1. Introduction
Nowadays, considerable research contributions have been made toward the evolution of visual Simultaneous Localization and Mapping (SLAM) [
1,
2,
3]. SLAM plays an essential role in robot applications, intelligent cars, and unmanned aerial vehicles. As for robot applications, SLAM helps mobile robots solve two key problems: “Where am I?” and “How am I going?”. SLAM is also helpful for augmented reality and virtual reality applications [
4]. Considering the high cost of laser SLAM, based on the laser range finder, and the limitations of its application scenarios, researchers have begun to focus on low-cost and information-rich visual SLAM in recent years. Among them, visual place recognition of pre-visited areas, widely known as Loop Closure Detection (LCD), constitutes one of the most important SLAM components [
5]. Accurate closed-loop detection technology can eliminate pose drift and reduce cumulative errors to obtain globally consistent trajectories and maps. When working outdoors, GPS can be used to provide global location information [
6]. However, indoors, we need to do something different.
Initially, the researchers used the similarity between images and maps to determine the consistency between image points and map points. However, this method is only suitable for the closed-loop detection of global maps in a small range of environments due to high computational complexity. Hahnel et al. proposed a method based on the odometer to determine whether the camera moved to a previous position by using the geometric relationship of the odometer [
7]. This approach is ideal, but because of the existence of cumulative error, we cannot correctly know whether the robot moved to a certain position before.
The other method is based on appearance, which only carries out loop detection according to the similarity of two images. By detecting the similarity between the current frame image obtained by the robot and the historical key frame image, it can judge whether the robot has passed the current position. Appearance-based methods mainly include local LCD and global LCD. A system based on local appearance searches for the best image match to a set of adjacent images and uses similar comparison techniques [
5]. Milford et al. proposed a sequence-based approach that calculates the best candidate matching positions in each local navigation sequence and then achieves localization by identifying the coherent sequences of these matches [
8]. Another system based on global appearance finds the most similar images in the database in an exhaustive way. For instance, the Bag of Words (BoW) method proposed by Mur-Artal et al. is a global detection system [
9]. In this method, a visual dictionary is constructed by clustering the data composed of the image features of the training set. Then, the image of the current frame is mapped to the visual dictionary and calculate the similarity of the feature description vector between the image of the current frame and the image of the historical frame. However, the limitation of this method is that the period of image feature extraction is several times that of other methods. However, this method is limited by the speed of image feature extraction, and the feature extraction cycle is several times longer than other steps. For low-texture features, Joan P. et al. proposed the LiPo-LCD method based on the combination of lines and points, which adopt the idea of incremental Bag-of-Binary-Words schemes, and build separate BoW models for each feature, and use them to retrieve previously seen images using a late fusion strategy [
10].
In other words, an appearance-based LCD problem can be transformed into an image retrieval task. In this case, the current input image is treated as a query image, while the previous image is treated as a database image [
11]. Therefore, the core factors affecting the performance of the appearance-based LCD method are image feature extraction and candidate frame selection. In most cases, existing methods work well. However, in some complex scenarios, such as changing lighting, dynamic object occlusion, and repetitive environments, these methods still face significant challenges. In this case, we need to consider the repeatability and discriminability of features. Secondly, the traditional BoW framework displaces the spatial information between visual words, resulting in quantization errors [
12]. Sparse feature matching used to be solved with hand-crafted descriptors [
13,
14,
15]. Recently, Convolutional Neural Networks (CNN) has had great success in pattern recognition and computer vision tasks [
16,
17]. Many researchers use the depth features extracted by CNN to improve the LCD algorithm and achieve fine results [
12,
18,
19]. However, the calculation amount of LCD based on CNN is quite enormous.
To solve the above problems, this paper proposes LFM: a lightweight feature matching algorithm based on candidate similar frames. The framework (shown in
Figure 1) includes the following steps:
Object detection of images form key frames based lightweight CNN;
Classify the images based on the salient features of the target detection results;
Classify the new input key frame images by a binary classified tree according to their labels, and then conduct lightweight feature matching for this image and the others from the same category, which could help the robots judge whether they have passed the current position before.
