
Data Clustering Using Moth-Flame Optimization Algorithm

 , ,
, ,  , and
, and 
Abstract
:1. Introduction
- MFO based approach for data clustering is presented.
- The proposed approach is evaluated using 12 machine learning benchmark datasets.
- The quality of the solutions produced by the proposed approach is compared against five well-known algorithms.
- Three statistical tests have been performed to measure the quality of the proposed approach statistically.
- Based on experimental values, statistical values, and convergence curves, the efficacy of the proposed approach is justified.
2. Basic Concepts
2.1. Clustering
- 1.
- 2.
- u, v = 1 …K;
- 3.
2.2. Moth Flame Optimization (MFO)
3. Moth Flame Optimization for Data Clustering
3.1. The Procedure
- Step1
- Initialization: Populate the position of moths M randomly with P candidate solutions, i.e., M = . Each candidate solution includes K centres of dimension D.
- Step2
- Moths Fitness Computation: Compute the fitness value of each moth initialized in step 1 using (2) and store it in a column vector FM = .
- Step3
- Flames Generation: Store the moths fitness values column vector FM in sorted form in flames fitness column vector FF = . Generate the flames , by placing the individual moth corresponding to their fitness value in FF respectively.
- Step4
- Update Moths Position: Each Moth’s positions is updated using the flame and logarithmic spiral function.
- Step5
- Update Flames: Flames and their corresponding fitness are updated by taking top P positions from previous flames and updated moth position.
- Step6
- Test Termination Condition: If the termination condition is satisfied, the algorithm terminates. Otherwise, go to Step 4 for the next iteration.
| Algorithm 1 MFO based Clustering Algorithm. |
Input:
Output:
Begin
End |
3.2. Analysis of Time Complexity
4. Experimental Setup
- Population size = 50
- Maximum iterations = 1000
- Independent runs = 20
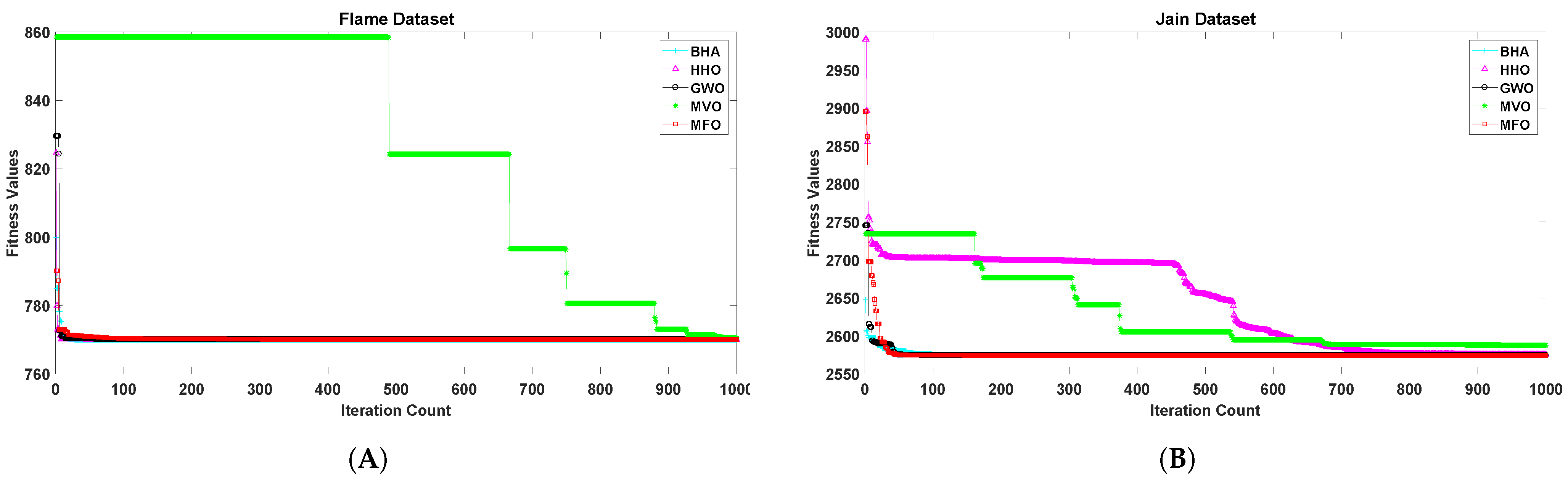
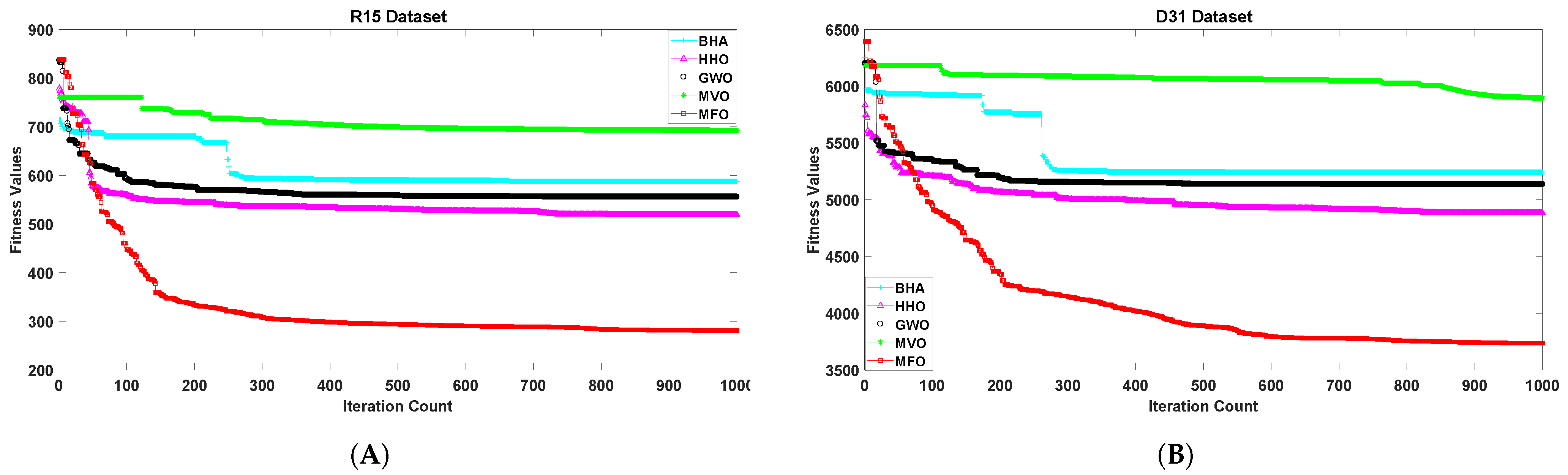
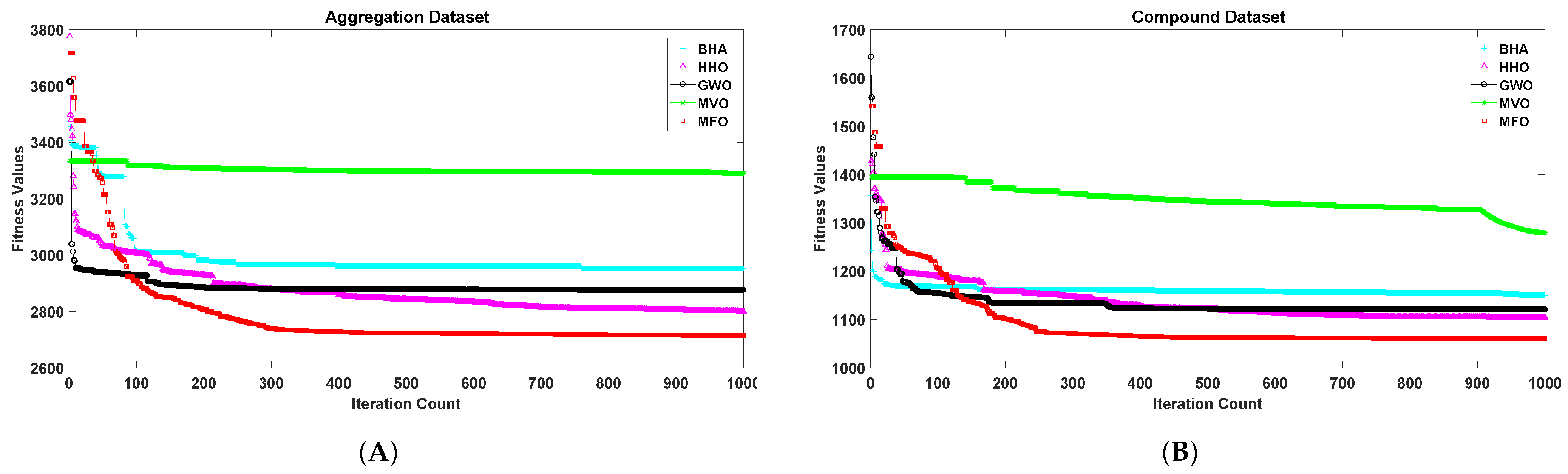
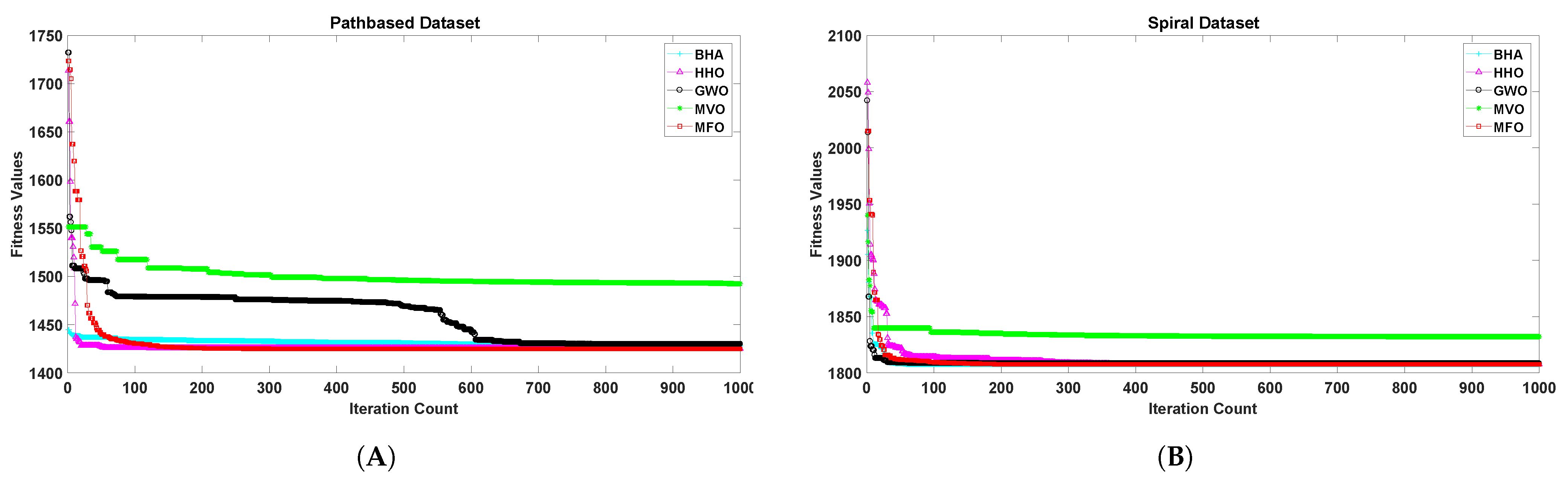
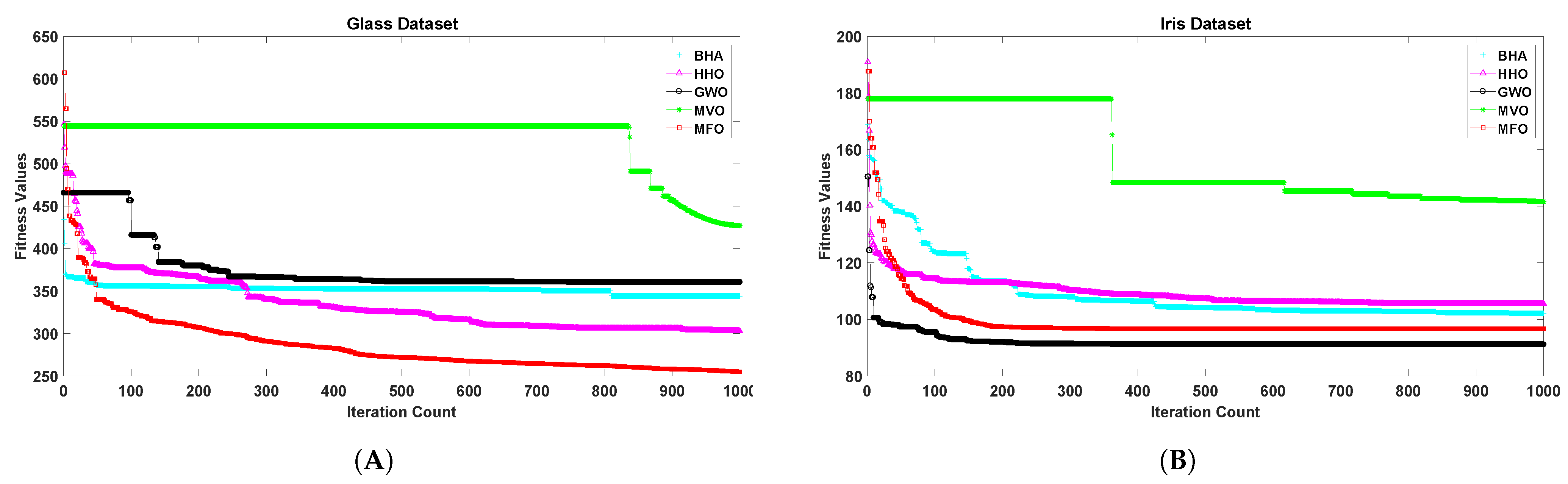
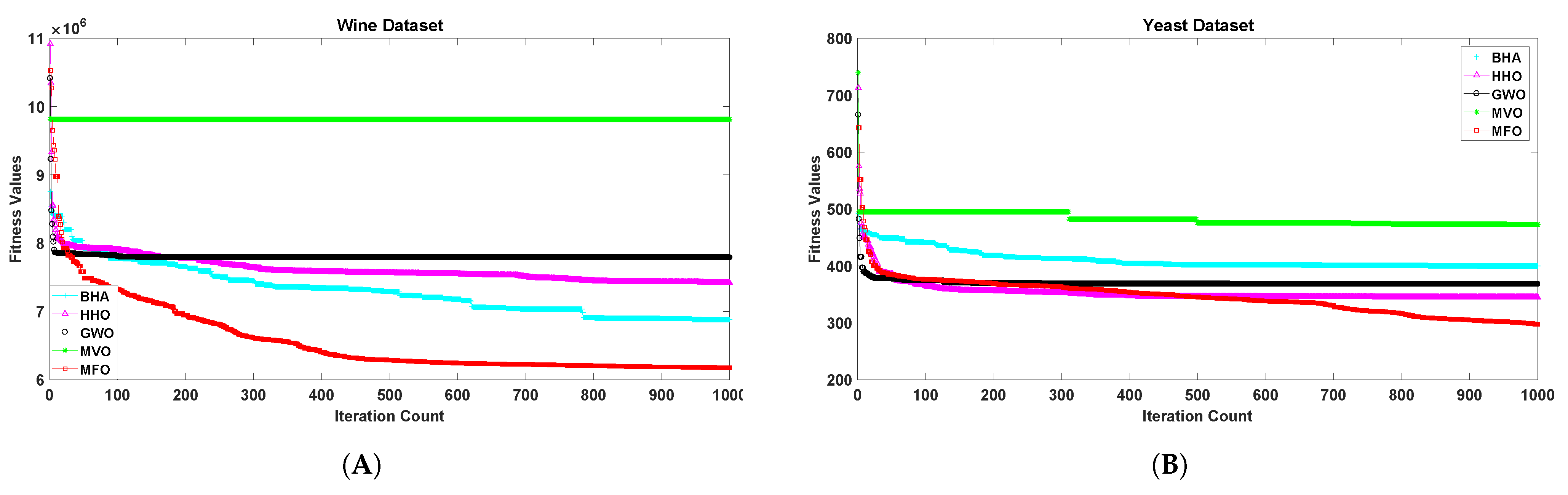
5. Results Analysis
6. Discussion
7. Conclusions and Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tan, P.N. Introduction to Data Mining; Pearson Education India: New Delhi, India, 2018. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Hu, G.; Zhou, S.; Guan, J.; Hu, X. Towards effective document clustering: A constrained K-means based approach. Inf. Process. Manag. 2008, 44, 1397–1409. [Google Scholar] [CrossRef]
- Li, Y.; Chung, S.M.; Holt, J.D. Text document clustering based on frequent word meaning sequences. Data Knowl. Eng. 2008, 64, 381–404. [Google Scholar] [CrossRef]
- Halberstadt, W.; Douglas, T.S. Fuzzy clustering to detect tuberculous meningitis-associated hyperdensity in CT images. Comput. Biol. Med. 2008, 38, 165–170. [Google Scholar] [CrossRef]
