial centers. Clustering results can be evaluated using either external or internal validation, in which external information is provided or only the information within the data set is used for clustering validation, respectively. Three different indices that are used for internal validation are the Calinski–Harabasz index [35], Dunn index [36] and Silhouette index [37], those indices have been recently used as validation methods to CoDa clusters in [38,39]. In this work, the choice of k considered, the interpretability of the clinical outcomes of the groups of both 6-h and 24-h and their distribution in the clr-biplot.
Groups of periods with different lengths were analyzed regarding the maximums and minimums of parts and ratios. Additional measures were also obtained to improve the interpretation of the 24-h periods: average blood glucose (BG), BG variation (BGV), Low and High Blood Glucose risk Indexes (LBGI and HBGI) [40], total basal insulin, total bolus insulin, time of pump suspension and total carbohydrate (CHO) ingested.
As stated, k-means algorithm was applied separately for periods of 6-h and 24-h, therefore, the categorization for periods of different duration was done independently. Once the categories of the 24-h periods were obtained, a discriminant analysis method was applied to each patient’s 24-h periods from 00:00 to 24:00. This discriminant analysis considered only 24-h periods from 00:00 to 24:00 and was used to find a discrimination rule to assign any individual 24-h composition (x) at different times (00:00, 06:00, 12:00, and 18:00) to a group. The main objective is to make possible that the individual looks at the previous 24-h composition, at different times of the day and determine the group to which that 24-h period belongs.
We considered a linear discriminant (LD) model where the discrimination rule is based on compositional linear functions on x [34]. Discriminant analysis was developed by [41] and it is one of the most traditional methods for classification. The discriminant rule is based on probabilities. One composition x is classified in a determined group with the largest probability, using the information provided by the training data set. The input features considered for the LD classifier were the ilr coordinates. The discrimination functions used to classify the data were calculated considering the information included in the composition using leave-one-out cross-validation (LOOCV). The accuracy of the method was measured by the percentage of compositions correctly classified in its respective group.
The probability model of transition between a category of the previous 24-h period to a subsequent 6-h period was performed through a retrospective analysis of the data after the proper categorization of the periods. This analysis was performed at different times of the day: 00:00, 06:00, 12:00, and 18:00. The counts of moving from determined category of 24-h period to a category of 6-h period were expressed it in terms of probabilities of transition at different times of the day. A probabilistic model of transition between the category of the past 24-h of glucose to the category of the future 6-h period was obtained.
4. Results
This section is organized as follows: first, a general description of the groups obtained for periods of both 24-h and 6-h duration is presented. For periods of both durations, the main characteristics of each group obtained are presented. Then, the results of the LD model used for the categorization of glucose profiles are presented. Finally, a probability model that represents the probabilities of transition from the preceding 24-h period to the following 6-h period is presented.
4.1. General Description of the Periods
Both 24-h and 6-h periods of each patient were categorized separately. The periods were characterized in terms of relative time spent by the individuals in specific glucose ranges during 24-h or 6-h, according to the log-ratio approach. Even though groups from different patients may present comparable characteristics regarding the relative interpretation of time spent in different glucose ranges, the results must be interpreted per patient and in a relative sense and not in an absolute way.
4.1.1. 24-H Periods
The 24-h periods were categorized in five different groups, described as V, W, X, Y, and Z:
- V - periods with relatively high amounts of time in level 2 hypoglycemia
- W - periods with relatively high amounts of time in level 1 hypoglycemia
- X - periods with relatively low amounts of time in the ranges related to hypo- and hyperglycemia
- Y - periods with relatively low amounts of time in the ranges related to hypo- and normoglycemia and high amounts of time in the ranges related to hyperglycemia.
- Z - periods with relatively high amounts of time in the ranges related to level 1 hypoglycemia and both levels of hyperglycemia.
Table 6 shows the log-ratios between the center of each group and the overall center for all patients (Table 3). Positive values reflect the relative mean of a part above the overall composition and negative values reflect the relative mean of a part below the overall composition.
