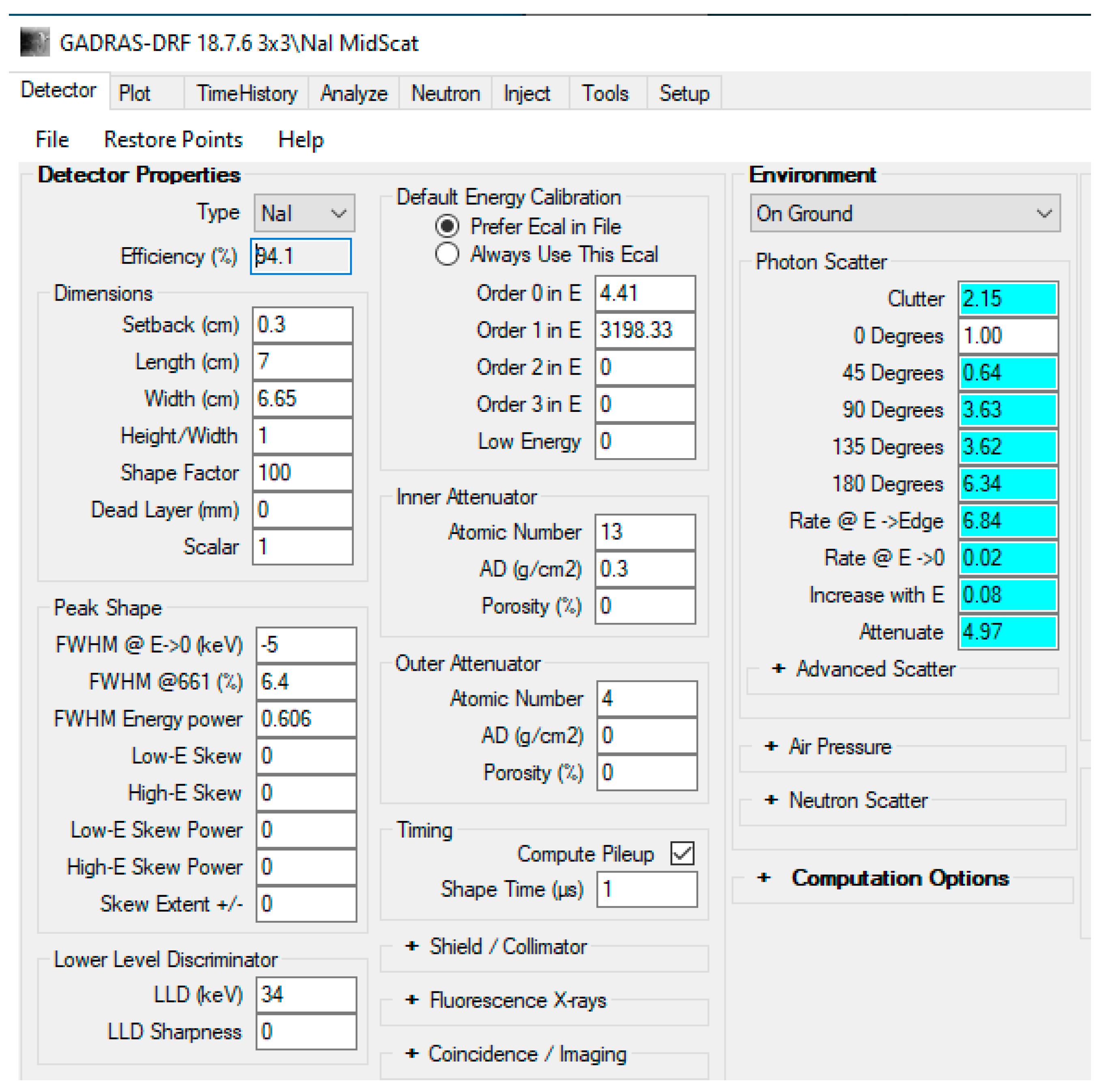
Figure 1.
NaI Detector parameters used in the GADRAS simulation.
Figure 1.
NaI Detector parameters used in the GADRAS simulation.
Figure 2.
Estimated source spectra (foreground-background) using the inject tool of GADRAS with background, using Plot tool alone and using the Inject tool with no background and no Poisson statistics for 238U, 10 uCi source with NaI detector @ 122 cm, H = 56 cm.
Figure 2.
Estimated source spectra (foreground-background) using the inject tool of GADRAS with background, using Plot tool alone and using the Inject tool with no background and no Poisson statistics for 238U, 10 uCi source with NaI detector @ 122 cm, H = 56 cm.
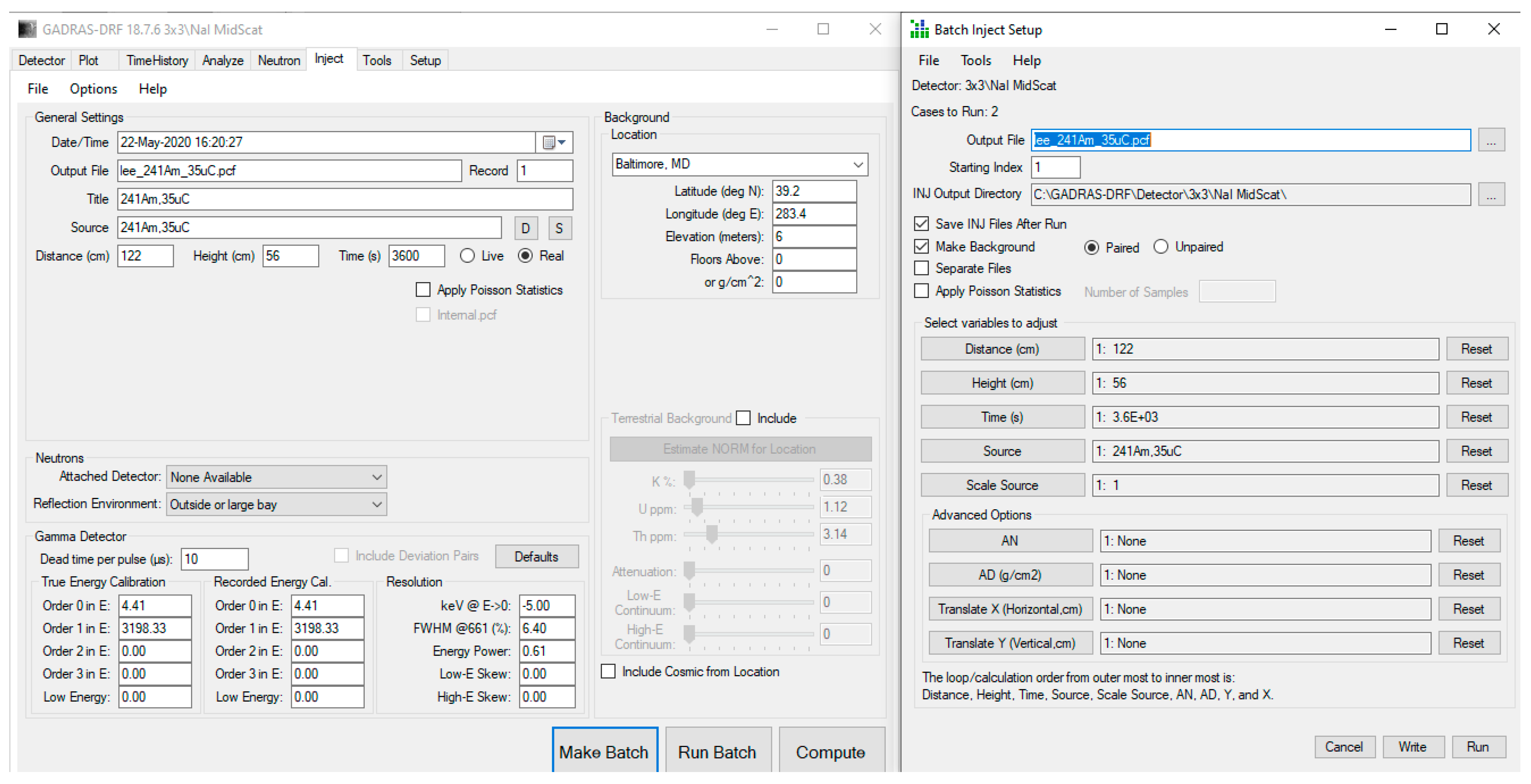
Figure 3.