- Webb, A.R. Statistical Pattern Recognition; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Zhou, H.; Liu, Y. Accurate integration of multi-view range images using k-means clustering. Pattern Recognit. 2008, 41, 152–175. [Google Scholar] [CrossRef]
- Shi, Y.; Otto, C.; Jain, A.K. Face clustering: Representation and pairwise constraints. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1626–1640. [Google Scholar] [CrossRef] [Green Version]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, present, and future of face recognition: A review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Jacques, S. Multi-Block Color-Binarized Statistical Images for Single-Sample Face Recognition. Sensors 2021, 21, 728. [Google Scholar] [CrossRef] [PubMed]
- Arikumar, K.; Natarajan, V.; Satapathy, S.C. EELTM: An Energy Efficient LifeTime Maximization Approach for WSN by PSO and Fuzzy-Based Unequal Clustering. Arab. J. Sci. Eng. 2020, 45, 10245–10260. [Google Scholar] [CrossRef]
- Nanda, S.J.; Panda, G. A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm Evol. Comput. 2014, 16, 1–18. [Google Scholar] [CrossRef]
- Aljarah, I.; Mafarja, M.; Heidari, A.A.; Faris, H.; Mirjalili, S. Clustering analysis using a novel locality-informed grey wolf-inspired clustering approach. Knowl. Inf. Syst. 2020, 62, 507–539. [Google Scholar] [CrossRef] [Green Version]
- Kushwaha, N.; Pant, M.; Kant, S.; Jain, V.K. Magnetic optimization algorithm for data clustering. Pattern Recognit. Lett. 2018, 115, 59–65. [Google Scholar] [CrossRef]
- Singh, T.; Mishra, K.K. Data Clustering Using Environmental Adaptation Method. In International Conference on Hybrid Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 156–164. [Google Scholar]
- Mansalis, S.; Ntoutsi, E.; Pelekis, N.; Theodoridis, Y. An evaluation of data stream clustering algorithms. Stat. Anal. Data Min. ASA Data Sci. J. 2018, 11, 167–187. [Google Scholar] [CrossRef]
- Almasri, A.; Alkhawaldeh, R.S.; Çelebi, E. Clustering-Based EMT Model for Predicting Student Performance. Arab. J. Sci. Eng. 2020, 45, 10067–10078. [Google Scholar] [CrossRef]
- Singh, T.; Mishra, K.K.; Ranvijay. A variant of EAM to uncover community structure in complex networks. Int. J. Bio-Inspired Comput. 2020, 16, 102–110. [Google Scholar] [CrossRef]
- Hatamlou, A. Black hole: A new heuristic optimization approach for data clustering. Inf. Sci. 2013, 222, 175–184. [Google Scholar] [CrossRef]
- Saida, I.B.; Nadjet, K.; Omar, B. A new algorithm for data clustering based on cuckoo search optimization. In Genetic and Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2014; pp. 55–64. [Google Scholar]
- Esmin, A.A.; Coelho, R.A.; Matwin, S. A review on particle swarm optimization algorithm and its variants to clustering high-dimensional data. Artif. Intell. Rev. 2015, 44, 23–45. [Google Scholar] [CrossRef]
- Han, X.; Quan, L.; Xiong, X.; Almeter, M.; Xiang, J.; Lan, Y. A novel data clustering algorithm based on modified gravitational search algorithm. Eng. Appl. Artif. Intell. 2017, 61, 1–7. [Google Scholar] [CrossRef]
- Yang, D.; Li, G.; Cheng, G. On the efficiency of chaos optimization algorithms for global optimization. Chaos Solitons Fractals 2007, 34, 1366–1375. [Google Scholar] [CrossRef]