Table 6.
Comparison between the compositional center of each group with the whole center. Values are expressed per part and represent relative proportion to the mean composition.
The values of Table 6 can be interpreted in terms of time: the values below 54 mg/dL (level 2 hypoglycemia) during periods of type V in patient P5 are approximately 61 () times the average time in this range considering the mean composition. This value decreases to 6% () when data in group Y for the same patient are considered. Considering the mean values showed in Table 3, during 24-h periods of group V of P5, this patient spends on average approximately 37 min in level 2 hypoglycemic range.
Table 7 shows the summary of glucose and insulin outcomes per group for 24-h periods. The lowest Avg BG is presented for periods of group W for all patients, except for patient P5, in which the lowest Avg BG is presented for periods of type V. The highest Avg BG is presented for periods of group Y for all patients. The greatest BGV is presented in periods of group V for patients P1, P2, and P4. Periods of type V of patients P2, P4, and P5 presented a moderate LBGI (LGBI between 2.5 and 5.0), and periods of type Y of all patients presented the highest HBGI between all groups; however, only for P1, P3, and P6 this index was considered high (HBGI > 9.0). All three groups of patient P5 presented high HBGI. Periods of type V of patients P1, P2, P3, and P5 presented the lowest amount of basal insulin during the 24-h periods, while the periods of type Y of patients P2, P3, and P5 presented the highest amount of bolus insulin. Periods of group W of P2, P3, and P4 presented the highest amounts of CHO ingested.
Table 7.
Summary of clinically relevant outcomes.
4.1.2. Categories of 6-h Periods
The 6-h periods were categorized in four different groups, described as A, B, C and D, according to the comparison of the compositional center of each group with the whole center:
- A—periods with relatively high amounts of time in both levels of hypoglycemia and relatively low amounts of time in both levels of hyperglycemia
- B—periods with relatively low amounts of time in both levels of hypoglycemia and level 2 hyperglycemia
- C—periods with relatively high amounts of time in both levels of hyperglycemia
- D—periods with relatively high amounts of time in both levels of hypoglycemia and low amounts of time in level 1 hyperglycemia.
Table 8 shows the compositional center of each group of 6-h periods for all patients. the geometric mean of the amounts of time spent in each glucose range, obtained by adjusting the geometric mean of components to 360 min.
Table 8.
Compositional center of each group of 6-h periods for each patient. Geometric mean of the amounts of time spent in each glucose range, obtained by adjusting the geometric mean of components to 360 min.
It should be emphasized that times in different glucose ranges showed in Table 8 are geometric means of groups composed by several periods. The 6-h periods of group A of all patients (except P4) are characterized by the fact that individuals during periods of type A spent longer time in both levels of hypoglycemia than during periods of other types. For P4, the average time spent in level 2 hypoglycemia during periods of type D is even higher than in periods of type A.
For all patients that presented 6-h periods of type D, except P5, even though most of the time was spent by the individuals in the target range, a parcel of the time during some of these 6-h periods was spent with BG below 54 mg/dL. Time spent in level 2 hypoglycemia would require immediate action to be taken by the patient.
4.2. Linear Discriminant Model
The classification accuracy obtained per patient with the linear discriminant model is showed in Table 9. These models were obtained with the valid 24-h periods starting at 00:00 and ending at 24:00, regardless of the existence of valid 6-h periods in sequence. LOOCV and the respective categories obtained for these periods were considered.
Table 9.
Accuracy of the linear discriminant models with LOOCV.
The LD models obtained are suitable for the categorization of glucose profiles, as shown in Table 9, which expresses high accuracy in classification.
4.3. Transition between Periods
The transition between the categories of the last 24-h period to the category of the subsequent 6-h period has been analyzed at different times of the day: 00:00, 06:00, 12:00, and 18:00. These transitions were counted and Table 10 shows the probabilities of transition at different times of the day for all patients.
Table 10.
