1. Introduction
As technology advances, the number of infotainment systems available in vehicles is increasing [
1,
2]. Car manufacturers are including more functions and services in vehicles to increase user satisfaction and provide a variety of infotainment systems and environmental control functions for the driver to manipulate [
3]. Accordingly, factors that can distract driver concentration, such as setting up a global positioning system (GPS) navigation system and using an audio entertainment device have also increased [
4]. However, in a road environment where various unexpected situations exist, driver carelessness can cause serious safety threats. Therefore, to control the interior of the vehicle without distracting the driver’s concentration, human–vehicle interaction (HVI) systems are becoming increasingly important [
5].
Various sensors, such as touch screen, camera, depth, voice, and radar sensors are used in HVI systems for in-vehicle device control [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. Touch screens provide the largest amount of information to users at once and show the highest recognition accuracy. However, because eyesight must remain on the touch screen for control, it can lead to dangerous situations as a result of the break in concentration on the road. In contrast, camera, depth, radar, and voice sensors can be used without causing driver neglect. However, camera and depth sensors have the disadvantages of high computational complexity, personal privacy problems, and susceptibility depending on the light condition. Because illuminance varies depending on the weather, location, and time in the road environment, it can harm the recognition performance.
Conversely, voice sensors are not affected by light environments, unlike vision-based sensors; therefore, they can be used during the day, at night, or anytime. It also requires much lower computational complexity than vision-based sensors and is inexpensive. Therefore, a voice sensor is suitable as an HVI system inside a vehicle implemented as a power-constrained and resource-constrained platform, and much research has been conducted. Voice sensor-based command recognition exhibits excellent performance without high computational costs. However, when a voice sensor is used alone, recognition performance degrades in a severely noisy environment.
Radar sensors are another solution for command recognition because they provide robust recognition regardless of the illumination environment and do not cause privacy problems. Conventionally, radar sensor-based gesture recognition uses a frequency-modulated continuous-wave (FMCW) radar to obtain a range-Doppler map (RDM) by applying a 2-dimensional (2D) fast Fourier transform (FFT). Subsequently, the feature is extracted from the RDM, and the command is recognized using a machine-learning algorithm [
9,
10,
11]. Command classification using the FMCW radar showed high accuracy. However, the FMCW radar requires a relatively higher computational complexity and memory requirement than the continuous wave (CW) radar because of the 2D FFT. CW radars can extract micro-Doppler frequencies with less computation than FMCW radar require, which can be used as a feature for command recognition [
17]. However, when a CW radar sensor is used alone in a vehicle environment, performance may be degraded in a cluttered cabin environment because of passenger movement or vehicle vibration.
Voice sensors have low computational complexity and are robust to lighting conditions, but their performance is poor in noisy environments. CW radar sensors have the advantage of requiring less computational complexity, are not affected by lighting conditions, and do not present privacy issues. However, recognition performance can be degraded in severely cluttered interiors. Therefore, if only a voice or CW radar sensor is used in a vehicle environment, command recognition performance degrades in a specific environment with either significant noise or clutter, so the sensors must be fused to complement each other.
Recently, research on deep learning algorithms for classifying fusion data has increased remarkably, and among them, convolutional neural network (CNN) algorithms have been widely used [
18,
19,
20,
21]. However, CNN algorithms are difficult to apply to power-constrained and resource-constrained platforms such as in-vehicle environments because of their high computational complexity and large memory requirements. Therefore, various studies have been conducted to implement the CNN algorithm on the embedded platform, and a popular technique for increasing resource efficiency is the quantized model [
22,
23,
24]. Among them, the binarized convolutional neural network (BCNN) has been in the spotlight because it does not show much deterioration in performance, while dramatically reducing computational complexity and memory by reducing the parameter to single-bit precision [
25,
26,
27,
28,
29].