- Tavazoei, M.S.; Haeri, M. Comparison of different one-dimensional maps as chaotic search pattern in chaos optimization algorithms. Appl. Math. Comput. 2007, 187, 1076–1085. [Google Scholar] [CrossRef]
- Chuang, L.Y.; Hsiao, C.J.; Yang, C.H. Chaotic particle swarm optimization for data clustering. Expert Syst. Appl. 2011, 38, 14555–14563. [Google Scholar] [CrossRef]
- Wan, M.; Wang, C.; Li, L.; Yang, Y. Chaotic ant swarm approach for data clustering. Appl. Soft Comput. 2012, 12, 2387–2393. [Google Scholar] [CrossRef]
- Singh, T. A chaotic sequence-guided Harris hawks optimizer for data clustering. Neural Comput. Appl. 2020, 32, 17789–17803. [Google Scholar] [CrossRef]
- Singh, T.; Saxena, N. Chaotic sequence and opposition learning guided approach for data clustering. Pattern Anal. Appl. 2021, 1–15. [Google Scholar] [CrossRef]
- Senthilnath, J.; Das, V.; Omkar, S.; Mani, V. Clustering using levy flight cuckoo search. In Proceedings of Seventh International Conference on Bio-Inspired Computing: Theories and Applications (BIC-TA 2012); Springer: Berlin/Heidelberg, Germany, 2013; pp. 65–75. [Google Scholar]
- Abdulwahab, H.A.; Noraziah, A.; Alsewari, A.A.; Salih, S.Q. An Enhanced Version of Black Hole Algorithm via Levy Flight for Optimization and Data Clustering Problems. IEEE Access 2019, 7, 142085–142096. [Google Scholar] [CrossRef]
- Rojas-Morales, N.; Rojas, M.C.R.; Ureta, E.M. A survey and classification of opposition-based metaheuristics. Comput. Ind. Eng. 2017, 110, 424–435. [Google Scholar] [CrossRef]
- Kumar, Y.; Sahoo, G. An Improved Cat Swarm Optimization Algorithm Based on Opposition-Based Learning and Cauchy Operator for Clustering. J. Inf. Process. Syst. 2017, 13, 1000–1013. [Google Scholar]
- Sun, L.; Chen, S.; Xu, J.; Tian, Y. Improved monarch butterfly optimization algorithm based on opposition-based learning and random local perturbation. Complexity 2019, 2019. [Google Scholar] [CrossRef] [Green Version]
- Nasiri, J.; Khiyabani, F.M. A whale optimization algorithm (WOA) approach for clustering. Cogent Math. Stat. 2018, 5, 1483565. [Google Scholar] [CrossRef]
- Jadhav, A.K.N.; Gomathi, N. WGC: Hybridization of exponential grey wolf optimizer with whale optimization for data clustering. Alex. Eng. J. 2018, 57, 1569–1584. [Google Scholar] [CrossRef]
- Alswaitti, M.; Albughdadi, M.; Isa, N.A.M. Variance-based differential evolution algorithm with an optional crossover for data clustering. Appl. Soft Comput. 2019, 80, 1–17. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, H.; Luo, Q.; Abdel-Baset, M. Automatic data clustering using nature-inspired symbiotic organism search algorithm. Knowl. Based Syst. 2019, 163, 546–557. [Google Scholar] [CrossRef]
- Eesa, A.S.; Orman, Z. A new clustering method based on the bio-inspired cuttlefish optimization algorithm. Expert Syst. 2019, 37, e12478. [Google Scholar] [CrossRef]
- Juho, J.; Tomi, R.; Timo, L. Clustering Structure Analysis in Time Series Data with Density-Based Clusterability. IEEE/CAA J. Autom. Sinica 2019, 6, 1332–1343. [Google Scholar]