Probabilitiesof transition from the preceding 24-h period to the following 6-h period. Analysis at 00:00, 06:00, 12:00 and 18:00.
Consider patient P2, at 12:00. The patient analyzes his glucose composition from his previous 24-h period, and verify that this period is categorized as type W. Currently, the probability of the category of the next 6-h period, from 12:00 to 18:00, being of type A is equal to 71.43%. As previously shown in Table 8, during 6-h periods of type A, patient P2 experiences, on average, 28 min of hypoglycemic events of level 1. If the patient knows the category of his previous 24-h period, and it is expected that he will continue with unsatisfactory glycemic control during the subsequent period, he/she may take a corrective action (that is, adjust basal insulin, take some carbohydrates, or correction bolus), to avoid that.
Consider patient P5, at 00:00. The patient analyzes his glucose composition and verify that the last 24-h are categorized as type W. During days of type W, even though P5 presents high Avg BG and BGV (Table 7), these days are also characterized by the fact this subject spends relatively high amounts of time experiencing hypoglycemic events of level 1 (Table 6). At this time, if a day of type W is detected, the probability of the next 6-h period (from 00:00 to 06:00) be of type A is approximately 57%. So if the patient knows that he has a nearly 60% chance of experiencing a hypoglycemic event during sleep time, he might take some carbohydrates before sleeping or even adjust the basal insulin during nighttime.
There are situations, however, in which it is probably better to avoid any special action. For instance, consider patient P4, at 18:00, even though the probability of moving from a day of type Y to a period of type C is the highest: 30.77%, and both types, Y and C, are characterized by high amounts of time in the ranges related to hyperglycemia, the probability of moving to a period related to hypoglycemia is almost as high: 23.08%, i.e., if the individual decides to increase the insulin aiming to avoid undesired hyperglycemia, it must be taken into account that the risk of that action will result in a hypoglycemic event is nearly the same.
5. Conclusions
A probabilistic model of transition between categories of glucose data has been presented in this work. This methodology is based on a previously presented methodology for the categorization of glucose profiles using compositional data analysis. In this work, we obtained a linear discriminant model suitable for the categorization of glucose data. A novel approach for the retrospective analysis of transition between categories of subsequent periods of different duration has been presented. The analysis was performed considering a dataset composed of 24-h and 6-h periods of glucose data, at different times of the day: 00:00, 06:00, 12:00, and 18:00. These times were chosen globally for all patients to comprise approximations of daytimes where relevant events occur, such as sleep time, waking up and breakfast, lunch, and dinner.
It is important to highlight that the probability model of transition between categories of 24-h to 6-h periods was retrospectively obtained from the available periods in sequence. Due to the limitation of the dataset, there were cases in which the probabilities values between different transitions were very similar. Additionally, the validation of the probability model has not been presented yet. The dataset used in this study has been acquired for different purposes. It was upon retrospective analysis that the authors considered the dataset, initially, for the categorization of profiles, and later, for the definition of the probability model of transition. The authors are aware that the number of patients involved in the study (six) is too small to represent the whole T1D patient population. However, this work aimed to present the feasibility of an individualized methodology that allows the analysis of transitions between different categories (or conditions) of both days and periods of a single patient. The categorization of glucose daily profiles has been presented earlier [13,14], this work shows that the discrimination of the past 24-h period is accurate and feasible to be performed at different times of the day. That is, in a real-time application, it is possible for the patient to look at his glycemic profile of the last 24-h, and to be able to identify in which category this period reliably fits. Then, the patient can use the transition model to predict the category of the future period and take corrective actions accordingly. The authors foresee that with a more expressive dataset, a probabilistic model of transitions could be validated with more representative results, allowing the application of the methodology into a decision support tool for managing T1D.