GADRAS Inject tool settings for generating individual radioactive source-only spectra with NaI detector @ 122 cm, H = 56 cm.
Figure 3.
GADRAS Inject tool settings for generating individual radioactive source-only spectra with NaI detector @ 122 cm, H = 56 cm.
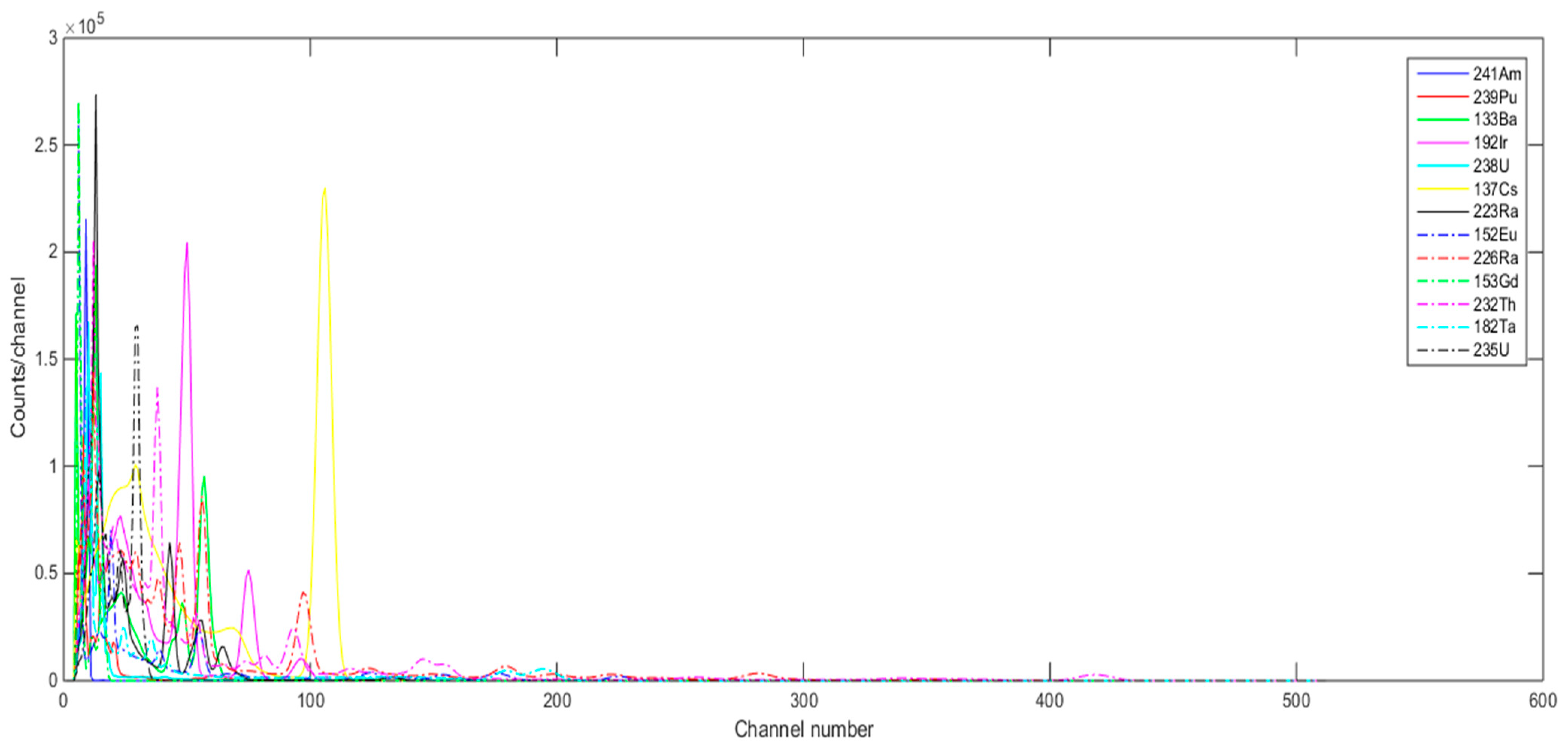
Figure 4.
Gamma ray signatures of the individual radioactive materials generated with GADRAS (NaI detector @ 122 cm, H = 56 cm).
Figure 4.
Gamma ray signatures of the individual radioactive materials generated with GADRAS (NaI detector @ 122 cm, H = 56 cm).
Figure 5.
GADRAS Inject tool settings for generating background spectrum with NaI detector @ 122 cm, H = 56 cm (Baltimore, MD location is used, and terrestrial and cosmic are included).
Figure 5.
GADRAS Inject tool settings for generating background spectrum with NaI detector @ 122 cm, H = 56 cm (Baltimore, MD location is used, and terrestrial and cosmic are included).
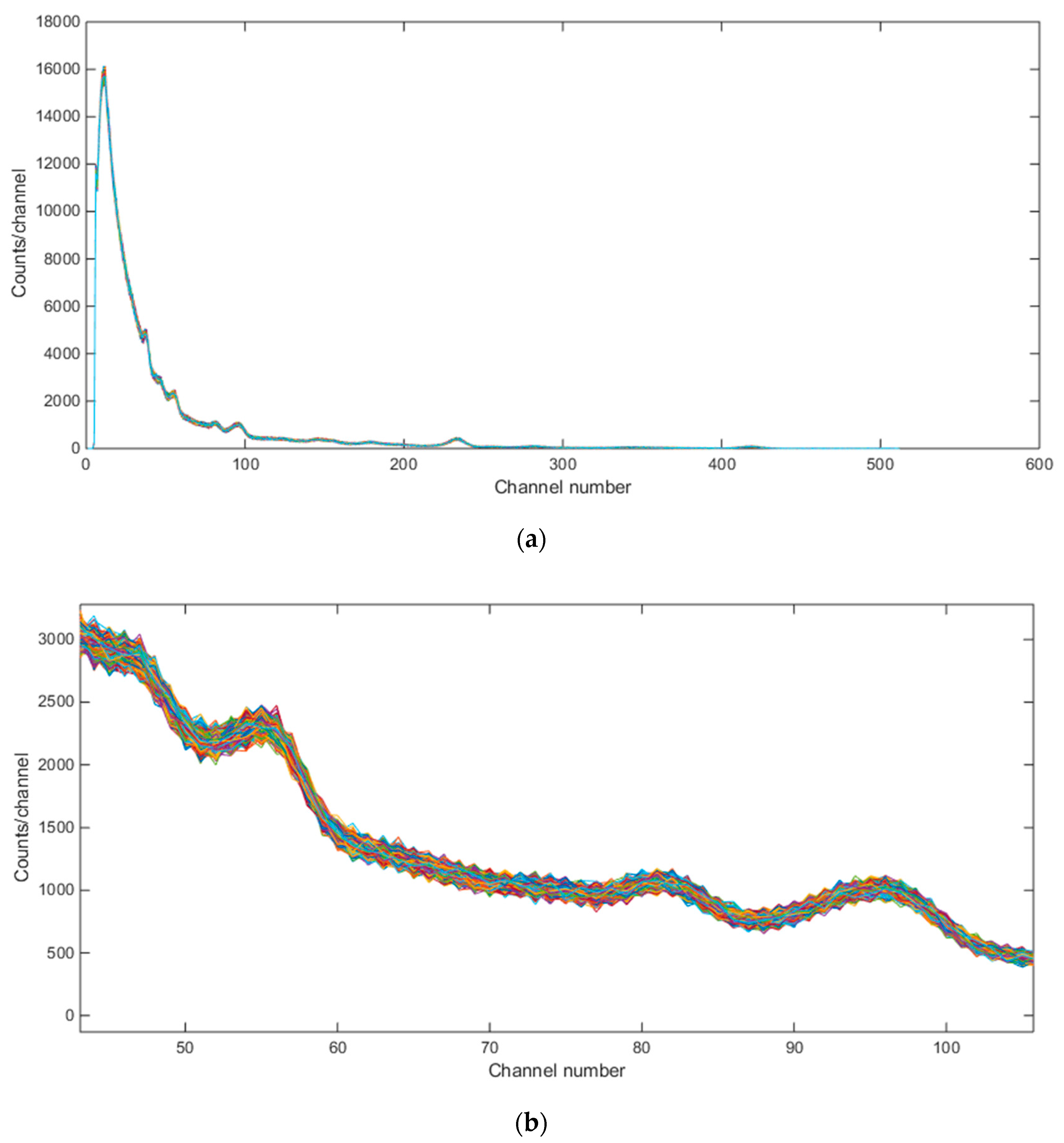
Figure 6.