- Singh, T. A novel data clustering approach based on whale optimization algorithm. Expert Syst. 2020, 38, e12657. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S. Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowl. Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Barbakh, W.A.; Wu, Y.; Fyfe, C. Review of clustering algorithms. In Non-Standard Parameter Adaptation for Exploratory Data Analysis; Springer: Berlin/Heidelberg, Germany, 2009; pp. 7–28. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Hatamlou, A. Multi-verse optimizer: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 2016, 27, 495–513. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris Hawks optimization: Algorithm and applications. Future Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Inman, R.L.; Davenpot, J.M. Approximations of the critical region of the Friedman statistic. Commun. Stat. Theory Methods A 1980, 9, 571–595. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures; Chapman and Hall/CRC: London, UK, 2003. [Google Scholar]
- Holm, S. A simple sequentially rejective multiple test procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | #Instances | #Features | #Classes | Year of Publication | Constructor | Dataset Objective |
|---|---|---|---|---|---|---|
| Flame | 240 | 2 | 2 | 2007 | L. Fu and E. Medico | DNA microarray data |
| Jain | 373 | 2 | 2 | 2005 | A. Jain and M. Law | Consensus function |
| R15 | 600 | 2 | 15 | 2002 | C.J. Veenman et al. | Maximum variance clustering |
| D31 | 3100 | 2 | 31 | 2002 | C.J. Veenman et al. | Maximum variance clustering |
| Aggregation | 788 | 2 | 7 | 2007 | A. Gionis et al. | Aggregating set of clusterings into single one |
| Compound | 399 | 2 | 6 | 1971 | C.T. Zahn | Detecting and describing gestalt clusters |
| Pathbased | 300 | 2 | 3 | 2008 | H. Chang and D.Y. Yeung | Robust path-based spectral clustering |
| Spiral | 312 | 2 | 3 | 2008 | H. Chang and D.Y. Yeung | Robust path-based spectral clustering |
| Name | #Instances | #Features | #Classes | Year of Publication | Constructor | Dataset Objective |
|---|---|---|---|---|---|---|
| Iris | 150 | 4 | 3 | 1936 | R.A. Fisher | To predict class of iris plant |
| Glass | 214 | 9 | 7 | 1987 | B. German | To define the glass in terms of their oxide content |
| Yeast | 1484 | 8 | 10 | 1991 | Kenta Nakai | Predicting the cellular localization sites of proteins |
| Wine | 178 | 13 | 3 | 1988 | M. Forina et al. | Using chemical analysis to determine the origin of wines |
| Dataset | Criteria | MFO | BHA | MVO | HHO | GWO | K-Means |
|---|---|---|---|---|---|---|---|
| Best | 770.09978 | 769.9661518 | 770.4754577 | 769.9927543 | 770.132897 | 778.2235737 | |
| Worst | 790.112976 | 799.8706082 | 883.7379944 | 881.5972455 | 862.9405109 | 882.2962778 | |
| Flame | Mean | 770.312682 | 770.0151324 | 820.6166847 | 773.1715904 | 774.9724323 | 825.0039174 |
| Std | 0.934345 | 0.048796151 | 25.9021804 | 2.197184147 | 3.456581526 | 32.9362996 | |
| Best | 2574.2421 | 2574.241619 | 2587.729382 | 2574.24163 | 2574.596821 | 2649.716145 | |