At the same time, considering the problem of computation and precision, we improve an ultra-lightweight CNN network to extract features. Experimental results show that LFM is especially superior in the LCD task. Summarized, our core contributions in this paper are:
Based on the Residual Inverted Block proposed by MobileNetV2 [
20], we designed a Residual Depth-wise Convolution Block (also called fish-scale block)to obtain more abundant depth information with less computation.
We applied the new lightweight CNN (FishScaleNet) to the object detection algorithm, which has a high mAP value while improving the speed and creates a binary classified tree for the key images according to their labels.
We applied the new lightweight CNN to the feature matching algorithm based on depth features, which can efficiently complete the matching task in the similar image categories. Compared with other feature matching algorithms, our lightweight feature matching algorithm has faster matching speed and less mismatching. Moreover, the LCD algorithm based on LFM can still guarantee better accuracy in the case of a high recall rate.
3. Methods
In this section, we introduce the framework of LFM-LCD in detail. These include: a lightweight CNN based on Fish Convolution Block; object detection based on YOLOv4 with our lightweight CNN instead of CSPDarkNet [
46]; a classification tree with a structure that is similar to the BoW dictionary; an improved feature matching network of LOFTR [
45].
3.1. FishScaleNet
Deep separable convolution decomposes the standard convolution process into two operations. The first operator, called depth-wise convolution, uses a single-channel filter to learn the spatial correlation between positions in each channel separately. The second operator is a 1 × 1 convolution, which is used to learn new features by computing linear combinations of all input channels.
Standard convolution takes an input tensor , and applies convolutional kernel to produce an output tensor . Standard convolutional layers have the computational cost: . Depth-wise separable convolutions are a drop-in replacement for standard convolutional layers. Empirically they work almost as well as regular convolutions, but only cost:.
When the size of the convolution kernel is , the computational effort of the deep separable convolution will be reduced by nearly 9 times.
Inspired by MobileNet [
20,
28], a novel convolution block was proposed based on the inverted residual block, which depth-wise convolution is related to each other and transmitted in turn. Its structure is like a fish scale (it can be seen in
Figure 2); therefore, we call it a fish-scale convolution block.
Fish-scale convolution works almost as well as inverted residual convolutions but costs just more than the latter: .
Reference [
47] proposed that the success of FPN is due to its divide-and-conquer solution to the object detection optimization problem, where dilated convolution plays an indispensable role. Dilated convolution mainly solves the problem of data structure loss in the space of standard convolution.
We adopted the Dilated Convolution [
48], which is different from other convolution blocks of different lightweight CNNs; it increases the receptive field without sacrificing the size of the feature map. The receptive field of the dilated convolution can be calculated as:
where
represents the size of the receptive field at the upper layer, K denotes the size of the new dilated convolution kernel, and k denotes the size of the standard convolution kernel; s indicates the stride of the dilated convolution, and r denotes the dilated rate.
As for k = 3, r = 2i, it is easy to get that size of the receptive field of each element in is ; therefore, the receptive field is a square of an exponentially increasing size.
Based on the design of the fish-scale block structure, we further designed a lightweight CNN framework with strong practicability, named FishScaleNet. It follows the design rules of MolieNetv3, as shown in
Table 1.
As shown in
Table 2, we compared the computational complexity of MobileNetV1-v3 and FishScaleNet, and pointwise convolution accounted for most of the computational amount. However, FishScaleNet relatively increases the proportion of deep convolution and obtains richer spatial correlation between features. It is of great help to the downstream work (target detection and feature matching) of our LCD task, and the accurate results are obtained.