Emulated background gamma ray spectra (for Baltimore, MD) for 4290 separate simulations. (a) whole spectrum; (b) zoomed version.
Figure 6.
Emulated background gamma ray spectra (for Baltimore, MD) for 4290 separate simulations. (a) whole spectrum; (b) zoomed version.
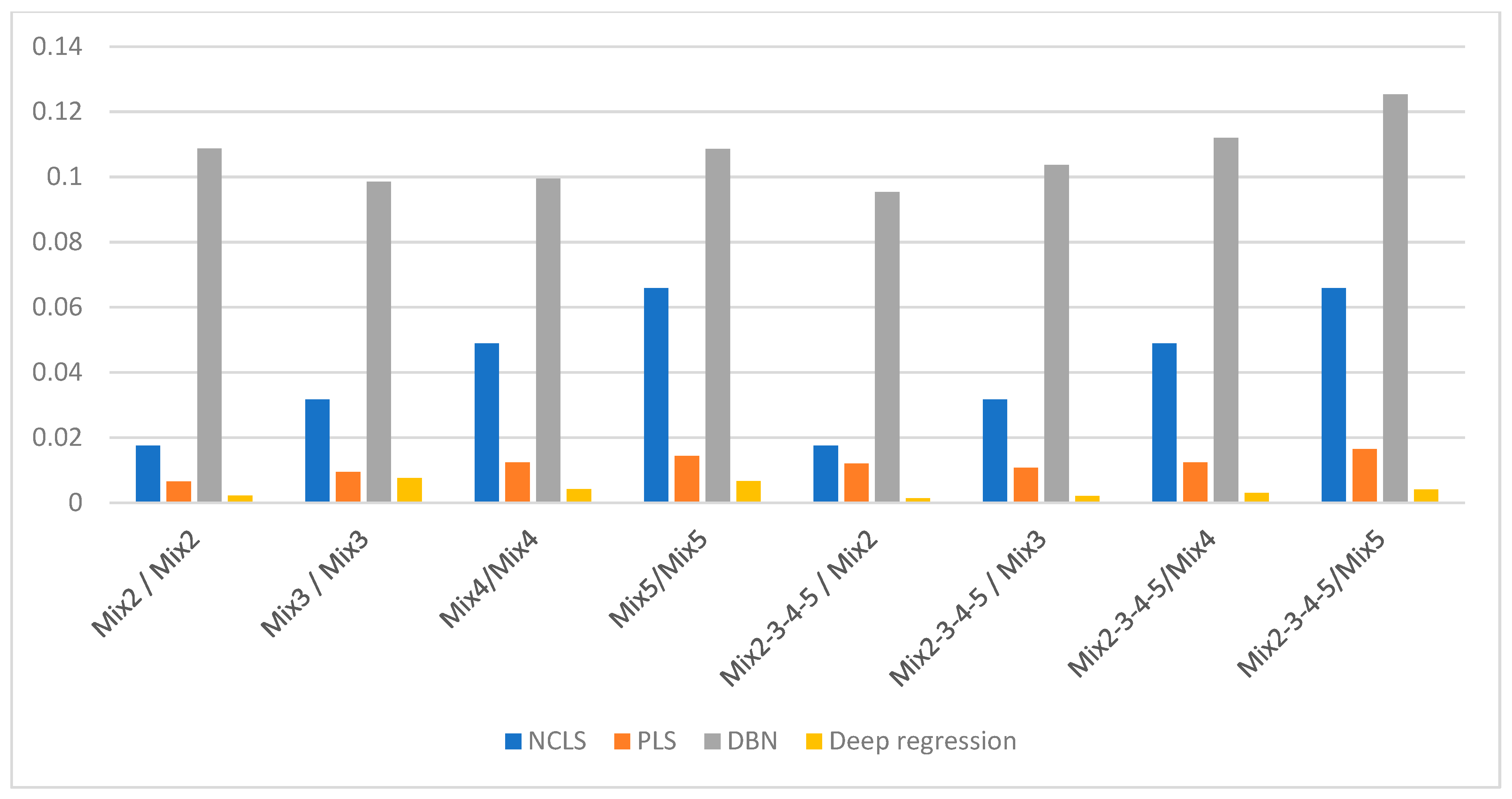
Figure 7.
Average RMSE comparison using bar plots for “high-mixing-rate mixture” dataset with respect to case (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00).
Figure 7.
Average RMSE comparison using bar plots for “high-mixing-rate mixture” dataset with respect to case (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00).
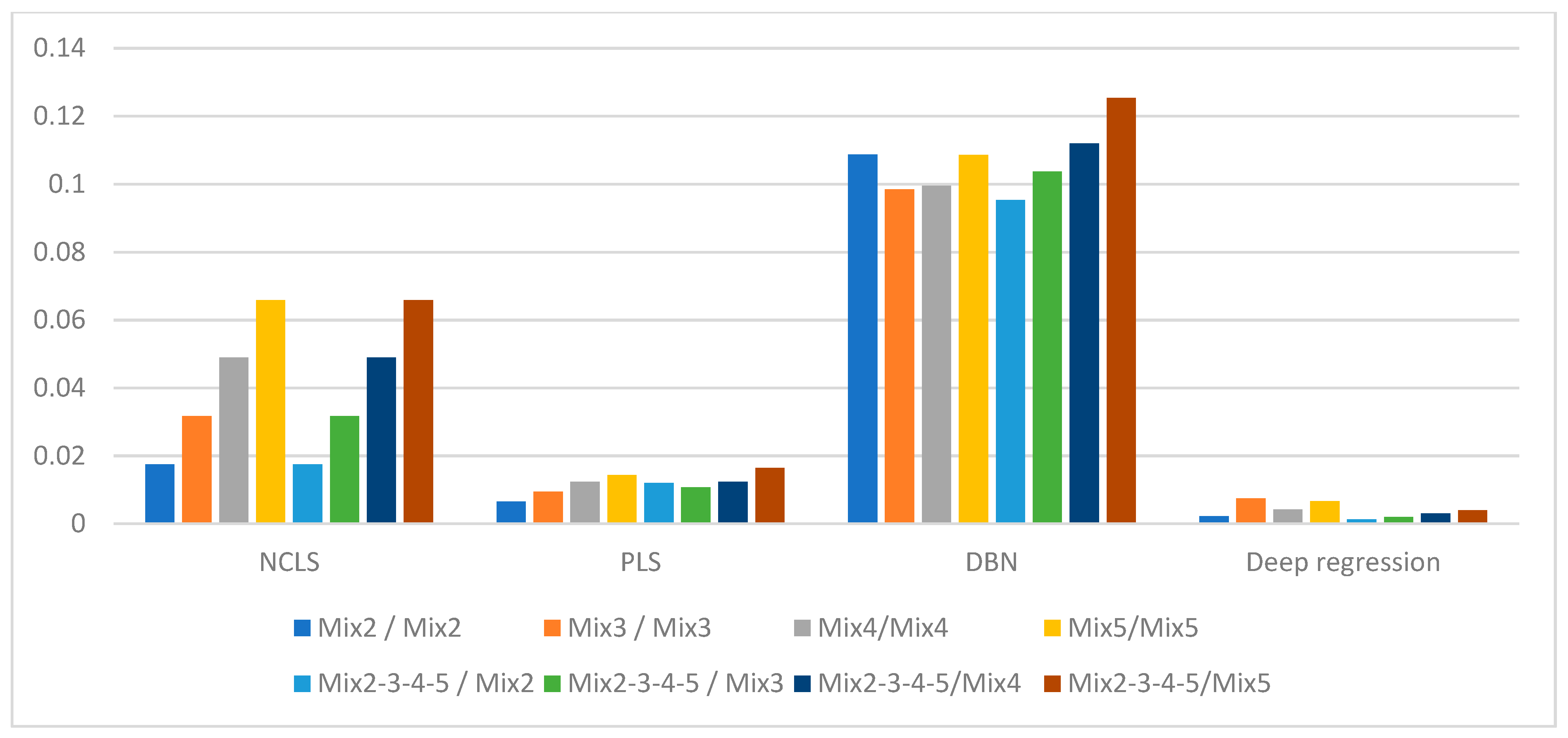
Figure 8.