| Worst | 2895.455517 | 2872.057675 | 3317.743133 | 3243.435326 | 3351.013971 | 3348.696543 | |
| Jain | Mean | 2578.583781 | 2575.625939 | 2783.852076 | 2609.24115 | 2604.748372 | 2898.773998 |
| Std | 5.434534 | 1.216412722 | 152.227768 | 50.99513097 | 46.7066178 | 190.2690739 | |
| Best | 281.130101 | 587.7144266 | 692.2279482 | 518.9798792 | 555.9717927 | 766.9066841 | |
| Worst | 838.491757 | 882.9244343 | 914.6624615 | 912.7932725 | 933.2892028 | 901.9060829 | |
| R15 | Mean | 334.6612324 | 686.732183 | 830.124701 | 680.9312354 | 676.6880723 | 839.092725 |
| Std | 23.321267 | 34.76318932 | 59.42568736 | 54.95447158 | 56.28049001 | 38.30256467 | |
| Best | 3736.584896 | 5242.218307 | 5896.654083 | 4882.938027 | 5136.104753 | 5894.744809 | |
| Worst | 6637.059685 | 6420.08449 | 6606.096812 | 6675.235841 | 6768.271523 | 6706.157344 | |
| D31 | Mean | 4133.73861 | 5658.97124 | 6215.426144 | 5440.848598 | 5600.169046 | 6411.356336 |
| Std | 109.343697 | 121.1404795 | 172.050326 | 210.6444026 | 213.5167965 | 201.3093209 | |
| Best | 2715.302689 | 2953.63615 | 3290.011686 | 2800.375925 | 2876.078555 | 3309.472801 | |
| Worst | 3718.291098 | 3840.375256 | 3939.087978 | 3952.609942 | 3959.489207 | 3995.872968 | |
| Aggregation | Mean | 2789.291202 | 3158.484101 | 3672.354272 | 3080.247639 | 3112.108684 | 3731.786921 |
| Std | 2.53496107 | 89.73403431 | 165.7279226 | 146.4400151 | 159.5026523 | 183.3215657 | |
| Best | 1060.674781 | 1150.328041 | 1279.985246 | 1104.072942 | 1120.609246 | 1361.339487 | |
| Worst | 1541.948974 | 1575.296587 | 1604.72384 | 1664.861515 | 1654.681553 | 1678.228393 | |
| Compound | Mean | 1094.9423 | 1248.529445 | 1423.281446 | 1246.770747 | 1273.87772 | 1493.276887 |
| Std | 13.2355642 | 35.63566319 | 79.71609294 | 66.55744532 | 71.96053364 | 86.13103684 | |
| Best | 1424.899542 | 1427.872936 | 1492.322506 | 1425.176917 | 1429.842419 | 1553.128473 | |
| Worst | 1723.311224 | 1676.139045 | 1901.140798 | 1857.587734 | 1897.234909 | 1893.710862 | |
| Pathbased | Mean | 1430.903602 | 1447.009762 | 1683.491592 | 1497.152685 | 1477.009539 | 1703.054894 |
| Std | 1.6570813 | 7.767526694 | 109.5463984 | 44.80756305 | 38.18020827 | 83.51041425 | |
| Best | 1807.54755 | 1807.510795 | 1832.06375 | 1807.595765 | 1808.281132 | 1896.181926 | |
| Worst | 2015.011175 | 1926.563714 | 2163.452999 | 2094.070221 | 2107.31257 | 2149.720749 | |
| Spiral | Mean | 1810.02073 | 1809.074549 | 1963.454005 | 1820.774656 | 1824.186315 | 1996.155056 |
| Std | 2.168093216 | 0.663986887 | 70.079482 | 10.71573663 | 17.47221358 | 73.8703224 |
| Dataset | Criteria | MFO | BHA | MVO | HHO | GWO | K-Means |
|---|---|---|---|---|---|---|---|
| Best | 254.5686207 | 344.1858768 | 427.2765574 | 302.6048772 | 360.4325397 | 482.794362 | |
| Worst | 607.015981 | 579.4491593 | 657.6790272 | 653.2463069 | 682.8121634 | 668.037993 | |
| Glass | Mean | 286.3971108 | 394.6702904 | 563.6985645 | 375.0501591 | 441.7389961 | 592.7121853 |
| Std | 8.5864965 | 14.97574454 | 37.57437297 | 29.06851845 | 44.90562621 | 50.8694328 | |