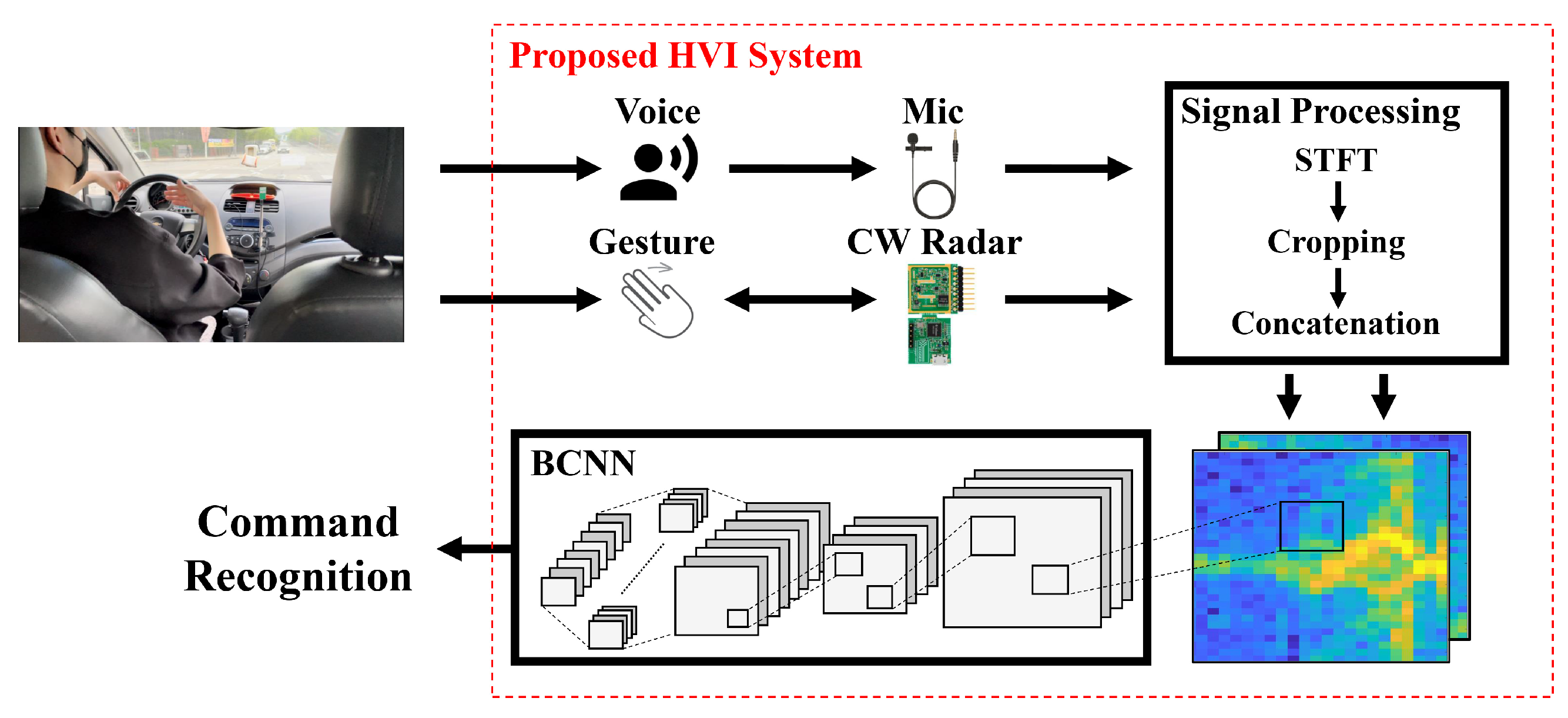
Therefore, in this paper, we propose an HVI system that can be implemented with high recognition performance on power- and resource-constrained platforms. To ensure command recognition performance, even under environmental constraints such as illumination, noise, and clutter, we fuse the voice and radar sensor information. Furthermore, we adopt BCNN algorithms that improve CNNs’ very high computational complexity and memory requirements and can implement them on an embedded platform. The rest of this paper is organized as follows:
Section 2 briefly reviews related works.
Section 3 provides an overview of the proposed system, BCNN algorithms, and signal processing methods.
Section 4 presents the experimental environment and performance evaluation results. Finally, the conclusions of this study are presented in
Section 5.
2. Related Works
Recently, command classification studies with voice recognition have been conducted frequently in vehicle environments. Wang et al. [
6] presented a front-end speech enhancement approach for robust speech recognition in automotive environments. In this study, a multiple Gaussian mixture model (GMM) architecture was proposed to deal with voice activity detection under low signal-to-noise ratio conditions. The trained GMMs were used to estimate the speech presence probability on a frame-by-frame basis. The estimated probability serves as basic information for the relative transfer function estimation, adaptive beamforming, and post-filtering. The average word error rate (WER) was 7.6% for several scenarios.