Average RMSE comparison using bar plots for “high-mixing-rate mixture” dataset with respect to method (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00).
Figure 8.
Average RMSE comparison using bar plots for “high-mixing-rate mixture” dataset with respect to method (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00).
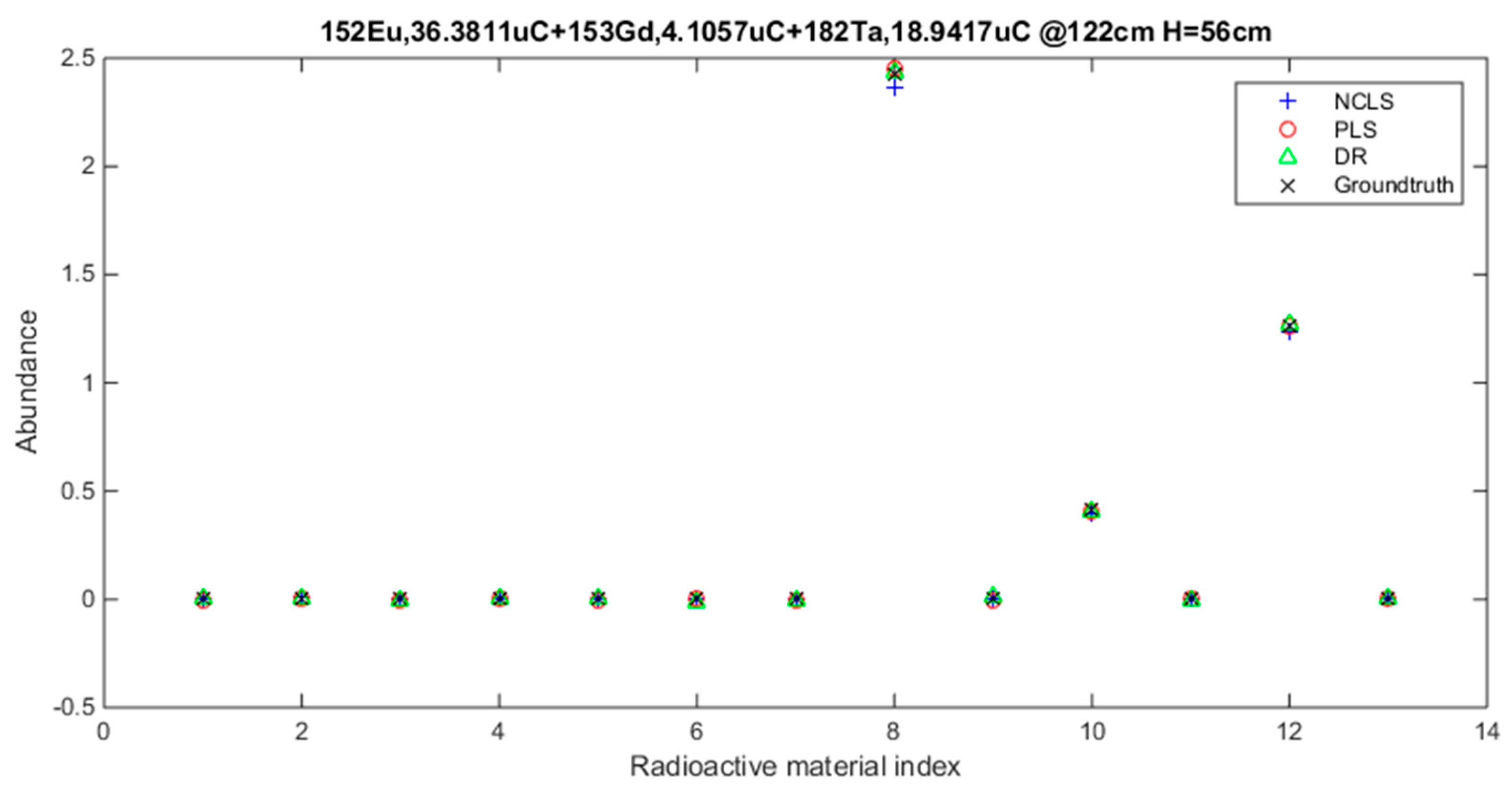
Figure 9.
Three-source mixture mixing-rate estimation example (source = background − subtracted foreground) from high mixing-rate dataset, (RMSE values: NCLS: 0.0181, PLS: 0.0090, DR: 0.0066).
Figure 9.
Three-source mixture mixing-rate estimation example (source = background − subtracted foreground) from high mixing-rate dataset, (RMSE values: NCLS: 0.0181, PLS: 0.0090, DR: 0.0066).
Figure 10.
Average RMSE comparison using bar plots for “low-mixing-rate mixture” dataset with respect to case (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1).
Figure 10.
Average RMSE comparison using bar plots for “low-mixing-rate mixture” dataset with respect to case (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1).