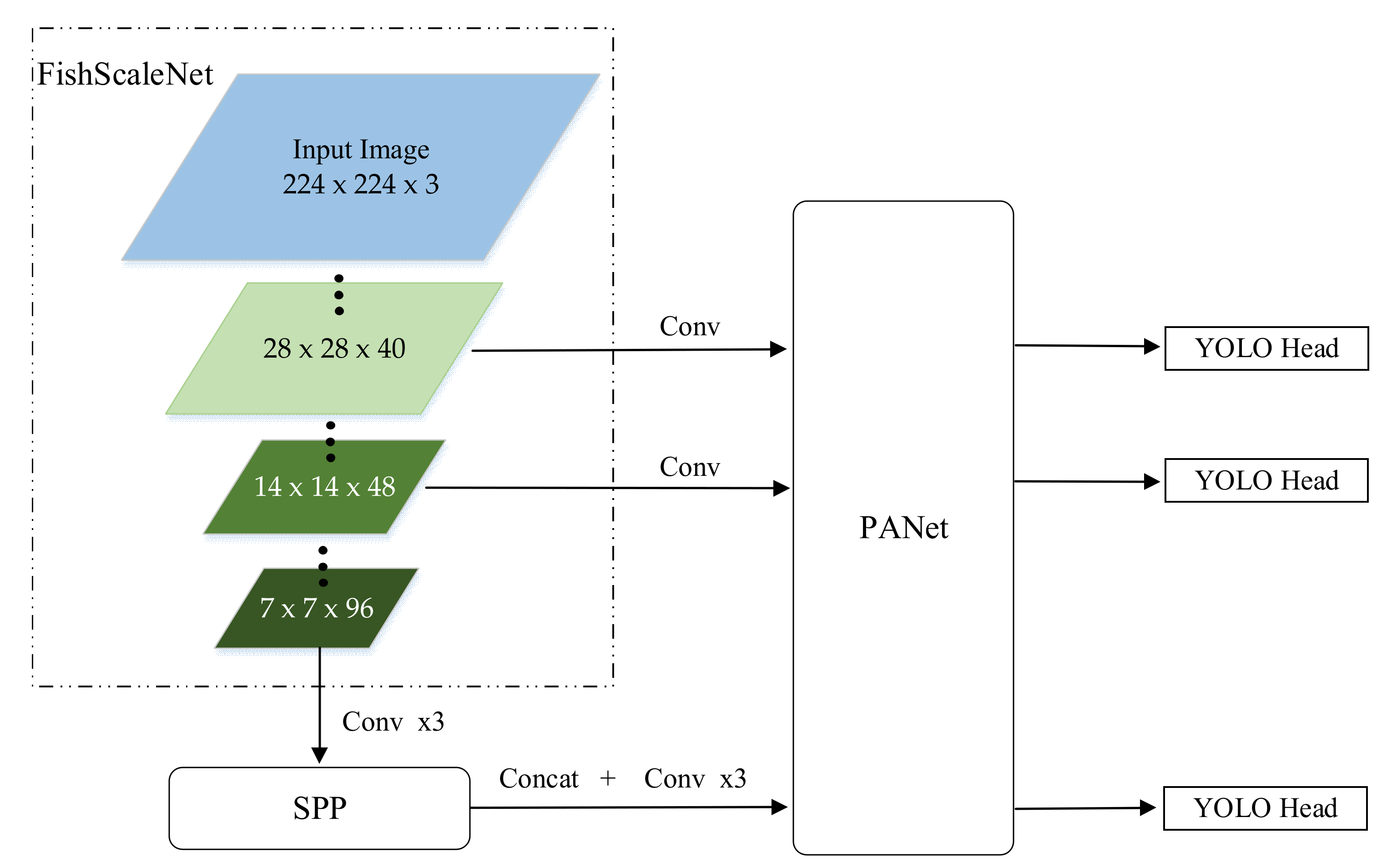
3.2. Lightweight YOLOv4
An ordinary object detector is composed of the backbone, neck, and head. The backbone network is used to extract the preliminary features, while the second part is used to extract the enhanced features. The final head is to get the predicted result. The backbone network of YOLOv4 is CSPDarknet [
46], the neck is SPP [
49] and PANet [
50], and the head is Yolo Head [
33].
As shown in
Figure 3, we replaced its backbone, CSPDarkNet, with a lightweight FishScaleNet, and kept the other main structures, such as Bag of Freebies (BoF) and Bag of Specials (BoS) for detector: CIoU-loss, CmBN, DropBlock regularization, mosaic data augmentation, self-adversarial training, eliminate grid sensitivity, using multiple anchors for a single ground truth, cosine annealing scheduler, optimal hyper-parameters, random training shapes, Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIoU-NMS [
34].