Loh et al. [
7] implemented a speech recognition interactive system that did not disturb the driver while driving. Fourteen speech commands were transformed into the frequency domain via the discrete Fourier transform (DFT), and Mel-frequency cepstral coefficients (MFCC) features were extracted by calculating the Mel-frequency spectrum. Subsequently, the MFCC feature was used to recognize the speech command with vector quantization using the Linde–Buzo–Gray model. The accuracy of the proposed system was 78.6%.
Feng et al. [
8] extracted MFCC features from speech signals, applied linear discriminant analysis (LDA), and aligned the data by applying a maximum-likelihood linear transform. Finally, maximum-likelihood linear transformation was applied to normalize the inter-speaker variability and for training and testing. The final data were combined with vehicle speed information, heating, ventilation, air conditioning (HVAC) fan status, wiper status, and vehicle type information. By adopting the hybrid deep neural network–hidden Markov model (DNN–HMM), WER was reduced by 6.3%. However, a single voice sensor system significantly reduced the accuracy in a noisy vehicle environment, and complex signal processing was required to improve performance.
Another sensor used in the HVI system is radar, and much research has focused on hand gesture recognition. Most of the studies used FMCW radar with high computational complexity. Smith et al. [
9] used FMCW radar to obtain RDM information. A total of nine features, including distance and velocity information, were extracted from the RDM and used for hand gesture classification. Random forest was adopted as the classification algorithm, and the proposed system performed at above 90% accuracy for all gestures on average.
Wang et al. [
10] proposed a method for continuous hand gesture detection and recognition based on the FMCW radar. RDM was acquired from raw data using a 2D FFT. A range map (RM) and Doppler map (DM) were extracted, and multiple signal classification (MUSIC) algorithms were used to extract an angle map (AM). Subsequently, hand gestures were segmented using threshold values; moreover, a fusion dynamic time warping (FDTW) algorithm was proposed, and a hand gesture recognition rate of 95.8% was achieved.
Sun et al. [
11] studied gesture recognition using a radar system based on micro-Doppler information. They incorporated the range information in addition to the micro-Doppler signature to filter out undesired moving targets. They used a total of five features from the acquired data, including the number of chirp-sequence cycles and the total bandwidth of the Doppler signal. The k-nearest neighbor (k-NN) algorithm was used to classify seven gestures, resulting in an accuracy of 84%. However, as in previous studies, the hand gesture recognition system using FMCW radar requires high computational complexity and memory owing to the 2D FFT operation to acquire RDM. Furthermore, an additional clutter removal algorithm is required to improve the performance in a vehicle environment with much clutter, leading to an increase in the complexity of the system.
Because a single sensor system has limitations in some environments, two or more sensors must be used by fusion. Over the past decade, research using deep learning techniques for sensor fusion data, mostly CNN algorithms, has been ongoing. Molchanov et al. [
18] presented a hand gesture recognition system that combined short-range radar, camera, and depth sensors. RDM was acquired by the FMCW radar, and distance, velocity, and angle information were obtained and then combined with the camera and depth sensors. The obtained datasets were used to learn and evaluate the 3D CNN classifier and showed a classification accuracy of 94.1%.
Münzner et al. [
19] studied deep learning methods for human activity recognition (HAR). A method for optimally fusing multimodal sensors was also studied. The early fusion, sensor-based late fusion, channel-based late fusion, and shared filter hybrid fusion performances of the CNN algorithm were analyzed.
Alay et al. [
20] proposed a multimodal biometric system to overcome the limitations of a single-mode biometric system. In this study, the CNN-based multimodal biometric system using iris, face, and finger vein recognition systems showed better accuracy than unimodal systems. The performance of the fusion technique was compared. The proposed system showed a performance of 99.4% with the feature-level fusion technique and 100% with the score-level fusion technique for the SDUMLA-HMT dataset [
30], a multimodal biometric database. In our work, we used reasonable voice and CW radar sensors on an embedded platform for command recognition in a vehicle environment. In addition, BCNN, a lightweight CNN algorithm, was used as a classification algorithm for fusion data. To the best of our knowledge, there are no BCNN-based sensor fusion studies with voice and radar sensors applicable to embedded systems.