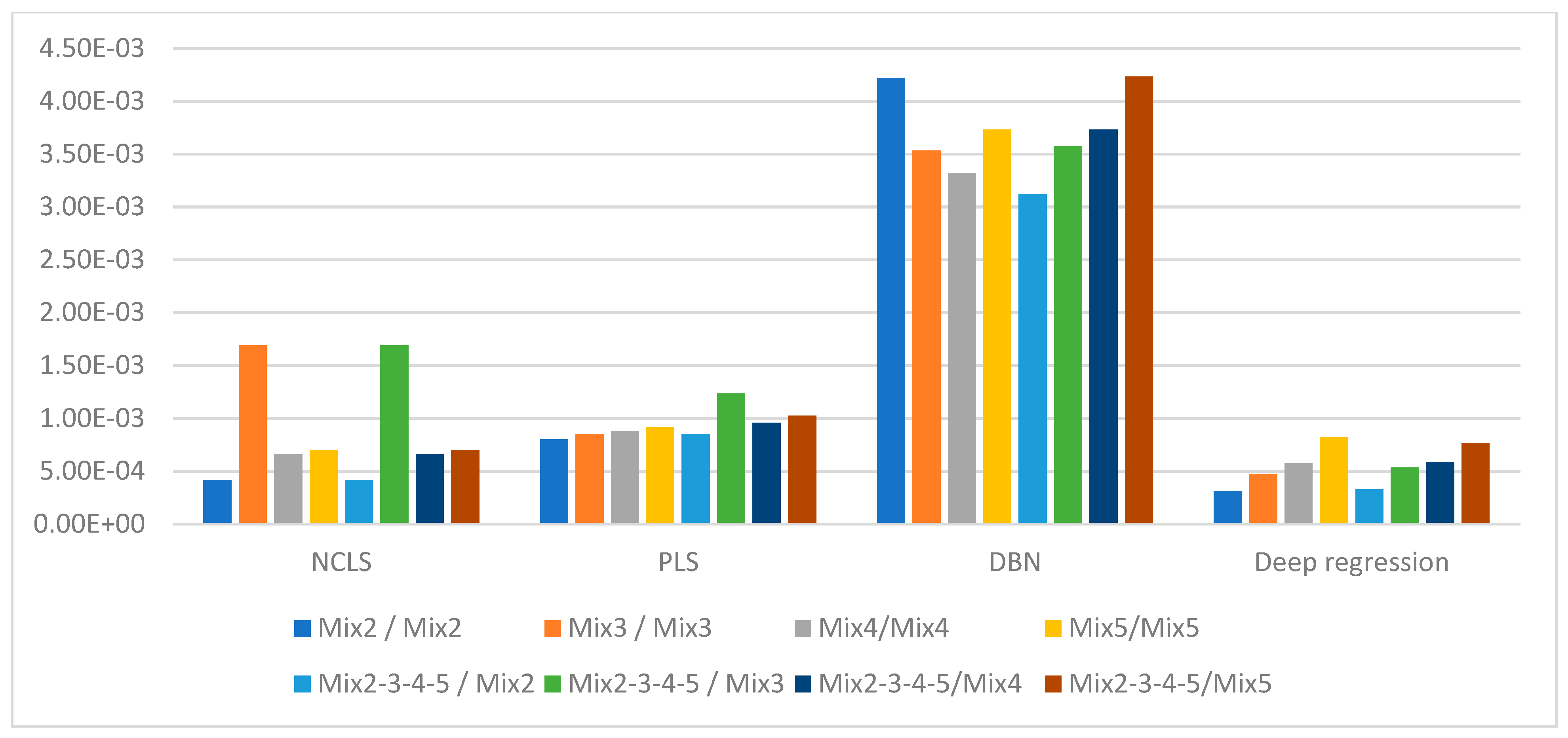
Figure 11.
Average RMSE comparison using bar plots for “low-mixing-rate mixture” dataset with respect to method (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1).
Figure 11.
Average RMSE comparison using bar plots for “low-mixing-rate mixture” dataset with respect to method (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1).
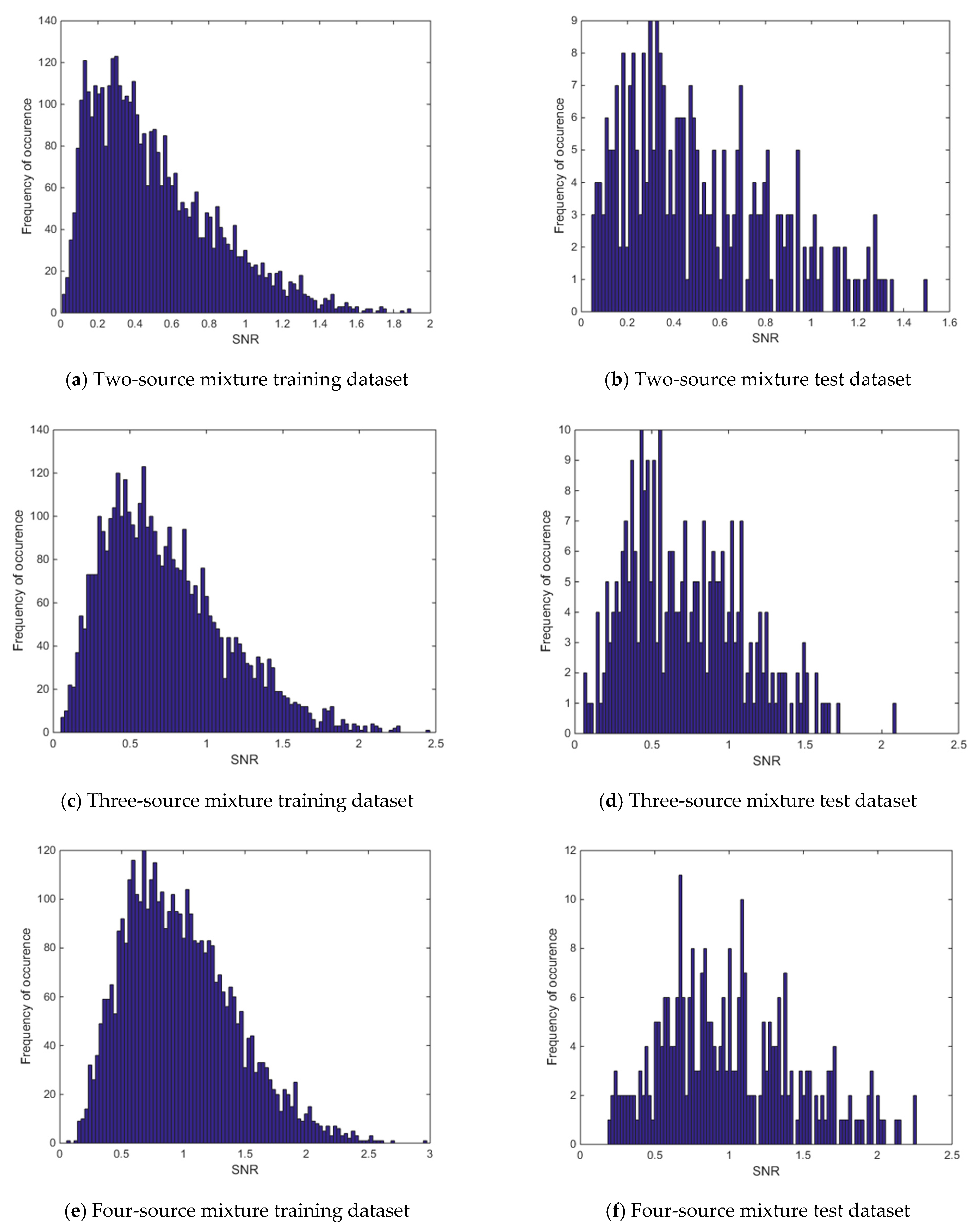
Figure 12.
Histogram of signal-to-background ratios for the low-mixing-rate dataset.
Figure 12.
Histogram of signal-to-background ratios for the low-mixing-rate dataset.
Figure 13.
Three-source mixture example from low-mixing-rate dataset when foreground spectrum is used for mixing-rate estimation (RMSE values: NCLS: 0.0260, PLS: 0.0016, DR: 0.0007).
Figure 13.
Three-source mixture example from low-mixing-rate dataset when foreground spectrum is used for mixing-rate estimation (RMSE values: NCLS: 0.0260, PLS: 0.0016, DR: 0.0007).