The prediction of blood glucose values using regression algorithms, considering glucose trends and other information regarding insulin therapy, has been pointed out by Oviedo et al as the most widely used for glucose management purposes [42]. This work, however, is not intended to present the prediction of blood glucose values or trends. The work follows a new approach for the identification of glycemic patterns based on a new method that considers the relative interpretation of time spent in different glucose ranges, based on CoDa analysis, as has been initially proposed by [13,14]. Followed by that, the main objective is to be able to predict the condition of the patient in the future, allowing the adjustment of therapy parameters according to the prediction, and for that, this work presents a new probability model of transition between categories of periods. Additionally, it is essential to recall that even though the results of groups of periods were presented considering common descriptions between patients, the results must be interpreted individually per patient, which would allow personalized analysis and assessment of patients’ state, prediction of future condition, and individualized adjustment of therapies
It was a first approach for the obtainment of a probabilistic model of transition between categories at different times of the day. In the future, the models can be adjusted, considering flexible periods according to patients’ routine. The approach is suitable for the categorization of glucose profiles and it can work as a new analysis tool. Additionally, it works as a complementary tool for the prediction of different categories of glucose control, which could assist patients to take correction measures ahead of adverse situations.
The methodology proposed could be incorporated into a DSS that would be able to identify patients’ current condition based on the distribution of time spent in different glucose ranges and to provide a probability of transition to another condition in the subsequent period. Therefore, following the definition of patients’ current category of glucose control, the transition model provides the prediction of patient’s condition in the future, which would allow tailored adjustments of therapy parameters according to the expected condition of the patient in the next few hours. In the future, the methodology could be applied for both open-loop and closed-loop systems (i.e., by suggesting ingestion of CHO, adjustments on insulin dosing, or modifications in the controller’s parameters). For example, if the patient expects a high probability that the future few hours will be characterized by the experience of hypoglycemic events, he might be able to decrease his basal insulin levels to try to avoid the hypoglycemic events. Additionally, if the patient expects that the next few hours will be characterized by high glucose variability, he can be less aggressive with his insulin boluses.
Even though the analysis was performed considering a limited dataset obtained from glucose data of six patients, the results could be used in the future. Over time, when additional data are available, it is possible that there could be changes in the number of clusters of each patient, indicating alterations in patients’ behavior and physiology. Following that, the probabilistic model of transitions could be periodically updated during the visits to the physicians. Likewise, the availability of new data could also support the creation of models with a fixed quantity of periods in analysis, where the incorporation of more recent data would imply the disposal of the earliest data. Nevertheless, a more representative model of transitions between periods would be required, including additional analysis of the insulin therapy of each patient and a more extensive dataset. The usage of this information could assist patients to identify evidence-based actions that would be of benefit and to anticipate the occurrence of adverse events. Additionally, it could support physicians to assess patients’ outcomes and tailor their insulin dosing profile.
Author Contributions
L.B. and A.B. wrote the manuscript, contributed to discussion, and reviewed/edited the manuscript. M.G. and I.C. supervised clinical studies. M.G., I.C., J.B., J.A.M.-F. and J.V. contributed to discussion, and reviewed/edited the manuscript. J.B. and J.V. obtained funding. All authors have read and agreed to the published version of the manuscript.
Funding
This project has been partially supported by the Spanish Government, Ministerio de Economía y Competitividad (MINECO) (Grants DPI2016-78831-C2-1-R, DPI2016-78831-C2-2-R, RTI2018-095518-B-C21 ), Agencia Estatal de Investigación (PID2019-107722RB-C21 / AEI / 10.13039/ 501100011033), the National Council of Technological and Scientific Development, CNPq Brazil through Grants 202050/2015-7, 207688/2014-1 and EU through FEDER funds.
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Ethics Committee of Hospital Clínic de Barcelona (protocol code HCB/2015/0683 and date of approval 22 September 2015).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Restrictions apply to the availability of these data. Data was obtained from the Spanish Consortium on Artificial Pancreas and Diabetes Technology and are available on request from the corresponding author with the permission of the Spanish Consortium on Artificial Pancreas and Diabetes Technology.