5. Conclusions
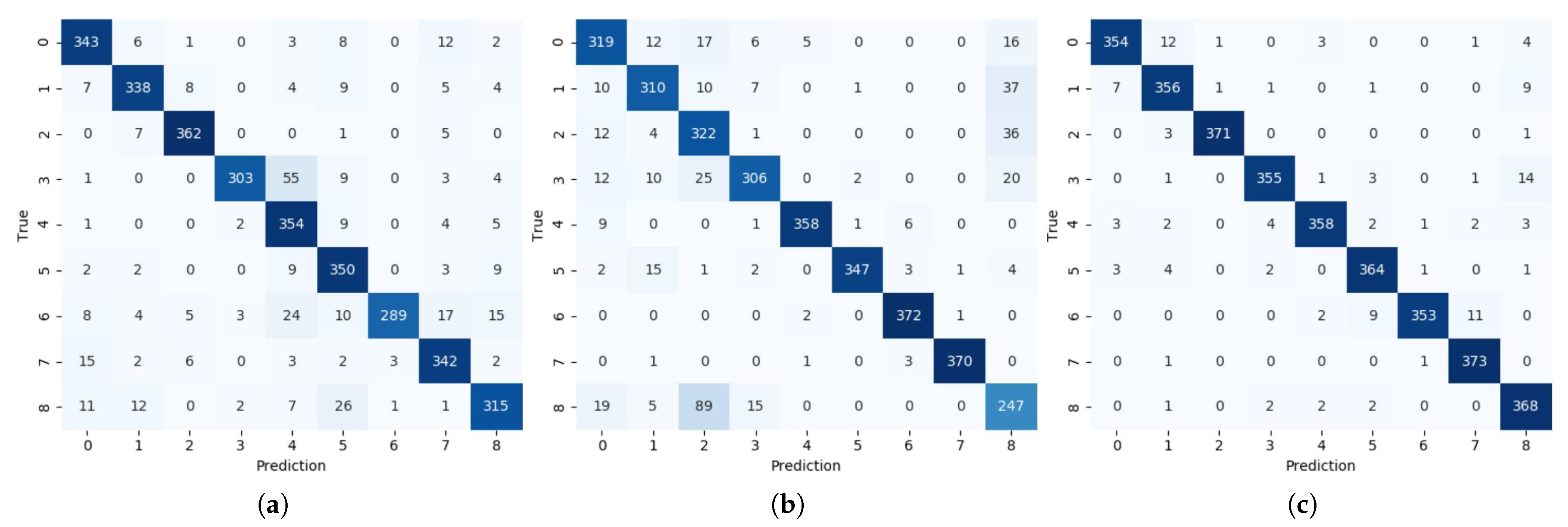
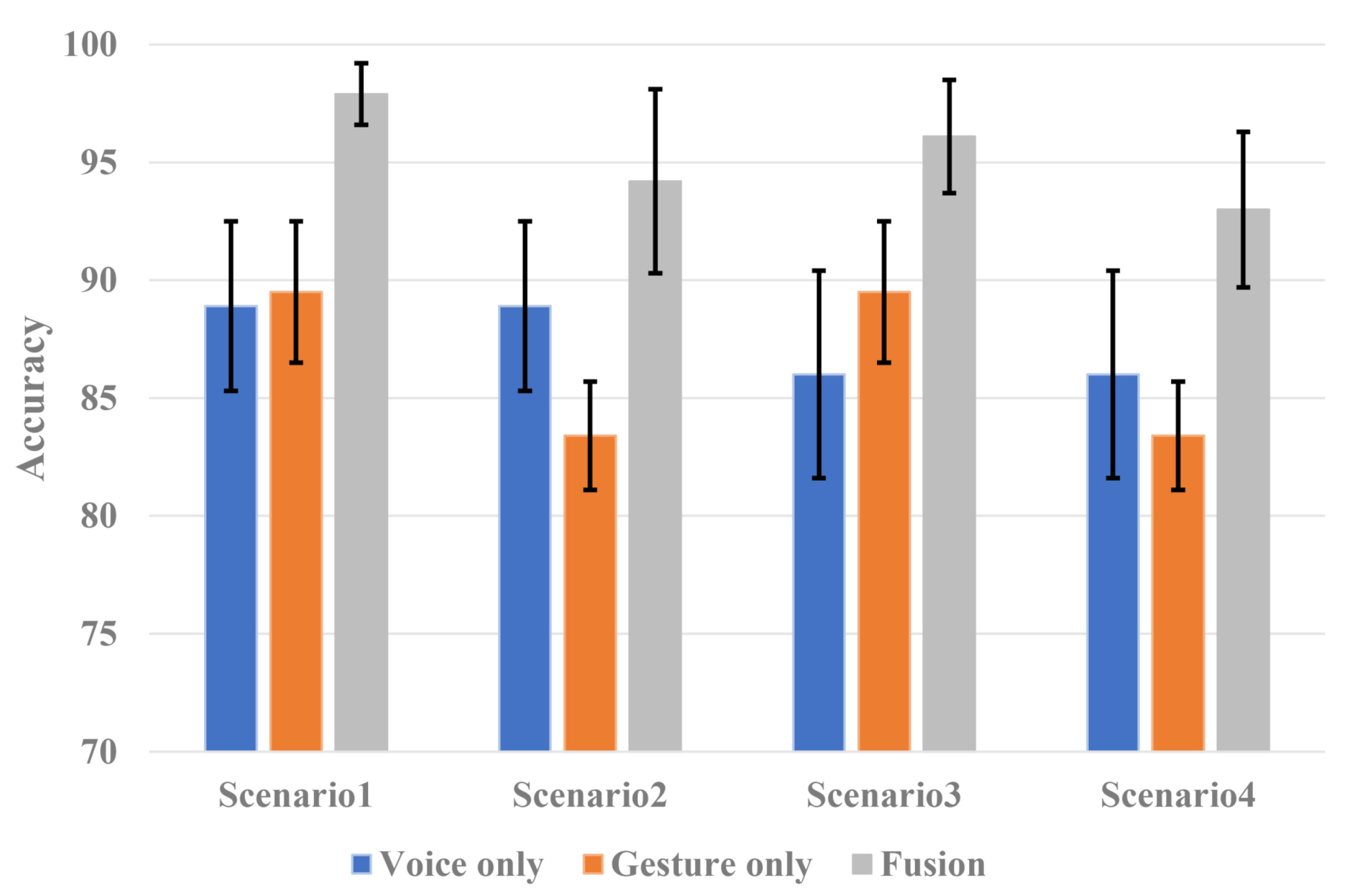
The HVI system for in-vehicle environments monitors human information based on various sensors without interfering with driving. However, it is difficult to apply a camera sensor to in-vehicle environments because of its high computational load, privacy issues, and vulnerability to dark environments. A depth sensor has the disadvantage of being vulnerable to bright light. Voice and radar sensors have the advantage of being robust in illuminated environments, and their computational complexity is smaller than that of vision-based sensors. However, if each sensor is used alone, it is vulnerable to noisy and cluttered environments. Therefore, the proposed HVI system provides robust recognition regardless of the illumination, noise, and clutter environment by fusion of voice and radar sensors, and it shows improved performance in a limited environment. CNNs can learn filters, extract features by themselves, and perform well. However, owing to the massive computation of CLs and the large memory requirement of FCLs, there is a limit to their application in embedded systems such as vehicles. Therefore, we applied BCNN algorithms using binarized inputs and weights to significantly reduce the large computational workload and memory requirements. As a result of the performance evaluation in the vehicle, a single voice sensor system showed 88.8% accuracy in a noisy environment. A single radar sensor system showed 87.4% accuracy in a cluttered environment. However, the proposed system showed a recognition accuracy of 96.4%, with a 7.6% improvement compared to the single voice sensor system and a 9% improvement compared to the single radar sensor system.
In future work, we will study a system that can more accurately classify a driver’s command by fusing voice sensors and FMCW radar sensors that can extract distance and angle information, as well as Doppler frequency. Using the FMCW radar instead of the CW radar, more information can be obtained, but the computational complexity for radar signal processing and BCNN increases. Therefore, we will study a lighter and improved signal processing algorithm and BCNN architecture. In addition, only the noise in the vehicle was considered as the interference signal of the voice sensor. In a practical driving environment, there may be two or more passengers. One can interfere with the gesture by movement, and the other can interfere with the voice by speaking. In this case, the recognition accuracy may be degraded. Nevertheless, the proposed system is expected to show better performance than a single sensor system because two different sensors complement each other. In future work, we will define additional scenarios with two or more passengers and verify the system. In addition, by applying a method of spotting voice or gesture commands, we will implement a real-time embedded system.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}