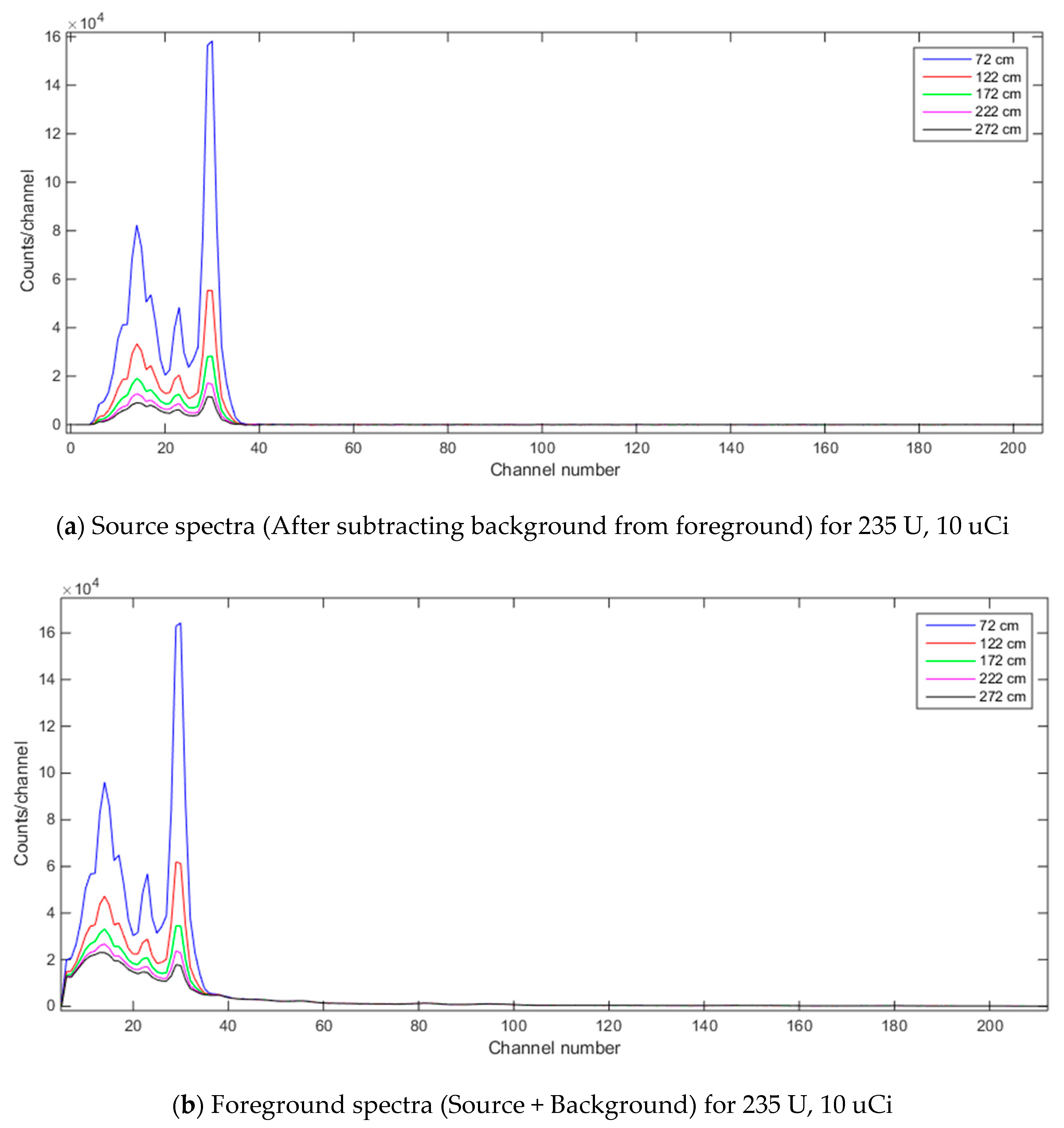
Figure 14.
Foreground and source spectra for 235 U, 10 uCi when source-to-detector distance varies (NaI detector where detector-to-ground distance is set to 56 cm and dwell time for detector is 3600 s).
Figure 14.
Foreground and source spectra for 235 U, 10 uCi when source-to-detector distance varies (NaI detector where detector-to-ground distance is set to 56 cm and dwell time for detector is 3600 s).
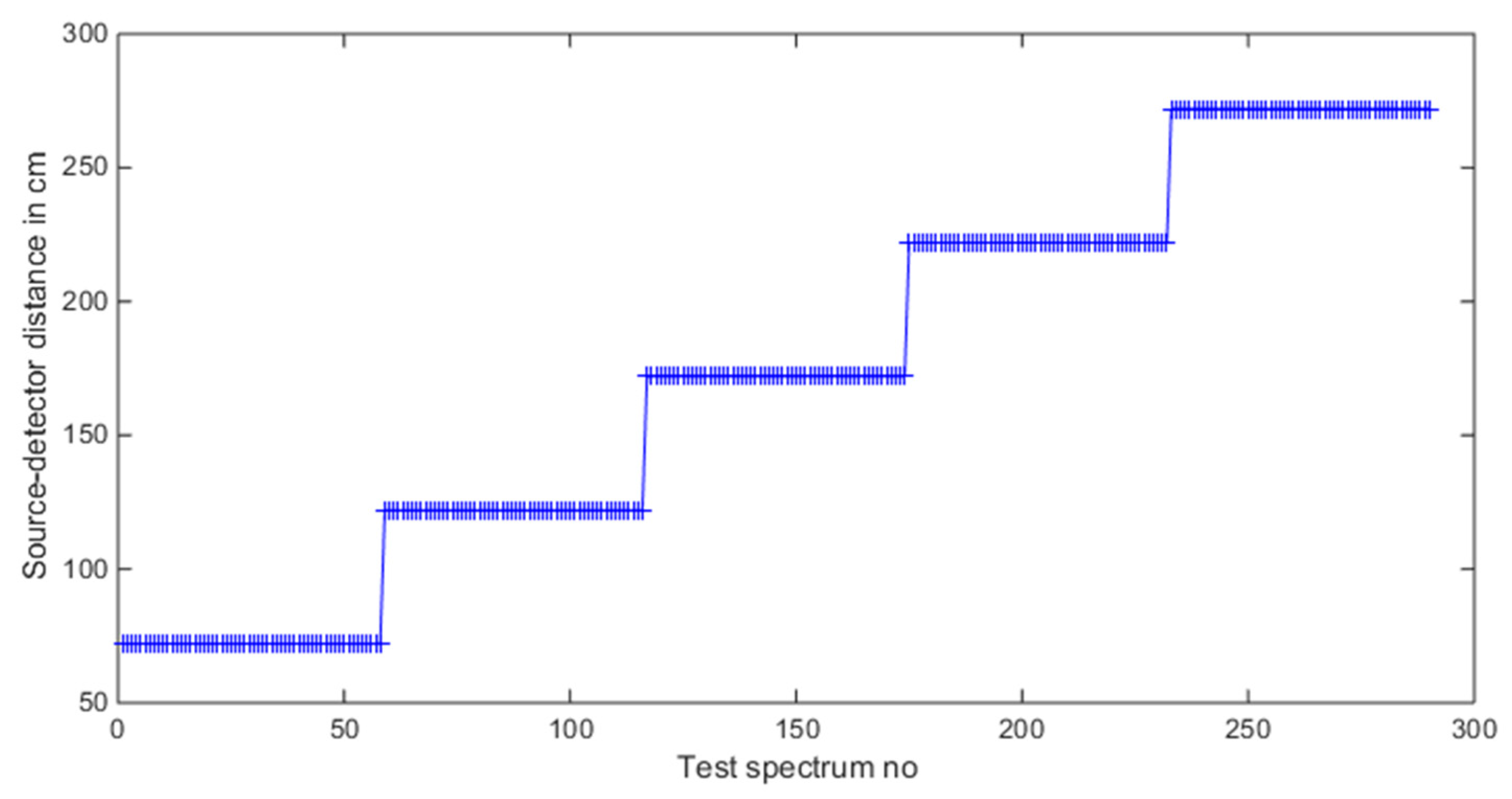
Figure 15.
Source-detector distance values in the test dataset.
Figure 15.
Source-detector distance values in the test dataset.