Acknowledgments
The authors are thankful to all the participants who dedicated their time and effort to complete this study.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| T1D | Type 1 diabetes |
| BG | Blood glucose |
| MDI | Multiple daily injections |
| CSII | Continuous subcutaneous insulin infusion |
| CGM | Continuous glucose monitoring |
| CoDa | Compositional Data |
| DSS | Decision support system |
| clr | Centered log-ratio |
| ilr | Isometric log-ratio |
| SBP | Sequential binary partition |
| BGV | Blood glucose variation |
| LBGI | Low blood glucose risk index |
| HBGI | High blood glucose risk index |
| CHO | Carbohydrate |
| LD | Linear discriminant |
| LOOCV | Leave-one-out cross-validation |
References
- Cobelli, C.; Dalla Man, C.; Sparacino, G.; Magni, L.; De Nicolao, G.; Kovatchev, B. Diabetes: Models, Signals, and Control. Biomed. Eng. IEEE Rev. 2009, 2, 54–96. [Google Scholar] [CrossRef]
- Walsh, J.; Roberts, R. Pumping Insulin: Everything You Need to Succeed on an Insulin Pump; Torrey Pines Press: San Diego, CA, USA, 2006. [Google Scholar]
- Kovatchev, B.; Cobelli, C. Glucose Variability: Timing, Risk Analysis, and Relationship to Hypoglycemia in Diabetes. Diabetes Care 2016, 39, 502–510. [Google Scholar] [CrossRef]
- Suh, S.; Kim, J.H. Glycemic variability: How do we measure it and why is it important? Diabetes Metab. J. 2015, 39, 273–282. [Google Scholar] [CrossRef]
- Sim, L.L.W.; Ban, K.H.K.; Tan, T.W.; Sethi, S.K.; Loh, T.P. Development of a clinical decision support system for diabetes care: A pilot study. PLoS ONE 2017, 12, e0173021. [Google Scholar] [CrossRef]
- Contreras, I.; Vehi, J. Artificial Intelligence for Diabetes Management and Decision Support: Literature Review. J. Med. Internet Res. 2018, 20, e10775. [Google Scholar] [CrossRef]
- Tyler, N.S.; Jacobs, P.G. Artificial Intelligence in Decision Support Systems for Type 1 Diabetes. Sensors 2020, 20, 3214. [Google Scholar] [CrossRef]
- Martín-Fernández, J.A.; Daunis-i-Estadella, J.; Mateu-Figueras, G. On the interpretation of differences between groups for compositional data. Sort 2015, 39, 231–252. [Google Scholar]
- Dumuid, D.; Stanford, T.E.; Martín-Fernández, J.A.; Pedišić, Ž.; Maher, C.A.; Lewis, L.K.; Hron, K.; Katzmarzyk, P.T.; Chaput, J.P.; Fogelholm, M.; et al. Compositional data analysis for physical activity, sedentary time and sleep research. Stat. Methods Med. Res. 2017, 27, 3726–3738. [Google Scholar] [CrossRef]
- Chastin, S.F.M.; Palarea-Albaladejo, J.; Dontje, M.L.; Skelton, D.A. Combined effects of time spent in physical activity, sedentary behaviors and sleep on obesity and cardio-metabolic health markers: A novel compositional data analysis approach. PLoS ONE 2015, 10, e0139984. [Google Scholar] [CrossRef]
- Pedišić, Ž.; Dumuid, D.; Olds, T.S. Integrating sleep, sedentary behaviour, and physical activity research in the emerging field of time-use epidemiology: Definitions, concepts, statistical methods, theoretical framework, and future directions. Kinesiology 2017, 49, 135–145. [Google Scholar]
- Dumuid, D.; Pedišić, Ž.; Stanford, T.E.; Martín-Fernández, J.A.; Hron, K.; Maher, C.A.; Lewis, L.K.; Olds, T. The compositional isotemporal substitution model: A method for estimating changes in a health outcome for reallocation of time between sleep, physical activity and sedentary behaviour. Stat. Methods Med. Res. 2019, 28, 846–857. [Google Scholar] [CrossRef]