| Best | 96.6566922 | 102.1609776 | 141.6280996 | 105.4454434 | 91.06876813 | 155.9380716 | |
| Worst | 187.7141075 | 196.0131392 | 231.7066358 | 220.9449828 | 186.6739426 | 215.8188002 | |
| Iris | Mean | 99.54558066 | 111.6727822 | 177.7656738 | 128.8472893 | 104.0780971 | 189.2905571 |
| Std | 0.04642567 | 2.418165686 | 18.17189821 | 9.40506885 | 9.580750806 | 19.36588562 | |
| Best | 6176852.759 | 6877262.007 | 9811505.667 | 7416306.523 | 7788077.075 | 10335482.5 | |
| Worst | 10526429.84 | 9127679.781 | 11418117.43 | 11754852.48 | 11731706.85 | 11731057.25 | |
| Wine | Mean | 6569678.631 | 7404560.759 | 10694275.29 | 8018085.743 | 8206163.788 | 10942626.63 |
| Std | 103291.3436 | 116859.092 | 411754.8747 | 253702.4043 | 229142.0161 | 351269.2404 | |
| Best | 297.404773 | 399.60419 | 472.7558453 | 344.6453467 | 368.171845 | 528.3446203 | |
| Worst | 642.528356 | 627.3754381 | 772.8618998 | 757.8158265 | 730.7458876 | 753.5334223 | |
| Yeast | Mean | 346.0571754 | 421.1546863 | 577.9115552 | 380.0538835 | 414.0104515 | 634.6032704 |
| Std | 1.325687567 | 4.639095791 | 53.82131146 | 13.81732081 | 35.1425062 | 55.9518587 |
| MFO | BHA | MVO | HHO | GWO | K-Means | |
|---|---|---|---|---|---|---|
| Shape Dataset | 1.375 | 2.5 | 4.875 | 3 | 3.25 | 6 |
| UCI Dataset | 1 | 3 | 5 | 2.75 | 3.25 | 6 |
| Test Name | Statistical Value | p-Value | Hypothesis |
|---|---|---|---|
| Iman-Davenport | 27.69026 | <0.00001 | Rejected |
| Friedman | 31.92857 | <0.00001 | Rejected |
| Test Name | Statistical Value | p-Value | Hypothesis |
|---|---|---|---|
| Iman-Davenport | 24.99996 | <0.00001 | Rejected |
| Friedman | 17.85714 | 0.003131 | Rejected |
| i | Algorithms | Statistical Value | p-Value | /i | Hypothesis |
|---|---|---|---|---|---|
| 5 | K-Means | 4.94433 | <0.00001 | 0.01 | Rejected |
| 4 | MVO | 3.74165 | 0.000183 | 0.0125 | Rejected |
| 3 | GWO | 2.00446 | 0.045027 | 0.0167 | Not Rejected |
| 2 | HHO | 1.73719 | 0.08237 | 0.025 | Not Rejected |
| 1 | BHA | 1.20267 | 0.22913 | 0.05 | Not Rejected |
| i | Algorithms | Statistical Value | p-Value | /i | Hypothesis |
|---|---|---|---|---|---|
| 5 | K-Means | 3.77964 | 0.000157 | 0.01 | Rejected |
| 4 | MVO | 3.02371 | 0.002497 | 0.0125 | Rejected |
| 3 | GWO | 1.70084 | 0.088981 | 0.0167 | Not Rejected |
| 2 | BHA | 1.51186 | 0.130585 | 0.025 | Not Rejected |
| 1 | HHO | 1.32287 | 0.185902 | 0.05 | Not Rejected |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 20.74266809 | 27.59365568 |
| C2 | 25.50196489 | 24.19312765 |
| C3 | 11.57011301 | 8.50840516 |
| C4 | 25.82211536 | 26.17793719 |
| C5 | 27.37201232 | 10.57384902 |
| C6 | 22.08486665 | 5.496210514 |
| C7 | 23.58523731 | 8.888237338 |
| C8 | 22.37594806 | 11.79535569 |
| C9 | 4.83205804 | 26.81225277 |
| C10 | 27.50193421 | 17.28098473 |
| C11 | 15.01686978 | 27.19744896 |
| C12 | 6.353870768 | 16.21830889 |
| C13 | 16.35650612 | 9.106767944 |
| C14 | 9.968810869 | 23.65566343 |
| C15 | 9.153853041 | 14.9149635 |
| C16 | 23.13295757 | 16.05797592 |
| C17 | 8.101549272 | 10.37341231 |
| C18 | 20.47807037 | 18.998876 |
| C19 | 4.965093478 | 20.47535923 |