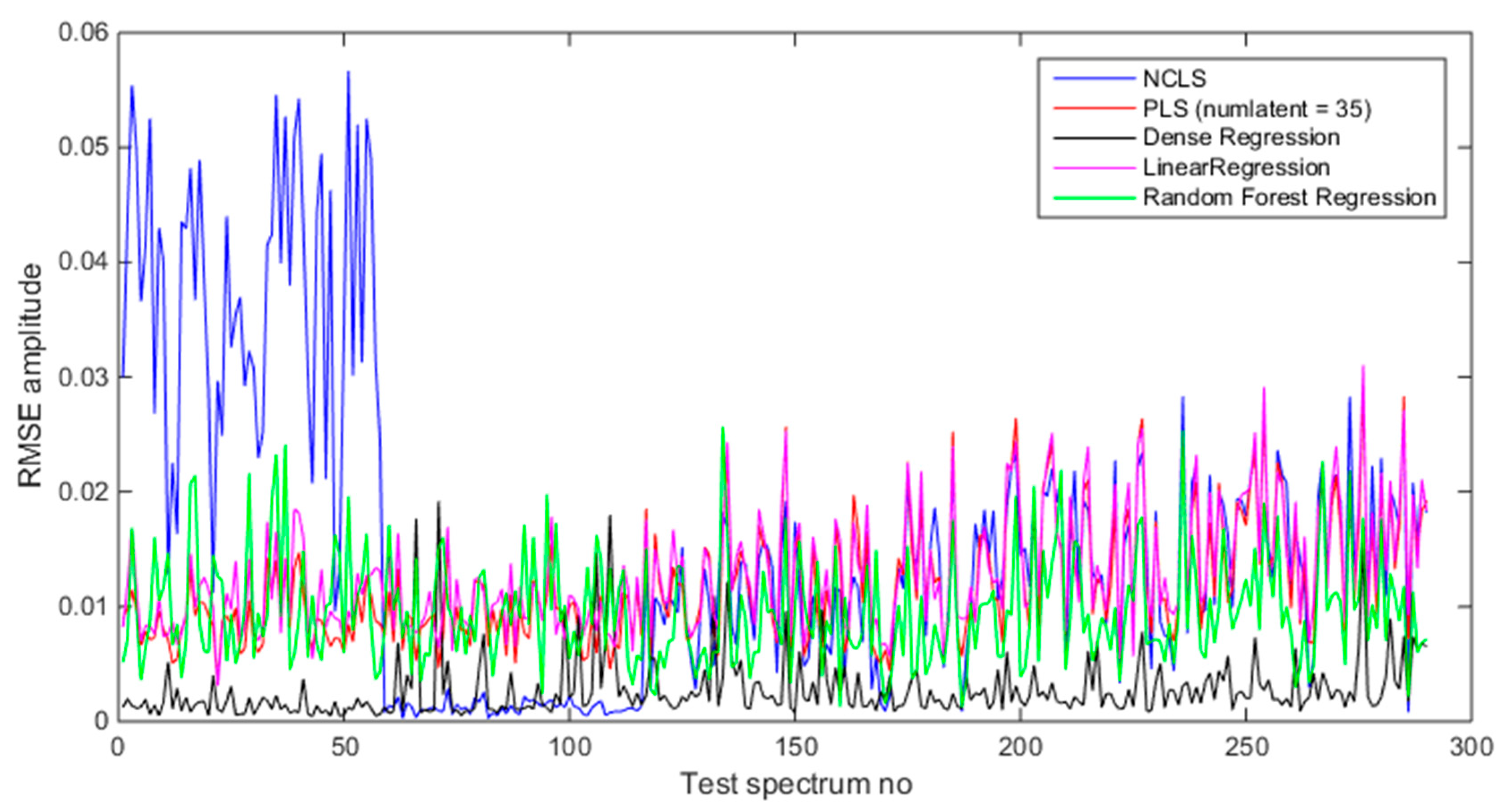
Figure 16.
Mixing ratio estimation results when using source-only spectra (foreground − background).
Figure 16.
Mixing ratio estimation results when using source-only spectra (foreground − background).
Figure 17.
Mixing ratio estimation results when using foreground spectra (source + background).
Figure 17.
Mixing ratio estimation results when using foreground spectra (source + background).
Table 1.
Dense deep learning model for multi-input multi-output regression (DR).
Table 1.
Dense deep learning model for multi-input multi-output regression (DR).
| Model | Layers | Optimizer |
|---|
| Sequential | Layer 1: 800 nodes with ReLu; Layer 2: 256 nodes with ReLu; Layer 3: linear | Loss function: Mean Square Error; Optimizer: Adam |
Table 2.
Radioactive materials and their activity units used in the GADRAS simulation with NaI detector.
Table 2.
Radioactive materials and their activity units used in the GADRAS simulation with NaI detector.
| Index | Radioactive Material | Unit in Curies (Ci) |
|---|
| 1 | 241Am | 35 uCi |
| 2 | 239Pu | 20,000 uCi |
| 3 | 133Ba | 30 uCi |
| 4 | 192Ir | 30 uCi |
| 5 | 238U | 150 uCi |
| 6 | 137Cs | 150 uCi |
| 7 | 223Ra | 35 uCi |
| 8 | 152Eu | 15 uCi |
| 9 | 226Ra | 40 uCi |
| 10 | 153Gd | 10 uCi |
| 11 | 232Th | 30 uCi |
| 12 | 182Ta | 15 uCi |
| 13 | 235U | 30 uCi |
Table 3.
Average RMSE results for “high-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00). Bold numbers indicate best performing algorithm.
Table 3.
Average RMSE results for “high-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00). Bold numbers indicate best performing algorithm.
| Training Data | Test Data | NCLS | PLS | DBN | DR |
|---|
| Two-source mixtures | Two-source mixtures | 0.0175 | 0.0065 | 0.1087 | 0.0022 |
| Three-source mixtures | Three-source mixtures | 0.0317 | 0.0094 | 0.0985 | 0.0075 |
| Four-source mixtures | Four-source mixtures | 0.0489 | 0.0124 | 0.0995 | 0.0042 |
| Five-source mixtures | Five-source mixtures | 0.0659 | 0.0143 | 0.1086 | 0.0066 |
| Merged two-three-four-five-source mixtures | Two-source mixtures | 0.0175 | 0.0120 | 0.0953 | 0.0013 |
| Merged two-three-four-five-source mixtures | Three-source mixtures | 0.0317 | 0.0107 | 0.1037 | 0.0020 |
| Merged two-three-four-five-source mixtures | Four-source mixtures | 0.0489 | 0.0123 | 0.1120 | 0.0030 |
| Merged two-three-four-five-source mixtures | Five-source mixtures | 0.0659 | 0.0164 | 0.1253 | 0.0040 |
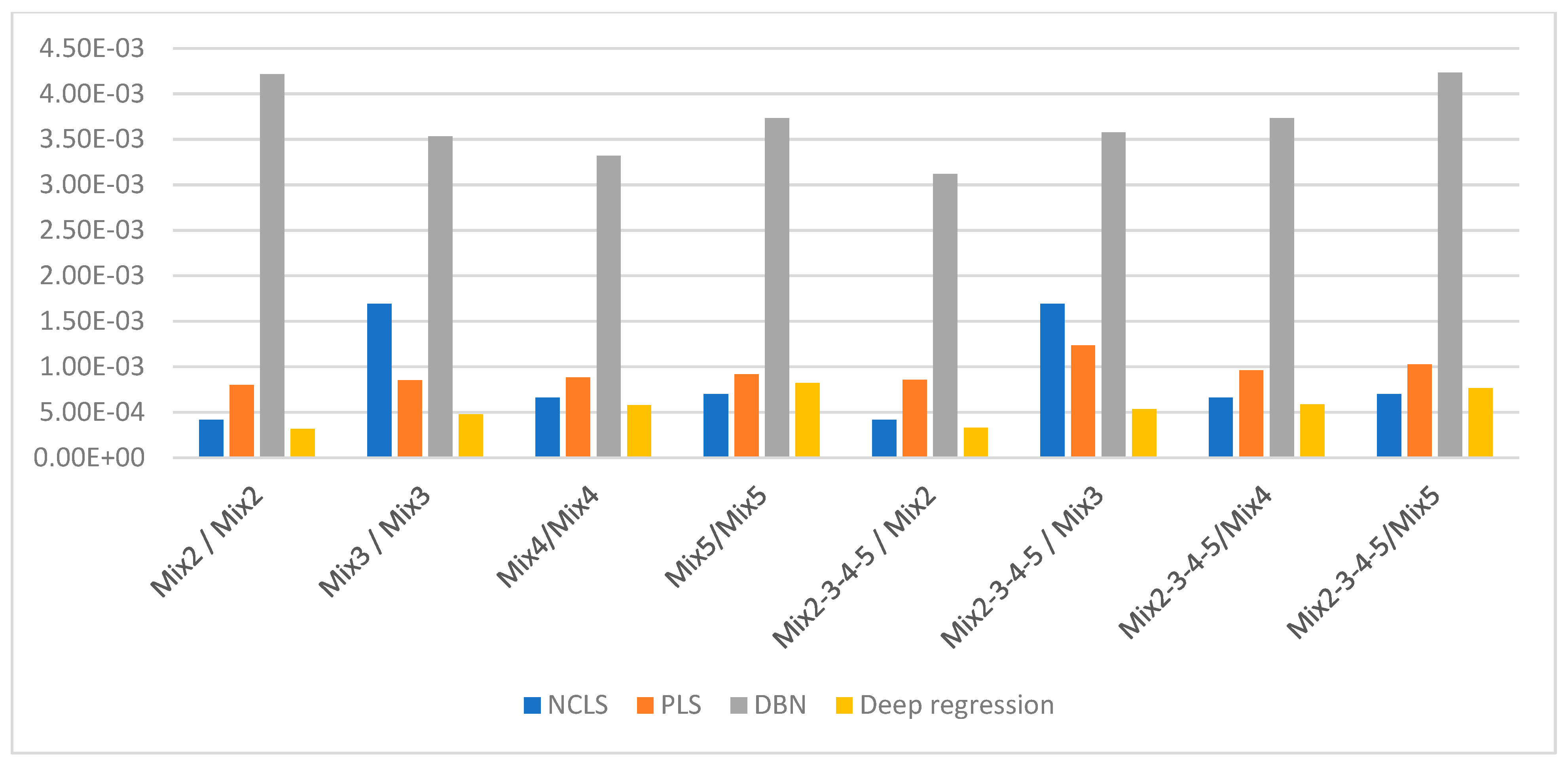
Table 4.