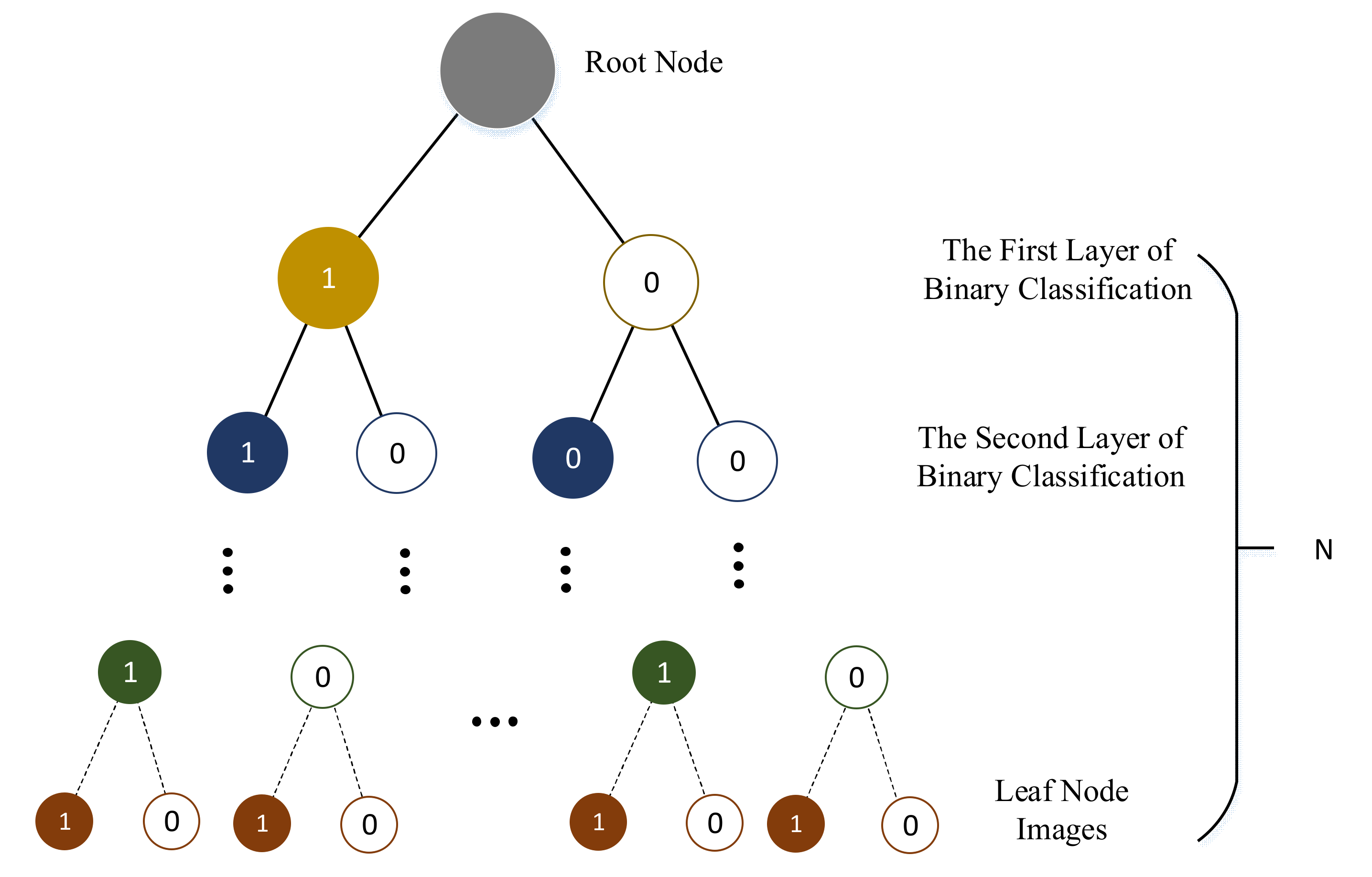
3.3. Binary Classified Tree
K-ary tree classifier is a fast graph classification algorithm, especially for large-scale graphs. The main idea of k-ary tree is to project the whole graph onto a set of optimized features in the common feature space without any prior knowledge of the subtree pattern. Then, a traversal table is constructed to track similar patterns in the optimization data [
51].