| C20 | 26.53577694 | 17.86530094 |
| C21 | 26.03937471 | 14.99664186 |
| C22 | 25.47861108 | 6.28135661 |
| C23 | 12.82474767 | 19.1136306 |
| C24 | 15.19151476 | 22.86896706 |
| C25 | 17.80680556 | 12.9098126 |
| C26 | 19.90521872 | 23.37912391 |
| C27 | 17.72660498 | 25.58120323 |
| C28 | 11.71645567 | 14.69915113 |
| C29 | 4.624749983 | 10.32233599 |
| C30 | 27.65379495 | 21.47346273 |
| C31 | 15.7736913 | 21.06158524 |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 4.189631608 | 12.80375838 |
| C2 | 14.09450165 | 5.001272186 |
| C3 | 8.337048918 | 9.062858908 |
| C4 | 4.101436934 | 7.52179159 |
| C5 | 13.97254731 | 14.93207276 |
| C6 | 12.79155218 | 8.05529297 |
| C7 | 8.230614736 | 10.92315677 |
| C8 | 16.41253705 | 9.985521142 |
| C9 | 8.646224944 | 16.24662551 |
| C10 | 11.02097643 | 11.58322744 |
| C11 | 9.551563967 | 12.06489806 |
| C12 | 11.92041063 | 9.712070237 |
| C13 | 9.967326937 | 10.10242535 |
| C14 | 9.645716964 | 7.980621354 |
| C15 | 8.663770617 | 3.772581562 |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 17.03102423 | 15.16831711 |
| C2 | 32.58459725 | 7.124899903 |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 7.206597929 | 24.16493517 |
| C2 | 7.301802789 | 17.84894502 |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 21.42567886 | 22.85728939 |
| C2 | 7.716573617 | 8.772216185 |
| C3 | 32.40196366 | 22.05208852 |
| C4 | 33.15470428 | 8.782254392 |
| C5 | 8.938930788 | 22.91640128 |
| C6 | 14.65416199 | 7.059473024 |
| C7 | 20.82265142 | 7.249080316 |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 18.77723869 | 18.83342046 |
| C2 | 32.64318475 | 16.28179213 |
| C3 | 37.48781021 | 17.33548448 |
| C4 | 10.65769689 | 19.33852537 |
| C5 | 18.67265227 | 9.510696233 |
| C6 | 12.61754072 | 9.616177793 |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 18.82903757 | 30.45142379 |
| C2 | 11.48394236 | 15.73097 |
| C3 | 26.16808047 | 16.08878767 |
| Sr No. | F1 | F2 |
|---|---|---|
| C1 | 22.64471503 | 22.66591643 |
| C2 | 11.172831 | 16.53101706 |
| C3 | 22.08495457 | 10.76472807 |
| Sr No. | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 |
|---|---|---|---|---|---|---|---|---|---|
| C1 | 1.531719668 | 13.06173613 | 3.510979859 | 1.394173337 | 72.84637382 | 0.162494133 | 8.41076102 | 0.025666476 | 0.007523229 |
| C2 | 1.52797292 | 12.80840956 | 0.246399681 | 1.609315064 | 73.83969663 | 0.245748967 | 11.78973298 | 0.462253331 | 0.257117154 |
| C3 | 1.52040748 | 13.35918127 | 0.219397152 | 2.308129393 | 70.18963569 | 6.207528249 | 6.479935975 | 0.152869685 | 0.03330514 |
| C4 | 1.533244544 | 13.8560578 | 3.047071044 | 1.202271091 | 70.60025867 | 3.494911842 | 7.093112782 | 0.306091421 | 0.059719952 |
| C5 | 1.512538966 | 13.84305467 | 2.912665802 | 0.875799374 | 72.00128777 | 0.047687008 | 9.335062282 | 0.08408769 | 0.032376928 |
| C6 | 1.5112 | 14.43925402 | 0.008206 | 2.085299146 | 73.35680382 | 0.457194235 | 8.521081118 | 1.11995061 | 0.005501446 |
| C7 | 1.513266442 | 12.92439889 | 2.072428469 | 0.29 | 72.17879752 | 0.585345503 | 9.906258882 | 0.045962136 | 0.026599321 |