Average RMSE results for “low-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1). Bold numbers indicate best performing algorithm.
Table 4.
Average RMSE results for “low-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1). Bold numbers indicate best performing algorithm.
| Training Data | Test Data | NCLS | PLS | DBN | DR |
|---|
| Two-source mixtures | Two-source mixtures | 0.4138 × 10−3 | 0.7989 × 10−3 | 4.2165 × 10−3 | 0.3140 × 10−3 |
| Three-source mixtures | Three-source mixtures | 1.6890 × 10−3 | 0.8518 × 10−3 | 3.5325 × 10−3 | 0.4743 × 10−3 |
| Four-source mixtures | Four-source mixtures | 0.6578 × 10−3 | 0.8792 × 10−3 | 3.3194 × 10−3 | 0.5770 × 10−3 |
| Five-source mixtures | Five source mixtures | 0.6994 × 10−3 | 0.9175 × 10−3 | 3.731 × 10−3 | 0.8196 × 10−3 |
| Merged two-three-four-five-source mixtures | Two-source mixtures | 0.4137 × 10−3 | 0.8541 × 10−3 | 3.1169 × 10−3 | 0.3293 × 10−3 |
| Merged two-three-four-five-source mixtures | Three-source mixtures | 1.6890 × 10−3 | 1.2341 × 10−3 | 3.5744 × 10−3 | 0.5326 × 10−3 |
| Merged two-three-four-five-source mixtures | Four-source mixtures | 0.6578 × 10−3 | 0.9574 × 10−3 | 3.7319 × 10−3 | 0.5849 × 10−3 |
| Merged two-three-four-five-source mixtures | Five-source mixtures | 0.6994 × 10−3 | 1.0262 × 10−3 | 4.2337 × 10−3 | 0.7652 × 10−3 |
Table 5.
Robustness analysis results for “high-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00). Bold numbers indicate best performing algorithm.
Table 5.
Robustness analysis results for “high-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [0.25 3.00], Min: 0.25 Max: 3.00). Bold numbers indicate best performing algorithm.
| Training Data | Test Data | NCLS | PLS | DR |
|---|
| Two-source mixtures | Three-source mixtures | 0.0317 | 0.0114 | 0.0141 |
| Two-source mixtures | Four-source mixtures | 0.0488 | 0.0208 | 0.0238 |
| Two-source mixtures | Five-source mixtures | 0.0658 | 0.0321 | 0.0320 |
| Three-source mixtures | Two-source mixtures | 0.0175 | 0.0093 | 0.0029 |
| Four-source mixtures | Two-source mixtures | 0.0175 | 0.0151 | 0.0063 |
| Five-source mixtures | Two-source mixtures | 0.0175 | 0.02269 | 0.0145 |
Table 6.
Robustness analysis results for “low-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1). Bold numbers indicate best performing algorithm.
Table 6.
Robustness analysis results for “low-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3 Max: 10−1). Bold numbers indicate best performing algorithm.
| Training Data | Test Data | NCLS | PLS | DR |
|---|
| Two-source mixtures | Three-source mixtures | 0.0016 | 0.0019 | 0.0015 |
| Two-source mixtures | Four-source mixtures | 0.0006 | 0.0008 | 0.0033 |
| Two-source mixtures | Five-source mixtures | 0.0006 | 0.0009 | 0.0049 |
| Three-source mixtures | Two-source mixtures | 0.4137 × 10−3 | 1.4944 × 10−3 | 0.7797 × 10−3 |
| Four-source mixtures | Two-source mixtures | 0.4137 × 10−3 | 0.8189 × 10−3 | 0.5300 × 10−3 |
| Five-source mixtures | Two-source mixtures | 0.4137 × 10−3 | 0.8084 × 10−3 | 0.9360 × 10−3 |
Table 7.
Average RMSE results when foreground spectra are used for mixing-rate estimation in the “low-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3, Max: 10−1). Bold numbers indicate best performing algorithm.
Table 7.
Average RMSE results when foreground spectra are used for mixing-rate estimation in the “low-mixing-rate mixture” dataset (Mixing-rate range used for synthesizing mixtures is: [10−3 10−1], Min: 10−3, Max: 10−1). Bold numbers indicate best performing algorithm.
| Training Data | Test Data | NCLS | PLS | DR |
|---|
| Two-source mixtures | Two-source mixtures | 0.0232 | 0.0006 | 0.0003 |
| Three-source mixtures | Three-source mixtures | 0.0268 | 0.0007 | 0.0004 |
| Four-source mixtures | Four-source mixtures | 0.0247 | 0.0007 | 0.0005 |
| Five-source mixtures | Five-source mixtures | 0.0250 | 0.00074 | 0.00073 |
| Merged two-three-four-five-source mixtures | Two-source mixtures | 0.0232 | 0.0007 | 0.0003 |
| Merged two-three-four-five-source mixtures | Three-source mixtures | 0.0268 | 0.0011 | 0.0005 |
| Merged two-three-four-five-source mixtures | Four-source mixtures | 0.0247 | 0.0009 | 0.0005 |
| Merged two-three-four-five-source mixtures | Five-source mixtures | 0.0250 | 0.0009 | 0.0006 |
Table 8.
Average RMSE values of the test dataset with five methods using Source and Foreground spectra. Bold numbers indicate best performing algorithm.
Table 8.
Average RMSE values of the test dataset with five methods using Source and Foreground spectra. Bold numbers indicate best performing algorithm.
| Spectrum Type Used | NCLS | PLS | DR | LR | RFR |
|---|
| Source | 0.0158 | 0.0119 | 0.0028 | 0.0128 | 0.0097 |
| Foreground | 0.0323 | 0.0115 | 0.0024 | 0.0123 | 0.0092 |























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}