- Biagi, L.; Bertachi, A.; Giménez, M.; Conget, I.; Bondia, J.; Martín-Fernández, J.A.; Vehí, J. Individual categorisation of glucose profiles using compositional data analysis. Stat. Methods Med. Res. 2019, 28, 3550–3567. [Google Scholar] [CrossRef]
- Biagi, L.; Bertachi, A.; Martín-Fernández, J.A.; Vehí, J. Compositional Data Analysis of Type 1 Diabetes Data. In Proceedings of the 3rd International Workshop on Knowledge Discovery in Healthcare Data (KDH), Stockholm, Sweden, 13 July 2018; Bach, K., Bunescu, R., Farri, O., Guo, A., Hasan, S., Ibrahim, Z.M., Marling, C., Raffa, J., Rubin, J., Wu, H., Eds.; pp. 8–12. [Google Scholar]
- Biagi, L.; Bertachi, A.; Martín-Fernández, J.A.; Vehí, J. Compositional Data Analysis of Glucose Profiles of Type 1 Diabetes Patients. IFAC-PapersOnLine 2019, 52, 1006–1011, 12th IFAC Symposium on Dynamics and Control of Process Systems, including Biosystems DYCOPS 2019. [Google Scholar] [CrossRef]
- Pearson, K. Mathematical Contributions to the Theory of Evolution.–On a Form of Spurious Correlation Which May Arise When Indices Are Used in the Measurement of Organs. Proc. R. Soc. Lond. (1854–1905) 1896, 60, 489–498. [Google Scholar] [CrossRef]
- Aitchison, J. The Statistical Analysis of Compositional Data. J. R. Statist. Soc. Ser. B 1982, 44, 139–177. [Google Scholar]
- Aitchison, J. The Statistical Analysis of Compositional Data (Monographs on Statistics and Applied Probability); Chapman and Hall: London, UK, 1986. [Google Scholar]
- Egozcue, J.J.; Pawlowsky-Glahn, V.; Mateu-Figueras, G.; Barceló-Vidal, C. Isometric Logratio Transformations for Compositional Data Analysis. Math. Geol. 2003, 35, 279–300. [Google Scholar]
- Aitchison, J. On criteria for measures of compositional difference. Math. Geol. 1992, 24, 365–379. [Google Scholar]
- Palarea-Albaladejo, J.; Martín-Fernández, J.A.; Soto, J.A. Dealing with Distances and Transformations for Fuzzy C-Means Clustering of Compositional Data. J. Classif. 2012, 29, 144–169. [Google Scholar] [CrossRef]
- Quirós, C.; Bertachi, A.; Giménez, M.; Biagi, L.; Viaplana, J.; Viñals, C.; Vehí, J.; Conget, I.; Bondia, J. Blood glucose monitoring during aerobic and anaerobic physical exercise using a new artificial pancreas system. Endocrinol. Diabetes Nutr. 2018, 65, 342–347. [Google Scholar] [CrossRef]
- Agiostratidou, G.; Anhalt, H.; Ball, D.; Blonde, L.; Gourgari, E.; Harriman, K.N.; Kowalski, A.J.; Madden, P.; McAuliffe-Fogarty, A.H.; McElwee-Malloy, M.; et al. Standardizing Clinically Meaningful Outcome Measures Beyond HbA1c for Type 1 Diabetes: A Consensus Report of the American Association of Clinical Endocrinologists, the American Association of Diabetes Educators, the American Diabetes Association, the Endocrine Society, JDRF International, The Leona M. and Harry B. Helmsley Charitable Trust, the Pediatric Endocrine Society, and the T1D Exchange. Diabetes Care 2017, 40, 1622–1630. [Google Scholar] [CrossRef] [PubMed]
- 6. Glycemic Targets: Standards of Medical Care in Diabetes—2019. Diabetes Care 2018, 42, S61–S70. [CrossRef]
- Martín-Fernández, J.A.; Barceló-Vidal, C.; Pawlowsky-Glahn, V. Dealing with Zeros and Missing Values in Compositional Data Sets Using Nonparametric Imputation. Math. Geol. 2003, 35, 253–278. [Google Scholar] [CrossRef]