| Sr No. | F1 | F2 | F3 | F4 |
|---|---|---|---|---|
| C1 | 5.01229979 | 3.40333071 | 1.471677299 | 0.235472045 |
| C2 | 6.732802141 | 3.067395056 | 5.623784792 | 2.106790702 |
| C3 | 5.934098654 | 2.797688794 | 4.417324546 | 1.41492155 |
| Sr No. | C1 | C2 | C3 |
|---|---|---|---|
| F1 | 39,986.76285 | 43,544.94447 | 20,030.90947 |
| F2 | 28,115.519 | 15,541.15111 | 13,971.82923 |
| F3 | 45,777.07237 | 35,143.40404 | 31,390.39269 |
| F4 | 28,154.45346 | 21,489.64815 | 33,270.71013 |
| F5 | 21,025.39322 | 25,555.71232 | 19,697.48292 |
| F6 | 16,405.36654 | 46,363.61618 | 27,124.14348 |
| F7 | 16,940.6724 | 35,341.31586 | 22,796.4139 |
| F8 | 37,050.85547 | 18,628.032 | 29,821.29914 |
| F9 | 19,508.26413 | 31,543.63104 | 24,125.44547 |
| F10 | 32,628.78338 | 23,408.28137 | 15,972.93531 |
| F11 | 10,576.51405 | 31,095.9809 | 29,682.27216 |
| F12 | 14,613.20707 | 45,340.52047 | 34,586.81203 |
| F13 | 16,507.21954 | 37,817.65194 | 10,303.62763 |
| Sr No. | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 |
|---|---|---|---|---|---|---|---|---|
| C1 | 0.757337919 | 0.142268616 | 0.827461959 | 0.001450393 | 0.527740868 | 0.771304322 | 0.630304293 | 0.383528402 |
| C2 | 0.781314193 | 0.71779793 | 0.419456881 | 0.377730495 | 0.560817461 | 0.015464843 | 0.511164619 | 0.170202938 |
| C3 | 0.496325357 | 0.491261885 | 0.499102561 | 0.234178288 | 0.500528038 | 0 | 0.504793757 | 0.25014915 |
| C4 | 0.131413932 | 0.34929326 | 0.393064657 | 0.841116915 | 0.704378018 | 0.212988264 | 0.518108105 | 0.444142521 |
| C5 | 0.957824847 | 0.549712612 | 0.456841891 | 0.964282073 | 0.540272009 | 0.393364094 | 0.288371843 | 0.448492104 |
| C6 | 0.147129502 | 0.724553473 | 0.474471507 | 0.175108699 | 0.571043788 | 0.746038613 | 0.534680335 | 0.185879771 |
| C7 | 0.430257651 | 0.47424918 | 0.534401249 | 0.225056925 | 0.500017048 | 0 | 0.478658653 | 0.655020513 |
| C8 | 0.371314927 | 0.342973839 | 0.518372939 | 0.135213842 | 0.521916885 | 0.016021841 | 0.545742633 | 0.275096267 |
| C9 | 0.292646344 | 0.132663231 | 0.270567884 | 0.035813911 | 0.505437432 | 0.366876625 | 0.08142005 | 0.187474957 |
| C10 | 0.411909662 | 0.491403883 | 0.541493781 | 0.519251596 | 0.546134059 | 0.000446405 | 0.4844054 | 0.113730494 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, T.; Saxena, N.; Khurana, M.; Singh, D.; Abdalla, M.; Alshazly, H. Data Clustering Using Moth-Flame Optimization Algorithm. Sensors 2021, 21, 4086. https://doi.org/10.3390/s21124086
Singh T, Saxena N, Khurana M, Singh D, Abdalla M, Alshazly H. Data Clustering Using Moth-Flame Optimization Algorithm. Sensors. 2021; 21(12):4086. https://doi.org/10.3390/s21124086
Chicago/Turabian StyleSingh, Tribhuvan, Nitin Saxena, Manju Khurana, Dilbag Singh, Mohamed Abdalla, and Hammam Alshazly. 2021. "Data Clustering Using Moth-Flame Optimization Algorithm" Sensors 21, no. 12: 4086. https://doi.org/10.3390/s21124086
APA StyleSingh, T., Saxena, N., Khurana, M., Singh, D., Abdalla, M., & Alshazly, H. (2021). Data Clustering Using Moth-Flame Optimization Algorithm. Sensors, 21(12), 4086. https://doi.org/10.3390/s21124086