The k-ary tree in BoW [
9] is a hierarchical K-means clustering, which obtains a tree with the depth of D and the branch of K, which can store KD words. It can be seen in
Figure 4.
In LFM-LCD, we can directly use the result of object detection in the previous step. Sort the labels of the class detected by the target by the actual space size. Then the image is classified according to its detection label (predictions with rejection probability less than 0.5) in this order, and the binary sequence of each image is obtained. The classification results are represented by vectors. The structure can be seen in
Figure 5.
where
c denotes the vector quantity of the binary classification. The
represents the category labels.
We eliminated the labels with a predicted probability of less than 0.5, and we also had to remove the non-influential labels in this scenario to expand the classification. We randomly extracted the classification vectors of M images,
. Then, the number of repeated appearances of each label in the M pictures,
was calculated. Finally, we can calculate the influence
of the label and remove the labels whose
was less than the threshold value.
We can get the category of each key frame through the binary classification tree. Then, we can carry out feature matching between images of the same category. In order to eliminate the error caused by the different detection results of the target detection algorithm for small objects, the order of binary classification is carried out from large objects to small objects. Set the number of images of the same category for feature matching to be at least m. When the current frame image enters the classification tree, if there is no image of the same category or the number is less than m, the upper binary classification can be traced to improve the accuracy of LCD.
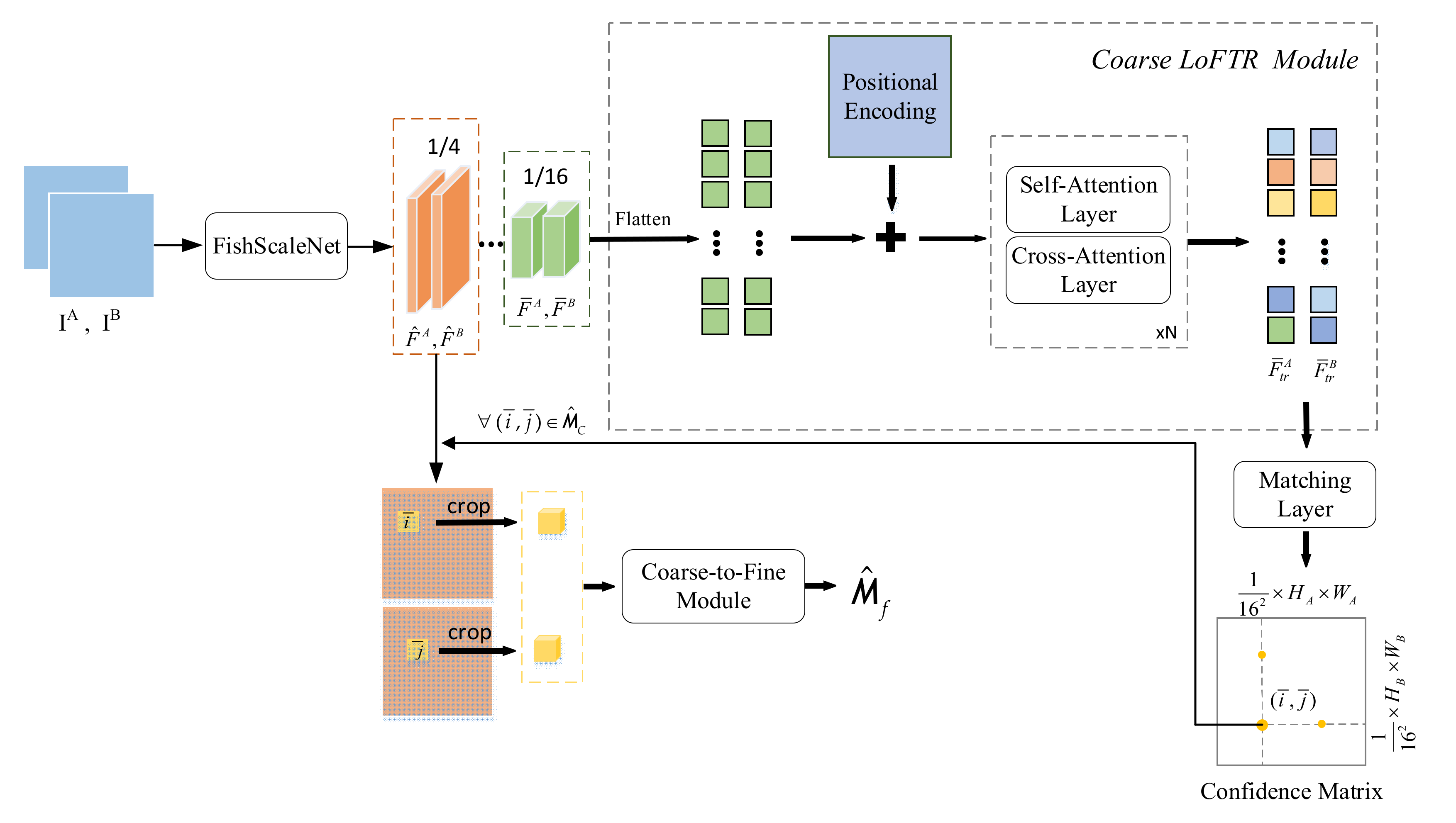
3.4. Feature Matching Based on LoFTR
Compared with other feature matching algorithms, such as ORB [
15] and SuperPoint [
40], LoFTR [
45] can solve the repeatability problem of feature detector. This is critical for the LCD task in SLAM. It is similar to LOFTR, i.e., our feature matching task performed fine-level feature matching after coarse-level feature matching. The difference is that we did not use standard CNN to extract features. Instead, we used FishScaleNet proposed in
Section 3.1. Meanwhile, we chose a feature map with a smaller size to further reduce the calculation amount of feature matching. The overview of the lightweight LoFTR can be seen in
Figure 6.
3.4.1. Lightweight Feature Extraction
For two similar images IA and IB in the same category, we used FishScaleNet to extract the multi-level features of the two images. LoFTR uses features extracted at 1/8 and 1/2. For lightweight FishScaleNet, and are used to represent coarse features extracted at 1/16 of the original image size, and are used to represent fine features extracted at 1/4 of the original image size.