- Martín-Fernández, J.A.; Palarea-Albaladejo, J.; Olea, R.A. Dealing with Zeros. In Compositional Data Analysis: Theory and Applications; John Wiley & Sons: Chichester, West Sussex, UK, 2011; pp. 43–58. [Google Scholar] [CrossRef]
- Martín-Fernández, J.A.; Hron, K.; Templ, M.; Filzmoser, P.; Palarea-Albaladejo, J. Computational Statistics and Data Analysis Model-based replacement of rounded zeros in compositional data: Classical and robust approaches. Comput. Stat. Data Anal. 2012, 56, 2688–2704. [Google Scholar] [CrossRef]
- Martín-Fernández, J.A.; Hron, K.; Templ, M.; Filzmoser, P.; Palarea-Albaladejo, J. Bayesian-multiplicative treatment of count zeros in compositional data sets. Stat. Model. Int. J. 2015, 15, 134–158. [Google Scholar] [CrossRef]
- Palarea-Albaladejo, J.; Martín-Fernández, J.A. zCompositions—R package for multivariate imputation of left-censored data under a compositional approach. Chemom. Intell. Lab. Syst. 2015, 143, 85–96. [Google Scholar]
- Egozcue, J.J.; Pawlowsky-Glahn, V. Compositional Data Analysis in the Geosciences: From Theory to Practice; Geological Society: London, UK, 2006; chapter Simplicial geometry for compositional data; pp. 145–159. [Google Scholar]
- Aitchison, J. The one-hour course in compositional data analysis or compositional data analysis is simple. In Proceedings of the IAMG’97 — The Third Annual Conference of the International Association for Mathematical Geology, Barcelona, Spain, 22–27 September 1997; Pawlosky-Glahn, V., Ed.; International Center for Numerical Methods in Engineering (CIMNE): Barcelona, Spain Volume I, II and addendum. ; pp. 3–35. [Google Scholar]
- Gabriel, K.R. The Biplot Graphic Display of Matrices with Application to Principal Component Analysis. Source Biom. Biom. Trust. 1971, 58, 453–467. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. A k-means clustering algorithm. JSTOR Appl. Stat. 1979, 28, 100–108. [Google Scholar]
- Pawlowsky-Glahn, V.; Egozcue, J.J.; Tolosana-Delgado, R. Modeling and Analysis of Compositional Data. John Wiley & Sons: Chichester, West Sussex, UK, 2015. [Google Scholar]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Dunn, J.C. Well-Separated Clusters and Optimal Fuzzy Partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Özgen Karacan, C.; Martín-Fernández, J.A.; Ruppert, L.F.; Olea, R.A. Insights on the characteristics and sources of gas from an underground coal mine using compositional data analysis. Int. J. Coal Geol. 2021, 241, 103767. [Google Scholar] [CrossRef]
- Olea, R.A.; Martín-Fernández, J.A.; Craddock, W.H. Multivariate Classification of the Crude Oil Petroleum Systems in Southeast Texas, USA, Using Conventional and Compositional Data Analysis of Biomarkers. In Advances in Compositional Data Analysis; Filzmoser, P.E.A., Ed.; Springer Nature Switzerland AG: Cham, Switzerland, 2021. [Google Scholar]
- Kovatchev, B.P.; Straume, M.; Cox, D.J.; Farhy, L.S. Risk Analysis of Blood Glucose Data: A Quantitative Approach to Optimizing the Control of Insulin Dependent Diabetes. J. Theor. Med. 2000, 3, 1–10. [Google Scholar] [CrossRef]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar]
- Oviedo, S.; Vehí, J.; Calm, R.; Armengol, J. A review of personalized blood glucose prediction strategies for T1DM patients. Int. J. Numer. Methods Biomed. Eng. 2016, 33, e2833. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).