3.4.2. Coarse LoFTR Module
LOFTR converts
and
into easier features, represented by
and
. In the self-attention layer, the input vectors are Q (query), K (key), and V(value). The query vector Q obtains attention weight information according to its dot product with the K vector and the corresponding with V. It is expressed as follows:
We used the same position encoding approach as DETR [
34]. In the self-attention layer, the two groups of the encoded features are the same, while in the cross-attention layer, the cross direction determines the change of features. After the self-attentional layer and the cross-attentional layer, we get two new groups of features
and
. The scoring matrix between the new features is S:
After the new feature passes through the matching layer, the confidence matrix
of the coarse level feature is obtained, and its size is
. Where, the matching probability in
is obtained by softmax on both dimension:
Then Mutual Nearest Neighbor (MNN) is used to eliminate outliers in the confidence matrix to obtain
.
3.4.3. Coarse-to-Fine Module
For arbitrary coarse matching , it is projected into 1/4 fine feature to obtain a small matching window. Since the proportion of coarse-to-fine is 4:1, the cropped feature . Two local fine features A and B are generated through LOFTR. By calculating the expected value of the probability distribution, the subpixel accuracy of the final position is obtained. All marches are collect to generate the final fine-level match .
5. Discussions
As with the RP-Curve shown in
Figure 10, compared with other methods, LFM-LCD has higher reliability in regards to indoor data sets of specific objects, which is quite conducive to SLAM of indoor robots. However, when we attempt to increase the key frame input frequency, our approach may not be able to achieve real-time results. Therefore, we still have a lot of room for improvement in speed and application for outdoor scenes needs to be improved too.
In addition, the area where the object features are not obvious will lead to a single classification, which will increase the burden of LFM. Therefore, we need to further optimize the label results of target detection in the future to solve this problem, e.g., by using semantic segmentation or instance segmentation instead of simple target detection networks. Of course, there are other problems, such as the complex scaling of the fish-scale block, which makes it less efficient. We still have a lot of work to do in the future, such as redesigning a more efficient lightweight backbone, or simplifying our methods to adapt to more real-time scenarios as much as possible.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}